Von Amazon verwaltete Workflows für Apache Airflow (Amazon MWAA) ist ein verwalteter Orchestrierungsdienst für Apache-Luftstrom mit dem Sie Datenpipelines in der Cloud im großen Maßstab einrichten und betreiben können. Apache Airflow ist ein Open-Source-Tool zum programmgesteuerten Erstellen, Planen und Überwachen von Prozess- und Aufgabensequenzen, genannt Workflows. Mit Amazon MWAA können Sie Apache Airflow und Python verwenden, um Workflows zu erstellen, ohne die zugrunde liegende Infrastruktur für Skalierbarkeit, Verfügbarkeit und Sicherheit verwalten zu müssen.
Durch die Verwendung mehrerer AWS-Konten können Unternehmen ihre Arbeitslasten effektiv skalieren und deren Komplexität bewältigen, wenn sie wachsen. Dieser Ansatz bietet einen robusten Mechanismus, um die potenziellen Auswirkungen von Störungen oder Ausfällen abzumildern und sicherzustellen, dass kritische Workloads betriebsbereit bleiben. Darüber hinaus ermöglicht es eine Kostenoptimierung durch die Ausrichtung der Ressourcen auf bestimmte Anwendungsfälle und stellt so sicher, dass die Ausgaben gut kontrolliert werden. Durch die Isolierung von Workloads mit spezifischen Sicherheitsanforderungen oder Compliance-Anforderungen können Unternehmen ein Höchstmaß an Datenschutz und Sicherheit gewährleisten. Darüber hinaus können Sie durch die Möglichkeit, mehrere AWS-Konten strukturiert zu organisieren, Ihre Geschäftsprozesse und Ressourcen an Ihre individuellen betrieblichen, behördlichen und budgetären Anforderungen anpassen. Dieser Ansatz fördert Effizienz, Flexibilität und Skalierbarkeit und ermöglicht es großen Unternehmen, ihre sich ändernden Anforderungen zu erfüllen und ihre Ziele zu erreichen.
In diesem Beitrag wird gezeigt, wie Sie mithilfe von eine End-to-End-ETL-Pipeline (Extrahieren, Transformieren und Laden) orchestrieren Amazon Simple Storage-Service (Amazon S3), AWS-Kleber und Amazon Redshift ohne Server mit Amazon MWAA.
Lösungsüberblick
In diesem Beitrag betrachten wir einen Anwendungsfall, bei dem ein Datenentwicklungsteam einen ETL-Prozess aufbauen und seinen Endbenutzern die beste Erfahrung bieten möchte, wenn sie die neuesten Daten abfragen möchten, nachdem neue Rohdateien zu Amazon S3 in der Zentrale hinzugefügt wurden Konto (Konto A im folgenden Architekturdiagramm). Das Data-Engineering-Team möchte die Rohdaten in sein eigenes AWS-Konto (Konto B im Diagramm) aufteilen, um die Sicherheit und Kontrolle zu erhöhen. Sie möchten die Datenverarbeitungs- und Transformationsarbeiten auch in ihrem eigenen Konto (Konto B) durchführen, um Aufgaben zu unterteilen und unbeabsichtigte Änderungen an den Quellrohdaten im zentralen Konto (Konto A) zu verhindern. Dieser Ansatz ermöglicht es dem Team, die von Konto A extrahierten Rohdaten in Konto B zu verarbeiten, das für Datenverarbeitungsaufgaben vorgesehen ist. Dadurch wird sichergestellt, dass die Roh- und verarbeiteten Daten bei Bedarf sicher getrennt über mehrere Konten verwaltet werden können, um die Datenverwaltung und -sicherheit zu verbessern.
Unsere Lösung verwendet eine von Amazon MWAA orchestrierte End-to-End-ETL-Pipeline, die an einem Amazon S3-Speicherort in Konto A, wo die Rohdaten vorhanden sind, nach neuen inkrementellen Dateien sucht. Dies erfolgt durch Aufrufen von AWS Glue ETL-Jobs und Schreiben in Datenobjekte in einem Redshift Serverless-Cluster in Konto B. Die Pipeline beginnt dann mit der Ausführung Gespeicherte Prozeduren und SQL-Befehle auf Redshift Serverless. Sobald die Ausführung der Abfragen abgeschlossen ist, wird ein ENTLADEN Der Vorgang wird vom Redshift-Data-Warehouse zum S3-Bucket in Konto A aufgerufen.
Da Sicherheit wichtig ist, behandelt dieser Beitrag auch die Konfiguration einer Airflow-Verbindung mit AWS Secrets Manager um das Speichern von Datenbankanmeldeinformationen in Airflow-Verbindungen und -Variablen zu vermeiden.
Das folgende Diagramm veranschaulicht die Architekturübersicht der an der Orchestrierung des Workflows beteiligten Komponenten.
