La semana pasada anunciamos la disponibilidad general de la integración entre Zona de datos de Amazon y Formación del lago AWS modo de acceso híbrido. En esta publicación, compartimos cómo esta nueva característica lo ayuda a simplificar la forma en que utiliza Amazon DataZone para permitir el intercambio seguro y gobernado de sus datos en el Pegamento AWS Catálogo de datos. También profundizamos en cómo los productores de datos pueden compartir sus tablas de AWS Glue a través de Amazon DataZone sin necesidad de registrarlas primero en Lake Formation.
Descripción general de la integración de Amazon DataZone con el modo de acceso híbrido de Lake Formation
Amazon DataZone es un servicio de administración de datos totalmente administrado para catalogar, descubrir, analizar, compartir y controlar datos entre productores y consumidores de datos de su organización. Con Amazon DataZone, los productores de datos completan el catálogo de datos empresariales con activos de datos de fuentes de datos como AWS Glue Data Catalog y Desplazamiento al rojo de Amazon. También enriquecen sus activos con un contexto empresarial para que los consumidores de datos puedan entenderlos fácilmente. Una vez que los datos están disponibles en el catálogo, los consumidores de datos, como analistas y científicos de datos, pueden buscar y acceder a estos datos solicitando suscripciones. Cuando se aprueba la solicitud, Amazon DataZone puede proporcionar automáticamente acceso a los datos mediante la administración de permisos en Lake Formation o Amazon Redshift para que el consumidor de datos pueda comenzar a consultar los datos utilizando herramientas como Atenea amazónica o Amazon Redshift.
Para administrar el acceso a los datos en AWS Glue Data Catalog, Amazon DataZone utiliza Lake Formation. Anteriormente, si deseaba utilizar Amazon DataZone para administrar el acceso a sus datos en el catálogo de datos de AWS Glue, primero tenía que incorporar sus datos a Lake Formation. Ahora, la integración del modo de acceso híbrido de Amazon DataZone y Lake Formation simplifica cómo puede comenzar su recorrido por Amazon DataZone al eliminar la necesidad de incorporar primero sus datos a Lake Formation.
Formación del lago modo de acceso híbrido le permite comenzar a administrar permisos en sus bases de datos y tablas de AWS Glue a través de Lake Formation, mientras continúa manteniendo cualquier existente Gestión de identidades y accesos de AWS (IAM) permisos en estas tablas y bases de datos. El modo de acceso híbrido de Lake Formation admite dos rutas de permisos para las mismas bases de datos y tablas del catálogo de datos:
- En la primera vía, Lake Formation le permite seleccionar directores específicos (directores de participación voluntaria) y otorgarles permisos de Lake Formation para acceder a bases de datos y tablas al optar por participar.
- La segunda vía permite que todos los demás directores (que no se agregan como directores optativos) accedan a estos recursos a través de las políticas principales de IAM para Servicio de almacenamiento simple de Amazon (Amazon S3) y acciones de AWS Glue
Con la integración entre Amazon DataZone y el modo de acceso híbrido de Lake Formation, si tiene tablas en el catálogo de datos de AWS Glue que se administran mediante políticas basadas en IAM, puede publicar estas tablas directamente en Amazon DataZone, sin registrarlas en Lake Formation. Amazon DataZone registra la ubicación de estas tablas en Lake Formation mediante el modo de acceso híbrido, que permite administrar permisos en tablas de AWS Glue a través de Lake Formation, mientras continúa manteniendo los permisos de IAM existentes.
Amazon DataZone le permite publicar cualquier tipo de activo en el catálogo de datos empresariales. Para algunos de estos activos, Amazon DataZone puede administrar automáticamente las concesiones de acceso. Estos activos se llaman activos gestionadose incluyen tablas del catálogo de datos administradas por Lake Formation y tablas y vistas de Amazon Redshift. Antes de esta integración, debía completar los siguientes pasos antes de que Amazon DataZone pudiera tratar la tabla del catálogo de datos publicada como un activo administrado:
- Identifique la ubicación de Amazon S3 asociada con la tabla del catálogo de datos.
- Registre la ubicación de Amazon S3 con Lake Formation en modo de acceso híbrido mediante un papel con los permisos adecuados.
- Publique los metadatos de la tabla en el catálogo de datos empresariales de Amazon DataZone.
El siguiente diagrama ilustra este flujo de trabajo.
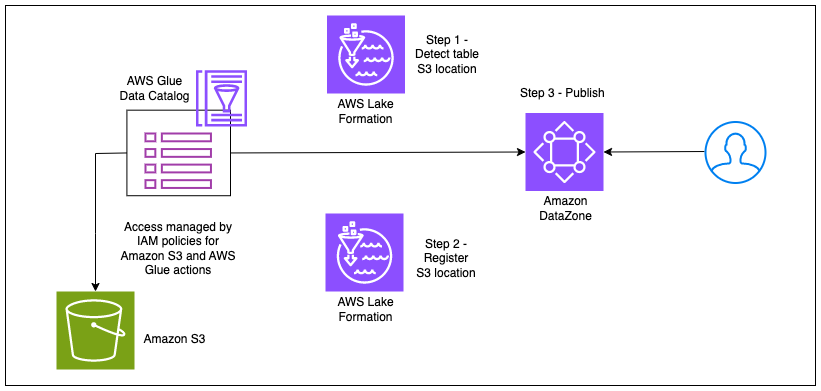
Con la integración de Amazon DataZone con el modo de acceso híbrido de Lake Formation, puede simplemente publicar sus tablas de AWS Glue en Amazon DataZone sin tener que preocuparse por registrar la ubicación de Amazon S3 o agregar una entidad principal de suscripción voluntaria en Lake Formation delegando estos pasos en Amazon DataZone. . El administrador de una cuenta de AWS puede habilitar la configuración de registro de ubicación de datos en el DefaultDataLake plano en la consola de Amazon DataZone. Ahora, un propietario o editor de datos puede publicar su tabla de AWS Glue (administrada mediante permisos de IAM) en Amazon DataZone sin pasos de configuración adicionales. Cuando un consumidor de datos se suscribe a esta tabla, Amazon DataZone registra las ubicaciones de Amazon S3 de la tabla en modo de acceso híbrido, agrega la función de IAM del consumidor de datos como entidad principal de participación y otorga acceso a la misma función de IAM mediante la administración de permisos en la tabla. mesa a través de la Formación del Lago. Esto garantiza que los permisos de IAM en la tabla puedan coexistir con los permisos de Lake Formation recién otorgados, sin interrumpir ningún flujo de trabajo existente. El siguiente diagrama ilustra este flujo de trabajo.

