Veriff es un socio de plataforma de verificación de identidad para organizaciones innovadoras impulsadas por el crecimiento, incluidos pioneros en servicios financieros, FinTech, criptografía, juegos, movilidad y mercados en línea. Proporcionan tecnología avanzada que combina la automatización impulsada por la IA con comentarios humanos, conocimientos profundos y experiencia.

Veriff ofrece una infraestructura probada que permite a sus clientes confiar en las identidades y atributos personales de sus usuarios en todos los momentos relevantes del recorrido del cliente. Clientes como Bolt, Deel, Monese, Starship, Super Awesome, Trustpilot y Wise confían en Veriff.
Como solución impulsada por IA, Veriff necesita crear y ejecutar docenas de modelos de aprendizaje automático (ML) de forma rentable. Estos modelos van desde modelos livianos basados en árboles hasta modelos de visión por computadora de aprendizaje profundo, que deben ejecutarse en GPU para lograr una baja latencia y mejorar la experiencia del usuario. Veriff también está agregando actualmente más productos a su oferta, apuntando a una solución hiperpersonalizada para sus clientes. Ofrecer diferentes modelos para diferentes clientes aumenta la necesidad de una solución de servicio de modelos escalable.
En esta publicación, le mostramos cómo Veriff estandarizó su flujo de trabajo de implementación de modelos usando Amazon SageMaker, reduciendo costos y tiempo de desarrollo.
Desafíos de infraestructura y desarrollo
La arquitectura backend de Veriff se basa en un patrón de microservicios, con servicios que se ejecutan en diferentes clústeres de Kubernetes alojados en la infraestructura de AWS. Este enfoque se utilizó inicialmente para todos los servicios de la empresa, incluidos los microservicios que ejecutan costosos modelos de aprendizaje automático de visión por computadora.
Algunos de estos modelos requirieron implementación en instancias de GPU. Consciente del costo comparativamente más alto de los tipos de instancias respaldadas por GPU, Veriff desarrolló una solución personalizada en Kubernetes para compartir los recursos de una GPU determinada entre diferentes réplicas de servicios. Una sola GPU normalmente tiene suficiente VRAM para almacenar en la memoria varios modelos de visión por computadora de Veriff.
Aunque la solución alivió los costos de GPU, también tenía la restricción de que los científicos de datos debían indicar de antemano cuánta memoria de GPU requeriría su modelo. Además, los DevOps tenían que aprovisionar manualmente instancias de GPU en respuesta a los patrones de demanda. Esto provocó una sobrecarga operativa y un aprovisionamiento excesivo de instancias, lo que resultó en un perfil de costos subóptimo.
Además del aprovisionamiento de GPU, esta configuración también requirió que los científicos de datos crearan un contenedor de API REST para cada modelo, que era necesario para proporcionar una interfaz genérica para que la consumieran otros servicios de la empresa y para encapsular el preprocesamiento y el posprocesamiento de los datos del modelo. Estas API requerían código de nivel de producción, lo que dificultaba que los científicos de datos pudieran producir modelos.
El equipo de la plataforma de ciencia de datos de Veriff buscó formas alternativas a este enfoque. El objetivo principal era apoyar a los científicos de datos de la empresa con una mejor transición de la investigación a la producción proporcionando canales de implementación más simples. El objetivo secundario era reducir los costos operativos del aprovisionamiento de instancias de GPU.
Resumen de la solución
Veriff necesitaba una nueva solución que resolviera dos problemas:
- Permitir crear contenedores de API REST alrededor de modelos ML con facilidad
- Permitir administrar la capacidad de la instancia de GPU aprovisionada de manera óptima y, si es posible, automáticamente
Al final, el equipo de la plataforma ML convergió en la decisión de utilizar Puntos finales multimodelo de Sagemaker (MMEs). Esta decisión fue impulsada por el apoyo de MME a NVIDIA. Servidor de inferencia Triton (un servidor centrado en ML que facilita la integración de modelos como API REST; Veriff también estaba experimentando con Triton), así como su capacidad para administrar de forma nativa el escalado automático de instancias de GPU a través de políticas simples de escalado automático.
Se crearon dos MME en Veriff, una para puesta en escena y otra para producción. Este enfoque les permite ejecutar pasos de prueba en un entorno de prueba sin afectar los modelos de producción.
