Al ejecutar aplicaciones Apache Flink en Servicio administrado de Amazon para Apache Flink, tiene el beneficio único de aprovechar su naturaleza sin servidor. Esto significa que los ejercicios de optimización de costos pueden realizarse en cualquier momento; ya no es necesario que se realicen en la fase de planificación. Con Managed Service para Apache Flink, puede agregar y eliminar computación con solo hacer clic en un botón.
Apache Flink es un marco de procesamiento de flujos de código abierto utilizado por cientos de empresas en aplicaciones comerciales críticas y por miles de desarrolladores que tienen necesidades de procesamiento de flujos para sus cargas de trabajo. Es altamente disponible y escalable, y ofrece alto rendimiento y baja latencia para las aplicaciones de procesamiento de flujo más exigentes. Estas propiedades escalables de Apache Flink pueden ser clave para optimizar sus costos en la nube.
El servicio administrado para Apache Flink es un servicio completamente administrado que reduce la complejidad de crear y administrar aplicaciones Apache Flink. El servicio administrado para Apache Flink administra la infraestructura subyacente y los componentes de Apache Flink que brindan un estado duradero de las aplicaciones, métricas, registros y más.
En esta publicación, puede obtener información sobre el modelo de costos del servicio administrado para Apache Flink, áreas para ahorrar costos en sus aplicaciones Apache Flink y, en general, obtener una mejor comprensión de sus procesos de procesamiento de datos. Profundizamos en la comprensión de sus costos, entendiendo si su aplicación está sobreaprovisionada, cómo pensar en escalar automáticamente y formas de optimizar sus aplicaciones Apache Flink para ahorrar costos. Por último, hacemos preguntas importantes sobre su carga de trabajo para determinar si Apache Flink es la tecnología adecuada para su caso de uso.
Cómo se calculan los costos en el servicio administrado para Apache Flink
Para optimizar los costos con respecto a su servicio administrado para la aplicación Apache Flink, puede ser útil tener una buena idea de lo que implica el precio del servicio administrado.
El servicio administrado para aplicaciones Apache Flink se compone de unidades de procesamiento Kinesis (KPU), que son instancias informáticas compuestas por 1 CPU virtual y 4 GB de memoria. El número total de KPU asignadas a la aplicación se determina multiplicando dos parámetros que usted controla directamente:
- Paralelismo – El nivel de procesamiento paralelo en la aplicación Apache Flink
- Paralelismo según KPU – El número de recursos dedicados a cada paralelismo.
El número de KPU se determina mediante la fórmula simple: KPU = Paralelismo / ParalelismoPorKPU, redondeado al siguiente entero.
También se cobra una KPU adicional por aplicación para la orquestación y no se utiliza directamente para el procesamiento de datos.
La cantidad total de KPU determina la cantidad de recursos, CPU, memoria y almacenamiento de aplicaciones asignados a la aplicación. Para cada KPU, la aplicación recibe 1 vCPU y 4 GB de memoria, de los cuales 3 GB se asignan de forma predeterminada a la aplicación en ejecución y el 1 GB restante se utiliza para la administración del almacén de estado de la aplicación. Cada KPU también viene con 50 GB de almacenamiento adjunto a la aplicación. Apache Flink retiene el estado de la aplicación en la memoria hasta un límite configurable y se extiende al almacenamiento adjunto.
El tercer componente del costo son las copias de seguridad duraderas de las aplicaciones, o instantáneas. Esto es completamente opcional y su impacto en el costo total es pequeño, a menos que conserve una gran cantidad de instantáneas.
Al momento de escribir este artículo, cada KPU en la región de AWS Este de EE. UU. (Ohio) cuesta $0.11 por hora y el almacenamiento de aplicaciones adjuntas cuesta $0.10 por GB por mes. El costo de la copia de seguridad duradera de la aplicación (instantáneas) es de $0.023 por GB al mes. Referirse a Precios del servicio administrado de Amazon para Apache Flink para precios actualizados y diferentes regiones.
