Los clientes de AWS de los sectores de la salud, los servicios financieros, el sector público y otras industrias almacenan miles de millones de documentos como imágenes o archivos PDF en Servicio de almacenamiento simple de Amazon (Amazon S3). Sin embargo, no pueden obtener conocimientos como el uso de la información contenida en los documentos para modelos de lenguaje grandes (LLM) o realizar búsquedas hasta que extraen el texto, los formularios, las tablas y otros datos estructurados. Con el procesamiento inteligente de documentos (IDP) de AWS que utiliza servicios de inteligencia artificial como Amazon Textil, puede aprovechar la tecnología de aprendizaje automático (ML) líder en la industria para procesar datos de forma rápida y precisa desde archivos PDF o imágenes de documentos (TIFF, JPEG, PNG). Una vez extraído el texto de los documentos, puede utilizarlo para ajustar un modelo básico, resumir los datos utilizando un modelo básico, o enviarlo a una base de datos.
En esta publicación, nos centramos en procesar una gran colección de documentos en archivos de texto sin formato y almacenarlos en Amazon S3. Le proporcionamos dos soluciones diferentes para este caso de uso. El primero le permite ejecutar un script de Python desde cualquier servidor o instancia, incluido un cuaderno Jupyter; esta es la forma más rápida de empezar. El segundo enfoque es una implementación llave en mano de varios componentes de infraestructura utilizando Kit de desarrollo en la nube de AWS (CDK de AWS) construcciones. La construcción de AWS CDK proporciona un marco resistente y flexible para procesar sus documentos y crear una canalización de IDP de un extremo a otro. Mediante el uso de AWS CDK, puede ampliar su funcionalidad para incluir redacción, almacenar la salida en Amazon OpenSearch, o agregar un personalizado AWS Lambda funcionar con su propia lógica de negocio.
Ambas soluciones le permiten procesar rápidamente muchos millones de páginas. Antes de ejecutar cualquiera de estas soluciones a escala, recomendamos probar con un subconjunto de sus documentos para asegurarse de que los resultados cumplan con sus expectativas. En las siguientes secciones, primero describimos la solución de script, seguida de la solución de construcción de AWS CDK.
Solución 1: utilice un script de Python
Esta solución procesa documentos para texto sin formato a través de Amazon Textract tan rápido como el servicio lo permite, con la expectativa de que si hay una falla en el script, el proceso continuará donde lo dejó. La solución utiliza tres servicios diferentes: Amazon S3, Amazon DynamoDBy Extracto de texto de Amazon.
El siguiente diagrama ilustra la secuencia de eventos dentro del guión. Cuando finalice el guión, se devolverá a la consola de SageMaker Studio un estado de finalización junto con el tiempo necesario.

Hemos empaquetado esta solución en un secuencia de comandos .ipynb y secuencia de comandos .py. Puede utilizar cualquiera de las soluciones implementables según sus requisitos.
Requisitos previos
Para ejecutar este script desde un cuaderno Jupyter, el Gestión de identidades y accesos de AWS (IAM) asignado al cuaderno debe tener permisos que le permitan interactuar con DynamoDB, Amazon S3 y Amazon Textract. La orientación general es proporcionar permisos con privilegios mínimos para cada uno de estos servicios a su AmazonSageMaker-ExecutionRole role. Para obtener más información, consulte Comience a utilizar las políticas administradas de AWS y avance hacia permisos con privilegios mínimos.
Alternativamente, puede ejecutar este script desde otros entornos, como un Nube informática elástica de Amazon (Amazon EC2) instancia o contenedor que administraría, siempre que Python, Pip3 y el AWS SDK para Python (Boto3) están instalados. Nuevamente, se deben aplicar las mismas políticas de IAM que permiten que el script interactúe con los distintos servicios administrados.
Tutorial
Para implementar esta solución, primero necesita clonar el repositorio. GitHub.
