
Imagen del creador de imágenes de Bing
Fundamentalmente, hay cuatro tipos de algoritmos de aprendizaje automático; algoritmos supervisados, algoritmos semi-supervisados, algoritmos no supervisados y algoritmos de aprendizaje por refuerzo. Los algoritmos supervisados son aquellos que trabajan sobre datos que tienen etiquetas. Semi-supervisado es donde parte de los datos están etiquetados y otra parte no. Sin supervisión es donde los datos no tienen etiquetas. El aprendizaje por refuerzo es un tipo de aprendizaje automático en el que tenemos un agente que trabaja para lograr un objetivo determinado y lo hace a través de prueba y error. El agente es recompensado cuando acierta y penalizado cuando se equivoca.
Nuestro enfoque está en un algoritmo de aprendizaje automático no supervisado, en particular el algoritmo de agrupamiento K-Means.
K-Means es un algoritmo de aprendizaje automático no supervisado que asigna puntos de datos a uno de los grupos K. Sin supervisión, como se mencionó anteriormente, significa que los datos no tienen etiquetas de grupo como las que tendría en un problema supervisado. El algoritmo observa los patrones en los datos y los usa para colocar cada punto de datos en un grupo con características similares. Por supuesto, existen otros algoritmos para resolver problemas de agrupamiento como DBSCAN, Agglomerative clustering, KNN y otros, pero K-Means es algo más popular en comparación con otros enfoques.
La K se refiere a los distintos grupos en los que se colocan los puntos de datos. Si K es 3, los puntos de datos se dividirán en 3 grupos. Si es 5, entonces tendremos 5 grupos. Más sobre esto más adelante.
Hay una miríada de formas en las que podemos aplicar el agrupamiento para resolver problemas del mundo real. A continuación se muestran algunos ejemplos de las aplicaciones:
- Agrupación de clientes: Las empresas pueden utilizar la agrupación para agrupar a sus clientes para lograr un mejor marketing objetivo y comprender su base de clientes.
- Clasificación de documentos: Agrupar documentos según los temas o palabras clave del contenido.
- Segmentaciones de imagen: agrupación de píxeles de imagen antes del reconocimiento de imagen.
- Agrupar a los estudiantes en función de su rendimiento.: Puede agruparlos en los de mejor desempeño, los de desempeño promedio y usarlos para mejorar la experiencia de aprendizaje.
El algoritmo ejecuta una iteración inicial en la que los puntos de datos se colocan aleatoriamente en grupos, cuyo punto central se conoce como centroide. Se calcula la distancia euclidiana de cada punto de datos a los centroides, y si la distancia de un punto es mayor que a otro centroide, el punto se reasigna al 'otro' centroide. Cuando esto sucede, el algoritmo ejecutará otra iteración y el proceso continúa hasta que todas las agrupaciones tengan la varianza mínima dentro del grupo.
Lo que queremos decir con tener una variabilidad mínima dentro de un grupo es que las características de las observaciones en un grupo deben ser lo más similares posible.
Imagine un conjunto de datos con dos variables trazadas como se muestra a continuación. Las variables podrían ser la altura y el peso de los individuos. Si tuviéramos una tercera variable como la edad, tendríamos un diagrama en 3D, pero por ahora, sigamos con el diagrama en 2D a continuación.
