¿Sabías que si bien el Blog de Ahrefs funciona con WordPress, gran parte del resto del sitio funciona con JavaScript como React?
La realidad de la web actual es que JavaScript está en todas partes. La mayoría de los sitios web utilizan algún tipo de JavaScript para agregar interactividad y mejorar la experiencia del usuario.
Sin embargo, la mayor parte del JavaScript utilizado en tantos sitios web no afectará en absoluto al SEO. Si tiene una instalación normal de WordPress sin mucha personalización, es probable que ninguno de los problemas se le aplique.
Donde encontrará problemas es cuando se utiliza JavaScript para crear una página completa, agregar o quitar elementos, o cambiar lo que ya estaba en la página. Algunos sitios lo usan para menús, para obtener productos o precios, para obtener contenido de múltiples fuentes o, en algunos casos, para todo lo que hay en el sitio. Si este le parece su sitio, siga leyendo.
Estamos viendo sistemas y aplicaciones completos creados con marcos de JavaScript e incluso algunos CMS tradicionales con un toque de JavaScript donde no tienen cabeza o están desacoplados. El CMS se utiliza como fuente de datos del backend, pero la presentación del frontend la maneja JavaScript.
No estoy diciendo que los SEO deban salir y aprender a programar JavaScript. De hecho, no lo recomiendo porque es poco probable que alguna vez toques el código. Lo que los SEO necesitan saber es cómo maneja Google JavaScript y cómo solucionar problemas.
JavaScript SEO es parte de SEO técnico (optimización de motores de búsqueda) que hace que los sitios web con mucho JavaScript sean fáciles de rastrear e indexar, además de fáciles de buscar. El objetivo es que estos sitios web sean encontrados y clasificar más alto en los motores de búsqueda.
JavaScript no es malo para el SEO y no es malo. Es simplemente diferente de lo que muchos SEO están acostumbrados y hay una pequeña curva de aprendizaje.
Muchos de los procesos son similares a cosas que los SEO ya están acostumbrados a ver, pero puede haber ligeras diferencias. Seguirás viendo principalmente código HTML, sin mirar JavaScript.
