Puede ingerir e integrar datos de múltiples sensores de Internet de las cosas (IoT) para obtener información valiosa. Sin embargo, es posible que deba integrar datos de múltiples dispositivos de sensores de IoT para obtener análisis, como información sobre el estado del equipo, de todos los sensores en función de elementos de datos comunes. Cada uno de estos dispositivos sensores podría transmitir datos con esquemas únicos y atributos diferentes.
Puede ingerir datos de todos sus sensores de IoT en una ubicación central en Servicio de almacenamiento simple de Amazon (Amazon S3). Evolución del esquema es una característica donde el esquema de una tabla de base de datos puede evolucionar para adaptarse a los cambios en los atributos de los archivos que se ingieren. Con la funcionalidad de evolución de esquema disponible en Pegamento AWS, Espectro de Redshift de Amazon puede manejar automáticamente cambios de esquema cuando se agregan nuevos atributos o se eliminan atributos existentes. Esto se logra con un rastreador de AWS Glue leyendo los cambios de esquema basados en las estructuras de archivos de S3. El rastreador crea un esquema híbrido que funciona con conjuntos de datos nuevos y antiguos. Puede leer todos los archivos de datos ingeridos en una ubicación especificada de Amazon S3 con diferentes esquemas a través de un único Espectro de Redshift de Amazon tabla consultando el catálogo de metadatos de AWS Glue.
En esta publicación, demostramos cómo utilizar la función de evolución de esquemas de AWS Glue para leer múltiples archivos con formato JSON con varios esquemas almacenados en una única ubicación de Amazon S3. También mostramos cómo consultar estos datos en Amazon S3 con Redshift Spectrum sin redefinir el esquema ni cargar los datos en tablas de Redshift.
Resumen de la solución
La solución consta de los siguientes pasos:
- Crear una Manguera de datos de Amazon flujo de entrega con Amazon S3 como destino.
- Generar datos de flujo de muestra desde el Generador de datos de Amazon Kinesis (KDG) con el flujo de entrega de Firehose como destino.
- Cargue los archivos de datos iniciales en la ubicación de Amazon S3.
- Cree y ejecute un rastreador de AWS Glue para completar el catálogo de datos con una definición de tabla externa leyendo los archivos de datos de Amazon S3.
- Cree el esquema externo llamado
iotdb_exten Amazon Redshift y consulte la tabla del catálogo de datos. - Consulta la tabla externa de Redshift Spectrum para leer datos del esquema inicial.
- Agregue elementos de datos adicionales a la plantilla KDG y envíe los datos al flujo de entrega de Firehose.
- Valide que los archivos de datos adicionales estén cargados en Amazon S3 con elementos de datos adicionales.
- Ejecute un rastreador de AWS Glue para actualizar las definiciones de tablas externas.
- Vuelva a consultar la tabla externa de Redshift Spectrum para leer el conjunto de datos combinado de dos esquemas diferentes.
- Elimine un elemento de datos de la plantilla y envíe los datos al flujo de entrega de Firehose.
- Valide que los archivos de datos adicionales estén cargados en Amazon S3 con un elemento de datos menos.
- Ejecute un rastreador de AWS Glue para actualizar las definiciones de tablas externas.
- Consulte la tabla externa de Redshift Spectrum para leer el conjunto de datos combinado de tres esquemas diferentes.
Esta solución se muestra en el siguiente diagrama de arquitectura.

Requisitos previos
Esta solución requiere los siguientes requisitos previos:
Implementar la solución
Complete los siguientes pasos para construir la solución:
- En la consola Kinesis, cree una secuencia de entrega de Firehose con los siguientes parámetros:
- Fuente, escoger PUT directa.
- Destino, escoger Amazon S3.
- Cucharón S3, ingrese su depósito S3.
- Particionamiento dinámico, seleccione implante.

-
- Agregue las siguientes claves de partición dinámica:
- Año clave con expresión.
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%Y") - Mes clave con expresión.
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%m") - Día clave con expresión.
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%d") - Hora clave con expresión.
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%H")
- Año clave con expresión.
- Agregue las siguientes claves de partición dinámica:
-
- Prefijo de segmento S3, introduzca
year=!{partitionKeyFromQuery:year}/month=!{partitionKeyFromQuery:month}/day=!{partitionKeyFromQuery:day}/hour=!{partitionKeyFromQuery:hour}/
- Prefijo de segmento S3, introduzca

