Introducción
En el corazón de Ciencia de los datos mentiras estadísticas, que han existido durante siglos pero siguen siendo fundamentalmente esenciales en la era digital actual. ¿Por qué? Debido a que los conceptos estadísticos básicos son la columna vertebral de análisis de los datos, permitiéndonos dar sentido a las grandes cantidades de datos que se generan diariamente. Es como conversar con datos, donde las estadísticas nos ayudan a hacer las preguntas correctas y comprender las historias que los datos intentan contar.
Desde predecir tendencias futuras y tomar decisiones basadas en datos hasta probar hipótesis y medir el desempeño, las estadísticas son la herramienta que impulsa los conocimientos detrás de las decisiones basadas en datos. Es el puente entre los datos sin procesar y los conocimientos prácticos, lo que los convierte en una parte indispensable de la ciencia de datos.
En este artículo, he recopilado los 15 conceptos estadísticos fundamentales principales que todo principiante en ciencia de datos debería conocer.

Tabla de contenidos.
1. Muestreo estadístico y recopilación de datos
Aprenderemos algunos conceptos estadísticos básicos, pero comprender de dónde provienen nuestros datos y cómo los recopilamos es esencial antes de sumergirnos profundamente en el océano de datos. Aquí es donde entran en juego las poblaciones, las muestras y diversas técnicas de muestreo.
Imaginemos que queremos saber la altura promedio de las personas en una ciudad. Es práctico medir a todos, por lo que tomamos un grupo más pequeño (muestra) que representa a la población más grande. El truco está en cómo seleccionamos esta muestra. Técnicas como el muestreo aleatorio, estratificado o por conglomerados garantizan que nuestra muestra esté bien representada, minimizando el sesgo y haciendo que nuestros hallazgos sean más confiables.
Al comprender las poblaciones y las muestras, podemos extender con confianza nuestros conocimientos de la muestra a toda la población, tomando decisiones informadas sin la necesidad de encuestar a todos.
2. Tipos de datos y escalas de medición
Los datos vienen en varios tipos, y conocer el tipo de datos con el que se está tratando es crucial para elegir las herramientas y técnicas estadísticas adecuadas.
Datos cuantitativos y cualitativos
- Datos cuantitativos: Este tipo de datos tiene que ver con números. Es mensurable y se puede utilizar para cálculos matemáticos. Los datos cuantitativos nos dicen “cuánto” o “cuántos”, como la cantidad de usuarios que visitan un sitio web o la temperatura en una ciudad. Es sencillo y objetivo y proporciona una imagen clara a través de valores numéricos.
- Datos cualitativos: Por el contrario, los datos cualitativos se ocupan de características y descripciones. Se trata de "qué tipo" o "qué categoría". Piense en ello como los datos que describen cualidades o atributos, como el color de un automóvil o el género de un libro. Estos datos son subjetivos y se basan en observaciones más que en mediciones.
Cuatro escalas de medida
- Escala nominal: Esta es la forma más simple de medición utilizada para categorizar datos sin un orden específico. Los ejemplos incluyen tipos de cocina, grupos sanguíneos o nacionalidad. Se trata de un etiquetado sin ningún valor cuantitativo.
- Escala ordinal: Los datos se pueden ordenar o clasificar aquí, pero los intervalos entre valores no están definidos. Piense en una encuesta de satisfacción con opciones como satisfecho, neutral e insatisfecho. Nos dice el orden pero no la distancia entre las clasificaciones.
- Escala de intervalo: Las escalas de intervalo ordenan los datos y cuantifican la diferencia entre las entradas. Sin embargo, no existe un punto cero real. Un buen ejemplo es la temperatura en grados Celsius; la diferencia entre 10°C y 20°C es la misma que entre 20°C y 30°C, pero 0°C no significa ausencia de temperatura.
- Escala de proporción: La escala más informativa tiene todas las propiedades de una escala de intervalo más un punto cero significativo, lo que permite una comparación precisa de magnitudes. Los ejemplos incluyen peso, altura e ingresos. Aquí podemos decir que algo vale el doble que otro.
3. Estadísticas descriptivas
Imagine estadísticas descriptivas como tu primera cita con tus datos. Se trata de conocer lo básico, las líneas generales que describen lo que tienes delante. La estadística descriptiva tiene dos tipos principales: medidas de tendencia central y de variabilidad.
