Im Zeitalter der Daten nutzen Unternehmen zunehmend Data Lakes, um große Mengen strukturierter und unstrukturierter Daten zu speichern und zu analysieren. Data Lakes bieten ein zentrales Repository für Daten aus verschiedenen Quellen und ermöglichen es Unternehmen, wertvolle Erkenntnisse zu gewinnen und datengesteuerte Entscheidungen voranzutreiben. Da die Datenmengen jedoch weiter wachsen, wird die Optimierung des Datenlayouts und der Datenorganisation für effiziente Abfragen und Analysen von entscheidender Bedeutung.
Eine der größten Herausforderungen in Data Lakes ist die potenziell langsame Abfrageleistung, insbesondere beim Umgang mit großen Datenmengen. Dies kann auf Faktoren wie ein ineffizientes Datenlayout zurückgeführt werden, das zu übermäßigem Datenscannen und einer ineffizienten Nutzung von Rechenressourcen führt. Um dieser Herausforderung zu begegnen, können gängige Praktiken wie Partitionierung und Bucketing die Abfrageleistung erheblich verbessern und die Rechenkosten senken.
Partitionierung ist eine Technik, die einen großen Datensatz anhand bestimmter Kriterien wie Datum, Region oder Produktkategorie in kleinere, besser verwaltbare Teile unterteilt. Durch die Partitionierung von Daten können nachgelagerte Analyseabfragen irrelevante Partitionen überspringen und so die Datenmenge reduzieren, die gescannt und verarbeitet werden muss. Sie können Partitionsspalten in der WHERE-Klausel in Abfragen verwenden, um nur die spezifischen Partitionen zu scannen, die Ihre Abfrage benötigt. Dies kann zu schnelleren Abfragelaufzeiten und einer effizienteren Ressourcennutzung führen. Dies funktioniert besonders gut, wenn Spalten mit niedriger Kardinalität als Schlüssel ausgewählt werden.
Was ist, wenn Sie eine Spalte mit hoher Kardinalität haben, die Sie manchmal nach VIP-Kunden filtern müssen? Jeder Kunde wird in der Regel mit einer ID identifiziert, die mehrere Millionen betragen kann. Die Partitionierung eignet sich nicht für Spalten mit solch hoher Kardinalität, da am Ende kleine Dateien, eine langsame Partitionsfilterung und hohe Dateien entstehen Amazon Simple Storage-Service (Amazon S3) API-Kosten (ein S3-Präfix wird pro Wert der Partitionsspalte erstellt). Obwohl Sie die Partitionierung mit einem natürlichen Schlüssel wie Stadt oder Bundesland verwenden können, um Ihren Datensatz bis zu einem gewissen Grad einzugrenzen, ist es dennoch erforderlich, datumsbasierte Partitionen abzufragen, wenn es sich bei Ihren Daten um Zeitreihen handelt.
Das ist wo eimern kommt ins Spiel. Durch Bucketing wird sichergestellt, dass alle Zeilen mit den gleichen Werten einer oder mehrerer Spalten in derselben Datei landen. Anstelle einer Datei pro Wert, wie bei der Partitionierung, wird eine Hash-Funktion verwendet, um Werte gleichmäßig auf eine feste Anzahl von Dateien zu verteilen. Durch die Organisation der Daten auf diese Weise können Sie eine effiziente Filterung durchführen, da nur die relevanten Buckets verarbeitet werden müssen, was den Rechenaufwand weiter reduziert.
Es gibt mehrere Optionen für die Implementierung von Bucketing in AWS. Ein Ansatz besteht darin, das zu verwenden Amazonas Athena CREATE TABLE AS SELECT (CTAS)-Anweisung, mit der Sie eine Bucket-Tabelle direkt aus einer Abfrage erstellen können. Alternativ können Sie verwenden AWS-Kleber für Apache Spark, das integrierte Unterstützung für Bucketing-Konfigurationen während des Datentransformationsprozesses bietet. Mit AWS Glue können Sie Bucketing-Parameter definieren, z. B. die Anzahl der Buckets und die Spalten, in denen Buckets erstellt werden sollen, und so ein optimiertes Datenlayout für effiziente Abfragen mit Athena bereitstellen.
In diesem Beitrag diskutieren wir, wie man Bucketing in AWS Data Lakes implementiert, einschließlich der Verwendung der Athena CTAS-Anweisung und AWS Glue für Apache Spark. Wir decken auch das Bucketing für Apache Iceberg-Tabellen ab.
Beispielanwendungsfall
In diesem Beitrag verwenden Sie einen öffentlichen Datensatz, den Integrierte Oberflächendatenbank der NOAA. Datenanalysten führen über Athena einmalige Datenabfragen der letzten fünf Jahre durch. Die meisten Abfragen beziehen sich auf bestimmte Stationen mit bestimmten Berichtstypen. Die Abfragen müssen in 5 Sekunden abgeschlossen sein und die Kosten müssen sorgfältig optimiert werden. In diesem Szenario sind Sie ein Dateningenieur, der für die Optimierung der Abfrageleistung und -kosten verantwortlich ist.
Wenn ein Analyst beispielsweise Daten für eine bestimmte Station abrufen möchte (z. B. Stations-ID). 123456) mit einem bestimmten Berichtstyp (z. B. CRN01), könnte die Abfrage wie folgt aussehen:
Im Fall der NOAA Integrated Surface Database ist die station_id Die Spalte weist wahrscheinlich eine hohe Kardinalität mit zahlreichen eindeutigen Stationskennungen auf. Andererseits ist die report_type Die Spalte hat möglicherweise eine relativ geringe Kardinalität und nur eine begrenzte Anzahl von Berichtstypen. Angesichts dieses Szenarios wäre es eine gute Idee, die Daten nach zu partitionieren report_type und wirf es weg station_id.
Mit dieser Partitionierungs- und Bucketing-Strategie kann Athena zunächst Partitionen für irrelevante Berichtstypen eliminieren und dann nur die Buckets innerhalb der relevanten Partition scannen, die mit der angegebenen Stations-ID übereinstimmen, wodurch die Menge der verarbeiteten Daten erheblich reduziert und die Abfragelaufzeiten beschleunigt werden. Dieser Ansatz erfüllt nicht nur die Anforderungen an die Abfrageleistung, sondern trägt auch zur Kostenoptimierung bei, indem die Menge der gescannten und für jede Abfrage in Rechnung gestellten Daten minimiert wird.
In diesem Beitrag untersuchen wir, wie sich das Datenlayout, insbesondere das Bucketing, auf die Abfrageleistung auswirkt. Wir vergleichen außerdem drei verschiedene Möglichkeiten, ein Bucketing zu erreichen. Die folgende Tabelle stellt Bedingungen für die zu erstellenden Tabellen dar.
| . | noaa_remote_original | athena_non_bucked | athena_bucked | kleber_bucked | athena_bucked_iceberg |
| Format | CSV | Parkett | Parkett | Parkett | Parkett |
| Kompression | n / a | Bissig | Bissig | Bissig | Bissig |
| Erstellt über | n / a | Athena CTAS | Athena CTAS | Kleben Sie ETL | Athena CTAS mit Eisberg |
| Motor | n / a | Trino | Trino | Apache Funken | Apache Eisberg |
| Ist partitioniert? | Ja, aber auf andere Weise | Ja | Ja | Ja | Ja |
| Ist geeimert? | Nein | Nein | Ja | Ja | Ja |
noaa_remote_original wird durch die unterteilt year Spalte, aber nicht durch die report_type Spalte. Diese Zeile stellt dar, ob die Tabelle nach den tatsächlichen Spalten partitioniert ist, die in den Abfragen verwendet werden.
Basistabelle
Für diesen Beitrag erstellen Sie mehrere Tabellen mit unterschiedlichen Bedingungen: einige ohne Bucketing und andere mit Bucketing, um die Leistungsmerkmale des Bucketings zu veranschaulichen. Erstellen wir zunächst eine Originaltabelle mit den NOAA-Daten. In den folgenden Schritten erfassen Sie Daten aus dieser Tabelle, um Testtabellen zu erstellen.
Es gibt mehrere Möglichkeiten, eine Tabellendefinition zu definieren: Ausführen von DDL, eines AWS Glue-Crawlers, der AWS Glue Data Catalog-API usw. In diesem Schritt führen Sie DDL über die Athena-Konsole aus.
Führen Sie die folgenden Schritte aus, um das zu erstellen "bucketing_blog"."noaa_remote_original" Tabelle im Datenkatalog:
- Öffnen Sie die Athena-Konsole.
- Führen Sie im Abfrageeditor die folgende DDL aus, um eine neue AWS Glue-Datenbank zu erstellen:
- Aussichten für Datenbase für Datum, wählen
bucketing_blogum die aktuelle Datenbank festzulegen. - Führen Sie die folgende DDL aus, um die Originaltabelle zu erstellen:
Da die Quelldaten Felder in Anführungszeichen enthalten, verwenden wir OpenCSVSerde anstelle der Standardeinstellung LazySimpleSerde.
