Esta publicación está escrita en colaboración con Claudia Chitu y Dosis de Spyridon de ACAST.
Fundada en 2014, Un molde es la empresa de podcasts independiente líder en el mundo, que ofrece a los creadores y anunciantes de podcasts la mejor experiencia auditiva. Al defender un ecosistema independiente y abierto para el podcasting, Acast pretende impulsar el podcasting con las herramientas y la monetización necesarias para prosperar.
La empresa utiliza los servicios de la nube de AWS para crear productos basados en datos y escalar las mejores prácticas de ingeniería. Para garantizar una plataforma de datos sostenible en medio de las fases de crecimiento y rentabilidad, sus equipos tecnológicos adoptaron una solución descentralizada. arquitectura de malla de datos.
En esta publicación, analizamos cómo Acast superó el desafío de las dependencias acopladas entre equipos que trabajan con datos a escala empleando el concepto de malla de datos.
El problema
Con un crecimiento y una expansión acelerados, Acast enfrentó un desafío que resuena a nivel mundial. Acast se encontró con diversas unidades de negocios y una gran cantidad de datos generados en toda la organización. La arquitectura monolítica y centralizada existente luchaba por satisfacer las crecientes demandas de los consumidores de datos. A los ingenieros de datos les resultaba cada vez más difícil mantener y escalar la infraestructura de datos, lo que generaba acceso a los datos, silos de datos e ineficiencias en la gestión de datos. Un objetivo clave era mejorar la experiencia del usuario de un extremo a otro, partiendo de las necesidades del negocio.
Acast necesitaba abordar estos desafíos para alcanzar una escala operativa, es decir, un máximo global de personas que pueden operar y ofrecer valor de forma independiente. En este caso, Acast intentó abordar el desafío de esta estructura monolítica y el alto tiempo de obtención de valor para los equipos de productos, equipos tecnológicos y consumidores finales. Vale la pena mencionar que también tienen otros equipos de productos y tecnología, incluidos equipos operativos o comerciales, sin cuentas de AWS.
Acast tiene un número variable de equipos de productos, que evolucionan continuamente fusionando los existentes, dividiéndolos, agregando nuevas personas o simplemente creando nuevos equipos. En los últimos dos años, han tenido entre 2 y 10 equipos, compuestos por entre 20 y 4 personas cada uno. Cada equipo posee al menos dos cuentas de AWS, hasta 10 cuentas, según la propiedad. La mayoría de los datos producidos por estas cuentas se utilizan posteriormente con fines de inteligencia empresarial (BI) y en Atenea amazónica, por cientos de usuarios empresariales todos los días.
La solución que implementó Acast es una malla de datos, diseñada en AWS. La solución refleja la estructura organizativa más que una decisión arquitectónica explícita. Según la maniobra inversa de Conway, la arquitectura tecnológica de Acast muestra isomorfismo con la arquitectura empresarial. En este caso, los usuarios empresariales pueden, a través de la arquitectura de malla de datos, obtener información más rápidamente y saber directamente quiénes son los propietarios de un dominio específico, lo que acelera la colaboración. Esto se detallará con más detalle cuando analicemos los roles de AWS Identity and Access Management (IAM) utilizados en nuestra certificación de AWS porque uno de los roles está dedicado al grupo empresarial.
Parámetros de éxito
Acast logró iniciar y escalar un nuevo producto de datos orientado a equipos y dominios y su correspondiente infraestructura y configuración, lo que resultó en menos fricción en la recopilación de conocimientos y usuarios y consumidores más felices.
El éxito de la implementación significó evaluar varios aspectos de la infraestructura de datos, la gestión de datos y los resultados comerciales. Clasificaron las métricas e indicadores en las siguientes categorías:
- El uso de datos – Una comprensión clara de quién consume qué fuente de datos, materializada con un mapeo de consumidores y productores. Las conversaciones con los usuarios mostraron que estaban más contentos de tener un acceso más rápido a los datos de una manera más sencilla, una organización de datos más estructurada y un mapeo claro de quién es el productor. Se ha avanzado mucho para avanzar en su cultura basada en datos (alfabetización en datos, intercambio de datos y colaboración entre unidades de negocio).
