Los clientes han estado utilizando soluciones de almacenamiento de datos para realizar sus tareas de análisis tradicionales. Recientemente, los lagos de datos han ganado mucha tracción para convertirse en la base de las soluciones analíticas, porque vienen con beneficios tales como escalabilidad, tolerancia a fallas y soporte para conjuntos de datos estructurados, semiestructurados y no estructurados.
Los lagos de datos no son transaccionales por defecto; sin embargo, existen múltiples marcos de código abierto que mejoran los lagos de datos con propiedades ACID, lo que brinda la mejor solución de ambos mundos entre los mecanismos de almacenamiento transaccional y no transaccional.
Las canalizaciones tradicionales de ingesta y procesamiento por lotes que implican operaciones como la limpieza de datos y la unión con datos de referencia son fáciles de crear y rentables de mantener. Sin embargo, existe el desafío de ingerir conjuntos de datos, como Internet de las cosas (IoT) y flujos de clics, a un ritmo rápido con SLA de entrega casi en tiempo real. También querrá aplicar actualizaciones incrementales con captura de datos modificados (CDC) desde el sistema de origen hasta el destino. Para tomar decisiones basadas en datos de manera oportuna, debe tener en cuenta los registros perdidos y la contrapresión, y mantener el orden y la integridad de los eventos, especialmente si los datos de referencia también cambian rápidamente.
En esta publicación, nuestro objetivo es abordar estos desafíos. Brindamos una guía paso a paso para unir datos de transmisión a una tabla de referencia que cambia en tiempo real usando Pegamento AWS, Amazon DynamoDBy Servicio de migración de bases de datos de AWS (AWS DMS). También demostramos cómo ingerir datos de transmisión en un lago de datos transaccionales usando apache hudi para lograr actualizaciones incrementales con transacciones ACID.
Resumen de la solución
Para nuestro caso de uso de ejemplo, los datos de transmisión están llegando Secuencias de datos de Amazon Kinesisy los datos de referencia se gestionan en MySQL. Los datos de referencia se replican continuamente desde MySQL a DynamoDB a través de AWS DMS. El requisito aquí es enriquecer los datos de flujo en tiempo real al unirlos con los datos de referencia casi en tiempo real, y hacerlos consultables desde un motor de consulta como Atenea amazónica manteniendo la consistencia. En este caso de uso, los datos de referencia en MySQL se pueden actualizar cuando se cambia el requisito, y luego las consultas deben devolver resultados al reflejar las actualizaciones en los datos de referencia.
Esta solución aborda el problema de los usuarios que desean unirse a secuencias con conjuntos de datos de referencia cambiantes cuando el tamaño del conjunto de datos de referencia es pequeño. Los datos de referencia se mantienen en las tablas de DynamoDB y el trabajo de transmisión carga la tabla completa en la memoria para cada microlote, uniendo una transmisión de alto rendimiento a un pequeño conjunto de datos de referencia.
El siguiente diagrama ilustra la arquitectura de la solución.

Requisitos previos
Para este tutorial, debe tener los siguientes requisitos previos:
Crear roles de IAM y depósito S3
En esta sección, usted crea un Servicio de almacenamiento simple de Amazon (Amazon S3) cubeta y dos Gestión de identidades y accesos de AWS (IAM): uno para el trabajo de AWS Glue y otro para AWS DMS. Hacemos esto usando un Formación en la nube de AWS modelo. Complete los siguientes pasos:
- Inicie sesión en la consola de AWS CloudFormation.
- Elige Pila de lanzamiento::

- Elige Siguiente.
- Nombre de pila, ingrese un nombre para su pila.
- Nombre de tabla de DynamoDB, introduzca
tgt_country_lookup_table. Este es el nombre de su nueva tabla de DynamoDB. - S3BucketNamePrefijo, ingrese el prefijo de su nuevo depósito S3.
- Seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM con nombres personalizados.
- Elige Crear pila.
La creación de la pila puede tardar aproximadamente 1 minuto.
