
Generado con Midjourney
La conferencia NeurIPS 2023, celebrada en la vibrante ciudad de Nueva Orleans del 10 al 16 de diciembre, tuvo especial énfasis en la IA generativa y los grandes modelos de lenguaje (LLM). A la luz de los recientes avances innovadores en este ámbito, no fue una sorpresa que estos temas dominaran las discusiones.
Uno de los temas centrales de la conferencia de este año fue la búsqueda de sistemas de inteligencia artificial más eficientes. Los investigadores y desarrolladores están buscando activamente formas de construir una IA que no sólo aprenda más rápido que los LLM actuales, sino que también posea capacidades de razonamiento mejoradas y al mismo tiempo consuma menos recursos informáticos. Esta búsqueda es crucial en la carrera hacia el logro de la Inteligencia General Artificial (AGI), un objetivo que parece cada vez más alcanzable en el futuro previsible.
Las charlas invitadas en NeurIPS 2023 fueron un reflejo de estos intereses dinámicos y en rápida evolución. Presentadores de diversas esferas de la investigación de la IA compartieron sus últimos logros y ofrecieron una ventana a los desarrollos de IA de vanguardia. En este artículo, profundizamos en estas charlas, extrayendo y discutiendo las conclusiones y aprendizajes clave, que son esenciales para comprender los panoramas actuales y futuros de la innovación en IA.
NextGenAI: la ilusión del escalamiento y el futuro de la IA generativa
In su charla, Björn Ommer, jefe del grupo de aprendizaje y visión por computadora de la Universidad Ludwig Maximilian de Munich, compartió cómo su laboratorio llegó a desarrollar la difusión estable, algunas lecciones que aprendieron de este proceso y los desarrollos recientes, incluido cómo podemos combinar modelos de difusión con coincidencia de flujo, aumento de recuperación y aproximaciones LoRA, entre otros.
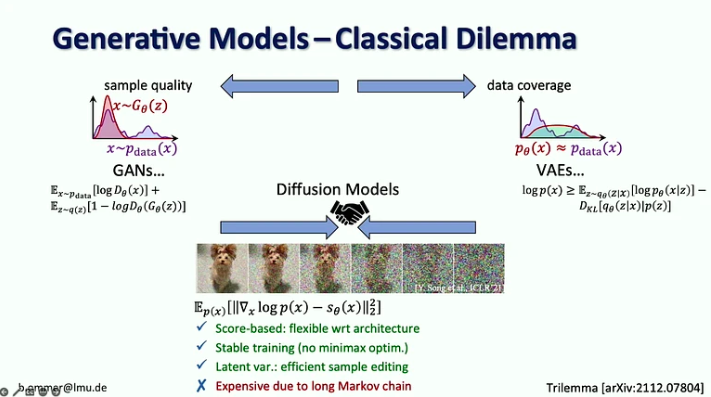
Puntos clave:
- En la era de la IA generativa, pasamos del enfoque en la percepción en los modelos de visión (es decir, el reconocimiento de objetos) a la predicción de las partes faltantes (por ejemplo, la generación de imágenes y videos con modelos de difusión).
- Durante 20 años, la visión por computadora se centró en la investigación de referencia, lo que ayudó a centrarse en los problemas más destacados. En la IA generativa, no tenemos puntos de referencia para optimizar, lo que abrió el campo para que cada uno vaya en su propia dirección.
- Los modelos de difusión combinan las ventajas de los modelos generativos anteriores al estar basados en puntuaciones con un procedimiento de entrenamiento estable y una edición eficiente de muestras, pero son costosos debido a su larga cadena de Markov.
- El desafío con los modelos de probabilidad fuerte es que la mayoría de los bits entran en detalles que son apenas perceptibles para el ojo humano, mientras que la codificación semántica, que es la más importante, requiere sólo unos pocos bits. El escalamiento por sí solo no resolvería este problema porque la demanda de recursos informáticos está creciendo nueve veces más rápido que la oferta de GPU.