Se siguen aplicando todas las mejores prácticas normales de SEO en la página. Ver nuestra guía sobre SEO on-page.
Incluso encontrará opciones familiares de tipo complemento para manejar muchos de los elementos básicos de SEO, si aún no están integrados en el marco que está utilizando. Para los marcos de JavaScript, estos se denominan módulos y encontrará muchas opciones de paquetes para instalarlos.
Hay versiones para muchos de los marcos populares como Reaccionar, Vue, Angular y Svelte que puede encontrar buscando el marco + nombre del módulo como "React Helmet". Las metaetiquetas, Casco y Cabeza son módulos populares con funcionalidad similar y permiten configurar muchas de las etiquetas populares necesarias para SEO.
En algunos aspectos, JavaScript es mejor que el HTML tradicional, como la facilidad de creación y el rendimiento. En cierto modo, JavaScript es peor, ya que no se puede analizar progresivamente (como pueden serlo HTML y CSS) y puede afectar mucho la carga y el rendimiento de la página. A menudo, es posible que esté intercambiando rendimiento por funcionalidad.
JavaScript no es perfecto y no siempre es la herramienta adecuada para el trabajo. Los desarrolladores lo usan en exceso para cosas en las que probablemente haya una solución mejor. Pero a veces hay que trabajar con lo que te dan.
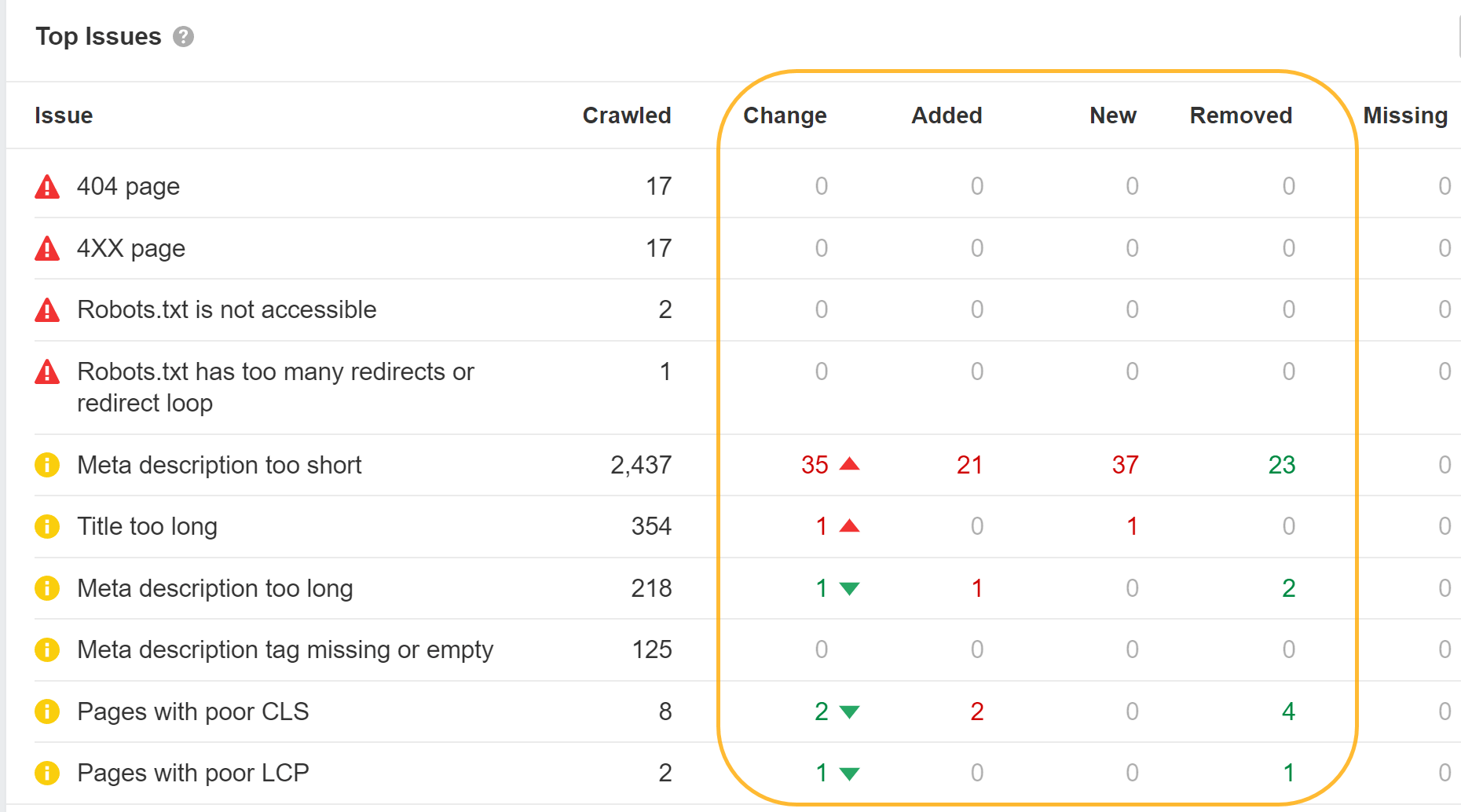
Estos son muchos de los problemas de SEO comunes que puede encontrar al trabajar con sitios de JavaScript.
Tener etiquetas de título y meta descripciones únicas
Todavía vas a querer tener algo único. etiquetas de título y Meta descripción a través de tus páginas. Debido a que muchos de los marcos de JavaScript tienen plantillas, es fácil terminar en una situación en la que se utilice el mismo título o meta descripción para todas las páginas o un grupo de páginas.
Asegúrate de leer Duplicados informe en Ahrefs' Auditoría del sitio y haga clic en cualquiera de las agrupaciones para ver más datos sobre los problemas que encontramos.
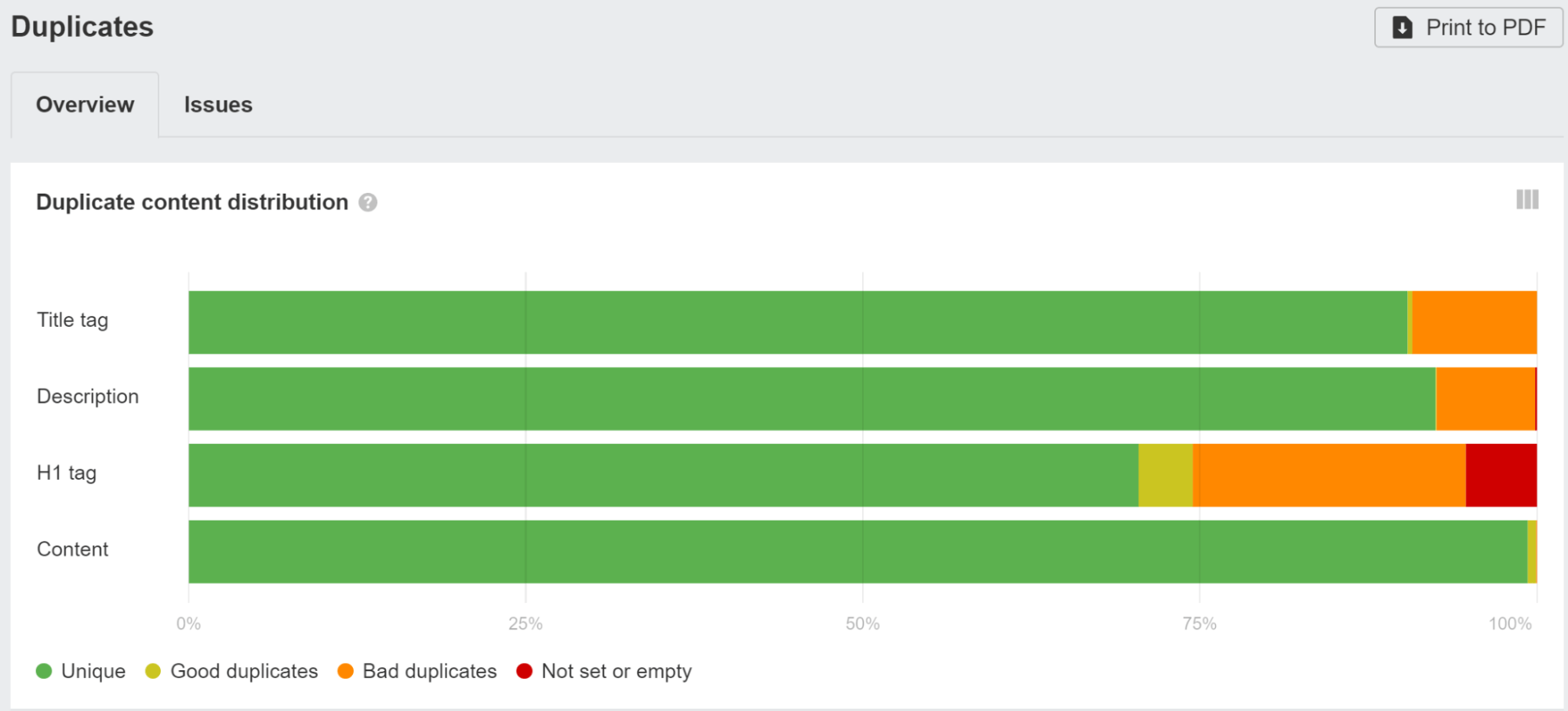
Puede utilizar uno de los módulos de SEO como Helmet para configurar etiquetas personalizadas para cada página.
