Autor: Vitalik Buterin a través de Blog de Vitalik Buterin
Un agradecimiento especial a los equipos de Worldcoin y Modulus Labs, Xinyuan Sun, Martin Koeppelmann e Illia Polosukhin por sus comentarios y debates.
Muchas personas a lo largo de los años me han hecho una pregunta similar: ¿cuáles son las intersecciones entre cripto e IA que considero más fructífero? Es una pregunta razonable: las criptomonedas y la IA son las dos principales tendencias tecnológicas profundas (de software) de la última década, y parece que están ahí. debe haber algún tipo de conexión entre los dos. Es fácil generar sinergias a un nivel superficial: la descentralización criptográfica puede equilibrar la centralización de la IA, la IA es opaca y las criptomonedas aportan transparencia, la IA necesita datos y las cadenas de bloques son buenas para almacenar y rastrear datos. Pero a lo largo de los años, cuando la gente me pedía que profundizara un nivel más y hablara sobre aplicaciones específicas, mi respuesta ha sido decepcionante: "sí, hay algunas cosas, pero no tantas".
En los últimos tres años, con el surgimiento de una IA mucho más poderosa en forma de modernas LLM, y el surgimiento de criptomonedas mucho más poderosas en forma no solo de soluciones de escalamiento de blockchain sino también ZKP, FHE, (bipartidista y N-partidista) MPC, estoy empezando a ver este cambio. De hecho, existen algunas aplicaciones prometedoras de la IA dentro de los ecosistemas blockchain, o IA junto con criptografía, aunque es importante tener cuidado con la forma en que se aplica la IA. Un desafío particular es: en criptografía, el código abierto es la única forma de hacer que algo sea verdaderamente seguro, pero en IA, un modelo (o incluso sus datos de entrenamiento) es abierto. aumenta enormemente su vulnerabilidad a aprendizaje automático adverso ataques. Esta publicación analizará una clasificación de las diferentes formas en que cripto + IA podrían cruzarse, y las perspectivas y desafíos de cada categoría.
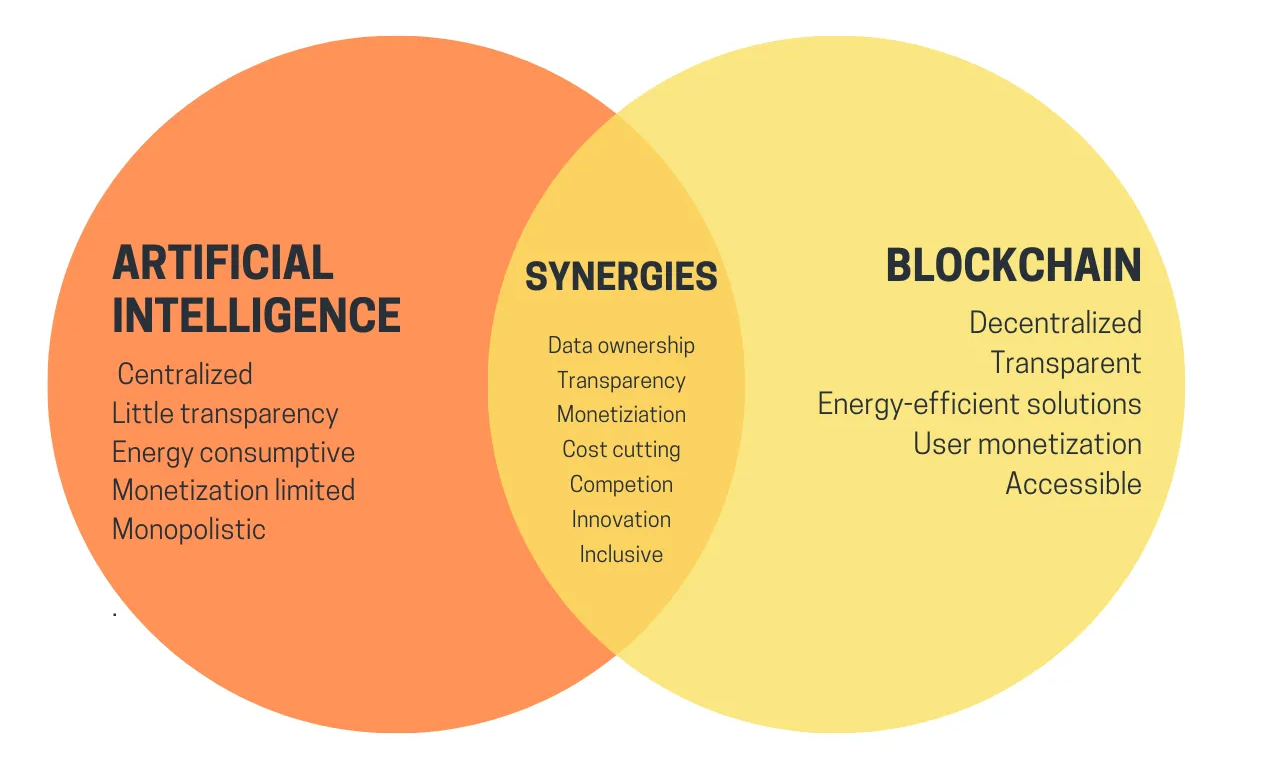
Las cuatro categorías principales
