Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Las redes antagónicas generativas (GAN) son una clase innovadora de modelos generativos profundos que se han desarrollado continuamente durante los últimos años. Fue propuesto por primera vez en 2014 por Goodfellow como una metodología de entrenamiento alternativa al modelo generativo [1]. Desde su nacimiento, las GAN se han utilizado en una amplia gama de aplicaciones por su gran rendimiento al tratar con datos complejos y de gran dimensión, por ejemplo, visión por computadora, lenguaje natural u otros dominios académicos como la generación de música o la seguridad.
Anuncios generativos que tienen la capacidad de generar datos nuevos nunca antes vistos. Se han utilizado para generar imágenes, videos e incluso audio realistas y tienen el potencial de revolucionar una amplia gama de aplicaciones, incluidos gráficos por computadora, diseño de videojuegos, imágenes médicas y más. A pesar de su poder, las GAN pueden ser difíciles de entrenar y estabilizar, y aún se está investigando mucho para comprender y mejorar su comportamiento.
En esta publicación de blog, exploraremos el funcionamiento interno de las GAN, los desafíos de capacitarlas y los desarrollos y avances más recientes en el campo. Ya sea que sea un investigador, un desarrollador o simplemente sienta curiosidad por las GAN, esta publicación le brindará una introducción completa a este emocionante campo de aprendizaje profundo en rápida evolución.
Las redes adversas generativas (GAN) son un tipo de red neuronal diseñada para generar datos nuevos, nunca antes vistos, similares a algunos datos de entrenamiento. Se componen de dos partes: una red generadora y una red discriminadora.
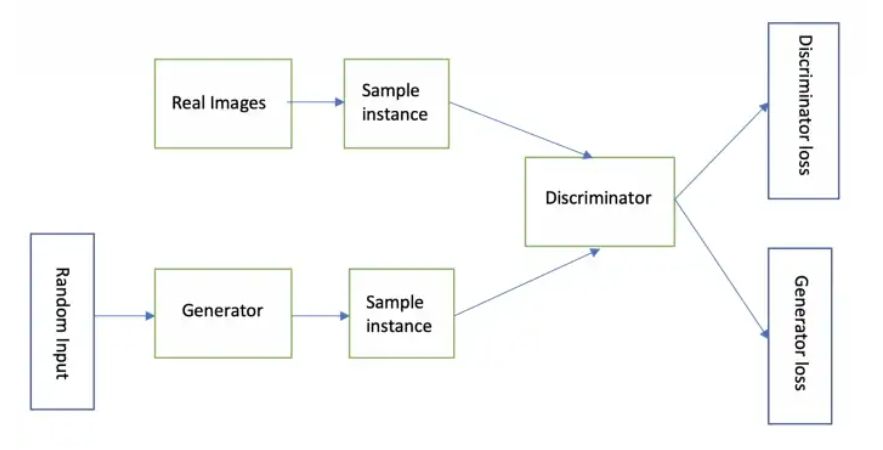
La red del generador está entrenando nuevas muestras de datos similares a los datos de entrenamiento. Lo hace tomando una señal de ruido aleatorio como entrada y transformándola a través de una serie de operaciones matemáticas implementadas usando redes neuronales en una muestra de datos de salida.
La red discriminadora está entrenada para tomar muestras de datos y predecir si cada muestra es una muestra "real" de los datos de entrenamiento o una muestra "falsa" generada por la red del generador.
Durante el entrenamiento, las redes del generador y del discriminador se entrenan por separado y alternativamente. El generador está entrenado para tratar de generar muestras que el discriminador clasificará como reales. Por el contrario, el discriminador está entrenado para tratar de clasificar correctamente las muestras como reales o falsas. Este proceso se repite muchas veces y, a través de este proceso contradictorio, el generador aprende a generar muestras de datos que son cada vez más similares a los datos de entrenamiento.
Las GAN se diferencian de los modelos tradicionales de aprendizaje automático en que están diseñadas para generar nuevos datos en lugar de clasificar o predecir valores para una entrada determinada. También se diferencian en que se entrenan mediante un proceso de confrontación, en el que las redes generadora y discriminadora compiten entre sí para mejorar su rendimiento.