JavaScript también se puede utilizar para sobrescribir los valores predeterminados que haya establecido. Google procesará esto y utilizará el título o la descripción sobrescritos. Para los usuarios, sin embargo, los títulos pueden ser problemáticos, ya que un título puede aparecer en el navegador y notarán un destello cuando se sobrescribe.
Si ves el título parpadeando, puedes usar Ahrefs Barra de herramientas SEO para ver tanto el HTML sin formato como las versiones renderizadas.
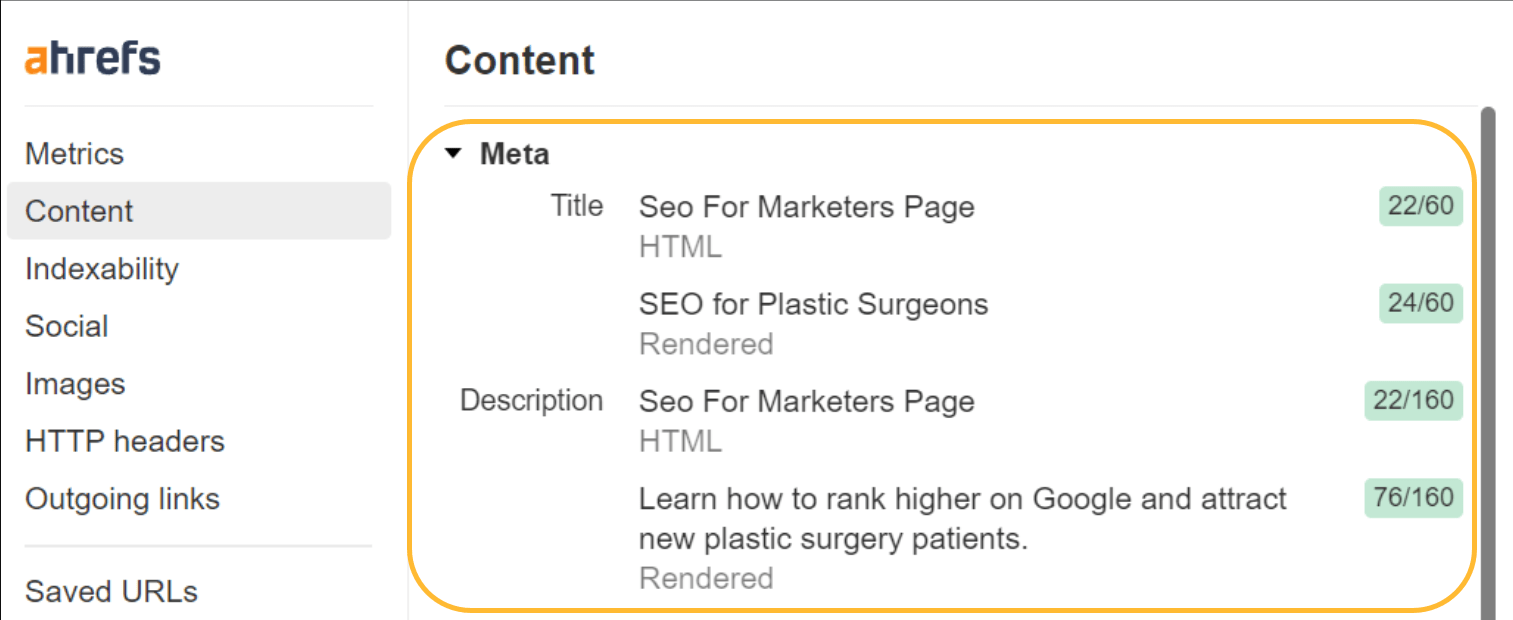
Es posible que Google no utilice sus títulos o meta descripciones de todos modos. Como mencioné, vale la pena limpiar los títulos para los usuarios. Sin embargo, arreglar esto para las meta descripciones realmente no hará una diferencia.