Diese CSV-Dateien haben eine Kopfzeile, die wir Athena durch Hinzufügen anweisen, zu überspringen skip.header.line.count und den Wert auf 1 setzen.
Weitere Einzelheiten finden Sie unter OpenCSVSerDe zur Verarbeitung von CSV.
- Führen Sie die folgende DDL aus, um Partitionen hinzuzufügen. Wir fügen Partitionen nur für 5 von 124 Jahren hinzu, basierend auf den Anwendungsfallanforderungen:
- Führen Sie den folgenden DML aus, um zu überprüfen, ob Sie die Daten erfolgreich abfragen können:
Jetzt können Sie mit der Abfrage der Originaltabelle beginnen, um die Basisleistung zu untersuchen.
- Führen Sie eine Abfrage für die Originaltabelle aus, um die Abfrageleistung als Basis auszuwerten. Die folgende Abfrage wählt Datensätze für fünf bestimmte Stationen mit Berichtstyp aus
CRN05: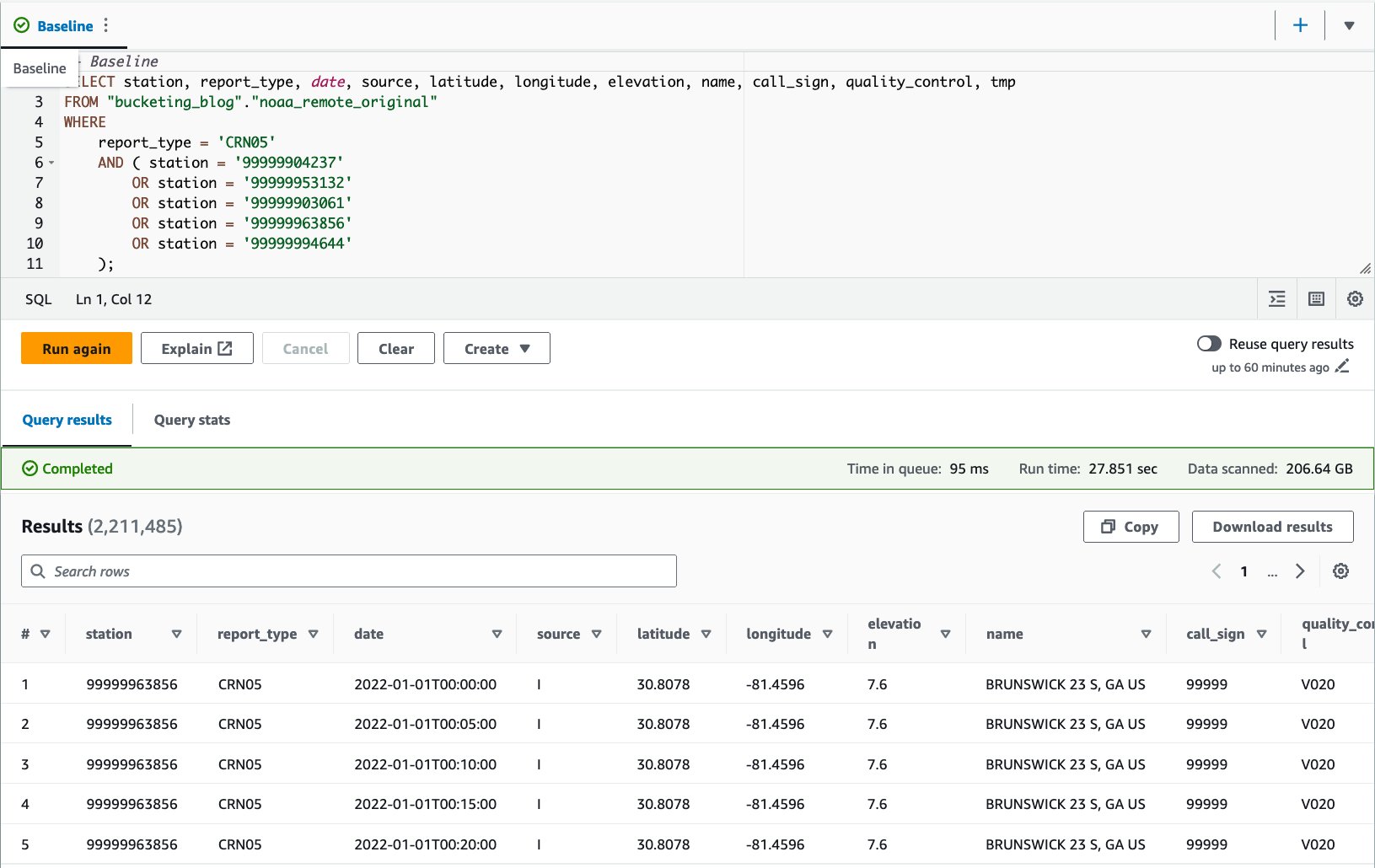
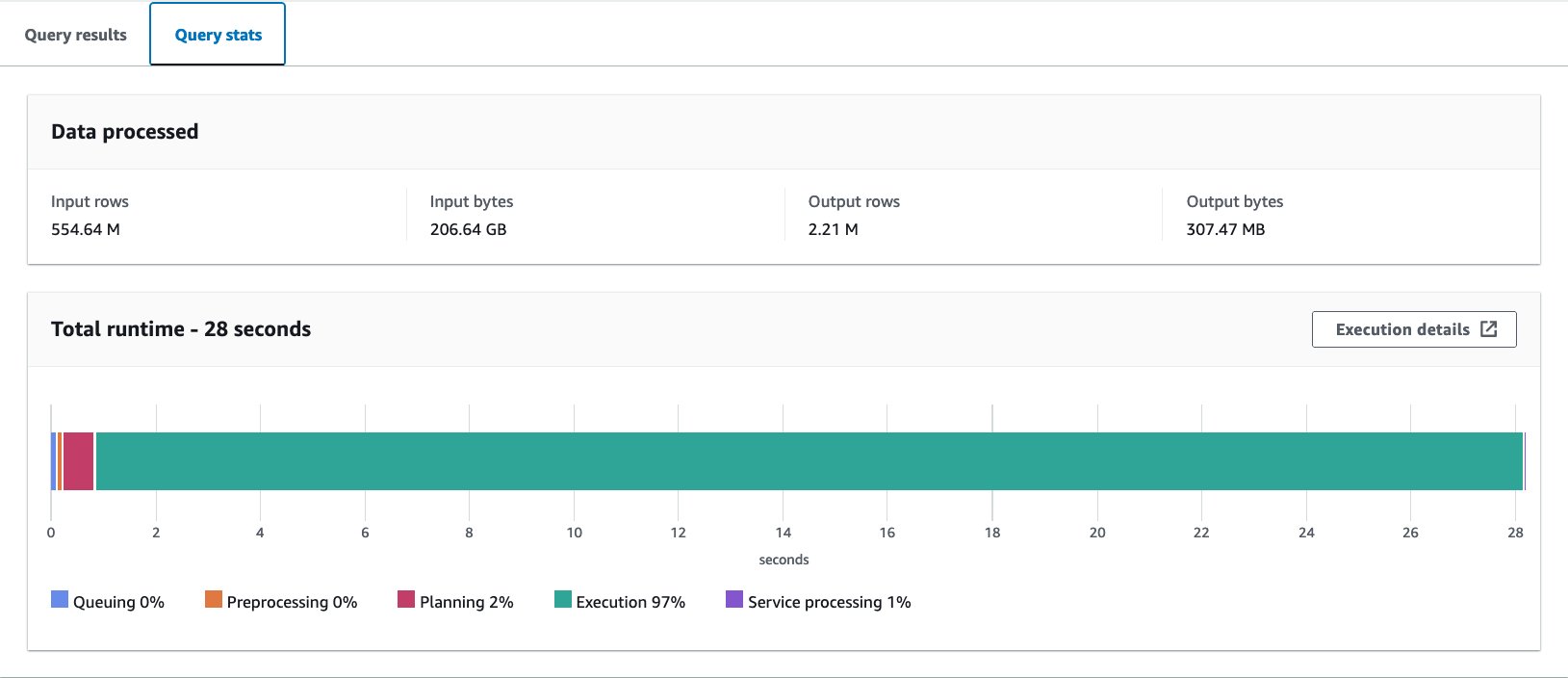
Wir haben diese Abfrage zehnmal ausgeführt. Die durchschnittliche Abfragelaufzeit für 10 Abfragen beträgt 10 Sekunden, was weit über unserem Ziel von 27.6 Sekunden liegt, und 10 GB Daten werden gescannt, um 155.75 Millionen Datensätze zurückzugeben. Dies ist die Basisleistung der ursprünglichen Rohtabelle. Es ist an der Zeit, von dieser Grundlinie aus mit der Optimierung des Datenlayouts zu beginnen.