La IA es un concepto muy amplio: se puede pensar en la “IA” como el conjunto de algoritmos que se crean no especificándolos explícitamente, sino más bien removiendo una gran sopa computacional y aplicando algún tipo de presión de optimización que empuja la sopa hacia produciendo algoritmos con las propiedades que desee. Definitivamente esta descripción no debe tomarse desdeñosamente: incluye las esa creado ¡Nosotros los humanos en primer lugar! Pero sí significa que los algoritmos de IA tienen algunas propiedades comunes: su capacidad para hacer cosas extremadamente poderosas, junto con límites en nuestra capacidad para saber o comprender lo que sucede bajo el capó.
Hay muchas formas de categorizar la IA; para los propósitos de esta publicación, que habla sobre las interacciones entre la IA y las cadenas de bloques (que han sido descritas como una plataforma para creando “juegos”), lo categorizaré de la siguiente manera:
- IA como jugador en un juego [mayor viabilidad]: Las IA participan en mecanismos donde la fuente final de incentivos proviene de un protocolo con aportaciones humanas.
- IA como interfaz para el juego [alto potencial, pero con riesgos]: Las IA ayudan a los usuarios a comprender el mundo criptográfico que los rodea y a garantizar que su comportamiento (es decir, mensajes y transacciones firmados) coincida con sus intenciones y no sean engañados ni estafados.
- La IA como reglas del juego [pise con mucho cuidado]: blockchains, DAO y mecanismos similares que llaman directamente a las IA. Piensa, por ejemplo. “Jueces de IA”
- La IA como objetivo del juego [a largo plazo pero intrigante]: diseñar cadenas de bloques, DAO y mecanismos similares con el objetivo de construir y mantener una IA que pueda usarse para otros fines, utilizando los bits criptográficos para incentivar mejor el entrenamiento o para evitar que la IA filtre datos privados o sea utilizada indebidamente.
Repasemos estos uno por uno.
IA como jugador en un juego
En realidad, esta es una categoría que ha existido durante casi una década, al menos desde intercambios descentralizados en cadena (DEX) comenzó a ver un uso significativo. Cada vez que hay un intercambio, existe la oportunidad de ganar dinero mediante el arbitraje, y los robots pueden realizar el arbitraje mucho mejor que los humanos. Este caso de uso ha existido durante mucho tiempo, incluso con IA mucho más simples que las que tenemos hoy, pero en última instancia es una intersección muy real de IA + criptografía. Más recientemente, hemos visto robots de arbitraje MEV. a menudo explotando unos a otros. Cada vez que tenga una aplicación blockchain que implique subastas o intercambios, tendrá robots de arbitraje.
