Desarrollar interfaces web para interactuar con un modelo de aprendizaje automático (ML) es una tarea tediosa. Con iluminado, desarrollar aplicaciones de demostración para su solución ML es fácil. iluminado es una biblioteca Python de código abierto que facilita la creación y el intercambio de aplicaciones web para ML y ciencia de datos. Como científico de datos, es posible que desee mostrar sus hallazgos para un conjunto de datos o implementar un modelo entrenado. Las aplicaciones Streamlit son útiles para presentar el progreso de un proyecto a su equipo, obtener y compartir información con sus gerentes e incluso recibir comentarios de los clientes.
Con el entorno de desarrollo integrado (IDE) de Estudio Amazon SageMaker Laboratorio Jupyter 3, podemos crear, ejecutar y ofrecer aplicaciones web Streamlit desde ese mismo entorno con fines de desarrollo. Esta publicación describe cómo compilar y alojar aplicaciones Streamlit en Studio de manera segura y reproducible sin ningún desarrollo front-end que requiera mucho tiempo. Como ejemplo, usamos una costumbre Reconocimiento de amazonas demo, que anotará y etiquetará una imagen cargada. Esto servirá como punto de partida y se puede generalizar para demostrar cualquier modelo de ML personalizado. El código de este blog se puede encontrar en este Repositorio GitHub.
Resumen de la solución
El siguiente es el diagrama de arquitectura de nuestra solución.
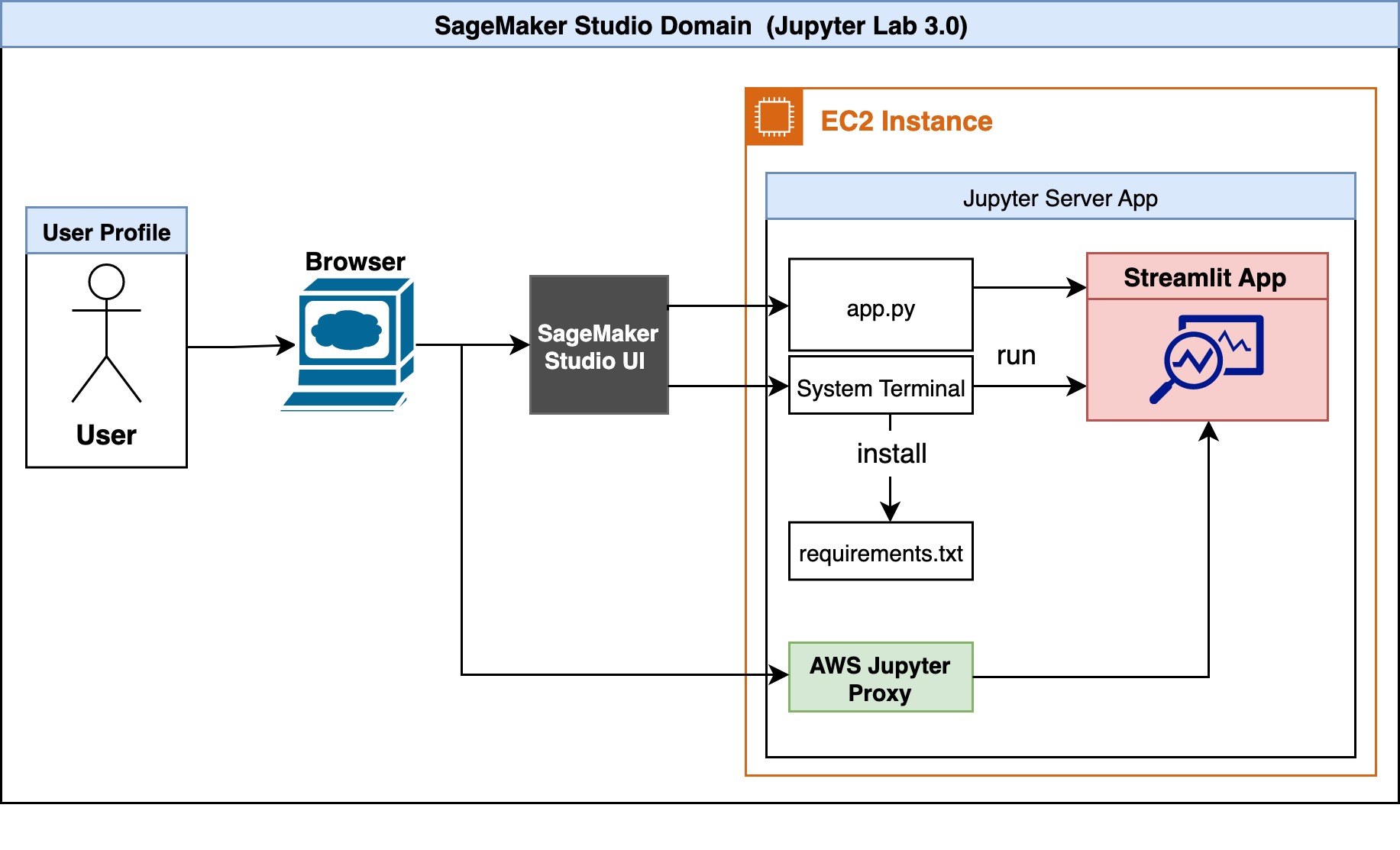
Un usuario accede primero a Studio a través del navegador. El servidor Jupyter asociado con el perfil de usuario se ejecuta dentro de la instancia de Studio Amazon Elastic Compute Cloud (Amazon EC2). Dentro de la instancia de Studio EC2 existe el código de ejemplo y la lista de dependencias. El usuario puede ejecutar la aplicación