Muchos clientes están interesados en aumentar la productividad en su ciclo de vida de desarrollo de software mediante el uso de IA generativa. Recientemente, AWS anunció la disponibilidad general de Amazon CodeWhisperer, un complemento de codificación de IA que utiliza modelos fundamentales para mejorar la productividad de los desarrolladores de software. Con Código de Amazon Whisperer, puede aceptar rápidamente la sugerencia principal, ver más sugerencias o continuar escribiendo su propio código. Esta integración reduce el tiempo total dedicado a escribir la integración de datos y la lógica de extracción, transformación y carga (ETL). También ayuda a los programadores principiantes a escribir sus primeras líneas de código. Cuadernos de AWS Glue Studio le permite crear trabajos de integración de datos con una interfaz de portátil sin servidor basada en web.
En esta publicación, analizamos casos de uso del mundo real para CodeWhisperer con tecnología de portátiles AWS Glue Studio.
Resumen de la solución
Para esta publicación, utiliza el CSV. Conjunto de datos de ganancias de deportes electrónicos, disponible para descargar a través de Kaggle. Los datos son extraídos de eSportsEarnings.com, que proporciona información sobre las ganancias de los jugadores y equipos de eSports. El objetivo es realizar transformaciones utilizando un cuaderno de AWS Glue Studio con recomendaciones de CodeWhisperer y luego volver a escribir los datos en Servicio de almacenamiento simple de Amazon (Amazon S3) en formato de archivo Parquet, así como a Desplazamiento al rojo de Amazon.
Requisitos previos
Nuestra solución tiene los siguientes requisitos previos:
- Configurar AWS Glue Studio.
- Configurar un Gestión de identidades y accesos de AWS (IAM) para interactuar con CodeWhisperer. Adjunte la siguiente política a su función de IAM adjunta al cuaderno de AWS Glue Studio:
- Descargar el CSV Conjunto de datos de ganancias de deportes electrónicos y sube el archivo CSV
highest_earning_players.csva la carpeta S3 que utilizará en este caso de uso.
Cree un cuaderno de AWS Glue Studio
Empecemos. Cree un nuevo trabajo de cuaderno de AWS Glue Studio completando los siguientes pasos:
- En la consola de AWS Glue, elija Cuadernos bajo Empleos de ETL en el panel de navegación.
- Seleccione Cuaderno Jupyter y elige Crear.
- Nombre del trabajo, introduzca
CodeWhisperer-s3toJDBC.
Se creará un nuevo cuaderno con las celdas de muestra como se muestra en la siguiente captura de pantalla.
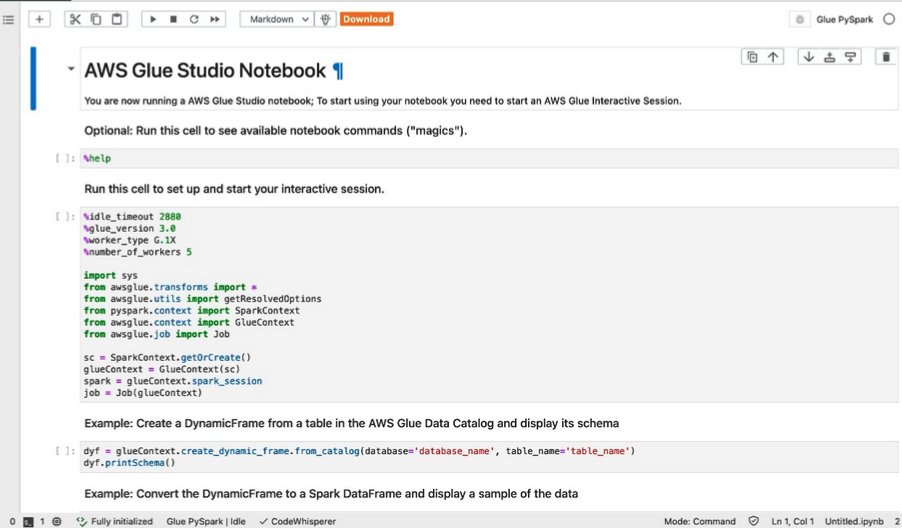
Usamos la segunda celda por ahora, para que puedas eliminar todas las demás celdas.
- En la segunda celda, actualice la configuración de la sesión interactiva configurando lo siguiente:
- Tipo de trabajador a G.1X
- Número de trabajadores a 3
- Versión de AWS Glue a 4.0
- Además, importar el
DynamicFramemódulo ycurrent_timestampfunciona de la siguiente manera:
Después de realizar estos cambios, la computadora portátil debería verse como la siguiente captura de pantalla.

