Von Amazon verwalteter Workflow für Apache Airflow (Amazon MWAA) ist ein verwalteter Dienst, der Ihnen die Nutzung eines vertrauten Produkts ermöglicht Apache-Luftstrom Umgebung mit verbesserter Skalierbarkeit, Verfügbarkeit und Sicherheit, um Ihre Geschäftsabläufe zu verbessern und zu skalieren, ohne die betriebliche Belastung durch die Verwaltung der zugrunde liegenden Infrastruktur. Im Luftstrom, Gerichtete azyklische Graphen (DAGs) werden als Python-Code definiert. Dynamische DAGs beziehen sich auf die Möglichkeit, DAGs im laufenden Betrieb zur Laufzeit zu generieren, typischerweise basierend auf einigen externen Bedingungen, Konfigurationen oder Parametern. Mit dynamischen DAGs können Sie Aufgaben innerhalb eines DAG erstellen, planen und ausführen, basierend auf Daten und Konfigurationen, die sich im Laufe der Zeit ändern können.
Es gibt verschiedene Möglichkeiten, Dynamik in Airflow-DAGs einzuführen (dynamische DAG-Generierung) mithilfe von Umgebungsvariablen und externen Dateien. Einer der Ansätze besteht darin, das zu verwenden DAG-Fabrik YAML-basierte Konfigurationsdateimethode. Diese Bibliothek soll die Erstellung und Konfiguration neuer DAGs durch die Verwendung deklarativer Parameter in YAML erleichtern. Es ermöglicht Standardanpassungen und ist Open Source, sodass neue Funktionen einfach erstellt und angepasst werden können.
In diesem Beitrag untersuchen wir den Prozess der Erstellung dynamischer DAGs mit YAML-Dateien mithilfe von DAG-Fabrik Bibliothek. Dynamische DAGs bieten mehrere Vorteile:
- Verbesserte Wiederverwendbarkeit des Codes – Durch die Strukturierung von DAGs über YAML-Dateien fördern wir wiederverwendbare Komponenten und reduzieren so die Redundanz in Ihren Workflow-Definitionen.
- Optimierte Wartung – Die YAML-basierte DAG-Generierung vereinfacht den Prozess der Änderung und Aktualisierung von Arbeitsabläufen und sorgt so für reibungslosere Wartungsabläufe.
- Flexible Parametrierung – Mit YAML können Sie DAG-Konfigurationen parametrisieren und so dynamische Anpassungen von Arbeitsabläufen basierend auf unterschiedlichen Anforderungen ermöglichen.
- Verbesserte Effizienz des Planers – Dynamische DAGs ermöglichen eine effizientere Planung, optimieren die Ressourcenzuteilung und verbessern die gesamten Arbeitsabläufe
- Verbesserte Skalierbarkeit – YAML-gesteuerte DAGs ermöglichen parallele Ausführungen und ermöglichen so skalierbare Workflows, mit denen erhöhte Arbeitslasten effizient bewältigt werden können.
Indem wir die Leistungsfähigkeit von YAML-Dateien und der DAG Factory-Bibliothek nutzen, entfesseln wir einen vielseitigen Ansatz zum Erstellen und Verwalten von DAGs und ermöglichen Ihnen die Erstellung robuster, skalierbarer und wartbarer Datenpipelines.
Lösungsübersicht
In diesem Beitrag verwenden wir eine Beispiel-DAG-Datei, die für die Verarbeitung eines COVID-19-Datensatzes konzipiert ist. Der Workflow-Prozess umfasst die Verarbeitung eines Open-Source-Datensatzes, der von angeboten wird WHO-COVID-19-Global. Nachdem wir die installiert haben DAG-Fabrik Mit dem Python-Paket erstellen wir eine YAML-Datei, die Definitionen verschiedener Aufgaben enthält. Die landesspezifischen Sterbefallzahlen verarbeiten wir passiv Country als Variable, die einzelne länderbasierte DAGs erstellt.
Das folgende Diagramm veranschaulicht die Gesamtlösung zusammen mit den Datenflüssen innerhalb logischer Blöcke.

Voraussetzungen:
Für diese exemplarische Vorgehensweise sollten Sie die folgenden Voraussetzungen erfüllen:
Führen Sie außerdem die folgenden Schritte aus (führen Sie das Setup in einem aus AWS-Region wo Amazon MWAA verfügbar ist):
- Erstellen Sie ein Amazon MWAA-Umgebung (falls Sie noch keins haben). Wenn Sie Amazon MWAA zum ersten Mal verwenden, lesen Sie Einführung von Amazon Managed Workflows für Apache Airflow (MWAA).