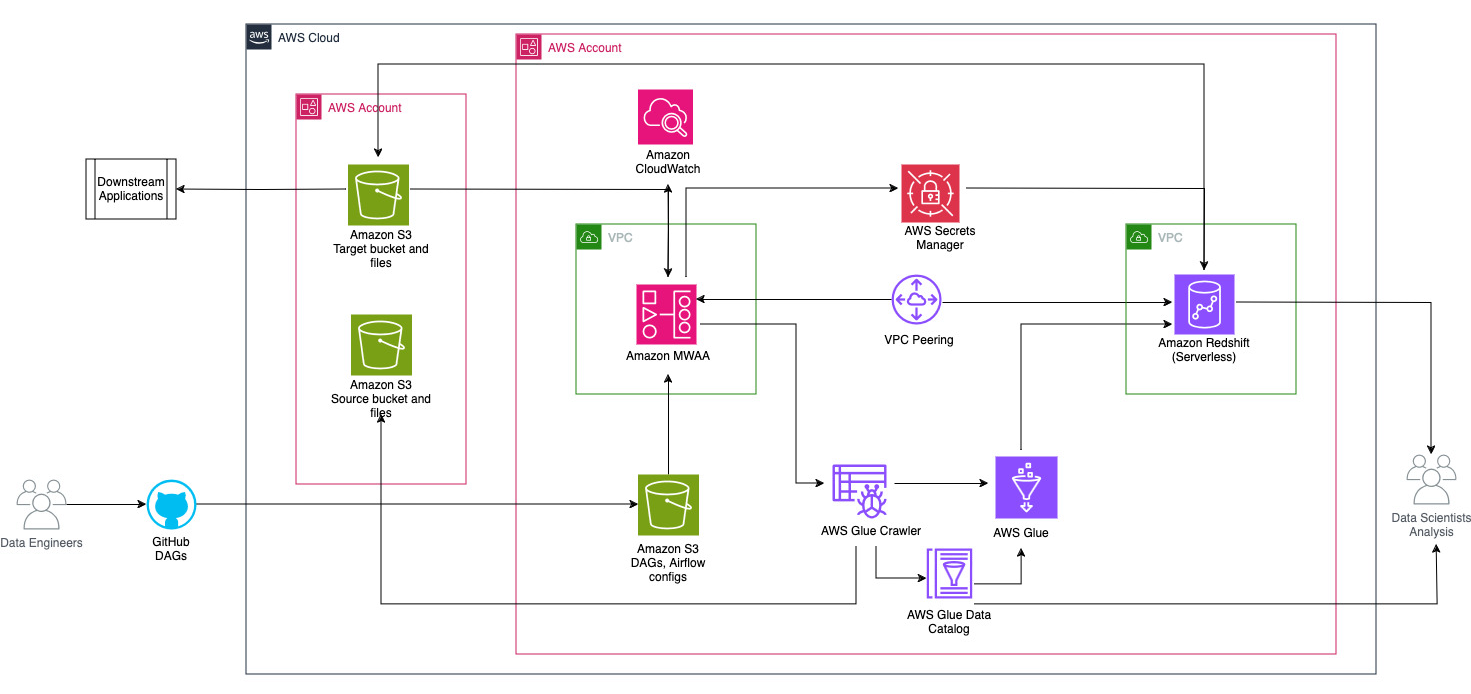
Der Workflow besteht aus folgenden Komponenten:
- Die Quell- und Ziel-S3-Buckets befinden sich in einem zentralen Konto (Konto A), während sich Amazon MWAA, AWS Glue und Amazon Redshift in einem anderen Konto (Konto B) befinden. Zwischen S3-Buckets in Konto A und Ressourcen in Konto B wurde ein kontoübergreifender Zugriff eingerichtet, um Daten laden und entladen zu können.
- Im zweiten Konto wird Amazon MWAA in einer VPC und Redshift Serverless in einer anderen VPC gehostet, die über VPC-Peering verbunden sind. Eine Redshift Serverless-Arbeitsgruppe ist in privaten Subnetzen über drei Availability Zones hinweg gesichert.
- Geheimnisse wie Benutzername, Passwort, DB-Port und AWS-Region für Redshift Serverless werden im Secrets Manager gespeichert.
- VPC-Endpunkte werden für Amazon S3 und Secrets Manager erstellt, um mit anderen Ressourcen zu interagieren.
- Normalerweise erstellen Dateningenieure einen Airflow Directed Asymmetric Graph (DAG) und übermitteln ihre Änderungen an GitHub. Mit GitHub-Aktionen werden sie in einem S3-Bucket in Konto B bereitgestellt (für diesen Beitrag laden wir die Dateien direkt in den S3-Bucket hoch). Der S3-Bucket speichert Airflow-bezogene Dateien wie DAG-Dateien,
requirements.txtDateien und Plugins. AWS Glue ETL-Skripte und Assets werden in einem anderen S3-Bucket gespeichert. Diese Trennung trägt dazu bei, die Organisation aufrechtzuerhalten und Verwirrung zu vermeiden. - Der Airflow DAG nutzt verschiedene Operatoren, Sensoren, Verbindungen, Aufgaben und Regeln, um die Datenpipeline nach Bedarf auszuführen.
- Die Airflow-Protokolle werden angemeldet Amazon CloudWatch, und Warnungen können für Überwachungsaufgaben konfiguriert werden. Weitere Informationen finden Sie unter Überwachung von Dashboards und Alarmen auf Amazon MWAA.
Voraussetzungen:
Da sich diese Lösung auf die Verwendung von Amazon MWAA zur Orchestrierung der ETL-Pipeline konzentriert, müssen Sie zuvor bestimmte grundlegende Ressourcen kontoübergreifend einrichten. Insbesondere müssen Sie die S3-Buckets und -Ordner, AWS Glue-Ressourcen und Redshift Serverless-Ressourcen in ihren jeweiligen Konten erstellen, bevor Sie die vollständige Workflow-Integration mit Amazon MWAA implementieren.
Stellen Sie Ressourcen in Konto A mithilfe von AWS CloudFormation bereit
Starten Sie in Konto A das bereitgestellte AWS CloudFormation Stack, um die folgenden Ressourcen zu erstellen:
- Die Quell- und Ziel-S3-Buckets und -Ordner. Als Best Practice werden die Eingabe- und Ausgabe-Bucket-Strukturen mit der Hive-Partitionierung als formatiert
s3://<bucket>/products/YYYY/MM/DD/. - Ein Beispieldatensatz namens
products.csv, die wir in diesem Beitrag verwenden.
![]()
Laden Sie den AWS Glue-Auftrag auf Amazon S3 in Konto B hoch
Erstellen Sie in Konto B einen Amazon S3-Standort mit dem Namen aws-glue-assets-<account-id>-<region>/scripts (falls nicht vorhanden). Ersetzen Sie die Parameter für die Konto-ID und die Region im sample_glue_job.py Skript und laden Sie die AWS Glue-Auftragsdatei an den Amazon S3-Speicherort hoch.
Stellen Sie Ressourcen in Konto B mithilfe von AWS CloudFormation bereit
Starten Sie in Konto B die bereitgestellte CloudFormation-Stack-Vorlage, um die folgenden Ressourcen zu erstellen:
- Der S3-Eimer
airflow-<username>-bucketzum Speichern von Airflow-bezogenen Dateien mit der folgenden Struktur:- Dags – Der Ordner für DAG-Dateien.
- Plugins – Die Datei für alle benutzerdefinierten oder Community-Airflow-Plugins.
- Anforderungen - Die
requirements.txtDatei für alle Python-Pakete. - Skripte – Alle im DAG verwendeten SQL-Skripte.
- technische Daten – Alle im DAG verwendeten Datensätze.
