
Imagen del autor
La orquestación de datos se ha convertido en un componente crítico de la ingeniería de datos moderna, lo que permite a los equipos optimizar y automatizar sus flujos de trabajo de datos. Si bien Apache Airflow es una herramienta ampliamente utilizada conocida por su flexibilidad y su sólido apoyo comunitario. Sin embargo, existen otras alternativas que ofrecen características y beneficios únicos.
En esta publicación de blog, discutiremos cinco alternativas para administrar flujos de trabajo: Prefect, Dagster, Luigi, Mage AI y Kedro. Estas herramientas se pueden utilizar en cualquier campo, no solo en la ingeniería de datos. Al comprender estas herramientas, podrá elegir la que mejor se adapte a sus necesidades de flujo de trabajo de datos y aprendizaje automático.
Prefecto es una herramienta de código abierto para crear y gestionar flujos de trabajo, proporcionando capacidades de observabilidad y clasificación. Puede crear aplicaciones de flujo de trabajo interactivas utilizando unas pocas líneas de código Python.
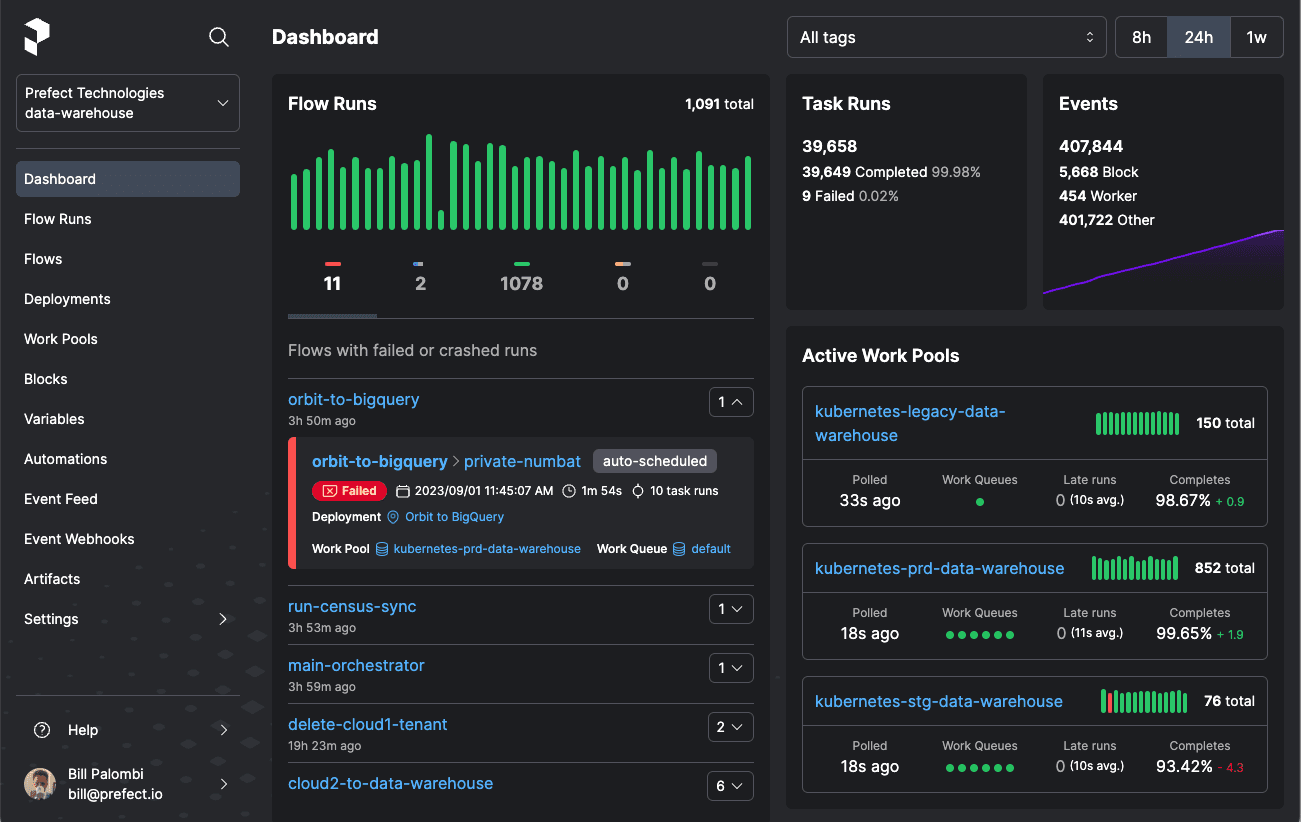
Prefect ofrece un modelo de ejecución híbrido que permite que los flujos de trabajo se ejecuten en la nube o en las instalaciones, brindando a los usuarios un mayor control sobre sus operaciones de datos. Su interfaz de usuario intuitiva y su API enriquecida permiten un fácil monitoreo y resolución de problemas de los flujos de trabajo de datos.