Ahora, asegurémonos de que CodeWhisperer esté funcionando según lo previsto. En la parte inferior derecha encontrarás el código susurrador opción al lado del Pegamento PySpark estado, como se muestra en la siguiente captura de pantalla.
Tu puedes elegir código susurrador para ver las opciones a utilizar Sugerencias automáticas.
Desarrolle su código utilizando CodeWhisperer en un cuaderno de AWS Glue Studio
En esta sección, mostramos cómo desarrollar un trabajo de cuaderno de AWS Glue para Amazon S3 como fuente de datos y fuentes de datos JDBC como destino. Para nuestro caso de uso, debemos asegurarnos de que las sugerencias automáticas estén habilitadas. Escriba su recomendación usando CodeWhisperer siguiendo los siguientes pasos:
- Escribe un comentario en lenguaje natural (en inglés) para leer archivos Parquet desde tu depósito S3:
Después de ingresar el comentario anterior y presionar Participar, el botón CodeWhisperer al final de la página mostrará que se está ejecutando para escribir la recomendación. El resultado de la recomendación de CodeWhisperer aparecerá en la siguiente línea y el código se elige después de presionar Tab audio. Puedes aprender más en Acciones del usuario.
Después de ingresar el comentario anterior, CodeWhisperer generará un fragmento de código similar al siguiente:
Tenga en cuenta que debe actualizar las rutas para que coincidan con el depósito de S3 que está utilizando en lugar del depósito generado por CodeWhisperer.
Del fragmento de código anterior, CodeWhisperer usó Spark DataFrames para leer los archivos CSV.
- Ahora puedes intentar reformular algunas palabras para obtener una sugerencia con las funciones de DynamicFrame:
Ahora CodeWhisperer generará un fragmento de código similar al siguiente:
Reformular las oraciones escritas ahora ha demostrado que después de algunas modificaciones en los comentarios que escribimos, obtuvimos la recomendación correcta de CodeWhisperer.
- A continuación, utilice CodeWhisperer para imprimir el esquema del marco dinámico de AWS Glue anterior mediante el siguiente comentario:
CodeWhisperer generará un fragmento de código similar al siguiente:
Obtenemos el siguiente resultado.

Ahora usamos CodeWhisperer para crear algunas funciones de transformación que pueden manipular el marco dinámico de AWS Glue leído anteriormente. Comenzamos ingresando código en una nueva celda.
- Primero, pruebe si CodeWhisperer puede utilizar las funciones de contexto correctas de AWS Glue como ResolverElección:
CodeWhisperer ha recomendado un fragmento de código similar al siguiente:
El fragmento de código anterior no representa con precisión el comentario que ingresamos.
- Puede aplicar la paráfrasis y simplificación de oraciones proporcionando los siguientes tres comentarios. Cada uno tiene una petición diferente y nosotros usamos el con columna Método Spark Frame, que se utiliza en tipos de columnas de fundición:
CodeWhisperer seleccionará los comandos anteriores y recomendará el siguiente fragmento de código en secuencia:
El siguiente resultado confirma la PlayerId La columna se cambia de cadena a número entero.

- Aplique el mismo proceso al AWS Glue DynamicFrame resultante para el
TotalUSDPrizecolumna convirtiéndola de cadena a larga usando elwithColumnSpark Frame funciona ingresando los siguientes comentarios:
El fragmento de código recomendado es similar al siguiente:
El esquema de salida del fragmento de código anterior es el siguiente.

Ahora intentaremos recomendar un fragmento de código que refleje el premio promedio de cada jugador según su código de país.
- Para hacerlo, comience por obtener el recuento de jugadores por cada país:
El fragmento de código recomendado es similar al siguiente:
Obtenemos el siguiente resultado.

- Únase al DataFrame principal con el DataFrame de recuento de códigos de país y luego agregue una nueva columna calculando el premio promedio más alto para cada jugador según su código de país:
El fragmento de código recomendado es similar al siguiente:
La salida del esquema ahora confirma que ambos DataFrames se unieron correctamente y que Count La columna se agrega al DataFrame principal.

- Obtenga la recomendación de código en el fragmento de código para calcular el promedio
TotalUSDPrizepara cada código de país y agréguelo a una nueva columna:
El fragmento de código recomendado es similar al siguiente:
El resultado del código anterior debería verse similar al siguiente.