Debe configurar las siguientes variables en el script antes de poder ejecutarlo:
- tabla_seguimiento – Este es el nombre de la tabla de DynamoDB que se creará.
- cubo_entrada – Esta es su ubicación de origen en Amazon S3 que contiene los documentos que desea enviar a Amazon Textract para la detección de texto. Para esta variable, proporcione el nombre del depósito, como
mybucket. - cubo_salida – Esto es para almacenar la ubicación donde desea que Amazon Textract escriba los resultados. Para esta variable, proporcione el nombre del depósito, como
myoutputbucket. - _input_prefix (opcional) – Si desea seleccionar ciertos archivos dentro de una carpeta en su depósito S3, puede especificar el nombre de esta carpeta como prefijo de entrada. De lo contrario, deje el valor predeterminado vacío para seleccionar todo.
El guión es el siguiente:
El siguiente esquema de tabla de DynamoDB se crea cuando se ejecuta el script:
Cuando el script se ejecuta por primera vez, comprobará si la tabla de DynamoDB existe y la creará automáticamente si es necesario. Una vez creada la tabla, debemos completarla con una lista de referencias de objetos de documentos de Amazon S3 que queremos procesar. El script por diseño enumerará más de los objetos en el especificado input_bucket y rellenar automáticamente nuestra tabla con sus nombres cuando se ejecute. Se necesitan aproximadamente 10 minutos para enumerar más de 100,000 3 documentos y completar esos nombres en la tabla de DynamoDB desde el script. Si tiene millones de objetos en un depósito, también puede usar la función de inventario de Amazon SXNUMX que genera un archivo CSV de nombres, luego completar la tabla de DynamoDB de esta lista con su propio script de antemano y no usar la función llamada fetchAllObjectsInBucketandStoreName comentándolo. Para obtener más información, consulte Configuración del inventario de Amazon S3.
Como se mencionó anteriormente, existe una versión para computadora portátil y una versión para script en Python. El cuaderno es la forma más sencilla de empezar; simplemente ejecute cada celda de principio a fin.
Si decide ejecutar el script Python desde una CLI, se recomienda utilizar un multiplexor de terminal como tmux. Esto es para evitar que el script se detenga si finaliza su sesión SSH. Por ejemplo: tmux new -d ‘python3 textractFeeder.py’.
El siguiente es el punto de entrada del guión; desde aquí puedes comentar los métodos que no sean necesarios:
Los siguientes campos se configuran cuando el script completa la tabla de DynamoDB:
- nombre del objeto – El nombre del documento ubicado en Amazon S3 que se enviará a Amazon Textract
- nombre del cubo – El depósito donde se almacena el objeto del documento.
Estos dos campos deben completarse si decide utilizar un archivo CSV del informe de inventario de S3 y omitir el llenado automático que ocurre dentro del script.
Ahora que la tabla está creada y completada con las referencias de objetos del documento, el script está listo para comenzar a llamar a Amazon Textract. StartDocumentTextDetection API. Amazon Textract, al igual que otros servicios administrados, tiene una límite predeterminado en las API llamadas transacciones por segundo (TPS). Si es necesario, puede solicitar un aumento de cuota desde la consola de Amazon Textract. El código está diseñado para utilizar varios subprocesos simultáneamente al llamar a Amazon Textract para maximizar el rendimiento del servicio. Puede cambiar esto dentro del código modificando el threadCountforTextractAPICall variable. De forma predeterminada, esto está configurado en 20 subprocesos. Inicialmente, el script leerá 200 filas de la tabla de DynamoDB y las almacenará en una lista en memoria que está empaquetada con una clase para seguridad de subprocesos. Luego, cada hilo de llamada se inicia y se ejecuta dentro de su propio carril. Básicamente, el hilo de llamada de Amazon Textract recuperará un elemento de la lista en memoria que contiene nuestra referencia de objeto. Luego llamará al asincrónico. start_document_text_detection API y espere el reconocimiento con el ID del trabajo. Luego, el ID del trabajo se actualiza nuevamente a la fila de DynamoDB para ese objeto y el hilo se repetirá recuperando el siguiente elemento de la lista.