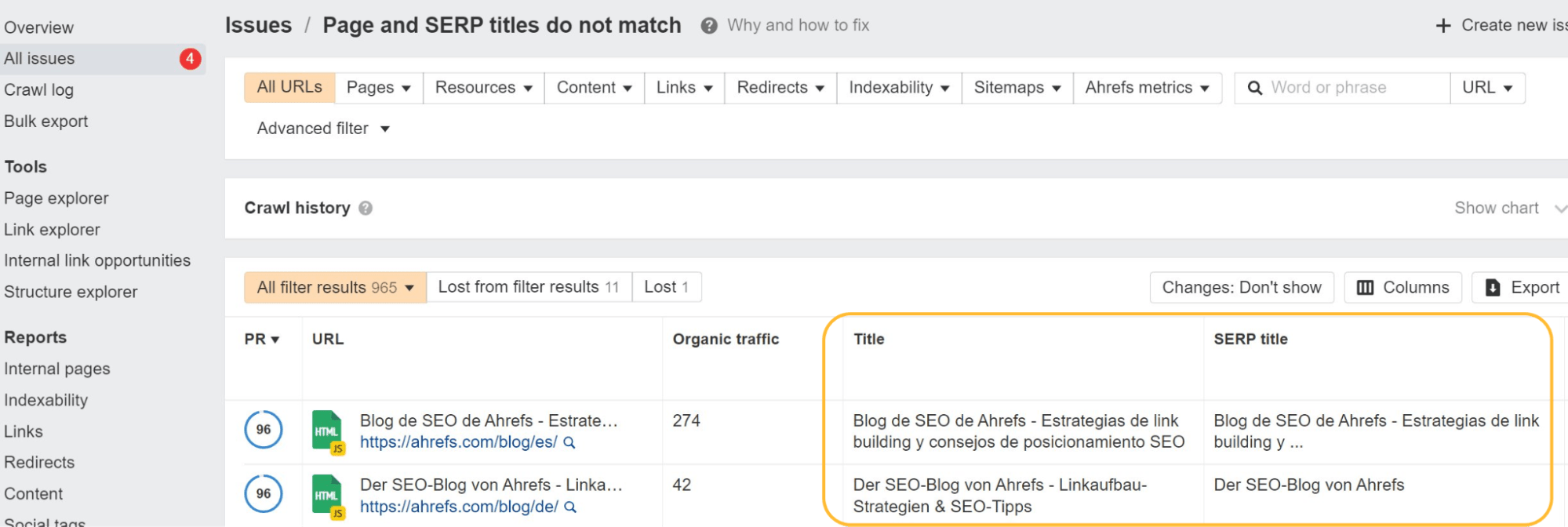
Cuando estudiamos la reescritura de Google, descubrimos que Google sobrescribe títulos el 33.4% de las veces y meta descripciones el 62.78% del tiempo. En Auditoría del sitio, incluso le mostraremos cuáles de sus etiquetas de título ha cambiado Google.
Problemas con etiquetas canónicas
Durante años, Google dijo que no respetaba etiquetas canónicas insertado con JavaScript. Finalmente agregó una excepción a la documentación para los casos en los que aún no había una etiqueta. Yo causé ese cambio. Realicé pruebas para demostrar que esto funcionaba cuando Google les decía a todos que no era así.
Si ya había una etiqueta canónica presente y agrega otra o sobrescribe la existente con JavaScript, entonces les está dando dos etiquetas canónicas. En este caso, Google tiene que decidir cuál usar o ignorar las etiquetas canónicas en favor de otras. señales de canonicalización.
El consejo estándar de SEO de “cada página debe tener una etiqueta canónica de autorreferencia” mete en problemas a muchos SEO. Un desarrollador acepta ese requisito y hace que las páginas con y sin barra diagonal sean autocanónicas.
example.com/page con una canónica de example.com/page y example.com/page/ con una canónica de example.com/page/. Ups, ¡eso está mal! Probablemente quieras redirigir una de esas versiones a la otra.
Lo mismo puede suceder con las versiones parametrizadas que quizás quieras combinar, pero cada una es autorreferenciada.
Google utiliza la metaetiqueta robots más restrictiva
Con etiquetas meta robots, Google siempre elegirá la opción más restrictiva que vea, sin importar la ubicación.
Si tiene una etiqueta de índice en el HTML sin formato y una etiqueta noindex en el HTML renderizado, Google la tratará como noindex. Si tiene una etiqueta noindex en el HTML sin formato pero la sobrescribe con una etiqueta de índice usando JavaScript, seguirá tratando esa página como noindex.
Funciona igual para las etiquetas nofollow. Google va a tomar la opción más restrictiva.