Stellen Sie sicher, dass die AWS Identity and Access Management and (IAM)-Benutzer oder -Rolle, die zum Einrichten der Umgebung verwendet werden, verfügen über IAM-Richtlinien für die folgenden Berechtigungen:
Die hier erwähnten Zugriffsrichtlinien dienen nur als Beispiel in diesem Beitrag. Stellen Sie in einer Produktionsumgebung nur die erforderlichen detaillierten Berechtigungen durch Ausübung bereit Prinzipien der geringsten Privilegien.
- Erstellen Sie beim Erstellen Ihrer Amazon MWAA-Umgebung einen eindeutigen (innerhalb eines Kontos) Amazon S3-Bucket-Namen und erstellen Sie Ordner mit dem Namen
dagsundrequirements.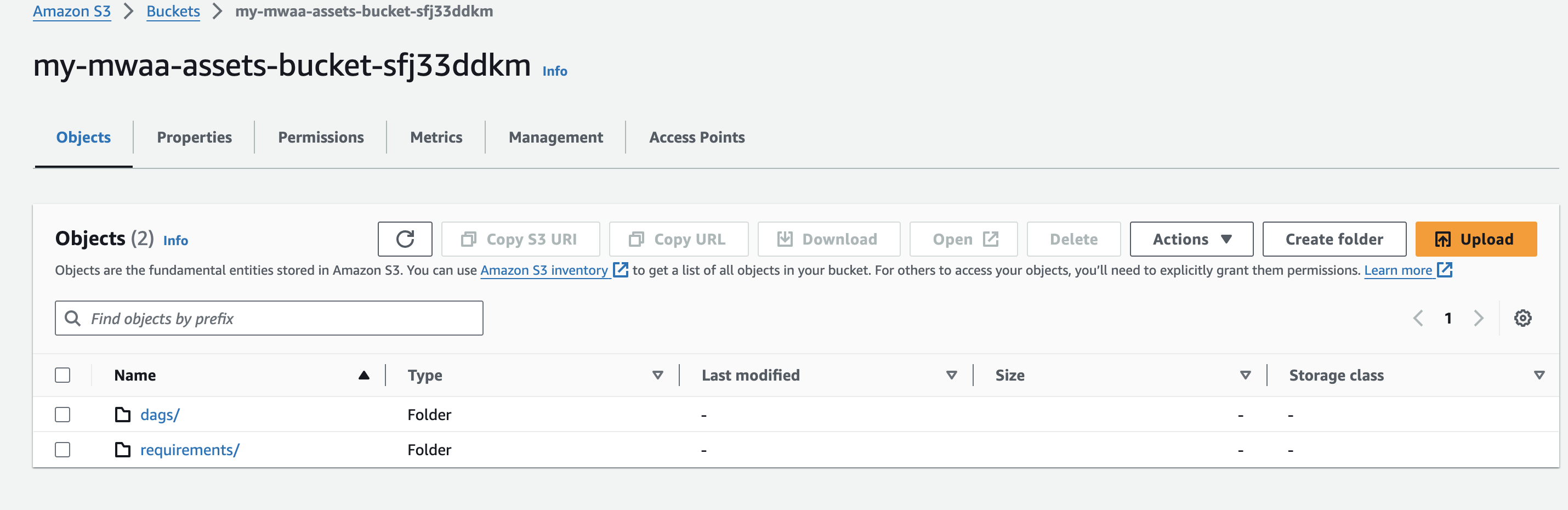
- Erstellen und hochladen Sie a
requirements.txtDatei mit folgendem Inhalt zumrequirementsOrdner. Ersetzen{environment-version}mit der Versionsnummer Ihrer Umgebung und{Python-version}mit der Python-Version, die mit Ihrer Umgebung kompatibel ist:
Pandas wird nur für den in diesem Beitrag beschriebenen Beispielanwendungsfall benötigt dag-factory ist das einzige erforderliche Plug-in. Es wird empfohlen, die Kompatibilität der neuesten Version von zu überprüfen dag-factory mit Amazon MWAA. Der boto und psycopg2-binary Bibliotheken sind in der Basisinstallation von Apache Airflow v2 enthalten und müssen in Ihrer nicht angegeben werden requirements.txt Datei.
- Laden Sie die WHO-COVID-19-globale Datendatei auf Ihren lokalen Computer und laden Sie es unter hoch
dagsPräfix Ihres S3-Buckets.
Stellen Sie sicher, dass Sie auf die neueste AWS S3-Bucket-Version Ihres verweisen requirements.txt Datei, damit die zusätzliche Paketinstallation durchgeführt werden kann. Dies sollte je nach Umgebungskonfiguration normalerweise zwischen 15 und 20 Minuten dauern.