Pero los robots de arbitraje de IA son sólo el primer ejemplo de una categoría mucho más grande, que espero que pronto comience a incluir muchas otras aplicaciones. Conoce a AIOmen, un Demostración de un mercado de predicción en el que las IA son protagonistas.:
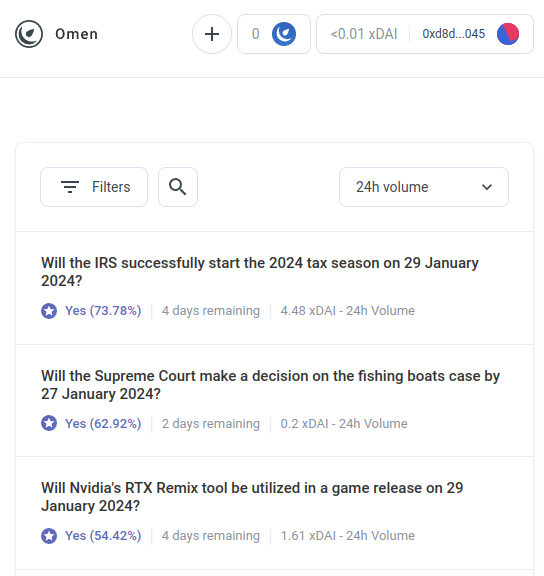
Una respuesta a esto es señalar las mejoras continuas de UX en Polimercado u otros nuevos mercados de predicción, y esperamos que tengan éxito donde las iteraciones anteriores han fracasado. Después de todo, cuenta la historia, la gente está dispuesta a apostar decenas de miles de millones en deportes, entonces ¿por qué la gente no invertiría suficiente dinero apostando en las elecciones estadounidenses o LK99 ¿Que empieza a tener sentido que los jugadores serios empiecen a llegar? Pero este argumento debe enfrentarse al hecho de que, bueno, iteraciones anteriores tienen no logró llegar a este nivel de escala (al menos en comparación con los sueños de sus defensores), por lo que parece que es necesario algo nuevo para que los mercados de predicción tengan éxito. Por lo tanto, una respuesta diferente es señalar una característica específica de los ecosistemas de mercado de predicción que podemos esperar ver en la década de 2020 y que no vimos en la década de 2010: la posibilidad de una participación ubicua de las IA.
Las IA están dispuestas a trabajar por menos de 1 dólar la hora y tienen el conocimiento de una enciclopedia y, si eso no fuera suficiente, incluso pueden integrarse con la capacidad de búsqueda web en tiempo real. Si se crea un mercado y se ofrece un subsidio de liquidez de 50 dólares, a los humanos no les importará lo suficiente como para pujar, pero miles de IA fácilmente se abalanzarán sobre la pregunta y harán las mejores suposiciones que puedan. El incentivo para hacer un buen trabajo en cualquier pregunta puede ser pequeño, pero el incentivo para crear una IA que haga buenas predicciones en general puede ser de millones. Tenga en cuenta que potencialmente, Ni siquiera necesitas a los humanos para resolver la mayoría de las preguntas.: puede utilizar un sistema de disputas de múltiples rondas similar a Augur o Kleros, donde las IA también serían las que participarían en rondas anteriores. Los seres humanos sólo necesitarían responder en aquellos pocos casos en los que se hayan producido una serie de escaladas y ambas partes hayan comprometido grandes cantidades de dinero.
Esta es una primitiva poderosa, porque una vez que se puede hacer que un “mercado de predicción” funcione a una escala tan microscópica, se puede reutilizar la primitiva de “mercado de predicción” para muchos otros tipos de preguntas:
- ¿Esta publicación en las redes sociales es aceptable según [términos de uso]?
- ¿Qué pasará con el precio de la acción X (por ejemplo, ver Numerai)
- ¿Esta cuenta que actualmente me envía mensajes es en realidad Elon Musk?
- ¿Es aceptable el envío de este trabajo en un mercado de tareas en línea?
- ¿Es la dapp en https://examplefinance.network una estafa?
- Is
0x1b54....98c3¿En realidad es la dirección del token ERC20 “Casinu Inu”?
Podrás notar que muchas de estas ideas van en la dirección de lo que llamé “defensa de información" en . En términos generales, la pregunta es: ¿cómo ayudamos a los usuarios a distinguir la información verdadera de la falsa y a detectar estafas, sin empoderar a una autoridad centralizada para decidir quién está bien y qué está mal, quién podría luego abusar de esa posición? A nivel micro, la respuesta puede ser "IA". Pero a nivel macro, la pregunta es: ¿quién construye la IA? La IA es un reflejo del proceso que la creó y, por lo tanto, no puede evitar tener sesgos. Por lo tanto, existe la necesidad de un juego de nivel superior que determine qué tan bien lo están haciendo las diferentes IA, donde las IA puedan participar como jugadores en el juego..
Este uso de la IA, en el que las IA participan en un mecanismo en el que, en última instancia, son recompensadas o penalizadas (probabilísticamente) por un mecanismo en cadena que recopila aportaciones de los humanos (llamémoslo descentralizado basado en el mercado). RLHF?), es algo que creo que realmente vale la pena analizar. Ahora es el momento adecuado para analizar más casos de uso como este, porque el escalamiento de blockchain finalmente está teniendo éxito, haciendo que cualquier “micro” cualquier cosa finalmente sea viable en la cadena cuando antes no lo era.