Establecer atributos alt en imágenes
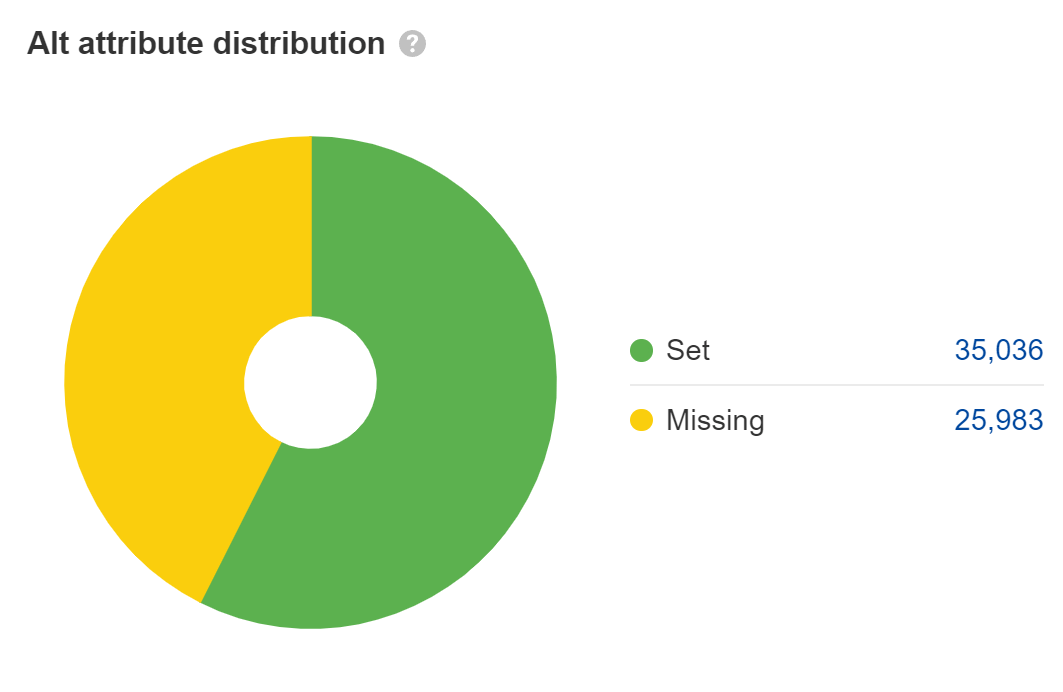
Desaparecido atributos alternativos son un problema de accesibilidad, que puede convertirse en un problema legal. La mayoría de las grandes empresas han sido demandadas por problemas de cumplimiento de la ADA en sus sitios web y algunas son demandadas varias veces al año. Yo arreglaría esto para las imágenes del contenido principal, pero no para cosas como marcadores de posición o imágenes decorativas donde puedes dejar los atributos alt en blanco.
Para la búsqueda web, el texto en los atributos alt cuenta como texto en la página, pero en realidad esa es la única función que desempeña. En mi opinión, a menudo se exagera su importancia para el SEO. Sin embargo, ayuda con la búsqueda y clasificación de imágenes.
Muchos desarrolladores de JavaScript dejan los atributos alt en blanco, así que verifica que los tuyos estén allí. Mira el Imágenes informe en Auditoría del sitio para encontrar estos.
Permitir el rastreo de archivos JavaScript
No bloquee el acceso a los recursos si son necesarios para crear parte de la página o agregar contenido. Google necesita acceder y descargar recursos para poder representar las páginas correctamente. En tus robots.txt, la forma más sencilla de permitir que se rastreen los recursos necesarios es agregar:
User-Agent: GooglebotAllow: .jsAllow: .css
También verifique los archivos robots.txt para ver si hay subdominios o dominios adicionales desde los que pueda realizar solicitudes, como aquellos para sus llamadas API.
Si ha bloqueado recursos con robots.txt, puede verificar si afecta el contenido de la página usando las opciones de bloqueo en la pestaña "Red" en Chrome Dev Tools. Seleccione el archivo y bloquéelo, luego vuelva a cargar la página para ver si se realizó algún cambio.
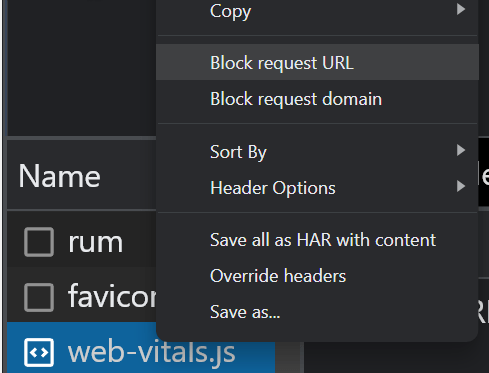
Comprueba si Google ve tu contenido
Es posible que muchas páginas con funcionalidad JavaScript no muestren todo el contenido a Google de forma predeterminada. Si habla con sus desarrolladores, es posible que se refieran a esto como si no estuviera cargado el Modelo de objetos de documento (DOM). Esto significa que el contenido no se cargó de forma predeterminada y podría cargarse más tarde con una acción como un clic.
Una comprobación rápida que puedes hacer es simplemente buscar un fragmento de tu contenido en Google entre comillas. Busque "alguna frase de su contenido" y vea si la página aparece en los resultados de búsqueda. Si es así, es probable que se haya visto su contenido.
Nota al margen.
Es posible que el contenido que está oculto de forma predeterminada no se muestre dentro de su fragmento en la SERPs. Es especialmente importante verificar su versión móvil, ya que a menudo está simplificada para la experiencia del usuario.
También puede hacer clic derecho y usar la opción "Inspeccionar". Busque el texto dentro de la pestaña "Elementos".