El siguiente diagrama ilustra las proporciones relativas de los componentes de costo de una aplicación en ejecución en Managed Service para Apache Flink. Usted controla la cantidad de KPU a través del paralelismo y el paralelismo por parámetros de KPU. El almacenamiento duradero de copia de seguridad de aplicaciones no está representado.
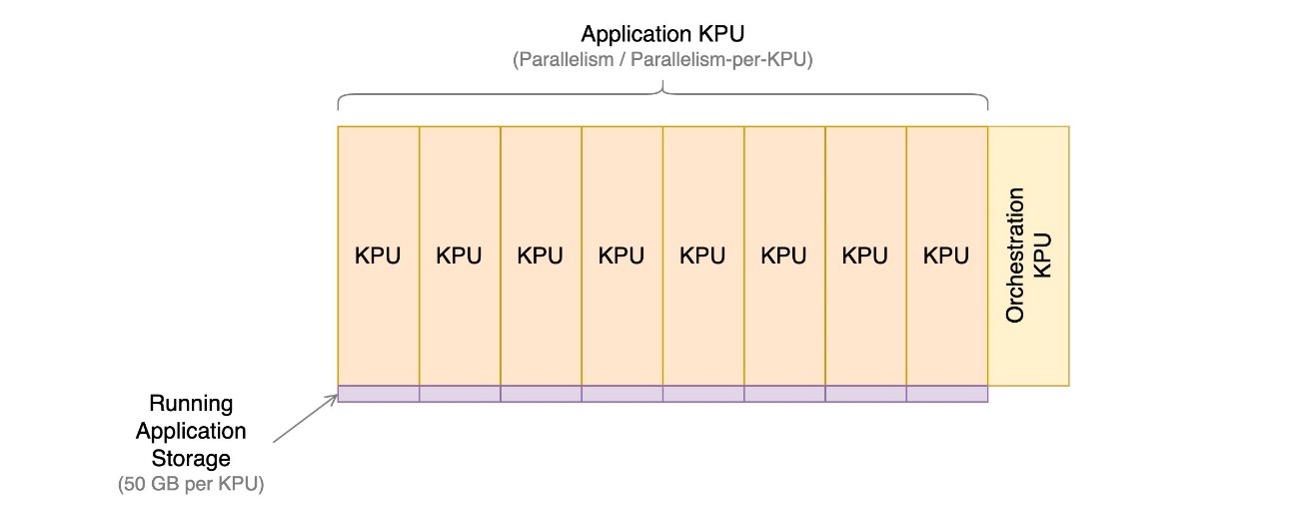
En las siguientes secciones, examinamos cómo monitorear sus costos, optimizar el uso de los recursos de la aplicación y encontrar la cantidad necesaria de KPU para manejar su perfil de rendimiento.
AWS Cost Explorer y cómo entender su factura
Para ver cuál es su gasto actual en Servicio Administrado para Apache Flink, puede usar Explorador de costos de AWS.
En la consola de Cost Explorer, puede filtrar por rango de fechas, tipo de uso y servicio para aislar su gasto en servicio administrado para aplicaciones Apache Flink. La siguiente captura de pantalla muestra los costos de los últimos 12 meses desglosados en las categorías de precios descritas en la sección anterior. La mayor parte del gasto en muchos de estos meses provino de KPU interactivas de Servicio administrado de Amazon para Apache Flink Studio.