Als Nächstes erstellen Sie Tabellen mit anderen Bedingungen als im Original: eine ohne Bucketing und eine mit Bucketing, und vergleichen diese.
Optimieren Sie das Datenlayout mit Athena CTAS
In diesem Abschnitt verwenden wir eine Athena CTAS-Abfrage, um das Datenlayout und sein Format zu optimieren.
Erstellen wir zunächst eine Tabelle mit Partitionierung, aber ohne Bucketing. Die neue Tabelle wird nach der Spalte partitioniert report_type da die meisten erwarteten Abfragen diese Spalte in der WHERE-Klausel verwenden und Objekte als Parquet mit Snappy-Komprimierung gespeichert werden.
- Öffnen Sie den Athena-Abfrage-Editor.
- Führen Sie die folgende Abfrage aus und geben Sie dabei Ihren eigenen S3-Bucket und Ihr Präfix an:
Ihre Daten sollten wie in den folgenden Screenshots aussehen.
Unter der Partition befinden sich 30 Dateien.
Als Nächstes erstellen Sie eine Tabelle mit Bucketing im Hive-Stil. Die Anzahl der Buckets muss durch Experimente sorgfältig auf Ihren eigenen Anwendungsfall abgestimmt werden. Im Allgemeinen gilt: Je mehr Buckets Sie haben, desto kleiner ist die Granularität, was möglicherweise zu einer besseren Leistung führt. Andererseits können zu viele kleine Dateien zu Ineffizienz bei der Abfrageplanung und -verarbeitung führen. Außerdem funktioniert das Bucketing nur, wenn Sie einige Werte des Bucketing-Schlüssels abfragen. Je mehr Werte Sie zu Ihrer Abfrage hinzufügen, desto wahrscheinlicher ist es, dass Sie am Ende alle Buckets lesen.
Das Folgende ist die zu optimierende Basisabfrage:
In diesem Beispiel wird die Tabelle durch eine Spalte mit hoher Kardinalität in 16 Buckets unterteilt (station), die für die WHERE-Klausel in der Abfrage verwendet werden soll. Alle anderen Bedingungen bleiben gleich. Die Basisabfrage hat fünf Werte in der Stations-ID, und Sie erwarten, dass Abfragen höchstens ungefähr diese Zahl haben, was weniger ist als die Anzahl der Buckets, sodass 16 gut funktionieren sollten. Es ist möglich, eine größere Anzahl von Buckets anzugeben, CTAS kann jedoch nicht verwendet werden, wenn die Gesamtzahl der Partitionen 100 überschreitet.
- Führen Sie die folgende Abfrage aus:
Die Abfrage erstellt S3-Objekte, die wie in den folgenden Screenshots dargestellt organisiert sind.
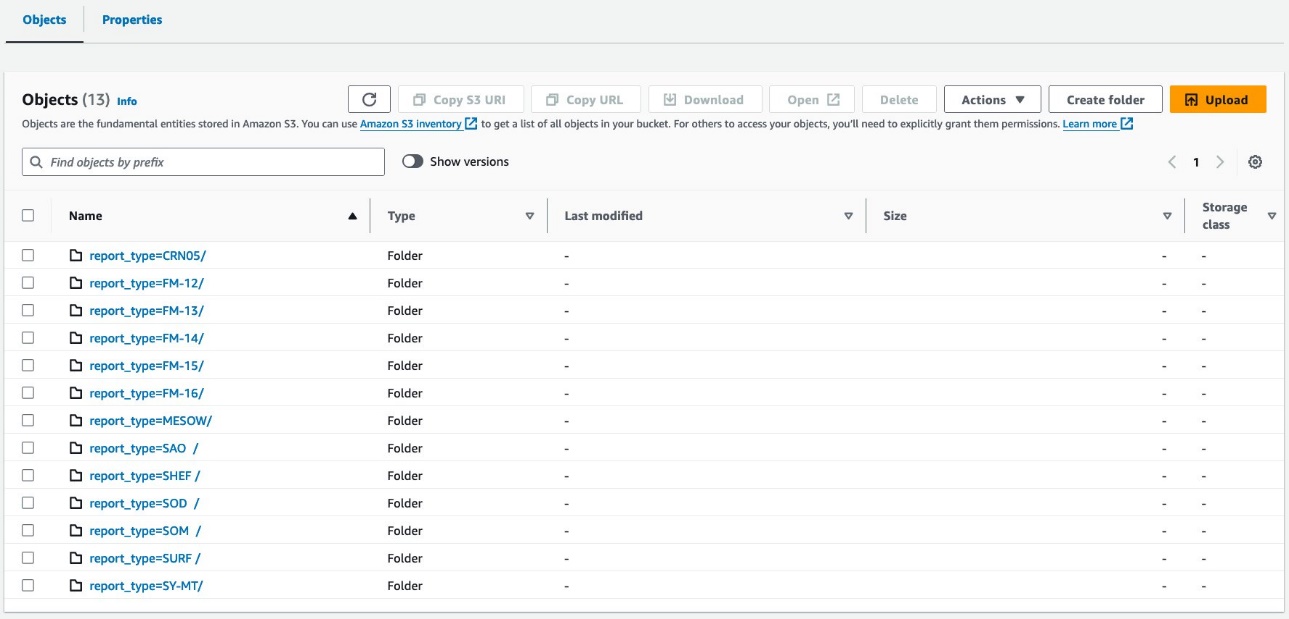

Das Layout auf Tabellenebene sieht genau gleich aus athena_non_bucketed und athena_bucketed: Es gibt 13 Partitionen in jeder Tabelle. Der Unterschied besteht in der Anzahl der Objekte unter den Partitionen. Pro Partition gibt es 16 Objekte (Buckets), in diesem Fall jeweils etwa 10–25 MB. Die Anzahl der Buckets bleibt unabhängig von der Datenmenge konstant beim angegebenen Wert, die Bucket-Größe hängt jedoch von der Datenmenge ab.
Jetzt können Sie jede Tabelle abfragen, um die Abfrageleistung zu bewerten. Die Abfrage wählt Datensätze mit fünf spezifischen Stationen und Berichtstypen aus CRN05 seit 5 Jahren. Obwohl Sie nicht sehen können, welche Daten einer bestimmten Station sich in welchem Bucket befinden, wurden sie von Athena korrekt berechnet und lokalisiert.
- Fragen Sie die Tabelle ohne Bucket mit der folgenden Anweisung ab:

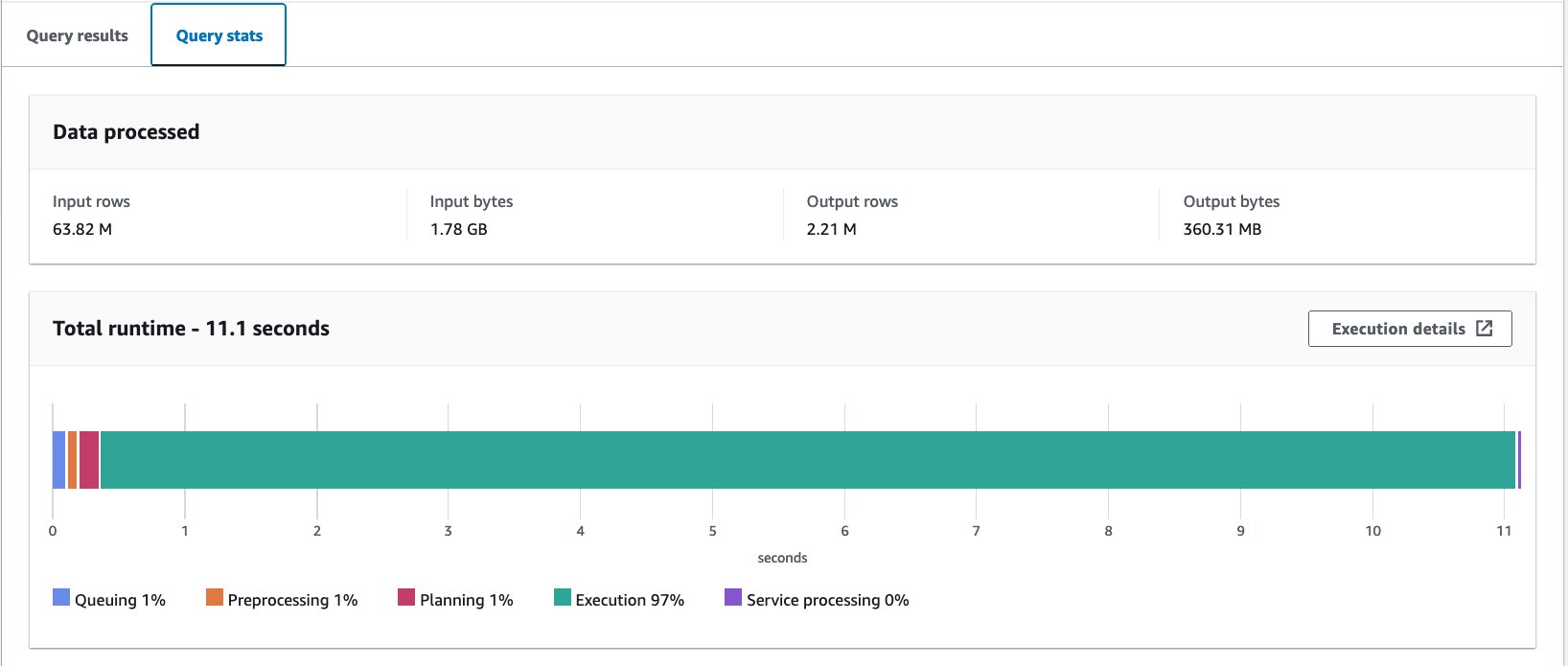
Wir haben diese Abfrage zehnmal ausgeführt. Die durchschnittliche Laufzeit der 10 Abfragen beträgt 10 Sekunden und es werden 10.95 MB Daten gescannt, um 358 Millionen Datensätze zurückzugeben. Sowohl die Laufzeit als auch die Scangröße wurden erheblich verringert, da Sie die Daten partitioniert haben und jetzt nur noch eine Partition lesen können, wobei 2.21 von 12 Partitionen übersprungen werden. Darüber hinaus ist die Menge der gescannten Daten von 13 GB auf 206 MB gesunken, was einer Reduzierung um 360 % entspricht. Das liegt nicht nur an der Partitionierung, sondern auch an der Umstellung des Formats auf Parquet und der Komprimierung mit Snappy.