Puede revisar los detalles de su flujo de entrega en la consola Kinesis Data Firehose.
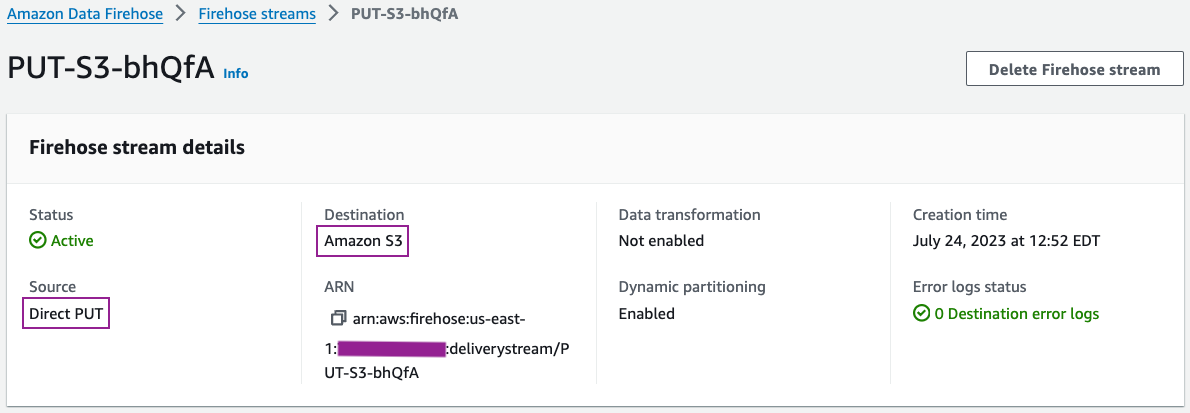
Los detalles de configuración de su flujo de entrega deben ser similares a la siguiente captura de pantalla.

- Genere datos de flujo de muestra desde KDG con el flujo de entrega de Firehose como destino con la siguiente plantilla:

- En la consola de Amazon S3, valide que el conjunto inicial de archivos se haya cargado en el depósito de S3.
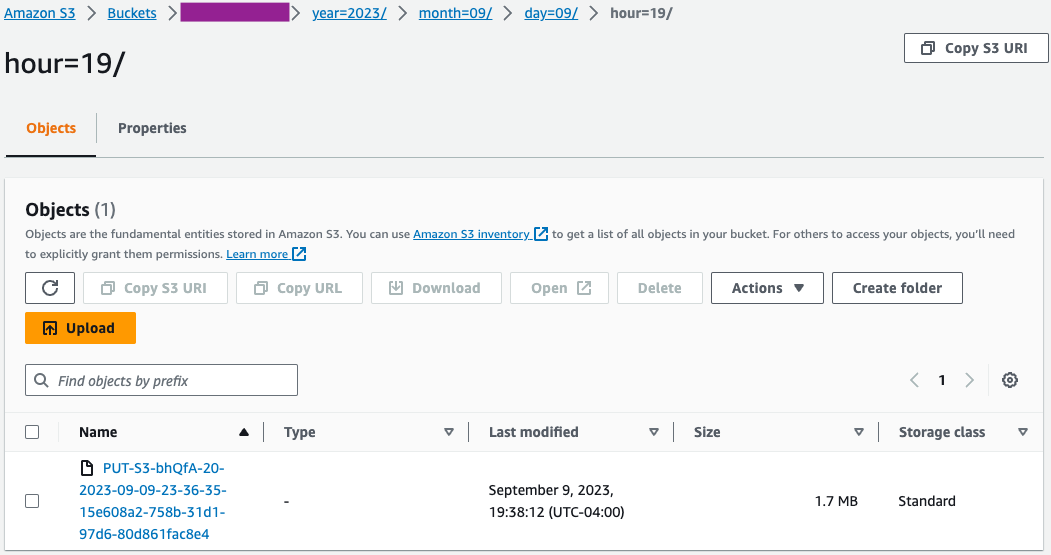
- En la consola de AWS Glue, crear y ejecutar un rastreador de AWS Glue con la fuente de datos como el depósito de S3 que utilizó en el paso anterior.
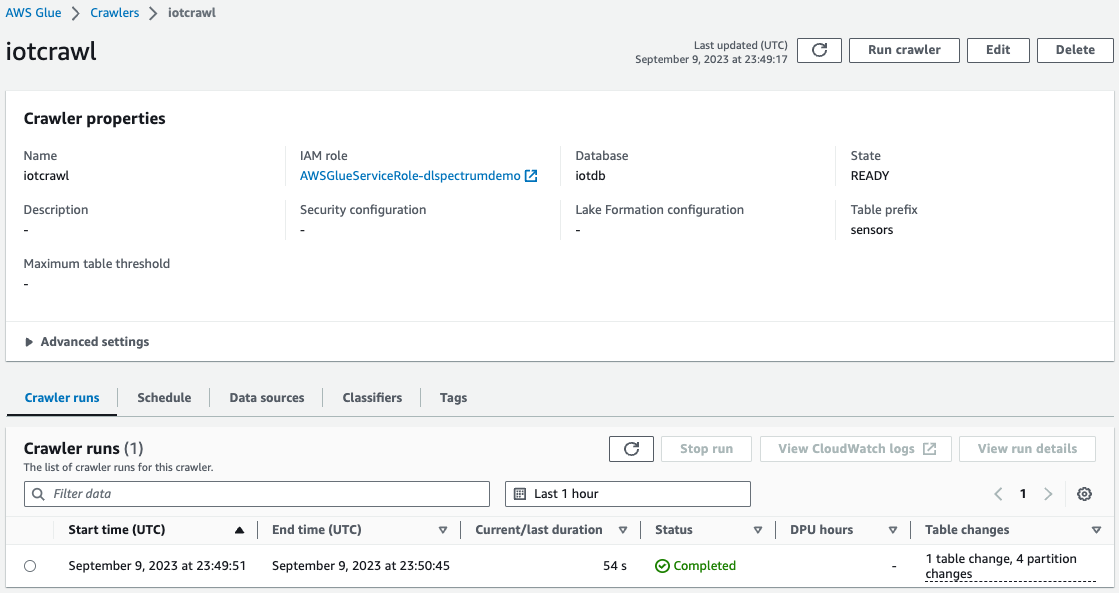
Cuando se complete el rastreador, podrá validar que la tabla se creó en la consola de AWS Glue.