daga es un potente orquestador de canalización de datos de código abierto que simplifica el desarrollo, el mantenimiento y la observación de los activos de datos durante todo su ciclo de vida. Diseñado para entornos nativos de la nube, Dagster ofrece linaje de datos integrado, observabilidad y un entorno de desarrollo fácil de usar, lo que lo convierte en una opción popular para ingenieros de datos, científicos de datos e ingenieros de aprendizaje automático.
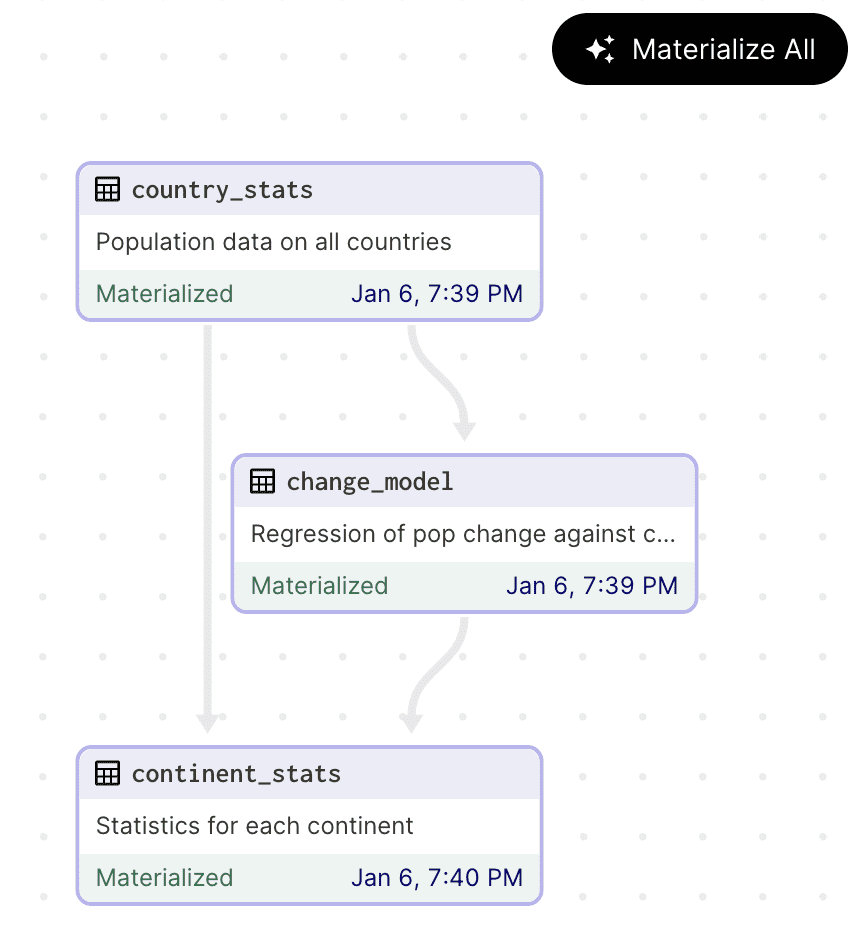
Dagster es un sistema de orquestación de datos de código abierto que permite a los usuarios definir sus activos de datos como funciones de Python. Una vez definidas, Dagster administra y ejecuta estas funciones según un cronograma definido por el usuario o en respuesta a eventos específicos. Dagster se puede utilizar en cada etapa del ciclo de vida del desarrollo de datos, desde el desarrollo local y las pruebas unitarias hasta las pruebas de integración, los entornos de ensayo y la producción.
