Ab Version 6.14 Amazon EMR-Studio unterstützt interaktive Analysen auf Amazon EMR ohne Server. Sie können jetzt zusätzlich zu Amazon EMR auf EC2-Clustern auch EMR Serverless-Anwendungen als Rechenleistung verwenden Amazon EMR auf EKS virtuelle Cluster, um JupyterLab-Notebooks von EMR Studio Workspaces aus auszuführen.
EMR Studio ist eine integrierte Entwicklungsumgebung (IDE), die es Datenwissenschaftlern und Dateningenieuren erleichtert, in PySpark, Python und Scala geschriebene Analyseanwendungen zu entwickeln, zu visualisieren und zu debuggen. EMR Serverless ist eine serverlose Option für Amazon EMR Dadurch ist es einfach, Open-Source-Frameworks für Big-Data-Analysen wie Apache Spark auszuführen, ohne Cluster oder Server konfigurieren, verwalten und skalieren zu müssen.
Im Beitrag zeigen wir, wie man Folgendes macht:
- Erstellen Sie einen serverlosen EMR-Endpunkt für interaktive Anwendungen
- Hängen Sie den Endpunkt an eine vorhandene EMR Studio-Umgebung an
- Erstellen Sie ein Notizbuch und führen Sie eine interaktive Anwendung aus
- Diagnostizieren Sie interaktive Anwendungen nahtlos in EMR Studio
Voraussetzungen:
In einer typischen Organisation richtet ein AWS-Kontoadministrator AWS-Ressourcen ein, z AWS Identitäts- und Zugriffsverwaltung (IAM) Rollen, Amazon Simple Storage-Service (Amazon S3) Eimer und Amazon Virtual Private Cloud (Amazon VPC)-Ressourcen für den Internetzugang und den Zugriff auf andere Ressourcen in der VPC. Sie weisen EMR Studio-Administratoren zu, die die Einrichtung von EMR Studios und die Zuweisung von Benutzern zu einem bestimmten EMR Studio verwalten. Nach der Zuweisung können EMR Studio-Entwickler EMR Studio zum Entwickeln und Überwachen von Workloads verwenden.
Stellen Sie sicher, dass Sie Ressourcen wie Ihren S3-Bucket, VPC-Subnetze und EMR Studio in derselben AWS-Region einrichten.
Führen Sie die folgenden Schritte aus, um diese Voraussetzungen bereitzustellen:
- Starten Sie Folgendes AWS CloudFormation Stapel.

- Geben Sie Werte für ein Administrator-Passwort und DevPassword und notieren Sie sich die von Ihnen erstellten Passwörter.
- Auswählen Weiter.
- Behalten Sie die Standardeinstellungen bei und wählen Sie Weiter erneut.
- Auswählen Ich erkenne an, dass AWS CloudFormation möglicherweise IAM-Ressourcen mit benutzerdefinierten Namen erstellt.
- Wählen Sie „Senden“..
Wir haben auch Anweisungen zum manuellen Bereitstellen dieser Ressourcen mit Beispiel-IAM-Richtlinien im bereitgestellt GitHub Repo.
Richten Sie EMR Studio und eine serverlose interaktive Anwendung ein
Nachdem der AWS-Kontoadministrator die Voraussetzungen erfüllt hat, kann sich der EMR Studio-Administrator bei anmelden AWS-Managementkonsole um eine EMR Studio-, Workspace- und EMR Serverless-Anwendung zu erstellen.
Erstellen Sie ein EMR-Studio und einen Arbeitsbereich
Der EMR Studio-Administrator sollte sich mit bei der Konsole anmelden emrs-interactive-app-admin-user Benutzeranmeldeinformationen. Wenn Sie die erforderlichen Ressourcen mithilfe der bereitgestellten CloudFormation-Vorlage bereitgestellt haben, verwenden Sie das Kennwort, das Sie als Eingabeparameter angegeben haben.
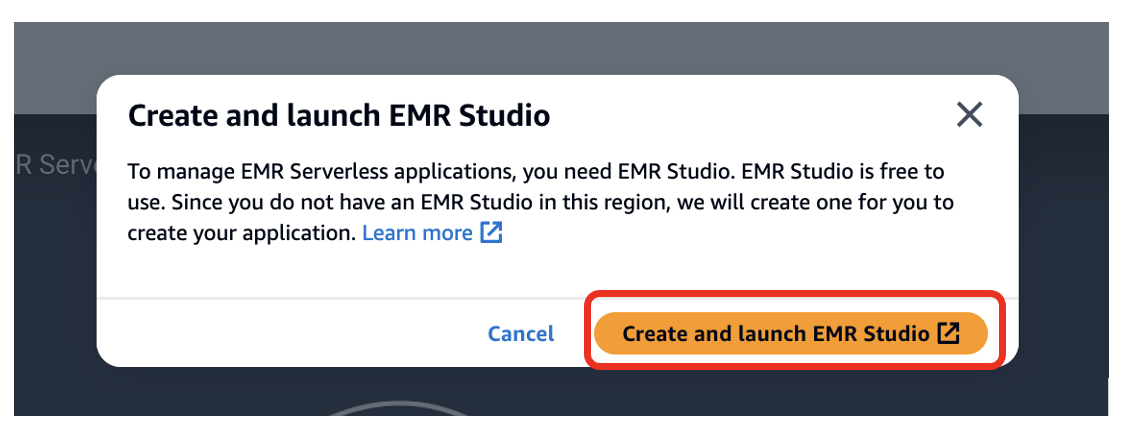
- Wählen Sie auf der Amazon EMR-Konsole EMR Serverlos im Navigationsbereich.