El siguiente es el código de orquestación principal. guión:
Los hilos de llamada continuarán repitiéndose hasta que ya no haya elementos dentro de la lista, momento en el cual los hilos se detendrán. Cuando todos los subprocesos que operan dentro de sus carriles se han detenido, se recuperan las siguientes 200 filas de DynamoDB y se inicia un nuevo conjunto de 20 subprocesos, y todo el proceso se repite hasta que cada fila que no contiene un ID de trabajo se recupera de DynamoDB y actualizado. Si el script falla debido a algún problema inesperado, entonces el script se puede ejecutar nuevamente desde el orchestrate() método. Esto garantiza que los subprocesos continuarán procesando filas que contienen ID de trabajo vacíos. Tenga en cuenta que al volver a ejecutar el orchestrate() método después de que el script se haya detenido, existe la posibilidad de que algunos documentos se envíen nuevamente a Amazon Textract. Este número será igual o menor que el número de subprocesos que se estaban ejecutando en el momento del bloqueo.
Cuando no haya más filas que contengan un ID de trabajo en blanco en la tabla de DynamoDB, el script se detendrá. Toda la salida JSON de Amazon Textract para todos los objetos se encontrará en el output_bucket por defecto bajo el textract_output carpeta. Cada subcarpeta dentro textract_output se nombrará con el ID del trabajo que corresponde al ID del trabajo que se almacenó en la tabla de DynamoDB para ese objeto. Dentro de la carpeta de ID del trabajo, encontrará el JSON, que tendrá un nombre numérico comenzando en 1 y potencialmente puede abarcar archivos JSON adicionales que se etiquetarían como 2, 3, etc. La extensión de archivos JSON es el resultado de documentos densos o de varias páginas, donde la cantidad de contenido extraído excede el tamaño JSON predeterminado de Amazon Textract de 1,000 bloques. Referirse a Bloquear para obtener más información sobre los bloques. Estos archivos JSON contendrán todos los metadatos de Amazon Textract, incluido el texto extraído de los documentos.
Puede encontrar la versión del cuaderno de códigos Python y el script para esta solución en GitHub.
Limpiar
Cuando el script de Python esté completo, puede ahorrar costos cerrando o deteniendo el Estudio Amazon SageMaker cuaderno o recipiente que hiciste.
Pasemos ahora a nuestra segunda solución para documentos a escala.
Solución 2: utilice una construcción AWS CDK sin servidor
Esta solución utiliza Funciones de paso de AWS y funciones Lambda para orquestar el canal IDP. Usamos el Construcciones IDP AWS CDK, que facilitan el trabajo con Amazon Textract a escala. Además utilizamos un Mapa distribuido de funciones de paso para iterar sobre todos los archivos en el depósito de S3 e iniciar el procesamiento. La primera función Lambda determina cuántas páginas tienen sus documentos. Esto permite que la canalización utilice automáticamente la API sincrónica (para documentos de una sola página) o asincrónica (para documentos de varias páginas). Cuando se utiliza la API asincrónica, se llama a una función Lambda adicional para todos los archivos JSON que Amazon Textract producirá para todas sus páginas en un archivo JSON para que sus aplicaciones posteriores puedan trabajar con la información de manera sencilla.
Esta solución también contiene dos funciones Lambda adicionales. La primera función analiza el texto del JSON y lo guarda como un archivo de texto en Amazon S3. La segunda función analiza el JSON y lo almacena para las métricas de la carga de trabajo.
El siguiente diagrama ilustra el flujo de trabajo de Step Functions.

Requisitos previos
Esta base de código utiliza AWS CDK y requiere Docker. Puede implementar esto desde un Nube de AWS9 instancia, que ya tiene AWS CDK y Docker configurados.