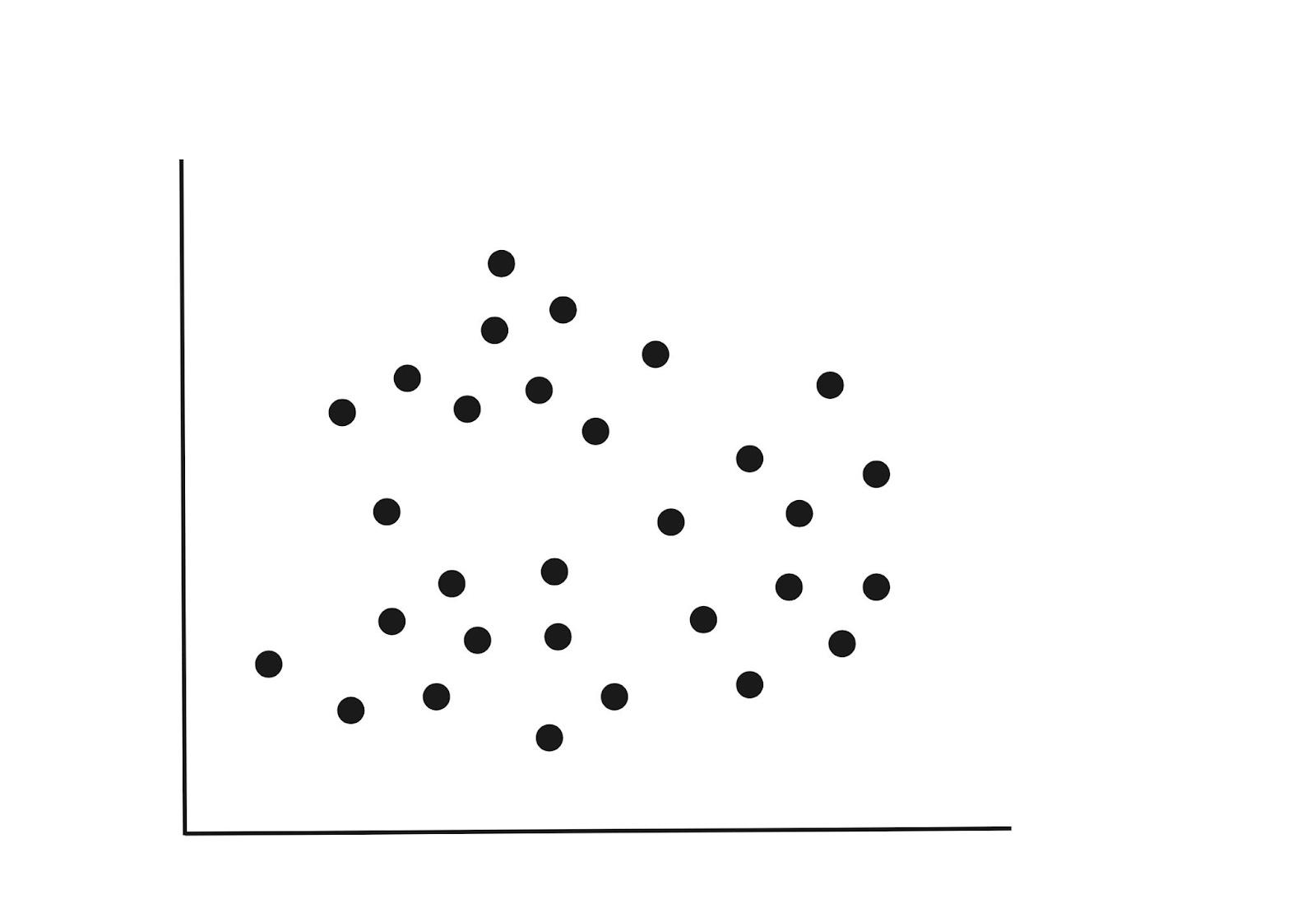
Paso 1: Inicialización
En el diagrama anterior podemos detectar tres grupos. Al ajustar nuestro modelo, podemos asignar aleatoriamente k=3. Esto simplemente significa que buscamos dividir los puntos de datos en tres grupos.
En la iteración inicial, los K centroides se seleccionan aleatoriamente en el ejemplo a continuación.
