Este artículo fue publicado como parte del Blogatón de ciencia de datos.

Fuente: DDI
Introducción
Los codificadores automáticos son un modelo no supervisado que toma datos no etiquetados y aprende una codificación efectiva sobre la estructura de datos que se puede aplicar a otro contexto. Se aproxima a la función que mapea los datos del espacio de entrada a coordenadas dimensionales más bajas y se aproxima aún más a la misma dimensión del espacio de entrada para que haya una pérdida mínima.
Los codificadores automáticos se pueden usar para una amplia variedad de tareas, como detección de anomalías, compresión de imágenes, búsqueda de imágenes, eliminación de ruido de imágenes, etc. Por lo tanto, dada su popularidad y uso extensivo en la industria, es imperativo tener una comprensión clara de esto para tener éxito en una entrevista de ciencia de datos.
En este artículo, he compilado una lista de cinco preguntas importantes sobre Autoencoder que podría usar como guía para familiarizarse más con el tema y también formular una respuesta efectiva para tener éxito en su próxima entrevista.
Preguntas de la entrevista sobre codificadores automáticos
Pregunta 1: ¿Qué es Autoencoder?
Respuesta: Autoencoder es una red neuronal que tiene como objetivo aprender una función de identidad para reconstruir la entrada original y, al mismo tiempo, comprimir los datos en el proceso. La imagen reconstruida es la aproximación a la entrada x.
El concepto surgió por primera vez en la década de 1980, y el artículo de investigación fundamental publicado más tarde por Hinton y Salakhutdinov en 2006.
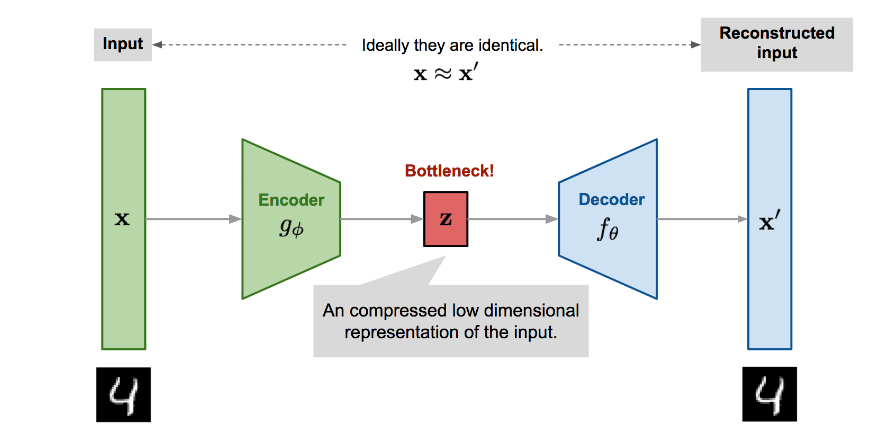
Figura 1: Diagrama que ilustra la arquitectura del codificador automático
Fuente: Lilian Weng
Consta de dos redes:
i) Red de codificador: Encoder Network convierte los datos de entrada originales de alta dimensión en la representación comprimida o latente de baja dimensión. En consecuencia, el tamaño de entrada es mayor que el tamaño de salida. En resumen, el codificador aprende a crear una versión comprimida/codificada de los datos de entrada y logra la reducción de la dimensionalidad.
ii) Red de decodificadores: La red del decodificador restaura los datos desde su representación latente, y los datos de entrada originales al codificador son casi idénticos a la entrada reconstruida. En resumen, el decodificador reconstruye los datos originales a partir de la versión comprimida.
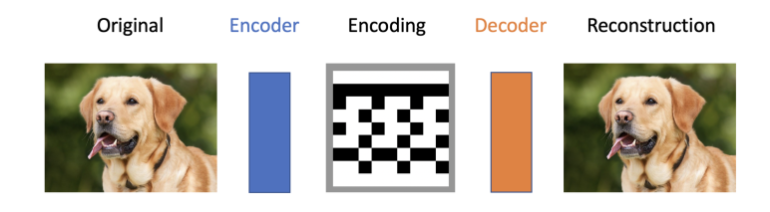
Figura 2: Diagrama que ilustra la compresión y descompresión/reconstrucción de la imagen original
Fuente: programmathically.com
La función de codificador g(.) está parametrizada por ϕ, y la función decodificador f(.) está parametrizada por θ. El código de baja dimensión aprendido para la entrada x en la capa de cuello de botella es z=gϕ(x), y la entrada reconstruida es x′=fθ(gϕ(x)).
Los parámetros (θ,ϕ) se aprenden conjuntamente para generar una muestra de datos reconstruida que es idéntica a la entrada original, x≈fθ(gϕ(x)). Las métricas como la entropía cruzada y la pérdida de MSE se pueden usar para cuantificar la diferencia entre dos vectores.