- Auswählen Los geht´s.
- Auswählen Erstellen und starten Sie EMR Studio.
Dadurch wird ein Studio mit dem Standardnamen erstellt studio_1 und einen Arbeitsbereich mit dem Standardnamen My_First_Workspace. Es öffnet sich ein neuer Browser-Tab Studio_1 Benutzeroberfläche.
Erstellen Sie eine serverlose EMR-Anwendung
Führen Sie die folgenden Schritte aus, um eine EMR Serverless-Anwendung zu erstellen:
- Wählen Sie auf der EMR Studio-Konsole aus Anwendungen im Navigationsbereich.
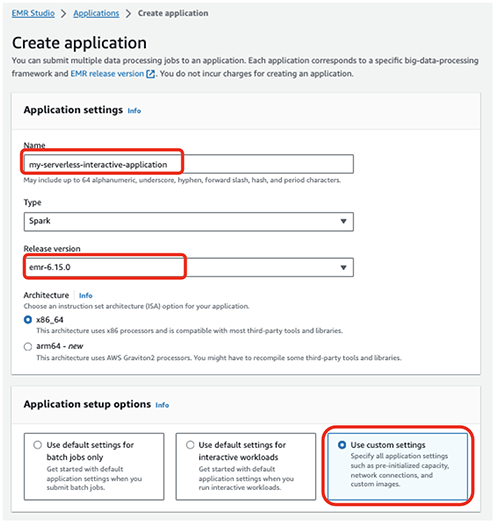
- Erstellen Sie eine neue Anwendung.
- Aussichten für Name und VornameGeben Sie einen Namen ein (z. B.
my-serverless-interactive-application). - Aussichten für Setup-Optionen für AnwendungenWählen Benutzerdefinierte Einstellungen verwenden für interaktive Workloads.
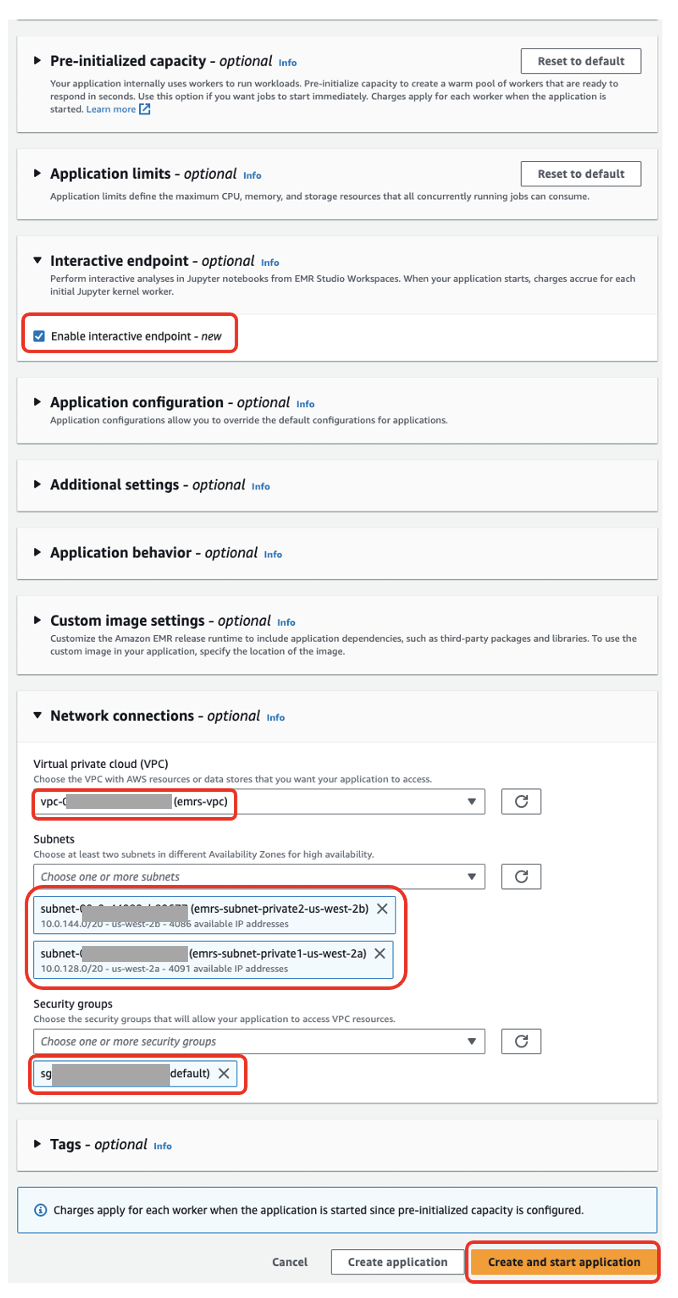
Für interaktive Anwendungen empfehlen wir als Best Practice, den Treiber und die Worker durch die Konfiguration vorinitialisiert zu halten vorinitialisierte Kapazität zum Zeitpunkt der Anwendungserstellung. Dadurch wird effektiv ein warmer Pool an Arbeitskräften für eine Anwendung erstellt und die Ressourcen bleiben einsatzbereit, sodass die Anwendung in Sekundenschnelle reagieren kann. Weitere Best Practices zum Erstellen serverloser EMR-Anwendungen finden Sie unter Definieren Sie Ressourcenlimits pro Team für Big-Data-Workloads mit Amazon EMR Serverless.