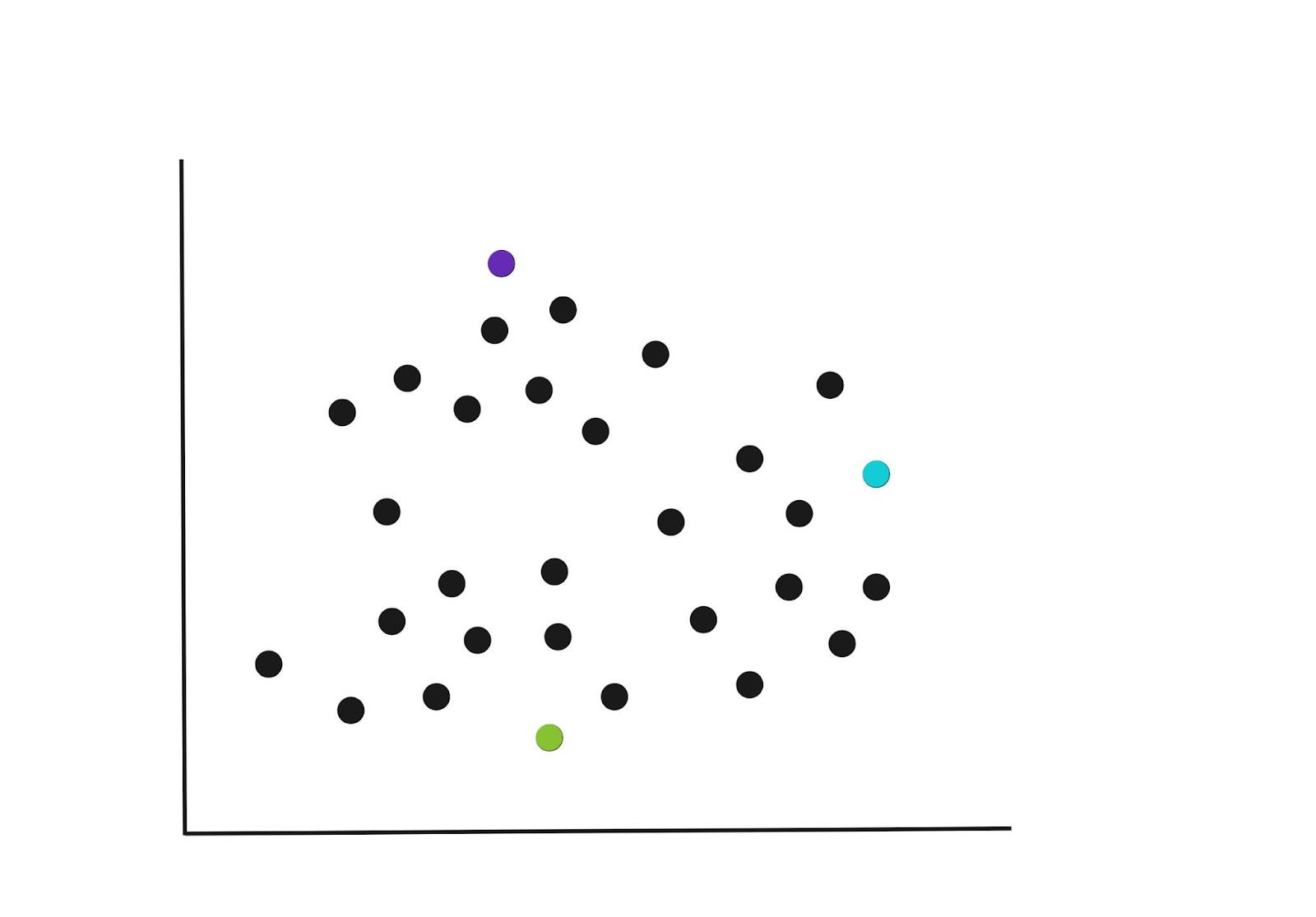
Puede especificar la cantidad de K-Clusters en los que el algoritmo debe agrupar los puntos de datos; sin embargo, hay un mejor enfoque para esto. Nos sumergiremos en cómo elegir K más tarde.
Paso 2: Asignar puntos a uno de los K centroides
Una vez que se han seleccionado los centroides, cada punto de datos se asigna al centroide más cercano, según la distancia euclidiana del punto al centroide más cercano. Esto podría resultar en las agrupaciones que se muestran en el siguiente gráfico.
Tenga en cuenta que se pueden utilizar otros tipos de medidas de distancia como la distancia de manhattan, la distancia de correlación de spearman y la distancia de correlación de Pearson como alternativa a la euclidiana, pero las clásicas son euclidiana y manhattan.