MME de SageMaker
SageMaker es un servicio completamente administrado que brinda a los desarrolladores y científicos de datos la capacidad de crear, entrenar e implementar modelos ML rápidamente. Los MME de SageMaker proporcionan una solución escalable y rentable para implementar una gran cantidad de modelos para la inferencia en tiempo real. Los MME usan un contenedor de servicio compartido y una flota de recursos que pueden usar instancias aceleradas, como GPU, para alojar todos sus modelos. Esto reduce los costos de hospedaje al maximizar la utilización de puntos finales en comparación con el uso de puntos finales de modelo único. También reduce la sobrecarga de implementación porque SageMaker administra la carga y descarga de modelos en la memoria y los escala en función de los patrones de tráfico del extremo. Además, todos los terminales en tiempo real de SageMaker se benefician de capacidades integradas para administrar y monitorear modelos, como incluir variantes de sombra, escalado automáticoe integración nativa con Reloj en la nube de Amazon (para más información, consulte Métricas de CloudWatch para implementaciones de terminales de varios modelos).
Modelos de conjuntos Triton personalizados
Hubo varias razones por las que Veriff decidió utilizar Triton Inference Server, siendo las principales:
- Permite a los científicos de datos crear API REST a partir de modelos organizando los archivos de artefactos del modelo en un formato de directorio estándar (sin solución de código).
- Es compatible con todos los principales marcos de IA (PyTorch, Tensorflow, XGBoost y más)
- Proporciona optimizaciones de servidor y de bajo nivel específicas de ML, como procesamiento por lotes dinámico de solicitudes
El uso de Triton permite a los científicos de datos implementar modelos con facilidad porque solo necesitan crear repositorios de modelos formateados en lugar de escribir código para crear API REST (Triton también admite Modelos de Python si se requiere lógica de inferencia personalizada). Esto reduce el tiempo de implementación del modelo y brinda a los científicos de datos más tiempo para concentrarse en crear modelos en lugar de implementarlos.
Otra característica importante de Triton es que te permite construir conjuntos modelo, que son grupos de modelos que están encadenados entre sí. Estos conjuntos pueden funcionar como si fueran un único modelo Triton. Veriff actualmente emplea esta característica para implementar lógica de preprocesamiento y posprocesamiento con cada modelo de ML usando modelos de Python (como se mencionó anteriormente), asegurando que no haya discrepancias en los datos de entrada o la salida del modelo cuando los modelos se usan en producción.
A continuación se muestra el aspecto de un repositorio de modelos Triton típico para esta carga de trabajo:
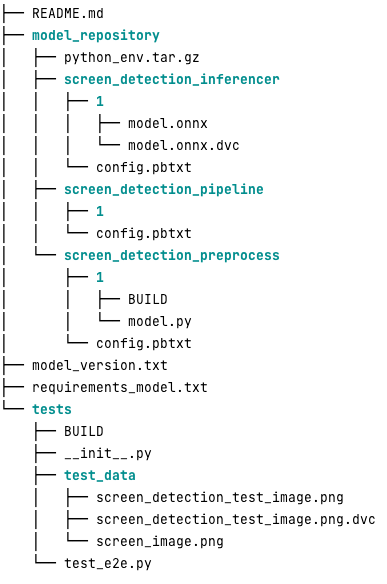
El model.py El archivo contiene código de preprocesamiento y posprocesamiento. Los pesos del modelo entrenado están en el screen_detection_inferencer directorio, bajo la versión del modelo 1 (El modelo está en formato ONNX en este ejemplo, pero también puede estar en formato TensorFlow, PyTorch u otros). La definición del modelo de conjunto se encuentra en el screen_detection_pipeline directorio, donde las entradas y salidas entre pasos se asignan en un archivo de configuración.
Las dependencias adicionales necesarias para ejecutar los modelos de Python se detallan en un requirements.txt archivo, y debe empaquetarse conda para crear un entorno Conda (python_env.tar.gz). Para obtener más información, consulte Administrar el tiempo de ejecución y las bibliotecas de Python. Además, los archivos de configuración para los pasos de Python deben apuntar a python_env.tar.gz usando el EXECUTION_ENV_PATH Directiva.