- Im Interaktiver Endpunkt Abschnitt auswählen Aktivieren Sie den interaktiven Endpunkt.
- Im Netzwerkverbindungen Wählen Sie im Abschnitt die VPC, die privaten Subnetze und die Sicherheitsgruppe aus, die Sie zuvor erstellt haben.
Wenn Sie den in diesem Beitrag bereitgestellten CloudFormation-Stack bereitgestellt haben, wählen Sie emr-serverless-sg als Sicherheitsgruppe.
Damit der Workload über die EMR Serverless-Anwendung auf das Internet zugreifen und externe Python-Pakete herunterladen kann, ist eine VPC erforderlich. Die VPC ermöglicht Ihnen auch den Zugriff auf Ressourcen wie z Relationaler Amazon-Datenbankdienst (Amazon RDS) und Amazon RedShift die sich in der VPC dieser Anwendung befinden. Das Anschließen einer serverlosen Anwendung an eine VPC kann zu einer IP-Erschöpfung im Subnetz führen. Stellen Sie daher sicher, dass in Ihrem Subnetz genügend IP-Adressen vorhanden sind.
- Auswählen Anwendung erstellen und starten.
Auf der Anwendungsseite können Sie überprüfen, ob sich der Status Ihrer serverlosen Anwendung in ändert Begann.
- Wählen Sie Ihre Anwendung aus und wählen Sie So funktioniert's.
- Auswählen Arbeitsbereiche anzeigen und starten.
- Auswählen Studio konfigurieren.
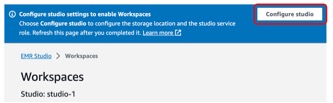
- Aussichten für Servicerolle¸ Stellen Sie die EMR Studio-Servicerolle bereit, die Sie als Voraussetzung erstellt haben (
emr-studio-service-role). - Aussichten für ArbeitsplatzspeicherGeben Sie den Pfad des S3-Buckets ein, den Sie als Voraussetzung erstellt haben (
emrserverless-interactive-blog-<account-id>-<region-name>). - Auswählen Änderungen speichern.
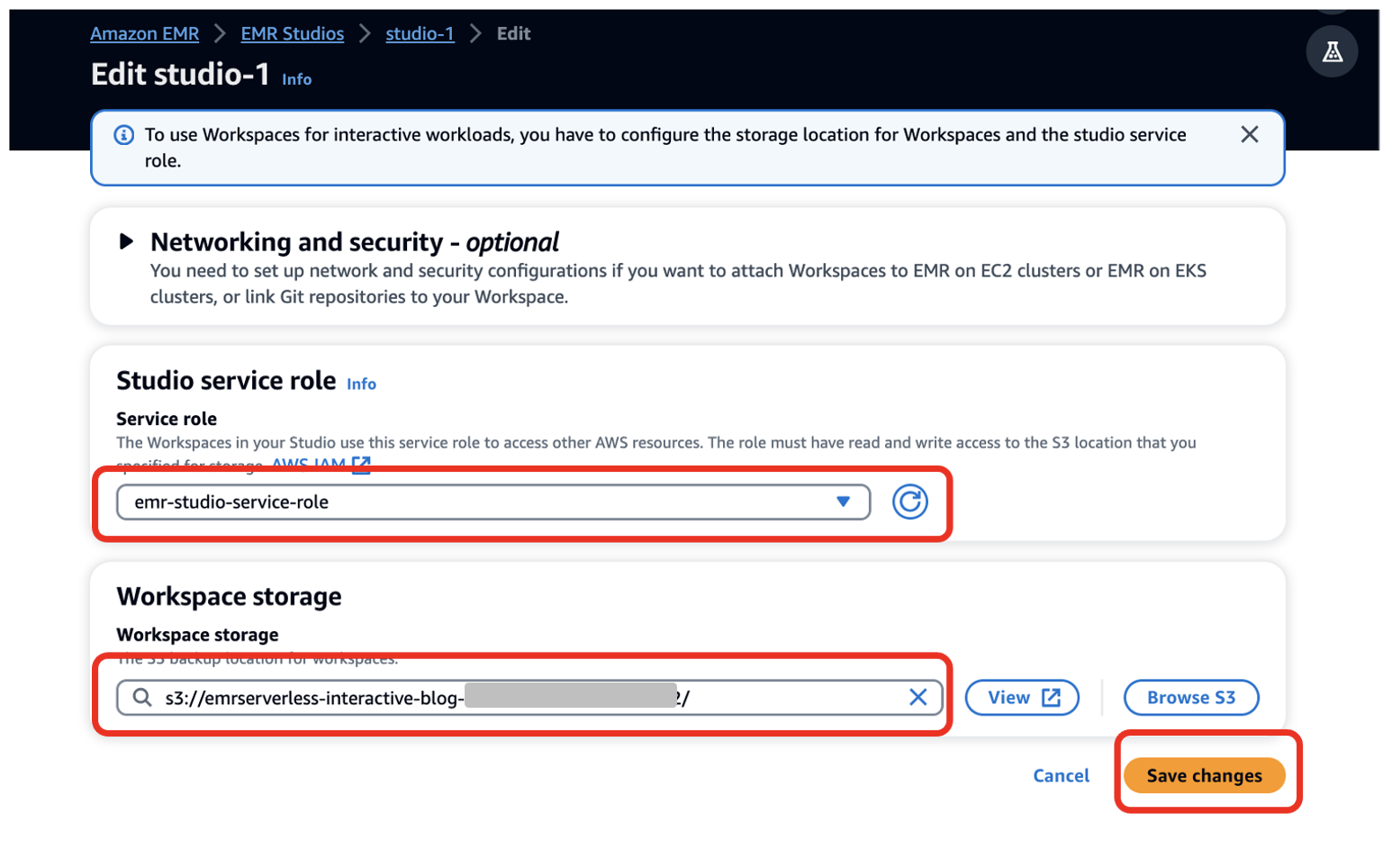