2. Proporcione un ejemplo de un problema del mundo real que se utilizó para resolver GAN.
Hay muchas aplicaciones potenciales para las GAN, que incluyen:
- Generar imágenes sintéticas (p. ej., fotografías de personas, objetos, paisajes, etc.) que son indistinguibles de las imágenes reales
- Generar audio sintético (p. ej., voz, música, etc.) que sea realista y suene como si lo hubiera producido un ser humano o un instrumento musical
- Generar texto sintético (p. ej., artículos de noticias, publicaciones en redes sociales, etc.) que sea coherente y se asemeje al texto escrito por humanos
- Submuestreo de imágenes o videos de baja resolución a resoluciones más altas
- Traducir imágenes de un dominio a otro (p. ej., convertir una imagen diurna en una imagen nocturna)
Un ejemplo de un problema del mundo real que se ha resuelto mediante GAN es la generación de datos de entrenamiento sintéticos para modelos de aprendizaje automático. En algunos casos, puede ser difícil o costoso obtener grandes cantidades de datos de entrenamiento de alta calidad para una tarea de aprendizaje automático. Las GAN se pueden usar para generar datos sintéticos similares a los datos reales, que se pueden usar para entrenar modelos de aprendizaje automático. Por ejemplo, las GAN se han utilizado para generar imágenes médicas sintéticas que se pueden usar para entrenar modelos de aprendizaje automático para detectar enfermedades o anomalías en las imágenes médicas.
3. Enumere algunas dificultades en el entrenamiento de GAN y cómo sortearlas.
Pueden surgir varios desafíos al entrenar GAN:
Colapso de modo: Esto ocurre cuando la red del generador se vuelve demasiado buena para generar muestras falsas y la red del discriminador no puede distinguir entre muestras reales y falsas. Como resultado, el generador termina generando muestras iguales o similares repetidamente en lugar de generar una gama diversa de muestras. El colapso de modo puede evitarse diseñando cuidadosamente la arquitectura del generador y las redes discriminadoras y utilizando técnicas como la discriminación de minilotes para alentar al generador a generar una amplia gama de muestras.Inestabilidad del entrenamiento: Las GAN pueden ser difíciles de entrenar porque las redes del generador y el discriminador son constantemente antagónicas, y los pequeños cambios en una red pueden causar grandes cambios en la otra. Esto puede hacer que el entrenamiento sea inestable y conducir a un bajo rendimiento. Para superar esto, es importante elegir cuidadosamente las tasas de aprendizaje y los optimizadores para las redes del generador y el discriminador y monitorear el proceso de entrenamiento para asegurar que sea estable.
Falta de diversidad en las muestras generadas: En algunos casos, es posible que la red del generador no pueda generar una gama diversa de muestras y solo produzca una gama limitada de muestras similares. Esto puede deberse a una falta de capacidad en la red del generador oa que la red del generador está demasiado influenciada por la red del discriminador. Para superar esto, puede ser necesario aumentar la capacidad de la red del generador o usar técnicas como agregar ruido a la entrada de la red del generador para alentarlo a generar una gama más diversa de muestras.
Dificultad para evaluar la calidad de las muestras generadas: Puede ser difícil evaluar la calidad de las muestras generadas, especialmente cuando las muestras son muy realistas y es difícil distinguirlas de las muestras reales. Una forma de evaluar la calidad de las muestras generadas es utilizar un enfoque de "evaluación humana", en el que se muestran muestras a seres humanos reales y se les pide que las clasifiquen como reales o falsas. Otro enfoque es utilizar un método de "evaluación automática", donde las muestras se comparan con muestras reales utilizando alguna métrica (p. ej., el error cuadrático medio) para medir la similitud entre las muestras.
4. ¿Cómo maneja GAN la distribución compleja y multimodal?
Las GAN son capaces de manejar distribuciones multimodales complejas, que son conjuntos de datos que tienen múltiples "modos" (es decir, múltiples grupos o grupos de puntos de datos) que no están bien separados. Esto se debe a que las GAN están diseñadas para conocer las propiedades estadísticas de un conjunto de datos en lugar de intentar ajustar los datos a un modelo o suposición predefinidos. Un ejemplo de un conjunto de datos en el que las GAN se han desempeñado excepcionalmente bien es el conjunto de datos CelebA, que consta de más 200,000 imágenes de famosos. Este conjunto de datos es multimodal porque contiene imágenes de una gran cantidad de celebridades diferentes, cada una con su propia apariencia única. Las GAN se han utilizado para generar imágenes sintéticas de celebridades que son muy realistas e indistinguibles de las imágenes reales.
En general, las GAN tienden a funcionar bien en conjuntos de datos que tienen una gran variabilidad y complejidad, como conjuntos de datos de imágenes o conjuntos de datos de audio. Pueden aprender las propiedades estadísticas de los datos y generar muestras que capturen la diversidad y complejidad del conjunto de datos.