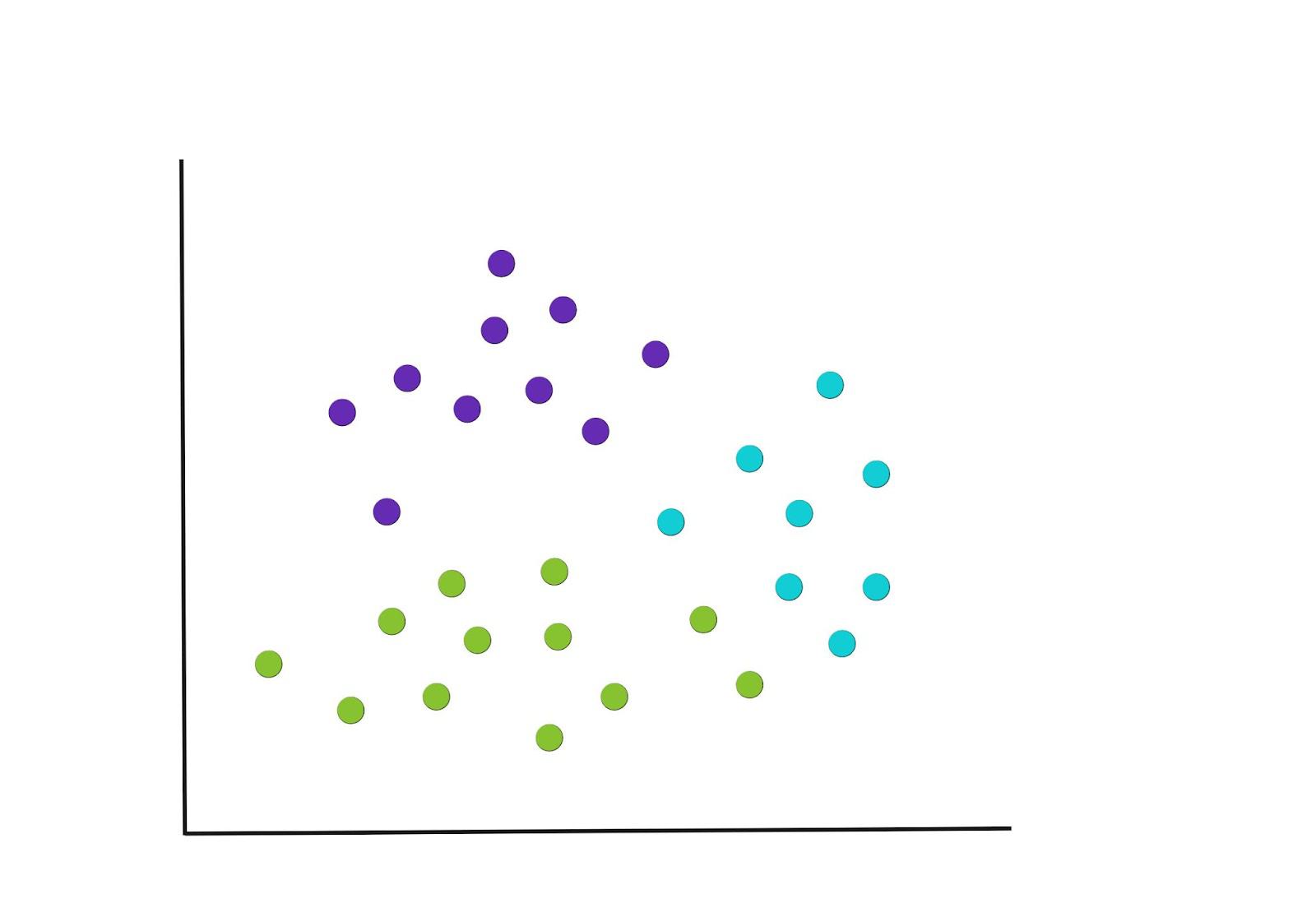
Paso 3: Vuelva a calcular los centroides
Después de la primera ronda de agrupaciones, los nuevos puntos centrales se vuelven a calcular y esto requerirá una reasignación de los puntos. El siguiente gráfico ofrece un ejemplo de cómo podrían ser potencialmente las nuevas agrupaciones y observa cómo algunos puntos se han movido a nuevos grupos.