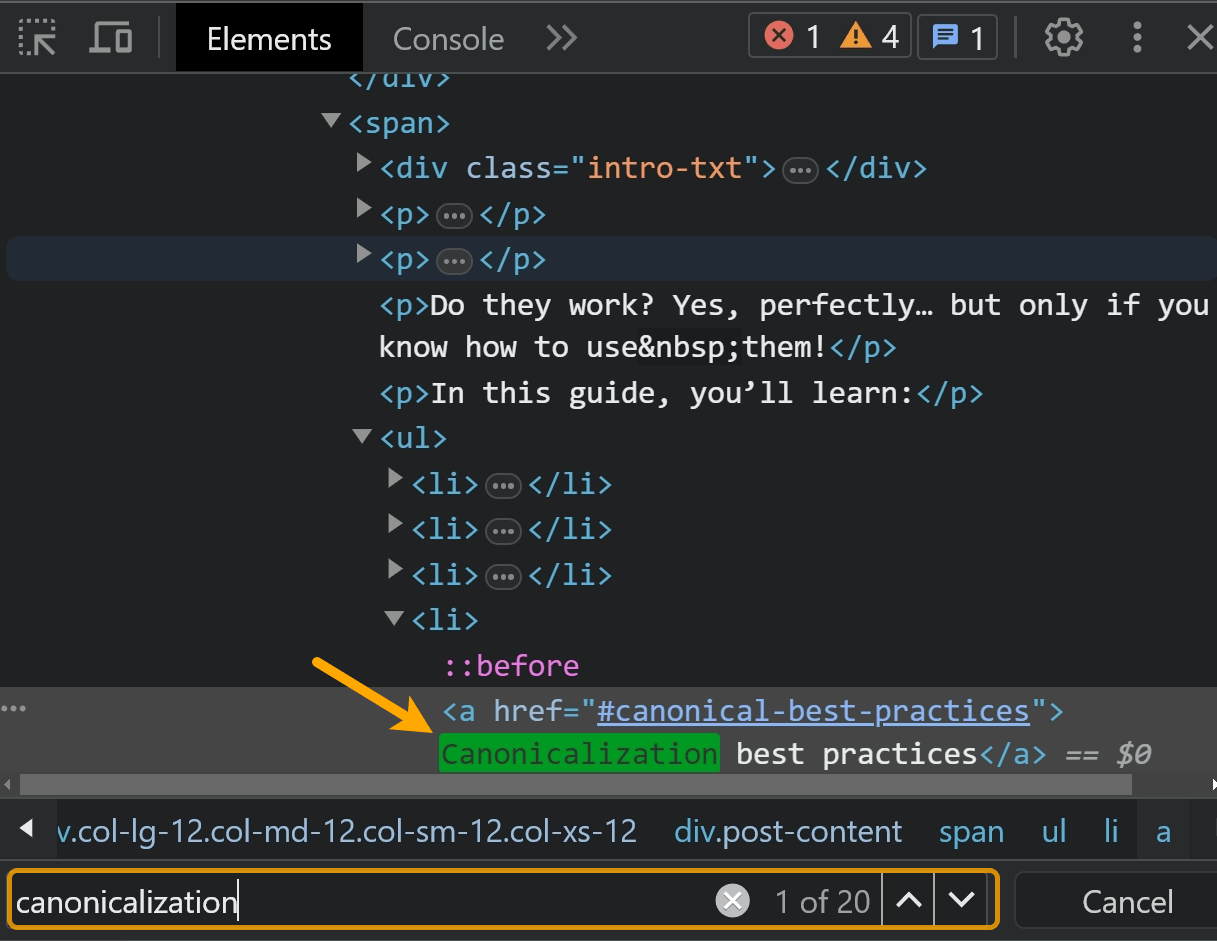
La mejor verificación será buscar en el contenido de una de las herramientas de prueba de Google, como la herramienta de inspección de URL en Google Search Console. Hablaré más sobre esto más adelante.
Definitivamente revisaría cualquier cosa detrás de un acordeón o un menú desplegable. A menudo, estos elementos realizan solicitudes que cargan contenido en la página cuando se hace clic en ellos. Google no hace clic, por lo que no ve el contenido.
Si utiliza el método de inspección para buscar contenido, asegúrese de copiar el contenido y luego volver a cargar la página o abrirla en una ventana de incógnito antes de realizar la búsqueda.
Si hizo clic en el elemento y el contenido cargado cuando se realizó esa acción, encontrará el contenido. Es posible que no vea el mismo resultado con una nueva carga de la página.
Problemas de contenido duplicado
Con JavaScript, puede haber varias URL para el mismo contenido, lo que lleva a contenido duplicado asuntos. Esto puede deberse a mayúsculas, barras diagonales, ID, parámetros con ID, etc. Por lo tanto, todos estos pueden existir:
domain.com/Abcdomain.com/abcdomain.com/123domain.com/?id=123
Si solo desea indexar una versión, debe establecer etiquetas canónicas de autorreferencia y etiquetas canónicas de otras versiones que hagan referencia a la versión principal o, idealmente, redirigir las otras versiones a la versión principal.
