Ha habido un enorme progreso en el campo del aprendizaje profundo distribuido para grandes modelos de lenguaje (LLM), especialmente después del lanzamiento de ChatGPT en diciembre de 2022. Los LLM continúan creciendo en tamaño con miles de millones o incluso billones de parámetros, y a menudo no lo hacen. encajar en un solo dispositivo acelerador como GPU o incluso en un solo nodo como ml.p5.32xlarge debido a limitaciones de memoria. Los clientes que forman LLM a menudo deben distribuir su carga de trabajo entre cientos o incluso miles de GPU. Permitir la capacitación a tal escala sigue siendo un desafío en la capacitación distribuida, y la capacitación eficiente en un sistema tan grande es otro problema igualmente importante. En los últimos años, la comunidad de capacitación distribuida ha introducido el paralelismo 3D (paralelismo de datos, paralelismo de canalización y paralelismo tensorial) y otras técnicas (como el paralelismo de secuencia y el paralelismo experto) para abordar tales desafíos.
En diciembre de 2023, Amazon anunció el lanzamiento del Biblioteca paralela de modelos SageMaker 2.0 (SMP), que logra una eficiencia de última generación en el entrenamiento de modelos grandes, junto con la Biblioteca de paralelismo de datos distribuidos de SageMaker (SMDDP). Esta versión es una actualización importante de 1.x: SMP ahora está integrado con PyTorch de código abierto Datos completamente fragmentados en paralelo (FSDP), que le permite utilizar una interfaz familiar al entrenar modelos grandes y es compatible con motor transformador (TE), desbloqueando técnicas de paralelismo tensorial junto con FSDP por primera vez. Para obtener más información sobre el lanzamiento, consulte La biblioteca paralela de modelos de Amazon SageMaker ahora acelera las cargas de trabajo de PyTorch FSDP hasta en un 20 %.
En esta publicación, exploramos los beneficios de rendimiento de Amazon SageMaker (incluidos SMP y SMDDP) y cómo puede utilizar la biblioteca para entrenar modelos grandes de manera eficiente en SageMaker. Demostramos el rendimiento de SageMaker con pruebas comparativas en clústeres ml.p4d.24xlarge de hasta 128 instancias y precisión mixta de FSDP con bfloat16 para el modelo Llama 2. Comenzamos con una demostración de eficiencias de escalamiento casi lineal para SageMaker, seguido de un análisis de las contribuciones de cada característica para un rendimiento óptimo, y terminamos con un entrenamiento eficiente con varias longitudes de secuencia hasta 32,768 mediante paralelismo tensorial.
Escalado casi lineal con SageMaker
Para reducir el tiempo total de entrenamiento de los modelos LLM, es fundamental preservar un alto rendimiento al escalar a clústeres grandes (miles de GPU), dada la sobrecarga de comunicación entre nodos. En esta publicación, demostramos eficiencias de escalado robusto y casi lineal (variando la cantidad de GPU para un tamaño total fijo del problema) en instancias p4d que invocan tanto SMP como SMDDP.
En esta sección, demostramos el rendimiento de escalamiento casi lineal de SMP. Aquí entrenamos modelos Llama 2 de varios tamaños (parámetros 7B, 13B y 70B) utilizando una longitud de secuencia fija de 4,096, el backend SMDDP para comunicación colectiva, TE habilitado, un tamaño de lote global de 4 millones, con 16 a 128 nodos p4d. . La siguiente tabla resume nuestra configuración óptima y el rendimiento del entrenamiento (modelo de TFLOP por segundo).
| Tamaño del modelo | Numero de nodos | TFLOP* | partido socialdemócrata* | tp* | descargar* | Eficiencia de escalado |
| 7B | 16 | 136.76 | 32 | 1 | N | 100.0% |
| 32 | 132.65 | 64 | 1 | N | 97.0% | |
| 64 | 125.31 | 64 | 1 | N | 91.6% | |
| 128 | 115.01 | 64 | 1 | N | 84.1% | |
| 13B | 16 | 141.43 | 32 | 1 | Y | 100.0% |
| 32 | 139.46 | 256 | 1 | N | 98.6% | |
| 64 | 132.17 | 128 | 1 | N | 93.5% | |
| 128 | 120.75 | 128 | 1 | N | 85.4% | |
| 70B | 32 | 154.33 | 256 | 1 | Y | 100.0% |
| 64 | 149.60 | 256 | 1 | N | 96.9% | |
| 128 | 136.52 | 64 | 2 | N | 88.5% |
*Con el tamaño del modelo, la longitud de la secuencia y la cantidad de nodos dados, mostramos el rendimiento y las configuraciones globalmente óptimos después de explorar varias combinaciones de descarga de activación, sdp y tp.