Crear un flujo de datos de Kinesis
En esta sección, creará un flujo de datos de Kinesis:
- En la consola de Kinesis, elija Flujos de datos en el panel de navegación.
- Elige Crear flujo de datos.
- Nombre del flujo de datos, ingresa el nombre de tu transmisión.
- Deje las configuraciones restantes como predeterminadas y elija Crear flujo de datos.
Se crea un flujo de datos de Kinesis con el modo bajo demanda.
Crear y configurar un clúster de Aurora MySQL
En esta sección, creará y configurará un clúster de Aurora MySQL como base de datos de origen. Primero, configure su clúster de base de datos Aurora MySQL de origen para habilitar CDC a través de AWS DMS a DynamoDB.
Crear un grupo de parámetros
Complete los siguientes pasos para crear un nuevo grupo de parámetros:
- En la consola de Amazon RDS, elija Grupos de parámetros en el panel de navegación.
- Elige Crear grupo de parámetros.
- Familia de grupos de parámetros, seleccione
aurora-mysql5.7. - Tipo de Propiedad, escoger Grupo de parámetros de clúster de base de datos.
- Nombre del grupo, introduzca
my-mysql-dynamodb-cdc. - Descripción, introduzca
Parameter group for demo Aurora MySQL database. - Elige Crear.
- Seleccione
my-mysql-dynamodb-cdc, y elige Editar bajo Acciones de grupo de parámetros. - Edite el grupo de parámetros de la siguiente manera:
| Nombre | Valor |
| binlog_row_imagen | ser completados |
| binlog_formato | FILA |
| binlog_checksum | NINGUNO |
| log_slave_updates | 1 |
- Elige Guardar los cambios.

Crear el clúster de Aurora MySQL
Complete los siguientes pasos para crear el clúster de Aurora MySQL:
- En la consola de Amazon RDS, elija Bases de datos en el panel de navegación.
- Elige Crear base de datos.
- Elija un método de creación de base de datos, escoger Creación estándar.
- under Opciones de motor, Para Tipo de motor, escoger Aurora (Compatible con MySQL).
- Versión del motor, escoger Aurora (MySQL 5.7) 2.11.2.
- Plantillas, escoger Producción.
- under Ajustes, Para Identificador de clúster de base de datos, ingrese un nombre para su base de datos.
- Nombre de usuario maestro, ingrese su nombre de usuario principal.
- Contraseña maestra y Confirmar contraseña maestra, ingrese su contraseña principal.
- under Configuración de instancia, Para clase de instancia de base de datos, escoger Clases Burstable (incluye clases t) y elige db.t3.pequeño.
- under Disponibilidad y durabilidad, Para Implementación Multi-AZ, escoger No cree una réplica de Aurora.
- under Conectividad, Para recurso de cómputo, escoger No conectarse a un recurso informático de EC2.
- Tipo de red, escoger IPv4.
- Nube privada virtual (VPC), elija su VPC.
- Grupo de subred de base de datos, elija su subred pública.
- Acceso público, escoger Sí.
- Grupo de seguridad de VPC (cortafuegos), elija el grupo de seguridad para su subred pública.
- under Autenticación de base de datos, Para Opciones de autenticación de base de datos, escoger Autenticación de contraseña.
- under Configuración adicional, Para Grupo de parámetros de clúster de base de datos, elija el grupo de parámetros de clúster que creó anteriormente.
- Elige Crear base de datos.
Otorgar permisos a la base de datos de origen
El siguiente paso es otorgar el permiso requerido en la base de datos Aurora MySQL de origen. Ahora puede conectarse al clúster de base de datos utilizando el Utilidad MySQL. Puede ejecutar consultas para completar las siguientes tareas:
- Cree una base de datos y una tabla de demostración y ejecute consultas sobre los datos
- Otorgar permiso a un usuario utilizado por el punto de enlace de AWS DMS
Complete los siguientes pasos:
- Inicie sesión en la instancia EC2 que está utilizando para conectarse a su clúster de base de datos.