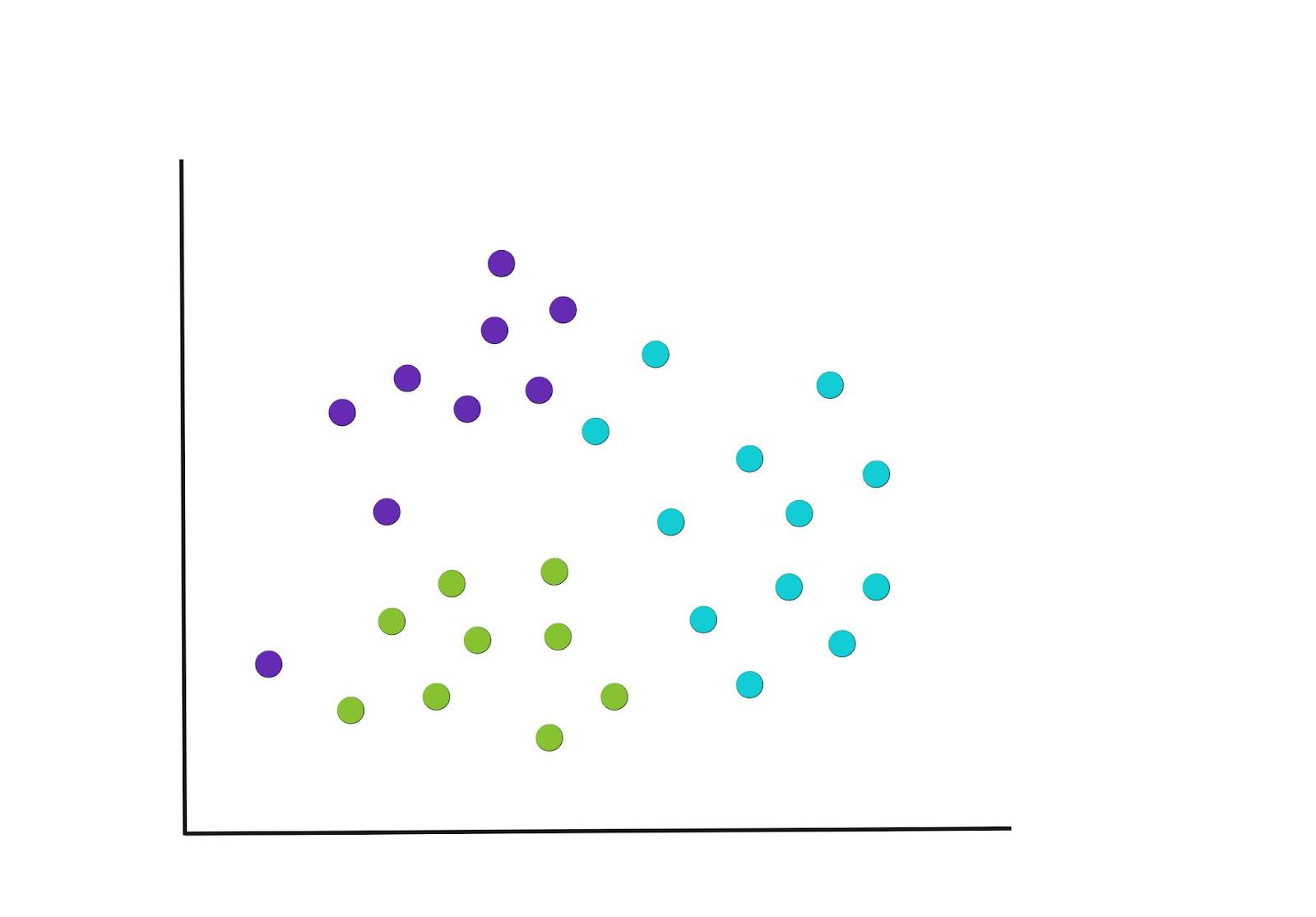
Iterar
El proceso de los pasos 2 y 3 se repite hasta llegar a un punto en el que no hay más reasignaciones de los puntos de datos o alcanzamos el número máximo de iteraciones. Las agrupaciones finales resultantes se muestran a continuación.