Validieren Sie die DAGs
Wenn Ihre Amazon MWAA-Umgebung als angezeigt wird Verfügbar Navigieren Sie auf der Amazon MWAA-Konsole zur Airflow-Benutzeroberfläche, indem Sie auswählen Öffnen Sie die Airflow-Benutzeroberfläche neben Ihrer Umgebung.

Überprüfen Sie die vorhandenen DAGs, indem Sie zur Registerkarte „DAGs“ navigieren.
Konfigurieren Sie Ihre DAGs
Führen Sie die folgenden Schritte aus:
- Erstellen Sie leere Dateien mit dem Namen
dynamic_dags.yml,example_dag_factory.pyundprocess_s3_data.pyauf Ihrem lokalen Computer. - Bearbeiten Sie das
process_s3_data.pyDatei und speichern Sie sie mit dem folgenden Codeinhalt. Laden Sie die Datei dann wieder in den Amazon S3-Bucket hochdagsOrdner. Wir führen einige grundlegende Datenverarbeitungen im Code durch:- Lesen Sie die Datei von einem Amazon S3-Speicherort
- Benennen Sie die
Country_codeGeben Sie die entsprechende Spalte für das Land ein. - Filtern Sie Daten nach dem angegebenen Land.
- Schreiben Sie die verarbeiteten Enddaten in das CSV-Format und laden Sie sie zurück in das S3-Präfix hoch.
- Bearbeiten Sie das
dynamic_dags.ymlund speichern Sie es mit dem folgenden Codeinhalt, dann laden Sie die Datei wieder hochdagsOrdner. Wir fügen verschiedene DAGs je nach Land wie folgt zusammen:- Definieren Sie die Standardargumente, die an alle DAGs übergeben werden.
- Erstellen Sie durch Übergabe eine DAG-Definition für einzelne Länder
op_args - Karte der
process_s3_datafunktionieren mitpython_callable_name. - Verwenden Sie die Python-Operator um im Amazon S3-Bucket gespeicherte CSV-Dateidaten zu verarbeiten.
- Wir haben eingestellt
schedule_intervalB. 10 Minuten, Sie können diesen Wert jedoch nach Bedarf anpassen.
- Bearbeiten Sie die Datei
example_dag_factory.pyund speichern Sie es mit dem folgenden Codeinhalt, dann laden Sie die Datei wieder hochdagsOrdner. Der Code bereinigt die vorhandenen DAGs und generiert sieclean_dags()Methode und das Erstellen neuer DAGs mithilfe dergenerate_dags()Methode aus demDagFactoryBeispiel.
- Nachdem Sie die Dateien hochgeladen haben, kehren Sie zur Airflow-UI-Konsole zurück und navigieren Sie zur Registerkarte „DAGs“, wo Sie neue DAGs finden.
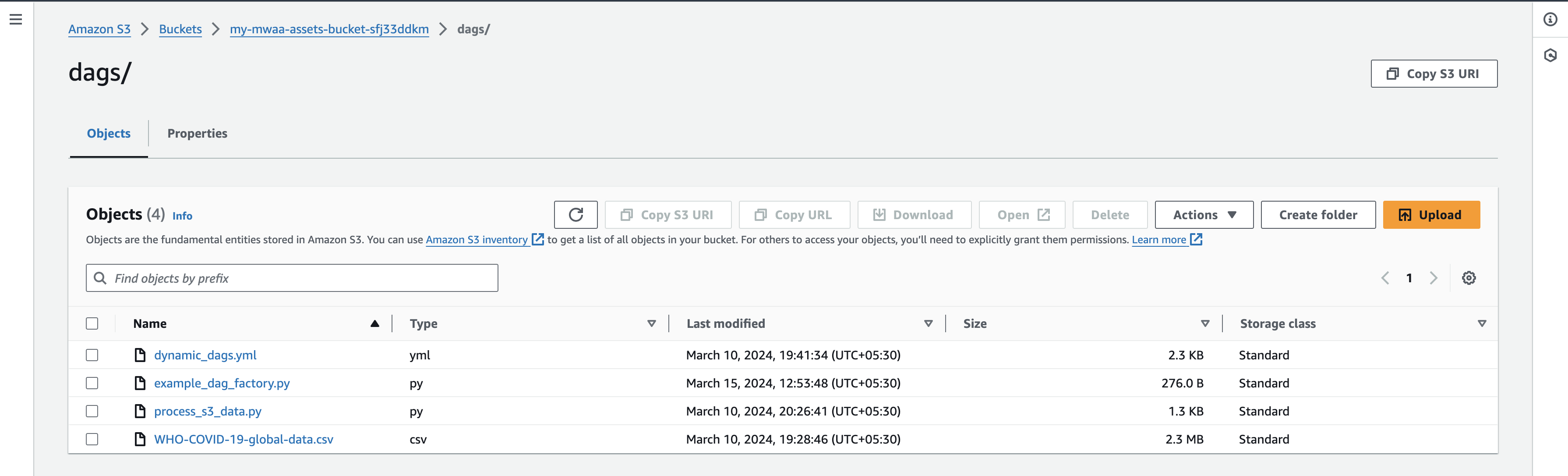
- Sobald Sie die Dateien hochgeladen haben, kehren Sie zur Airflow-UI-Konsole zurück. Auf der Registerkarte „DAGs“ werden neue DAGs angezeigt, wie unten dargestellt:

Sie können DAGs aktivieren, indem Sie sie aktiv machen und einzeln testen. Bei der Aktivierung wird eine zusätzliche CSV-Datei namens count_death_{COUNTRY_CODE}.csv wird im dags-Ordner generiert.