- Ingrese el siguiente comando en el símbolo del sistema para conectarse a la instancia de base de datos principal de su clúster de base de datos:
- Ejecute el siguiente comando SQL para crear una base de datos:
- Ejecute el siguiente comando SQL para crear una tabla:
- Ejecute el siguiente comando SQL para completar la tabla con datos:
- Ejecute el siguiente comando SQL para crear un usuario para el punto de enlace de AWS DMS y otorgar permisos para tareas de CDC (reemplace el marcador de posición con su contraseña preferida):
Cree y configure recursos de AWS DMS para cargar datos en la tabla de referencia de DynamoDB
En esta sección, creará y configurará AWS DMS para replicar datos en la tabla de referencia de DynamoDB.
Crear una instancia de replicación de AWS DMS
Primero, cree una instancia de replicación de AWS DMS completando los siguientes pasos:
- En la consola de AWS DMS, elija Instancias de replicación en el panel de navegación.
- Elige Crear instancia de replicación.
- under Ajustes, Para Nombre, ingrese un nombre para su instancia.
- under Configuración de instancia, Para Alta disponibilidad, escoger Carga de trabajo de desarrollo o prueba (Single-AZ).
- under Conectividad y seguridad, Para Grupos de seguridad de VPC, escoger tu préstamo estudiantil.
- Elige Crear instancia de replicación.
Crear puntos de enlace de Amazon VPC
Opcionalmente, puede crear Puntos de enlace de Amazon VPC para DynamoDB cuando necesite conectarse a su tabla de DynamoDB desde la instancia de AWS DMS en una red privada. También asegúrese de habilitar Públicamente Accesible cuando necesite conectarse a una base de datos fuera de su VPC.
Crear un punto de enlace de origen de AWS DMS
Cree un punto de enlace de origen de AWS DMS completando los siguientes pasos:
- En la consola de AWS DMS, elija Endpoints en el panel de navegación.
- Elige Crear punto final.
- Tipo de punto final, escoger Extremo de origen.
- under Configuración de punto final, Para Identificador de punto final, ingrese un nombre para su punto final.
- motor de origen, escoger Amazon Aurora MySQL.
- Acceso a la base de datos de puntos finales, escoger Proporcionar información de acceso manualmente.
- Nombre del servidor, ingrese el nombre del punto final de su instancia de escritor de Aurora (por ejemplo,
mycluster.cluster-123456789012.us-east-1.rds.amazonaws.com). - Puerto, introduzca
3306. - nombre de usuario, ingrese un nombre de usuario para su tarea de AWS DMS.
- Contraseña, Ingrese una contraseña.
- Elige Crear punto final.
Cree un punto de enlace de destino de AWS DMS
Cree un punto de enlace de destino de AWS DMS completando los siguientes pasos:
- En la consola de AWS DMS, elija Endpoints en el panel de navegación.
- Elige Crear punto final.
- Tipo de punto final, escoger punto final de destino.
- under Configuración de punto final, Para Identificador de punto final, ingrese un nombre para su punto final.
- motor de destino, escoger Amazon DynamoDB.
- ARN del rol de acceso al servicio, ingrese el rol de IAM para su tarea de AWS DMS.
- Elige Crear punto final.
Crear tareas de migración de AWS DMS
Cree tareas de migración de bases de datos de AWS DMS completando los siguientes pasos:
- En la consola de AWS DMS, elija Tareas de migración de base de datos en el panel de navegación.
- Elige Crear tarea.
- under Configuración de tareas, Para Identificador de tareas, ingrese un nombre para su tarea.
- Instancia de replicación, elija su instancia de replicación.
- Extremo de la base de datos de origen, elija su punto final de origen.
- Punto final de la base de datos de destino, elija su punto final de destino.
- Tipo de migración, escoger Migre los datos existentes y replique los cambios en curso.
- under Configuraciones de tareas, Para Modo de preparación de la tabla de objetivos, escoger Hacer nada.
- Detener la tarea después de completar la carga completa, escoger No pares.
- Configuración de la columna LOB, escoger Modo LOB limitado.
- Registros de tareas, habilitar Activar registros de CloudWatch y Activar la aplicación optimizada por lotes.