Resumen de la solución
Para demostrar esta nueva capacidad, utilizamos un escenario de cliente de muestra en el que el equipo de finanzas desea acceder a datos propiedad del equipo de ventas para análisis e informes financieros. El equipo de ventas tiene un canal que crea un conjunto de datos que contiene información valiosa sobre la venta de entradas, eventos populares, lugares y temporadas. Lo llamamos conjunto de datos tickit. El equipo de ventas almacena este conjunto de datos en Amazon S3 y lo registra en una base de datos en el Catálogo de datos. El acceso a esta tabla se gestiona actualmente mediante permisos basados en IAM. Sin embargo, el equipo de ventas desea publicar esta tabla en Amazon DataZone para facilitar el intercambio de datos seguro y gobernado con el equipo de finanzas.
Los pasos para configurar esta solución son los siguientes:
- El administrador de Amazon DataZone habilita la configuración de registro de ubicación del lago de datos en Amazon DataZone para registrar automáticamente la ubicación de Amazon S3 de las tablas de AWS Glue en el modo de acceso híbrido de Lake Formation.
- Una vez habilitada la integración del modo de acceso híbrido en Amazon DataZone, el equipo de finanzas solicita una suscripción al activo de datos de ventas. El activo aparece como un activo administrado, lo que significa que Amazon DataZone puede administrar el acceso a este activo incluso si la ubicación de Amazon S3 de este activo no está registrada en Lake Formation.
- Se notifica al equipo de ventas sobre una solicitud de suscripción planteada por el equipo de finanzas. Revisan y aprueban la solicitud de acceso. Una vez aprobada la solicitud, Amazon DataZone cumple con la solicitud de suscripción administrando los permisos en Lake Formation. Registra la ubicación de Amazon S3 de la tabla suscrita en modo híbrido de Lake Formation.
- El equipo de finanzas obtiene acceso al conjunto de datos de ventas necesarios para sus informes financieros. Pueden ir a su entorno DataZone y comenzar a ejecutar consultas utilizando Athena en su conjunto de datos suscrito.
Requisitos previos
Para seguir los pasos de esta publicación, necesita una cuenta de AWS. Si no tienes una cuenta, puedes crear una. Además, deberás tener configurados los siguientes recursos en tu cuenta:
- Un cubo S3
- Una base de datos y un rastreador de AWS Glue
- Roles de IAM para diferentes personas y servicios
- Un dominio y proyecto de Amazon DataZone
- Un entorno y perfil de entorno de Amazon DataZone
- Una fuente de datos de Amazon DataZone
Si aún no tiene estos recursos configurados, puede crearlos implementando lo siguiente Formación en la nube de AWS apilar:
- Elige Pila de lanzamiento para implementar una plantilla de CloudFormation.

- Complete los pasos para implementar la plantilla y deje todas las configuraciones como predeterminadas.
- Seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM, A continuación, elija Enviar.
Una vez completada la implementación de CloudFormation, puede iniciar sesión en el portal de Amazon DataZone y activar manualmente una ejecución de fuente de datos. Esto extrae los metadatos nuevos o modificados de la fuente y actualiza los activos asociados en el inventario. Esta fuente de datos se ha configurado para publicar automáticamente los activos de datos en el catálogo.
- En la consola de Amazon DataZone, elija Ver dominios.
Debe iniciar sesión con el mismo rol que se utiliza para implementar CloudFormation y verificar que se encuentra en la misma región de AWS.
- Encuentra el dominio
blog_dz_domain, A continuación, elija portal de datos abiertos. - Elige Explorar todos los proyectos y elige Proyecto de productor de ventas..
- En Datos pestaña, elegir Fuentes de datos en el panel de navegación.
- Localice y elija la fuente de datos que desea ejecutar.
Esto abre la página de detalles de la fuente de datos.
- Elija el menú de opciones (tres puntos verticales) al lado de
tickit_datasourcey elige Ejecutar.
El estado de la fuente de datos cambia a En ejecución cuando Amazon DataZone actualiza los metadatos del recurso.
Habilite la integración del modo híbrido en Amazon DataZone
En este paso, el administrador de Amazon DataZone realiza el proceso de habilitar la integración de Amazon DataZone con el modo de acceso híbrido de Lake Formation. Complete los siguientes pasos:
- En una pestaña separada del navegador, abra la consola de Amazon DataZone.
Verifique que se encuentre en la misma región donde implementó la plantilla de CloudFormation.
- Elige Ver dominios.
- Elija el dominio creado por AWS CloudFormation,
blog_dz_domain. - Desplácese hacia abajo en la página de detalles del dominio y elija el Plano .
A proyecto define qué herramientas y servicios de AWS se pueden utilizar con los activos de datos publicados en Amazon DataZone. El DefaultDataLake blueprint está habilitado como parte de la implementación de la pila de CloudFormation. Este plano le permite crear y consultar tablas de AWS Glue mediante Athena. Para conocer los pasos para habilitar esto en sus propias implementaciones, consulte Habilite los blueprints integrados en la cuenta de AWS propietaria del dominio de Amazon DataZone.
- Elija el
DefaultDataLakePlano.
- En Aprovisionamiento pestaña, elegir Editar.
