Desplazamiento al rojo de Amazon es un servicio de almacenamiento de datos completamente administrado que actualmente ayuda a decenas de miles de clientes a administrar análisis a escala. continúa Puntos de referencia de precio-rendimiento de plomoy separa el cómputo y el almacenamiento para que cada uno se pueda escalar de forma independiente y solo pague por lo que necesita. También elimina los silos de datos al simplificar el acceso a sus bases de datos operativas, almacén de datos y lago de datos con políticas de seguridad y gobernanza coherentes.
Con la función de ingestión de transmisión de Amazon Redshift, es más fácil que nunca acceder y analizar datos provenientes de fuentes de datos en tiempo real. Simplifica la arquitectura de transmisión al proporcionar una integración nativa entre Amazon Redshift y los motores de transmisión en AWS, que son Secuencias de datos de Amazon Kinesis y Streaming administrado por Amazon para Apache Kafka (Amazon MSK). Las fuentes de datos de transmisión como registros del sistema, fuentes de redes sociales y transmisiones de IoT pueden continuar enviando eventos a los motores de transmisión, y Amazon Redshift simplemente se convierte en un consumidor más. Antes de que la transmisión de Amazon Redshift estuviera disponible, primero teníamos que organizar los datos de transmisión en Servicio de almacenamiento simple de Amazon (Amazon S3) y luego ejecute el comando de copia para cargarlo en Amazon Redshift. La eliminación de la necesidad de organizar los datos en Amazon S3 da como resultado un rendimiento más rápido y una latencia mejorada. Con esta función podemos ingerir cientos de megas de datos por segundo y tener una latencia de apenas unos segundos.
Otro desafío común para nuestros clientes es la habilidad adicional requerida al usar la transmisión de datos. En la ingestión de streaming de Amazon Redshift, solo se requiere SQL. Usamos SQL para hacer lo siguiente:
- Defina la integración entre Amazon Redshift y nuestros motores de transmisión con la creación de esquema externo
- Cree los diferentes objetos de la base de datos de transmisión que realmente vistas materializadas
- Consultar y analizar los datos de transmisión
- Genere nuevas funciones que se utilizan para predecir retrasos mediante el aprendizaje automático (ML)
- Realizar inferencias de forma nativa utilizando Aprendizaje automático de Amazon Redshift
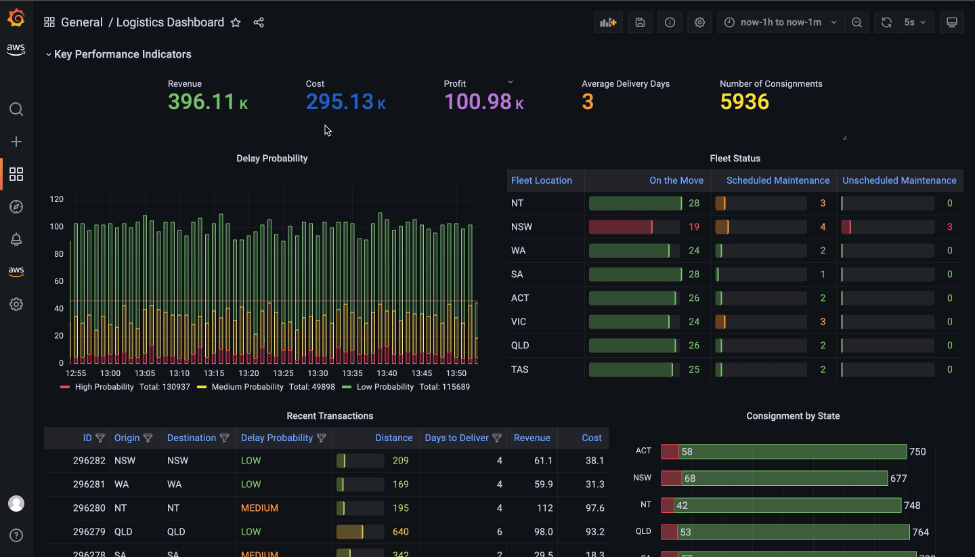
En esta publicación, construimos un tablero de logística casi en tiempo real utilizando Amazon Redshift y Grafana gestionado por Amazon. Nuestro ejemplo es un tablero de inteligencia operativa para una empresa de logística que proporciona conocimiento de la situación e inteligencia aumentada para su equipo de operaciones. Desde este tablero, el equipo puede ver el estado actual de sus envíos y su flota logística en función de los eventos que ocurrieron hace solo unos segundos. También muestra las predicciones de retrasos en los envíos de un modelo de aprendizaje automático de Amazon Redshift que les ayuda a responder de manera proactiva a las interrupciones incluso antes de que sucedan.