Luego, la carpeta del modelo debe comprimirse con TAR y cambiarse el nombre usando model_version.txt. Finalmente, el resultado <model_name>_<model_version>.tar.gz el archivo se copia en el Servicio de almacenamiento simple de Amazon (Amazon S3) conectado al MME, lo que permite a SageMaker detectar y servir el modelo.
Versionado de modelos e implementación continua
Como quedó claro en la sección anterior, construir un repositorio de modelos Triton es sencillo. Sin embargo, ejecutar todos los pasos necesarios para implementarlo es tedioso y propenso a errores si se ejecuta manualmente. Para superar esto, Veriff creó un monorepo que contiene todos los modelos que se implementarán en MME, donde los científicos de datos colaboran en un enfoque similar a Gitflow. Este monorepo tiene las siguientes características:
- Se gestiona usando Pantalones.
- Las herramientas de calidad de código como Black y MyPy se aplican mediante Pants.
- Se definen pruebas unitarias para cada modelo, que verifican que el resultado del modelo sea el resultado esperado para una entrada del modelo determinada.
- Los pesos de los modelos se almacenan junto con los repositorios de modelos. Estos pesos pueden ser archivos binarios grandes, por lo que DVC se utiliza para sincronizarlos con Git de forma versionada.
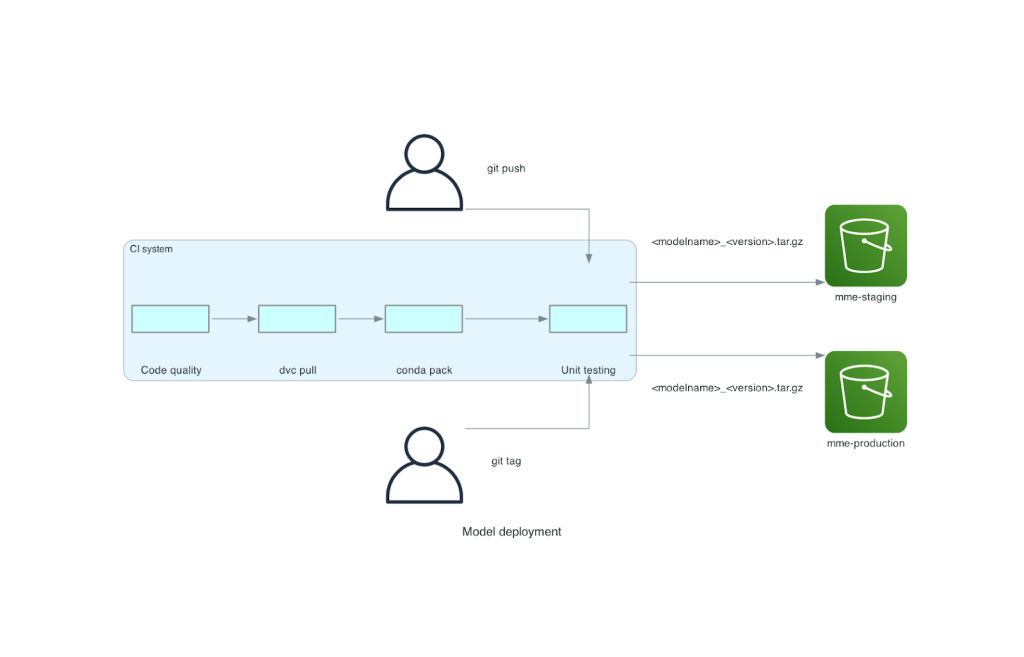
Este monorepo está integrado con una herramienta de integración continua (CI). Para cada nuevo envío al repositorio o nuevo modelo, se ejecutan los siguientes pasos:
- Pase el control de calidad del código.
- Descarga los pesos del modelo.
- Construya el entorno Conda.
- Inicie un servidor Triton utilizando el entorno Conda y utilícelo para procesar solicitudes definidas en pruebas unitarias.
- Cree el archivo TAR del modelo final (
<model_name>_<model_version>.tar.gz).
Estos pasos garantizan que los modelos tengan la calidad requerida para la implementación, por lo que para cada envío a una rama del repositorio, el archivo TAR resultante se copia (en otro paso de CI) al depósito provisional de S3. Cuando se realizan envíos en la rama principal, el archivo del modelo se copia en el depósito de producción S3. El siguiente diagrama muestra este sistema CI/CD.