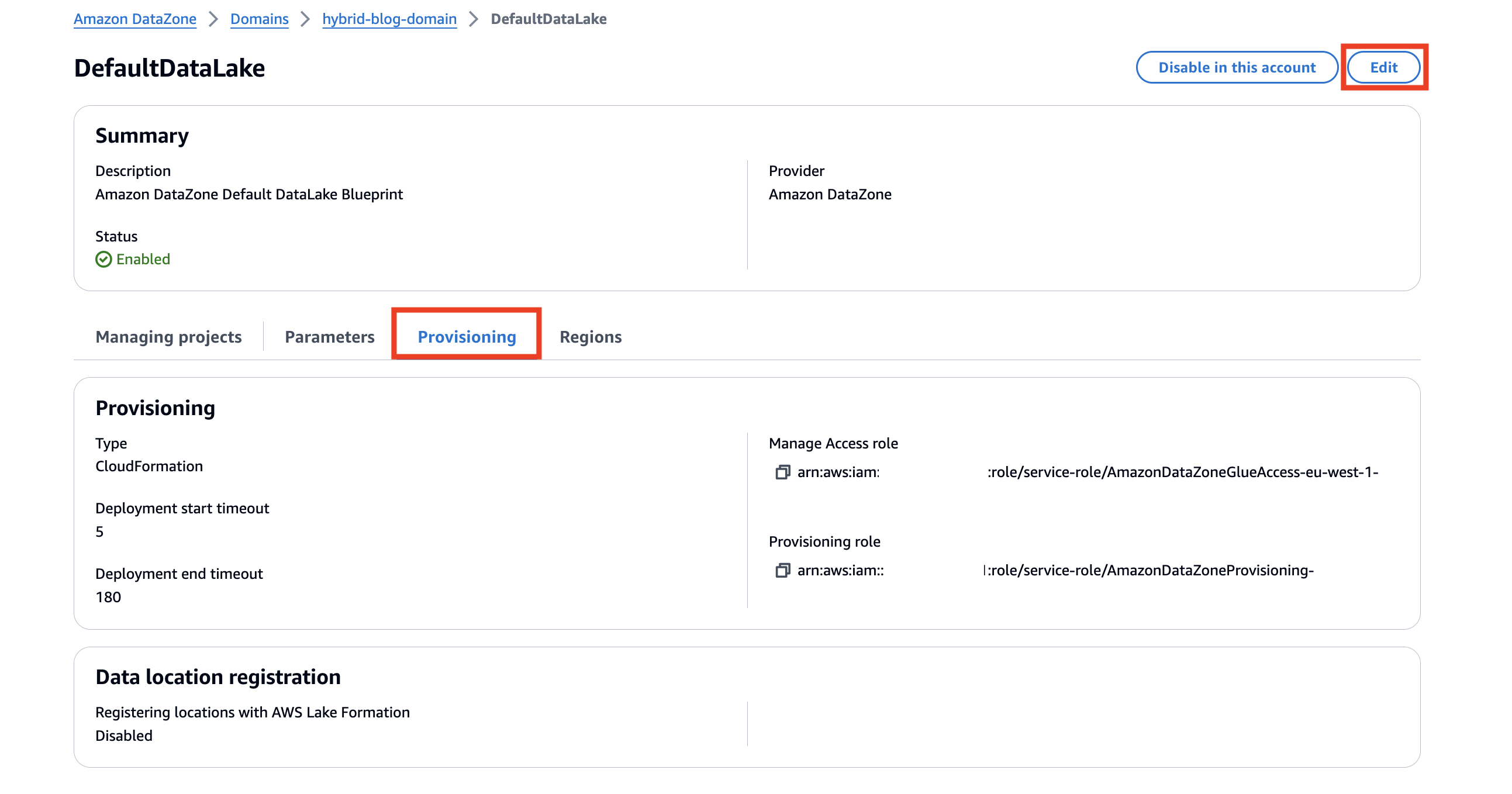
- Seleccione Habilite Amazon DataZone para registrar ubicaciones de S3 mediante el modo de acceso híbrido de AWS Lake Formation.
Tiene la opción de excluir ubicaciones específicas de Amazon S3 si no desea que Amazon DataZone las registre automáticamente en el modo de acceso híbrido de Lake Formation.
- Elige Guardar los cambios.

Solicitar acceso
En este paso, inicia sesión en Amazon DataZone como equipo de finanzas, busca el activo de datos de ventas y se suscribe a él. Complete los siguientes pasos:
- Regrese a la pestaña del navegador del portal de datos de Amazon DataZone.