- Fragen Sie die Bucket-Tabelle mit der folgenden Anweisung ab:
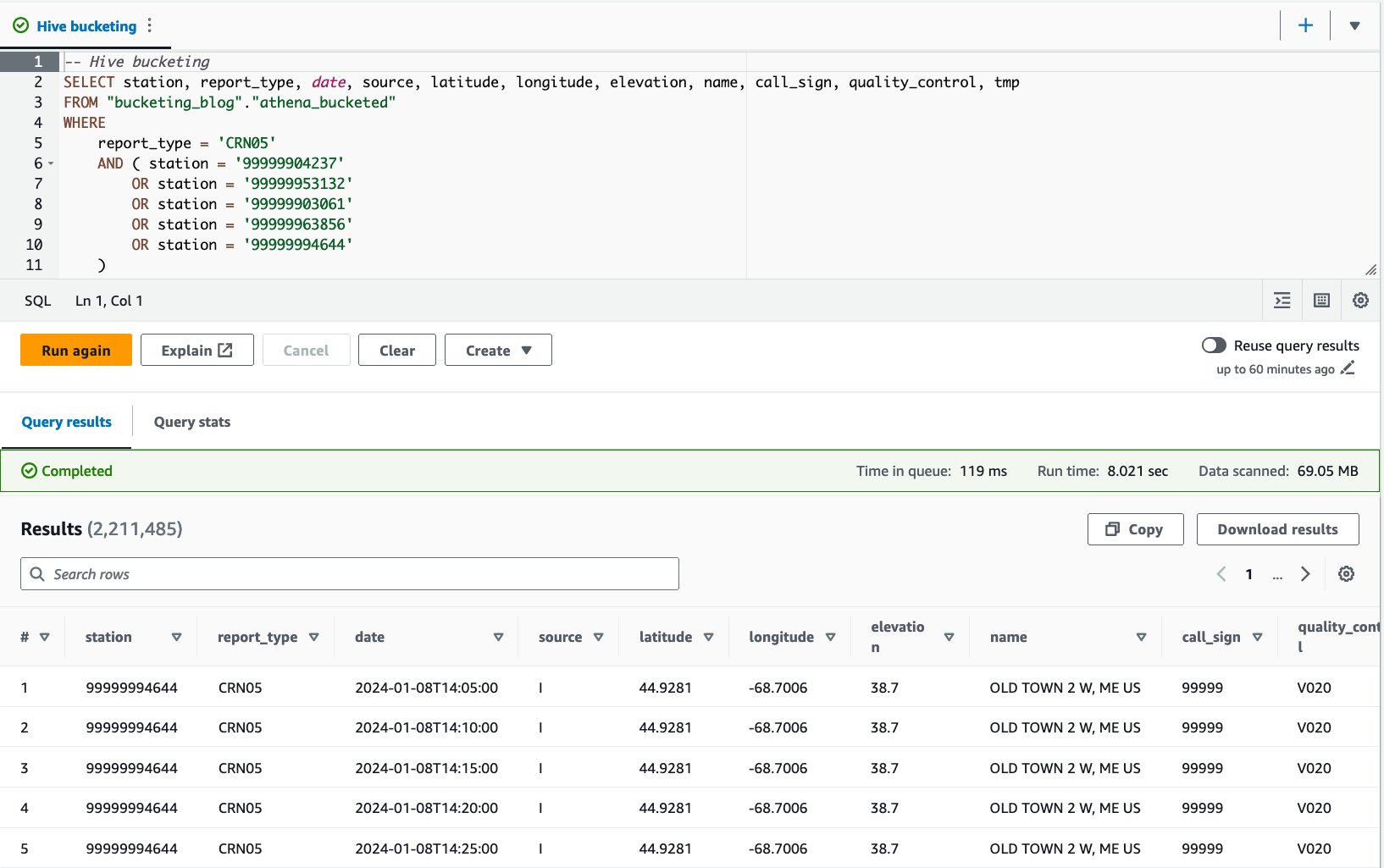
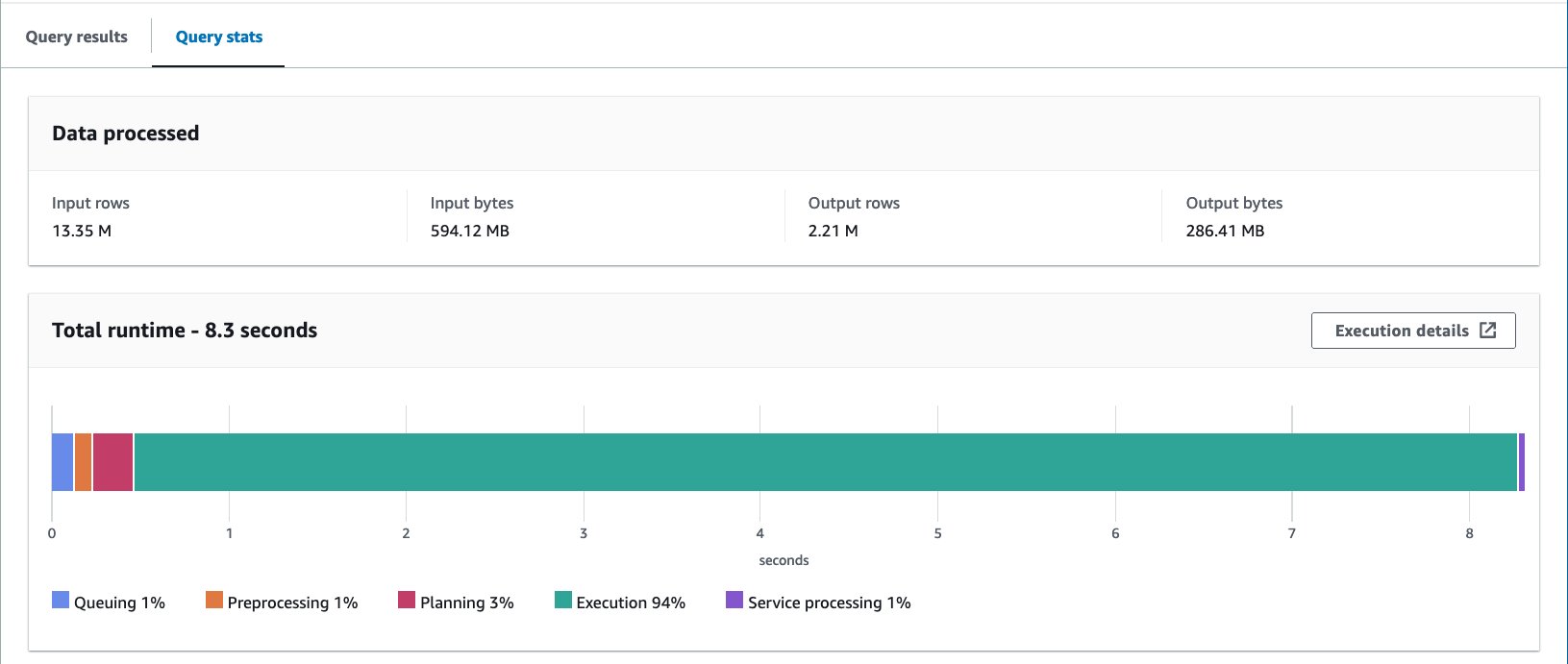
Wir haben diese Abfrage zehnmal ausgeführt. Die durchschnittliche Laufzeit der 10 Abfragen beträgt 10 Sekunden und es werden 7.82 MB Daten gescannt, um 69 Millionen Datensätze zurückzugeben. Dies bedeutet eine Reduzierung der durchschnittlichen Laufzeit von 2.21 auf 10.95 Sekunden (-7.82 %) und eine drastische Reduzierung der gescannten Daten von 29 MB auf 358 MB (-69 %), um die gleiche Anzahl an Datensätzen im Vergleich zur Tabelle ohne Buckets zurückzugeben . In diesem Fall wurden sowohl die Laufzeit als auch die gescannten Daten durch Bucketing verbessert. Dies bedeutet, dass das Bucketing nicht nur zur Leistung, sondern auch zur Kostenreduzierung beitrug.