- Eine serverlose Redshift-Umgebung. Dem Namen der Arbeitsgruppe und des Namespace wird ein Präfix vorangestellt
sample. - Eine AWS Glue-Umgebung, die Folgendes enthält:
- Ein AWS-Kleber Crawler, das die Daten aus dem S3-Quell-Bucket crawlt
sample-inp-bucket-etl-<username>in Konto A. - Eine Datenbank namens
products_dbim AWS Glue-Datenkatalog. - Ein ELT Job namens
sample_glue_job. Dieser Job kann Dateien aus dem lesenproductsTabelle im Datenkatalog und laden Sie Daten in die Redshift-Tabelleproducts.
- Ein AWS-Kleber Crawler, das die Daten aus dem S3-Quell-Bucket crawlt
- Ein VPC-Gateway-Endpunkt zu Amazon S3.
- Eine Amazon MWAA-Umgebung. Ausführliche Schritte zum Erstellen einer Amazon MWAA-Umgebung mithilfe der Amazon MWAA-Konsole finden Sie unter Einführung von Amazon Managed Workflows für Apache Airflow (MWAA).
![]()
Erstellen Sie Amazon Redshift-Ressourcen
Erstellen Sie zwei Tabellen und eine gespeicherte Prozedur in einer Redshift Serverless-Arbeitsgruppe mit products.sql Datei.
In diesem Beispiel erstellen wir zwei Tabellen namens products und products_f. Der Name der gespeicherten Prozedur lautet sp_products.
Konfigurieren Sie Airflow-Berechtigungen
Nachdem die Amazon MWAA-Umgebung erfolgreich erstellt wurde, wird der Status als angezeigt Verfügbar. Wählen Sie Öffnen Sie die Airflow-Benutzeroberfläche , um die Airflow-Benutzeroberfläche anzuzeigen. DAGs werden automatisch aus dem S3-Bucket synchronisiert und sind in der Benutzeroberfläche sichtbar. Zu diesem Zeitpunkt befinden sich jedoch keine DAGs im S3-Ordner.
Fügen Sie die vom Kunden verwaltete Richtlinie hinzu AmazonMWAAFullConsoleAccess, wodurch Airflow-Benutzern Zugriffsberechtigungen gewährt werden AWS Identity and Access Management and (IAM)-Ressourcen und fügen Sie diese Richtlinie der Amazon MWAA-Rolle hinzu. Weitere Informationen finden Sie unter Zugriff auf eine Amazon MWAA-Umgebung.
Die mit der Amazon MWAA-Rolle verbundenen Richtlinien haben vollen Zugriff und dürfen nur zu Testzwecken in einer sicheren Testumgebung verwendet werden. Befolgen Sie für Produktionsbereitstellungen das Prinzip der geringsten Rechte.
Richten Sie die Umgebung ein
In diesem Abschnitt werden die Schritte zum Konfigurieren der Umgebung beschrieben. Der Prozess umfasst die folgenden allgemeinen Schritte:
- Aktualisieren Sie alle erforderlichen Anbieter.
- Kontoübergreifenden Zugriff einrichten.
- Stellen Sie eine VPC-Peering-Verbindung zwischen der Amazon MWAA VPC und der Amazon Redshift VPC her.
- Konfigurieren Sie Secrets Manager für die Integration mit Amazon MWAA.
- Definieren Sie Luftstromverbindungen.
Aktualisieren Sie die Anbieter
Befolgen Sie die Schritte in diesem Abschnitt, wenn Ihre Version von Amazon MWAA niedriger als 2.8.1 ist (die neueste Version zum Zeitpunkt des Verfassens dieses Beitrags).
Anbieter sind Pakete, die von der Community verwaltet werden und alle Kernoperatoren, Hooks und Sensoren für einen bestimmten Dienst enthalten. Der Amazon-Anbieter wird für die Interaktion mit AWS-Diensten wie Amazon S3, Amazon Redshift Serverless, AWS Glue und mehr verwendet. Innerhalb des Amazon-Anbieters gibt es über 200 Module.
Obwohl die in Amazon MWAA unterstützte Airflow-Version 2.6.3 ist, die im Lieferumfang der von Amazon bereitgestellten Paketversion 8.2.0 enthalten ist, wurde die Unterstützung für Amazon Redshift Serverless erst mit der von Amazon bereitgestellten Paketversion 8.4.0 hinzugefügt. Da die standardmäßig gebündelte Anbieterversion älter ist als zum Zeitpunkt der Einführung der Redshift Serverless-Unterstützung, muss die Anbieterversion aktualisiert werden, um diese Funktionalität nutzen zu können.
Der erste Schritt besteht darin, die Einschränkungsdatei zu aktualisieren und requirements.txt Datei mit den richtigen Versionen. Beziehen auf Angabe neuerer Anbieterpakete Schritte zum Aktualisieren des Amazon-Anbieterpakets.
- Geben Sie die Anforderungen wie folgt an:
- Aktualisieren Sie die Version in der Einschränkungsdatei auf 8.4.0 oder höher.
- Fügen Sie Einschränkungen-3.11-aktualisiert.txt Datei an die
/dags-Ordner.
Beziehen auf Apache Airflow-Versionen in Amazon Managed Workflows für Apache Airflow für korrekte Versionen der Einschränkungsdatei abhängig von der Airflow-Version.
- Navigieren Sie zur Amazon MWAA-Umgebung und wählen Sie Bearbeiten.
- Der DAG-Code in Amazon S3Z. Anforderungsdatei, wählen Sie die neueste Version.
- Auswählen Speichern.
Dadurch wird die Umgebung aktualisiert und neue Anbieter werden wirksam.