- Cambie al proyecto de consumidor financiero eligiendo el menú desplegable junto al nombre del proyecto y eligiendo Proyecto de consumo financiero.
A partir de este paso, asumes la personalidad de un usuario de finanzas que busca suscribirse a un activo de datos publicado en el paso anterior.
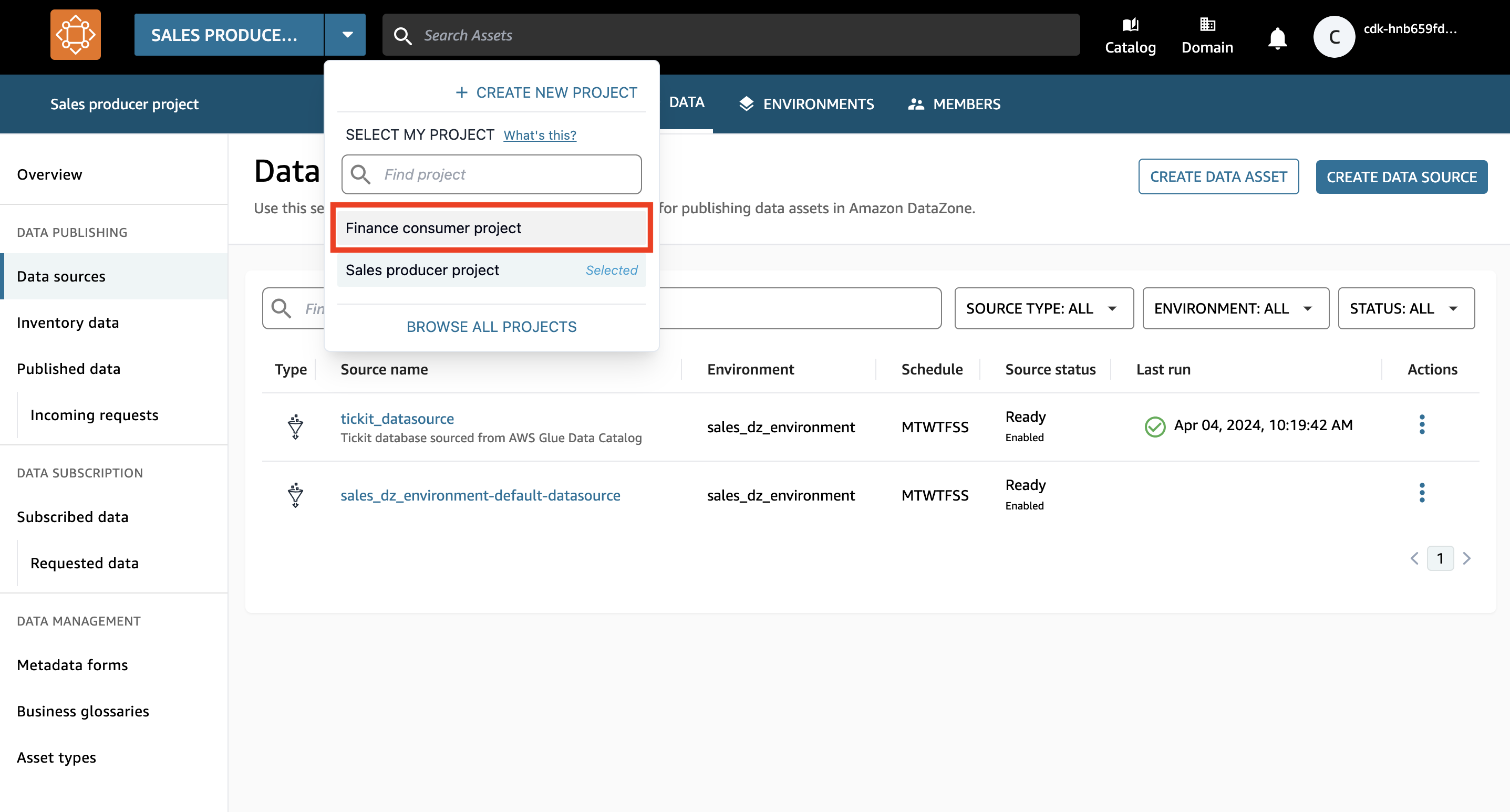
- En la barra de búsqueda, busque y elija el
salesactivo de datos.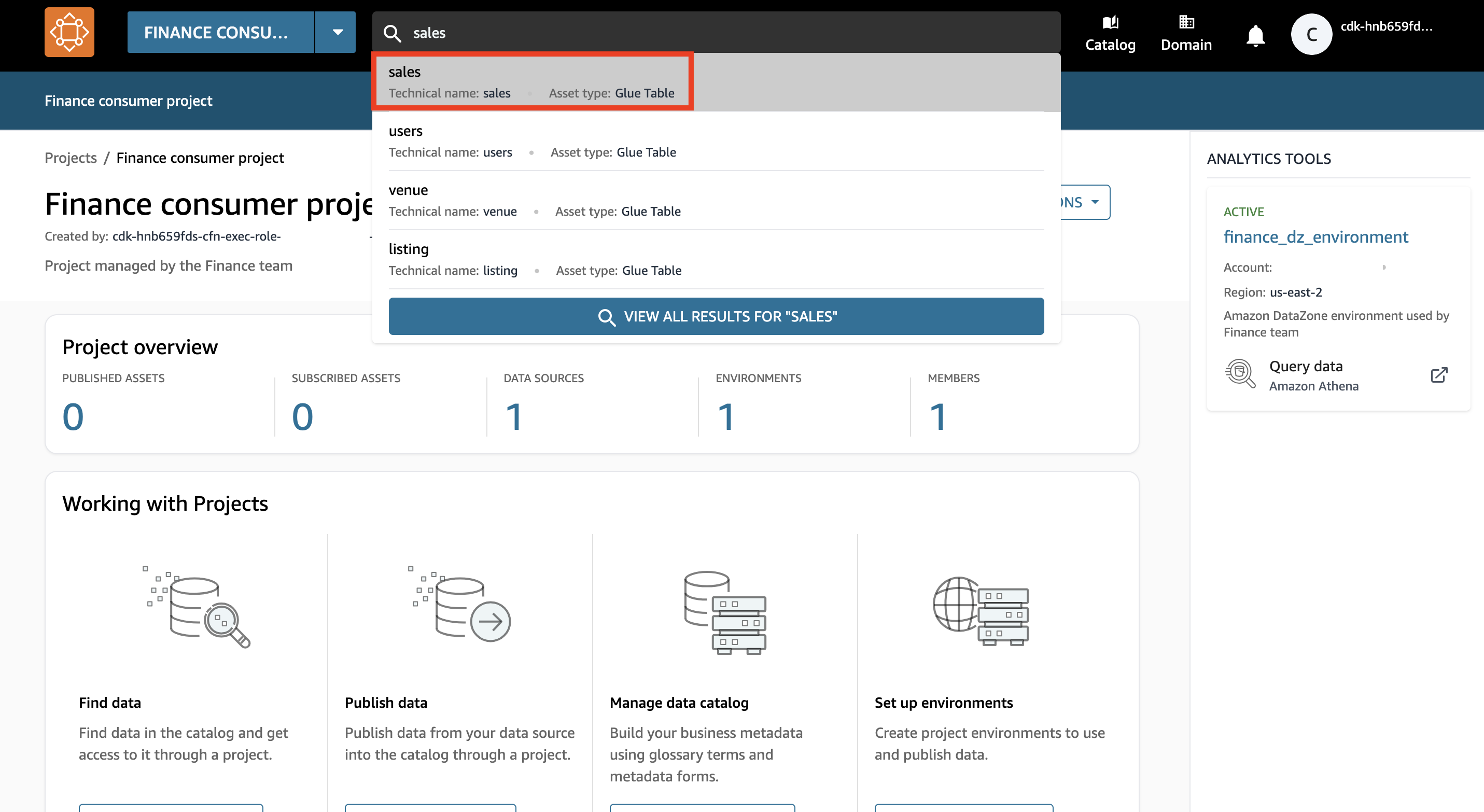
- Elige Suscríbete.
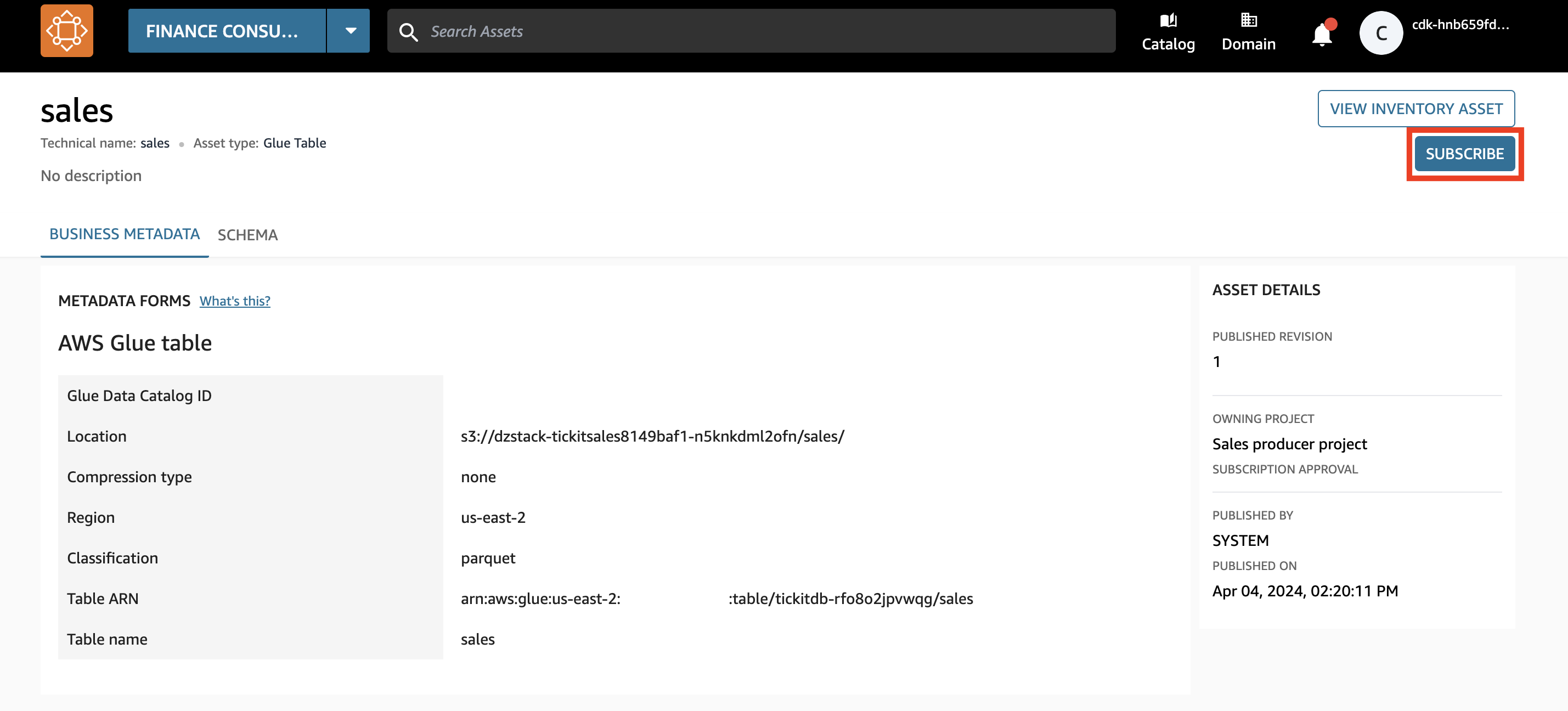
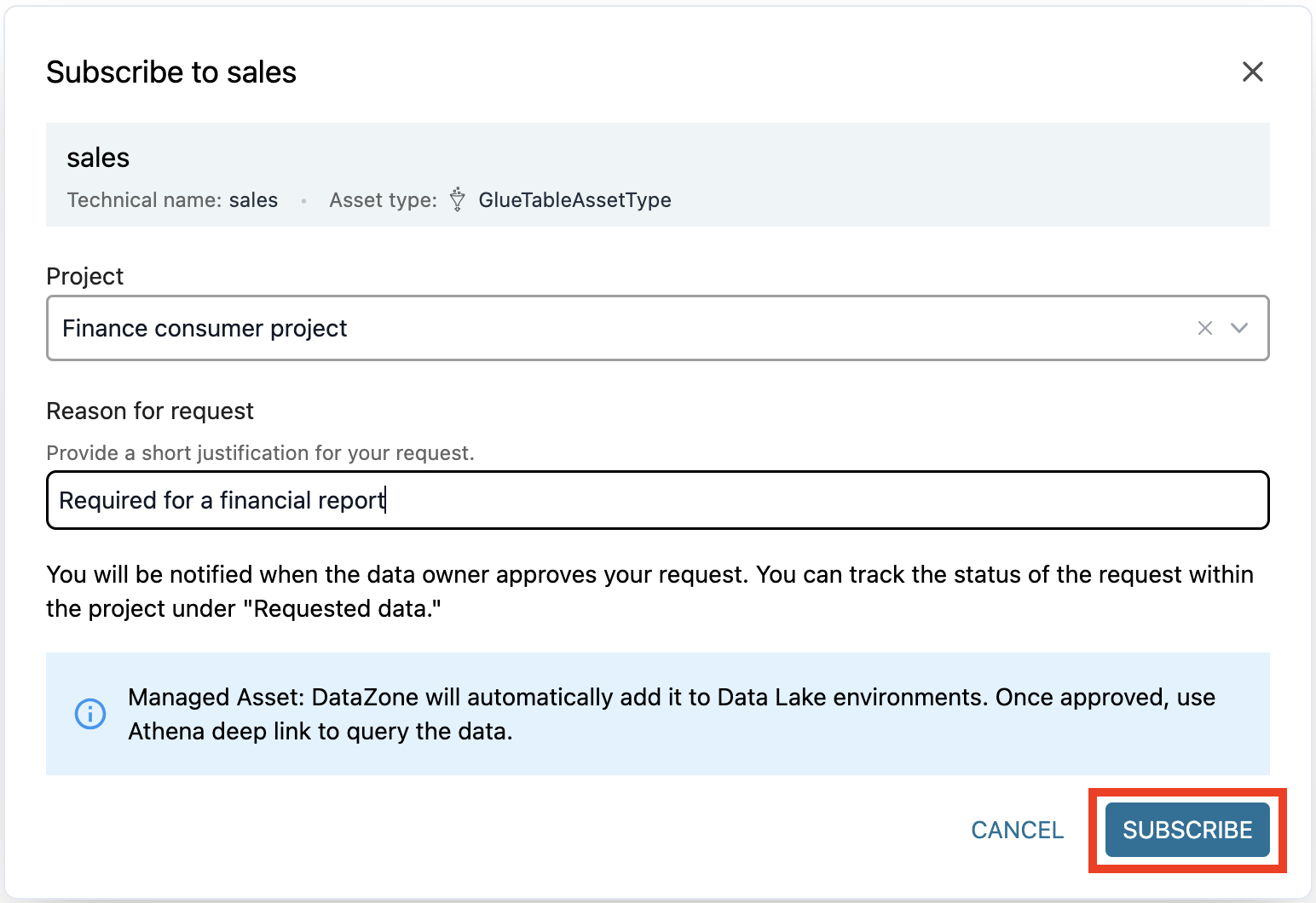
El activo aparece como activo administrado. Esto significa que Amazon DataZone puede otorgar acceso a este activo de datos al proyecto del equipo financiero administrando los permisos en Lake Formation.
- Ingrese un motivo para la solicitud de acceso y elija Suscríbete.
Aprobar solicitud de acceso
El equipo de ventas recibe una notificación de que se envió una solicitud de acceso del equipo de finanzas. Para aprobar la solicitud, complete los siguientes pasos:
- Elija el menú desplegable junto al nombre del proyecto y elija Proyecto de productor de ventas..
Ahora asume la personalidad del equipo de ventas, que son los propietarios y administradores de los activos de datos de ventas.
- Elija el ícono de notificación en la esquina superior derecha del portal DataZone.
- Elija el Solicitud de suscripción creada tarea.