La tabla anterior resume los números de rendimiento óptimos sujetos al grado de fragmentación paralela de datos (sdp) (generalmente usando fragmentación híbrida FSDP en lugar de fragmentación completa, con más detalles en la siguiente sección), grado de tensor paralelo (tp) y cambios en el valor de descarga de activación. demostrando un escalado casi lineal para SMP junto con SMDDP. Por ejemplo, dado el tamaño del modelo Llama 2 7B y la longitud de secuencia 4,096, en general logra eficiencias de escala del 97.0%, 91.6% y 84.1% (en relación con 16 nodos) en 32, 64 y 128 nodos, respectivamente. Las eficiencias de escala son estables en diferentes tamaños de modelos y aumentan ligeramente a medida que el tamaño del modelo aumenta.
SMP y SMDDP también demuestran eficiencias de escala similares para otras longitudes de secuencia, como 2,048 y 8,192.
Rendimiento de la biblioteca paralela 2.0 del modelo SageMaker: Llama 2 70B
Los tamaños de los modelos han seguido creciendo en los últimos años, junto con frecuentes actualizaciones de rendimiento de última generación en la comunidad LLM. En esta sección, ilustramos el rendimiento en SageMaker para el modelo Llama 2 utilizando un tamaño de modelo fijo de 70B, una longitud de secuencia de 4,096 y un tamaño de lote global de 4 millones. Para comparar con la configuración y el rendimiento globalmente óptimos de la tabla anterior (con backend SMDDP, generalmente fragmentación híbrida FSDP y TE), la siguiente tabla se extiende a otros rendimientos óptimos (potencialmente con paralelismo tensorial) con especificaciones adicionales en el backend distribuido (NCCL y SMDDP). , estrategias de fragmentación FSDP (fragmentación completa y fragmentación híbrida) y habilitar TE o no (predeterminado).
| Tamaño del modelo | Numero de nodos | TFLOPS | Configuración de TFLOP #3 | Mejora de TFLOP con respecto al valor inicial | ||||||||
| . | . | Fragmentación completa de NCCL: #0 | Fragmentación completa SMDDP: #1 | Fragmentación híbrida SMDDP: #2 | Fragmentación híbrida SMDDP con TE: #3 | partido socialdemócrata* | tp* | descargar* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70B | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | - 0.6% | 0.1% | 2.9% | 2.3% |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | 0.0% | 0.7% | 2.9% | 3.6% | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | 50.4% | 26.8% | 4.5% | 99.2% | |
*Con el tamaño del modelo, la longitud de la secuencia y la cantidad de nodos dados, mostramos el rendimiento y la configuración globalmente óptimos después de explorar varias combinaciones de descarga de activación, sdp y tp.
La última versión de SMP y SMDDP admite múltiples funciones, incluido PyTorch FSDP nativo, fragmentación híbrida extendida y más flexible, integración de motor de transformador, paralelismo de tensores y operación colectiva optimizada. Para comprender mejor cómo SageMaker logra una capacitación distribuida eficiente para LLM, exploramos las contribuciones incrementales de SMDDP y el siguiente SMP características principales:
- Mejora de SMDDP sobre NCCL con fragmentación completa de FSDP
- Reemplazar la fragmentación completa de FSDP por fragmentación híbrida, lo que reduce el costo de comunicación para mejorar el rendimiento
- Un impulso adicional al rendimiento con TE, incluso cuando el paralelismo tensorial está desactivado
- En configuraciones de recursos más bajas, la descarga de activación podría permitir un entrenamiento que de otro modo sería inviable o muy lento debido a la alta presión de la memoria.
Fragmentación completa de FSDP: mejora de SMDDP sobre NCCL
Como se muestra en la tabla anterior, cuando los modelos están completamente fragmentados con FSDP, aunque los rendimientos de NCCL (TFLOP #0) y SMDDP (TFLOP #1) son comparables en 32 o 64 nodos, hay una enorme mejora del 50.4 % de NCCL a SMDDP. en 128 nodos.
En tamaños de modelos más pequeños, observamos mejoras consistentes y significativas con SMDDP sobre NCCL, comenzando con tamaños de clúster más pequeños, porque SMDDP puede mitigar el cuello de botella de comunicación de manera efectiva.