- under Asignaciones de tablas, escoger Editor JSON e introduzca las siguientes reglas.
Aquí puede agregar valores a la columna. Con las siguientes reglas, la tarea CDC de AWS DMS primero creará una nueva tabla de DynamoDB con el nombre especificado en target-table-name. Luego replicará todos los registros, asignación de las columnas de la tabla de base de datos a los atributos de la tabla de DynamoDB.

- Elige Crear tarea.
Ahora se ha iniciado la tarea de replicación de AWS DMS.
- Esperen al Estado para mostrar como Carga completa.
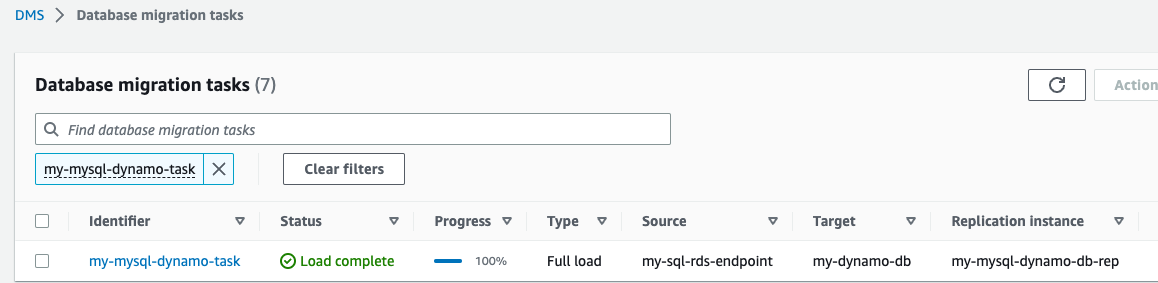
- En la consola DynamoDB, elija Mesas en el panel de navegación.
- Seleccione la tabla de referencia de DynamoDB y elija Explora los elementos de la mesa para revisar los registros replicados.

Cree una tabla de AWS Glue Data Catalog y un trabajo de ETL de transmisión de AWS Glue
En esta sección, creará una tabla de AWS Glue Data Catalog y un trabajo de extracción, transformación y carga (ETL) de transmisión de AWS Glue.
Crear una tabla de catálogo de datos
Cree una tabla de AWS Glue Data Catalog para el flujo de datos de origen de Kinesis con los siguientes pasos:
- En la consola de AWS Glue, elija Bases de datos bajo Catálogo de datos en el panel de navegación.
- Elige Agregar base de datos.
- Nombre, introduzca
my_kinesis_db. - Elige Crear base de datos.
- Elige Mesas bajo Bases de datos, A continuación, elija Agregar tabla.
- Nombre, introduzca
my_stream_src_table. - Base de datos, escoger
my_kinesis_db. - Seleccione el tipo de fuente, escoger Kinesis.
- El flujo de datos de Kinesis se encuentra en, escoger mi cuenta.
- Nombre de transmisión de Kinesis, ingrese un nombre para su flujo de datos.
- Clasificación, seleccione JSON.
- Elige Siguiente.
- Elige Editar esquema como JSON, ingrese el siguiente JSON, luego elija Guardar.