Una categoría relacionada de aplicaciones va en dirección a agentes altamente autónomos. usando blockchains para cooperar mejor, ya sea mediante pagos o mediante el uso de contratos inteligentes para asumir compromisos creíbles.
La IA como interfaz del juego.
Una idea que mencioné en mi escritos sobre es la idea de que existe una oportunidad de mercado para escribir software orientado al usuario que proteja los intereses de los usuarios al interpretar e identificar los peligros en el mundo en línea por el que navega el usuario. Un ejemplo ya existente de esto es la función de detección de estafas de Metamask:
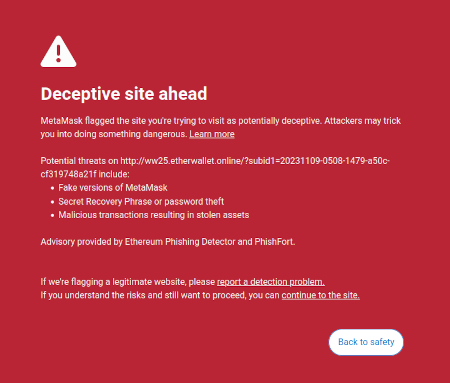
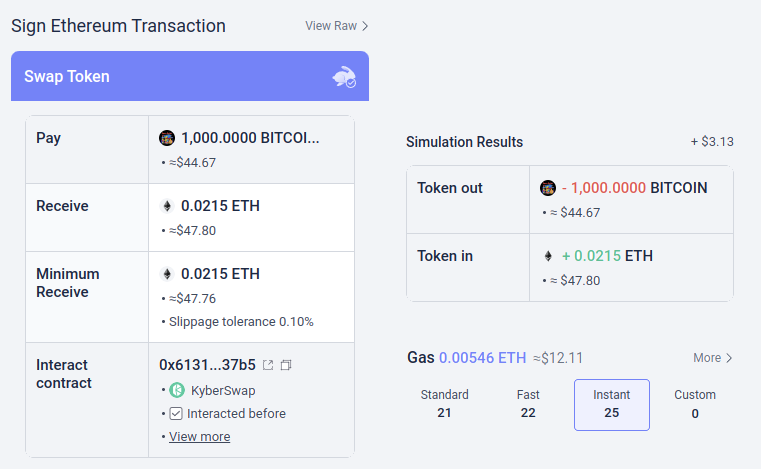
Potencialmente, este tipo de herramientas podrían estar supercargadas con IA. La IA podría dar una explicación mucho más rica y amigable para los humanos sobre en qué tipo de dapp estás participando, las consecuencias de las operaciones más complicadas que estás firmando, si un token en particular es genuino o no (por ejemplo, BITCOIN no es solo una cadena de caracteres, es el nombre de una criptomoneda real, que no es un token ERC20 y que tiene un precio muy superior a $ 0.045, y un LLM moderno lo sabría), y así sucesivamente. Hay proyectos que empiezan a ir muy lejos en esta dirección (por ejemplo, el Cartera LangChain, que utiliza la IA como primario interfaz). Mi propia opinión es que las interfaces de IA pura probablemente sean demasiado arriesgadas en este momento, ya que aumentan el riesgo de otros tipos de errores, pero la IA que complementa una interfaz más convencional se está volviendo muy viable.
Hay un riesgo particular que vale la pena mencionar. Hablaré más de esto en la sección "La IA como reglas del juego" a continuación, pero El problema general es el aprendizaje automático adversario: si un usuario tiene acceso a un asistente de IA dentro de una billetera de código abierto, los malos también tendrán acceso a ese asistente de IA, por lo que tendrán oportunidades ilimitadas de optimizar sus estafas para no desencadenar las defensas de esa billetera. Todas las IA modernas tienen errores en alguna parte, y no es demasiado difícil para un proceso de entrenamiento, incluso uno con sólo acceso limitado al modelo, para encontrarlos.
Aquí es donde las “IA que participan en micromercados en cadena” funcionan mejor: cada IA individual es vulnerable a los mismos riesgos, pero se está creando intencionalmente un ecosistema abierto de docenas de personas que los iteran y mejoran constantemente. Además, cada IA individual es cerrada: la seguridad del sistema proviene de la apertura de las reglas del juego, no el funcionamiento interno de cada uno jugador.
