
La arquitectura de microservicios promueve la creación de servicios flexibles e independientes con límites bien definidos. Este enfoque escalable permite a los desarrolladores mantener y desarrollar servicios individualmente sin afectar toda la aplicación. Sin embargo, para aprovechar todo el potencial de la arquitectura de microservicios, particularmente para aplicaciones de chat impulsadas por IA, se requiere una integración sólida con los últimos modelos de lenguaje grande (LLM) como Meta Llama V2 y ChatGPT de OpenAI y otros lanzamientos optimizados en función de cada caso de uso de aplicación para Proporcionar un enfoque multimodelo para una solución diversificada.
Los LLM son modelos a gran escala que generan texto similar a un humano basándose en su entrenamiento con datos diversos. Al aprender de miles de millones de palabras en Internet, los LLM comprenden el contexto y generan contenido adaptado en varios dominios. Sin embargo, la integración de varios LLM en una sola aplicación a menudo plantea desafíos debido al requisito de interfaces únicas, puntos finales de acceso y cargas útiles específicas para cada modelo. Por lo tanto, tener un único servicio de integración que pueda manejar una variedad de modelos mejora el diseño de la arquitectura y potencia la escala de servicios independientes.
Este tutorial le presentará las integraciones de IntelliNode para ChatGPT y LLaMA V2 en una arquitectura de microservicio utilizando Node.js y Express.
Aquí hay algunas opciones de integración de chat proporcionadas por IntelliNode:
- Llama V2: Puede integrar el modelo LLaMA V2 a través de la API de Replicate para un proceso sencillo o a través de su host AWS SageMaker para un control adicional.
LLaMA V2 es un potente modelo de lenguaje grande (LLM) de código abierto que ha sido previamente entrenado y ajustado con hasta 70B de parámetros. Destaca en tareas de razonamiento complejas en varios dominios, incluidos campos especializados como programación y escritura creativa. Su metodología de formación implica datos autosupervisados y alineación con las preferencias humanas a través del aprendizaje por refuerzo con retroalimentación humana (RLHF). LLaMA V2 supera los modelos de código abierto existentes y es comparable a modelos de código cerrado como ChatGPT y BARD en usabilidad y seguridad.
- ChatGPT: Simplemente proporcionando su clave API de OpenAI, el módulo IntelliNode permite la integración con el modelo en una sencilla interfaz de chat. Puede acceder a ChatGPT a través de los modelos GPT 3.5 o GPT 4. Estos modelos han sido entrenados con grandes cantidades de datos y ajustados para proporcionar respuestas altamente contextuales y precisas.
Comencemos inicializando un nuevo proyecto Node.js. Abra su terminal, navegue hasta el directorio de su proyecto y ejecute el siguiente comando:
npm init -y
Este comando creará un nuevo archivo `package.json` para su aplicación.
A continuación, instale Express.js, que se utilizará para manejar solicitudes y respuestas HTTP e intellinode para la conexión de modelos LLM:
npm install express npm install intellinode
Una vez que concluya la instalación, cree un nuevo archivo llamado `aplicación.js` en el directorio raíz de su proyecto. luego, agregue el código de inicialización rápido en `app.js`.
Código por autor
Replicate proporciona una ruta de integración rápida con Llama V2 a través de una clave API, e IntelliNode proporciona la interfaz de chatbot para desacoplar su lógica de negocios del backend de Replicate, lo que le permite cambiar entre diferentes modelos de chat.
Comencemos por la integración con Llama alojada en el backend de Replica:
Código por autor
Obtenga su clave de prueba de replicar.com para activar la integración.
Ahora, cubramos la integración de Llama V2 a través de AWS SageMaker, brindando privacidad y una capa adicional de control.
La integración requiere generar un punto final API desde su cuenta de AWS. Primero configuraremos el código de integración en nuestra aplicación de microservicio:
Código por autor
Los siguientes pasos son para crear un punto final de Llama en su cuenta, una vez que configure la puerta de enlace API, copie la URL para usarla para ejecutar '/llama/aws' Servicio.