Überlegungen
Wie bereits erwähnt, dimensionieren Sie Ihren Bucket sorgfältig, um die Leistung Ihrer Abfrage zu maximieren. Bucketing funktioniert nur, wenn Sie einige Werte des Bucketing-Schlüssels abfragen. Erwägen Sie die Erstellung von mehr Buckets als in der tatsächlichen Abfrage erwartete Werte.
Darüber hinaus ist eine Athena CTAS-Abfrage auf die gleichzeitige Erstellung von bis zu 100 Partitionen beschränkt. Wenn Sie eine große Anzahl von Partitionen benötigen, können Sie AWS Glue zum Extrahieren, Transformieren und Laden (ETL) verwenden, obwohl es eine gibt Problemumgehung zur Aufteilung in mehrere SQL-Anweisungen.
Optimieren Sie das Datenlayout mit AWS Glue ETL
Apache Spark ist ein Open-Source-Framework für die verteilte Verarbeitung, das flexibles ETL mit PySpark, Scala und Spark SQL ermöglicht. Es ermöglicht Ihnen, Ihre Daten entsprechend Ihren Anforderungen zu partitionieren und in Buckets zu unterteilen. Spark verfügt über mehrere Optimierungsoptionen, um Aufträge zu beschleunigen. Sie können Spark-Jobs mühelos automatisieren und überwachen. In diesem Abschnitt verwenden wir AWS Glue ETL-Jobs, um Spark-Code auszuführen und das Datenlayout zu optimieren.
Im Gegensatz zum Athena-Bucketing verwendet AWS Glue ETL Spark-basiertes Bucketing als Bucketing-Algorithmus. Sie müssen lediglich die folgende Tabelleneigenschaft zur Tabelle hinzufügen: bucketing_format = 'spark'. Einzelheiten zu dieser Tabelleneigenschaft finden Sie unter Partitionieren und Eimern in Athena.
Führen Sie die folgenden Schritte aus, um eine Tabelle mit Bucketing über AWS Glue ETL zu erstellen:
- Wählen Sie in der AWS Glue-Konsole aus ETL-Jobs im Navigationsbereich.
- Auswählen Job erstellen und wählen Sie Visuelles ETL.
- Der Knoten hinzufügen, wählen AWS Glue-Datenkatalog für Quellen.
- Aussichten für Datenbase, wählen
bucketing_blog. - Aussichten für Tisch, wählen
noaa_remote_original. - Der Knoten hinzufügen, wählen Schema ändern für Verwandelt sich.
- Der Knoten hinzufügen, wählen Benutzerdefinierte Transformation für Verwandelt sich.
- Aussichten für Name und Vorname, eingeben
ToS3WithBucketing. - Aussichten für Knoteneltern, wählen Schema ändern.
- Aussichten für CodeblockGeben Sie den folgenden Codeausschnitt ein:
Der folgende Screenshot zeigt den Job, der mit AWS Glue Studio erstellt wurde, um eine Tabelle und Daten zu generieren.
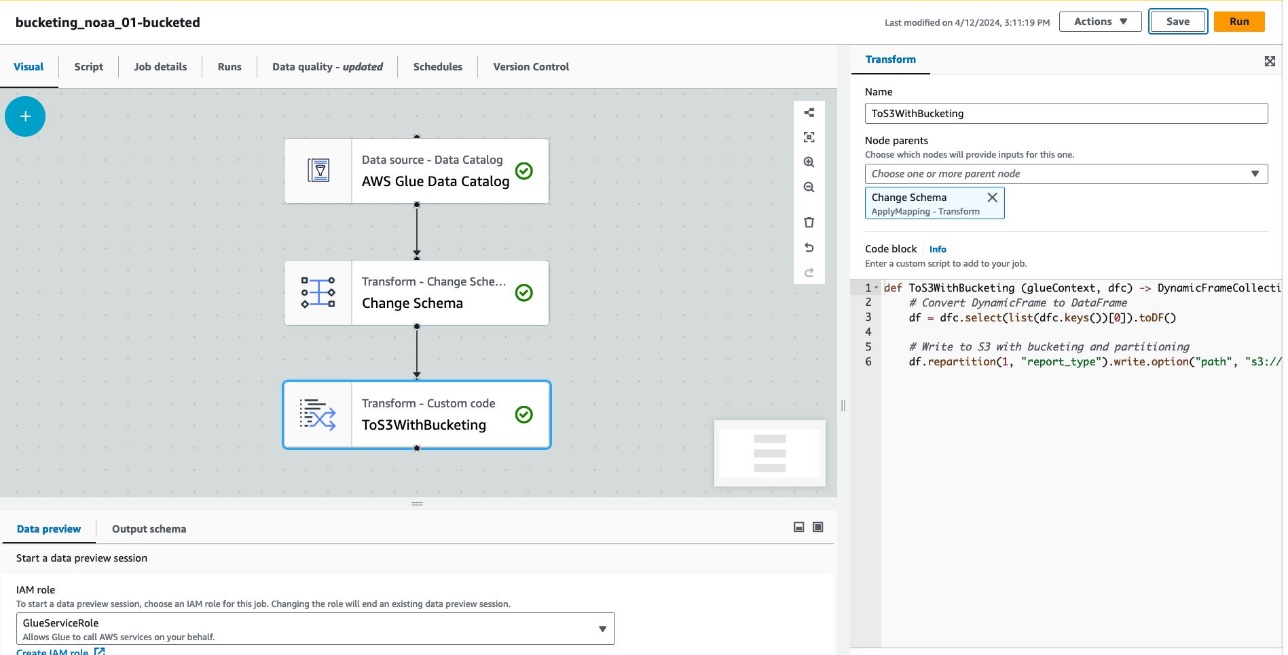
Jeder Knoten stellt Folgendes dar:
- Das AWS Glue-Datenkatalog Knoten lädt die
noaa_remote_originalTabelle aus dem Datenkatalog - Das Schema ändern Der Knoten stellt sicher, dass er im Datenkatalog registrierte Spalten lädt
- Das ToS3WithBucketing Der Knoten schreibt Daten sowohl mit Partitionierung als auch mit Spark-basiertem Bucketing in Amazon S3
Der Job wurde erfolgreich im visuellen Editor erstellt.
- Der JobdetailsZ. IAM-Rolle, wähle dein AWS Identity and Access Management and (IAM)-Rolle für diesen Job.
- Aussichten für Arbeitertyp, wählen G.8X.
- Aussichten für Angeforderte Anzahl von Arbeitern, 5 eingeben.
- Auswählen Speichern, Dann wählen Führen Sie.
Nach diesen Schritten ist die Tabelle glue_bucketed. wurde erschaffen.
- Auswählen
Tische im Navigationsbereich und wählen Sie die Tabelle aus
glue_bucketed. - Auf dem Aktionen Menü, wählen Sie Tabelle bearbeiten für Verwalten.
- Im Tabelleneigenschaften Wählen Sie im Abschnitt Speichern.