14. Navigieren Sie zur Studios-Konsole, indem Sie wählen Studios im linken Navigationsmenü im EMR-Studio Abschnitt. Beachten Sie das Studio-Zugriffs-URL von der Studios-Konsole aus und stellen Sie es Ihren Entwicklern zur Verfügung, damit diese ihre Spark-Anwendungen ausführen können.
Führen Sie Ihre erste Spark-Anwendung aus
Nachdem der EMR Studio-Administrator das Studio, den Workspace und die serverlose Anwendung erstellt hat, kann der Studio-Benutzer den Workspace und die Anwendung verwenden, um Spark-Workloads zu entwickeln und zu überwachen.
Starten Sie den Arbeitsbereich und hängen Sie die serverlose Anwendung an
Führen Sie die folgenden Schritte aus:
- Melden Sie sich mit der vom EMR Studio-Administrator bereitgestellten Studio-URL an
emrs-interactive-app-dev-userBenutzeranmeldeinformationen, die vom AWS-Kontoadministrator geteilt werden.
Wenn Sie die erforderlichen Ressourcen mithilfe der bereitgestellten CloudFormation-Vorlage bereitgestellt haben, verwenden Sie das Kennwort, das Sie als Eingabeparameter angegeben haben.
Auf dem Workspaces Auf der Seite können Sie den Status Ihres Arbeitsbereichs überprüfen. Wenn der Arbeitsbereich gestartet wird, sehen Sie, dass sich der Status in ändert Bereit.
- Starten Sie den Arbeitsbereich, indem Sie den Namen des Arbeitsbereichs auswählen (
My_First_Workspace).
Dadurch wird ein neuer Tab geöffnet. Stellen Sie sicher, dass Ihr Browser Pop-ups zulässt.
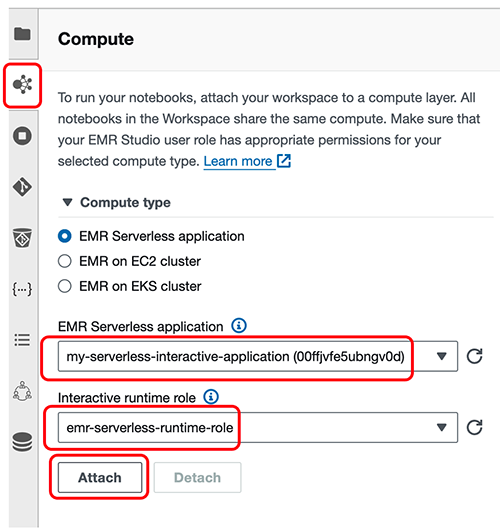
- Wählen Sie im Arbeitsbereich Berechnen (Cluster-Symbol) im Navigationsbereich.
- Aussichten für EMR Serverless-Anwendung, wählen Sie Ihre Anwendung (
my-serverless-interactive-application). - Aussichten für Interaktive Laufzeitrolle, wählen Sie eine interaktive Laufzeitrolle (für diesen Beitrag verwenden wir
emr-serverless-runtime-role). - Auswählen Anfügen um die serverlose Anwendung als Rechentyp für alle Notebooks in diesem Arbeitsbereich anzuhängen.