Streamlit, app.py, en la terminal del sistema. Studio ejecuta la interfaz de usuario de JupyterLab en un servidor Jupyter, desacoplado de los núcleos de los portátiles. El servidor Jupyter viene con un proxy y nos permite acceder a nuestra aplicación Streamlit. Una vez que la aplicación se está ejecutando, el usuario puede iniciar una sesión separada a través de AWS Jupyter Proxy ajustando la URL.
Desde el punto de vista de la seguridad, AWS Jupyter Proxy se amplía mediante la autenticación de AWS. Siempre que un usuario tenga acceso a la cuenta de AWS, el ID de dominio de Studio y el perfil de usuario, puede acceder al enlace.
Crear estudio usando JupyterLab 3.0
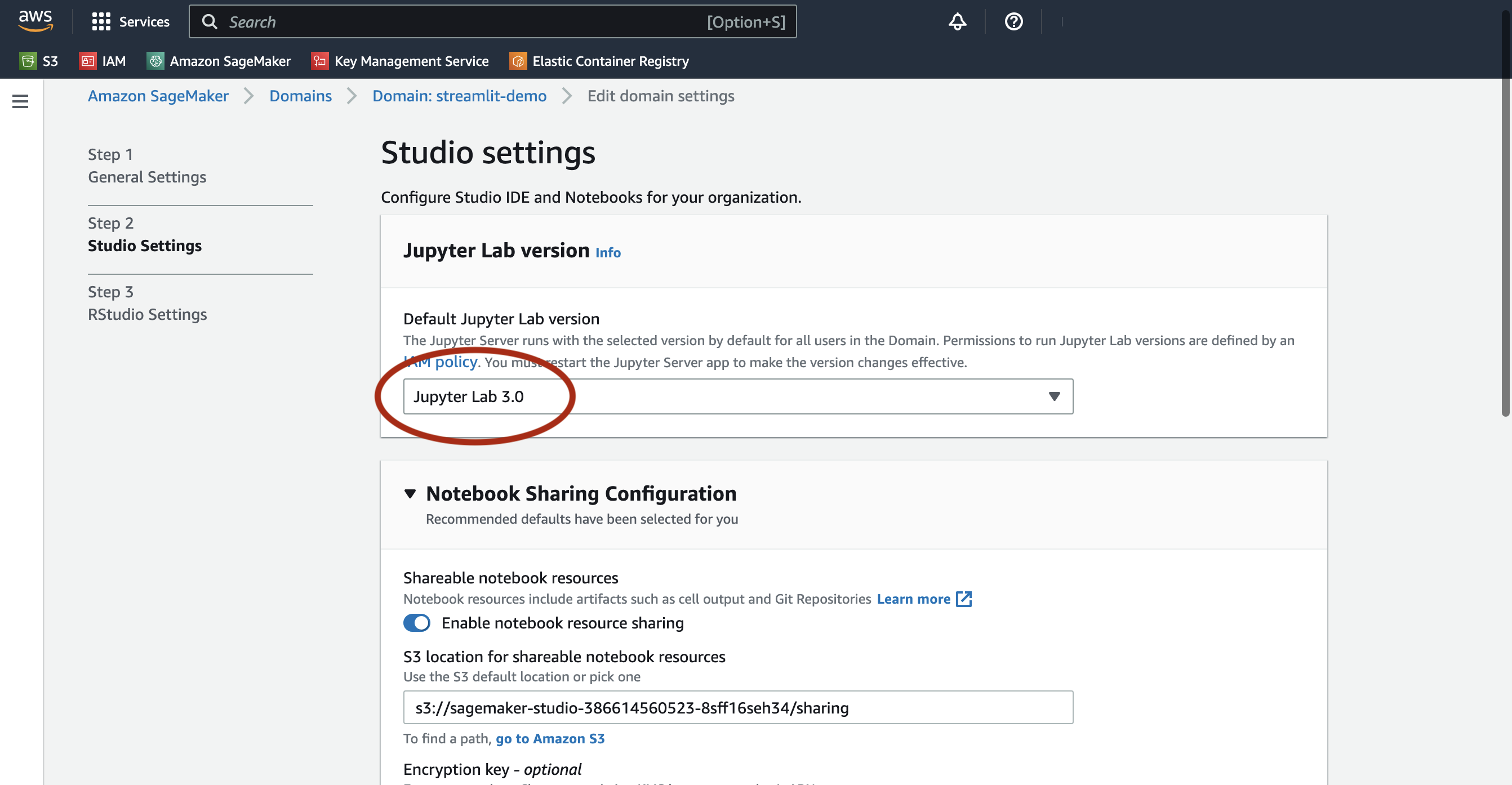
Studio con JupyterLab 3 debe estar instalado para que esta solución funcione. Es posible que las versiones anteriores no admitan las funciones descritas en esta publicación. Para obtener más información, consulte Amazon SageMaker Studio y SageMaker Notebook Instance ahora vienen con notebooks JupyterLab 3 para aumentar la productividad de los desarrolladores. De manera predeterminada, Studio viene con JupyterLab 3. Debe verificar la versión y cambiarla si ejecuta una versión anterior. Para obtener más información, consulte Control de versiones de JupyterLab.
Puede configurar Studio usando el Kit de desarrollo en la nube de AWS (CDK de AWS); para obtener más información, consulte Configure Amazon SageMaker Studio con Jupyter Lab 3 mediante el CDK de AWS. Como alternativa, puede usar la consola de SageMaker para cambiar la configuración del dominio. Complete los siguientes pasos:
- En la consola de SageMaker, elija dominios en el panel de navegación.
- Seleccione su dominio y elija Editar.

- Versión predeterminada de Jupyter Lab, asegúrese de que la versión esté establecida en Laboratorio Jupyter 3.0.