- Gobierno de Datos – Con su objeto de nivel de servicio que indica cuándo están disponibles las fuentes de datos (entre otros detalles), los equipos saben a quién notificar y pueden hacerlo en menos tiempo cuando llegan datos tarde u otros problemas con los datos. Con la implementación de una función de administrador de datos, la propiedad se ha fortalecido.
- Productividad del equipo de datos – A través de retrospectivas de ingeniería, Acast descubrió que sus equipos aprecian la autonomía para tomar decisiones con respecto a sus dominios de datos.
- Eficiencia de costos y recursos – Esta es un área donde Acast observó una reducción en la duplicación de datos y, por lo tanto, una reducción de costos (en algunas cuentas, eliminando la copia de datos al 100%), al leer datos entre cuentas y al mismo tiempo permitir el escalamiento.
Descripción general de la malla de datos
Una malla de datos es un enfoque sociotécnico para construir una arquitectura de datos descentralizada mediante el uso de un diseño de autoservicio orientado a dominios (en una perspectiva de desarrollo de software), y toma prestada la teoría del diseño impulsado por dominios de Eric Evans y la de Manuel Pais y Matthew Skelton. Teoría de topologías de equipos. Es importante establecer el contexto para comprender qué es la malla de datos porque prepara el escenario para los detalles técnicos que siguen y puede ayudarlo a comprender cómo los conceptos discutidos en esta publicación encajan en el marco más amplio de una malla de datos.
Para resumir antes de profundizar en la implementación de Acast, el concepto de malla de datos se basa en los siguientes principios:
- Está impulsado por el dominio, a diferencia de las canalizaciones como una preocupación de primera clase.
- Sirve datos como producto.
- Es un buen producto que deleita a los usuarios (los datos son confiables, la documentación está disponible y es fácilmente consumible)
- Ofrece gobernanza computacional federada y propiedad descentralizada: una plataforma de datos de autoservicio
Arquitectura basada en dominios
En el enfoque de Acast de poseer los conjuntos de datos operativos y analíticos, los equipos están estructurados con propiedad basada en el dominio, leyendo directamente del productor de los datos, a través de una API o mediante programación desde el almacenamiento de Amazon S3 o utilizando Athena como motor de consultas SQL. En la siguiente figura se presentan algunos ejemplos de los dominios de Acast.
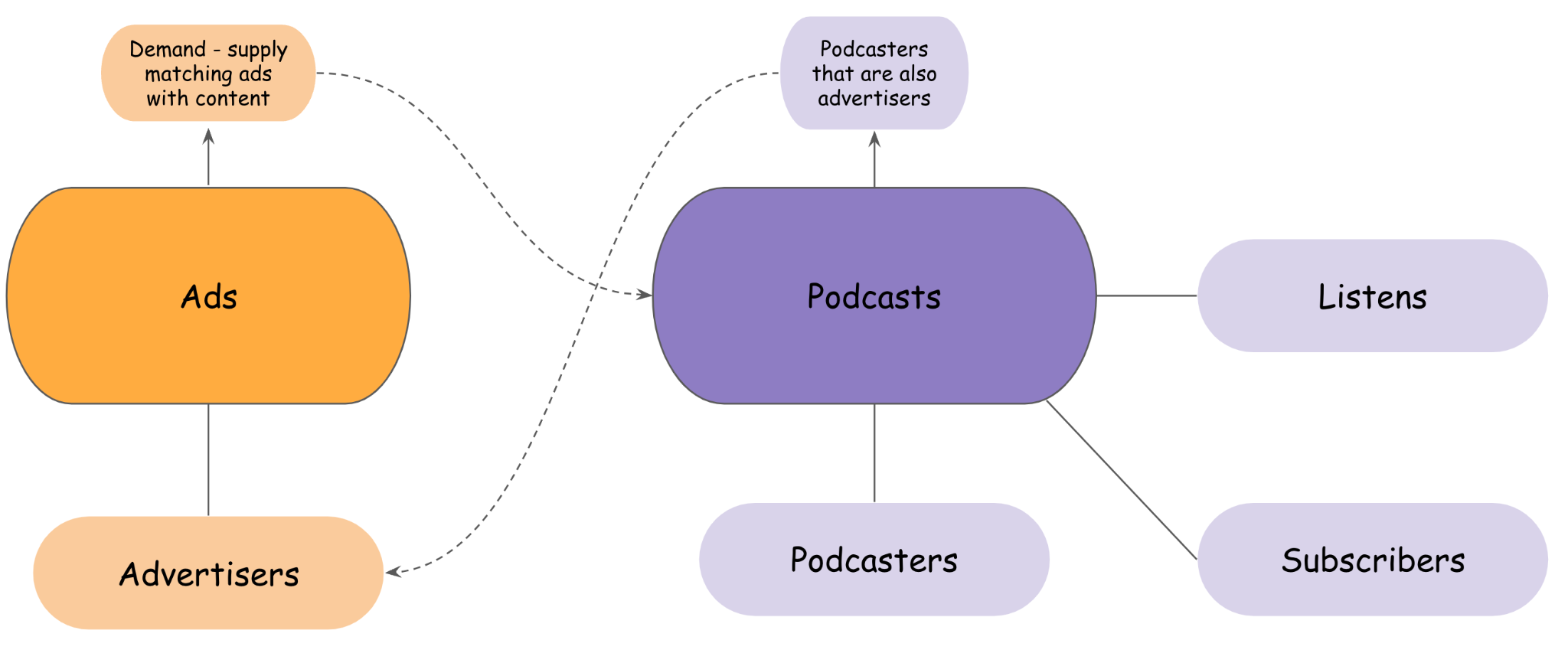
Como se ilustra en la figura anterior, algunos dominios están débilmente acoplados a los puntos finales operativos o analíticos de otros dominios, con una propiedad diferente. Otros podrían tener una mayor dependencia, como se espera, para los negocios (algunos podcasters también pueden ser anunciantes, creando creatividades de patrocinio y ejecutando campañas para sus propios programas, o realizando transacciones publicitarias utilizando el software como servicio de Acast).