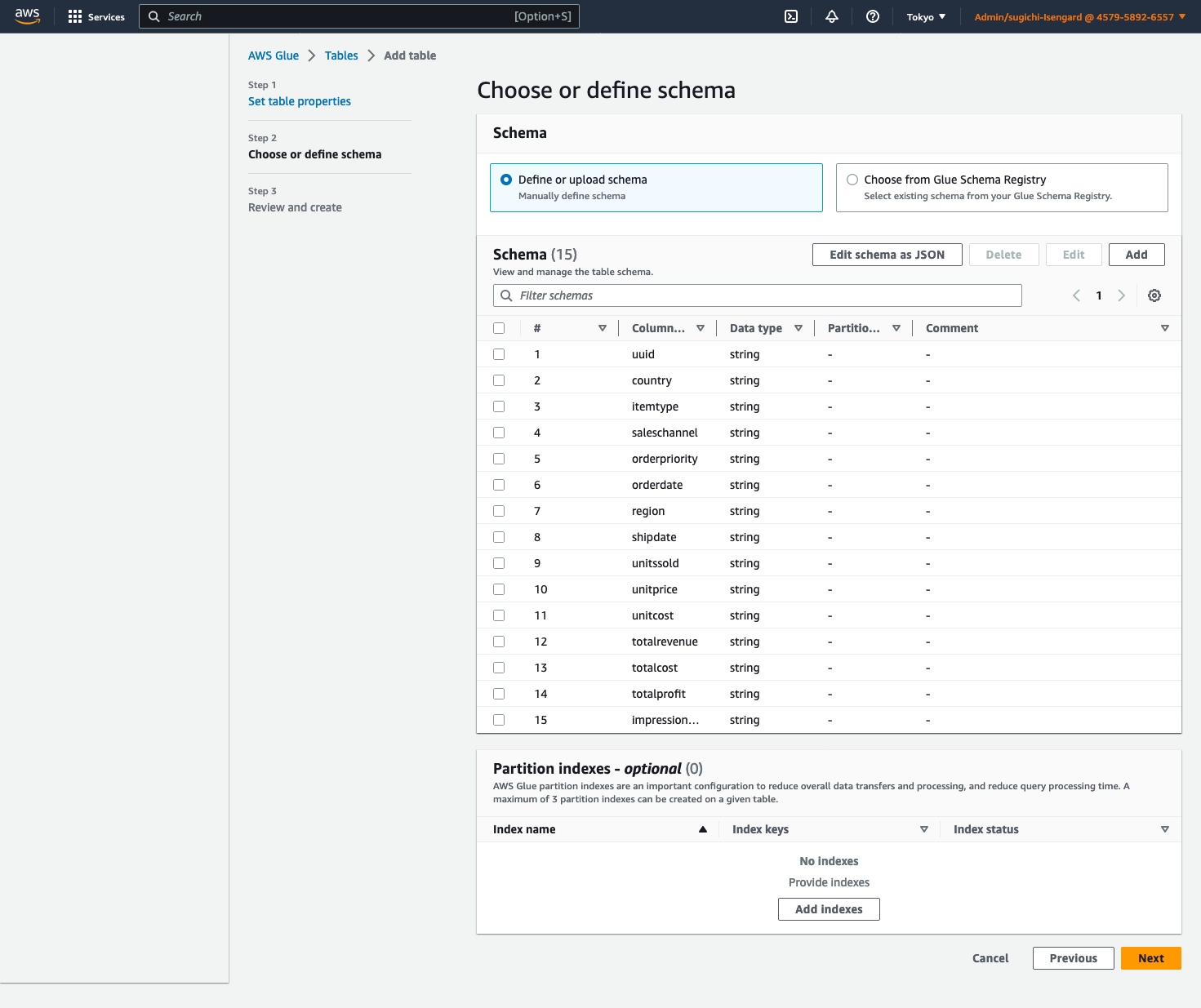
-
- Elige Siguiente, A continuación, elija Crear.
Cree un trabajo ETL de transmisión de AWS Glue
A continuación, crea un trabajo de transmisión de AWS Glue. AWS Glue 3.0 y versiones posteriores admiten Apache Hudi de forma nativa, por lo que usamos esta integración nativa para ingerir en una tabla de Hudi. Complete los siguientes pasos para crear el trabajo de transmisión de AWS Glue:
- En la consola de AWS Glue Studio, elija Editor de secuencias de comandos de chispa y elige Crear.
- under Detalles del trabajo pestaña, para Nombre, ingrese un nombre para su trabajo.
- Rol de IAM, elija el rol de IAM para su trabajo de AWS Glue.
- Tipo de Propiedad, seleccione Transmisión de chispa.
- Versión con pegamento, escoger Glue 4.0 - Soporta Spark 3.3, Scala 2, Python 3.
- Número solicitado de trabajadores, introduzca
3. - under Propiedades avanzadas, Para Parámetros de trabajo, escoger Añadir nuevo parámetro.