Para configurar un punto final Llama V2 en su cuenta de AWS:
1- Servicio SageMaker: seleccione el servicio SageMaker de su cuenta de AWS y haga clic en dominios.

sagemaker de selección de cuenta de AWS
2- Crea un dominio SageMaker: Comience creando un nuevo dominio en su AWS SageMaker. Este paso establece un espacio controlado para sus operaciones de SageMaker.
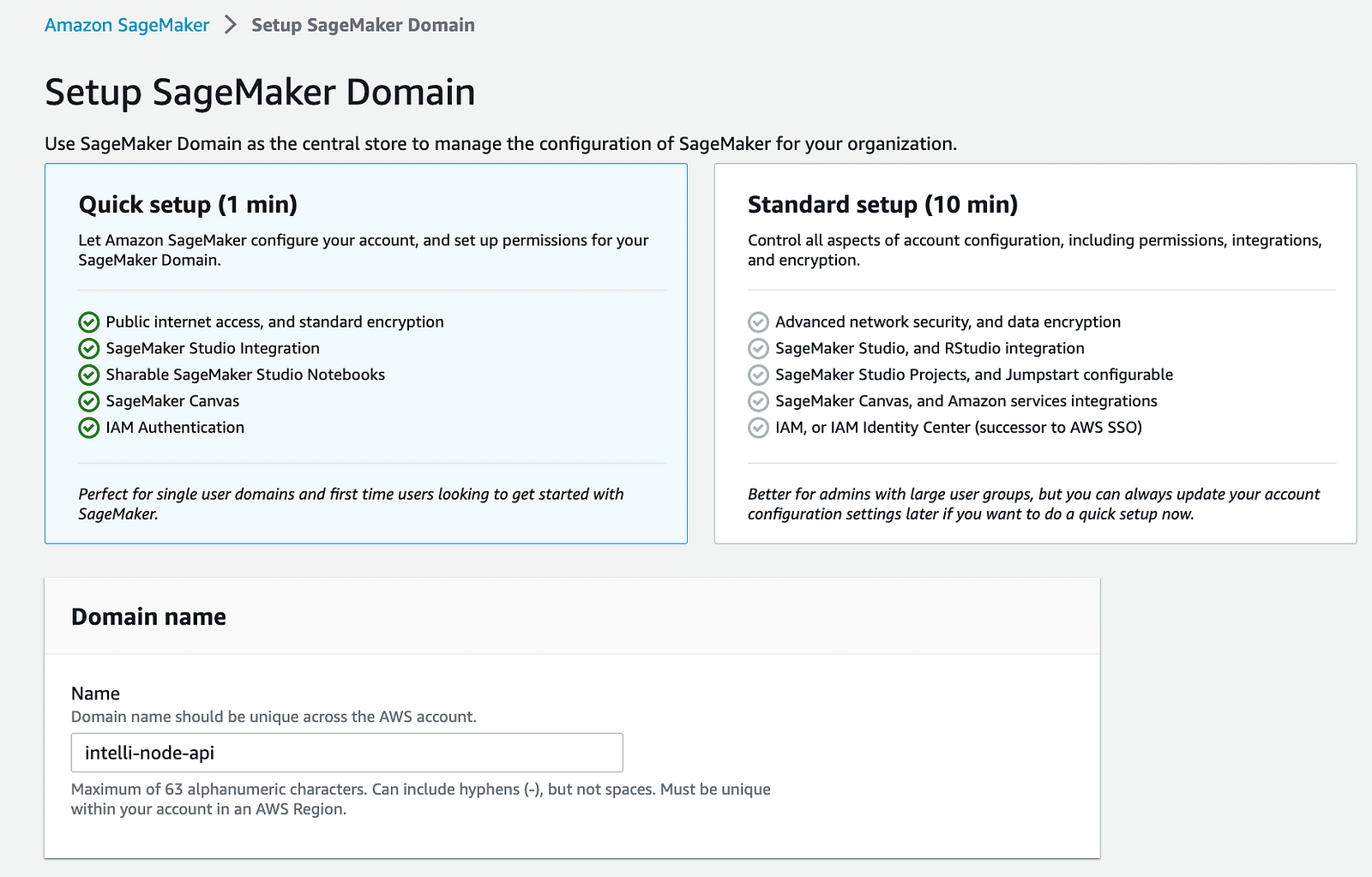
dominio aws cuenta-sagemaker
3- Implementar el modelo Llama: Utilice SageMaker JumpStart para implementar el modelo Llama que planea integrar. Se recomienda comenzar con el modelo 2B debido al mayor costo mensual por ejecutar el modelo 70B.