Luigi, desarrollado por Spotify, es un marco basado en Python para crear canales complejos de trabajos por lotes. Maneja la resolución de dependencias, la gestión del flujo de trabajo, la visualización y más, centrándose en la confiabilidad y la escalabilidad.
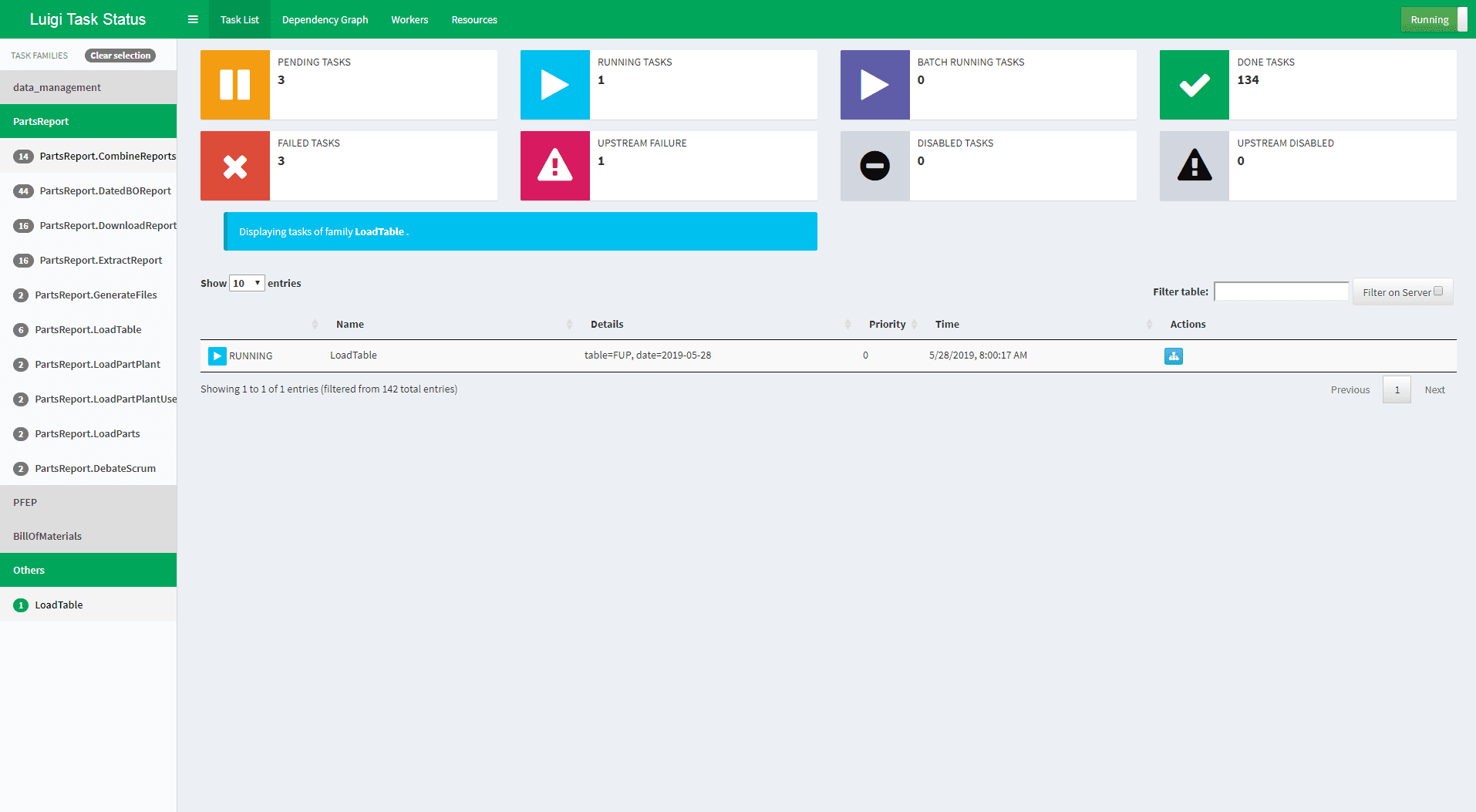
Luigi es una herramienta poderosa que se destaca en la gestión de dependencias de tareas, asegurando que las tareas se ejecuten en el orden correcto y solo si se cumplen sus dependencias. Es particularmente adecuado para flujos de trabajo que involucran una combinación de trabajos de Hadoop, scripts de Python y otros procesos por lotes.