- Clave, introduzca
--conf. - Valor, introduzca
spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.hive.convertMetastoreParquet=false. - Elige Añadir nuevo parámetro.
- Clave, introduzca
--datalake-formats. - Valor, introduzca
hudi. - Ruta de la secuencia de comandos, introduzca
s3://<S3BucketName>/scripts/. - ruta temporal, introduzca
s3://<S3BucketName>/temporary/. - Opcionalmente, para Ruta de registros de la interfaz de usuario de Spark, introduzca
s3://<S3BucketName>/sparkHistoryLogs/.
- En Guión pestaña, ingrese el siguiente script en el editor de AWS Glue Studio y elija Crear.
El trabajo de transmisión casi en tiempo real enriquece los datos al unir un flujo de datos de Kinesis con una tabla de DynamoDB que contiene datos de referencia actualizados con frecuencia. El conjunto de datos enriquecido se carga en la tabla Hudi de destino en el lago de datos. Reemplazar con su depósito que creó a través de AWS CloudFormation:
- Elige Ejecutar para iniciar el trabajo de transmisión.
La siguiente captura de pantalla muestra ejemplos de DataFrames data_frame, country_lookup_dfy final_frame.
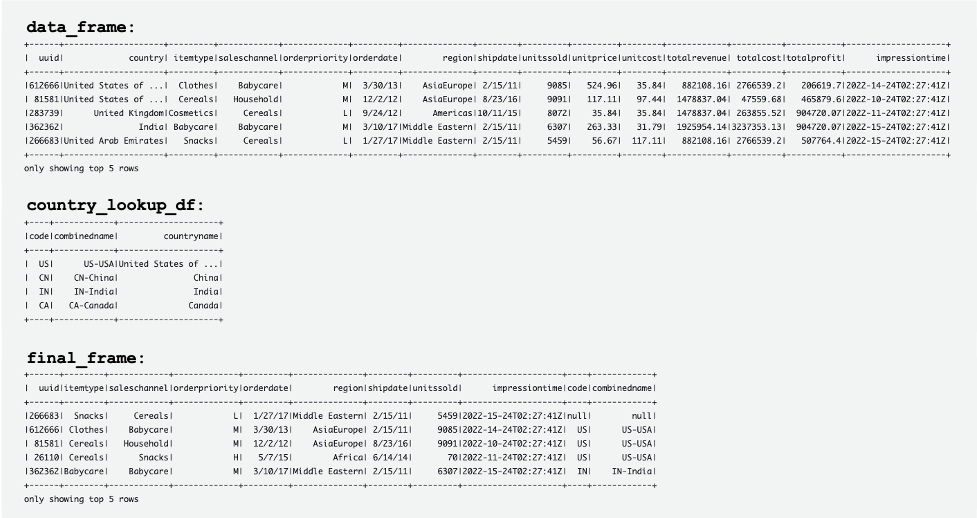
El trabajo de AWS Glue unió correctamente los registros provenientes del flujo de datos de Kinesis y la tabla de referencia en DynamoDB, y luego ingirió los registros unidos en Amazon S3 en formato Hudi.
Cree y ejecute una secuencia de comandos de Python para generar datos de muestra y cargarlos en el flujo de datos de Kinesis.
En esta sección, creará y ejecutará Python para generar datos de muestra y cargarlos en el flujo de datos de origen de Kinesis. Complete los siguientes pasos:
- Inicie sesión en AWS Cloud9, su instancia EC2 o cualquier otro host informático que coloque registros en su flujo de datos.
- Cree un archivo de Python llamado
generate-data-for-kds.py:
- Abra el archivo Python e ingrese el siguiente script:
Este script coloca un registro de flujo de datos de Kinesis cada 2 segundos.
Simule la actualización de la tabla de referencia en el clúster de Aurora MySQL
Ahora todos los recursos y configuraciones están listos. Para este ejemplo, queremos agregar un código de país de 3 dígitos a la tabla de referencia. Actualicemos registros en la tabla de Aurora MySQL para simular cambios. Complete los siguientes pasos:
- Asegúrese de que el trabajo de transmisión de AWS Glue ya se esté ejecutando.