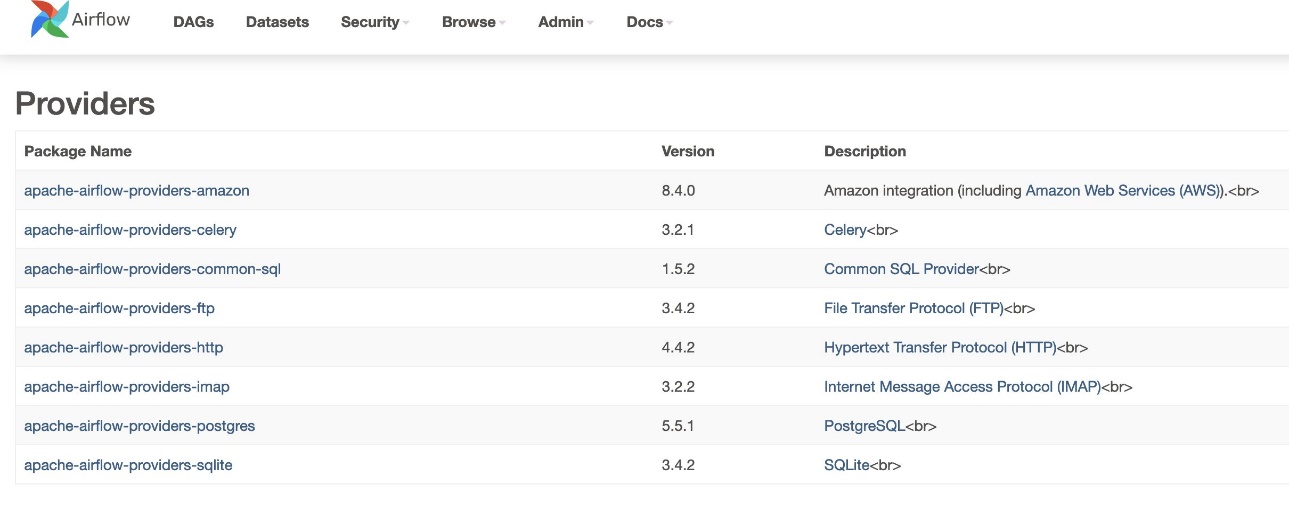
- Um die Version des Anbieters zu überprüfen, gehen Sie zu Anbieter unter dem Administrator Tabelle.
Die Version für das Amazon-Anbieterpaket sollte 8.4.0 sein, wie im folgenden Screenshot gezeigt. Wenn nicht, ist beim Laden ein Fehler aufgetreten requirements.txt. Um etwaige Fehler zu beheben, gehen Sie zur CloudWatch-Konsole und öffnen Sie die requirements_install_ip Einloggen Streams protokollieren, wo Fehler aufgelistet sind. Beziehen auf Aktivieren von Protokollen auf der Amazon MWAA-Konsole für weitere Informationen an.
Kontoübergreifenden Zugriff einrichten
Sie müssen kontoübergreifende Richtlinien und Rollen zwischen Konto A und Konto B einrichten, um auf die S3-Buckets zugreifen und Daten laden und entladen zu können. Führen Sie die folgenden Schritte aus:
- Konfigurieren Sie in Konto A die Bucket-Richtlinie für den Bucket
sample-inp-bucket-etl-<username>um den AWS Glue- und Amazon MWAA-Rollen in Konto B Berechtigungen für Objekte im Bucket zu erteilensample-inp-bucket-etl-<username>: - Konfigurieren Sie auf ähnliche Weise die Bucket-Richtlinie für den Bucket
sample-opt-bucket-etl-<username>So erteilen Sie Amazon MWAA-Rollen in Konto B Berechtigungen zum Einfügen von Objekten in diesen Bucket: - Erstellen Sie in Konto A eine IAM-Richtlinie mit dem Namen
policy_for_roleA, was die erforderlichen Amazon S3-Aktionen für den Ausgabe-Bucket ermöglicht: - Erstellen Sie eine neue IAM-Rolle mit dem Namen
RoleAmit Konto B als vertrauenswürdige Entitätsrolle und fügen Sie diese Richtlinie der Rolle hinzu. Dadurch kann Konto B die Rolle A übernehmen, um die erforderlichen Amazon S3-Aktionen für den Ausgabe-Bucket auszuführen. - Erstellen Sie in Konto B eine IAM-Richtlinie mit dem Namen
s3-cross-account-accessmit der Berechtigung, auf Objekte im Bucket zuzugreifensample-inp-bucket-etl-<username>, das sich auf Konto A befindet. - Fügen Sie diese Richtlinie zur AWS Glue-Rolle und der Amazon MWAA-Rolle hinzu:
- Erstellen Sie in Konto B die IAM-Richtlinie
policy_for_roleBAngabe von Konto A als vertrauenswürdige Entität. Das Folgende ist die Vertrauensrichtlinie, die angenommen werden sollteRoleAin Konto A: - Erstellen Sie eine neue IAM-Rolle mit dem Namen
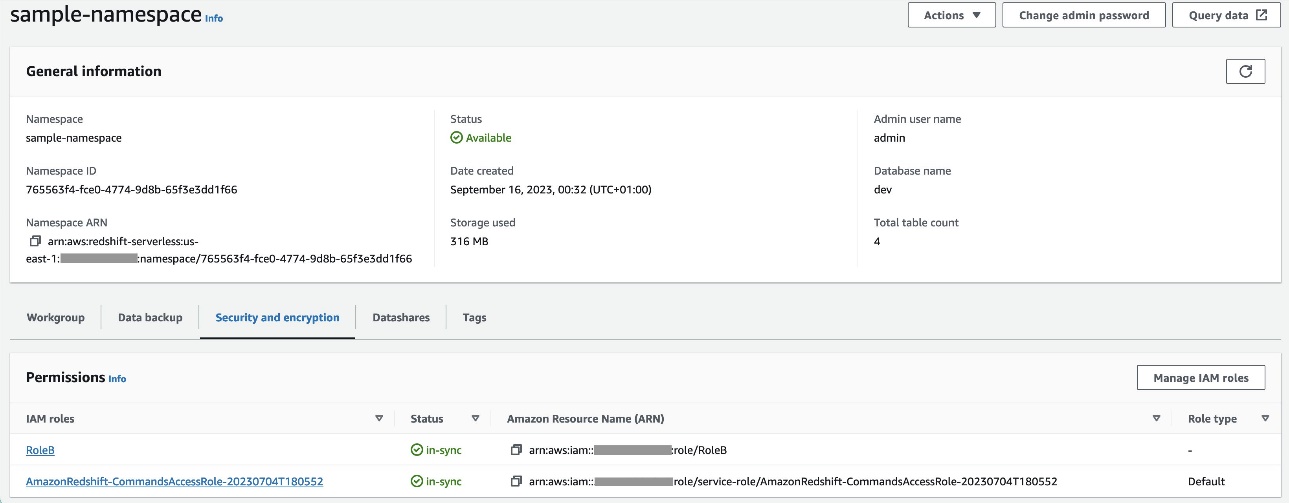
RoleBmit Amazon Redshift als vertrauenswürdigem Entitätstyp und fügen Sie diese Richtlinie der Rolle hinzu. Dies erlaubtRoleBannehmenRoleAin Konto A und auch von Amazon Redshift übernommen werden. - Anfügen
RoleBin den Redshift Serverless-Namespace, sodass Amazon Redshift Objekte in den S3-Ausgabe-Bucket in Konto A schreiben kann. - Anhängen der Richtlinie
policy_for_roleBzur Amazon MWAA-Rolle, die Amazon MWAA den Zugriff auf den Ausgabe-Bucket in Konto A ermöglicht.