- La solución sugerida es combinar las fortalezas de los modelos de difusión y ConvNets, particularmente la eficiencia de las convoluciones para representar detalles locales y la expresividad de los modelos de difusión para contextos de largo alcance.
- Björn Ommer también sugiere utilizar un enfoque de coincidencia de flujo para permitir la síntesis de imágenes de alta resolución a partir de pequeños modelos de difusión latente.
- Otro enfoque para aumentar la eficiencia de la síntesis de imágenes es centrarse en la composición de la escena mientras se utiliza el aumento de recuperación para completar los detalles.
- Finalmente, presentó el enfoque iPoke para la síntesis de vídeo estocástica controlada.
Si este contenido detallado es útil para usted, suscríbase a nuestra lista de correo de IA ser alertado cuando lancemos nuevo material.
Las muchas caras de la IA responsable
In su presentación, Lora Aroyo, científica investigadora de Google Research, destacó una limitación clave en los enfoques tradicionales de aprendizaje automático: su dependencia de categorizaciones binarias de datos como ejemplos positivos o negativos. Esta simplificación excesiva, argumentó, pasa por alto la compleja subjetividad inherente a los escenarios y contenidos del mundo real. A través de varios casos de uso, Aroyo demostró cómo la ambigüedad del contenido y la variación natural en los puntos de vista humanos a menudo conducen a desacuerdos inevitables. Hizo hincapié en la importancia de tratar estos desacuerdos como señales significativas y no como simples ruidos.

Estas son las conclusiones clave de la charla:
- El desacuerdo entre los laboratorios humanos puede ser productivo. En lugar de tratar todas las respuestas como correctas o incorrectas, Lora Aroyo introdujo la “verdad por desacuerdo”, un enfoque de verdad distributiva para evaluar la confiabilidad de los datos aprovechando el desacuerdo de los evaluadores.
- La calidad de los datos es difícil incluso con los expertos porque los expertos no están de acuerdo tanto como los expertos. Estos desacuerdos pueden ser mucho más informativos que las respuestas de un solo experto.
- En las tareas de evaluación de la seguridad, los expertos no están de acuerdo en el 40% de los ejemplos. En lugar de intentar resolver estos desacuerdos, necesitamos recopilar más ejemplos de este tipo y utilizarlos para mejorar los modelos y las métricas de evaluación.
- Lora Aroyo también presentó su Seguridad con Diversidad Método para examinar los datos en términos de qué contienen y quién los ha anotado.
- Este método produjo un conjunto de datos de referencia con variabilidad en los juicios de seguridad de LLM entre varios grupos demográficos de evaluadores (2.5 millones de calificaciones en total).
- Para el 20% de las conversaciones, fue difícil decidir si la respuesta del chatbot era segura o insegura, ya que hubo aproximadamente el mismo número de encuestados que las etiquetaron como seguras o inseguras.
- La diversidad de evaluadores y datos juega un papel crucial en la evaluación de modelos. No reconocer la amplia gama de perspectivas humanas y la ambigüedad presente en el contenido puede obstaculizar la alineación del rendimiento del aprendizaje automático con las expectativas del mundo real.
- El 80% de los esfuerzos de seguridad de la IA ya son bastante buenos, pero el 20% restante requiere duplicar el esfuerzo para abordar los casos extremos y todas las variantes en el espacio infinito de la diversidad.
Estadísticas de coherencia, experiencia autogenerada y por qué los humanos jóvenes son mucho más inteligentes que la IA actual
In su charla, Linda Smith, profesora distinguida de la Universidad de Indiana en Bloomington, exploró el tema de la escasez de datos en los procesos de aprendizaje de bebés y niños pequeños. Se centró específicamente en el reconocimiento de objetos y el aprendizaje de nombres, profundizando en cómo las estadísticas de experiencias autogeneradas por los bebés ofrecen soluciones potenciales al desafío de la escasez de datos.