- Vuelva a conectarse a la instancia de base de datos principal, como se describió anteriormente.
- Ingrese sus comandos SQL para actualizar registros:
Ahora se ha actualizado la tabla de referencia en la base de datos de origen de Aurora MySQL. Luego, los cambios se replican automáticamente en la tabla de referencia en DynamoDB.
Las siguientes tablas muestran los registros en data_frame, country_lookup_dfy final_frame. En country_lookup_df y final_frame, el combinedname columna tiene valores formateados como <2-digit-country-code>-<3-digit-country-code>-<country-name>, que muestra que los registros modificados en la tabla a la que se hace referencia se reflejan en la tabla sin reiniciar el trabajo de transmisión de AWS Glue. Significa que el trabajo de AWS Glue une correctamente los registros entrantes del flujo de datos de Kinesis con la tabla de referencia incluso cuando la tabla de referencia está cambiando.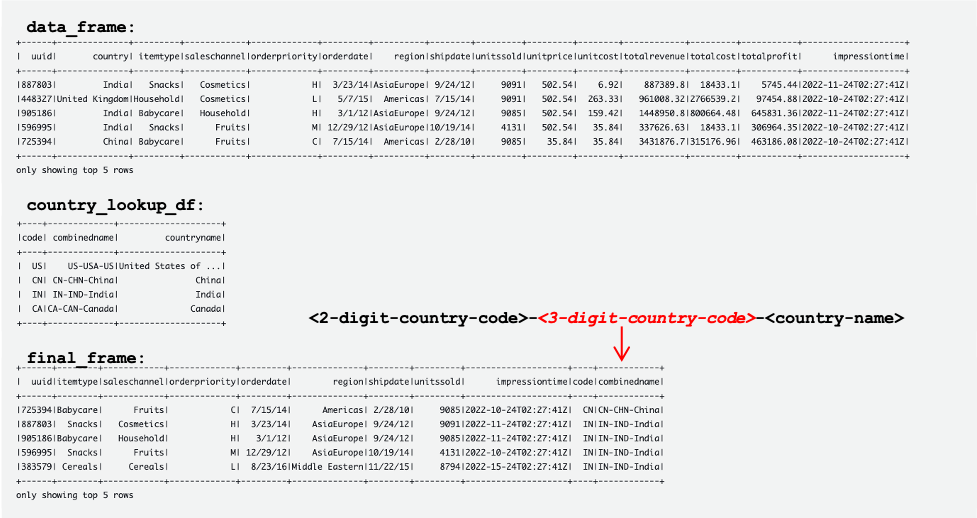
Consulta la tabla Hudi usando Athena
Consultemos la tabla Hudi usando Athena para ver los registros en la tabla de destino. Complete los siguientes pasos:
- Asegúrese de que el script y el trabajo de AWS Glue Streaming sigan funcionando:
- El script de Python (
generate-data-for-kds.py) todavía se está ejecutando. - Los datos generados se envían al flujo de datos.
- El trabajo de transmisión de AWS Glue aún se está ejecutando.
- El script de Python (
- En la consola de Athena, ejecute el siguiente SQL en el editor de consultas:
El siguiente resultado de la consulta muestra los registros que se procesan antes de cambiar la tabla a la que se hace referencia. Registros en el combinedname columna son similares a <2-digit-country-code>-<country-name>.

El siguiente resultado de la consulta muestra los registros que se procesan después de cambiar la tabla a la que se hace referencia. Registros en el combinedname columna son similares a <2-digit-country-code>-<3-digit-country-code>-<country-name>.

Ahora comprende que los datos de referencia modificados se reflejan correctamente en la tabla Hudi de destino que une los registros del flujo de datos de Kinesis y los datos de referencia en DynamoDB.
Limpiar
Como paso final, limpie los recursos:
- Elimine el flujo de datos de Kinesis.
- Elimine la tarea de migración, el punto de enlace y la instancia de replicación de AWS DMS.
- Detenga y elimine el trabajo de transmisión de AWS Glue.
