
Imagen de pch.vecto on Freepik
La limpieza de datos es una actividad obligada para cualquier experto en datos porque necesitamos que nuestros datos estén libres de errores, sean coherentes y se puedan utilizar para el análisis. Sin este paso, el resultado del análisis podría verse afectado. Sin embargo, la limpieza de datos a menudo lleva mucho tiempo y puede ser repetitiva. Además, a veces nos perdemos un error del que debemos darnos cuenta.
Por eso podemos confiar en los paquetes de Python diseñados para la limpieza de datos. Estos paquetes se diseñaron para mejorar nuestra experiencia de limpieza de datos y acortar el tiempo de procesamiento de la limpieza de datos. ¿Qué son estos paquetes? Vamos a averiguar.
Pandas proporciona muchas funciones de limpieza de datos, como fillna y dropna, pero aún podrían mejorarse. PyJanitor es un paquete de Python que proporciona API de limpieza de datos dentro de la API de Pandas sin reemplazarlas. El paquete proporciona varios métodos que incluyen, entre otros, los siguientes:
- Limpieza de nombres de columnas,
- Identificación de valores duplicados,
- Factorización de datos,
- codificación de datos,
Y muchos más. Sin embargo, lo especial de PyJanitor es que las API se pueden ejecutar a través del método de cadena. Vamos a probarlos con los datos de ejemplo. Para este ejemplo, usaría el Datos de entrenamiento del Titanic de Kaggle.
Para empezar, instalemos el paquete PyJanitor.
pip install pyjanitor
Luego cargaríamos el conjunto de datos del Titanic.
import pandas as pd
df = pd.read_csv('train.csv')
df.head()

Usaríamos el conjunto de datos anterior para nuestro ejemplo. Probemos el paquete PyJanitor para limpiar nuestros datos con algunas funciones de muestra.
import janitor df.factorize_columns(column_names=["Sex"]).also( lambda df: print(f"DataFrame shape after factorize is: {df.shape}")
).bin_numeric(from_column_name="Age", to_column_name="Age_binned").also( lambda df: print(f"DataFrame shape after binning is: {df.shape}")
).clean_names()
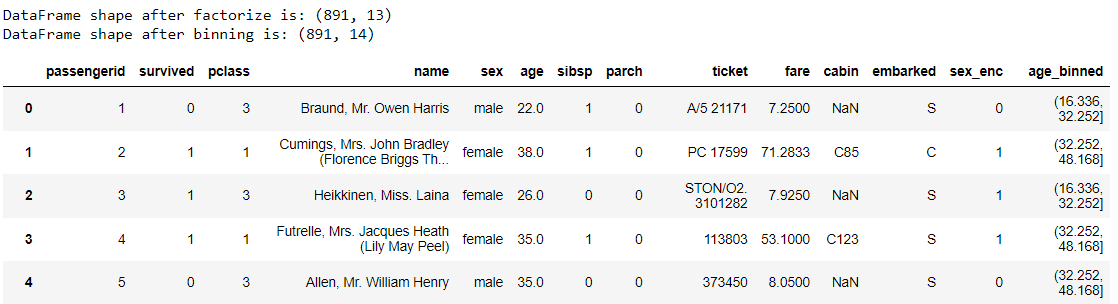
Transformamos nuestro marco de datos inicial con un método de encadenamiento. Entonces, ¿qué sucede con el código anterior? Déjame desglosarlo.
- Primero, transformamos la columna 'Sexo' en una función numérica con factorización,
- Con la función también, imprimimos la forma después de la factorización,
- Luego, dividimos la edad en grupos usando la función bin_numeric,
- Lo mismo con la función también,
- Por último, limpiamos el nombre de la columna convirtiéndolos a minúsculas, luego reemplazamos todos los espacios con guiones bajos usando clean_names
Todo lo anterior se puede hacer con métodos de encadenamiento único que se realizan directamente en nuestro marco de datos de Pandas. Todavía puede hacer mucho más con el paquete PyJanitor, por lo que le sugiero que revise su documentación.
Motor de características es un paquete de Python diseñado para la ingeniería y selección de funciones que conserva el método de las API de aprendizaje de scikit, como ajuste y transformación. El paquete se diseñó para proporcionar un transformador de datos integrado en la tubería de aprendizaje automático.
El paquete proporciona varios transformadores de limpieza de datos, incluidos, entre otros:
- imputación de datos,
- codificación categórica,
- Eliminación de valores atípicos,
- selección de variables,
Y muchas funciones más. Probemos el paquete instalándolos primero.
pip install feature-engine
El uso de Feature-Engine es fácil; solo necesita importarlos y entrenar el transformador, similar a la API scikit-learn. Por ejemplo, utilizo un Imputer para llenar los datos faltantes de la columna Edad con la Mediana.
from feature_engine.imputation import MeanMedianImputer # set up the imputer
median_imputer = MeanMedianImputer(imputation_method='median', variables=['Age'])
# fit the imputer
median_imputer.fit(df) median_imputer.transform(df)
El código anterior llenaría nuestra columna de edad en el marco de datos con la mediana. Hay tantos transformadores con los que podrías experimentar. Intente encontrar el que se adapte a su tubería de datos en el documentación.
laboratorio limpio es un paquete de Python de código abierto para solucionar cualquier problema con la etiqueta del conjunto de datos de aprendizaje automático. Está diseñado para hacer que cualquier entrenamiento de aprendizaje automático con etiquetas ruidosas sea más sólido y brinde un resultado confiable. Cualquier modelo con salida probabilística se puede entrenar junto con los paquetes Cleanlab.