Resumen de la solución
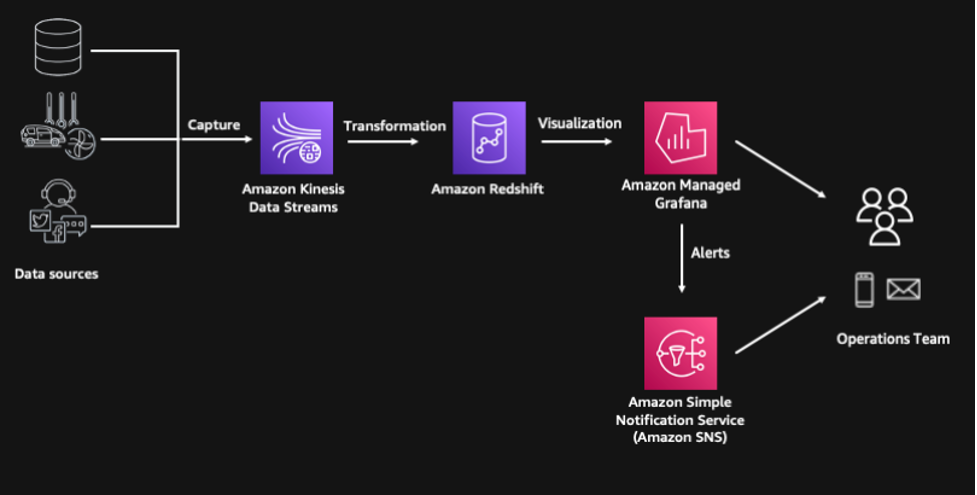
Esta solución está compuesta por los siguientes componentes, y el aprovisionamiento de recursos está automatizado utilizando el Kit de desarrollo en la nube de AWS (CDK de AWS):
- Múltiples fuentes de datos de transmisión se simulan a través del código Python que se ejecuta en nuestro servicio de cómputo sin servidor, AWS Lambda
- Los eventos de transmisión son capturados por Secuencias de datos de Amazon Kinesis, que es un servicio de transmisión de datos sin servidor altamente escalable
- Usamos la función de ingestión de transmisión de Amazon Redshift para procesar y almacenar los datos de transmisión y Amazon Redshift ML para predecir la probabilidad de que un envío se retrase.
- Utilizamos Funciones de paso de AWS para orquestación de flujo de trabajo sin servidor
- La solución incluye una capa de consumo construida sobre Amazon Managed Grafana donde podemos visualizar los insights e incluso generar alertas a través de Servicio de notificación simple de Amazon (Amazon SNS) para nuestro equipo de operaciones
El siguiente diagrama ilustra la arquitectura de nuestra solución.
Requisitos previos
El proyecto tiene los siguientes requisitos previos:
Ejemplo de implementación con AWS CDK
AWS CDK es un proyecto de código abierto que le permite definir su infraestructura en la nube utilizando lenguajes de programación familiares. Utiliza construcciones de alto nivel para representar los componentes de AWS a fin de simplificar el proceso de creación. En esta publicación, usamos Python para definir la infraestructura de la nube debido a su familiaridad con muchos profesionales de análisis y datos.
Clona el repositorio de GitHub e instala las dependencias de Python:
A continuación, arranque el CDK de AWS. Esto configura los recursos requeridos por AWS CDK para implementar en la cuenta de AWS. Este paso solo es necesario si no ha utilizado el CDK de AWS en la cuenta de implementación y la región.
Implementar todas las pilas:
Todo el tiempo de implementación tarda entre 10 y 15 minutos.