Resumen: La IA puede ayudar a los usuarios a comprender lo que sucede en un lenguaje sencillo, puede servir como un tutor en tiempo real, puede proteger a los usuarios de errores, pero tenga cuidado al intentar usarla directamente contra desinformadores y estafadores maliciosos.
La IA como reglas del juego
Ahora llegamos a la aplicación que entusiasma a mucha gente, pero que creo que es la más arriesgada y donde debemos andar con más cuidado: lo que yo llamo que las IA son parte de las reglas del juego. Esto se relaciona con el entusiasmo entre las élites políticas dominantes acerca de los “jueces de IA” (por ejemplo, ver este artículo en el sitio web de la “Cumbre Mundial de Gobiernos”), y existen análogos de estos deseos en las aplicaciones blockchain. Si un contrato inteligente basado en blockchain o una DAO necesita tomar una decisión subjetiva (por ejemplo, ¿es aceptable un producto de trabajo en particular en un contrato de trabajo por contrato? ¿Cuál es la interpretación correcta de una constitución en lenguaje natural como Optimism? Ley de Cadenas?), ¿podría hacer que una IA simplemente sea parte del contrato o DAO para ayudar a hacer cumplir estas reglas?
Aquí es donde aprendizaje automático adverso Va a ser un desafío extremadamente difícil. El argumento básico de dos oraciones por qué es el siguiente:
Si un modelo de IA que desempeña un papel clave en un mecanismo está cerrado, no se puede verificar su funcionamiento interno, por lo que no es mejor que una aplicación centralizada. Si el modelo de IA está abierto, entonces un atacante puede descargarlo y simularlo localmente, y diseñar ataques muy optimizados para engañar al modelo, que luego puede reproducir en la red en vivo.

Ahora bien, es posible que los lectores frecuentes de este blog (o los habitantes del criptoverso) ya se estén adelantando a mí y pensando: ¡pero espera! Tenemos sofisticadas pruebas de conocimiento cero y otras formas de criptografía realmente interesantes. Seguramente podemos hacer algo de criptomagia y ocultar el funcionamiento interno del modelo para que los atacantes no puedan optimizar los ataques, pero al mismo tiempo ¡Que el modelo se está ejecutando correctamente y que se construyó utilizando un proceso de entrenamiento razonable en un conjunto razonable de datos subyacentes!
Normalmente, esto es exactamente el tipo de pensamiento que defiendo tanto en este blog como en mis otros escritos. Pero en el caso de la computación relacionada con la IA, existen dos objeciones principales:
- Sobrecarga criptográfica: es mucho menos eficiente hacer algo dentro de un SNARK (o MPC o…) que hacerlo “en claro”. Dado que la IA ya es muy intensiva desde el punto de vista computacional, ¿es computacionalmente viable hacer IA dentro de cajas negras criptográficas?
- Ataques de aprendizaje automático adversarios de caja negra: hay formas de optimizar los ataques contra modelos de IA incluso sin saber mucho sobre el funcionamiento interno del modelo. Y si te escondes demasiado, corre el riesgo de que sea demasiado fácil para quien elija los datos de entrenamiento corromper el modelo con envenenamiento ataques.
Ambas son madrigueras de conejo complicadas, así que analicemos cada una de ellas por separado.
Sobrecarga criptográfica
Los dispositivos criptográficos, especialmente los de uso general como ZK-SNARK y MPC, tienen unos gastos generales elevados. Un cliente tarda unos cientos de milisegundos en verificar directamente un bloque de Ethereum, pero generar un ZK-SNARK para demostrar la exactitud de dicho bloque puede llevar horas. La sobrecarga típica de otros dispositivos criptográficos, como MPC, puede ser incluso peor. El cálculo de la IA ya es caro: los LLM más potentes pueden generar palabras individuales sólo un poco más rápido de lo que los seres humanos pueden leerlas, sin mencionar los costos computacionales, a menudo multimillonarios, de la formación los modelos. La diferencia de calidad entre los modelos de gama alta y los modelos que intentan economizar mucho más coste de formación or recuento de parámetros es largo. A primera vista, esta es una muy buena razón para sospechar de todo el proyecto de intentar agregar garantías a la IA envolviéndola en criptografía.