(Opcional) Crear un espacio compartido
Podemos usar la consola de SageMaker o la CLI de AWS para agregar soporte para espacios compartidos a un dominio existente siguiendo los pasos en los documentos o en este blog. Crear un espacio compartido en AWS tiene los siguientes beneficios:
- Colaboración: un espacio compartido permite que varios usuarios o equipos colaboren en un proyecto o conjunto de recursos, sin tener que duplicar datos o infraestructura.
- Ahorro de costos: en lugar de que cada usuario o equipo cree y administre sus propios recursos, un espacio compartido puede ser más rentable, ya que los recursos se pueden agrupar y compartir entre varios usuarios.
- Gestión simplificada: con un espacio compartido, los administradores pueden gestionar los recursos de forma centralizada, en lugar de tener que gestionar varias instancias de los mismos recursos para cada usuario o equipo.
- Escalabilidad mejorada: un espacio compartido se puede ampliar o reducir más fácilmente para satisfacer las demandas cambiantes, ya que los recursos se pueden asignar dinámicamente para satisfacer las necesidades de diferentes usuarios o equipos.
- Seguridad mejorada: al centralizar los recursos en un espacio compartido, se puede mejorar la seguridad, ya que los controles de acceso y el monitoreo se pueden aplicar de manera más fácil y consistente.
Instalar dependencias y clonar el ejemplo en Studio
A continuación, lanzamos Studio y abrimos la terminal del sistema. Usamos el IDE de SageMaker para clonar nuestro ejemplo y la terminal del sistema para iniciar nuestra aplicación. El código de este blog se puede encontrar en este Repositorio GitHub. Empezamos con la clonación del repositorio:

A continuación, abrimos la Terminal del sistema.