Los datos como producto
Tratar los datos como un producto implica tres componentes clave: los datos en sí, los metadatos y el código y la infraestructura asociados. En este enfoque, los equipos responsables de generar datos se denominan productores. Estos equipos de productores poseen un conocimiento profundo sobre sus consumidores y comprenden cómo se utiliza su producto de datos. Cualquier cambio planificado por los productores de datos se comunica con antelación a todos los consumidores. Esta notificación proactiva garantiza que los procesos posteriores no se vean interrumpidos. Al avisar a los consumidores con antelación, tienen tiempo suficiente para prepararse y adaptarse a los próximos cambios, manteniendo un flujo de trabajo fluido e ininterrumpido. Los productores ejecutan una nueva versión del conjunto de datos inicial en paralelo, notifican a los consumidores individualmente y discuten con ellos el plazo necesario para comenzar a consumir la nueva versión. Cuando todos los consumidores utilizan la nueva versión, los productores hacen que la versión inicial no esté disponible.
Los esquemas de datos se infieren del formato común acordado para compartir archivos entre equipos, que es Parquet en el caso de Acast. Los datos se pueden compartir en archivos, eventos por lotes o en streaming, y más. Cada equipo tiene su propia cuenta de AWS actuando como una entidad independiente y autónoma con su propia infraestructura. Para la orquestación utilizan el Kit de desarrollo en la nube de AWS (AWS CDK) para infraestructura como código (IaC) y Pegamento AWS Catálogos de datos para la gestión de metadatos. Los usuarios también pueden presentar solicitudes a los productores para mejorar la forma en que se presentan los datos o enriquecerlos con nuevos puntos de datos para generar un mayor valor comercial.
Dado que cada equipo posee una cuenta de AWS y un ID de catálogo de datos de Athena, es sencillo ver esto a través de las lentes de un lago de datos distribuido en la parte superior de Amazon S3, con un catálogo común que mapea todos los catálogos de todas las cuentas.
Al mismo tiempo, cada equipo también puede asignar otros catálogos a su propia cuenta y utilizar sus propios datos, que producen junto con los datos de otras cuentas. A menos que se trate de datos confidenciales, se puede acceder a ellos mediante programación o desde el Consola de administración de AWS de forma autoservicio sin depender de los ingenieros de infraestructura de datos. Esta es una forma compartida e independiente del dominio de autoservicio de datos. El descubrimiento del producto se produce a través del registro del catálogo. Utilizando solo unos pocos estándares comúnmente acordados y adoptados en toda la empresa, con fines de interoperabilidad, Acast abordó los silos fragmentados y la fricción para intercambiar datos o consumir datos independientes del dominio.