Puntos clave:
- A la edad de tres años, los niños han desarrollado la capacidad de aprender de una sola vez en varios ámbitos. En menos de 16,000 horas de vigilia antes de cumplir cuatro años, logran aprender más de 1,000 categorías de objetos, dominar la sintaxis de su lengua materna y absorber los matices culturales y sociales de su entorno.
- La Dra. Linda Smith y su equipo descubrieron tres principios del aprendizaje humano que permiten a los niños captar mucho de datos tan escasos:
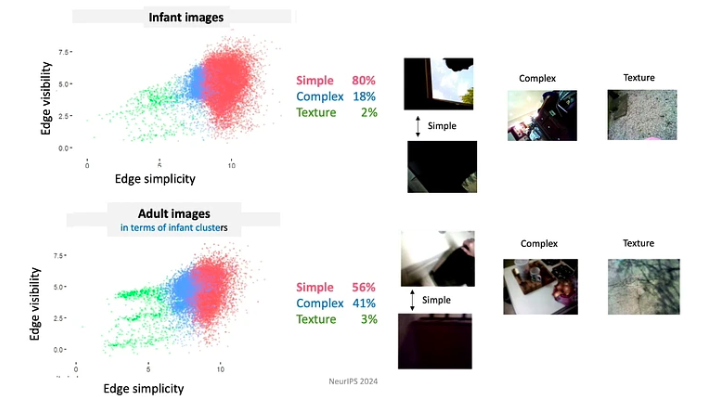
- Los alumnos controlan la entrada y, momento a momento, le dan forma y estructuran. Por ejemplo, durante los primeros meses de vida, los bebés tienden a mirar más objetos con bordes simples.
- Dado que los bebés evolucionan continuamente en sus conocimientos y capacidades, siguen un plan de estudios muy restringido. Los datos a los que están expuestos están organizados de maneras profundamente significativas. Por ejemplo, los bebés menores de 4 meses pasan la mayor parte del tiempo mirando caras, aproximadamente 15 minutos por hora, mientras que los mayores de 12 meses se centran principalmente en las manos, observándolas durante unos 20 minutos por hora.
- Los episodios de aprendizaje consisten en una serie de experiencias interconectadas. Las correlaciones espaciales y temporales crean coherencia, lo que a su vez facilita la formación de recuerdos duraderos a partir de acontecimientos únicos. Por ejemplo, cuando se les presenta una variedad aleatoria de juguetes, los niños a menudo se centran en unos pocos juguetes "favoritos". Se involucran con estos juguetes usando patrones repetitivos, lo que ayuda a aprender más rápido los objetos.
- Los recuerdos transitorios (de trabajo) persisten más que la información sensorial. Las propiedades que mejoran el proceso de aprendizaje incluyen la multimodalidad, las asociaciones, las relaciones predictivas y la activación de recuerdos pasados.
- Para un aprendizaje rápido, se necesita una alianza entre los mecanismos que generan los datos y los mecanismos que aprenden.
Dibujo: herramientas básicas, aumento del aprendizaje y solidez adaptativa
Jelani Nelson, profesora de Ingeniería Eléctrica y Ciencias de la Computación en UC Berkeley, introdujo el concepto de “bocetos” de datos – una representación comprimida en memoria de un conjunto de datos que aún permite responder consultas útiles. Aunque la charla fue bastante técnica, brindó una excelente descripción general de algunas herramientas fundamentales de dibujo, incluidos los avances recientes.
Conclusiones clave:
- CountSketch, la herramienta principal de dibujo, se introdujo por primera vez en 2002 para abordar el problema de los "grandes bateadores", informando una pequeña lista de los elementos más frecuentes de un flujo de elementos determinado. CountSketch fue el primer algoritmo sublineal conocido utilizado para este propósito.
- Dos aplicaciones de grandes bateadores que no son de transmisión incluyen:
- Método basado en puntos interiores (IPM) que proporciona un algoritmo conocido asintóticamente más rápido para programación lineal.
- Método HyperAttention que aborda el desafío computacional planteado por la creciente complejidad de los contextos largos utilizados en los LLM.