inicio rápido de cuenta aws-sagemaker
4- Copie el nombre del punto final: Una vez que haya implementado un modelo, asegúrese de anotar el nombre del punto final, que es crucial para pasos futuros.
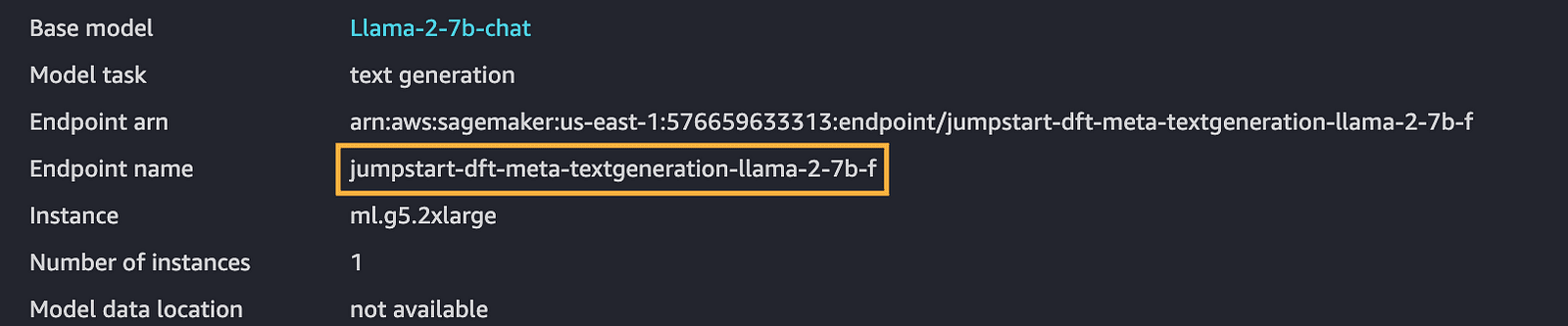
punto final de cuenta de AWS-sagemaker
5- Crear función Lambda: AWS Lambda permite ejecutar el código back-end sin administrar servidores. Cree una función lambda de Node.js para usarla en la integración del modelo implementado.
6- Configurar la variable de entorno: Cree una variable de entorno dentro de su lambda llamada llama_endpoint con el valor del punto final de SageMaker.