- Fügen Sie ein Schlüsselpaar mit Schlüssel hinzu
bucketing_formatund Wertefunke.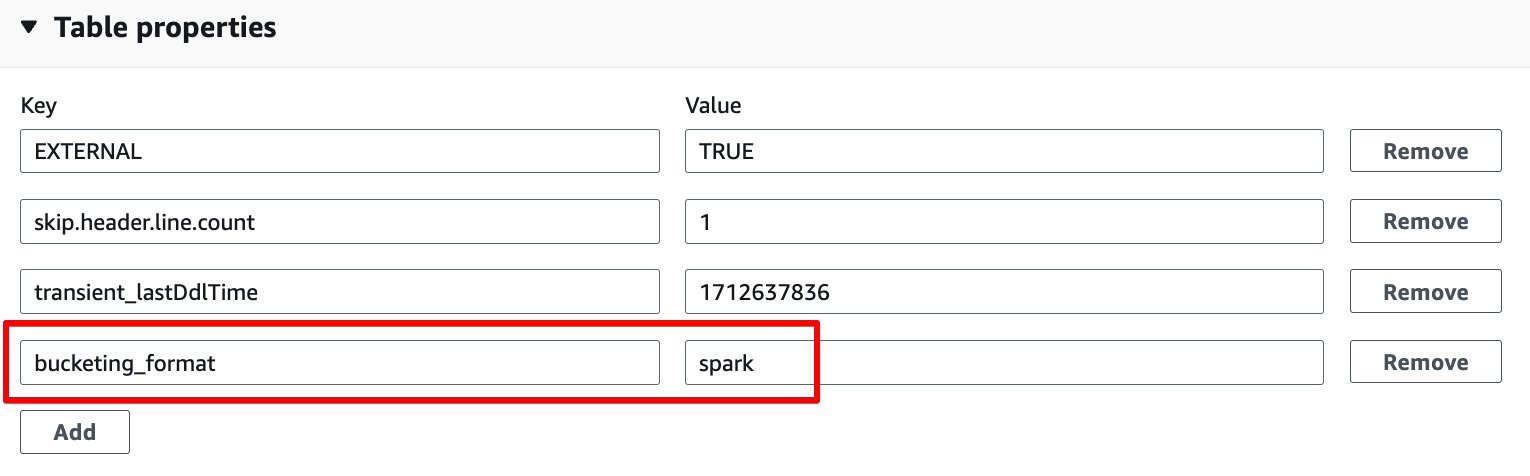
- Auswählen Speichern.
Jetzt ist es an der Zeit, die Tabellen abzufragen.
- Fragen Sie die Bucket-Tabelle mit der folgenden Anweisung ab:

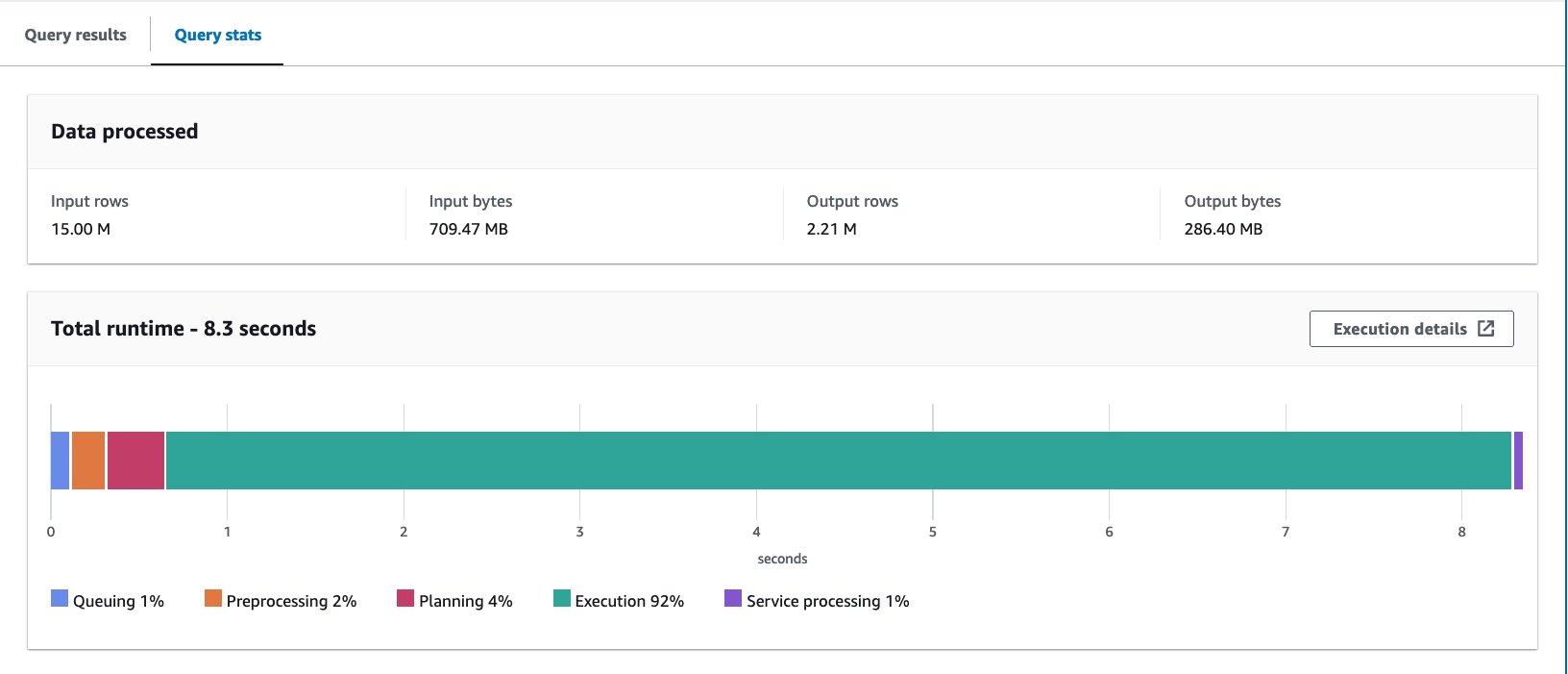
Wir haben die Abfrage zehnmal ausgeführt. Die durchschnittliche Laufzeit der 10 Abfragen beträgt 10 Sekunden und es werden 7.09 MB Daten gescannt, um 88 Millionen Datensätze zurückzugeben. In diesem Fall wurden sowohl die Laufzeit als auch die gescannten Daten durch Bucketing verbessert. Dies bedeutet, dass das Bucketing nicht nur zur Leistung, sondern auch zur Kostenreduzierung beitrug.
Der Grund für die größeren gescannten Bytes im Vergleich zum Athena CTAS-Beispiel liegt darin, dass die Werte in dieser Tabelle unterschiedlich verteilt waren. In der Bucket-Tabelle von AWS Glue wurden die Werte auf fünf Dateien verteilt. In der Bucket-Tabelle von Athena CTAS wurden die Werte auf vier Dateien verteilt. Denken Sie daran, dass Zeilen mithilfe einer Hash-Funktion in Buckets verteilt werden. Der Spark-Bucketing-Algorithmus verwendet eine andere Hash-Funktion als Hive und führte in diesem Fall zu einer anderen Verteilung über die Dateien.
Überlegungen
Kleben Sie DynamicFrame unterstützt kein natives Bucketing. Sie müssen Spark DataFrame anstelle von DynamicFrame verwenden, um Tabellen zu Buckets zu machen.
Informationen zur Feinabstimmung der AWS Glue ETL-Leistung finden Sie unter Best Practices für die Leistungsoptimierung von AWS Glue für Apache Spark-Jobs.
Optimieren Sie das Iceberg-Datenlayout mit versteckter Partitionierung
Apache Iceberg ist ein leistungsstarkes offenes Tabellenformat für große Analysetabellen, das die Zuverlässigkeit und Einfachheit von SQL-Tabellen auf Big Data überträgt. In letzter Zeit besteht eine große Nachfrage nach der Verwendung von Apache Iceberg-Tabellen, um erweiterte Funktionen wie ACID-Transaktionen, Zeitreiseabfragen und mehr zu erreichen.
In Iceberg funktioniert das Bucketing anders als die Hive-Tabellenmethode, die wir bisher gesehen haben. In Iceberg ist Bucketing eine Teilmenge der Partitionierung und kann mithilfe der Bucket-Partitionstransformation angewendet werden. Die Art und Weise, wie Sie es verwenden, und das Endergebnis ähneln dem Bucketing in Hive-Tabellen. Weitere Einzelheiten zu Iceberg-Bucket-Transformationen finden Sie unter Details zur Bucket-Transformation.
Führen Sie die folgenden Schritte aus:
- Öffnen Sie den Athena-Abfrage-Editor.
- Führen Sie die folgende Abfrage aus, um eine Iceberg-Tabelle mit versteckter Partitionierung und Bucketing zu erstellen:
Ihre Daten sollten wie im folgenden Screenshot aussehen.

Es gibt zwei Ordner: data und metadata. Drilldown zu data.