Medidas de tendencia central: Son como el centro de gravedad de los datos. Nos dan un valor único típico o representativo de nuestro conjunto de datos.
Media: El promedio se calcula sumando todos los valores y dividiendo por el número de valores. Es como la calificación general de un restaurante basada en todas las reseñas. La fórmula matemática para el promedio se proporciona a continuación:

Mediana: El valor medio cuando los datos se ordenan de menor a mayor. Si el número de observaciones es par, es el promedio de los dos números del medio. Se utiliza para encontrar el punto medio de un puente.
Si n es par, la mediana es el promedio de los dos números centrales.
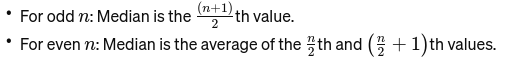
Modo: La altura de la cúpula es XNUMX metros, que es Valor que aparece con más frecuencia en un conjunto de datos. Piense en ello como el plato más popular en un restaurante.
Medidas de variabilidad: Mientras que las medidas de tendencia central nos llevan al centro, las medidas de variabilidad nos informan sobre la dispersión.
Rango: La diferencia entre los valores más altos y más bajos. Da una idea básica de la propagación.
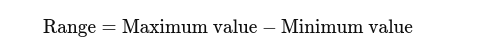
Diferencia: Mide qué tan lejos está cada número del conjunto de la media y, por tanto, de todos los demás números del conjunto. Para una muestra, se calcula como:
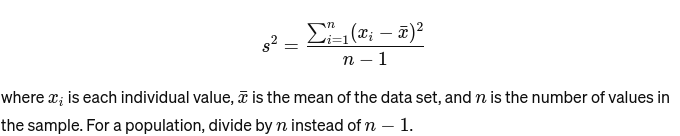
Desviación Estándar: La raíz cuadrada de la varianza proporciona una medida de la distancia promedio desde la media. Es como evaluar la consistencia del tamaño de un pastel de panadero. Se representa como:
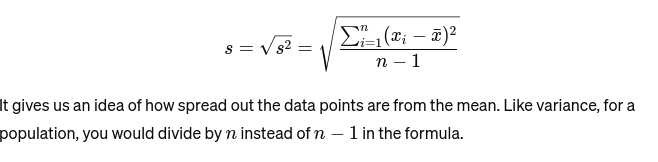
Antes de pasar al siguiente concepto estadístico básico, he aquí un Guía para principiantes de análisis estadístico para usted!
4. Visualización de datos
Visualización de datos es el arte y la ciencia de contar historias con datos. Convierte los resultados complejos de nuestro análisis en algo tangible y comprensible. Es crucial para el análisis exploratorio de datos, donde el objetivo es descubrir patrones, correlaciones y conocimientos a partir de los datos sin llegar aún a conclusiones formales.
- Cuadros y gráficos: Comenzando con lo básico, los gráficos de barras, los gráficos de líneas y los gráficos circulares brindan información fundamental sobre los datos. Son el ABC de la visualización de datos, esenciales para cualquier narrador de datos.
Tenemos un ejemplo de un gráfico de barras (izquierda) y un gráfico de líneas (derecha) a continuación.
- Visualizaciones avanzadas: A medida que profundizamos, los mapas de calor, los diagramas de dispersión y los histogramas permiten un análisis más matizado. Estas herramientas ayudan a identificar tendencias, distribuciones y valores atípicos.
A continuación se muestra un ejemplo de un diagrama de dispersión y un histograma.

Las visualizaciones unen los datos sin procesar y la cognición humana, lo que nos permite interpretar y dar sentido a conjuntos de datos complejos rápidamente.
5. Conceptos básicos de probabilidad
Probabilidad es la gramática del lenguaje de la estadística. Se trata de la posibilidad o probabilidad de que ocurran eventos. Comprender conceptos de probabilidad es esencial para interpretar resultados estadísticos y hacer predicciones.
- Eventos Independientes y Dependientes:
- Eventos independientes: El resultado de un evento no afecta el resultado de otro. Al igual que lanzar una moneda, obtener cara en un lanzamiento no cambia las probabilidades para el siguiente lanzamiento.
- Eventos dependientes: El resultado de un evento afecta el resultado de otro. Por ejemplo, si robas una carta de un mazo y no la reemplazas, tus posibilidades de sacar otra carta específica cambian.
La probabilidad proporciona la base para hacer inferencias sobre los datos y es fundamental para comprender la significación estadística y la prueba de hipótesis.