5. Según su experiencia, ¿cuáles son algunas de las áreas de investigación más prometedoras relacionadas con GAN?
Hay muchas áreas de investigación prometedoras relacionadas con las GAN, que incluyen:
Mejora de la estabilidad y fiabilidad del entrenamiento GAN: Hay investigaciones en curso sobre el desarrollo de nuevos algoritmos y técnicas de entrenamiento que pueden mejorar la estabilidad y la confiabilidad del entrenamiento GAN. Esto incluye métodos para evitar el colapso del modo, equilibrar el entrenamiento de las redes del generador y el discriminador, y adaptar las GAN a nuevas tareas o conjuntos de datos.Desarrollo de nuevas arquitecturas GAN y patrones de diseño: Hay mucho interés en desarrollar nuevas arquitecturas GAN que sean más eficientes, flexibles y poderosas. Esto incluye la investigación sobre el diseño de GAN para tareas específicas (por ejemplo, generación de imágenes, generación de audio, etc.), el diseño de GAN que pueden manejar distribuciones de datos complejas y el diseño de GAN que pueden aprender de pequeñas cantidades de datos.
Aplicación de GAN a nuevos dominios y tareas: Las GAN ya se han aplicado a una amplia gama de dominios y tareas, pero todavía hay mucho potencial para usar GAN en nuevas áreas. Esto incluye el uso de GAN para tareas como el procesamiento de lenguaje natural, el aumento de datos y la generación de modelos o escenas en 3D.
Explorando las implicaciones éticas y sociales de las GAN: A medida que las GAN se vuelven más poderosas y predominantes, existe una necesidad creciente de considerar las implicaciones éticas y sociales de estos modelos. Esto incluye investigaciones sobre temas como la posibilidad de que las GAN se utilicen con fines nefastos (p. ej., generar noticias falsas o propaganda), el impacto de las GAN en los empleos y las industrias, y el papel de las GAN en la configuración de la percepción pública y la toma de decisiones.
6. En comparación con otros modelos generativos como los codificadores automáticos variacionales (VAE), ¿cómo les va a las arquitecturas GAN?
Los GAN y los codificadores automáticos variacionales (VAE) son modelos generativos que se pueden usar para generar nuevas muestras de datos nunca antes vistas. Sin embargo, funcionan de formas un tanto diferentes y tienen diferentes fortalezas y debilidades. Una diferencia clave entre las GAN y las VAE es la forma en que se capacitan. Las GAN se entrenan mediante un proceso contradictorio, en el que una red generadora compite con una red discriminadora para generar muestras realistas. Los VAE, por otro lado, se entrenan mediante un proceso de optimización, donde el objetivo es maximizar la probabilidad de los datos de entrenamiento bajo el modelo.
Otra diferencia es que las GAN son generalmente más flexibles y pueden generar muestras de una gama más amplia de distribuciones, mientras que los VAE están más limitados en los tipos de distribuciones que pueden modelar. Las GAN pueden generar muestras muy realistas, pero pueden ser difíciles de entrenar y pueden sufrir problemas como el colapso del modo. Los VAE son generalmente más fáciles de entrenar y pueden generar muestras más diversas, pero es posible que las muestras no sean tan realistas como las generadas por las GAN.
En cuanto a cuándo elegir uno u otro, realmente depende de la tarea específica y los requisitos de la aplicación. Las GAN pueden ser una buena opción cuando el objetivo es generar muestras muy realistas y cuando hay una gran cantidad de datos de entrenamiento disponibles. Los VAE pueden ser una buena opción cuando el objetivo es generar una gama diversa de muestras o cuando hay datos de entrenamiento limitados disponibles.
7. ¿Puede hablar sobre algún desarrollo o avance reciente en las GAN?
Ha habido muchos desarrollos y avances recientes en el campo de las GAN. Algunos de los desarrollos más significativos incluyen:Algoritmos y técnicas de entrenamiento mejorados: Ha habido una serie de avances recientes en algoritmos y técnicas de entrenamiento para GAN, incluidos métodos para mejorar la estabilidad y confiabilidad del entrenamiento, equilibrar el entrenamiento de las redes del generador y el discriminador, y adaptar las GAN a nuevas tareas o conjuntos de datos.
Nuevas arquitecturas GAN y patrones de diseño: Los investigadores han desarrollado una amplia gama de nuevas arquitecturas GAN y patrones de diseño que son más eficientes, flexibles y potentes. Estos incluyen arquitecturas para tareas específicas (por ejemplo, generación de imágenes, generación de audio, etc.), arquitecturas para manejar distribuciones de datos complejas y arquitecturas que pueden aprender de pequeñas cantidades de datos.