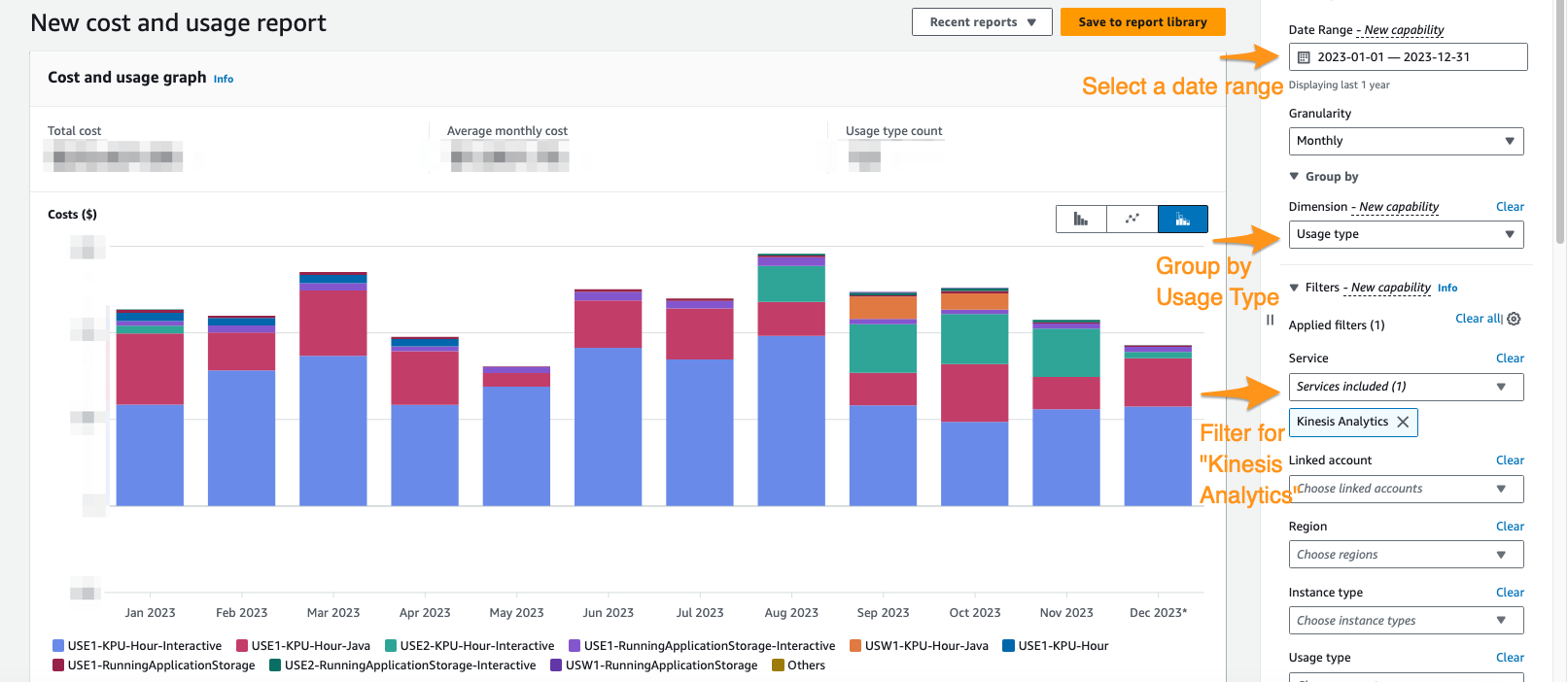
El uso de Cost Explorer no solo puede ayudarlo a comprender su factura, sino también a optimizar aún más aplicaciones particulares que pueden haber escalado más allá de las expectativas automáticamente o debido a requisitos de rendimiento. Con el etiquetado adecuado de las aplicaciones, también puede desglosar este gasto por aplicación para ver qué aplicaciones representan el costo.
Señales de sobreaprovisionamiento o uso ineficiente de los recursos
Para minimizar los costos asociados con el servicio administrado para aplicaciones Apache Flink, un enfoque sencillo implica reducir la cantidad de KPU que utilizan sus aplicaciones. Sin embargo, es fundamental reconocer que esta reducción podría afectar negativamente al rendimiento si no se evalúa y prueba minuciosamente. Para evaluar rápidamente si sus aplicaciones podrían estar sobreaprovisionadas, examine indicadores clave como el uso de CPU y memoria, la funcionalidad de la aplicación y la distribución de datos. Sin embargo, aunque estos indicadores pueden sugerir un posible aprovisionamiento excesivo, es esencial realizar pruebas de rendimiento y validar sus patrones de escalamiento antes de realizar ajustes en la cantidad de KPU.