Solucionando Problemas
Si los datos no se cargan en Amazon S3 después de enviarlos desde la plantilla KDG al flujo de entrega de Firehose, actualice y asegúrese de haber iniciado sesión en KDG.
Limpiar
Es posible que desee eliminar sus datos de S3 y el clúster de Redshift si no planea usarlos más para evitar costos innecesarios para su cuenta de AWS.
Conclusión
Con la aparición de requisitos para el análisis predictivo y prescriptivo basado en big data, existe una demanda creciente de soluciones de datos que integren datos de múltiples modelos de datos heterogéneos con un mínimo esfuerzo. En esta publicación, mostramos cómo se pueden derivar métricas de elementos de datos atómicos comunes de diferentes fuentes de datos con esquemas únicos. Puede almacenar datos de todas las fuentes de datos en una ubicación común de S3, ya sea en la misma carpeta o en varias subcarpetas de cada fuente de datos. Puede definir y programar un rastreador de AWS Glue para que se ejecute con la misma frecuencia que los requisitos de actualización de datos para su consumo de datos. Con esta solución, puede crear una tabla Redshift Spectrum para leer desde una ubicación S3 con diferentes estructuras de archivos mediante el catálogo de datos de AWS Glue y la funcionalidad de evolución de esquemas.
Si tiene alguna pregunta o sugerencia, deje sus comentarios en la sección de comentarios. Si necesita más ayuda para crear soluciones de análisis con datos de varios sensores de IoT, comuníquese con su equipo de cuentas de AWS.
Acerca de los autores
 Swapna Bandla es arquitecto de soluciones senior en el equipo SA de AWS Analytics Specialist. A Swapna le apasiona comprender las necesidades de análisis y datos de los clientes y capacitarlos para desarrollar soluciones bien diseñadas basadas en la nube. Fuera del trabajo, le gusta pasar tiempo con su familia.
Swapna Bandla es arquitecto de soluciones senior en el equipo SA de AWS Analytics Specialist. A Swapna le apasiona comprender las necesidades de análisis y datos de los clientes y capacitarlos para desarrollar soluciones bien diseñadas basadas en la nube. Fuera del trabajo, le gusta pasar tiempo con su familia.
 Indira Balakrishnan es Arquitecto principal de soluciones en el equipo de AWS Analytics Specialist SA. Le apasiona ayudar a los clientes a crear soluciones de análisis basadas en la nube para resolver sus problemas comerciales utilizando decisiones basadas en datos. Fuera del trabajo, es voluntaria en las actividades de sus hijos y pasa tiempo con su familia.
Indira Balakrishnan es Arquitecto principal de soluciones en el equipo de AWS Analytics Specialist SA. Le apasiona ayudar a los clientes a crear soluciones de análisis basadas en la nube para resolver sus problemas comerciales utilizando decisiones basadas en datos. Fuera del trabajo, es voluntaria en las actividades de sus hijos y pasa tiempo con su familia.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/build-an-analytics-pipeline-that-is-resilient-to-schema-changes-using-amazon-redshift-spectrum/