- Elimine el entorno de AWS Cloud9.
- Elimine la plantilla de CloudFormation.
Conclusión
La creación y el mantenimiento de un lago de datos transaccionales que involucra la ingesta y el procesamiento de datos en tiempo real tiene múltiples componentes variables y decisiones que se deben tomar, como qué servicio de ingesta usar, cómo almacenar sus datos de referencia y qué marco de lago de datos transaccionales usar. En esta publicación, proporcionamos los detalles de implementación de dicha canalización, utilizando componentes nativos de AWS como componentes básicos y Apache Hudi como marco de código abierto para un lago de datos transaccionales.
Creemos que esta solución puede ser un punto de partida para las organizaciones que buscan implementar un nuevo lago de datos con tales requisitos. Además, los diferentes componentes son totalmente conectables y se pueden mezclar y combinar con lagos de datos existentes para abordar nuevos requisitos o migrar los existentes, abordando sus puntos débiles.
Sobre los autores
 manish kola es un arquitecto de soluciones de laboratorio de datos en AWS, donde trabaja en estrecha colaboración con clientes de diversas industrias para diseñar soluciones nativas en la nube para sus necesidades de inteligencia artificial y análisis de datos. Se asocia con los clientes en su recorrido por AWS para resolver sus problemas comerciales y crear prototipos escalables. Antes de unirse a AWS, la experiencia de Manish incluye ayudar a los clientes a implementar proyectos de almacenamiento de datos, BI, integración de datos y lago de datos.
manish kola es un arquitecto de soluciones de laboratorio de datos en AWS, donde trabaja en estrecha colaboración con clientes de diversas industrias para diseñar soluciones nativas en la nube para sus necesidades de inteligencia artificial y análisis de datos. Se asocia con los clientes en su recorrido por AWS para resolver sus problemas comerciales y crear prototipos escalables. Antes de unirse a AWS, la experiencia de Manish incluye ayudar a los clientes a implementar proyectos de almacenamiento de datos, BI, integración de datos y lago de datos.
 santosh kotagiri es arquitecto de soluciones en AWS con experiencia en análisis de datos y soluciones en la nube que conducen a resultados comerciales tangibles. Su experiencia radica en el diseño e implementación de soluciones de análisis de datos escalables para clientes de todas las industrias, con un enfoque en servicios nativos de la nube y de código abierto. Le apasiona aprovechar la tecnología para impulsar el crecimiento empresarial y resolver problemas complejos.
santosh kotagiri es arquitecto de soluciones en AWS con experiencia en análisis de datos y soluciones en la nube que conducen a resultados comerciales tangibles. Su experiencia radica en el diseño e implementación de soluciones de análisis de datos escalables para clientes de todas las industrias, con un enfoque en servicios nativos de la nube y de código abierto. Le apasiona aprovechar la tecnología para impulsar el crecimiento empresarial y resolver problemas complejos.
 Chiho Sugimoto es ingeniero de soporte en la nube en el equipo de soporte de Big Data de AWS. Le apasiona ayudar a los clientes a crear lagos de datos mediante cargas de trabajo de ETL. Le encanta la ciencia planetaria y disfruta estudiar el asteroide Ryugu los fines de semana.
Chiho Sugimoto es ingeniero de soporte en la nube en el equipo de soporte de Big Data de AWS. Le apasiona ayudar a los clientes a crear lagos de datos mediante cargas de trabajo de ETL. Le encanta la ciencia planetaria y disfruta estudiar el asteroide Ryugu los fines de semana.
 Noritaka Sekiyama es Arquitecto Principal de Big Data en el equipo de AWS Glue. Es responsable de crear artefactos de software para ayudar a los clientes. En su tiempo libre, disfruta andar en bicicleta con su nueva bicicleta de carretera.
Noritaka Sekiyama es Arquitecto Principal de Big Data en el equipo de AWS Glue. Es responsable de crear artefactos de software para ayudar a los clientes. En su tiempo libre, disfruta andar en bicicleta con su nueva bicicleta de carretera.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/join-streaming-source-cdc-glue/