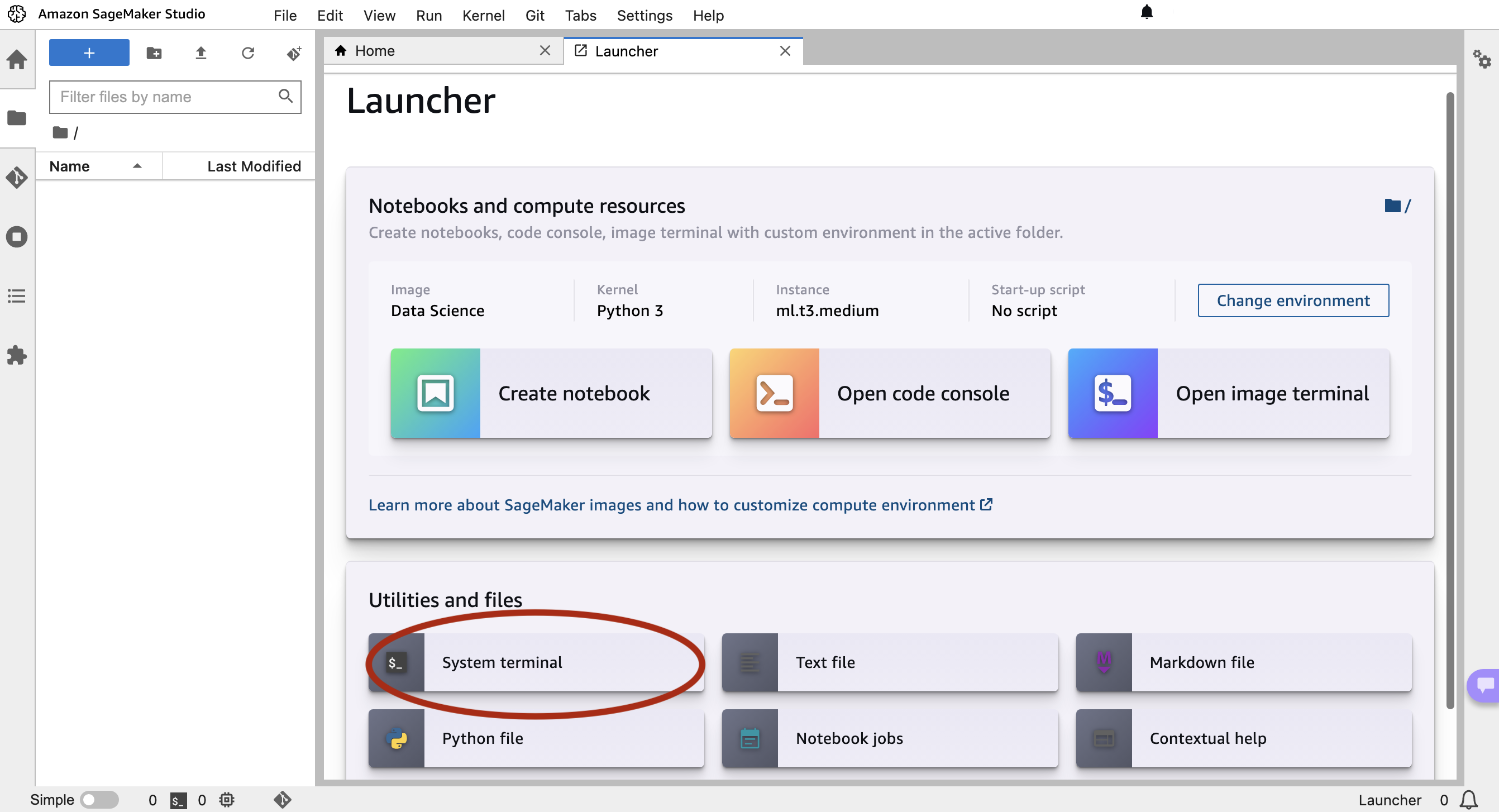
Una vez clonado, en la terminal del sistema instale las dependencias para ejecutar nuestro código de ejemplo ejecutando el siguiente comando. Esto primero instalará las dependencias ejecutando pip install --no-cache-dir -r requirements.txt. no-cache-dir bandera deshabilitará el caché. El almacenamiento en caché ayuda a almacenar los archivos de instalación (.whl) de los módulos que instalas a través de pip. También almacena los archivos fuente (.tar.gz) para evitar volver a descargarlos cuando no hayan caducado. Si no hay espacio en nuestro disco duro o si queremos mantener una imagen de Docker lo más pequeña posible, podemos usar este indicador para que el comando se ejecute hasta el final con un uso mínimo de memoria. A continuación, el script instalará paquetes. iproute y jq , que se utilizará en el siguiente paso.sh setup.sh
Ejecute la demostración de Streamlit y cree un enlace para compartir
Para verificar que todas las dependencias se hayan instalado correctamente y para ver la demostración de Amazon Rekognition, ejecute el siguiente comando:
Se mostrará el número de puerto que aloja la aplicación.
Tenga en cuenta que durante el desarrollo, puede ser útil volver a ejecutar automáticamente el script cuando app.py se modifica en el disco. Para hacer, para que podamos modificar el runOnSave opción de configuración agregando el --server.runOnSave true bandera a nuestro comando:
La siguiente captura de pantalla muestra un ejemplo de lo que debería mostrarse en el terminal.