Con este principio, los equipos obtienen la seguridad de que los datos son seguros, confiables y precisos, y se administran controles de acceso adecuados en cada nivel de dominio. Además, en la cuenta central, se definen roles para diferentes tipos de permisos y accesos, utilizando Centro de identidad de AWS IAM permisos. Todos los conjuntos de datos se pueden descubrir desde una única cuenta central. La siguiente figura ilustra cómo está instrumentado, donde dos tipos de grupos de usuarios (consumidores) asumen dos roles de IAM: uno que tiene acceso a un conjunto de datos limitado, que son datos restringidos, y otro que tiene acceso a datos no restringidos. También existe una manera de asumir cualquiera de estos roles, para cuentas de servicio, como las utilizadas en trabajos de procesamiento de datos en Flujos de trabajo administrados por Amazon para Apache Airflow (Amazon MWAA), por ejemplo.
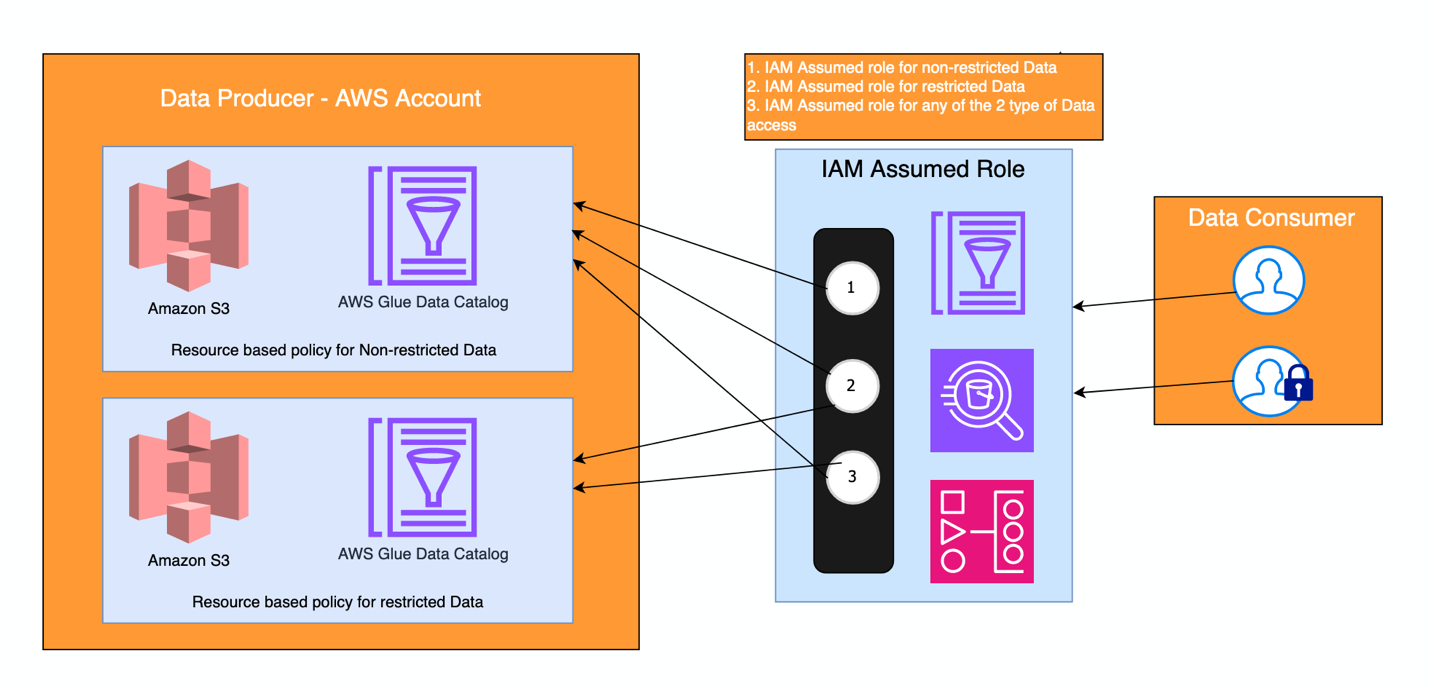
Cómo resolvió Acast la alta alineación y una arquitectura débilmente acoplada
El siguiente diagrama muestra una arquitectura conceptual de cómo los equipos de Acast organizan datos y colaboran entre sí.