Métrica
Analizando métricas para su aplicación on Reloj en la nube de Amazon puede revelar señales claras de sobreaprovisionamiento. Si el containerCPUUtilization y containerMemoryUtilization Si las métricas permanecen constantemente por debajo del 20% durante un período estadísticamente significativo para los patrones de tráfico de su aplicación, podría ser viable reducir la escala y asignar más datos a menos máquinas. Generalmente, consideramos que las aplicaciones tienen el tamaño adecuado cuando containerCPUUtilization oscila entre el 50% y el 75%. A pesar de containerMemoryUtilization puede fluctuar a lo largo del día y verse influenciado por la optimización del código, un valor constantemente bajo durante un período sustancial podría indicar un posible aprovisionamiento excesivo.
Paralelismo por KPU subutilizado
Otra señal sutil de que su aplicación está sobreaprovisionada es si su aplicación está exclusivamente vinculada a E/S o solo realiza llamadas simples a bases de datos y operaciones que no requieren un uso intensivo de la CPU. Si este es el caso, puede usar el paralelismo por parámetro KPU dentro del Servicio administrado para Apache Flink para cargar más tareas en una sola unidad de procesamiento.
Puede ver el paralelismo por parámetro KPU como una medida de densidad de carga de trabajo por unidad de recursos informáticos y de memoria (la KPU). Aumentar el paralelismo por KPU por encima del valor predeterminado de 1 hace que el procesamiento sea más denso, asignando más procesos paralelos en una sola KPU.
El siguiente diagrama ilustra cómo, al mantener constante el paralelismo de la aplicación (por ejemplo, 4) y aumentar el paralelismo por KPU (por ejemplo, de 1 a 2), su aplicación utiliza menos recursos con el mismo nivel de ejecuciones en paralelo.
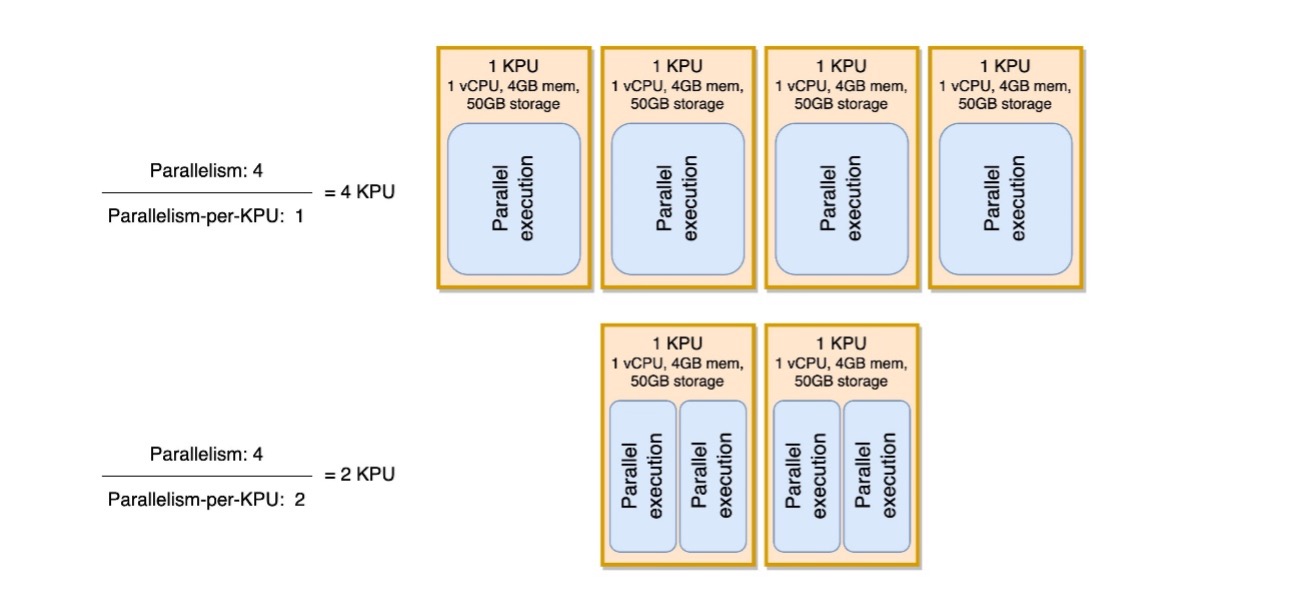
La decisión de aumentar el paralelismo por KPU, como todas las recomendaciones de esta publicación, debe tomarse con mucho cuidado. Aumentar el paralelismo por valor de KPU puede generar más carga en una sola KPU y debe estar dispuesta a tolerar esa carga. Las operaciones vinculadas a E/S no aumentarán la utilización de la CPU o la memoria de ninguna manera significativa, pero una función de proceso que calcula muchas operaciones complejas con los datos no sería una operación ideal para cotejar en una sola KPU, porque podría abrumar los recursos. Pruebe el rendimiento y evalúe si esta es una buena opción para sus aplicaciones.