Tutorial
Para implementar esta solución, primero debe clonar el repositorio.
Después de clonar el repositorio, instale las dependencias:
Luego utilice el siguiente código para implementar la pila de AWS CDK:
Debe proporcionar tanto el depósito de origen como el prefijo de origen (la ubicación de los archivos que desea procesar) para esta solución.
Cuando se complete la implementación, navegue hasta la consola de Step Functions, donde debería ver la máquina de estado. ServerlessIDPArchivePipeline.
Abra la página de detalles de la máquina de estado y en el Ejecuciones pestaña, elegir Iniciar ejecución.
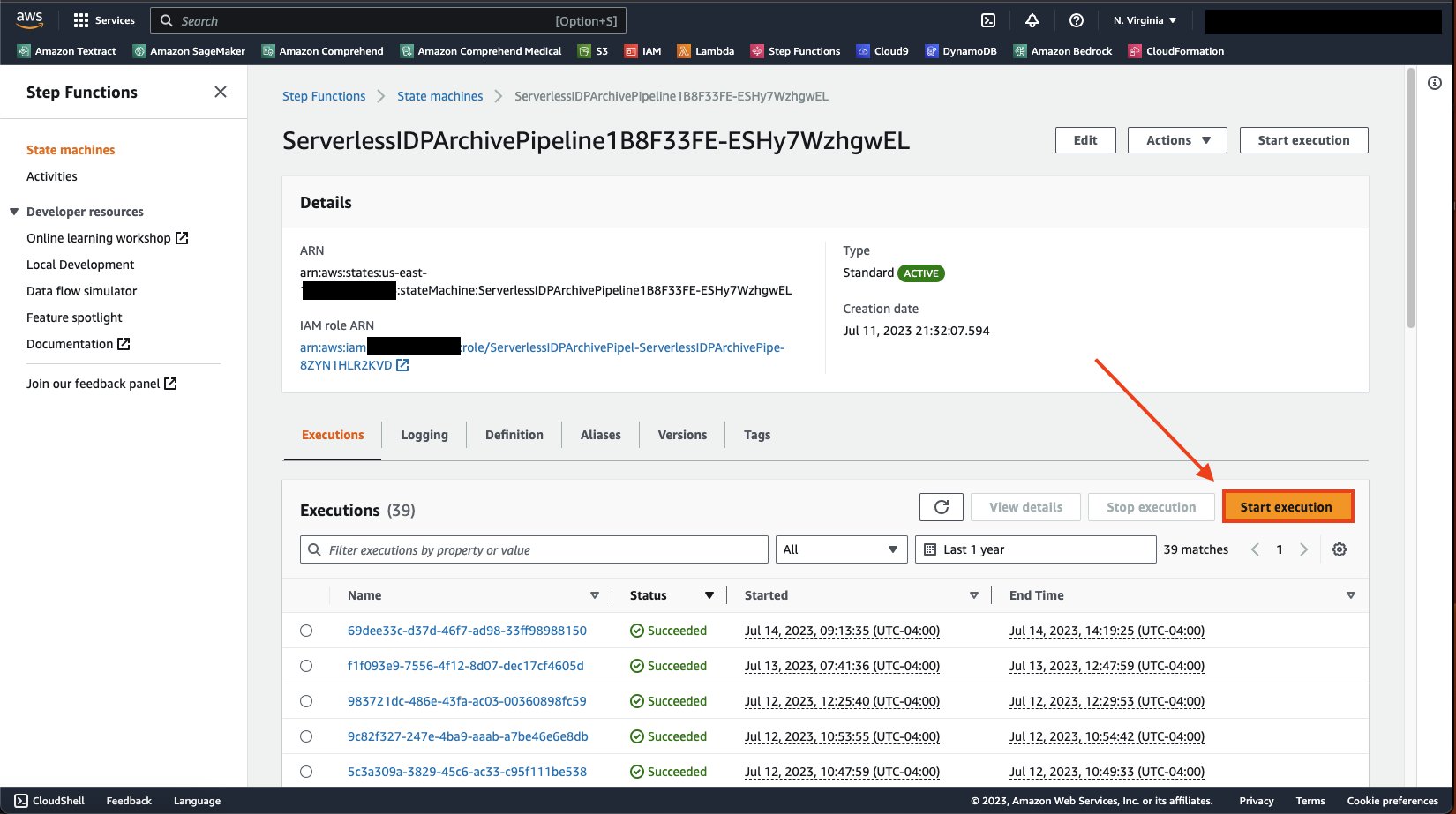
Elige Iniciar ejecución nuevamente para ejecutar la máquina de estados.