Fragmentación híbrida FSDP para reducir el costo de comunicación
En SMP 1.0, lanzamos paralelismo de datos fragmentados, una técnica de formación distribuida impulsada internamente por Amazon micrófonos tecnología. En SMP 2.0, presentamos la fragmentación híbrida SMP, una técnica de fragmentación híbrida extensible y más flexible que permite fragmentar los modelos entre un subconjunto de GPU, en lugar de todas las GPU de entrenamiento, como es el caso de la fragmentación completa FSDP. Es útil para modelos de tamaño mediano que no necesitan fragmentarse en todo el clúster para satisfacer las limitaciones de memoria por GPU. Esto lleva a que los clústeres tengan más de una réplica de modelo y que cada GPU se comunique con menos pares en tiempo de ejecución.
La fragmentación híbrida de SMP permite una fragmentación eficiente del modelo en un rango más amplio, desde el grado de fragmentación más pequeño sin problemas de falta de memoria hasta el tamaño completo del clúster (lo que equivale a una fragmentación completa).
La siguiente figura ilustra la dependencia del rendimiento de sdp en tp = 1 por simplicidad. Aunque no es necesariamente el mismo valor de tp óptimo para la fragmentación completa NCCL o SMDDP en la tabla anterior, los números son bastante cercanos. Valida claramente el valor de cambiar de fragmentación completa a fragmentación híbrida en un tamaño de clúster grande de 128 nodos, que es aplicable tanto a NCCL como a SMDDP. Para tamaños de modelo más pequeños, las mejoras significativas con la fragmentación híbrida comienzan en tamaños de clúster más pequeños y la diferencia sigue aumentando con el tamaño del clúster.
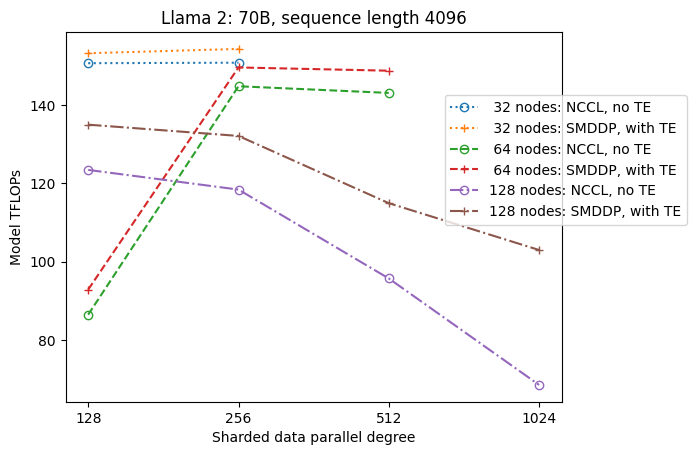
Mejoras con TE
TE está diseñado para acelerar la formación LLM en GPU NVIDIA. A pesar de no usar FP8 porque no es compatible con instancias de p4d, todavía vemos una aceleración significativa con TE en p4d.
Además de MiCS entrenado con el backend SMDDP, TE introduce un aumento constante del rendimiento en todos los tamaños de clúster (la única excepción es la fragmentación completa en 128 nodos), incluso cuando el paralelismo del tensor está deshabilitado (el grado de paralelo del tensor es 1).
Para tamaños de modelos más pequeños o varias longitudes de secuencia, el impulso TE es estable y no trivial, en el rango de aproximadamente 3 a 7.6%.
Descarga de activación en configuraciones de bajos recursos
En configuraciones de recursos bajos (dada una pequeña cantidad de nodos), FSDP puede experimentar una alta presión de memoria (o incluso falta de memoria en el peor de los casos) cuando el punto de control de activación está habilitado. Para escenarios con cuellos de botella debido a la memoria, activar la descarga de activación es potencialmente una opción para mejorar el rendimiento.
Por ejemplo, como vimos anteriormente, aunque Llama 2 con un tamaño de modelo 13B y una longitud de secuencia de 4,096 es capaz de entrenar de manera óptima con al menos 32 nodos con puntos de control de activación y sin descarga de activación, logra el mejor rendimiento con descarga de activación cuando se limita a 16. nodos.
