Imagen de Freepik
Los modelos de lenguaje han revolucionado el campo del procesamiento del lenguaje natural. Si bien los modelos grandes como GPT-3 han acaparado los titulares, los modelos de lenguaje pequeño también son ventajosos y accesibles para diversas aplicaciones. En este artículo, exploraremos en detalle la importancia y los casos de uso de los modelos de lenguaje pequeño con todos los pasos de implementación.
Los modelos de lenguaje pequeño son versiones compactas de sus homólogos más grandes. Ofrecen varias ventajas. Algunas de las ventajas son las siguientes:
- Eficiencia: En comparación con los modelos grandes, los modelos pequeños requieren menos potencia computacional, lo que los hace adecuados para entornos con recursos limitados.
- Velocidad: Pueden hacer el cálculo más rápido, como generar los textos basados en una entrada dada más rápidamente, lo que los hace ideales para aplicaciones en tiempo real donde se puede tener un alto tráfico diario.
- Personalización: Puede ajustar modelos pequeños según sus requisitos para tareas específicas de dominio.
- Privacidad: Los modelos más pequeños se pueden utilizar sin servidores externos, lo que garantiza la privacidad e integridad de los datos.
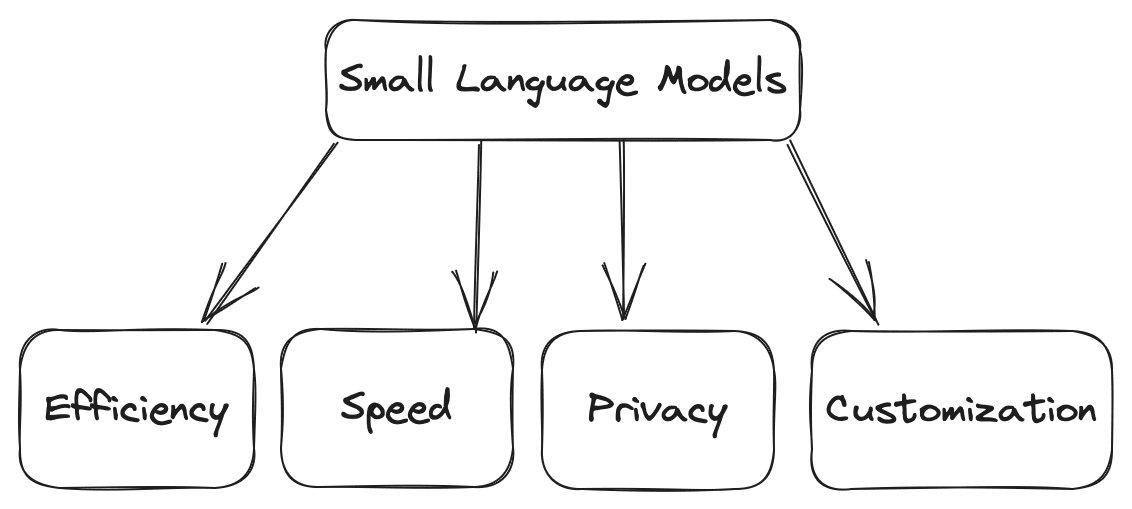
Imagen del autor
Varios casos de uso para modelos de lenguaje pequeños incluyen chatbots, generación de contenido, análisis de sentimientos, respuesta a preguntas y muchos más.
Antes de comenzar a profundizar en el funcionamiento de modelos de lenguajes pequeños, debe configurar su entorno, lo que implica instalar las bibliotecas y dependencias necesarias. Seleccionar los marcos y bibliotecas adecuados para crear un modelo de lenguaje en su CPU local se vuelve crucial. Las opciones populares incluyen bibliotecas basadas en Python como TensorFlow y PyTorch. Estos marcos proporcionan muchas herramientas y recursos prediseñados para el aprendizaje automático y aplicaciones basadas en aprendizaje profundo.
Instalación de bibliotecas necesarias
En este paso, instalaremos la biblioteca “llama-cpp-python” y ctransformers para presentarle pequeños modelos de lenguaje. Debes abrir tu terminal y ejecutar los siguientes comandos para instalarlo. Mientras ejecuta los siguientes comandos, asegúrese de tener Python y pip instalados en su sistema.
pip install llama-cpp-python
pip install ctransformers -q
Salida:

Ahora que nuestro entorno está listo, podemos obtener un modelo de lenguaje pequeño previamente entrenado para uso local. Para un modelo de lenguaje pequeño, podemos considerar arquitecturas más simples como LSTM o GRU, que son computacionalmente menos intensivas que modelos más complejos como los transformadores. También puede utilizar incrustaciones de palabras previamente entrenadas para mejorar el rendimiento de su modelo y al mismo tiempo reducir el tiempo de entrenamiento. Pero para trabajar rápidamente, descargaremos un modelo previamente entrenado de la web.