Beziehen auf Wie gewähre ich kontoübergreifenden Zugriff auf Objekte, die sich in Amazon S3-Buckets befinden? Weitere Informationen zum Einrichten des kontoübergreifenden Zugriffs auf Objekte in Amazon S3 über AWS Glue und Amazon MWAA. Beziehen auf Wie kann ich Daten von Amazon Redshift in einen Amazon S3-Bucket in einem anderen Konto KOPIEREN oder ENTLADEN? Weitere Informationen zum Einrichten von Rollen zum Entladen von Daten von Amazon Redshift nach Amazon S3 von Amazon MWAA.
Richten Sie VPC-Peering zwischen den Amazon MWAA- und Amazon Redshift-VPCs ein
Da sich Amazon MWAA und Amazon Redshift in zwei separaten VPCs befinden, müssen Sie VPC-Peering zwischen ihnen einrichten. Sie müssen den Routing-Tabellen, die den Subnetzen für beide Dienste zugeordnet sind, eine Route hinzufügen. Beziehen auf Arbeiten Sie mit VPC-Peering-Verbindungen Einzelheiten zum VPC-Peering finden Sie hier.

Stellen Sie sicher, dass der CIDR-Bereich der Amazon MWAA VPC in der Redshift-Sicherheitsgruppe zulässig ist und der CIDR-Bereich der Amazon Redshift VPC in der Amazon MWAA-Sicherheitsgruppe zulässig ist, wie im folgenden Screenshot gezeigt.

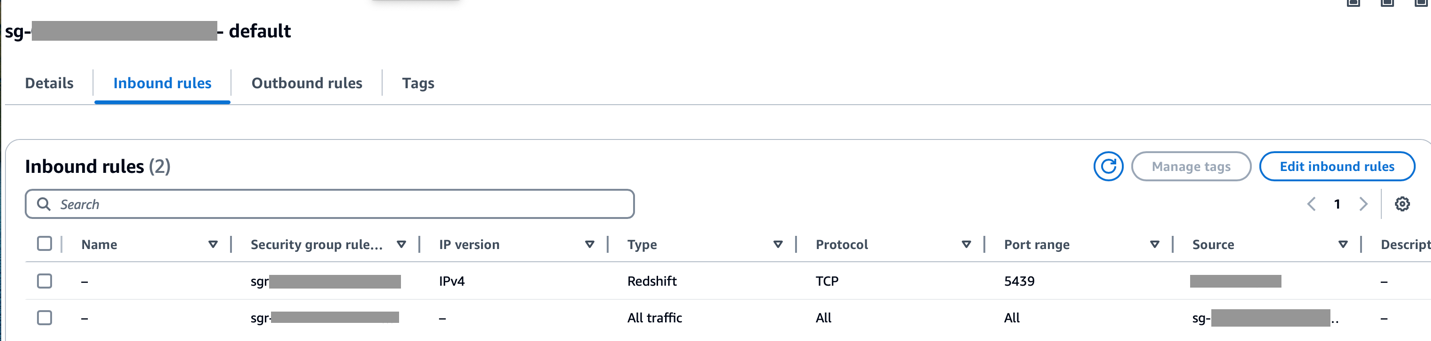
Wenn einer der vorherigen Schritte falsch konfiguriert ist, wird bei der DAG-Ausführung wahrscheinlich ein „Verbindungs-Timeout“-Fehler auftreten.
Konfigurieren Sie die Amazon MWAA-Verbindung mit Secrets Manager
Wenn die Amazon MWAA-Pipeline für die Verwendung von Secrets Manager konfiguriert ist, sucht sie zunächst in einem alternativen Backend (wie Secrets Manager) nach Verbindungen und Variablen. Wenn das alternative Backend den benötigten Wert enthält, wird er zurückgegeben. Andernfalls wird die Metadatendatenbank auf den Wert überprüft und stattdessen dieser zurückgegeben. Weitere Einzelheiten finden Sie unter Konfigurieren einer Apache Airflow-Verbindung mithilfe eines AWS Secrets Manager-Geheimnisses.
Führen Sie die folgenden Schritte aus:
- Konfigurieren Sie a VPC-Endpunkt um Amazon MWAA und Secrets Manager zu verknüpfen (
com.amazonaws.us-east-1.secretsmanager).
Dadurch kann Amazon MWAA auf die im Secrets Manager gespeicherten Anmeldeinformationen zugreifen.

- Um Amazon MWAA die Berechtigung zum Zugriff auf die geheimen Schlüssel von Secrets Manager zu erteilen, fügen Sie die Richtlinie mit dem Namen hinzu
SecretsManagerReadWritezur IAM-Rolle der Umgebung. - Um das Secrets Manager-Backend als Apache Airflow-Konfigurationsoption zu erstellen, gehen Sie zu den Airflow-Konfigurationsoptionen, fügen Sie die folgenden Schlüssel-Wert-Paare hinzu und speichern Sie Ihre Einstellungen.
Dadurch wird Airflow so konfiguriert, dass es nach Verbindungszeichenfolgen und Variablen sucht airflow/connections/* und airflow/variables/* Wege:

- Um eine Airflow-Verbindungs-URI-Zeichenfolge zu generieren, gehen Sie zu AWS CloudShell und geben Sie eine Python-Shell ein.
- Führen Sie den folgenden Code aus, um die Verbindungs-URI-Zeichenfolge zu generieren:
Die Verbindungszeichenfolge sollte wie folgt generiert werden:
- Fügen Sie die Verbindung im Secrets Manager hinzu, indem Sie den folgenden Befehl im verwenden AWS-Befehlszeilenschnittstelle (AWS-CLI).