Cómo abordar el tamaño
Antes de implementar un servicio administrado para la aplicación Apache Flink, puede resultar difícil estimar la cantidad de KPU que debe asignar para su aplicación. En general, debes tener una buena idea de tus patrones de tráfico antes de realizar una estimación. Comprender sus patrones de tráfico en función de la tasa de ingesta de megabytes por segundo puede ayudarle a aproximarse a un punto de partida.
Como regla general, puede comenzar con una KPU por cada 1 MB/s que procesará su aplicación. Por ejemplo, si su aplicación procesa 10 MB/s (en promedio), asignaría 10 KPU como punto de partida para su aplicación. Tenga en cuenta que se trata de una aproximación de muy alto nivel que hemos considerado eficaz para una estimación general. Sin embargo, también es necesario realizar pruebas de rendimiento y evaluar si se trata de un tamaño adecuado a largo plazo en función de métricas (CPU, memoria, latencia, rendimiento laboral general) durante un largo período de tiempo.
Para encontrar el tamaño adecuado para su aplicación, debe ampliar y reducir la aplicación Apache Flink. Como se mencionó, en Managed Service para Apache Flink tiene dos controles separados: paralelismo y paralelismo por KPU. Juntos, estos parámetros determinan el nivel de procesamiento paralelo dentro de la aplicación y los recursos generales de computación, memoria y almacenamiento disponibles.
La metodología de prueba recomendada es cambiar el paralelismo o el paralelismo por KPU por separado, mientras se experimenta para encontrar el tamaño correcto. En general, solo cambie el paralelismo por KPU para aumentar el número de operaciones paralelas vinculadas a E/S, sin aumentar los recursos generales. Para todos los demás casos, cambie únicamente el paralelismo (KPU cambiará en consecuencia) para encontrar el tamaño adecuado para su carga de trabajo.
También puede establecer paralelismo a nivel de operador para restringir fuentes, sumideros o cualquier otro operador que pueda necesitar ser restringido e independiente de los mecanismos de escalamiento. Puede usar esto para una aplicación Apache Flink que lea un tema de Apache Kafka que tenga 10 particiones. Con el setParallelism() método, puede restringir KafkaSource a 10, pero escalar la aplicación Servicio administrado para Apache Flink a un paralelismo superior a 10 sin crear tareas inactivas para la fuente de Kafka. Se recomienda para otros casos de procesamiento de datos no establecer estáticamente el paralelismo del operador en un valor estático, sino más bien una función del paralelismo de la aplicación para que escale cuando la aplicación general escale.
Escalado y escalado automático
En Managed Service para Apache Flink, modificar el paralelismo o el paralelismo por KPU es una actualización de la configuración de la aplicación. Hace que la aplicación tome automáticamente un instantánea (a menos que esté deshabilitado), detenga la aplicación y reiníciela con el nuevo tamaño, restaurando el estado de la instantánea. Las operaciones de escalado no causan pérdida de datos ni inconsistencias, pero pausan el procesamiento de datos por un corto período de tiempo mientras se agrega o elimina infraestructura. Esto es algo que debe tener en cuenta al reescalar en un entorno de producción.
Durante el proceso de prueba y optimización, recomendamos desactivar escalado automático y modificar el paralelismo y el paralelismo por KPU para encontrar los valores óptimos. Como se mencionó, el escalado manual es solo una actualización de la configuración de la aplicación y se puede ejecutar a través del Consola de administración de AWS o API con el Acción Actualizar aplicación.