Internamente, el cuello de botella consta de una capa oculta que describe un código que representa la entrada. Las capas ocultas suelen tener menos nodos que las capas de entrada y salida para impedir que las redes aprendan la función de identidad. Tener menos nodos en las capas ocultas que los nodos de entrada obliga al codificador automático a priorizar las funciones útiles que desea conservar e ignorar el ruido.
Esta arquitectura es útil para aplicaciones como la reducción de dimensionalidad o la compresión de archivos, donde deseamos almacenar una versión de nuestros datos que sea más eficiente en memoria o reconstruir una copia (versión) de una entrada que tenga menos ruido que los datos originales.
En comparación con los métodos deterministas para la compresión de datos, los codificadores automáticos se aprenden, lo que significa que dependen de las funciones que son específicas/exclusivas de los datos en los que se entrenó el codificador automático.
Nota: Para que la reducción de la dimensionalidad sea eficaz, las características de dimensiones inferiores deben tener alguna relación entre sí. Cuanto mayor sea la correlación mejor será la reconstrucción.
Pregunta 2: ¿Qué sucederá si la capa oculta y la capa de entrada tienen la misma cantidad de nodos?
Respuesta: Cuando la capa oculta y la capa de entrada tienen la misma cantidad de nodos, la codificación se parecerá a la entrada, lo que hará que el codificador automático sea completamente inútil.
Pregunta 3: ¿Autoencoder y PCA son lo mismo o hay alguna diferencia?
Respuesta No, autoencoder y PCA no son lo mismo.
Dado que PCA no se ha cubierto en detalle en esta publicación, permítanme explicarlo brevemente antes de hablar sobre las diferencias entre PCA y Autoencoder.
El análisis de componentes principales (PCA) es un método que proyecta/transforma los datos de alta dimensión en un espacio de menor dimensión mientras retiene la mayor cantidad de información posible. La varianza de los datos determina los vectores de proyecciones. Al limitar la dimensionalidad a un cierto no. de componentes que compensan la mayor parte de la varianza del conjunto de datos, se logra la reducción de la dimensionalidad.
Ahora, cuando se trata de la comparación entre PCA y Autoencoder, las siguientes son algunas de las diferencias:
- Análisis de componentes principales (PCA) y Autoencoder (Encoder Network) consiguen una reducción de la dimensionalidad. Sin embargo, los codificadores automáticos son más adaptables.
- PCA solo puede modelar funciones lineales, mientras que Autoencoders puede modelar funciones lineales y no lineales complejas.
- Las características de PCA no están linealmente correlacionadas entre sí porque las características son proyecciones sobre una base ortogonal. Sin embargo, las características codificadas automáticamente pueden tener correlaciones porque están entrenadas para una reconstrucción aproximada.
- En comparación con los codificadores automáticos, PCA es más rápido y computacionalmente más económico.
- Un codificador automático con una sola capa oculta y una función de activación lineal es similar a PCA.
- Debido a que hay tantos parámetros, los codificadores automáticos son susceptibles de sobreajuste. (Pero la regularización y las elecciones de diseño cautelosas pueden evitar esto)
Pregunta 4: ¿Cuándo se debe usar PCA y cuándo se debe codificar automáticamente?
Respuesta Además de considerar los recursos informáticos, la elección de la técnica depende de las propiedades del propio espacio de características. Cuando las características tienen una relación no lineal, el codificador automático puede comprimir mejor los datos/información en un espacio latente de menor dimensión utilizando su capacidad para modelar funciones no lineales complejas.