Führen Sie Ihre Spark-Anwendung interaktiv aus
Führen Sie die folgenden Schritte aus:
- Wähle die Notebook-Beispiele (Symbol mit drei Punkten) im Navigationsbereich und öffnen Sie es
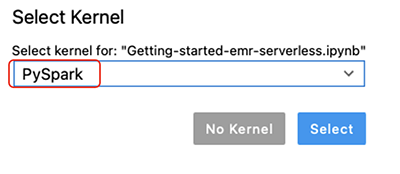
Getting-started-with-emr-serverlessNotebook. - Auswählen Im Arbeitsbereich speichern.
Für unser Notebook stehen drei Kernel zur Auswahl: Python 3, PySpark und Spark (für Scala).
- Wenn Sie dazu aufgefordert werden, wählen Sie PySpark als der Kernel.
- Auswählen Auswählen.
Jetzt können Sie Ihre Spark-Anwendung ausführen. Verwenden Sie dazu die %%configure Funkenmagie Befehl, der die Parameter für die Sitzungserstellung konfiguriert. Interaktive Anwendungen unterstützen virtuelle Python-Umgebungen. Wir verwenden eine benutzerdefinierte Umgebung in den Worker-Knoten, indem wir einen Pfad für eine andere Python-Laufzeit für die Executor-Umgebung angeben spark.executorEnv.PYSPARK_PYTHON. Siehe folgenden Code:
Externe Pakete installieren
Da Sie nun über eine unabhängige virtuelle Umgebung für die Mitarbeiter verfügen, können Sie mit EMR Studio-Notebooks mithilfe von Spark externe Pakete aus der serverlosen Anwendung heraus installieren install_pypi_package Funktion über den Spark-Kontext. Durch die Verwendung dieser Funktion wird das Paket für alle EMR Serverless-Worker verfügbar gemacht.
Installieren Sie zunächst matplotlib, ein Python-Paket, von PyPi:
Wenn der vorherige Schritt nicht reagiert, überprüfen Sie Ihr VPC-Setup und stellen Sie sicher, dass es für den Internetzugang richtig konfiguriert ist.
Jetzt können Sie einen Datensatz verwenden und Ihre Daten visualisieren.
Erstellen Sie Visualisierungen
Um Visualisierungen zu erstellen, verwenden wir einen öffentlichen Datensatz über gelbe Taxis in New York:
Im vorherigen Codeblock lesen Sie die Parquet-Datei aus einem öffentlichen Bucket in Amazon S3. Die Datei hat Header und wir möchten, dass Spark das Schema ableitet. Anschließend verwenden Sie einen Spark-Datenrahmen, um bestimmte Spalten daraus zu gruppieren und zu zählen taxi_df:
Verwenden Sie die %%display magic, um das Ergebnis im Tabellenformat anzuzeigen:
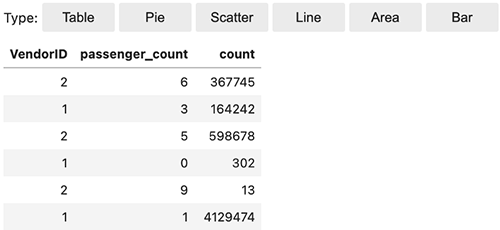
Sie können Ihre Daten auch schnell mit fünf Diagrammtypen visualisieren. Sie können den Anzeigetyp auswählen und das Diagramm ändert sich entsprechend. Im folgenden Screenshot verwenden wir ein Balkendiagramm zur Visualisierung unserer Daten.
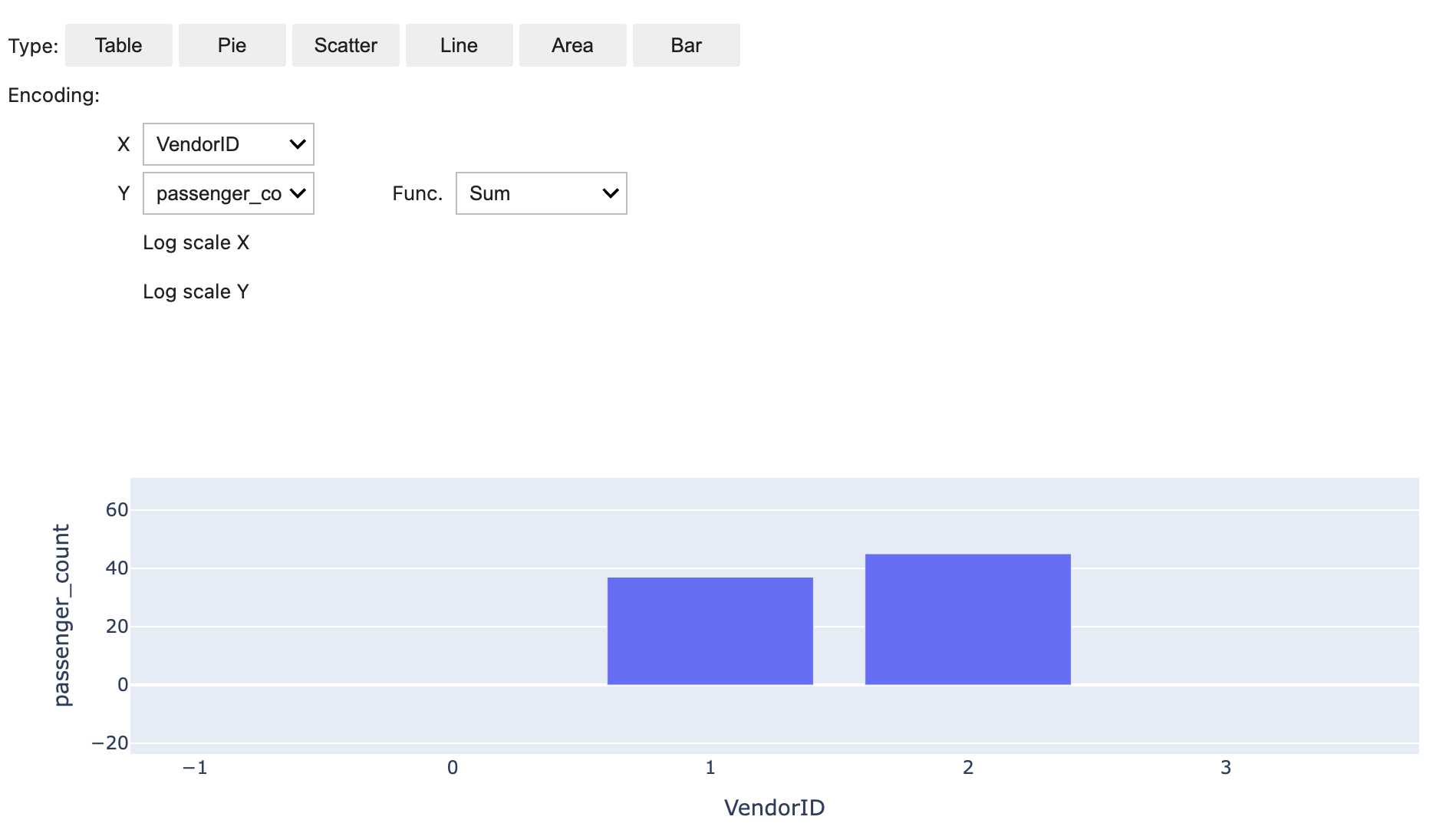
Interagieren Sie mit EMR Serverless über Spark SQL
Sie können mit Tabellen im interagieren AWS Glue-Datenkatalog Verwendung von Spark SQL auf EMR Serverless. Im Beispielnotizbuch zeigen wir, wie Sie Daten mithilfe eines Spark-Datenrahmens transformieren können.
Erstellen Sie zunächst eine neue temporäre Ansicht mit dem Namen „Taxis“. Dadurch können Sie Spark SQL verwenden, um Daten aus dieser Ansicht auszuwählen. Erstellen Sie dann einen Taxi-Datenrahmen zur weiteren Verarbeitung:
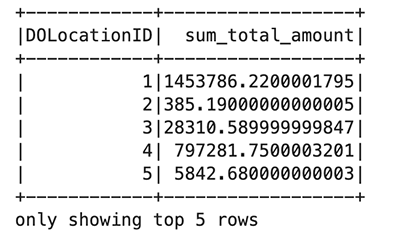
In jeder Zelle Ihres EMR Studio-Notizbuchs können Sie erweitern Spark-Jobfortschritt um die verschiedenen Phasen des an EMR Serverless übermittelten Jobs anzuzeigen, während diese bestimmte Zelle ausgeführt wird. Sie können die Zeit sehen, die zum Abschließen jeder Phase benötigt wird. Im folgenden Beispiel umfasst Phase 14 des Auftrags 12 abgeschlossene Aufgaben. Darüber hinaus können Sie im Falle eines Fehlers die Protokolle einsehen, was die Fehlerbehebung zu einem reibungslosen Erlebnis macht. Wir besprechen dies im nächsten Abschnitt ausführlicher.
![Job[14]: showString bei NativeMethodAccessorImpl.java:0 und Job[15]: showString bei NativeMethodAccessorImpl.java:0](https://zephyrnet.com/wp-content/uploads/2024/04/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio-amazon-web-services-11.png)
Verwenden Sie den folgenden Code, um den verarbeiteten Datenrahmen mithilfe des matplotlib-Pakets zu visualisieren. Sie verwenden die Bibliothek „maptplotlib“, um den Abgabeort und die Gesamtmenge als Balkendiagramm darzustellen.