Cuando haya encontrado el tamaño óptimo, si espera que el rendimiento ingerido varíe considerablemente, puede decidir habilitar el escalado automático.
En Managed Service para Apache Flink, puede utilizar varios tipos de escalado automático:
- Escalado automático listo para usar – Puede habilitar esto para ajustar el paralelismo de la aplicación automáticamente según el
containerCPUUtilizationmétrico. El escalado automático está habilitado de forma predeterminada en aplicaciones nuevas. Para obtener detalles sobre el algoritmo de escalado automático, consulte Escalado automático. - Escalado automático detallado basado en métricas – Esto es sencillo de implementar. La automatización puede basarse en prácticamente cualquier métrica, incluida métricas personalizadas su aplicación expone.
- Escalado programado – Esto puede resultar útil si espera picos de carga de trabajo en determinados momentos del día o días de la semana.
El escalado automático listo para usar y el escalado detallado basado en métricas se excluyen mutuamente. Para obtener más detalles sobre el escalado automático basado en métricas detalladas y el escalado programado, y un ejemplo de código completamente funcional, consulte Habilite el escalado programado y basado en métricas para Amazon Managed Service para Apache Flink.
Optimizaciones de código
Otra forma de abordar el ahorro de costos para su servicio administrado para aplicaciones Apache Flink es mediante la optimización del código. El código no optimizado requerirá más máquinas para realizar los mismos cálculos. La optimización del código podría permitir una menor utilización general de recursos, lo que a su vez podría permitir la reducción y el ahorro de costos en consecuencia.
El primer paso para comprender el rendimiento de su código es a través de la utilidad integrada en Apache Flink llamada Gráficos de llamas.
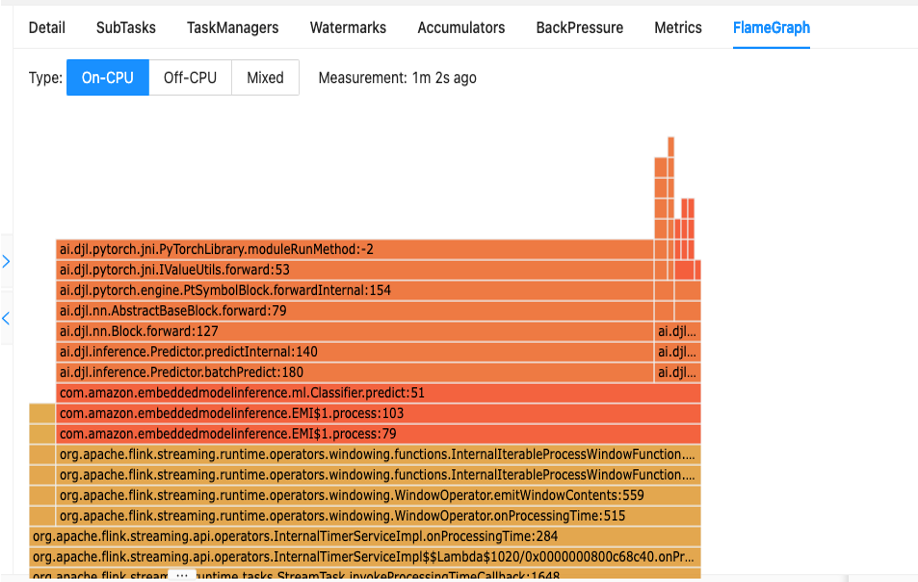
Flame Graphs, a los que se puede acceder a través del panel de Apache Flink, le brindan una representación visual del seguimiento de su pila. Cada vez que se llama a un método, la barra que representa esa llamada al método en el seguimiento de la pila aumenta proporcionalmente al recuento total de muestras. Esto significa que si tiene un fragmento de código ineficiente con una barra muy larga en el gráfico de llama, esto podría ser motivo de investigación sobre cómo hacer que este código sea más eficiente. Además, puedes utilizar Generador de perfiles de Amazon CodeGuru a supervise y optimice sus aplicaciones Apache Flink que se ejecutan en el servicio administrado para Apache Flink.