Figura 3: Diagrama que ilustra la salida de PCA y Autoencoder cuando están sujetos a diferentes funciones 2D
Fuente: Urwa Muaz
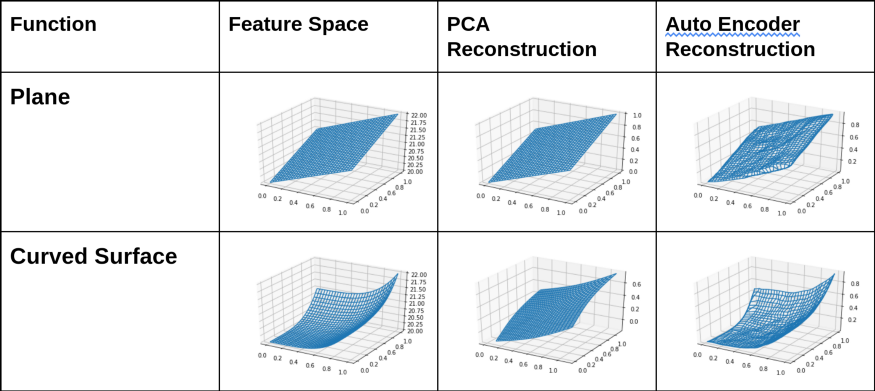
Figura 4: Diagrama que ilustra la salida de PCA y Autoencoder cuando están sujetos a diferentes funciones 3D
Fuente: Urwa Muaz
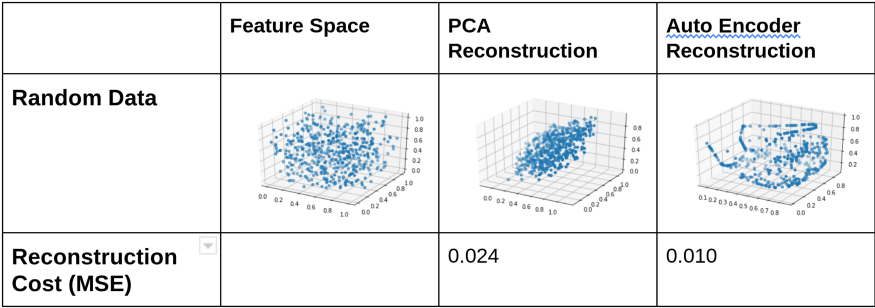
Figura 5: Diagrama que ilustra la salida de PCA y Autoencoder cuando están sujetos a diferentes funciones aleatorias
Fuente: Urwa Muaz
Entonces, a partir de los diagramas y MSE anteriores, es bastante evidente que siempre que haya una relación no lineal en el espacio de características, Autoencoder reconstruye con mayor precisión. Por el contrario, PCA conserva solo la proyección sobre el primer componente principal, y se pierde cualquier otra información perpendicular a él.
Pregunta 5: Enumere algunas aplicaciones de Autoencoder.
Respuesta: Las siguientes son algunas de las aplicaciones de Autoencoder:
- Reducción de dimensionalidad: La red del codificador (del Autoencoder) aprende a crear una versión comprimida/codificada de los datos de entrada y, por lo tanto, logra la reducción de la dimensionalidad.
- Extracción de características: Cuando se les dan datos sin etiquetar, los codificadores automáticos pueden codificar de manera eficiente la estructura de los datos y usar esa información para tareas de aprendizaje supervisado.
- Eliminación de ruido de la imagen: El codificador automático recibe la imagen de entrada ruidosa como entrada y reconstruye la salida sin ruido minimizando la pérdida de reconstrucción de la salida objetivo original (sin ruido). Los pesos del codificador automático capacitados se pueden usar para eliminar el ruido de la imagen original.
- Compresión de imagen: Autoencoder tiene como objetivo aprender una función de identidad para reconstruir la entrada original y al mismo tiempo comprimir los datos en el proceso. La imagen reconstruida es la aproximación a la entrada x.
- Búsqueda de imágenes: La base de datos de imágenes se puede comprimir usando codificadores automáticos. La incrustación comprimida se puede usar para comparar o buscar usando una versión codificada de la imagen de búsqueda.
- Detección de anomalías: Un modelo de detección de anomalías puede detectar una transacción fraudulenta o cualquier tarea supervisada desequilibrada.
- Imputación del valor faltante: Los valores que faltan en el conjunto de datos se pueden imputar utilizando codificadores automáticos de eliminación de ruido.
Conclusión
Este artículo presenta las cinco preguntas de entrevista más imperativas sobre codificadores automáticos que podrían formularse en entrevistas de ciencia de datos. Usando estas preguntas de la entrevista, puede trabajar en su comprensión de diferentes conceptos, formular respuestas efectivas y presentárselas al entrevistador.
En resumen, los puntos clave de este artículo son:
1. Autoencoder tiene como objetivo aprender una función de identidad para reconstruir la entrada original y al mismo tiempo comprimir los datos en el proceso. La imagen reconstruida es la aproximación a la entrada x.
2. Autoencoder consta de una red de codificador y decodificador.
3. Internamente, el cuello de botella consta de una capa oculta que describe un código que representa la entrada. Las capas ocultas suelen tener menos nodos que las capas de entrada y salida para impedir que las redes aprendan la función de identidad.
4. Cuando la capa oculta y la capa de entrada tengan el mismo número de nodos, el codificador automático será inútil.
5. Tanto PCA como Autoencoder (Encoder Network) logran una reducción de la dimensionalidad. Sin embargo, los codificadores automáticos son más flexibles. PCA solo puede modelar funciones lineales, mientras que Autoencoders puede modelar funciones lineales y no lineales complejas.
6. Los codificadores automáticos se pueden utilizar para la reducción de dimensionalidad, la búsqueda de imágenes, la compresión de imágenes, la imputación de valores faltantes, etc.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2022/11/top-5-interview-questions-on-autoencoders/