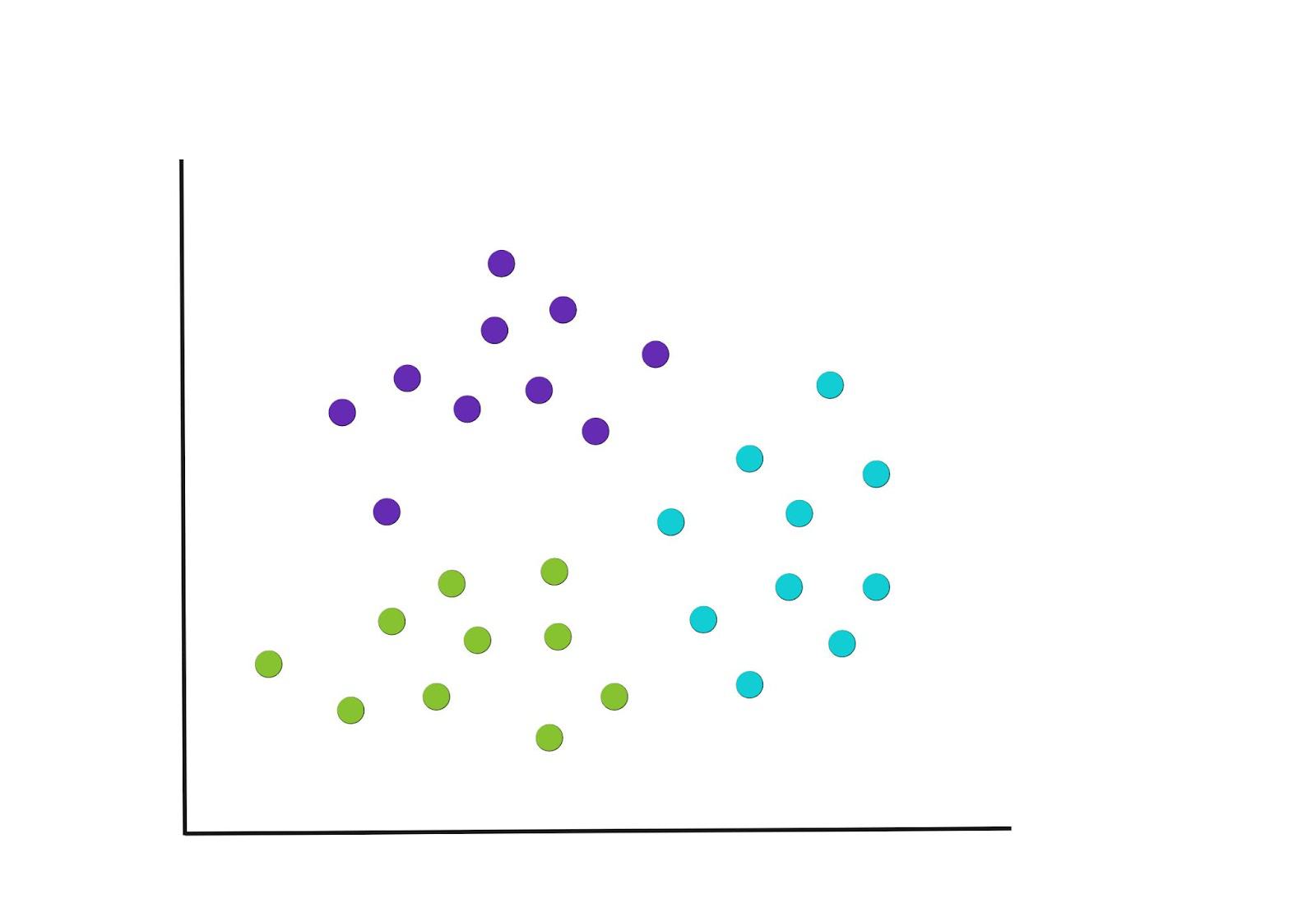
La elección de K
Los datos en los que trabajará como científico de datos no siempre tendrán demarcaciones distintas cuando se representen, como vería en el conjunto de datos de iris. A menudo, tratará con datos con dimensiones más altas que no se pueden graficar o, incluso si se grafican, no podrá determinar el número óptimo de agrupaciones. Un buen ejemplo de esto es el siguiente gráfico.