En el ejemplo anterior, vemos el número de puerto, el ID de dominio y la URL del estudio en el que estamos ejecutando nuestra aplicación. Finalmente, podemos ver la URL que necesitamos usar para acceder a nuestra aplicación streamlit. Este script está modificando la URL de Studio, reemplazando lab? proxy/[PORT NUMBER]/ . Se mostrará la demostración de detección de objetos de Rekognition, como se muestra en la siguiente captura de pantalla.

Ahora que tenemos la aplicación Streamlit funcionando, podemos compartir esta URL con cualquier persona que tenga acceso a este ID de dominio y perfil de usuario de Studio. Para facilitar el intercambio de estas demostraciones, podemos verificar el estado y enumerar todas las aplicaciones streamlit en ejecución ejecutando el siguiente comando: sh status.sh
Podemos usar scripts de ciclo de vida o espacios compartidos para extender este trabajo. En lugar de ejecutar manualmente los scripts de shell e instalar las dependencias, use guiones de ciclo de vida para agilizar este proceso. Para desarrollar y ampliar esta aplicación con un equipo y compartir paneles con compañeros, use espacios compartidos. Al crear espacios compartidos en Studio, los usuarios pueden colaborar en el espacio compartido para desarrollar una aplicación Streamlit en tiempo real. Todos los recursos en un espacio compartido se filtran y etiquetan, lo que facilita concentrarse en los proyectos de ML y administrar los costos. Consulte el siguiente código para crear sus propias aplicaciones en Studio.
Limpiar
Una vez que hayamos terminado de usar la aplicación, queremos liberar los puertos de escucha. Para que todos los procesos se ejecuten streamlit y liberarlos para su uso, podemos ejecutar nuestro script de limpieza: sh cleanup.sh
Conclusión
En esta publicación, mostramos un ejemplo completo del alojamiento de una demostración de Streamlit para una tarea de detección de objetos con Amazon Rekognition. Detallamos las motivaciones para crear aplicaciones web rápidas, las consideraciones de seguridad y la configuración necesaria para ejecutar nuestra propia aplicación Streamlit en Studio. Finalmente, modificamos el patrón de URL en nuestro navegador web para iniciar una sesión separada a través del proxy AWS Jupyter.
Esta demostración le permite cargar cualquier imagen y visualizar los resultados de Amazon Rekognition. Los resultados también se procesan y puede descargar un archivo CSV con todos los cuadros delimitadores a través de la aplicación. Puede ampliar este trabajo para anotar y etiquetar su propio conjunto de datos, o modificar el código para mostrar su modelo personalizado.
Acerca de los autores
 Dipika Khullar es un ingeniero de ML en el Laboratorio de soluciones de Amazon ML. Ayuda a los clientes a integrar soluciones de ML para resolver sus problemas comerciales. Más recientemente, ha creado canalizaciones de formación e inferencia para clientes de medios y modelos predictivos para marketing.
Dipika Khullar es un ingeniero de ML en el Laboratorio de soluciones de Amazon ML. Ayuda a los clientes a integrar soluciones de ML para resolver sus problemas comerciales. Más recientemente, ha creado canalizaciones de formación e inferencia para clientes de medios y modelos predictivos para marketing.
 marcelo aberle es un ingeniero de ML en la organización de IA de AWS. Está liderando los esfuerzos de MLOps en el Laboratorio de soluciones de Amazon ML, ayudando a los clientes a diseñar e implementar sistemas ML escalables. Su misión es guiar a los clientes en su viaje empresarial de ML y acelerar su ruta de ML hacia la producción.
marcelo aberle es un ingeniero de ML en la organización de IA de AWS. Está liderando los esfuerzos de MLOps en el Laboratorio de soluciones de Amazon ML, ayudando a los clientes a diseñar e implementar sistemas ML escalables. Su misión es guiar a los clientes en su viaje empresarial de ML y acelerar su ruta de ML hacia la producción.
 Yash Shah es Gerente de Ciencias en el Laboratorio de soluciones de Amazon ML. Él y su equipo de científicos aplicados e ingenieros de ML trabajan en una variedad de casos de uso de ML de salud, deportes, automoción y fabricación.
Yash Shah es Gerente de Ciencias en el Laboratorio de soluciones de Amazon ML. Él y su equipo de científicos aplicados e ingenieros de ML trabajan en una variedad de casos de uso de ML de salud, deportes, automoción y fabricación.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/build-streamlit-apps-in-amazon-sagemaker-studio/