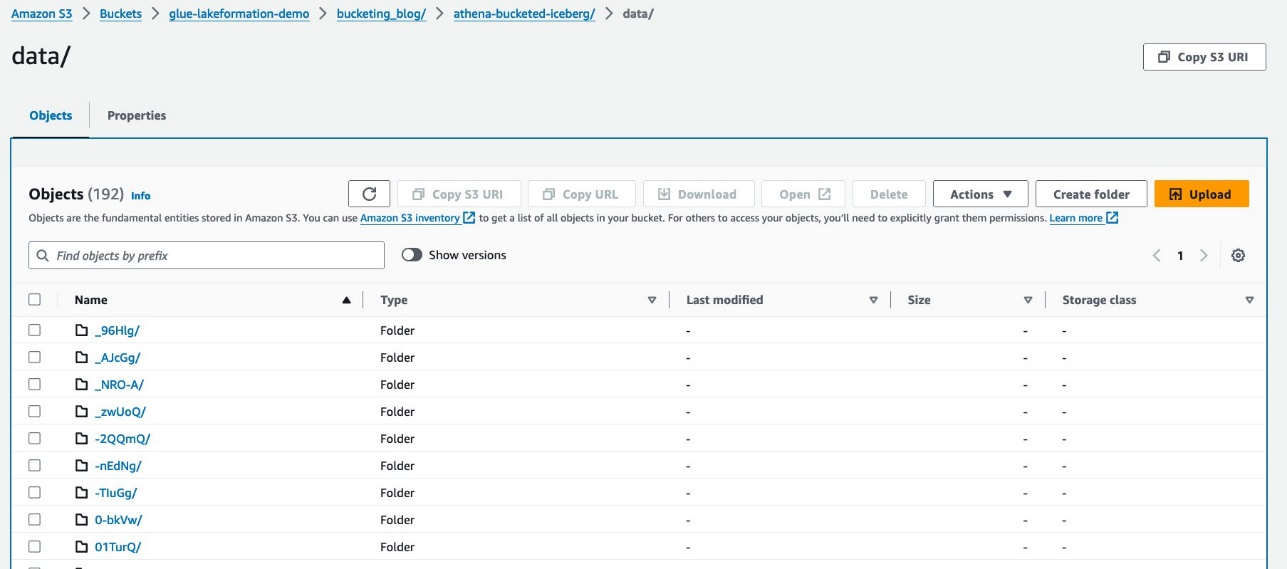
Unter dem werden zufällige Präfixe angezeigt data Ordner. Wählen Sie das erste aus, um dessen Details anzuzeigen.
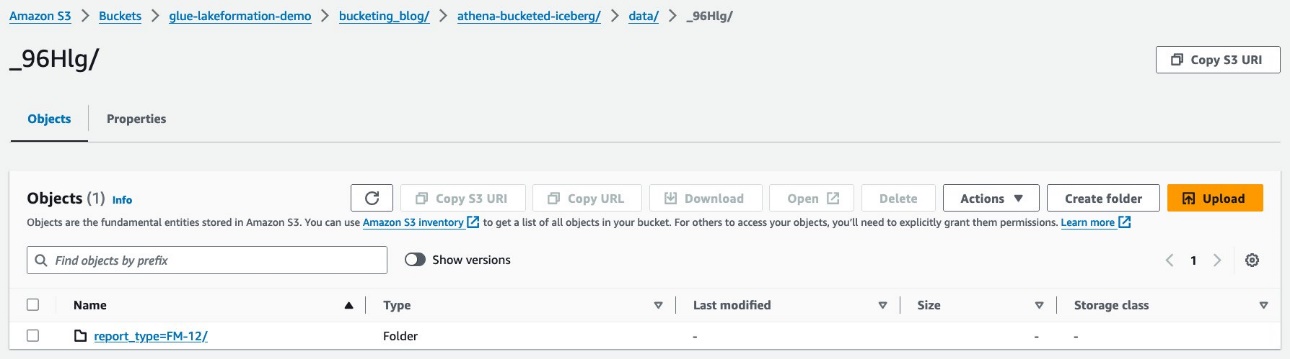
Sie sehen die Partition der obersten Ebene basierend auf report_type Spalte. Drilldown zur nächsten Ebene.

Sie sehen die Partition der zweiten Ebene, eingeteilt in die station Spalte.
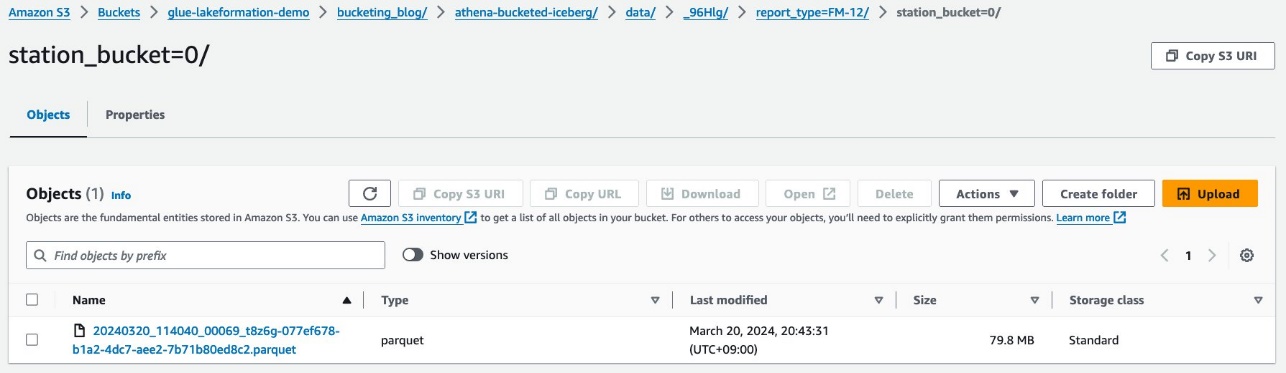
Die Parquet-Datendateien befinden sich in diesen Ordnern.
- Fragen Sie die Bucket-Tabelle mit der folgenden Anweisung ab:
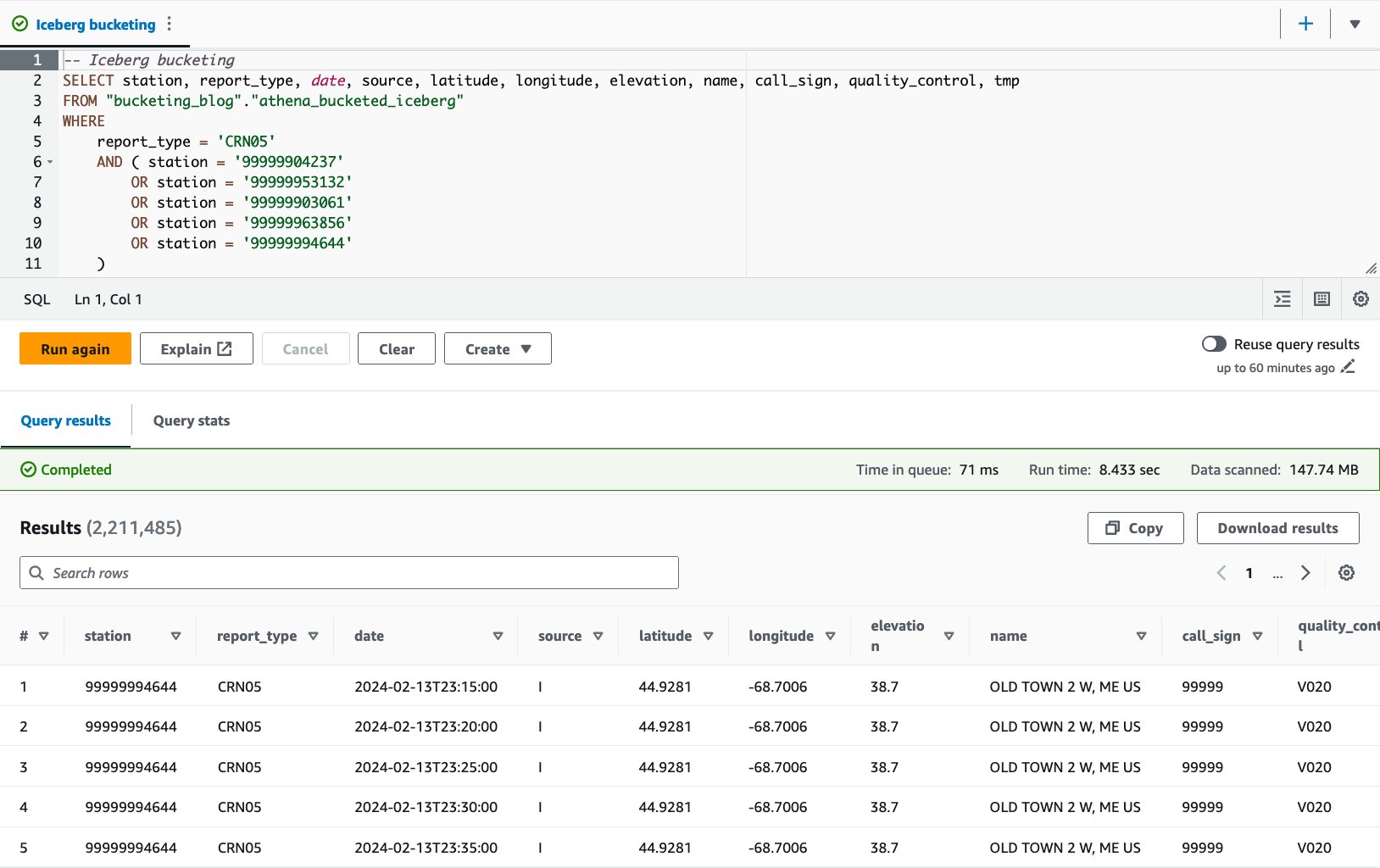
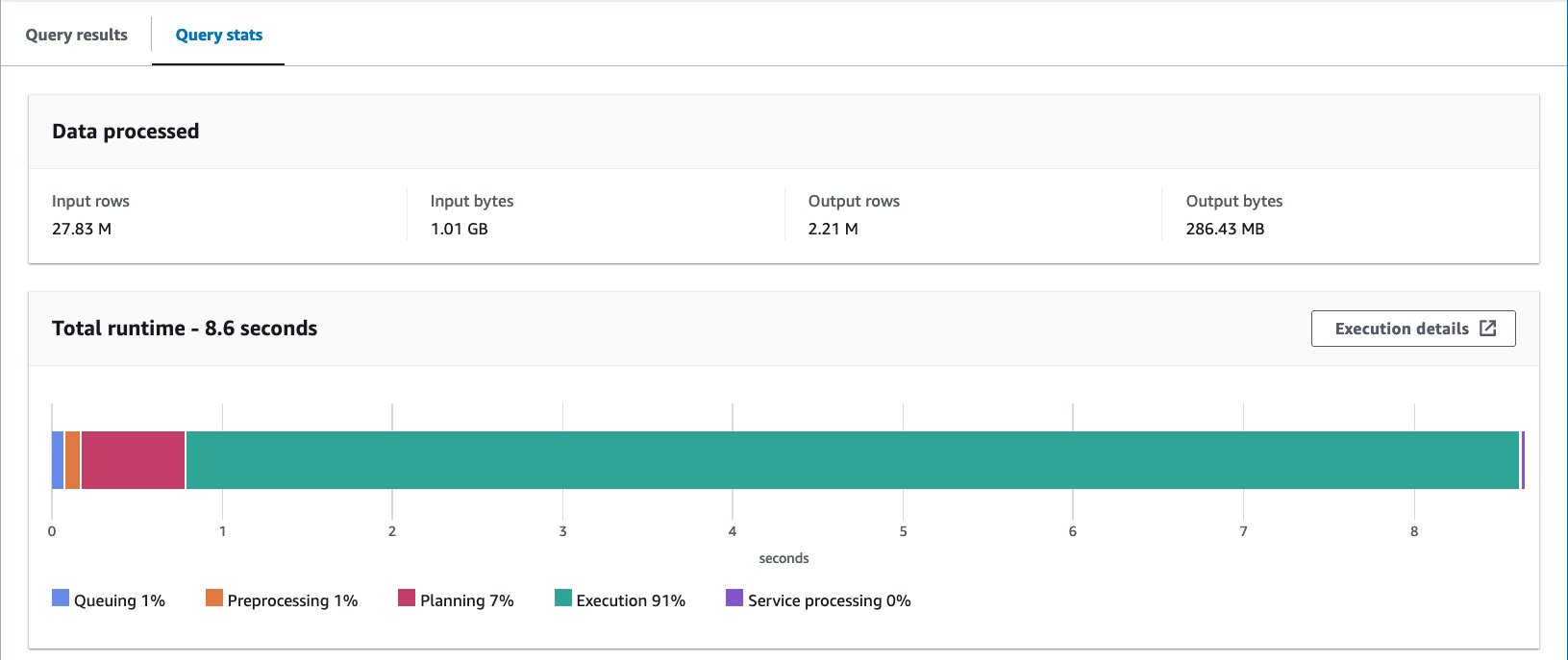
Mit der Iceberg-Bucket-Tabelle beträgt die durchschnittliche Laufzeit der 10 Abfragen 8.03 Sekunden und es werden 148 MB Daten gescannt, um 2.21 Millionen Datensätze zurückzugeben. Dies ist weniger effizient als das Bucketing mit AWS Glue oder Athena, liegt aber angesichts der Vorteile der verschiedenen Funktionen von Iceberg in einem akzeptablen Bereich.
Die Ergebnisse
Die folgende Tabelle fasst alle Ergebnisse zusammen.
| . | noaa_remote_original | athena_non_bucked | athena_bucked | kleber_bucked | athena_bucked_iceberg |
| Format | CSV | Parkett | Parkett | Parkett | Eisberg (Parkett) |
| Kompression | n / a | Bissig | Bissig | Bissig | Bissig |
| Erstellt über | n / a | Athena CTAS | Athena CTAS | Kleben Sie ETL | Athena CTAS mit Eisberg |
| Motor | n / a | Trino | Trino | Apache Funken | Apache Eisberg |
| Tabellengröße (GB) | 155.8 | 5.0 | 5.0 | 5.8 | 5.0 |
| Die Anzahl der S3-Objekte | 53360 | 376 | 192 | 192 | 195 |
| Ist partitioniert? | Ja, aber auf andere Weise | Ja | Ja | Ja | Ja |
| Ist geeimert? | Nein | Nein | Ja | Ja | Ja |
| Bucketing-Format | n / a | n / a | Bienenstock | Spark | Iceberg |
| Anzahl der Eimer | n / a | n / a | 16 | 16 | 16 |
| Durchschnittliche Laufzeit (Sek.) | 29.178 | 10.950 | 7.815 | 7.089 | 8.030 |
| Gescannte Größe (MB) | 206640.0 | 358.6 | 69.1 | 87.8 | 147.7 |
Mit der athena_bucketed, glue_bucketed und athena_bucketed_icebergkonnten Sie das Latenzziel von 10 Sekunden erreichen. Durch das Bucketing konnten Sie eine Reduzierung der Laufzeit um 25–40 % und eine Reduzierung der Scangröße um 60–85 % feststellen, was sowohl zur Latenz als auch zur Kostenoptimierung beitragen kann.
Wie Sie dem Ergebnis entnehmen können, trägt die Partitionierung zwar erheblich zur Reduzierung der Laufzeit und der Scangröße bei, Bucketing kann jedoch auch zu einer weiteren Reduzierung beitragen.