Dies kann auch über die Secrets Manager-Konsole erfolgen. Dies wird im Secrets Manager als Klartext hinzugefügt.
Nutzen Sie die Verbindung airflow/connections/secrets_redshift_connection in der DAG. Wenn der DAG ausgeführt wird, sucht er nach dieser Verbindung und ruft die Geheimnisse vom Secrets Manager ab. Im Falle von RedshiftDataOperator, pass die secret_arn als Parameter anstelle des Verbindungsnamens.
Sie können Geheimnisse auch über die Secrets Manager-Konsole als Schlüssel-Wert-Paare hinzufügen.
- Fügen Sie im Secrets Manager ein weiteres Geheimnis hinzu und speichern Sie es unter
airflow/connections/redshift_conn_test.
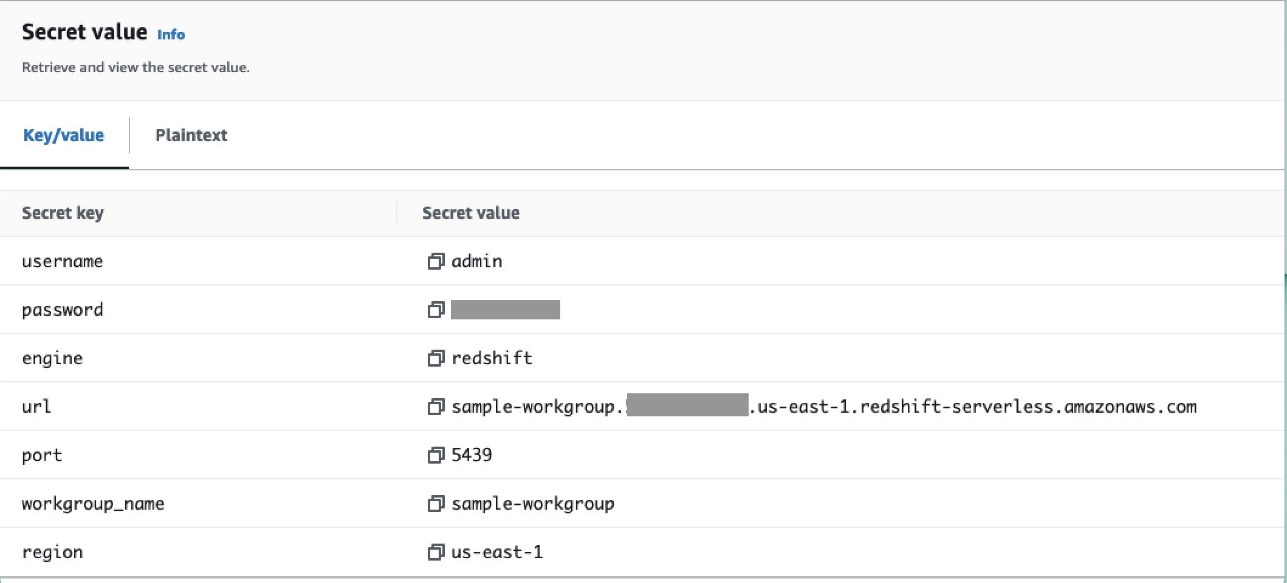
Erstellen Sie eine Airflow-Verbindung über die Metadatendatenbank
Sie können auch Verbindungen in der Benutzeroberfläche erstellen. In diesem Fall werden die Verbindungsdetails in einer Airflow-Metadatendatenbank gespeichert. Wenn die Amazon MWAA-Umgebung nicht für die Verwendung des Secrets Manager-Backends konfiguriert ist, überprüft sie die Metadatendatenbank auf den Wert und gibt diesen zurück. Sie können eine Airflow-Verbindung über die Benutzeroberfläche, AWS CLI oder API erstellen. In diesem Abschnitt zeigen wir, wie Sie mithilfe der Airflow-Benutzeroberfläche eine Verbindung herstellen.
- Aussichten für Verbindungs-IDGeben Sie einen Namen für die Verbindung ein.
- Aussichten für Verbindungstyp, wählen Amazon RedShift.
- Aussichten für GastgeberGeben Sie den Redshift-Endpunkt (ohne Port und Datenbank) für Redshift Serverless ein.
- Aussichten für Datenbase, eingeben
dev. - Aussichten für Mitglied, geben Sie Ihren Admin-Benutzernamen ein.
- Aussichten für Passwort, geben Sie Ihr Passwort ein.
- Aussichten für Hafen, verwenden Sie Port 5439.
- Aussichten für ExtraStellen Sie die
regionundtimeoutParameter. - Testen Sie die Verbindung und speichern Sie dann Ihre Einstellungen.

Erstellen Sie eine DAG und führen Sie sie aus
In diesem Abschnitt beschreiben wir, wie Sie mit verschiedenen Komponenten eine DAG erstellen. Nachdem Sie den DAG erstellt und ausgeführt haben, können Sie die Ergebnisse überprüfen, indem Sie Redshift-Tabellen abfragen und die Ziel-S3-Buckets überprüfen.
Erstellen Sie einen DAG
In Airflow werden Datenpipelines im Python-Code als DAGs definiert. Wir erstellen eine DAG, die aus verschiedenen Operatoren, Sensoren, Verbindungen, Aufgaben und Regeln besteht:
- Der DAG beginnt mit der Suche nach Quelldateien im S3-Bucket
sample-inp-bucket-etl-<username>unter Konto A für den aktuellen Tag verwendenS3KeySensor. S3KeySensor wird verwendet, um darauf zu warten, dass ein oder mehrere Schlüssel in einem S3-Bucket vorhanden sind.- Unser S3-Bucket ist beispielsweise partitioniert als
s3://bucket/products/YYYY/MM/DD/, daher sollte unser Sensor nach Ordnern mit dem aktuellen Datum suchen. Wir haben das aktuelle Datum im DAG abgeleitet und an übergebenS3KeySensor, das nach neuen Dateien im aktuellen Tagesordner sucht. - Wir haben auch eingestellt
wildcard_matchasTrue, was die Suche ermöglichtbucket_keyals Unix-Wildcard-Muster zu interpretieren. Stellen Sie die einmodezureschedulesodass die Sensoraufgabe den Worker-Slot freigibt, wenn die Kriterien nicht erfüllt sind, und sie zu einem späteren Zeitpunkt neu geplant wird. Es empfiehlt sich, diesen Modus zu verwenden, wennpoke_intervalist länger als 1 Minute, um eine Überlastung des Planers zu verhindern.