Al diseñar sus aplicaciones, se recomienda utilizar la API de nivel más alto que se requiere para una operación particular en un momento dado. Apache Flink ofrece cuatro niveles de soporte API: Flink SQL, Table API, Datastream API y ProcessFunction API, con niveles crecientes de complejidad y responsabilidad. Si su aplicación se puede escribir completamente en Flink SQL o Table API, usar esto puede ayudar a aprovechar el marco Apache Flink en lugar de administrar el estado y los cálculos manualmente.
sesgo de datos
En el panel de Apache Flink, puede recopilar otra información útil sobre sus trabajos de Servicio administrado para Apache Flink.
En el panel, puede inspeccionar tareas individuales dentro del gráfico de su solicitud de empleo. Cada cuadro azul representa una tarea y cada tarea se compone de subtareas o unidades de trabajo distribuidas para esa tarea. Puede identificar datos sesgados entre subtareas de esta manera.
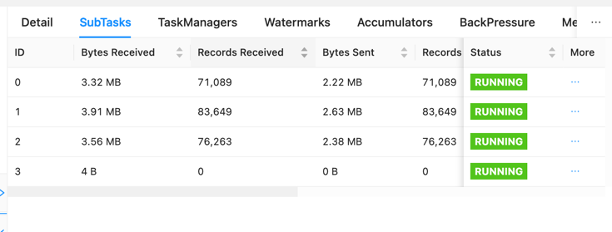
La distorsión de datos es un indicador de que se envían más datos a una subtarea que a otra, y que una subtarea que recibe más datos está haciendo más trabajo que la otra. Si tiene síntomas de sesgo de datos, puede trabajar para eliminarlos identificando la fuente. Por ejemplo, un GroupBy or KeyedStream podría tener un sesgo en la clave. Esto significaría que los datos no se distribuyen uniformemente entre las claves, lo que resultaría en una distribución desigual del trabajo entre las instancias informáticas de Apache Flink. Imagine un escenario en el que está agrupando por userId, pero su aplicación recibe datos de un usuario significativamente más que el resto. Esto puede resultar en datos sesgados. Para eliminar esto, puede elegir una clave de agrupación diferente para distribuir uniformemente los datos entre las subtareas. Tenga en cuenta que esto requerirá una modificación del código para elegir una clave diferente.
Cuando se elimina la distorsión de datos, puede volver a la containerCPUUtilization y containerMemoryUtilization métricas para reducir el número de KPU.
Otras áreas para la optimización del código incluyen asegurarse de acceder a sistemas externos a través del API de E/S asíncrona o mediante una unión a un flujo de datos, porque una consulta sincrónica a un almacén de datos puede crear ralentizaciones y problemas en los puntos de control. Además, consulte Solución de problemas de rendimiento para problemas que pueda experimentar con puntos de control o registros lentos, que pueden causar contrapresión en la aplicación.
Cómo determinar si Apache Flink es la tecnología adecuada
Si su aplicación no utiliza ninguna de las poderosas capacidades detrás del marco Apache Flink y el servicio administrado para Apache Flink, podría ahorrar costos usando algo más simple.
El lema de Apache Flink es "Computaciones con estado sobre flujos de datos". Con estado, en este contexto, significa que está utilizando la construcción de estado de Apache Flink. State, en Apache Flink, le permite recordar mensajes que ha visto en el pasado durante períodos de tiempo más largos, lo que hace posible cosas como uniones de transmisión, deduplicación, procesamiento exactamente una vez, ventanas y manejo de datos tardíos. Lo hace mediante el uso de un almacén de estado en memoria. En el servicio administrado para Apache Flink, utiliza RocksDB para mantener su estado.