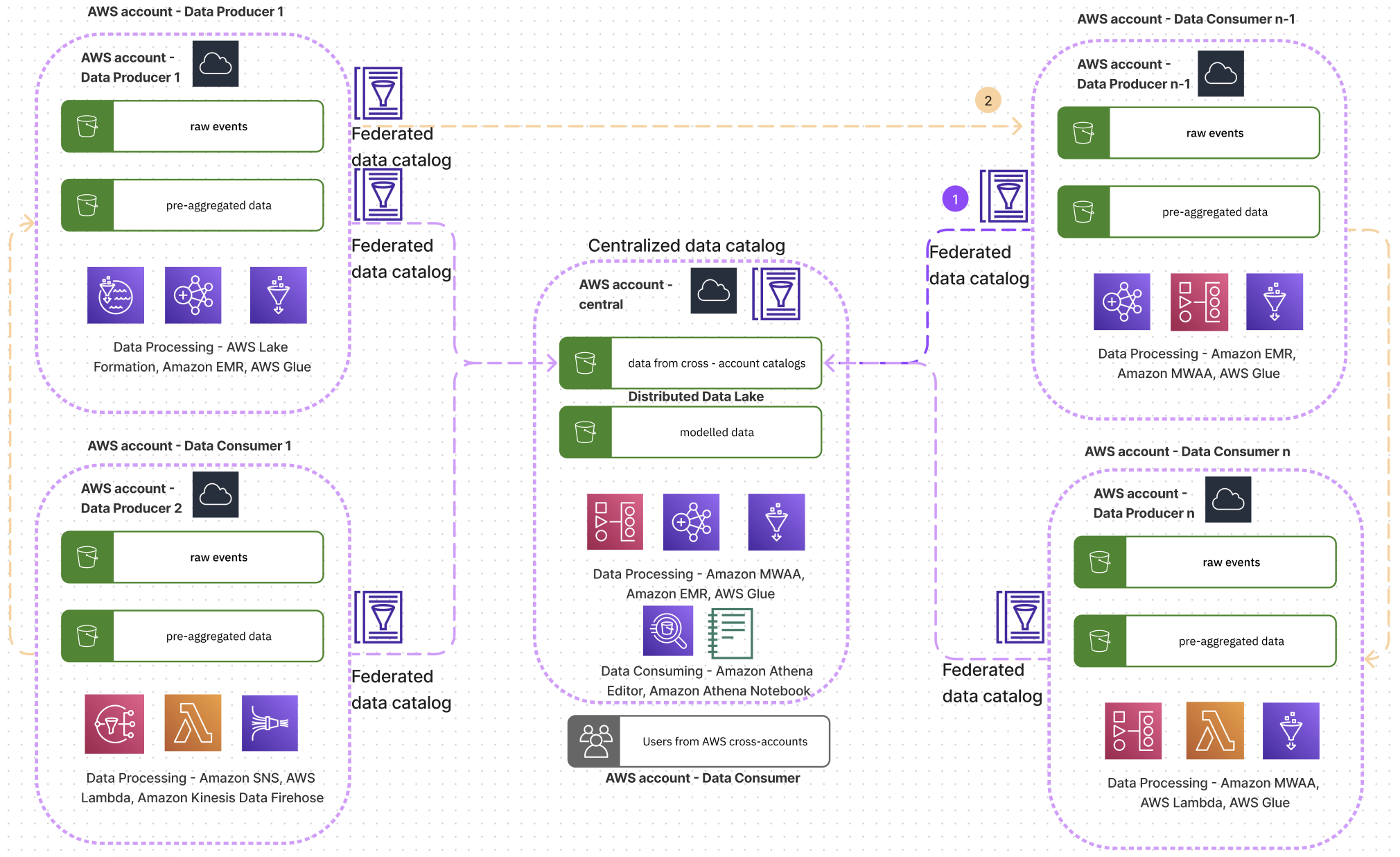
Acast utilizó el Marco bien diseñado para que la cuenta central mejore su práctica de ejecutar cargas de trabajo analíticas en la nube. A través de los lentes de la herramienta, Acast pudo abordar un mejor monitoreo, optimización de costos, rendimiento y seguridad. Les ayudó a comprender las áreas en las que podrían mejorar sus cargas de trabajo y cómo abordar problemas comunes, con soluciones automatizadas, además de cómo medir el éxito, definiendo KPI. Les ahorró tiempo para obtener aprendizajes que de otro modo les habría llevado más tiempo encontrar. Spyridon Dosis, responsable de seguridad de la información de Acast, comparte: “Estamos contentos de que AWS siempre esté a la vanguardia en el lanzamiento de herramientas que permiten la configuración, evaluación y revisión de la configuración de múltiples cuentas. Esta es una gran ventaja para nosotros, trabajar en una organización descentralizada”. Spyridon también agrega: "Un concepto muy importante que valoramos son los valores predeterminados de seguridad de AWS (por ejemplo, el cifrado predeterminado para los depósitos S3)".