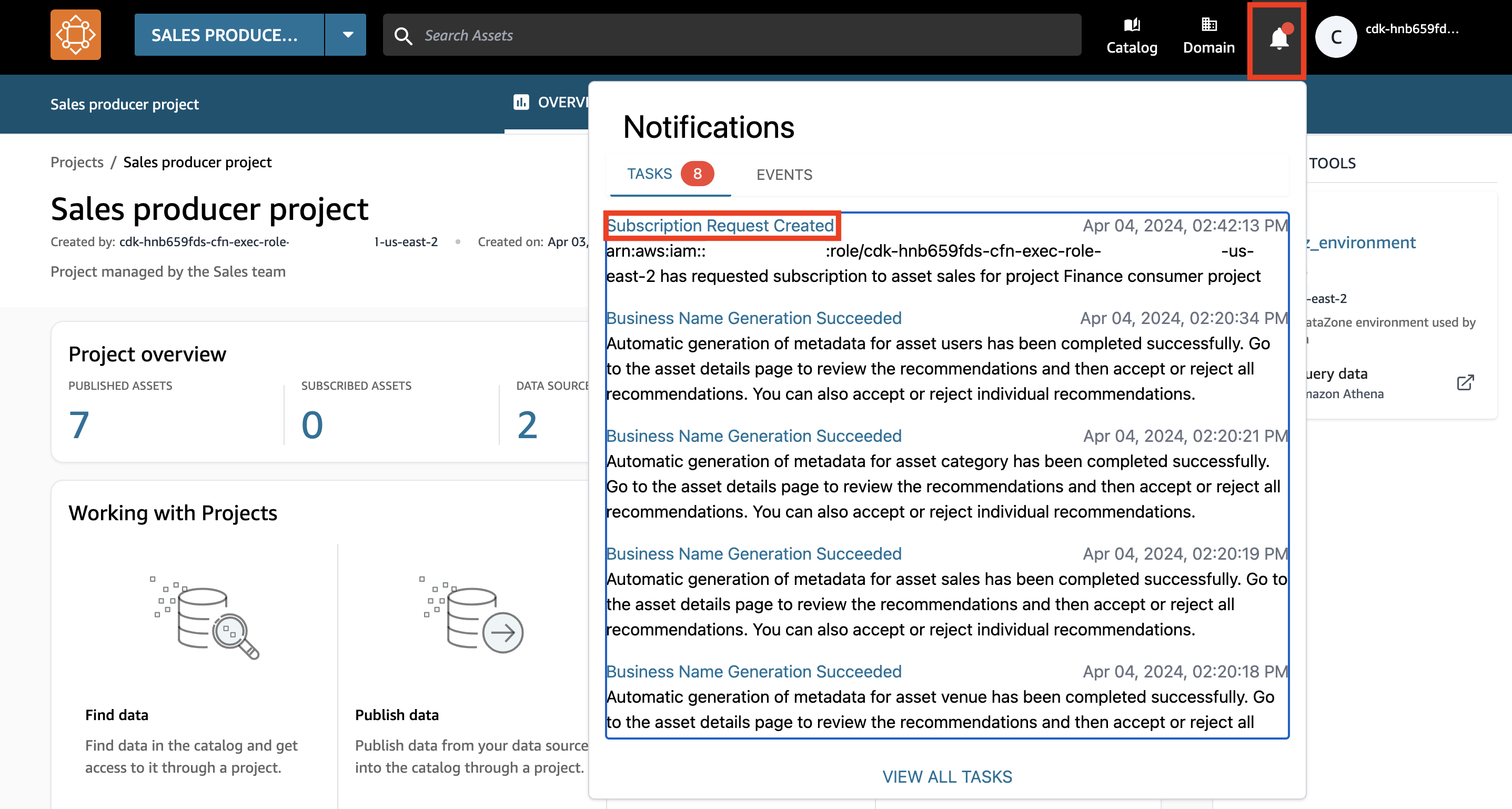
- Otorgue acceso al activo de datos de ventas al equipo de finanzas y elija Aprobar.

Analiza los datos
Al equipo de finanzas se le ha otorgado acceso a los datos de ventas y este conjunto de datos ha estado en su entorno Amazon DataZone. Pueden acceder al entorno y consultar el conjunto de datos de ventas con Athena, junto con cualquier otro conjunto de datos que posean actualmente. Complete los siguientes pasos:
- En el menú desplegable, elija Proyecto de consumo financiero.
En el panel derecho de la pantalla de descripción general del proyecto, puede encontrar una lista de entornos activos disponibles para su uso.
- Elija el entorno de Amazon DataZone
finance_dz_environment.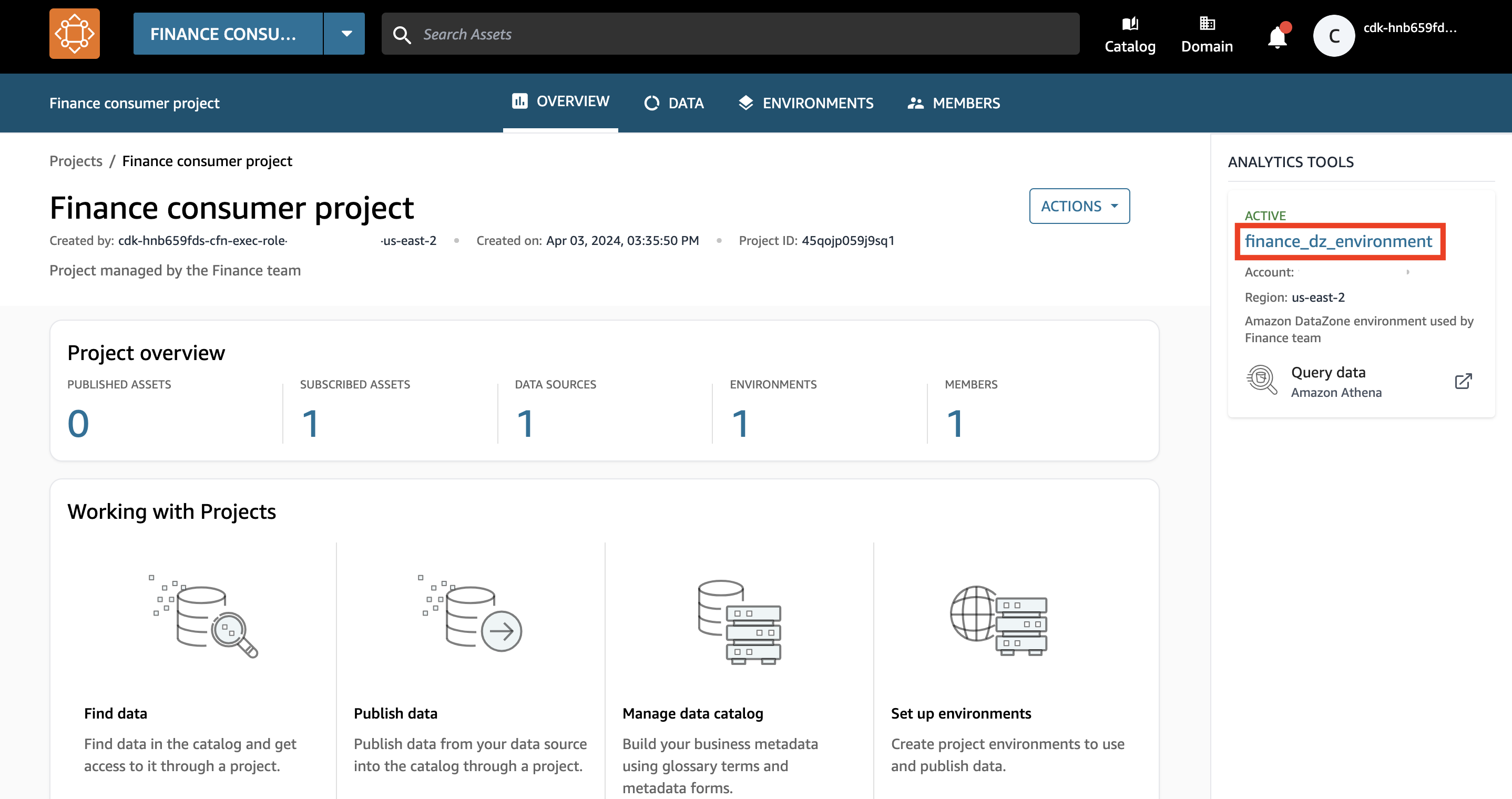
- En el panel de navegación, debajo Activos de datos, escoger Suscrito.