Aplicación de GAN a nuevos dominios y tareas: Las GAN se han aplicado a una amplia gama de nuevos dominios y tareas, incluido el procesamiento del lenguaje natural, el aumento de datos y la generación de modelos o escenas en 3D.
Exploración de las implicaciones éticas y sociales de las GAN: Ha habido una atención cada vez mayor sobre las implicaciones éticas y sociales de las GAN, incluido el potencial de que las GAN se utilicen con fines nefastos, el impacto de las GAN en los trabajos y las industrias, y el papel de las GAN en la configuración de la percepción pública y la toma de decisiones.
8. ¿Puede describir cómo cooperan el generador y el discriminador de una GAN para mejorar el rendimiento del modelo?
En una GAN, las redes generadora y discriminadora trabajan juntas para mejorar el rendimiento del modelo compitiendo entre sí en un proceso contradictorio. La red del generador se entrena para generar nuevas muestras de datos sintéticos que son similares a los datos de entrenamiento, mientras que la red del discriminador se entrena para clasificar cada muestra como real (a partir de los datos de entrenamiento) o falsa (generada por el generador). Durante el entrenamiento , las redes del generador y del discriminador se entrenan alternativamente. Primero, la red del generador se entrena para generar un lote de muestras, y estas muestras se pasan a la red del discriminador junto con un lote de muestras reales de los datos de entrenamiento. La red discriminadora luego intenta clasificar cada muestra como real o falsa. La red del generador se actualiza en función de lo bien que pudo engañar al discriminador.
A continuación, la red del discriminador se entrena en un nuevo lote de muestras y la red del generador se actualiza en función del rendimiento del discriminador. Este proceso se repite muchas veces y, a través de este proceso contradictorio, la red del generador aprende a generar muestras que son cada vez más similares a los datos de entrenamiento. Por el contrario, la red discriminadora aprende a clasificar las muestras como reales o falsas con mayor precisión.
En general, las redes del generador y del discriminador trabajan juntas para mejorar el rendimiento del modelo al impulsarse mutuamente para ser más precisos y efectivos. El generador trata de generar muestras indistinguibles de muestras reales, mientras que el discriminador intenta identificar correctamente qué muestras son reales y cuáles son falsas. A través de este proceso, la GAN aprende las propiedades estadísticas de los datos de entrenamiento y puede generar nuevas muestras sintéticas que son similares a los datos de entrenamiento.
9. ¿Cómo se puede usar la arquitectura GAN para el aprendizaje no supervisado?
Los GAN se pueden usar para el aprendizaje no supervisado, lo que significa que pueden aprender a generar nuevas muestras de datos sin necesidad de ejemplos de entrenamiento etiquetados. En una GAN, la red del generador se entrena para generar muestras similares a los datos de entrenamiento, mientras que la red del discriminador se entrena para clasificar cada muestra como real (a partir de los datos de entrenamiento) o falsa (generada por el generador). Durante el entrenamiento, el La red del generador se proporciona con una señal de ruido aleatorio como entrada, generando una muestra sintética basada en esta entrada. Luego, la red discriminadora toma esta muestra sintética y muestras reales de los datos de entrenamiento e intenta clasificar cada muestra como real o falsa. La red del generador se actualiza en función de lo bien que podría engañar al discriminador y el proceso se repite muchas veces.
A través de este proceso contradictorio, la red del generador aprende a generar muestras que son similares a los datos de entrenamiento sin necesidad de etiquetas o supervisión explícitas. El generador puede aprender las propiedades estadísticas de los datos de entrenamiento y generar nuevas muestras que sean consistentes con estas propiedades.
Por ejemplo, las GAN se han utilizado para generar imágenes sintéticas de celebridades que son muy realistas e indistinguibles de las imágenes reales. En este caso, el GAN se entrenó en un conjunto de datos de imágenes de celebridades y aprendió a generar nuevas imágenes sintéticas de celebridades sin necesidad de etiquetas o supervisión explícitas. La GAN pudo aprender las propiedades estadísticas de los datos de entrenamiento y generar nuevas muestras que capturaron la diversidad y complejidad del conjunto de datos.
10. ¿Cómo maneja la arquitectura GAN los datos de alta dimensión?