En el diagrama de arquitectura, podemos ver que cada equipo puede ser un productor de datos, excepto el equipo que posee la cuenta central, que sirve como plataforma de datos central, modelando la lógica de múltiples dominios para pintar el panorama empresarial completo. Todos los demás equipos pueden ser productores o consumidores de datos. Pueden conectarse a la cuenta central y descubrir conjuntos de datos a través del catálogo de datos de AWS Glue entre cuentas, analizarlos en el editor de consultas de Athena o con los cuadernos de Athena, o asignar el catálogo a su propia cuenta de AWS. El acceso al catálogo central de Athena se implementa con IAM Identity Center, con funciones para datos abiertos y acceso restringido a datos.
Para datos no confidenciales (datos abiertos), Acast utiliza una plantilla donde los conjuntos de datos están abiertos de forma predeterminada para que toda la organización pueda leerlos, utilizando una condición para proporcionar el parámetro de ID asignado por la organización, como se muestra en el siguiente fragmento de código:
Cuando manejan datos confidenciales como los financieros, los equipos utilizan un modelo colaborativo de administración de datos. El administrador de datos trabaja con el solicitante para evaluar la justificación del acceso para el caso de uso previsto. Juntos, determinan los métodos de acceso apropiados para satisfacer la necesidad manteniendo la seguridad. Esto podría incluir roles de IAM, cuentas de servicio o servicios de AWS específicos. Este enfoque permite a los usuarios empresariales fuera de la organización tecnológica (lo que significa que no tienen una cuenta de AWS) acceder y analizar de forma independiente la información que necesitan. Al otorgar acceso a través de políticas de IAM a los recursos de AWS Glue y los depósitos de S3, Acast proporciona capacidades de autoservicio y al mismo tiempo controla los datos delicados mediante la revisión humana. La función de administrador de datos ha sido valiosa para comprender los casos de uso, evaluar los riesgos de seguridad y, en última instancia, facilitar el acceso que acelera el negocio a través de conocimientos analíticos.
Para el caso de uso de Acast, no se necesitaban controles de acceso granulares a nivel de fila o columna, por lo que el enfoque fue suficiente. Sin embargo, otras organizaciones pueden requerir una gobernanza más detallada sobre campos de datos confidenciales. En esos casos, soluciones como Formación del lago AWS podría implementar los permisos necesarios y al mismo tiempo proporcionar un modelo de acceso a datos de autoservicio. Para obtener más información, consulte Diseñe una arquitectura de malla de datos con AWS Lake Formation y AWS Glue.
Al mismo tiempo, los equipos pueden leer directamente de otros productores, desde Amazon S3 o mediante una API, manteniendo la dependencia al mínimo, lo que mejora la velocidad de desarrollo y entrega. Por tanto, una cuenta puede ser productora y consumidora al mismo tiempo. Cada equipo es autónomo y es responsable de su propia pila tecnológica.