- Verifique que su entorno ahora tenga acceso a los datos de ventas.
Es posible que el recurso de datos tarde unos minutos en agregarse automáticamente a su entorno.
- Elija el icono de nueva pestaña para Consultar datos.
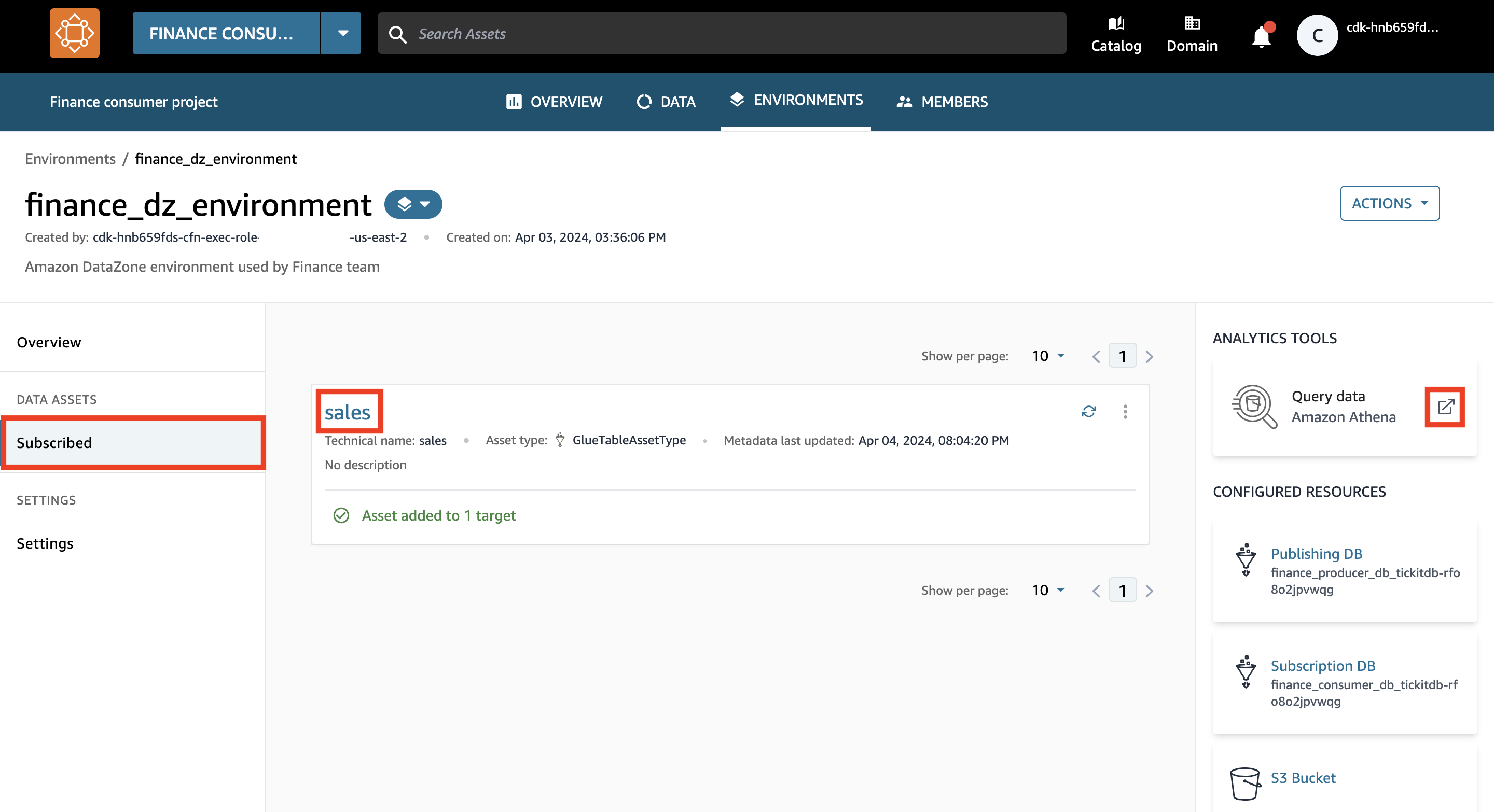
Se abre una nueva pestaña con el editor de consultas de Athena.