Acceda a datos de transmisión mediante la ingestión de transmisión de Amazon Redshift
La implementación de AWS CDK aprovisiona un clúster de Amazon Redshift con el rol de IAM predeterminado apropiado para acceder al flujo de datos de Kinesis. Podemos crear un esquema externo para establecer una conexión entre el clúster de Amazon Redshift y el flujo de datos de Kinesis:
Para obtener instrucciones sobre cómo conectarse al clúster, consulte Conexión al clúster Redshift.
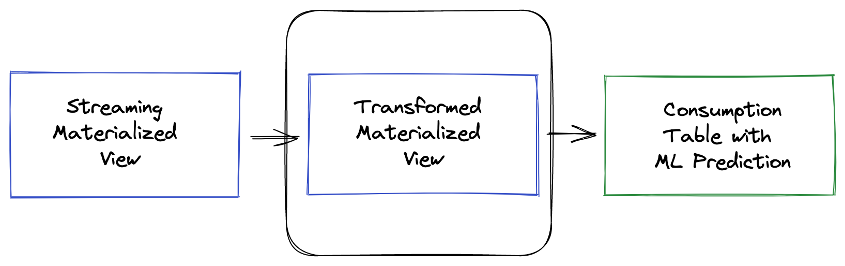
Usamos una vista materializada para analizar datos en el flujo de datos de Kinesis. En este caso, toda la carga útil se ingiere tal cual y se almacena mediante el SÚPER tipo de datos en Amazon Redshift. Los datos almacenados en motores de transmisión suelen estar en formato semiestructurado, y el tipo de datos SUPER proporciona una manera rápida y eficiente de analizar datos semiestructurados dentro de Amazon Redshift.

Ver el siguiente código:
Al actualizar la vista materializada, se invoca a Amazon Redshift para leer datos directamente desde el flujo de datos de Kinesis y cargarlos en la vista materializada. Esta actualización se puede hacer automáticamente agregando el AUTOREFRESCAR cláusula en la definición de vista materializada. Sin embargo, en este ejemplo, estamos orquestando la canalización de datos de un extremo a otro utilizando Funciones de paso de AWS.
Ahora podemos comenzar a ejecutar consultas en nuestros datos de transmisión y unificarlos con otros conjuntos de datos, como los datos de la flota logística. Si queremos conocer la distribución de nuestros envíos en diferentes estados, podemos desempaquetar fácilmente el contenido de la carga útil JSON usando el PartiQL sintaxis.
Genere características utilizando funciones SQL de Amazon Redshift
El siguiente paso es transformar y enriquecer los datos de transmisión mediante Amazon Redshift SQL para generar características adicionales que Amazon Redshift ML utilizará para sus predicciones. Usamos funciones de fecha y hora para identificar el día de la semana y calcular el número de días entre la fecha del pedido y la fecha de entrega prevista.
También usamos funciones geoespaciales, específicamente ST_DistanceSphere, para calcular la distancia entre las ubicaciones de origen y destino. El GEOMETRÍA El tipo de datos dentro de Amazon Redshift proporciona una forma rentable de analizar datos geoespaciales como la longitud y la latitud a escala. En este ejemplo, las direcciones ya se han convertido a longitud y latitud. Sin embargo, si necesita realizar una geocodificación, puede integrar los servicios de ubicación de Amazon con Amazon Redshift mediante funciones definidas por el usuario (UDF). Además de la geocodificación, Servicio de ubicación de Amazon también le permite con mayor precisión calcular la distancia de la ruta entre origen y destino, e incluso especificar waypoints a lo largo del camino.
Usamos otra vista materializada para persistir estas transformaciones. Una vista materializada proporciona una manera simple pero eficiente de crear canalizaciones de datos utilizando su capacidad de actualización incremental. Amazon Redshift identifica los cambios incrementales desde la última actualización y solo actualiza la vista materializada de destino en función de estos cambios. En esta vista materializada, todas nuestras transformaciones son deterministas, por lo que esperamos que nuestros datos sean consistentes al pasar por una actualización completa o incremental.
Ver el siguiente código:
Predecir retrasos con Amazon Redshift ML
Podemos utilizar estos datos enriquecidos para hacer predicciones sobre la probabilidad de retraso de un envío. Aprendizaje automático de Amazon Redshift es una característica de Amazon Redshift que le permite utilizar el poder de Amazon Redshift para crear, entrenar e implementar modelos de aprendizaje automático directamente dentro de su almacén de datos.