Beneficios de costo y velocidad de implementación
El uso de MME permite a Veriff utilizar un enfoque monorepo para implementar modelos en producción. En resumen, el flujo de trabajo de implementación del nuevo modelo de Veriff consta de los siguientes pasos:
- Crea una rama en el monorepo con el nuevo modelo o versión del modelo.
- Definir y ejecutar pruebas unitarias en una máquina de desarrollo.
- Empuje la rama cuando el modelo esté listo para ser probado en el entorno de prueba.
- Fusione la rama con la principal cuando el modelo esté listo para usarse en producción.
Con esta nueva solución implementada, implementar un modelo en Veriff es una parte sencilla del proceso de desarrollo. El tiempo de desarrollo de nuevos modelos ha disminuido de 10 días a un promedio de 2 días.
Las funciones de aprovisionamiento de infraestructura administrada y escalado automático de SageMaker brindaron a Veriff beneficios adicionales. Ellos usaron el Invocaciones por instancia Métrica de CloudWatch para escalar según los patrones de tráfico, ahorrando costos sin sacrificar la confiabilidad. Para definir el valor umbral de la métrica, realizaron pruebas de carga en el punto final de preparación para encontrar la mejor compensación entre latencia y costo.
Después de implementar siete modelos de producción en MME y analizar el gasto, Veriff informó una reducción de costos del 75 % en el modelo de GPU en comparación con la solución original basada en Kubernetes. Los costos operativos también se redujeron, ya que se liberó a los ingenieros de DevOps de la empresa de la carga de aprovisionar instancias manualmente.
Conclusión
En esta publicación, revisamos por qué Veriff eligió Sagemaker MME en lugar de la implementación de modelos autogestionados en Kubernetes. SageMaker asume el trabajo pesado indiferenciado, lo que permite a Veriff disminuir el tiempo de desarrollo del modelo, aumentar la eficiencia de la ingeniería y reducir drásticamente el costo de la inferencia en tiempo real mientras mantiene el rendimiento necesario para sus operaciones críticas para el negocio. Finalmente, mostramos la canalización de CI/CD de implementación de modelos simple pero efectiva de Veriff y el mecanismo de control de versiones de modelos, que se puede utilizar como una implementación de referencia para combinar las mejores prácticas de desarrollo de software y MME de SageMaker. Puede encontrar ejemplos de código sobre cómo alojar varios modelos utilizando SageMaker MME en GitHub.
Acerca de los autores
 ricard borras es Senior Machine Learning en Veriff, donde lidera los esfuerzos de MLOps en la empresa. Ayuda a los científicos de datos a crear productos de IA/ML mejores y más rápidos mediante la creación de una plataforma de ciencia de datos en la empresa y la combinación de varias soluciones de código abierto con servicios de AWS.
ricard borras es Senior Machine Learning en Veriff, donde lidera los esfuerzos de MLOps en la empresa. Ayuda a los científicos de datos a crear productos de IA/ML mejores y más rápidos mediante la creación de una plataforma de ciencia de datos en la empresa y la combinación de varias soluciones de código abierto con servicios de AWS.
 joão moura es un arquitecto de soluciones especialista en IA/ML en AWS, con sede en España. Ayuda a los clientes con la optimización de la inferencia y la capacitación a gran escala de modelos de aprendizaje profundo y, de manera más amplia, con la construcción de plataformas de aprendizaje automático a gran escala en AWS.
joão moura es un arquitecto de soluciones especialista en IA/ML en AWS, con sede en España. Ayuda a los clientes con la optimización de la inferencia y la capacitación a gran escala de modelos de aprendizaje profundo y, de manera más amplia, con la construcción de plataformas de aprendizaje automático a gran escala en AWS.
 Miguel ferreira Trabaja como arquitecto senior de soluciones en AWS con sede en Helsinki, Finlandia. AI/ML ha sido un interés de toda la vida y ha ayudado a varios clientes a integrar Amazon SageMaker en sus flujos de trabajo de ML.
Miguel ferreira Trabaja como arquitecto senior de soluciones en AWS con sede en Helsinki, Finlandia. AI/ML ha sido un interés de toda la vida y ha ayudado a varios clientes a integrar Amazon SageMaker en sus flujos de trabajo de ML.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/how-veriff-decreased-deployment-time-by-80-using-amazon-sagemaker-multi-model-endpoints/