Athena CTAS ist unkompliziert und schnell genug, um den Eimerbildungsprozess abzuschließen. AWS Glue ETL ist flexibler und skalierbar, um erweiterte Anwendungsfälle zu realisieren. Sie können je nach Anforderung und Anwendungsfall eine der beiden Methoden wählen, da Sie die Vorteile des Bucketings über beide Optionen nutzen können.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, wie Sie das Layout Ihrer Tabellendaten mit Partitionierung und Bucketing mithilfe von Athena CTAS und AWS Glue ETL optimieren. Wir haben gezeigt, dass Bucketing dazu beiträgt, die Abfragelatenz zu beschleunigen und die Scangröße zu reduzieren, um die Kosten weiter zu optimieren. Wir haben auch das Bucketing für Iceberg-Tabellen durch versteckte Partitionierung besprochen.
Nur eine Technik zur Optimierung des Datenlayouts durch Reduzierung des Datenscans nutzen. Um Ihr gesamtes Datenlayout zu optimieren, empfehlen wir, andere Optionen wie Partitionierung, die Verwendung eines spaltenorientierten Dateiformats und Komprimierung in Verbindung mit Bucketing in Betracht zu ziehen. Dadurch können Ihre Daten die Abfrageleistung weiter verbessern.
Viel Spaß beim Eimern!
Über die Autoren
 Takeshi Nakatani ist Hauptberater für Big Data im Professional Services-Team in Tokio. Er verfügt über 26 Jahre Erfahrung in der IT-Branche und verfügt über Fachkenntnisse in der Architektur von Dateninfrastrukturen. An seinen freien Tagen kann er Rock-Schlagzeuger oder Motorradfahrer sein.
Takeshi Nakatani ist Hauptberater für Big Data im Professional Services-Team in Tokio. Er verfügt über 26 Jahre Erfahrung in der IT-Branche und verfügt über Fachkenntnisse in der Architektur von Dateninfrastrukturen. An seinen freien Tagen kann er Rock-Schlagzeuger oder Motorradfahrer sein.
 Noritaka Sekiyama ist Principal Big Data Architect im AWS Glue-Team. Er ist für die Erstellung von Software-Artefakten verantwortlich, um Kunden zu helfen. In seiner Freizeit fährt er gerne mit seinem Rennrad Rad.
Noritaka Sekiyama ist Principal Big Data Architect im AWS Glue-Team. Er ist für die Erstellung von Software-Artefakten verantwortlich, um Kunden zu helfen. In seiner Freizeit fährt er gerne mit seinem Rennrad Rad.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/optimize-data-layout-by-bucketing-with-amazon-athena-and-aws-glue-to-accelerate-downstream-queries/