- ÚNASE AL
country_code_sumDataFrame con el DataFrame principal de antes y obtén el promedio de premios por jugador por país:
El fragmento de código recomendado es similar al siguiente:
- La última parte de la fase de transformación consiste en ordenar los datos por el premio medio más alto por jugador por país:
El fragmento de código recomendado es similar al siguiente:
Las primeras cinco filas serán similares a las siguientes.

Para el último paso, escribimos DynamicFrame en Amazon S3 y en Amazon Redshift.
- Escriba el DynamicFrame en Amazon S3 con el siguiente código:
La recomendación de CodeWhisperer es similar al siguiente fragmento de código:
Necesitamos corregir el fragmento de código generado después de la recomendación porque no contiene claves de partición. Como señalamos, partitionkeys está vacío, por lo que podemos tener otra sugerencia de bloque de código para configurar partitionkey y luego escríbalo en la ubicación de destino de Amazon S3. Además, de acuerdo con las actualizaciones más recientes relacionadas con la escritura de DynamicFrames en Amazon S3 usando glueparquet, format = "glueparquet" ya no se usa. En su lugar, deberá utilizar el tipo de parquet con useGlueParquetWriter habilitado
Después de las actualizaciones, nuestro código es similar al siguiente:
Otra opción aquí sería escribir los archivos en Amazon Redshift mediante una conexión JDBC.
- Primero, ingrese el siguiente comando para verificar si CodeWhisperer entenderá el comentario en una oración y usará las funciones correctas o no:
El resultado del comentario es similar al siguiente fragmento de código:
Como podemos ver, CodeWhisperer interpretó correctamente el comentario seleccionando solo las columnas especificadas para escribir en Amazon Redshift.
- Ahora, utilice CodeWhisperer para escribir DynamicFrame en Amazon Redshift. Usamos el Pre-acción parámetro para ejecutar una consulta SQL para seleccionar solo ciertas columnas que se escribirán en Amazon Redshift:
La recomendación de CodeWhisperer es similar al siguiente fragmento de código:
Después de verificar el fragmento de código anterior, puede observar que hay un fragmento de código fuera de lugar format, que puedes eliminar. También puedes agregar el iam_role como entrada en connection_options. También puede notar que CodeWhisperer ha asumido automáticamente que la URL de Redshift tiene el mismo nombre que la carpeta S3 que usamos. Por lo tanto, debe cambiar la URL y el depósito del directorio temporal de S3 para reflejar sus propios parámetros y eliminar el parámetro de contraseña. El fragmento de código final debería ser similar al siguiente:
El siguiente es el código completo y los fragmentos de comentarios:
Conclusión
En esta publicación, demostramos un caso de uso del mundo real sobre cómo la integración de portátiles de AWS Glue Studio con CodeWhisperer le ayuda a crear trabajos de integración de datos más rápidamente. Puede comenzar a utilizar el cuaderno de AWS Glue Studio con CodeWhisperer para acelerar la creación de sus trabajos de integración de datos.
Para obtener más información sobre el uso de cuadernos de AWS Glue Studio y CodeWhisperer, consulte lo siguiente video.
Sobre los autores
 ishan gaur Trabaja como Sr. Big Data Cloud Engineer (ETL) especializado en AWS Glue. Le apasiona ayudar a los clientes a crear flujos de análisis y cargas de trabajo ETL distribuidas y escalables en AWS.
ishan gaur Trabaja como Sr. Big Data Cloud Engineer (ETL) especializado en AWS Glue. Le apasiona ayudar a los clientes a crear flujos de análisis y cargas de trabajo ETL distribuidas y escalables en AWS.
 Omar Elkharbotly es una PYME de Glue que trabaja como Big Data Cloud Support Engineer 2 (DIST). Se dedica a ayudar a los clientes a resolver problemas relacionados con sus cargas de trabajo ETL y a crear canales de análisis y procesamiento de datos escalables en AWS.
Omar Elkharbotly es una PYME de Glue que trabaja como Big Data Cloud Support Engineer 2 (DIST). Se dedica a ayudar a los clientes a resolver problemas relacionados con sus cargas de trabajo ETL y a crear canales de análisis y procesamiento de datos escalables en AWS.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/explore-real-world-use-cases-for-amazon-codewhisperer-powered-by-aws-glue-studio-notebooks/