Descarga de un modelo previamente entrenado
Puede encontrar modelos de lenguaje pequeño previamente entrenados en plataformas como Hugging Face (https://huggingface.co/models). A continuación se ofrece un recorrido rápido por el sitio web, donde puede observar fácilmente las secuencias de modelos proporcionados, que puede descargar fácilmente iniciando sesión en la aplicación, ya que son de código abierto.
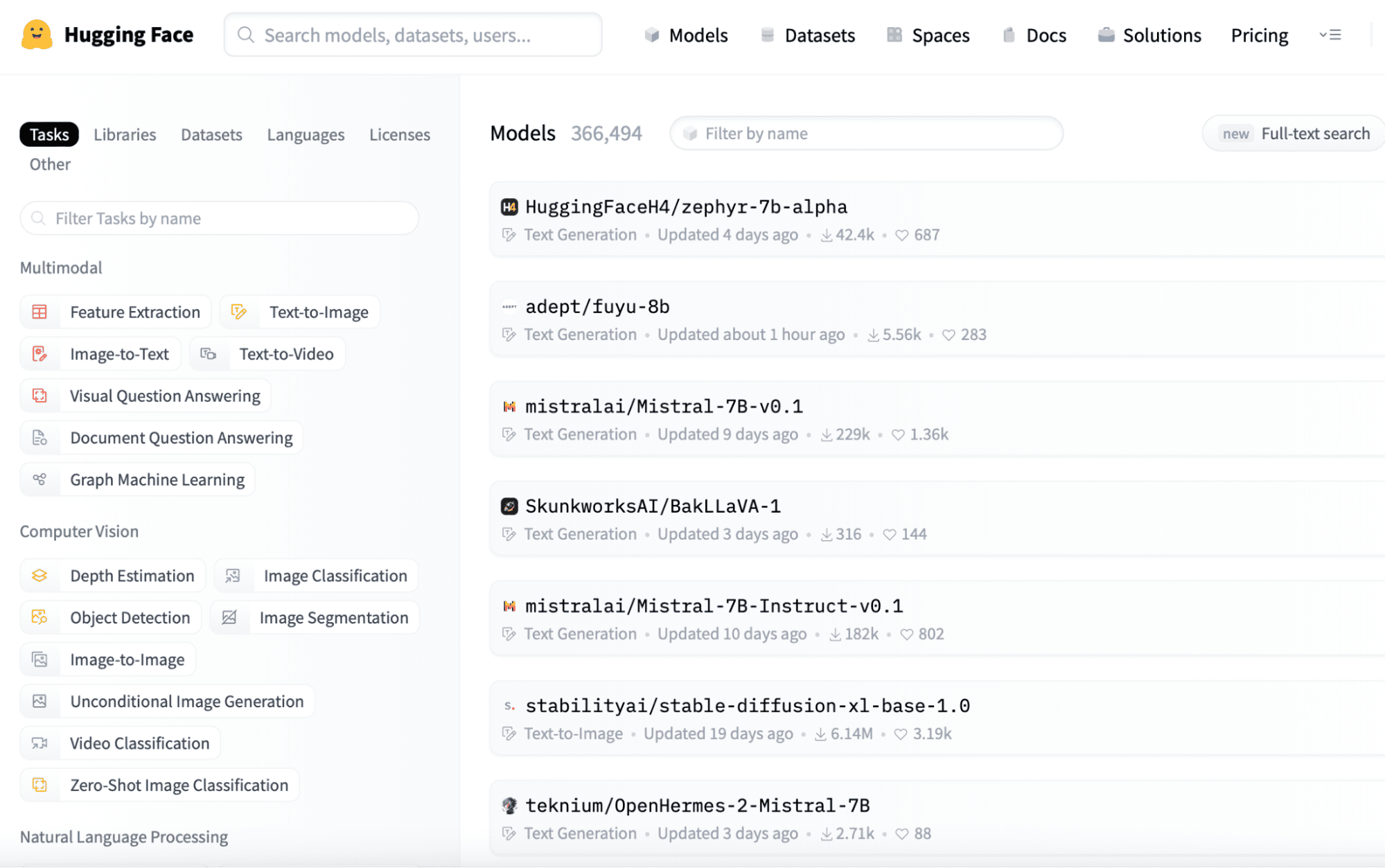
Puede descargar fácilmente el modelo que necesita desde este enlace y guardarlo en su directorio local para su uso posterior.
from ctransformers import AutoModelForCausalLMEn el paso anterior, hemos finalizado el modelo previamente entrenado de Hugging Face. Ahora podemos usar ese modelo cargándolo en nuestro entorno. Importamos la clase AutoModelForCausalLM de la biblioteca ctransformers en el siguiente código. Esta clase se puede utilizar para cargar y trabajar con modelos para el modelado de lenguaje causal.