- Unser S3-Bucket ist beispielsweise partitioniert als
- Nachdem die Datei im S3-Bucket verfügbar ist, wird der AWS Glue-Crawler mit ausgeführt
GlueCrawlerOperatorum den S3-Quell-Bucket zu crawlensample-inp-bucket-etl-<username>unter Konto A und aktualisiert die Tabellenmetadaten unterproducts_dbDatenbank im Datenkatalog. Der Crawler verwendet die AWS Glue-Rolle und die Datenkatalogdatenbank, die in den vorherigen Schritten erstellt wurden. - Die DAG verwendet
GlueCrawlerSensorwarten, bis der Crawler abgeschlossen ist. - Wenn der Crawler-Job abgeschlossen ist,
GlueJobOperatorwird zum Ausführen des AWS Glue-Jobs verwendet. Der Name des AWS Glue-Skripts (zusammen mit dem Standort) wird zusammen mit der AWS Glue IAM-Rolle an den Operator übergeben. Andere Parameter wieGlueVersion,NumberofWorkersundWorkerTypewerden mit übergebencreate_job_kwargsParameters. - Die DAG verwendet
GlueJobSensorum auf den Abschluss des AWS Glue-Auftrags zu warten. Wenn es fertig ist, ist die Redshift-Staging-Tabelleproductswird mit Daten aus der S3-Datei geladen. - Sie können von Airflow aus auf drei verschiedene Arten eine Verbindung zu Amazon Redshift herstellen Betreiber:
PythonOperator.SQLExecuteQueryOperator, das eine PostgreSQL-Verbindung verwendet undredshift_defaultals Standardverbindung.RedshiftDataOperator, das die Redshift Data API verwendet undaws_defaultals Standardverbindung.
In unserer DAG verwenden wir SQLExecuteQueryOperator und RedshiftDataOperator um zu zeigen, wie diese Operatoren verwendet werden. Die gespeicherten Redshift-Prozeduren werden ausgeführt RedshiftDataOperator. Die DAG führt auch SQL-Befehle in Amazon Redshift aus, um die Daten mithilfe von aus der Staging-Tabelle zu löschen SQLExecuteQueryOperator.
Da wir unsere Amazon MWAA-Umgebung so konfiguriert haben, dass sie im Secrets Manager nach Verbindungen sucht, ruft der DAG beim Ausführen die Redshift-Verbindungsdetails wie Benutzername, Passwort, Host, Port und Region vom Secrets Manager ab. Wenn die Verbindung im Secrets Manager nicht gefunden wird, werden die Werte von den Standardverbindungen abgerufen.
In SQLExecuteQueryOperatorübergeben wir den Verbindungsnamen, den wir im Secrets Manager erstellt haben. Es sucht airflow/connections/secrets_redshift_connection und ruft die Geheimnisse vom Secrets Manager ab. Wenn Secrets Manager nicht eingerichtet ist, wird die Verbindung manuell erstellt (z. B. redshift-conn-id) übergeben werden kann.
In RedshiftDataOperator, wir übergeben den Secret_arn des airflow/connections/redshift_conn_test Verbindung, die im Secrets Manager erstellt wurde, als Parameter.
- Als letzte Aufgabe
RedshiftToS3Operatorwird verwendet, um Daten aus der Redshift-Tabelle in einen S3-Bucket zu entladensample-opt-bucket-etlin Konto B.airflow/connections/redshift_conn_testvom Secrets Manager wird zum Entladen der Daten verwendet. TriggerRuleeingestellt istALL_DONE, wodurch der nächste Schritt ausgeführt werden kann, nachdem alle Upstream-Aufgaben abgeschlossen sind.- Die Abhängigkeit von Aufgaben wird über definiert
chain()Funktion, die bei Bedarf die parallele Ausführung von Aufgaben ermöglicht. In unserem Fall möchten wir, dass alle Aufgaben nacheinander ausgeführt werden.
Das Folgende ist der vollständige DAG-Code. Der dag_id sollte mit dem Namen des DAG-Skripts übereinstimmen, andernfalls wird es nicht mit der Airflow-Benutzeroberfläche synchronisiert.
Überprüfen Sie die DAG-Ausführung
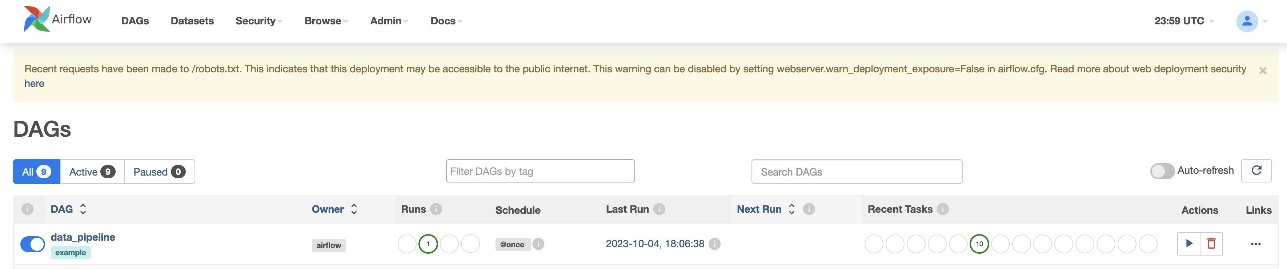
Nachdem Sie die DAG-Datei erstellt (die Variablen im DAG-Skript ersetzt) und in die Datei hochgeladen haben s3://sample-airflow-instance/dags Ordner, wird er automatisch mit der Airflow-Benutzeroberfläche synchronisiert. Alle DAGs erscheinen auf der DAGs Tab. Schalten Sie die um ON Option, um die DAG ausführbar zu machen. Weil unser DAG darauf eingestellt ist schedule="@once", müssen Sie den Job manuell ausführen, indem Sie unten auf das Symbol „Ausführen“ klicken Aktionen. Wenn der DAG abgeschlossen ist, wird der Status in Grün aktualisiert, wie im folgenden Screenshot gezeigt.