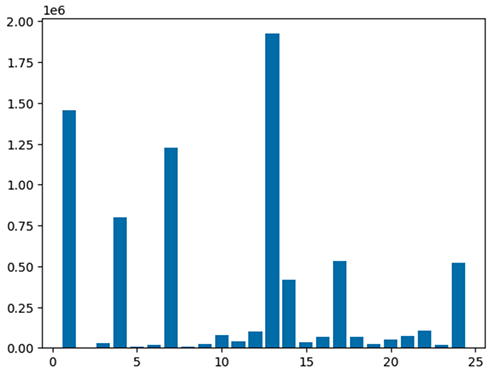
Diagnostizieren Sie interaktive Anwendungen
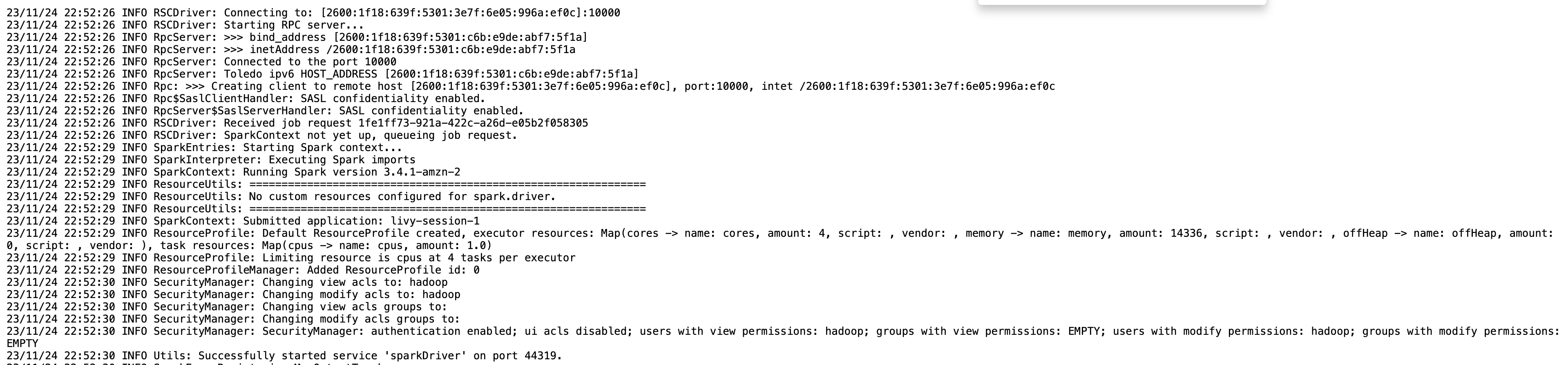
Sie können die Sitzungsinformationen für Ihren Livy-Endpunkt mithilfe von abrufen %%info Funkenmagie. Dadurch erhalten Sie Links zum Zugriff auf die Spark-Benutzeroberfläche sowie das Fahrerprotokoll direkt in Ihrem Notebook.

Der folgende Screenshot ist ein Treiberprotokollausschnitt für unsere Anwendung, den wir über den Link in unserem Notizbuch geöffnet haben.
Ebenso können Sie den untenstehenden Link wählen Spark-Benutzeroberfläche um die Benutzeroberfläche zu öffnen. Der folgende Screenshot zeigt die Vollstrecker Registerkarte, die Zugriff auf die Treiber- und Executor-Protokolle bietet.
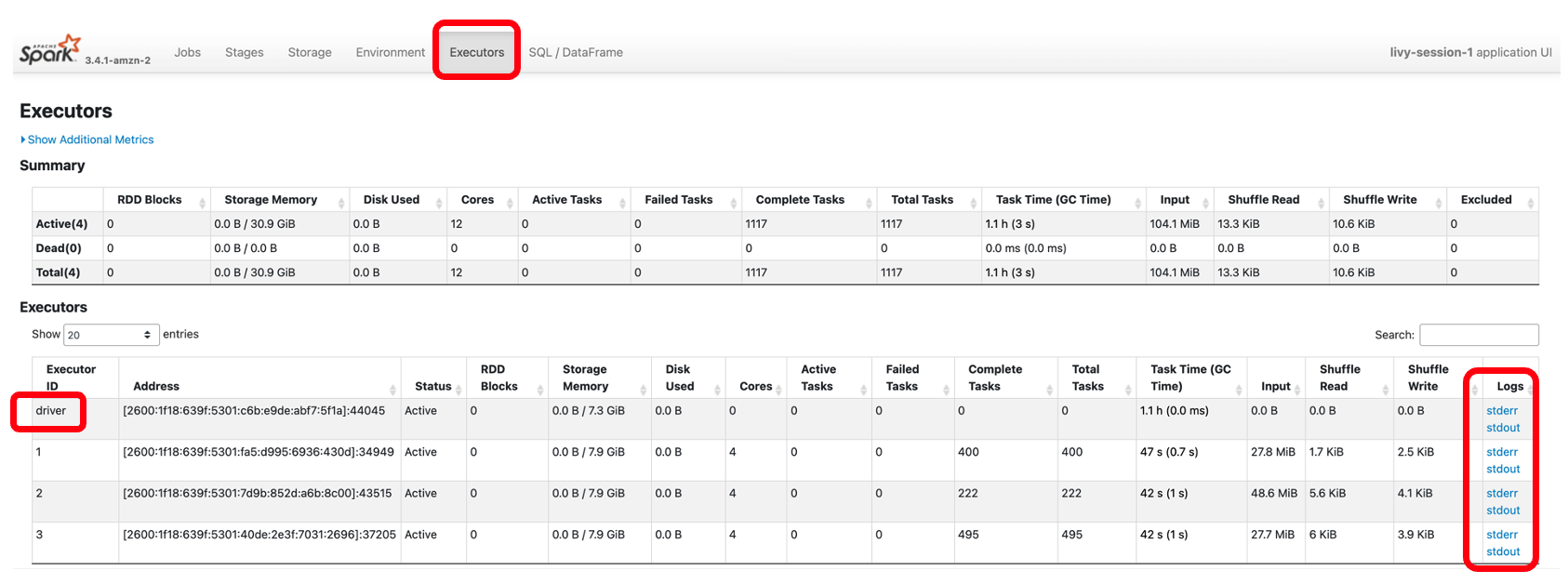
Der folgende Screenshot zeigt Stufe 14, die dem zuvor gesehenen Spark SQL-Schritt entspricht, in dem wir die standortbezogene Summe der gesamten Taxisammlungen berechnet haben, die in 12 Aufgaben unterteilt wurde. Über die Spark-Benutzeroberfläche stellt die interaktive Anwendung direkt von Ihrem Notebook aus detaillierte Status-, E/A- und Shuffle-Details auf Aufgabenebene sowie Links zu entsprechenden Protokollen für jede Aufgabe für diese Phase bereit und ermöglicht so eine nahtlose Fehlerbehebung.