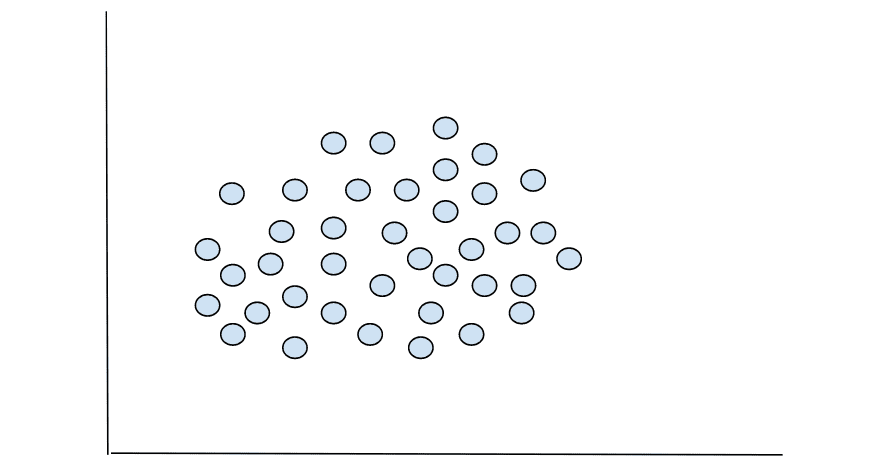
¿Puedes decir el número de agrupaciones? No claramente. Entonces, ¿cómo encontraremos la cantidad óptima de grupos en los que se pueden agrupar los puntos de datos anteriores?
Se utilizan diferentes métodos para encontrar el K óptimo, en el que se pueden agrupar los puntos de datos de un conjunto de datos dado, métodos de codo y silueta. Veamos brevemente cómo funcionan los dos enfoques.
método del codo
Este enfoque utiliza las variaciones totales dentro de un conglomerado, también conocidas como WCSS (dentro de la suma de los cuadrados del conglomerado). El objetivo es tener la varianza mínima dentro de los grupos (WCSS).
Este método funciona de esta manera:
- Toma un rango de valores K, digamos 1 - 8 y calcula el WSS para cada valor K.
- Los datos resultantes tendrán un valor K y el WSS correspondiente. Estos datos luego se usan para trazar un gráfico de WCSS contra los valores de k.
- El número óptimo de K está en el punto del codo, donde la curva comienza a acelerar. Es de este punto que el método deriva su nombre. Piensa en el codo de tu brazo.
Método de la silueta
Este método mide la similitud y la disimilitud. Cuantifica la distancia de un punto a otros miembros de su grupo asignado, y también la distancia a los miembros de otros grupos. Funciona de esta manera:
- Toma un rango de valores de K comenzando con 2.
- Para cada valor de K, calcula la similitud del grupo, que es la distancia promedio entre un punto de datos y todos los demás miembros del grupo en el mismo grupo.
- A continuación, la disimilitud del grupo se calcula calculando la distancia promedio entre un punto de datos y todos los demás miembros del grupo más cercano.
- El coeficiente de silueta será la diferencia entre el valor de similitud del grupo y el valor de disimilitud del grupo, dividido por el mayor de los dos valores.
El K óptimo sería aquel con el coeficiente más alto. Los valores de este coeficiente están acotados en el rango de -1 a 1.
Este es un artículo de introducción al algoritmo de agrupamiento de K-Means en el que cubrimos qué es, cómo funciona y cómo elegir K. En el siguiente artículo, veremos el proceso para resolver un agrupamiento del mundo real. problemas al usar la biblioteca scikit-learn de Python.
Clinton Oyogo Clinton cree que el análisis de datos para obtener información práctica es una parte crucial de su trabajo diario. Con sus habilidades en visualización de datos, disputa de datos y aprendizaje automático, se enorgullece de su trabajo como científico de datos.
Original. Publicado de nuevo con permiso.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/05/kmeans-clustering-algorithm-work.html?utm_source=rss&utm_medium=rss&utm_campaign=what-is-k-means-clustering-and-how-does-its-algorithm-work