Después de iniciar la máquina de estado, puede monitorear la canalización observando la ejecución del mapa. Verás un Estado de procesamiento del artículo sección como la siguiente captura de pantalla. Como puede ver, esto está diseñado para ejecutarse y realizar un seguimiento de lo que tuvo éxito y lo que falló. Este proceso continuará ejecutándose hasta que se hayan leído todos los documentos.

Con esta solución, debería poder procesar millones de archivos en su cuenta de AWS sin preocuparse por cómo determinar correctamente qué archivos enviar a qué API o archivos corruptos que fallan en su canalización. A través de la consola de Step Functions, podrás ver y monitorear tus archivos en tiempo real.
Limpiar
Una vez que su canalización haya terminado de ejecutarse, para limpiar, puede volver a su proyecto e ingresar el siguiente comando:
Esto eliminará todos los servicios que se implementaron para este proyecto.
Conclusión
En esta publicación, presentamos una solución que simplifica la conversión de imágenes de documentos y archivos PDF en archivos de texto. Este es un requisito previo clave para utilizar sus documentos para búsqueda e inteligencia artificial generativa. Para obtener más información sobre el uso de texto para entrenar o ajustar sus modelos básicos, consulte Ajuste Llama 2 para la generación de texto en Amazon SageMaker JumpStart. Para utilizar con la búsqueda, consulte Implemente un índice de búsqueda de documentos inteligente con Amazon Textract y Amazon OpenSearch. Para obtener más información sobre las capacidades avanzadas de procesamiento de documentos que ofrecen los servicios de IA de AWS, consulte Guía para el procesamiento inteligente de documentos en AWS.
Acerca de los autores
 Tim Condello es arquitecto senior de soluciones especializado en inteligencia artificial (IA) y aprendizaje automático (ML) en Amazon Web Services (AWS). Su enfoque es el procesamiento del lenguaje natural y la visión por computadora. A Tim le gusta tomar las ideas de los clientes y convertirlas en soluciones escalables.
Tim Condello es arquitecto senior de soluciones especializado en inteligencia artificial (IA) y aprendizaje automático (ML) en Amazon Web Services (AWS). Su enfoque es el procesamiento del lenguaje natural y la visión por computadora. A Tim le gusta tomar las ideas de los clientes y convertirlas en soluciones escalables.
 David Girling es un arquitecto senior de soluciones de IA/ML con más de veinte años de experiencia en el diseño, liderazgo y desarrollo de sistemas empresariales. David forma parte de un equipo de especialistas que se centra en ayudar a los clientes a aprender, innovar y utilizar estos servicios de gran capacidad con sus datos para sus casos de uso.
David Girling es un arquitecto senior de soluciones de IA/ML con más de veinte años de experiencia en el diseño, liderazgo y desarrollo de sistemas empresariales. David forma parte de un equipo de especialistas que se centra en ayudar a los clientes a aprender, innovar y utilizar estos servicios de gran capacidad con sus datos para sus casos de uso.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/create-a-document-lake-using-large-scale-text-extraction-from-documents-with-amazon-textract/