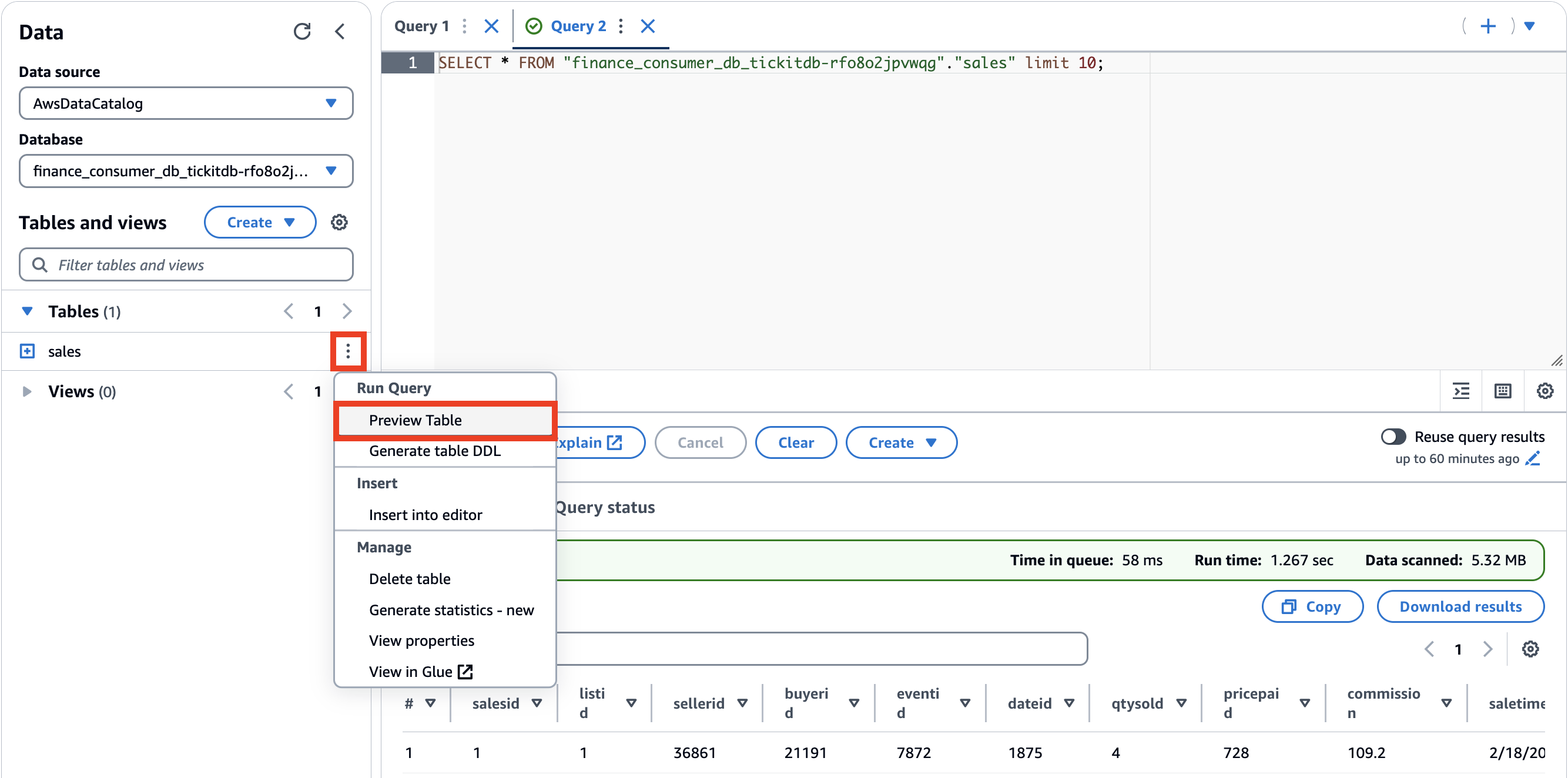
- Base de datos, escoger
finance_consumer_db_tickitdb-<suffix>.
Esta base de datos contendrá sus activos de datos suscritos.

- Genere una vista previa de la tabla de ventas eligiendo el menú de opciones (tres puntos verticales) y eligiendo Tabla de vista previa.
Limpiar
Para limpiar sus recursos, complete los siguientes pasos:
- Vuelva a la función de administrador que utilizó para implementar la pila de CloudFormation.
- En la consola de Amazon DataZone, eliminar los proyectos utilizado en esta publicación. Esto eliminará la mayoría de los objetos relacionados con el proyecto, como entornos y activos de datos.
- En la consola de AWS CloudFormation, elimine la pila que implementó al principio de esta publicación.
- En la consola de Amazon S3, elimine los depósitos de S3 que contienen el conjunto de datos tickit.
- En la consola de Lake Formation, elimine los administradores de Lake Formation registrados por Amazon DataZone.
- En la consola de Lake Formation, elimine las tablas y bases de datos creadas por Amazon DataZone.
Conclusión
En esta publicación, analizamos cómo la integración entre Amazon DataZone y el modo de acceso híbrido de Lake Formation simplifica el proceso para comenzar a utilizar Amazon DataZone para la gobernanza de un extremo a otro de sus datos en AWS Glue Data Catalog. Esta integración le ayuda a omitir los pasos manuales de incorporación a Lake Formation antes de poder comenzar a utilizar Amazon DataZone.
Para obtener más información sobre cómo empezar a utilizar Amazon DataZone, consulte la Guía de inicio. Echa un vistazo a la YouTube lista de reproducción para ver algunas de las demostraciones más recientes de Amazon DataZone y breves descripciones de las capacidades disponibles. Para obtener más información sobre Amazon DataZone, consulte Cómo Amazon DataZone ayuda a los clientes a encontrar valor en océanos de datos.
Acerca de los autores
 Mittal Utkarsh es gerente técnico senior de productos para Amazon DataZone en AWS. Le apasiona crear productos innovadores que simplifiquen los recorridos analíticos de un extremo a otro de los clientes. Fuera del mundo de la tecnología, a Utkarsh le encanta tocar música y la batería es su último esfuerzo.
Mittal Utkarsh es gerente técnico senior de productos para Amazon DataZone en AWS. Le apasiona crear productos innovadores que simplifiquen los recorridos analíticos de un extremo a otro de los clientes. Fuera del mundo de la tecnología, a Utkarsh le encanta tocar música y la batería es su último esfuerzo.
 Praveen Kumar es arquitecto principal de soluciones de análisis en AWS con experiencia en el diseño, construcción e implementación de plataformas modernas de análisis y datos utilizando servicios centrados en la nube. Sus áreas de interés son la tecnología sin servidor, los modernos almacenes de datos en la nube, el streaming y las aplicaciones de IA generativa.
Praveen Kumar es arquitecto principal de soluciones de análisis en AWS con experiencia en el diseño, construcción e implementación de plataformas modernas de análisis y datos utilizando servicios centrados en la nube. Sus áreas de interés son la tecnología sin servidor, los modernos almacenes de datos en la nube, el streaming y las aplicaciones de IA generativa.
 pablo villena es un arquitecto senior de soluciones de análisis en AWS con experiencia en la creación de soluciones de análisis y datos modernas para impulsar el valor empresarial. Trabaja con los clientes para ayudarlos a aprovechar el poder de la nube. Sus áreas de interés son la infraestructura como código, las tecnologías sin servidor y la codificación en Python.
pablo villena es un arquitecto senior de soluciones de análisis en AWS con experiencia en la creación de soluciones de análisis y datos modernas para impulsar el valor empresarial. Trabaja con los clientes para ayudarlos a aprovechar el poder de la nube. Sus áreas de interés son la infraestructura como código, las tecnologías sin servidor y la codificación en Python.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/amazon-datazone-announces-integration-with-aws-lake-formation-hybrid-access-mode-for-the-aws-glue-data-catalog/