Afortunadamente, sin embargo, La IA es una tipo muy específico de cálculo, lo que lo hace susceptible de todo tipo de optimizaciones de los que no pueden beneficiarse tipos de computación más “no estructurados” como los ZK-EVM. Examinemos la estructura básica de un modelo de IA:

y = max(x, 0)). Asintóticamente, las multiplicaciones de matrices ocupan la mayor parte del trabajo: multiplicar dos N*N matrices toma �(�2.8) tiempo, mientras que el número de operaciones no lineales es mucho menor. Esto es realmente conveniente para la criptografía, porque muchas formas de criptografía pueden realizar operaciones lineales (que son las multiplicaciones de matrices, al menos si cifra el modelo pero no las entradas) casi "gratis"..
Si es criptógrafo, probablemente ya haya oído hablar de un fenómeno similar en el contexto de encriptación homomórfica: ejecutando Adiciones en textos cifrados cifrados es realmente fácil, pero multiplicaciones son increíblemente difíciles y no descubrimos ninguna manera de hacerlo con profundidad ilimitada hasta 2009.
Para ZK-SNARK, el equivalente es protocolos como este de 2013, que muestran un menos de 4x gastos generales para demostrar multiplicaciones de matrices. Desafortunadamente, la sobrecarga en las capas no lineales sigue siendo significativa y las mejores implementaciones en la práctica muestran una sobrecarga de alrededor de 200x. Pero existe la esperanza de que esto pueda reducirse considerablemente mediante más investigaciones; ver esta presentación de Ryan Cao para un enfoque reciente basado en GKR, y el mío explicación simplificada de cómo funciona el componente principal de GKR.
Pero para muchas aplicaciones, no solo queremos que una salida de IA se calculó correctamente, también queremos ocultar el modelo. Existen enfoques ingenuos para esto: puede dividir el modelo para que un conjunto diferente de servidores almacene de forma redundante cada capa, y esperar que algunos de los servidores que filtran algunas de las capas no filtren demasiados datos. Pero también existen formas sorprendentemente efectivas de computación multipartita especializada.
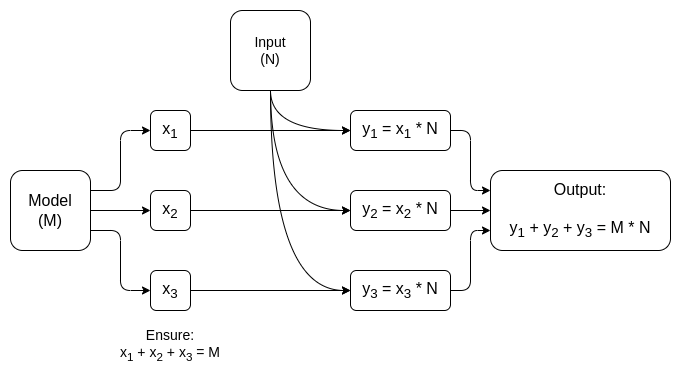
En ambos casos, la moraleja de la historia es la misma: La mayor parte de un cálculo de IA son las multiplicaciones de matrices, para las cuales es posible hacer muy eficiente ZK-SNARK o MPC (o incluso FHE), por lo que la sobrecarga total de colocar IA dentro de cajas criptográficas es sorprendentemente baja.. Generalmente, son las capas no lineales las que suponen el mayor cuello de botella a pesar de su menor tamaño; tal vez técnicas más nuevas como argumentos de búsqueda va a ayudar.
Aprendizaje automático adversario de caja negra
Ahora, vayamos al otro gran problema: los tipos de ataques que puedes realizar aunque el contenido del modelo se mantiene privado y usted solo tiene "acceso API" al modelo. Citando un papel de 2016:
Muchos modelos de aprendizaje automático son vulnerables a ejemplos contradictorios: entradas que están especialmente diseñadas para hacer que un modelo de aprendizaje automático produzca una salida incorrecta. Los ejemplos contradictorios que afectan a un modelo a menudo afectan a otro modelo, incluso si los dos modelos tienen arquitecturas diferentes o fueron entrenados en conjuntos de entrenamiento diferentes, siempre y cuando ambos modelos hayan sido entrenados para realizar la misma tarea.. Por lo tanto, un atacante puede entrenar su propio modelo sustituto, crear ejemplos contradictorios contra el sustituto y transferirlos a un modelo de víctima, con muy poca información sobre la víctima.
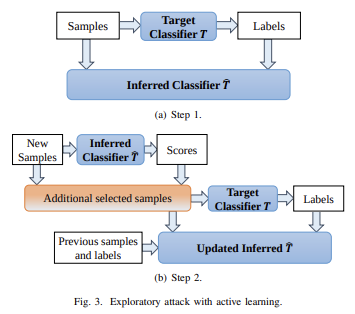
Potencialmente, incluso puedes crear ataques sabiendo solo los datos de entrenamiento, incluso si tienes acceso muy limitado o nulo al modelo que intentas atacar. A partir de 2023, este tipo de ataques seguirán siendo un gran problema.