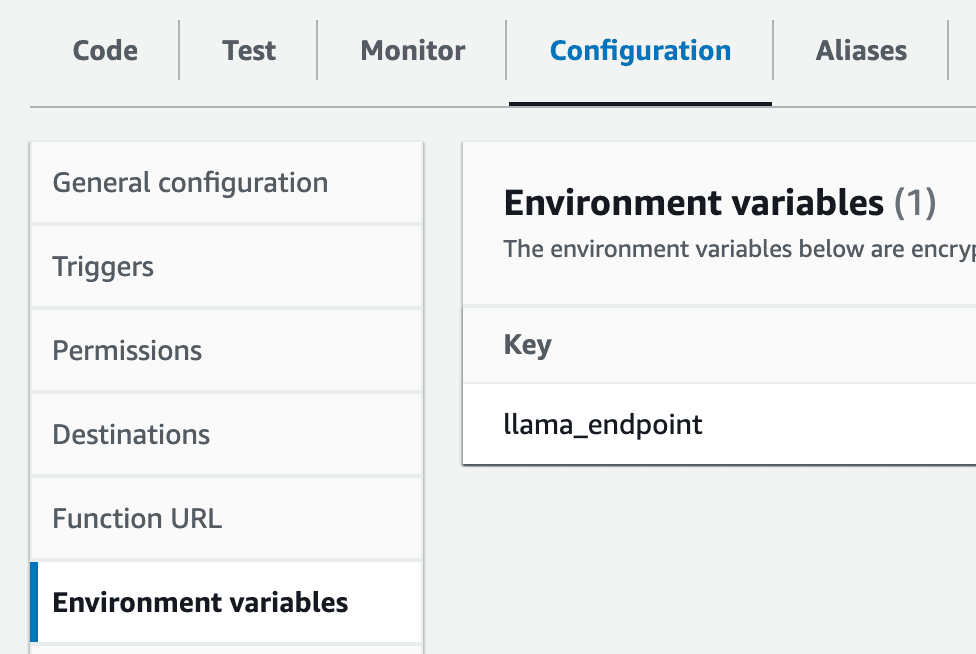
configuración de lmabda de cuenta de AWS
7- Importación Intellinode Lambda: Debe importar el archivo zip Lambda preparado que establece una conexión con su implementación de SageMaker Llama. Esta exportación es un archivo zip y se puede encontrar en el lambda_llama_sagemaker directorio.

carga de la cuenta aws-lambda desde un archivo zip
8- Configuración de la puerta de enlace API: Haga clic en la opción "Agregar disparador" en la página de la función Lambda y seleccione "API Gateway" de la lista de disparadores disponibles.