Im Links Im Abschnitt gibt es Optionen zum Anzeigen des Codes, der Grafik, des Rasters, des Protokolls und mehr. Wählen Graph um die DAG in einem Diagrammformat zu visualisieren. Wie im folgenden Screenshot gezeigt, bezeichnet jede Farbe des Knotens einen bestimmten Operator und die Farbe der Knotenumrisse bezeichnet einen bestimmten Status.

Überprüfen Sie die Ergebnisse
Navigieren Sie in der Amazon Redshift-Konsole zu der Abfrage-Editor v2 und wählen Sie die Daten im aus products_f Tisch. Die Tabelle sollte geladen sein und die gleiche Anzahl an Datensätzen wie S3-Dateien haben.

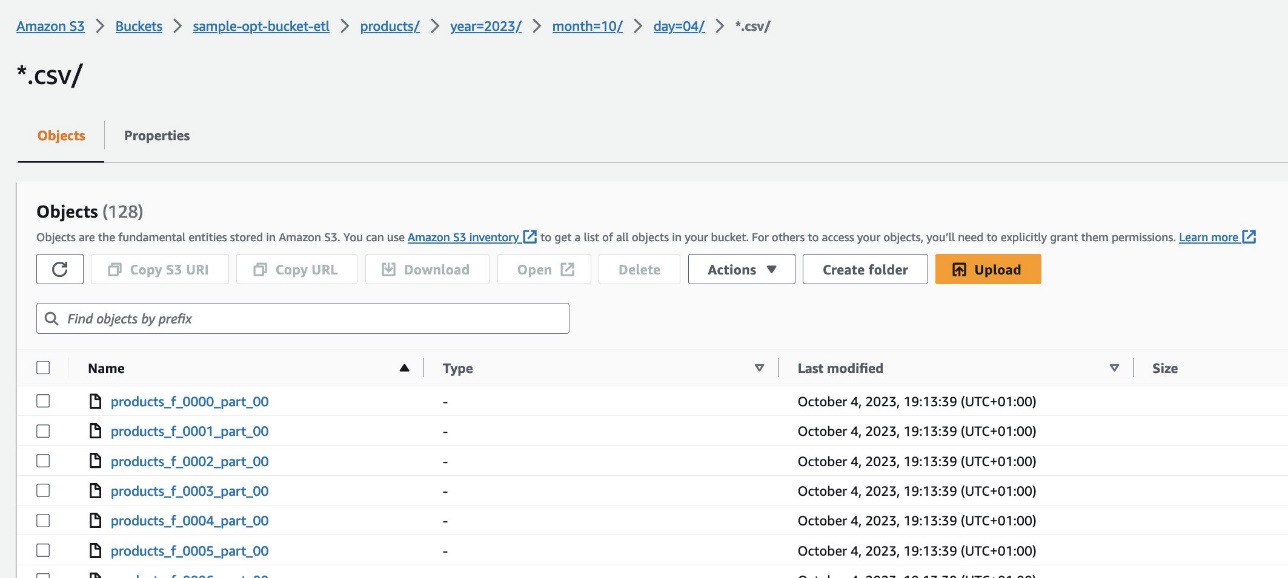
Navigieren Sie auf der Amazon S3-Konsole zum S3-Bucket s3://sample-opt-bucket-etl in Konto B. Die product_f Dateien sollten unter der Ordnerstruktur erstellt werden s3://sample-opt-bucket-etl/products/YYYY/MM/DD/.
Aufräumen
Bereinigen Sie die im Rahmen dieses Beitrags erstellten Ressourcen, um laufende Kosten zu vermeiden:
- Löschen Sie die CloudFormation-Stacks und den S3-Bucket, die Sie als Voraussetzungen erstellt haben.
- Löschen Sie die VPCs und VPC-Peering-Verbindungen, kontoübergreifenden Richtlinien und Rollen sowie Geheimnisse im Secrets Manager.
Zusammenfassung
Mit Amazon MWAA können Sie mithilfe von Airflow und Python komplexe Arbeitsabläufe erstellen, ohne Cluster, Knoten oder anderen betrieblichen Aufwand zu verwalten, der normalerweise mit der Bereitstellung und Skalierung von Airflow in der Produktion verbunden ist. In diesem Beitrag haben wir gezeigt, wie Amazon MWAA eine automatisierte Möglichkeit bietet, Daten zwischen verschiedenen Konten und Diensten innerhalb von AWS aufzunehmen, umzuwandeln, zu analysieren und zu verteilen. Weitere Beispiele für andere AWS-Betreiber finden Sie im Folgenden GitHub-Repository; Wir ermutigen Sie, mehr zu erfahren, indem Sie einige dieser Beispiele ausprobieren.
Über die Autoren

Radhika Jakkula ist Big Data Prototyping Solutions Architect bei AWS. Sie hilft Kunden beim Erstellen von Prototypen mithilfe von AWS-Analysediensten und speziell entwickelten Datenbanken. Sie ist Spezialistin für die Bewertung einer Vielzahl von Anforderungen und die Anwendung relevanter AWS-Services, Big-Data-Tools und Frameworks zur Erstellung einer robusten Architektur.
 Sidhanth Muralidhar ist Principal Technical Account Manager bei AWS. Er arbeitet mit großen Unternehmenskunden zusammen, die ihre Workloads auf AWS ausführen. Ihm liegt die Zusammenarbeit mit Kunden am Herzen und er unterstützt sie bei der Gestaltung von Workloads im Hinblick auf Kosten, Zuverlässigkeit, Leistung und betriebliche Exzellenz im richtigen Maßstab auf ihrem Weg in die Cloud. Er hat auch ein großes Interesse an Datenanalysen.
Sidhanth Muralidhar ist Principal Technical Account Manager bei AWS. Er arbeitet mit großen Unternehmenskunden zusammen, die ihre Workloads auf AWS ausführen. Ihm liegt die Zusammenarbeit mit Kunden am Herzen und er unterstützt sie bei der Gestaltung von Workloads im Hinblick auf Kosten, Zuverlässigkeit, Leistung und betriebliche Exzellenz im richtigen Maßstab auf ihrem Weg in die Cloud. Er hat auch ein großes Interesse an Datenanalysen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/orchestrate-an-end-to-end-etl-pipeline-using-amazon-s3-aws-glue-and-amazon-redshift-serverless-with-amazon-mwaa/