Probemos el paquete con un ejemplo de código. Primero, necesitamos instalar el Cleanlab.
pip install cleanlab
Mientras Cleanlab trabaja para limpiar los problemas de las etiquetas, intentemos preparar el conjunto de datos para el entrenamiento de aprendizaje automático.
# Selecting the features
df = df[["Survived", "Pclass", "SibSp", "Parch"]] # Splitting the dataset
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( df.drop("Survived", axis=1), df["Survived"], random_state=42
)
Una vez que el conjunto de datos esté listo, intentaríamos ajustar el conjunto de datos con un modelo clasificador. Veamos las métricas de predicción sin limpiar la etiqueta.
#Fit the model
from sklearn.linear_model import LogisticRegression model = LogisticRegression(random_state = 42)
model.fit(X_train, y_train)
preds = model.predict(X_test) #Print the metrics result
from sklearn.metrics import classification_report print(classification_report(y_test, preds))
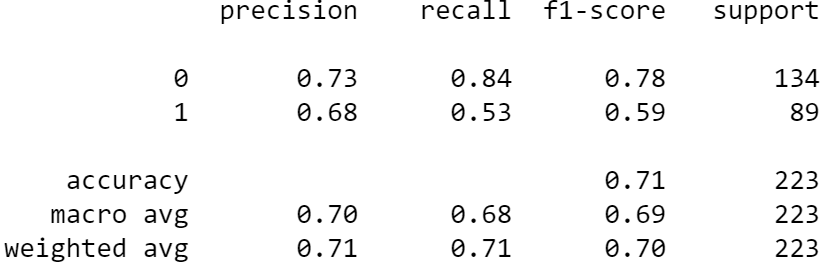
Es un buen resultado, pero veamos si podemos mejorar el resultado después de limpiar la etiqueta. Intentemos hacer eso con el siguiente código.
from cleanlab.classification import CleanLearning #initiate model with CleanLearning
cl = CleanLearning(model, seed=42) # Fit model
cl.fit(X_train, y_train) # Examine the label quality
cl.get_label_issues()
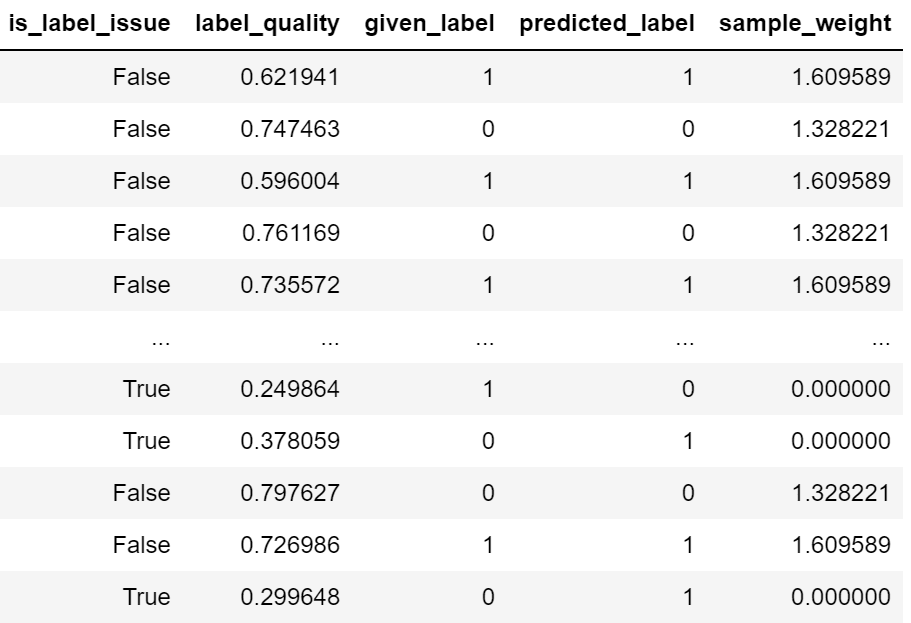
Podemos ver en el resultado anterior que algunas etiquetas tienen problemas debido a errores de predicción. Al limpiar la etiqueta, veamos cómo resultan las métricas del modelo.
clean_preds = cl.predict(X_test)
print(classification_report(y_test, clean_preds))

Podemos ver que hay una mejora en los resultados en comparación con nuestro modelo anterior sin limpieza de etiquetas. Todavía puedes hacer muchas cosas con Cleanlab; Te sugiero que visites el documentación para aprender más.
La limpieza de datos es un paso obligatorio para cualquier proceso de análisis de datos. Aún así, a menudo lleva mucho tiempo limpiar todo correctamente. Afortunadamente, existen paquetes de Python desarrollados para ayudarnos a limpiar los datos correctamente. En este artículo, presento tres paquetes para ayudar a limpiar los datos: PyJanitor, Feature-Engine y Cleanlab.
Cornelio Yudha Wijaya es subgerente de ciencia de datos y escritor de datos. Mientras trabaja a tiempo completo en Allianz Indonesia, le encanta compartir consejos sobre Python y datos a través de las redes sociales y los medios de escritura.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/03/introduction-python-libraries-data-cleaning.html?utm_source=rss&utm_medium=rss&utm_campaign=introduction-to-python-libraries-for-data-cleaning