- Gran parte del trabajo reciente se ha centrado en diseñar bocetos que sean sólidos para la interacción adaptativa. La idea principal es utilizar conocimientos del análisis de datos adaptativos.
Más allá del panel de escala
Este gran panel sobre modelos de lenguaje grandes fue moderado por Alexander Rush, profesor asociado de Cornell Tech e investigador de Hugging Face. Los otros participantes incluyeron:
- Aakanksha Chowdhery: investigador científico en Google DeepMind con intereses de investigación en sistemas, formación previa en LLM y multimodalidad. Formó parte del equipo que desarrolló PaLM, Gemini y Pathways.
- Angela Fan: científica investigadora en Meta Generative AI con intereses de investigación en alineación, centros de datos y multilingüismo. Participó en el desarrollo de Llama-2 y Meta AI Assistant.
- Percy Liang: profesor de Stanford que investiga creadores, código abierto y agentes generativos. Es el Director del Centro de Investigación sobre Modelos de Fundaciones (CRFM) en Stanford y el fundador de Together AI.
La discusión se centró en cuatro temas clave: (1) arquitecturas e ingeniería, (2) datos y alineación, (3) evaluación y transparencia, y (4) creadores y contribuyentes.
Estas son algunas de las conclusiones de este panel:
- Entrenar los modelos lingüísticos actuales no es intrínsecamente difícil. El principal desafío al entrenar un modelo como Llama-2-7b radica en los requisitos de infraestructura y la necesidad de coordinar entre múltiples GPU, centros de datos, etc. Sin embargo, si la cantidad de parámetros es lo suficientemente pequeña como para permitir el entrenamiento en una sola GPU, Incluso un estudiante universitario puede manejarlo.
- Si bien los modelos autorregresivos se suelen utilizar para la generación de texto y los modelos de difusión para generar imágenes y vídeos, se han realizado experimentos para revertir estos enfoques. Específicamente, en el proyecto Gemini, se utiliza un modelo autorregresivo para la generación de imágenes. También se han realizado exploraciones sobre el uso de modelos de difusión para la generación de texto, pero aún no han demostrado ser suficientemente efectivos.
- Dada la disponibilidad limitada de datos en inglés para modelos de entrenamiento, los investigadores están explorando enfoques alternativos. Una posibilidad es entrenar modelos multimodales con una combinación de texto, video, imágenes y audio, con la expectativa de que las habilidades aprendidas de estas modalidades alternativas puedan transferirse al texto. Otra opción es el uso de datos sintéticos. Es importante señalar que los datos sintéticos a menudo se mezclan con datos reales, pero esta integración no es aleatoria. El texto publicado en línea suele ser curado y editado por humanos, lo que podría agregar valor adicional para la capacitación de modelos.
- Los modelos de base abierta suelen considerarse beneficiosos para la innovación, pero potencialmente perjudiciales para la seguridad de la IA, ya que pueden ser explotados por actores malintencionados. Sin embargo, el Dr. Percy Liang sostiene que los modelos abiertos también contribuyen positivamente a la seguridad. Sostiene que, al ser accesibles, brindan a más investigadores oportunidades para realizar investigaciones sobre la seguridad de la IA y revisar los modelos en busca de posibles vulnerabilidades.
- Hoy en día, anotar datos exige mucha más experiencia en el ámbito de la anotación en comparación con hace cinco años. Sin embargo, si los asistentes de IA funcionan como se espera en el futuro, recibiremos datos de retroalimentación más valiosos de los usuarios, lo que reducirá la dependencia de datos extensos de los anotadores.
Sistemas para modelos de cimentación y modelos de cimentación para sistemas
In esta charla, Christopher Ré, profesor asociado del Departamento de Ciencias de la Computación de la Universidad de Stanford, muestra cómo los modelos básicos cambiaron los sistemas que construimos. También explora cómo construir modelos básicos de manera eficiente, tomando prestados conocimientos de la investigación de sistemas de bases de datos y analiza arquitecturas potencialmente más eficientes para modelos básicos que Transformer.