6. Distribuciones de probabilidad comunes
Distribuciones de probabilidad son como especies diferentes en el ecosistema estadístico, cada una adaptada a su nicho de aplicaciones.
- Distribución normal: A menudo llamada curva de campana debido a su forma, esta distribución se caracteriza por su media y desviación estándar. Es una suposición común en muchas pruebas estadísticas porque muchas variables se distribuyen naturalmente de esta manera en el mundo real.
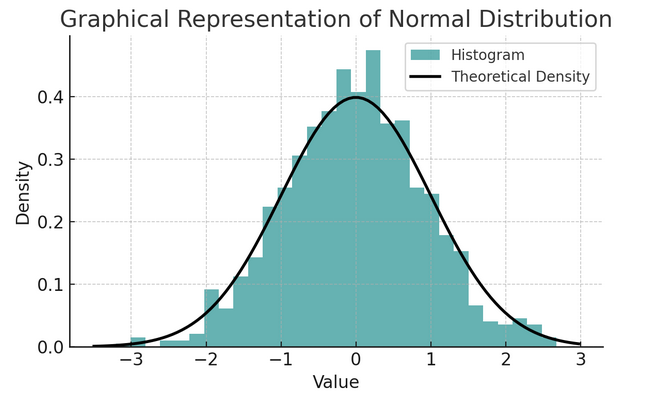
Un conjunto de reglas conocida como regla empírica o regla 68-95-99.7 resume las características de una distribución normal, que describe cómo se distribuyen los datos alrededor de la media.
Regla 68-95-99.7 (Regla empírica)
Esta regla se aplica a una distribución perfectamente normal y describe lo siguiente:
- 68% de los datos se encuentran dentro de una desviación estándar (σ) de la media (μ).
- 95% de los datos se encuentran dentro de dos desviaciones estándar de la media.
- Aproximadamente 99.7% de los datos se encuentran dentro de tres desviaciones estándar de la media.
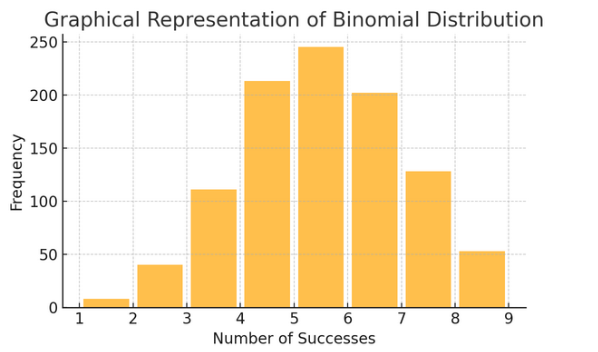
Distribución binomial: Esta distribución se aplica a situaciones con dos resultados (como el éxito o el fracaso) repetidos varias veces. Ayuda a modelar eventos como lanzar una moneda al aire o realizar una prueba de verdadero/falso.
Distribución de veneno cuenta el número de veces que algo sucede en un intervalo o espacio específico. Es ideal para situaciones en las que los eventos suceden de forma independiente y constante, como los correos electrónicos que recibe diariamente.
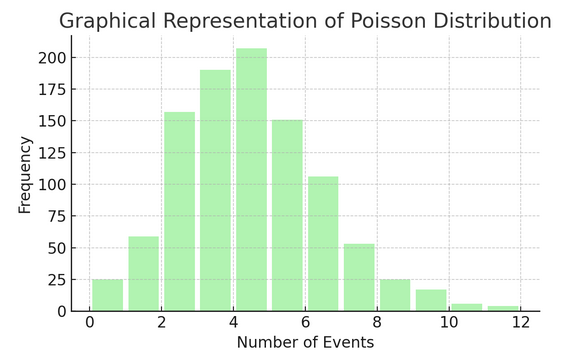
Cada distribución tiene su propio conjunto de fórmulas y características, y elegir la correcta depende de la naturaleza de sus datos y de lo que esté tratando de descubrir. Comprender estas distribuciones permite a los estadísticos y científicos de datos modelar fenómenos del mundo real y predecir eventos futuros con precisión.
7 . Evaluación de la hipótesis
Piensa en evaluación de la hipótesis como trabajo detectivesco en estadística. Es un método para probar si una teoría particular sobre nuestros datos podría ser cierta. Este proceso comienza con dos hipótesis opuestas:
- Hipótesis nula (H0): Ésta es la suposición predeterminada, que sugiere que hay un efecto o una diferencia. Dice: "No es nuevo aquí".