Habilitar el entrenamiento con secuencias largas: paralelismo tensor SMP
Se desean secuencias más largas para conversaciones y contexto prolongados, y están recibiendo más atención en la comunidad LLM. Por lo tanto, en la siguiente tabla informamos varios rendimientos de secuencia larga. La tabla muestra los rendimientos óptimos para el entrenamiento de Llama 2 en SageMaker, con varias longitudes de secuencia desde 2,048 hasta 32,768. Con una longitud de secuencia de 32,768 32, el entrenamiento FSDP nativo no es factible con 4 nodos en un tamaño de lote global de XNUMX millones.
| . | . | . | TFLOPS | ||
| Tamaño del modelo | Longitud de la secuencia | Numero de nodos | FSDP y NCCL nativos | SMP y SMDDP | Mejora del SMP |
| 7B | 2048 | 32 | 129.25 | 138.17 | 6.9% |
| 4096 | 32 | 124.38 | 132.65 | 6.6% | |
| 8192 | 32 | 115.25 | 123.11 | 6.8% | |
| 16384 | 32 | 100.73 | 109.11 | 8.3% | |
| 32768 | 32 | N / A | 82.87 | . | |
| 13B | 2048 | 32 | 137.75 | 144.28 | 4.7% |
| 4096 | 32 | 133.30 | 139.46 | 4.6% | |
| 8192 | 32 | 125.04 | 130.08 | 4.0% | |
| 16384 | 32 | 111.58 | 117.01 | 4.9% | |
| 32768 | 32 | N / A | 92.38 | . | |
| *: máx. | . | . | . | . | 8.3% |
| *: mediana | . | . | . | . | 5.8% |
Cuando el tamaño del clúster es grande y se le da un tamaño de lote global fijo, es posible que parte del entrenamiento del modelo no sea factible con PyTorch FSDP nativo, ya que carece de una canalización incorporada o soporte de paralelismo tensorial. En la tabla anterior, dado un tamaño de lote global de 4 millones, 32 nodos y una longitud de secuencia de 32,768, el tamaño de lote efectivo por GPU es 0.5 (por ejemplo, tp = 2 con un tamaño de lote 1), que de otro modo no sería factible sin introducir paralelismo tensorial.
Conclusión
En esta publicación, demostramos una capacitación LLM eficiente con SMP y SMDDP en instancias p4d, atribuyendo contribuciones a múltiples características clave, como la mejora de SMDDP sobre NCCL, fragmentación híbrida FSDP flexible en lugar de fragmentación completa, integración TE y habilitación del paralelismo tensorial a favor de longitudes de secuencia largas. Después de ser probado en una amplia gama de configuraciones con varios modelos, tamaños de modelo y longitudes de secuencia, exhibe eficiencias de escalamiento casi lineales sólidas, hasta 128 instancias de p4d en SageMaker. En resumen, SageMaker sigue siendo una herramienta poderosa para los investigadores y profesionales de LLM.
Para obtener más información, consulte Biblioteca de paralelismo de modelos SageMaker v2o póngase en contacto con el equipo de SMP en sm-modelo-paralelo-feedback@amazon.com.
Agradecimientos
Nos gustaría agradecer a Robert Van Dusen, Ben Snyder, Gautam Kumar y Luis Quintela por sus comentarios y debates constructivos.
Acerca de los autores

Xinle Sheila Liu es un SDE en Amazon SageMaker. En su tiempo libre le gusta la lectura y los deportes al aire libre.
 Suhit Kódgule es ingeniero de desarrollo de software en el grupo de inteligencia artificial de AWS que trabaja en marcos de aprendizaje profundo. En su tiempo libre le gusta hacer senderismo, viajar y cocinar.
Suhit Kódgule es ingeniero de desarrollo de software en el grupo de inteligencia artificial de AWS que trabaja en marcos de aprendizaje profundo. En su tiempo libre le gusta hacer senderismo, viajar y cocinar.
 Víctor Zhu es Ingeniero de Software en Aprendizaje Profundo Distribuido en Amazon Web Services. Se le puede encontrar disfrutando de caminatas y juegos de mesa en el Área de la Bahía de San Francisco.
Víctor Zhu es Ingeniero de Software en Aprendizaje Profundo Distribuido en Amazon Web Services. Se le puede encontrar disfrutando de caminatas y juegos de mesa en el Área de la Bahía de San Francisco.
 Derya Cavdar Trabaja como ingeniero de software en AWS. Sus intereses incluyen el aprendizaje profundo y la optimización de la capacitación distribuida.
Derya Cavdar Trabaja como ingeniero de software en AWS. Sus intereses incluyen el aprendizaje profundo y la optimización de la capacitación distribuida.
 Teng Xu es Ingeniero de Desarrollo de Software en el grupo de Capacitación Distribuida en AWS AI. Le gusta leer.
Teng Xu es Ingeniero de Desarrollo de Software en el grupo de Capacitación Distribuida en AWS AI. Le gusta leer.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/distributed-training-and-efficient-scaling-with-the-amazon-sagemaker-model-parallel-and-data-parallel-libraries/