Aprendizajes adicionales
¿Qué aprendió Acast? Hasta ahora hemos discutido que el diseño arquitectónico es un efecto de la estructura organizacional. Debido a que la organización tecnológica consta de múltiples equipos multifuncionales y es sencillo iniciar un nuevo equipo, siguiendo los principios comunes de la malla de datos, Acast aprendió que esto no siempre funciona sin problemas. Para configurar una cuenta completamente nueva en AWS, los equipos pasan por el mismo viaje, pero ligeramente diferente, considerando su propio conjunto de particularidades.
Esto puede crear ciertas fricciones y es difícil lograr que todos los equipos de producción de datos alcancen una alta madurez como productores de datos. Esto puede explicarse por las diferentes competencias en datos en esos equipos multifuncionales y por no ser equipos de datos dedicados.
Al implementar la solución descentralizada, Acast abordó eficazmente el desafío de la escalabilidad adaptando sus equipos para alinearse con las necesidades comerciales en evolución. Este enfoque garantiza un alto desacoplamiento y alineación. Además, fortalecieron la propiedad, reduciendo significativamente el tiempo necesario para identificar y resolver problemas porque la fuente ascendente es fácilmente conocida y accesible con SLA específicos. El volumen de consultas de soporte de datos ha experimentado una reducción de más del 50 %, porque los usuarios empresariales pueden obtener información más rápidamente. En particular, eliminaron con éxito decenas de terabytes de almacenamiento redundante que antes se copiaban únicamente para cumplir con solicitudes posteriores. Este logro fue posible gracias a la implementación de lectura cruzada de cuentas, lo que llevó a la eliminación de los costos asociados de desarrollo y mantenimiento de estos ductos.
Conclusión
Acast utilizó la ley de maniobra inversa de Conway y empleó servicios de AWS donde cada equipo de producto multifuncional tiene su propia cuenta de AWS para construir una arquitectura de malla de datos que permita escalabilidad, alta propiedad y consumo de datos de autoservicio. Esto ha funcionado bien para la empresa en cuanto a cómo se abordaron la propiedad de los datos y las operaciones, para cumplir con sus principios de ingeniería, lo que resultó en que la malla de datos fuera un efecto en lugar de una intención deliberada. Para otras organizaciones, la malla de datos deseada podría verse diferente y el enfoque podría tener otros aprendizajes.
Para concluir, un arquitectura de datos moderna en AWS le permite construir de manera eficiente productos de datos e infraestructura de malla de datos a bajo costo sin comprometer el rendimiento.
Los siguientes son algunos ejemplos de servicios de AWS que puede utilizar para diseñar la malla de datos que desee en AWS:
Acerca de los autores
 Claudia Chitú es un estratega de datos y un líder influyente en el espacio de análisis. Centrada en alinear las iniciativas de datos con los objetivos estratégicos generales de la organización, emplea los datos como fuerza guía para la planificación a largo plazo y el crecimiento sostenible.
Claudia Chitú es un estratega de datos y un líder influyente en el espacio de análisis. Centrada en alinear las iniciativas de datos con los objetivos estratégicos generales de la organización, emplea los datos como fuerza guía para la planificación a largo plazo y el crecimiento sostenible.
 Dosis de espiridón es un Profesional de Seguridad de la Información en Acast. Spyridon apoya a la organización en el diseño, implementación y operación de sus servicios de manera segura protegiendo los datos de la empresa y de los usuarios.
Dosis de espiridón es un Profesional de Seguridad de la Información en Acast. Spyridon apoya a la organización en el diseño, implementación y operación de sus servicios de manera segura protegiendo los datos de la empresa y de los usuarios.
 Srikant Das es arquitecto de soluciones de laboratorio de aceleración en Amazon Web Services. Tiene más de 13 años de experiencia en análisis de Big Data e ingeniería de datos, donde disfruta creando soluciones confiables, escalables y eficientes. Fuera del trabajo, le gusta viajar y escribir blogs sobre sus experiencias en las redes sociales.
Srikant Das es arquitecto de soluciones de laboratorio de aceleración en Amazon Web Services. Tiene más de 13 años de experiencia en análisis de Big Data e ingeniería de datos, donde disfruta creando soluciones confiables, escalables y eficientes. Fuera del trabajo, le gusta viajar y escribir blogs sobre sus experiencias en las redes sociales.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/design-a-data-mesh-on-aws-that-reflects-the-envisioned-organization/