Aufräumen
Mit der Nutzung der verschiedenen in diesem Beitrag besprochenen AWS-Dienste können Kosten verbunden sein. Um zu verhindern, dass in Zukunft Gebühren anfallen, löschen Sie die Amazon MWAA-Umgebung, nachdem Sie die in diesem Beitrag beschriebenen Aufgaben abgeschlossen haben, und leeren und löschen Sie den S3-Bucket.
Zusammenfassung
In diesem Blogbeitrag haben wir gezeigt, wie man das verwendet Dag-Fabrik Bibliothek zum Erstellen dynamischer DAGs. Dynamische DAGs zeichnen sich durch ihre Fähigkeit aus, bei jedem Parsen der DAG-Datei basierend auf Konfigurationen Ergebnisse zu generieren. Erwägen Sie die Verwendung dynamischer DAGs in den folgenden Szenarien:
- Automatisierung der Migration von einem Altsystem zu Airflow, wo Flexibilität bei der DAG-Generierung von entscheidender Bedeutung ist
- Situationen, in denen sich nur ein Parameter zwischen verschiedenen DAGs ändert, wodurch der Workflow-Management-Prozess optimiert wird
- Verwalten von DAGs, die auf die sich entwickelnde Struktur eines Quellsystems angewiesen sind, und sorgen so für Anpassungsfähigkeit an Änderungen
- Etablieren Sie standardisierte Praktiken für DAGs in Ihrem Team oder Ihrer Organisation, indem Sie diese Blaupausen erstellen und so Konsistenz und Effizienz fördern
- Umfassende YAML-basierte Deklarationen statt komplexer Python-Codierung, wodurch DAG-Konfigurations- und Wartungsprozesse vereinfacht werden
- Erstellen Sie datengesteuerte Arbeitsabläufe, die sich auf der Grundlage der Dateneingaben anpassen und weiterentwickeln und so eine effiziente Automatisierung ermöglichen
Durch die Integration dynamischer DAGs in Ihren Workflow können Sie die Automatisierung, Anpassungsfähigkeit und Standardisierung verbessern und letztendlich die Effizienz und Effektivität Ihres Datenpipeline-Managements verbessern.
Weitere Informationen zur Amazon MWAA DAG Factory finden Sie unter Amazon MWAA für Analytics-Workshop: DAG Factory. Weitere Details und Codebeispiele zu Amazon MWAA finden Sie unter Amazon MWAA-Benutzerhandbuch und für Amazon MWAA-Beispiele GitHub Repository.
Über die Autoren
 Jayesh Shinde ist Senior Application Architect bei AWS ProServe India. Er ist auf die Entwicklung verschiedener Cloud-zentrierter Lösungen spezialisiert und nutzt moderne Softwareentwicklungspraktiken wie Serverless, DevOps und Analytics.
Jayesh Shinde ist Senior Application Architect bei AWS ProServe India. Er ist auf die Entwicklung verschiedener Cloud-zentrierter Lösungen spezialisiert und nutzt moderne Softwareentwicklungspraktiken wie Serverless, DevOps und Analytics.
 Harshd Yeola ist Sr. Cloud Architect bei AWS ProServe India und unterstützt Kunden bei der Migration und Modernisierung ihrer Infrastruktur in AWS. Er ist auf den Aufbau von DevSecOps und skalierbarer Infrastruktur mithilfe von Containern, AIOPs sowie AWS-Entwicklertools und -Services spezialisiert.
Harshd Yeola ist Sr. Cloud Architect bei AWS ProServe India und unterstützt Kunden bei der Migration und Modernisierung ihrer Infrastruktur in AWS. Er ist auf den Aufbau von DevSecOps und skalierbarer Infrastruktur mithilfe von Containern, AIOPs sowie AWS-Entwicklertools und -Services spezialisiert.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/dynamic-dag-generation-with-yaml-and-dag-factory-in-amazon-mwaa/