Luigi proporciona una infraestructura que admite diversas operaciones, incluidas recomendaciones, listas principales, análisis de pruebas A/B, informes externos, paneles internos, etc.
Mago IA es un participante más reciente en el espacio de la orquestación de datos, que ofrece un marco híbrido para transformar e integrar datos, combinando la flexibilidad de las computadoras portátiles con el rigor del código modular. Está diseñado para agilizar el proceso de extracción, transformación y carga de datos, permitiendo a los usuarios trabajar con datos de una manera más eficiente y fácil de usar.
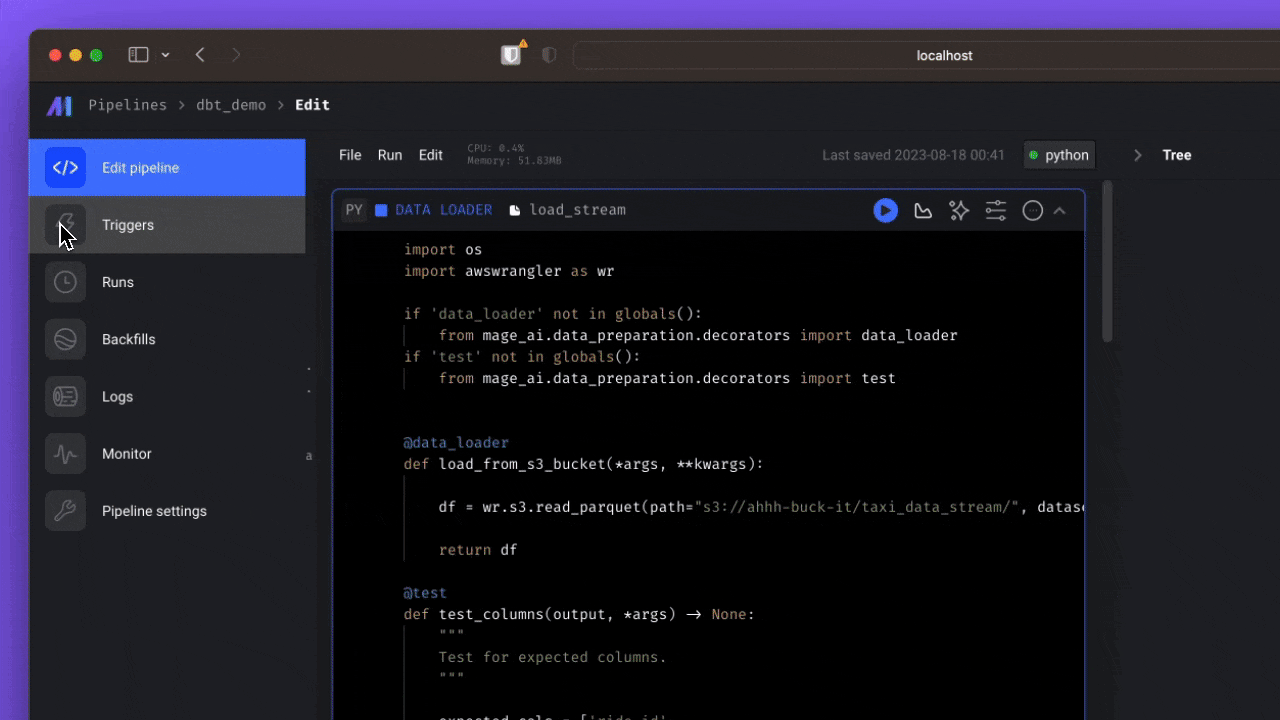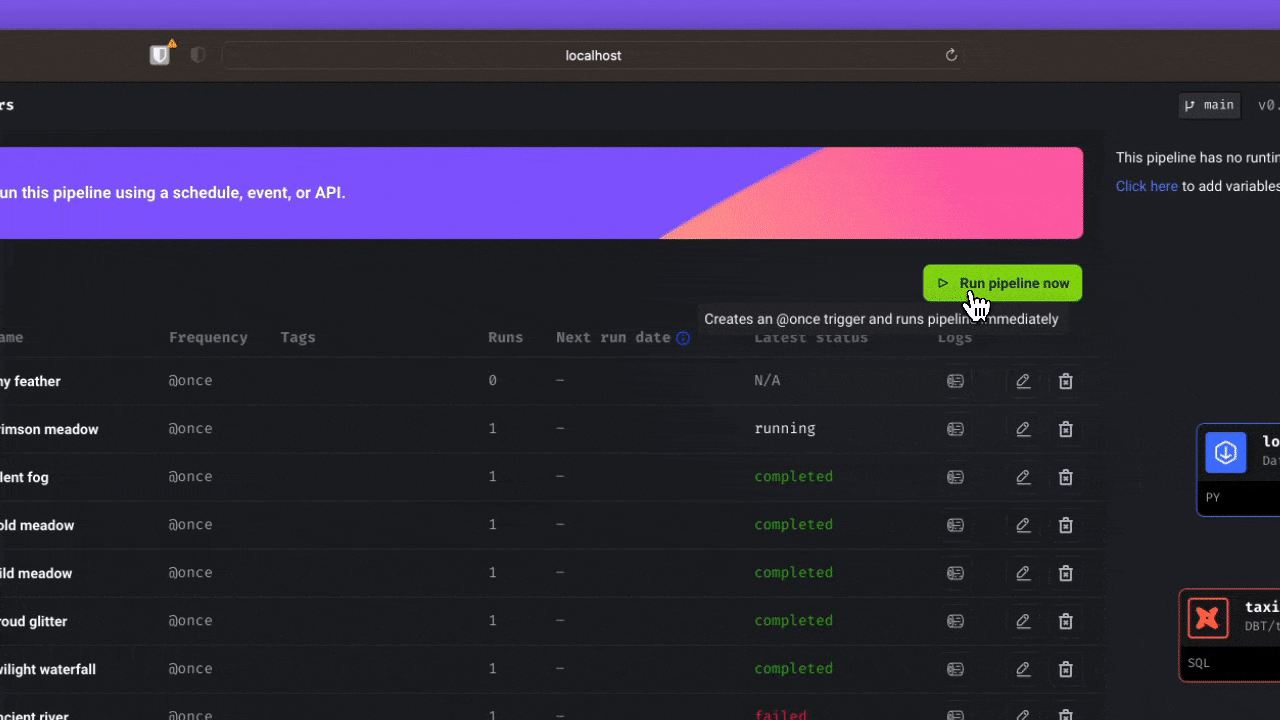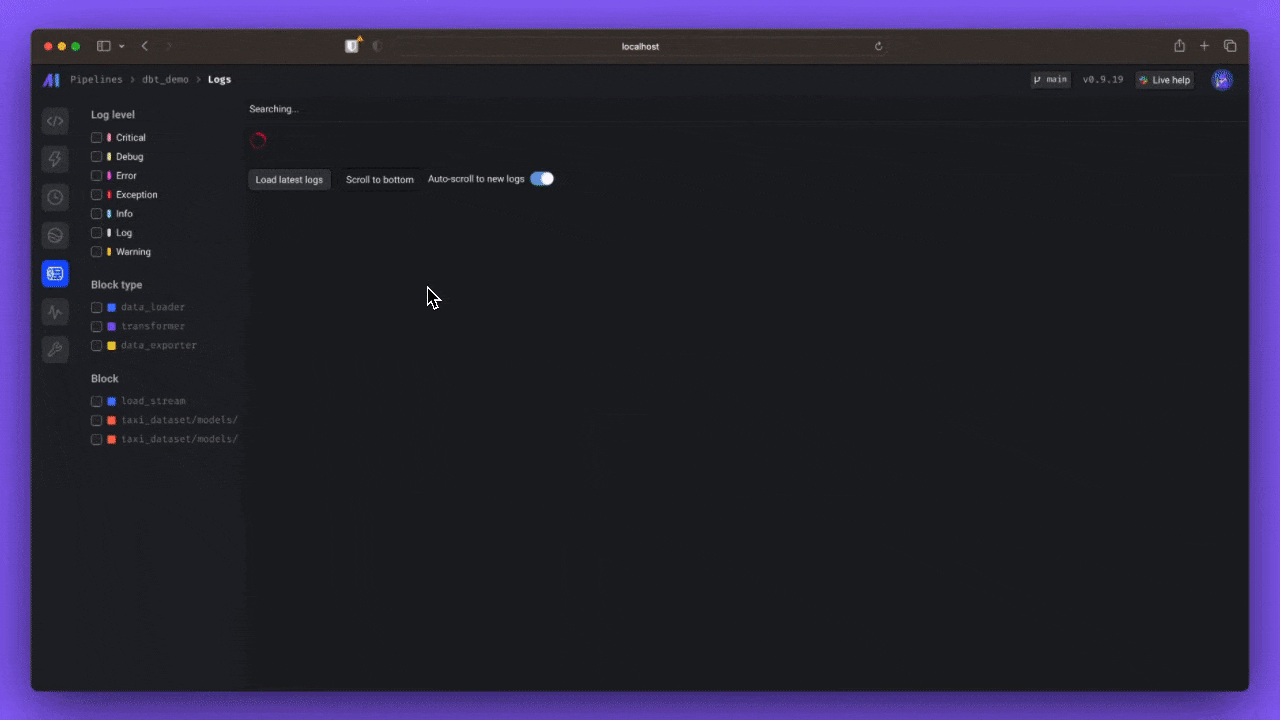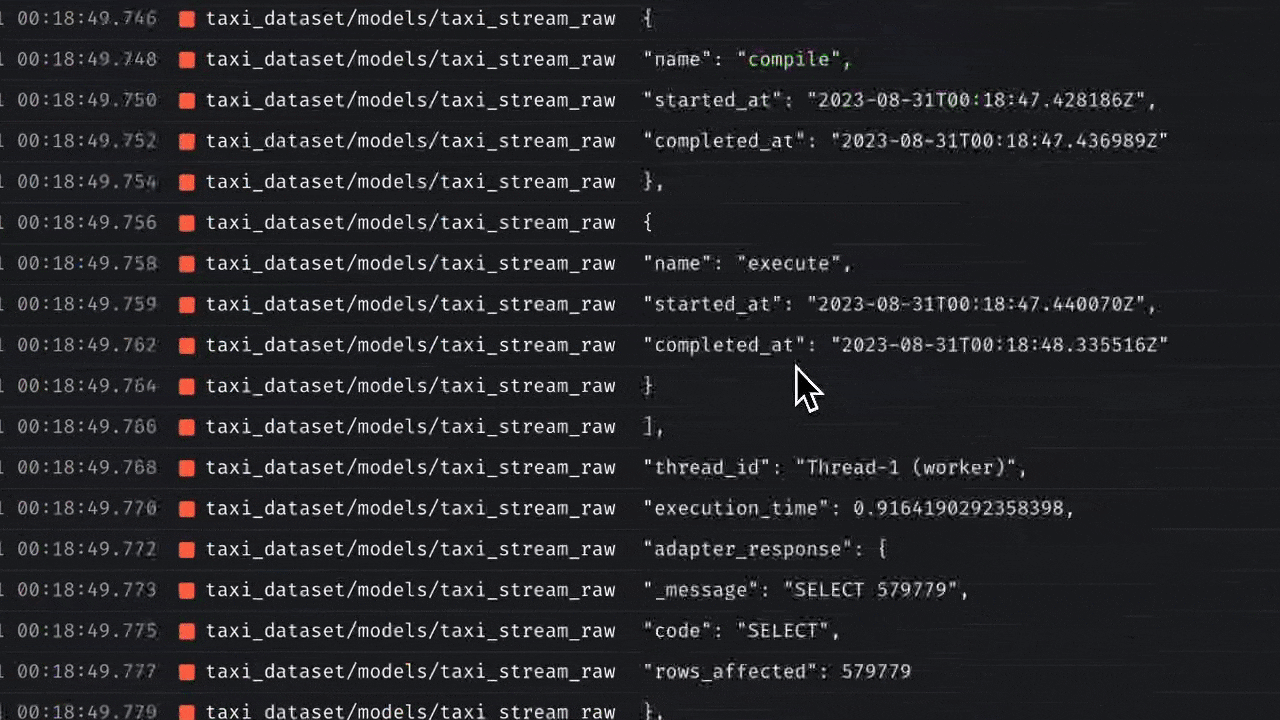