- Al “hipótesis alternativa (H1 o Ha): Esto desafía el status quo, proponiendo un efecto o una diferencia. Afirma: "Algo interesante está sucediendo".
Ejemplo: probar si un nuevo programa de dieta conduce a la pérdida de peso en comparación con no seguir ninguna dieta.
- Hipótesis nula (H0): El nuevo programa de dieta no conduce a la pérdida de peso (no hay diferencia en la pérdida de peso entre quienes siguen el nuevo programa de dieta y quienes no).
- Hipótesis alternativa (H1): El nuevo programa de dieta conduce a la pérdida de peso (una diferencia en la pérdida de peso entre quienes lo siguen y quienes no lo siguen).
La prueba de hipótesis implica elegir entre estos dos basándose en la evidencia (nuestros datos).
Error tipo I y II y niveles de significancia:
- Error tipo I: Esto sucede cuando rechazamos incorrectamente la hipótesis nula. Condena a una persona inocente.
- Error tipo II: Esto ocurre cuando no logramos rechazar una hipótesis nula falsa. Deja en libertad a un culpable.
- Nivel de significancia (α): Este es el umbral para decidir cuánta evidencia es suficiente para rechazar la hipótesis nula. A menudo se establece en el 5 % (0.05), lo que indica un riesgo del 5 % de cometer un error de tipo I.
8. Intervalos de confianza
Intervalos de confianza danos un rango de valores dentro del cual esperamos que el parámetro poblacional válido (como una media o proporción) caiga con un cierto nivel de confianza (comúnmente 95%). Es como predecir el resultado final de un equipo deportivo con un margen de error; estamos diciendo: "Tenemos un 95% de confianza en que la puntuación real estará dentro de este rango".
Construir e interpretar intervalos de confianza nos ayuda a comprender la precisión de nuestras estimaciones. Cuanto más amplio es el intervalo, nuestra estimación es menos precisa y viceversa.
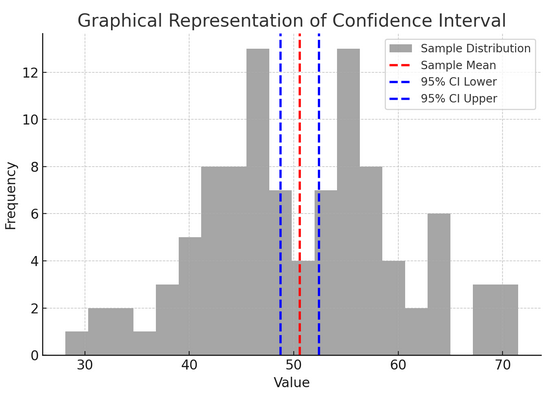
La figura anterior ilustra el concepto de intervalo de confianza (IC) en estadística, utilizando una distribución muestral y su intervalo de confianza del 95% alrededor de la media muestral.
Aquí hay un desglose de los componentes críticos en la figura:
- Distribución de muestra (histograma gris): Esto representa la distribución de 100 puntos de datos generados aleatoriamente a partir de una distribución normal con una media de 50 y una desviación estándar de 10. El histograma representa visualmente cómo se distribuyen los puntos de datos alrededor de la media.
- Media muestral (línea discontinua roja): Esta línea indica el valor medio (promedio) de los datos de la muestra. Sirve como estimación puntual alrededor de la cual construimos el intervalo de confianza. En este caso, representa el promedio de todos los valores de la muestra.
- Intervalo de confianza del 95% (líneas discontinuas azules): Estas dos líneas marcan los límites inferior y superior del intervalo de confianza del 95% alrededor de la media muestral. El intervalo se calcula utilizando el error estándar de la media (SEM) y una puntuación Z correspondiente al nivel de confianza deseado (1.96 para un 95 % de confianza). El intervalo de confianza sugiere que tenemos un 95% de confianza en que la media poblacional se encuentra dentro de este rango.
9. Correlación y causalidad
Correlación y causalidad A menudo se confunden, pero son diferentes:
- Correlación: Indica una relación o asociación entre dos variables. Cuando uno cambia, el otro tiende a cambiar también. La correlación se mide mediante un coeficiente de correlación que oscila entre -1 y 1. Un valor más cercano a 1 o -1 indica una relación fuerte, mientras que 0 sugiere que no hay vínculos.