Las GAN son capaces de manejar datos de alta dimensión, como imágenes o audio, aprendiendo las propiedades estadísticas de los datos y generando muestras que son consistentes con estas propiedades. Sin embargo, puede ser más desafiante entrenar GAN en datos de alta dimensión debido a la complejidad de los datos y la mayor cantidad de parámetros que deben aprenderse. Una forma de manejar datos de alta dimensión en el contexto de GAN es usar técnicas para reducir la dimensionalidad de los datos. Se pueden utilizar varios métodos para la reducción de la dimensionalidad, entre ellos:
Análisis de componentes principales (PCA): Esta técnica de reducción de dimensionalidad lineal proyecta los datos en un espacio de menor dimensión al encontrar las direcciones de variación máxima en los datos.
t-SNE (incrustación de vecinos estocásticos distribuidos en t): Esta es una técnica de reducción de dimensionalidad no lineal que asigna los datos a un espacio de menor dimensión de una manera que conserva la estructura local de los datos.
Los autocodificadores son redes neuronales capacitado para comprimir los datos en una representación de menor dimensión y luego reconstruir los datos originales a partir de esta representación. Los codificadores automáticos se pueden usar como un paso de preprocesamiento para reducir la dimensionalidad de los datos antes de entrenar una GAN.
El uso de estas u otras técnicas de reducción de dimensionalidad puede ayudar a reducir la complejidad de los datos y facilitar el entrenamiento de una GAN en datos de alta dimensión. Sin embargo, es fundamental tener cuidado al utilizar la reducción de dimensionalidad, ya que también puede introducir pérdida de información y degradar la calidad de las muestras generadas.
11. ¿Puede hablar sobre problemas éticos al usar GAN, particularmente al crear datos sintéticos realistas?
Existen varias preocupaciones éticas en torno al uso de GAN, particularmente en la generación de datos sintéticos realistas. Algunas de las principales preocupaciones incluyen las siguientes:Mal uso de datos sintéticos: Las GAN pueden generar datos sintéticos muy realistas, como imágenes o audio, que no se pueden distinguir de los datos reales. Esto plantea preocupaciones sobre la posibilidad de que los datos sintéticos se utilicen con fines nefastos, como crear noticias o propaganda falsas, hacerse pasar por personas o cometer fraude.
Impacto en los empleos y las industrias: El uso de GAN y otros modelos de aprendizaje automático para generar datos sintéticos puede alterar potencialmente las industrias que dependen de la creación y distribución de datos reales, como las industrias de medios o entretenimiento. Esto podría conducir a la pérdida de puestos de trabajo y otros impactos económicos negativos.
Dar forma a la percepción pública y la toma de decisiones: Las GAN y otros modelos de aprendizaje automático se pueden usar para generar datos sintéticos que son muy realistas e influyentes, como videos de políticos o celebridades que dicen o hacen cosas que en realidad nunca sucedieron. Esto puede moldear la percepción pública y la toma de decisiones de manera no deseada o dañina.
Estas preocupaciones son similares a las de otros modelos de aprendizaje automático. Aún así, pueden ser más pronunciados en el caso de las GAN debido a su capacidad para generar datos sintéticos muy realistas. Es importante que los investigadores, desarrolladores y usuarios de GAN consideren estos problemas éticos y tomen medidas para mitigar cualquier posible impacto negativo. Esto puede incluir el desarrollo de pautas o regulaciones para usar GAN o entablar un diálogo con las partes interesadas para abordar inquietudes y encontrar soluciones.
Conclusión
Los GAN son una clase poderosa de modelos de aprendizaje profundo que tienen la capacidad de generar nuevos, previamente a. Se han utilizado en una amplia gama de aplicaciones y tienen el potencial de revolucionar campos como gráficos por computadora, diseño de videojuegos, imágenes médicas y más. Sin embargo, las GAN pueden ser difíciles de entrenar y estabilizar, y aún se está investigando mucho para comprender y mejorar su comportamiento. Esta publicación de blog ha discutido el funcionamiento interno de las GAN, los desafíos de capacitarlas y los desarrollos y avances más recientes en el campo. Las GAN son un campo en rápida evolución y, con la propuesta de nuevas técnicas y arquitecturas, es muy prometedor en muchos campos diferentes. Los siguientes son algunos puntos destacados de nuestra discusión sobre las GAN:
- Las GAN son un modelo generativo que puede aprender a generar nuevas muestras de datos sintéticos similares a un conjunto de datos de entrenamiento.
- Las GAN se entrenan mediante un proceso contradictorio, en el que una red generadora compite con una red discriminadora para generar muestras realistas.
- Las GAN se han aplicado a varias tareas y dominios, incluida la generación de imágenes, la generación de audio y el procesamiento del lenguaje natural.
- Los GAN pueden ser difíciles de entrenar debido a problemas como el colapso del modo y la inestabilidad del entrenamiento. Hay una serie de técnicas que se pueden utilizar para mejorar la estabilidad y la fiabilidad del entrenamiento GAN.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/01/top-11-most-asked-interview-questions-on-gan-architecture/