Para reducir eficazmente este tipo de ataques de caja negra, debemos hacer dos cosas:
- realmente limitar quién o qué puede consultar el modelo y cuánto. Las cajas negras con acceso API sin restricciones no son seguras; pueden ser cajas negras con acceso API muy restringido.
- Ocultar los datos de entrenamiento, manteniendo la confianza. que el proceso utilizado para crear los datos de entrenamiento no esté dañado.
El proyecto que más ha hecho en el primero es quizás Worldcoin, del cual analizo en profundidad una versión anterior (entre otros protocolos) esta página. Worldcoin utiliza ampliamente modelos de IA a nivel de protocolo, para (i) convertir escaneos de iris en "códigos de iris" cortos que sean fáciles de comparar en busca de similitudes, y (ii) verificar que lo que está escaneando es en realidad un ser humano. La principal defensa en la que se basa Worldcoin es el hecho de que No permite que nadie simplemente llame al modelo de IA: más bien, utiliza hardware confiable para garantizar que el modelo solo acepte entradas firmadas digitalmente por la cámara del orbe..
No se garantiza que este enfoque funcione: resulta que se pueden realizar ataques adversarios contra la IA biométrica que vienen en forma de parches físicos o joyas que puedes ponerte en la cara:

Pero la esperanza es que si combinar todas las defensas juntas, al ocultar el modelo de IA en sí, al limitar en gran medida el número de consultas y al exigir que cada consulta esté autenticada de alguna manera, se pueden generar ataques adversarios lo suficientemente difíciles como para que el sistema sea seguro.
Y esto nos lleva a la segunda parte: ¿cómo podemos ocultar los datos de entrenamiento? Aquí es donde Las “DAO para gobernar democráticamente la IA” podrían tener sentido: podemos crear un DAO en cadena que gobierne el proceso de quién puede enviar datos de entrenamiento (y qué certificaciones se requieren sobre los datos en sí), quién puede realizar consultas y cuántas, y utilizar técnicas criptográficas como MPC. para cifrar todo el proceso de creación y ejecución de la IA desde la entrada de capacitación de cada usuario individual hasta el resultado final de cada consulta. Esta DAO podría satisfacer simultáneamente el objetivo muy popular de compensar a las personas por enviar datos.
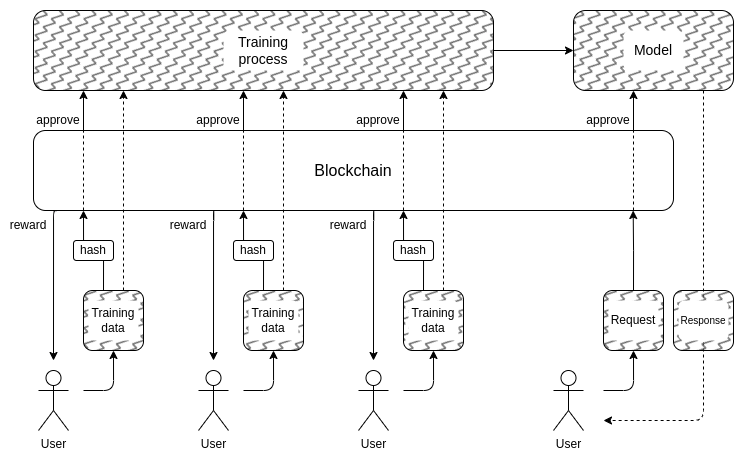
- La sobrecarga criptográfica aún podría resultar demasiado alta para que este tipo de arquitectura completamente de caja negra sea competitiva con los enfoques tradicionales cerrados de "confía en mí".
- Podría resultar que No existe una buena manera de descentralizar el proceso de envío de datos de capacitación. y protegido contra ataques de envenenamiento.
- Los dispositivos informáticos multipartitos podrían estropearse sus garantías de seguridad o privacidad debido a participantes en connivencia: después de todo, esto ha sucedido con los puentes de criptomonedas entre cadenas de nuevo y de nuevo.