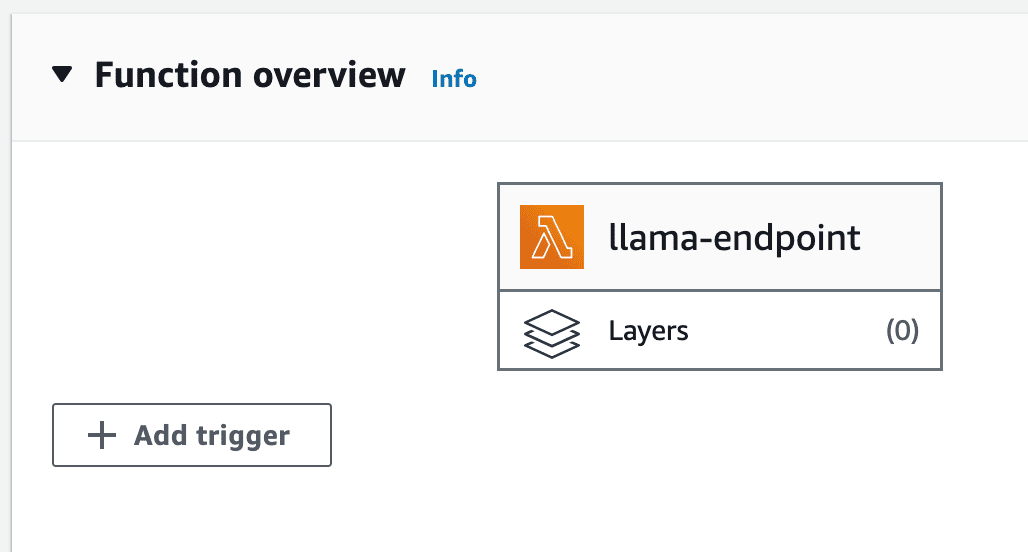
disparador lambda de cuenta aws
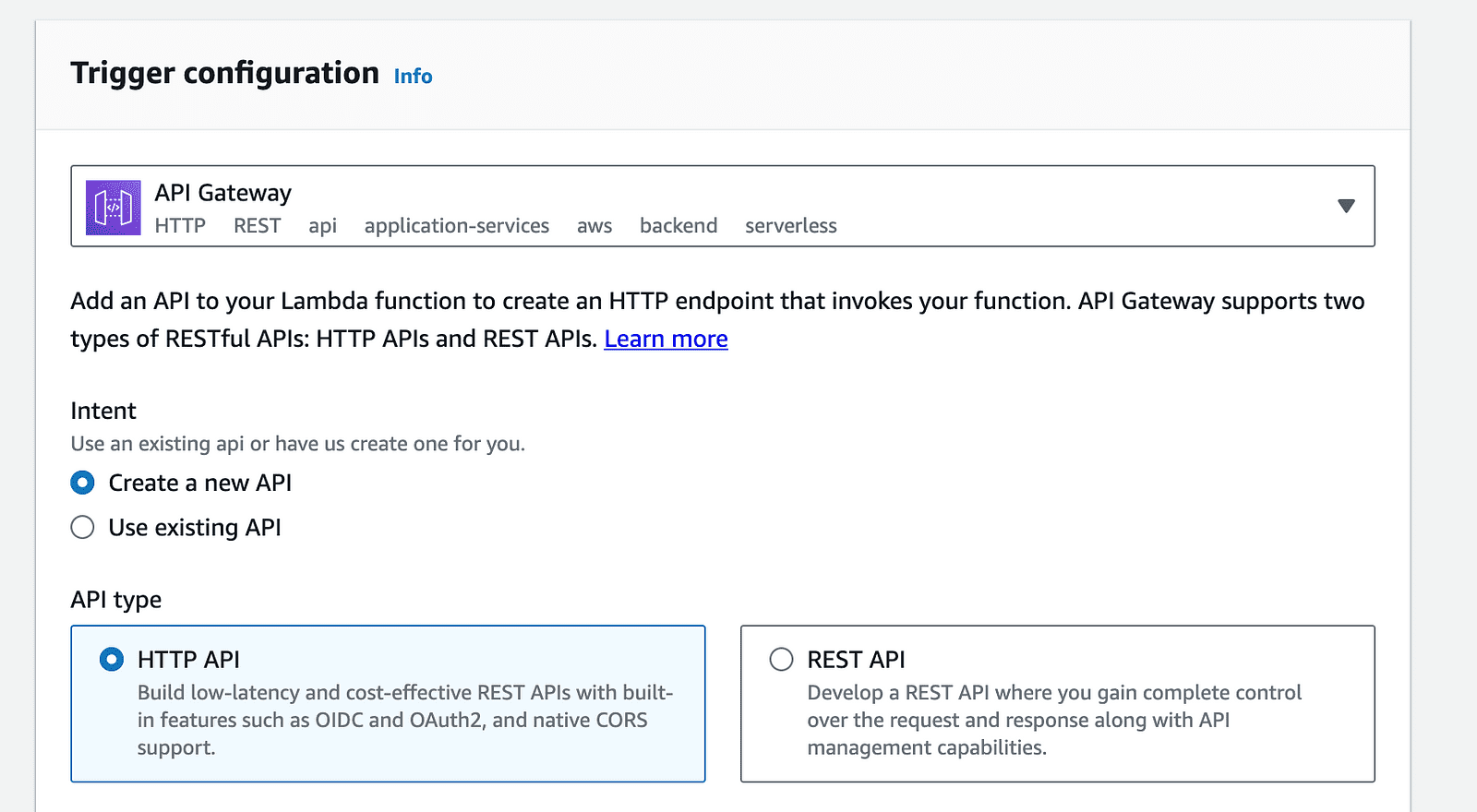
Activador de puerta de enlace API de cuenta de AWS
9- Configuración de la función Lambda: actualice la función lambda para otorgar los permisos necesarios para acceder a los puntos finales de SageMaker. Además, el período de tiempo de espera de la función debe ampliarse para adaptarse al tiempo de procesamiento. Realice estos ajustes en la pestaña "Configuración" de su función Lambda.