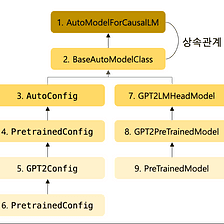
Imagen de Medio
# Load the pretrained model
llm = AutoModelForCausalLM.from_pretrained('TheBloke/Llama-2-7B-Chat-GGML', model_file = 'llama-2-7b-chat.ggmlv3.q4_K_S.bin' )
Salida:

Los modelos de lenguaje pequeños se pueden ajustar según sus necesidades específicas. Si tiene que utilizar estos modelos en aplicaciones de la vida real, lo principal que debe recordar es la eficiencia y la escalabilidad. Por lo tanto, para que los modelos de lenguaje pequeños sean eficientes en comparación con los modelos de lenguaje grandes, puede ajustar el tamaño del contexto y el procesamiento por lotes (particionar datos en lotes más pequeños para un cálculo más rápido), lo que también permite superar el problema de escalabilidad.
Modificar el tamaño del contexto
El tamaño del contexto determina cuánto texto considera el modelo. Según sus necesidades, puede elegir el valor del tamaño del contexto. En este ejemplo, estableceremos el valor de este hiperparámetro en 128 tokens.
model.set_context_size(128)Procesamiento por lotes para mayor eficiencia
Al introducir la técnica de procesamiento por lotes, es posible procesar múltiples segmentos de datos simultáneamente, lo que puede manejar las consultas en paralelo y ayudar a escalar la aplicación para un gran conjunto de usuarios. Pero al decidir el tamaño del lote, debe verificar cuidadosamente las capacidades de su sistema. De lo contrario, su sistema puede causar problemas debido a una carga pesada.
model.set_batch_size(16)Hasta este paso, hemos terminado de crear el modelo, ajustarlo y guardarlo. Ahora podemos probarlo rápidamente según nuestro uso y comprobar si proporciona el mismo resultado que esperamos. Entonces, proporcionemos algunas consultas de entrada y generemos el texto según nuestro modelo cargado y configurado.
for word in llm('Explain something about Kdnuggets', stream = True): print(word, end='')
Salida:

Para obtener los resultados adecuados para la mayoría de las consultas de entrada de su modelo de lenguaje pequeño, se pueden considerar las siguientes cosas.
- Sintonia FINA: Si su aplicación exige un alto rendimiento, es decir, que el resultado de las consultas se resuelva en mucho menos tiempo, entonces debe ajustar su modelo en su conjunto de datos específico, el corpus en el que está entrenando su modelo.
- Almacenamiento en caché: Al utilizar la técnica de almacenamiento en caché, puede almacenar datos de uso común según el usuario en la RAM, de modo que cuando el usuario vuelva a solicitar esos datos, se puedan proporcionar fácilmente en lugar de recuperarlos del disco, lo que requiere relativamente más tiempo, debido a lo cual puede generar resultados para acelerar solicitudes futuras.
- Problemas comunes: Si tiene problemas al crear, cargar y configurar el modelo, puede consultar la documentación y la comunidad de usuarios para obtener sugerencias para la solución de problemas.
En este artículo, analizamos cómo puede crear e implementar un modelo de lenguaje pequeño en su CPU local siguiendo los siete sencillos pasos descritos en este artículo. Este enfoque rentable abre la puerta a diversas aplicaciones de procesamiento de lenguaje o visión por computadora y sirve como trampolín para proyectos más avanzados. Pero mientras trabajas en proyectos, debes recordar lo siguiente para superar cualquier problema:
- Guarde periódicamente puntos de control durante el entrenamiento para asegurarse de que pueda continuar entrenando o recuperar su modelo en caso de interrupciones.
- Optimice su código y canales de datos para un uso eficiente de la memoria, especialmente cuando trabaja en una CPU local.
- Considere utilizar aceleración de GPU o recursos basados en la nube si necesita ampliar su modelo en el futuro.
En conclusión, los modelos de lenguaje pequeño ofrecen una solución versátil y eficiente para diversas tareas de procesamiento del lenguaje. Con la configuración y optimización correctas, puedes aprovechar su poder de manera efectiva.
Garg ario es un B.Tech. Estudiante de Ingeniería Eléctrica, actualmente en el último año de la carrera. Su interés radica en el campo del Desarrollo Web y el Aprendizaje Automático. Ha perseguido este interés y estoy ansioso por trabajar más en estas direcciones.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/7-steps-to-running-a-small-language-model-on-a-local-cpu?utm_source=rss&utm_medium=rss&utm_campaign=7-steps-to-running-a-small-language-model-on-a-local-cpu