Asegúrate de leer Duplicados informe en Auditoría del sitio. Desglosamos qué clústeres duplicados tienen etiquetas canónicas establecidas y cuáles tienen problemas.
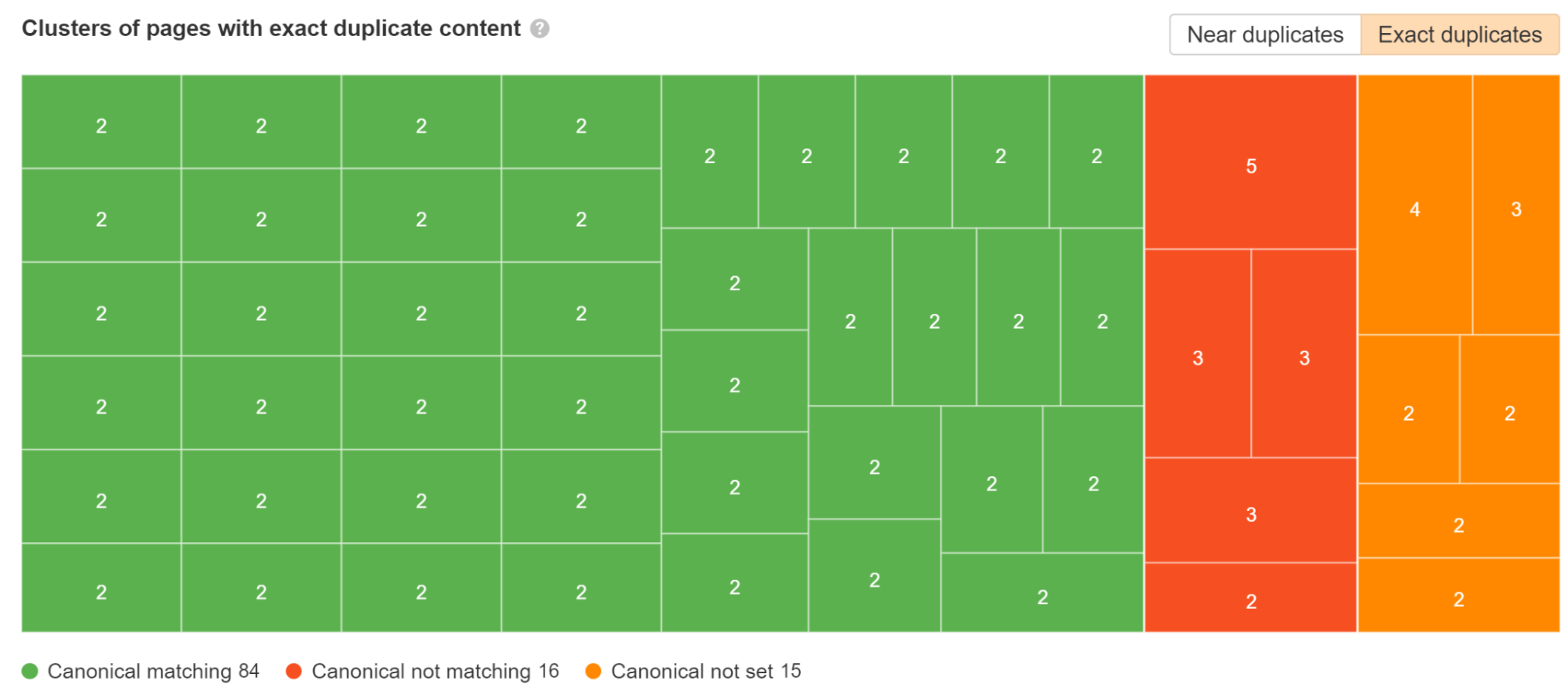
Un problema común con los marcos de JavaScript es que las páginas pueden existir con y sin barra diagonal. Lo ideal sería elegir la versión que prefiera y asegurarse de que esa versión tenga una etiqueta canónica de autorreferencia y luego redirigir la otra versión a su versión preferida.
Con los modelos de shell de aplicaciones, es posible que se muestre muy poco contenido y código en la respuesta HTML inicial. De hecho, cada página del sitio puede mostrar el mismo código, y este código puede ser exactamente el mismo que el de otros sitios web.
Si ve muchas URL con un recuento bajo de palabras en Auditoría del sitio, puede indicar que tiene este problema.