Haga clic en el nombre del rol para actualizar los permisos y otorgar permiso para acceder a sagemaker:
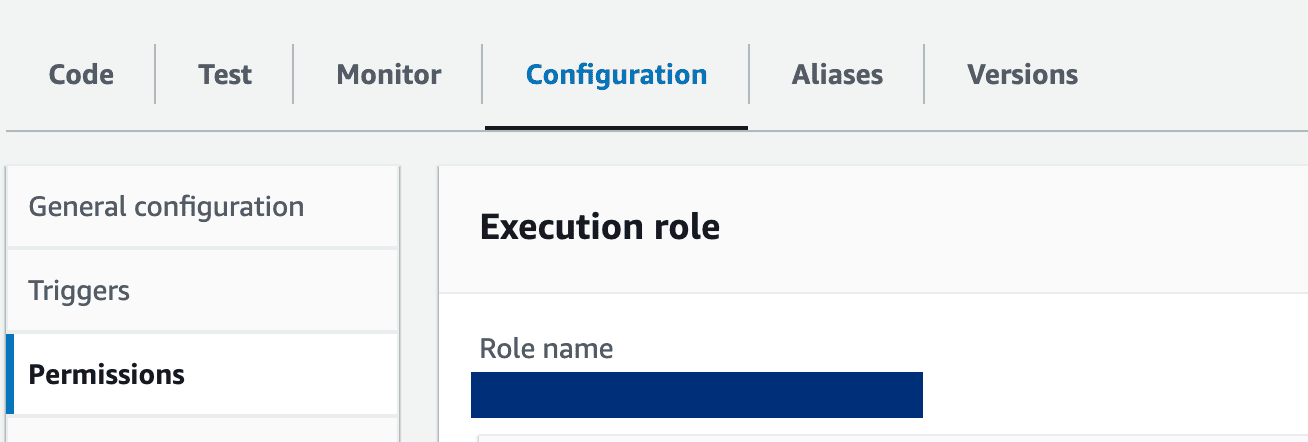
función lambda de cuenta de AWS
Finalmente, ilustraremos los pasos para integrar Openai ChatGPT como otra opción en la arquitectura de microservicios:
Código por autor
Obtenga su clave de prueba de plataforma.openai.com.
Primero exporte la clave API en su terminal de la siguiente manera:
Código por autor
Luego ejecute la aplicación de nodo:
node app.js
Escriba la siguiente URL en el navegador para probar el servicio chatGPT:
http://localhost:3000/chatgpt?message=hello
Construimos un microservicio potenciado por las capacidades de modelos de lenguaje grandes como Llama V2 y ChatGPT de OpenAI. Esta integración abre la puerta a aprovechar infinitos escenarios empresariales impulsados por IA avanzada.
Al traducir sus requisitos de aprendizaje automático en microservicios desacoplados, su aplicación puede obtener los beneficios de flexibilidad y escalabilidad. En lugar de configurar sus operaciones para que se ajusten a las limitaciones de un modelo monolítico, la función de modelos de lenguaje ahora se puede gestionar y desarrollar individualmente; esto promete una mayor eficiencia y una solución de problemas y una gestión de actualizaciones más sencillas.
Referencias
- API de chatGPT: liga.
- API de réplica: liga.
- Inicio rápido de SageMaker Llama: liga
- Introducción a IntelliNode: liga
- Repositorio de código completo de GitHub: liga
Ahmad Albarqawi Es ingeniero y maestro en ciencia de datos en Illinois Urbana-Champaign.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- ChartPrime. Eleve su juego comercial con ChartPrime. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.kdnuggets.com/building-microservice-for-multichat-backends-using-llama-and-chatgpt?utm_source=rss&utm_medium=rss&utm_campaign=building-microservice-for-multi-chat-backends-using-llama-and-chatgpt