Si su aplicación no implica operaciones con estado, puede considerar alternativas como AWS Lambda, aplicaciones en contenedores o un Nube informática elástica de Amazon (Amazon EC2) instancia que ejecuta su aplicación. Es posible que la complejidad de Apache Flink no sea necesaria en tales casos. Los cálculos con estado, incluidos los datos almacenados en caché o los procedimientos de enriquecimiento que requieren una memoria de posición de flujo independiente, pueden garantizar las capacidades con estado de Apache Flink. Si existe la posibilidad de que su aplicación tenga estado en el futuro, ya sea a través de una retención prolongada de datos u otros requisitos de estado, continuar usando Apache Flink podría ser más sencillo. Las organizaciones que enfatizan Apache Flink para las capacidades de procesamiento de transmisiones pueden preferir seguir con Apache Flink para aplicaciones con y sin estado, de modo que todas sus aplicaciones procesen datos de la misma manera. También debe tener en cuenta sus características de orquestación, como el procesamiento exactamente una vez, las capacidades de distribución y el cálculo distribuido antes de realizar la transición de Apache Flink a alternativas.
Otra consideración son sus requisitos de latencia. Debido a que Apache Flink sobresale en el procesamiento de datos en tiempo real, no tiene sentido usarlo para una aplicación con un requisito de latencia de 6 horas o 1 día. El ahorro de costos al cambiar a un proceso por lotes temporal fuera de Servicio de almacenamiento simple de Amazon (Amazon S3), por ejemplo, sería significativo.
Conclusión
En esta publicación, cubrimos algunos aspectos a considerar al intentar medidas de ahorro de costos para el servicio administrado para Apache Flink. Discutimos cómo identificar su gasto general en el servicio administrado, algunas métricas útiles para monitorear al reducir sus KPU, cómo optimizar su código para reducir y cómo determinar si Apache Flink es adecuado para su caso de uso.
La implementación de estas estrategias de ahorro de costos no solo mejora la rentabilidad, sino que también proporciona una implementación de Apache Flink simplificada y bien optimizada. Si es consciente de su gasto general, utiliza métricas clave y toma decisiones informadas sobre la reducción de recursos, puede lograr una operación rentable sin comprometer el rendimiento. A medida que navega por el panorama de Apache Flink, evaluar constantemente si se alinea con su caso de uso específico se vuelve fundamental, para que pueda lograr una solución personalizada y eficiente para sus necesidades de procesamiento de datos.
Si alguna de las recomendaciones analizadas en esta publicación se adapta a sus cargas de trabajo, le recomendamos que las pruebe. Con las métricas especificadas y los consejos sobre cómo comprender mejor sus cargas de trabajo, ahora debería tener lo que necesita para optimizar de manera eficiente sus cargas de trabajo de Apache Flink en Managed Service for Apache Flink. Los siguientes son algunos recursos útiles que puede utilizar para complementar esta publicación:
Acerca de los autores
 jeremy ber Ha trabajado en el espacio de datos de telemetría durante los últimos 10 años como ingeniero de software, ingeniero de aprendizaje automático y, más recientemente, ingeniero de datos. En AWS, es arquitecto de soluciones especializado en streaming y brinda soporte tanto a Amazon Managed Streaming para Apache Kafka (Amazon MSK) como a Amazon Managed Service para Apache Flink.
jeremy ber Ha trabajado en el espacio de datos de telemetría durante los últimos 10 años como ingeniero de software, ingeniero de aprendizaje automático y, más recientemente, ingeniero de datos. En AWS, es arquitecto de soluciones especializado en streaming y brinda soporte tanto a Amazon Managed Streaming para Apache Kafka (Amazon MSK) como a Amazon Managed Service para Apache Flink.
 lorenzo nicara Trabaja como arquitecto sénior de soluciones de streaming en AWS y ayuda a los clientes de toda EMEA. Lleva más de 25 años creando sistemas nativos de la nube con uso intensivo de datos, trabajando en la industria financiera a través de consultorías y para empresas de productos FinTech. Ha aprovechado ampliamente las tecnologías de código abierto y contribuido a varios proyectos, incluido Apache Flink.
lorenzo nicara Trabaja como arquitecto sénior de soluciones de streaming en AWS y ayuda a los clientes de toda EMEA. Lleva más de 25 años creando sistemas nativos de la nube con uso intensivo de datos, trabajando en la industria financiera a través de consultorías y para empresas de productos FinTech. Ha aprovechado ampliamente las tecnologías de código abierto y contribuido a varios proyectos, incluido Apache Flink.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/real-time-cost-savings-for-amazon-managed-service-for-apache-flink/