Mage AI proporciona una experiencia de desarrollador sencilla, admite múltiples lenguajes de programación y permite el desarrollo colaborativo. Sus funciones integradas de monitoreo, alertas y observabilidad lo hacen ideal para canalizaciones de datos complejas y a gran escala. Mage AI también admite dbt para crear, ejecutar y administrar modelos dbt.
Kedro es un marco de Python que proporciona una forma estandarizada de crear canales de datos y aprendizaje automático. Utiliza las mejores prácticas de ingeniería de software para ayudarle a crear procesos de ingeniería y ciencia de datos que sean reproducibles, mantenibles y modulares.
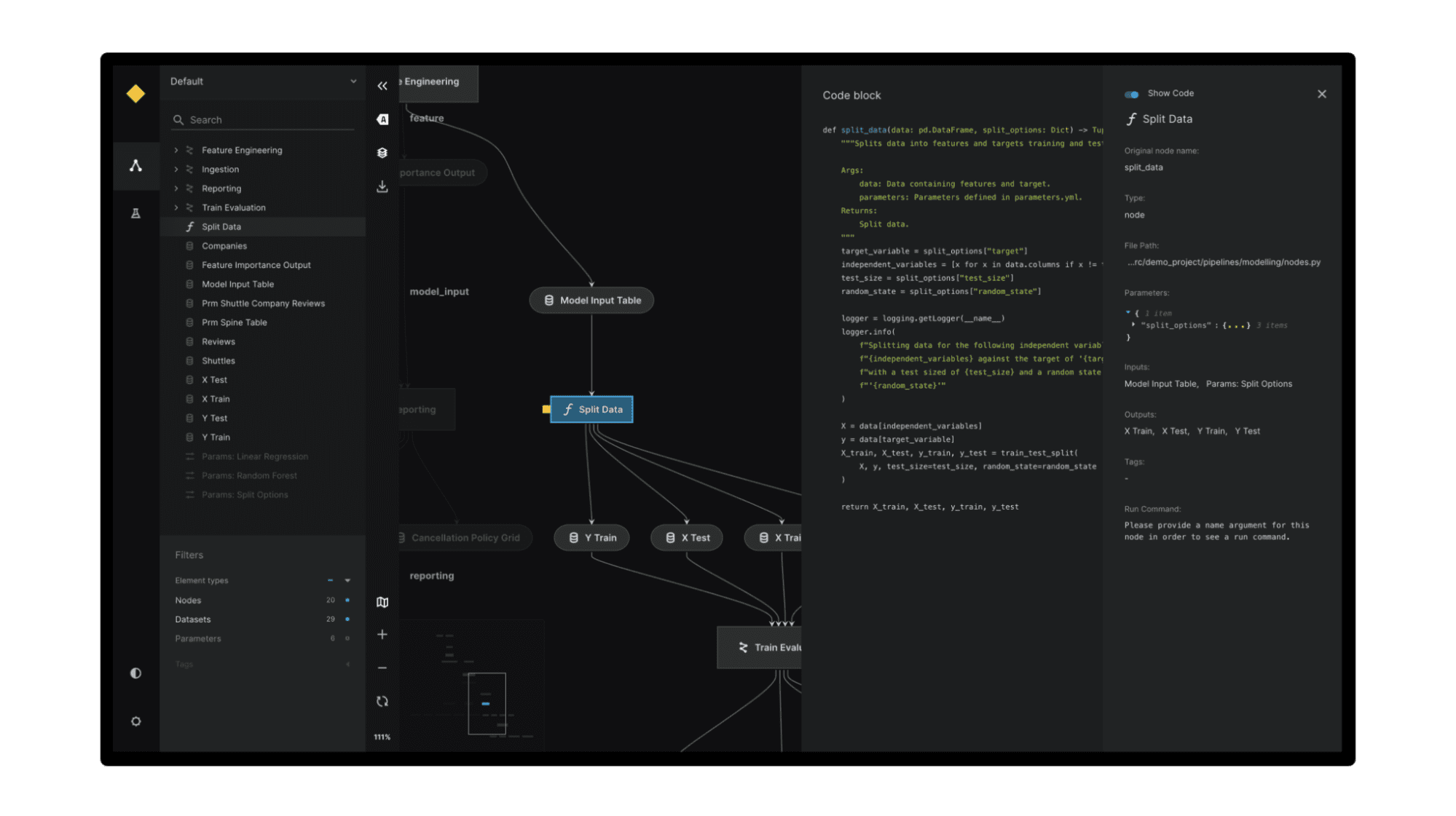
Kedro proporciona una plantilla de proyecto estandarizada, conectores de datos, abstracción de canalizaciones, estándares de codificación y opciones de implementación flexibles, que simplifican el proceso de creación, prueba e implementación de proyectos de ciencia de datos. Al utilizar Kedro, los científicos de datos pueden garantizar una estructura de proyecto coherente y organizada, gestionar fácilmente el control de versiones de datos y modelos, automatizar las dependencias de canalización e implementar proyectos en varias plataformas.
Si bien Apache Airflow sigue siendo una herramienta popular para la orquestación de datos, las alternativas presentadas