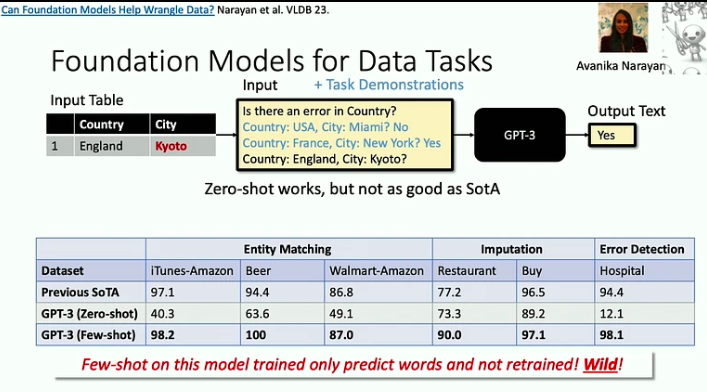
Estas son las conclusiones clave de esta charla:
- Los modelos de cimentación son eficaces para abordar problemas de “muerte por 1000 cortes”, donde cada tarea individual puede ser relativamente simple, pero la amplitud y variedad de tareas presentan un desafío importante. Un buen ejemplo de esto es el problema de la limpieza de datos, que los LLM ahora pueden ayudar a resolver de manera mucho más eficiente.
- A medida que los aceleradores se vuelven más rápidos, la memoria a menudo surge como un cuello de botella. Este es un problema que los investigadores de bases de datos han estado abordando durante décadas y podemos adoptar algunas de sus estrategias. Por ejemplo, el enfoque Flash Attention minimiza los flujos de entrada y salida mediante bloqueo y fusión agresiva: cada vez que accedemos a una información, realizamos tantas operaciones como sea posible.
- Existe una nueva clase de arquitecturas, basada en el procesamiento de señales, que podría ser más eficiente que el modelo Transformer, especialmente en el manejo de secuencias largas. El procesamiento de señales ofrece estabilidad y eficiencia, sentando las bases para modelos innovadores como el S4.
Aprendizaje de refuerzo en línea en intervenciones de salud digital
In su charla, Susan Murphy, profesora de Estadística e Informática de la Universidad de Harvard, compartió las primeras soluciones a algunos de los desafíos que enfrentan en el desarrollo de algoritmos de RL en línea para su uso en intervenciones de salud digital.
Aquí hay algunas conclusiones de la presentación:
- La Dra. Susan Murphy habló sobre dos proyectos en los que ha estado trabajando:
- HeartStep, donde se han sugerido actividades basadas en datos de teléfonos inteligentes y rastreadores portátiles, y
- Orallytics para el asesoramiento en salud bucal, donde las intervenciones se basaron en datos de participación recibidos de un cepillo de dientes electrónico.
- Al desarrollar una política de comportamiento para un agente de IA, los investigadores deben garantizar que sea autónoma y que pueda implementarse de manera factible en el sistema de salud más amplio. Esto implica garantizar que el tiempo necesario para la participación de una persona sea razonable y que las acciones recomendadas sean éticamente sólidas y científicamente plausibles.
- Los principales desafíos en el desarrollo de un agente de RL para intervenciones de salud digital incluyen lidiar con altos niveles de ruido, ya que las personas llevan sus vidas y es posible que no siempre puedan responder a los mensajes, incluso si lo desean, así como también manejar efectos negativos fuertes y retardados. .
Como puede ver, NeurIPS 2023 ha brindado una visión esclarecedora del futuro de la IA. Las charlas invitadas destacaron una tendencia hacia modelos más eficientes y conscientes de los recursos y la exploración de arquitecturas novedosas más allá de los paradigmas tradicionales.
¿Disfrutas este artículo? Regístrese para obtener más actualizaciones de investigación de IA.
Le informaremos cuando publiquemos más artículos de resumen como este.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.topbots.com/neurips-2023-invited-talks/