El entrenamiento de un nuevo modelo de aprendizaje automático de Amazon Redshift se inició como parte de la implementación de AWS CDK utilizando el CREAR MODELO declaración. El conjunto de datos de entrenamiento se define en la cláusula FROM y TARGET define qué columna intenta predecir el modelo. La cláusula FUNCTION define el nombre de la función que se usa para hacer predicciones.
Este modelo simplificado se entrena utilizando observaciones históricas y el proceso de entrenamiento tarda alrededor de 30 minutos en completarse. Puede verificar el estado del trabajo de entrenamiento ejecutando el MOSTRAR MODELO declaración:
Cuando el modelo esté listo, podemos comenzar a hacer predicciones sobre los nuevos datos que se transmiten a Amazon Redshift. Las predicciones se generan mediante la función Amazon Redshift ML que se definió durante el proceso de capacitación. Pasamos las características calculadas de la vista materializada transformada a esta función, y los resultados de predicción completan el delay_probability columna.
Esta salida final se conserva en el consignment_predictions y Step Functions está organizando la carga de datos incrementales en curso en esta tabla de destino. Usamos una tabla para el resultado final, en lugar de una vista materializada, porque las predicciones de ML involucran la aleatoriedad y pueden darnos resultados no deterministas. El uso de una tabla nos da más control sobre cómo se cargan los datos.

Ver el siguiente código:
Cree un panel de Grafana administrado por Amazon
Usamos Grafana administrado por Amazon para crear un panel de control de logística casi en tiempo real. Amazon Managed Grafana es un servicio completamente administrado que facilita la creación, configuración y uso compartido de paneles y gráficos interactivos para monitorear sus datos. También podemos usar Grafana para configurar alertas y notificaciones basadas en condiciones o umbrales específicos, lo que le permite identificar y responder rápidamente a los problemas.
Los pasos de alto nivel para configurar el tablero son los siguientes:
- Cree un espacio de trabajo de Grafana.
- Configure la autenticación de Grafana usando Centro de identidad de AWS IAM (sucesor del inicio de sesión único de AWS) o utilizando Integración SAML.
- Configurar Amazon Redshift como Fuente de datos Grafana.
- Importar el JSON archivo para el panel de control de logística casi en tiempo real.
Un conjunto de instrucciones más detalladas está disponible en el Repositorio GitHub para tu referencia.
Limpiar
Para evitar cargos continuos, elimine los recursos implementados. Acceda al entorno de Amazon Linux 2 y ejecute el comando de destrucción de AWS CDK. Elimine los objetos de Grafana relacionados con este despliegue.
Conclusión
En esta publicación, mostramos lo fácil que es crear un panel de control de logística casi en tiempo real con Amazon Redshift y Amazon Managed Grafana. Creamos una canalización de datos moderna de un extremo a otro usando solo SQL. Esto muestra cómo Amazon Redshift es una plataforma poderosa para democratizar sus datos: permite que una amplia gama de usuarios, incluidos analistas comerciales, científicos de datos y otros, trabajen y analicen datos sin necesidad de conocimientos técnicos especializados o experiencia.
Lo alentamos a explorar qué más se puede lograr con Amazon Redshift y Amazon Managed Grafana. También te recomendamos visitar la Blog de grandes datos de AWS para otras publicaciones de blog útiles sobre Amazon Redshift.
Sobre la autora
 pablo villena es un arquitecto de soluciones de análisis en AWS con experiencia en la creación de soluciones modernas de datos y análisis para impulsar el valor comercial. Trabaja con los clientes para ayudarlos a aprovechar el poder de la nube. Sus áreas de interés son la infraestructura como código, las tecnologías sin servidor y la codificación en Python.
pablo villena es un arquitecto de soluciones de análisis en AWS con experiencia en la creación de soluciones modernas de datos y análisis para impulsar el valor comercial. Trabaja con los clientes para ayudarlos a aprovechar el poder de la nube. Sus áreas de interés son la infraestructura como código, las tecnologías sin servidor y la codificación en Python.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/build-near-real-time-logistics-dashboards-using-amazon-redshift-and-amazon-managed-grafana-for-better-operational-intelligence/