- Causalidad: Implica que los cambios en una variable causan directamente cambios en otra. Es una afirmación más sólida que la correlación y requiere pruebas rigurosas.
El hecho de que dos variables estén correlacionadas no significa que una cause la otra. Éste es un caso clásico de no confundir “correlación” con “causalidad”.
10. Regresión lineal simple
sencillos regresión lineal es una forma de modelar la relación entre dos variables ajustando una ecuación lineal a los datos observados. Una variable se considera variable explicativa (independiente) y la otra es variable dependiente.
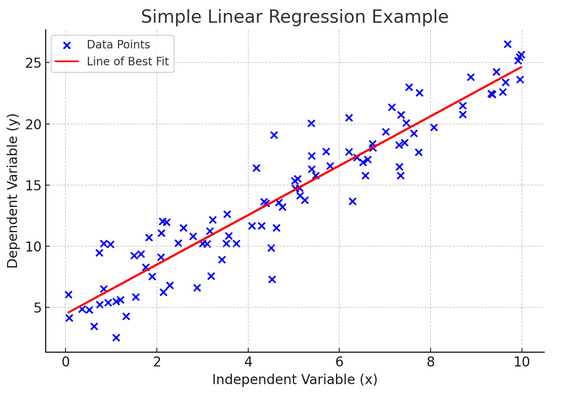
La regresión lineal simple nos ayuda a comprender cómo los cambios en la variable independiente afectan a la variable dependiente. Es una poderosa herramienta de predicción y es fundamental para muchos otros modelos estadísticos complejos. Al analizar la relación entre dos variables, podemos hacer predicciones informadas sobre cómo interactuarán.
La regresión lineal simple supone una relación lineal entre la variable independiente (variable explicativa) y la variable dependiente. Si la relación entre estas dos variables no es lineal, entonces se pueden violar los supuestos de la regresión lineal simple, lo que podría conducir a predicciones o interpretaciones inexactas. Por tanto, verificar una relación lineal en los datos es esencial antes de aplicar la regresión lineal simple.
11. Regresión lineal múltiple
Piense en la regresión lineal múltiple como una extensión de la regresión lineal simple. Aún así, en lugar de intentar predecir un resultado con un caballero de brillante armadura (predictor), tienes todo un equipo. Es como pasar de un juego de baloncesto individual a un esfuerzo de equipo completo, donde cada jugador (predictor) aporta habilidades únicas. La idea es ver cómo varias variables juntas influyen en un solo resultado.
Sin embargo, un equipo más grande conlleva el desafío de gestionar las relaciones, lo que se conoce como multicolinealidad. Ocurre cuando los predictores están demasiado cerca unos de otros y comparten información similar. Imagínese a dos jugadores de baloncesto intentando constantemente realizar el mismo tiro; pueden interponerse en el camino del otro. La regresión puede dificultar ver la contribución única de cada predictor, lo que potencialmente distorsiona nuestra comprensión de qué variables son significativas.
12. Regresión logística
Si bien la regresión lineal predice resultados continuos (como la temperatura o los precios), regresión logística se utiliza cuando el resultado es definitivo (como sí/no, ganar/perder). Imagínese intentar predecir si un equipo ganará o perderá en función de varios factores; La regresión logística es su estrategia preferida.
Transforma la ecuación lineal para que su resultado esté entre 0 y 1, lo que representa la probabilidad de pertenecer a una categoría particular. Es como tener una lente mágica que convierte puntuaciones continuas en una visión clara de "esto o aquello", lo que nos permite predecir resultados categóricos.
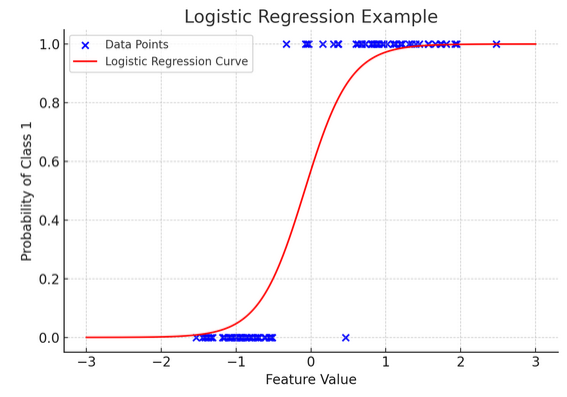
La representación gráfica ilustra un ejemplo de regresión logística aplicada a un conjunto de datos de clasificación binaria sintética. Los puntos azules representan los puntos de datos, y su posición a lo largo del eje x indica el valor de la característica y el eje y indica la categoría (0 o 1). La curva roja representa la predicción del modelo de regresión logística de la probabilidad de pertenecer a la clase 1 (por ejemplo, “ganar”) para diferentes valores de características. Como puede ver, la curva pasa suavemente de la probabilidad de clase 0 a la clase 1, lo que demuestra la capacidad del modelo para predecir resultados categóricos basados en una característica continua subyacente.