Una de las razones por las que no comencé esta sección con más grandes etiquetas rojas de advertencia que decían "NO HAGAS JUECES DE IA, ESO ES DISTOPICO", es que nuestra sociedad ya depende en gran medida de jueces de IA centralizados e irresponsables: los algoritmos que determinan qué tipos de Las publicaciones y las opiniones políticas son impulsadas y debilitadas, o incluso censuradas, en las redes sociales. Creo que expandir esta tendencia promover en esta etapa es una idea bastante mala, pero no creo que haya una gran posibilidad de que la comunidad blockchain experimenta más con IA será lo que contribuya a empeorarlo.
De hecho, hay algunas formas bastante básicas y de bajo riesgo en las que la tecnología criptográfica puede mejorar incluso estos sistemas centralizados existentes y en las que tengo bastante confianza. Una técnica simple es IA verificada con publicación retrasada: cuando un sitio de redes sociales realiza una clasificación de publicaciones basada en IA, podría publicar un ZK-SNARK que demuestre el hash del modelo que generó esa clasificación. El sitio podría comprometerse a revelar sus modelos de IA después, por ejemplo. un retraso de un año. Una vez que se revela un modelo, los usuarios pueden verificar el hash para verificar que se lanzó el modelo correcto y la comunidad puede realizar pruebas en el modelo para verificar su imparcialidad. El retraso en la publicación garantizaría que cuando se revele el modelo, ya esté desactualizado.
Así que en comparación con el centralizado mundo, la pregunta no es if podemos hacerlo mejor, pero Por cuanto. Para el mundo descentralizado, sin embargo, es importante tener cuidado: si alguien construye, por ejemplo. un mercado de predicción o una moneda estable que utiliza un oráculo de IA, y resulta que el oráculo es atacable, es una enorme cantidad de dinero que podría desaparecer en un instante.
La IA como objetivo del juego
Si las técnicas anteriores para crear una IA privada descentralizada y escalable, cuyo contenido es una caja negra que nadie conoce, realmente pueden funcionar, entonces esto también podría usarse para crear IA con una utilidad que vaya más allá de las cadenas de bloques. El equipo del protocolo NEAR está haciendo de esto un objetivo central de su trabajo en curso.
Hay dos razones para hacer esto:
- Si podemos hacer "IA de caja negra confiables"Al ejecutar el proceso de capacitación e inferencia utilizando alguna combinación de blockchains y MPC, muchas aplicaciones donde los usuarios están preocupados de que el sistema esté sesgado o los engañe podrían beneficiarse de ello. Mucha gente ha expresado su deseo de la gobernabilidad democrática de IA de importancia sistémica del que dependeremos; Las técnicas criptográficas y basadas en blockchain podrían ser un camino para lograrlo.
- Desde un seguridad de la IA En perspectiva, esta sería una técnica para crear una IA descentralizada que también tenga un interruptor de apagado natural y que podría limitar las consultas que buscan utilizar la IA para comportamientos maliciosos.
También vale la pena señalar que “usar incentivos criptográficos para incentivar la creación de una mejor IA” se puede hacer sin tener que recurrir al uso de criptografía para cifrarla por completo: enfoques como BitTensor Caer en esta categoría.
Conclusiones
Ahora que tanto las cadenas de bloques como las IA se están volviendo más poderosas, hay un número creciente de casos de uso en la intersección de las dos áreas. Sin embargo, algunos de estos casos de uso tienen mucho más sentido y son mucho más sólidos que otros. En general, los casos de uso en los que el mecanismo subyacente continúa diseñándose aproximadamente como antes, pero el individuo players convertirse en IA, permitiendo que el mecanismo funcione eficazmente a una escala mucho más micro, son las más prometedoras de inmediato y las más fáciles de lograr.
Las más difíciles de lograr son las aplicaciones que intentan utilizar cadenas de bloques y técnicas criptográficas para crear un "singleton": una única IA descentralizada y confiable en la que alguna aplicación confiaría para algún propósito. Estas aplicaciones son prometedoras, tanto por su funcionalidad como por mejorar la seguridad de la IA de una manera que evite los riesgos de centralización asociados con enfoques más convencionales para ese problema. Pero también hay muchas maneras en que los supuestos subyacentes podrían fallar; por lo tanto, vale la pena actuar con cuidado, especialmente cuando se implementan estas aplicaciones en contextos de alto valor y riesgo.
Espero ver más intentos de casos de uso constructivos de la IA en todas estas áreas, para que podamos ver cuáles de ellos son realmente viables a escala.
Escrito por: Vitalik Buterin
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: Inteligencia de datos de Platón.