Aufräumen
Wenn Sie die in diesem Beitrag erstellten Ressourcen nicht mehr behalten möchten, führen Sie die folgenden Bereinigungsschritte aus:
- Löschen Sie die EMR Serverless-Anwendung.
- Löschen Sie das EMR Studio und die zugehörigen Arbeitsbereiche und Notizbücher.
- Um die restlichen Ressourcen zu löschen, navigieren Sie zur CloudFormation-Konsole, wählen Sie den Stack aus und wählen Sie Löschen.
Alle Ressourcen werden gelöscht, mit Ausnahme des S3-Buckets, dessen Löschrichtlinie auf „Beibehalten“ eingestellt ist.
Zusammenfassung
Der Beitrag zeigte, wie man interaktive PySpark-Workloads in EMR Studio mit EMR Serverless als Rechenleistung ausführt. Sie können Spark-Anwendungen auch in einem interaktiven JupyterLab Workspace erstellen und überwachen.
In einem kommenden Beitrag werden wir zusätzliche Funktionen von EMR Serverless Interactive-Anwendungen besprechen, wie zum Beispiel:
- Arbeiten mit Ressourcen wie Amazon RDS und Amazon Redshift in Ihrer VPC (z. B. für JDBC/ODBC-Konnektivität)
- Ausführen transaktionaler Arbeitslasten mithilfe serverloser Endpunkte
Wenn Sie EMR Studio zum ersten Mal erkunden, empfehlen wir Ihnen, sich das anzusehen Amazon EMR-Workshops und unter Bezugnahme auf Erstellen Sie ein EMR-Studio.
Über die Autoren
 Sekar Srinivasan ist Principal Specialist Solutions Architect bei AWS mit Schwerpunkt auf Datenanalyse und KI. Sekar verfügt über mehr als 20 Jahre Erfahrung im Umgang mit Daten. Seine Leidenschaft besteht darin, Kunden dabei zu helfen, skalierbare Lösungen zu entwickeln, ihre Architektur zu modernisieren und Erkenntnisse aus ihren Daten zu gewinnen. In seiner Freizeit arbeitet er gerne an gemeinnützigen Projekten, die sich auf die Bildung benachteiligter Kinder konzentrieren.
Sekar Srinivasan ist Principal Specialist Solutions Architect bei AWS mit Schwerpunkt auf Datenanalyse und KI. Sekar verfügt über mehr als 20 Jahre Erfahrung im Umgang mit Daten. Seine Leidenschaft besteht darin, Kunden dabei zu helfen, skalierbare Lösungen zu entwickeln, ihre Architektur zu modernisieren und Erkenntnisse aus ihren Daten zu gewinnen. In seiner Freizeit arbeitet er gerne an gemeinnützigen Projekten, die sich auf die Bildung benachteiligter Kinder konzentrieren.
 Disha Umarwani ist Senior Data Architect bei Amazon Professional Services im Bereich Global Health Care und LifeSciences. Sie hat mit Kunden zusammengearbeitet, um maßstabsgetreue Datenstrategien zu entwerfen, zu entwerfen und umzusetzen. Sie ist auf die Architektur von Data Mesh-Architekturen für Unternehmensplattformen spezialisiert.
Disha Umarwani ist Senior Data Architect bei Amazon Professional Services im Bereich Global Health Care und LifeSciences. Sie hat mit Kunden zusammengearbeitet, um maßstabsgetreue Datenstrategien zu entwerfen, zu entwerfen und umzusetzen. Sie ist auf die Architektur von Data Mesh-Architekturen für Unternehmensplattformen spezialisiert.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio/