aquí ofrecen una variedad de características y beneficios que pueden adaptarse mejor a ciertos proyectos o preferencias del equipo. Ya sea que priorice la simplicidad, el diseño centrado en el código o la integración de flujos de trabajo de aprendizaje automático, es probable que exista una alternativa que satisfaga sus necesidades. Al explorar estas opciones, los equipos pueden encontrar la herramienta adecuada para mejorar sus operaciones de datos e impulsar más valor de sus iniciativas de datos.
Si es nuevo en el campo de la ingeniería de datos, considere tomar el Curso Profesional de Ingeniería de Datos para estar listo para trabajar y comenzar a ganar $ 300 mil al año.
Abid Ali Awan (@ 1abidaliawan) es un profesional científico de datos certificado al que le encanta crear modelos de aprendizaje automático. Actualmente, se está enfocando en la creación de contenido y escribiendo blogs técnicos sobre aprendizaje automático y tecnologías de ciencia de datos. Abid tiene una Maestría en Gestión de Tecnología y una licenciatura en Ingeniería de Telecomunicaciones. Su visión es construir un producto de IA utilizando una red neuronal gráfica para estudiantes que luchan contra enfermedades mentales.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/5-airflow-alternatives-for-data-orchestration?utm_source=rss&utm_medium=rss&utm_campaign=5-airflow-alternatives-for-data-orchestration