La fórmula de regresión logística viene dada por:

Esta fórmula utiliza la función logística para transformar la salida de la ecuación lineal en una probabilidad entre 0 y 1. Esta transformación nos permite interpretar las salidas como probabilidades de pertenecer a una categoría particular según el valor de la variable independiente xx.
13. Pruebas ANOVA y Chi-cuadrado
ANOVA (análisis de varianza) y Pruebas de chi cuadrado Son como detectives en el mundo de la estadística, ayudándonos a resolver diferentes misterios. It nos permite comparar medias entre múltiples grupos para ver si al menos uno es estadísticamente diferente. Piense en ello como probar muestras de varios lotes de galletas para determinar si algún lote tiene un sabor significativamente diferente.
Por otro lado, la prueba de Chi-Cuadrado se utiliza para datos categóricos. Nos ayuda a comprender si existe una asociación significativa entre dos variables categóricas. Por ejemplo, ¿existe una relación entre el género musical favorito de una persona y su grupo de edad? La prueba de Chi-Cuadrado ayuda a responder estas preguntas.
14. El teorema del límite central y su importancia en la ciencia de datos
El Teorema del límite central (CLT) Es un principio estadístico fundamental que parece casi mágico. Nos dice que si se toman suficientes muestras de una población y se calculan sus medias, esas medias formarán una distribución normal (la curva de campana), independientemente de la distribución original de la población. Esto es increíblemente poderoso porque nos permite hacer inferencias sobre poblaciones incluso cuando no conocemos su distribución exacta.
En la ciencia de datos, el CLT sustenta muchas técnicas, lo que nos permite utilizar herramientas diseñadas para datos distribuidos normalmente incluso cuando nuestros datos inicialmente no cumplen con esos criterios. Es como encontrar un adaptador universal para métodos estadísticos, haciendo que muchas herramientas poderosas sean aplicables en más situaciones.
15. Compensación entre sesgo y varianza
In modelado predictivo y máquina de aprendizaje, la compensación de sesgo-varianza Es un concepto crucial que resalta la tensión entre dos tipos principales de error que pueden hacer que nuestros modelos salgan mal. El sesgo se refiere a errores de modelos demasiado simplistas que no captan bien las tendencias subyacentes. Imagínese intentar trazar una línea recta a través de una carretera con curvas; perderás el blanco. Por el contrario, las variaciones de modelos demasiado complejos capturan el ruido en los datos como si fuera un patrón real, como rastrear cada giro y tomar un camino lleno de baches, pensando que es el camino a seguir.
El arte consiste en equilibrar estos dos para minimizar el error total, encontrar el punto ideal donde su modelo es perfecto: lo suficientemente complejo como para capturar los patrones precisos pero lo suficientemente simple como para ignorar el ruido aleatorio. Es como afinar una guitarra; no sonará bien si está demasiado apretado o suelto. El equilibrio entre sesgo y varianza Se trata de encontrar el equilibrio perfecto entre estos dos. La compensación sesgo-varianza es la esencia del ajuste de nuestros modelos estadísticos para que funcionen al máximo en la predicción de resultados con precisión.
Conclusión
Desde el muestreo estadístico hasta el equilibrio entre sesgo y varianza, estos principios no son meras nociones académicas sino herramientas esenciales para un análisis de datos profundo. Dotan a los aspirantes a científicos de datos con las habilidades para convertir una gran cantidad de datos en conocimientos prácticos, haciendo hincapié en las estadísticas como la columna vertebral de la innovación y la toma de decisiones basadas en datos en la era digital.
¿Se nos ha escapado algún concepto básico de estadística? Háganos saber en la sección de comentarios a continuación.
Explora nuestra solución guía de estadísticas de principio a fin ¡Para que la ciencia de datos conozca el tema!
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