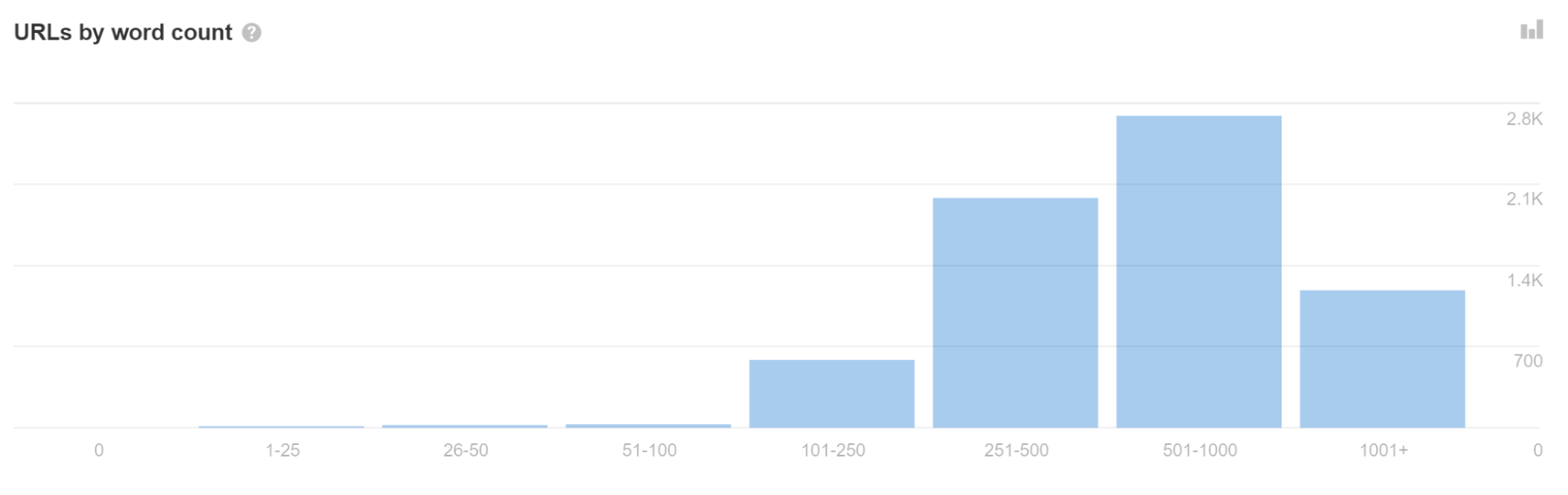
A veces, esto puede hacer que las páginas se traten como duplicadas y no se procesen inmediatamente. Peor aún, es posible que aparezca la página equivocada o incluso el sitio equivocado en los resultados de búsqueda. Esto debería resolverse solo con el tiempo, pero puede ser problemático, especialmente con sitios web más nuevos.
No utilice fragmentos (#) en las URL
# ya tiene una funcionalidad definida para navegadores. Al hacer clic en él, se vincula a otra parte de una página, como nuestra función de “tabla de contenido” en el blog. Los servidores generalmente no procesan nada después de #. Entonces, para una URL como abc.com/#something, cualquier cosa después de # normalmente se ignora.
Los desarrolladores de JavaScript han decidido que quieren utilizar # como activador para diferentes propósitos, y eso genera confusión. Las formas más comunes en que se utilizan incorrectamente son para enrutar y para Parámetros de URL. Sí, funcionan. No, no deberías hacerlo.
Los marcos de JavaScript suelen tener enrutadores que asignan lo que llaman rutas (rutas) a URL limpias. Muchos desarrolladores de JavaScript utilizan hashes (#) para el enrutamiento. Esto es especialmente un problema para Vue y algunas de las versiones anteriores de Angular.
Para solucionar este problema en Vue, puede trabajar con su desarrollador para cambiar lo siguiente:
Vue router: Use ‘History’ Mode instead of the traditional ‘Hash’ Mode.
const router = new VueRouter ({mode: ‘history’,router: [] //the array of router links)}
¿Existe una tendencia creciente en la que la gente usa # en lugar de? como identificador de fragmento, especialmente para parámetros de URL pasivos como los utilizados para el seguimiento. Tiendo a desaconsejarlo debido a toda la confusión y los problemas. Situacionalmente, podría estar de acuerdo con que me deshaga de muchos parámetros innecesarios.
Crear un mapa del sitio
Las opciones de enrutador que permiten URL limpias suelen tener un módulo adicional que también puede crear mapas de sitio. Puede encontrarlos buscando el mapa del sitio de su sistema + enrutador, como "mapa del sitio del enrutador Vue".
Muchas de las soluciones de renderizado también pueden tener opciones de mapas del sitio. Nuevamente, simplemente busque el sistema que utiliza y busque en Google el sistema + mapa del sitio, como “mapa del sitio de Gatsby”, y seguramente encontrará una solución que ya existe.
Códigos de estado y 404 suaves
Debido a que los marcos de JavaScript no están del lado del servidor, en realidad no pueden generar un error de servidor como un 404. Tiene un par de opciones diferentes para las páginas de error, como por ejemplo:
- Usar una redirección de JavaScript a una página que responde con un código de estado 404.
- Agregar una etiqueta noindex a la página que falla junto con algún tipo de mensaje de error como "Página 404 no encontrada". Esto se tratará como un 404 suave ya que el código de estado real devuelto será 200 correcto.
Las redirecciones de JavaScript están bien, pero no son las preferidas
Los SEO están acostumbrados a Redirecciones 301/302, que están del lado del servidor. JavaScript normalmente se ejecuta en el lado del cliente. Las redirecciones del lado del servidor e incluso las redirecciones de metaactualización serán más fáciles de procesar para Google que las redirecciones de JavaScript, ya que no tendrá que representar la página para verlas.
Las redirecciones de JavaScript aún se verán y procesarán durante la renderización y deberían estar bien en la mayoría de los casos; simplemente no son tan ideales como otros tipos de redirecciones. Se tratan como redireccionamientos permanentes y aún así pasan todas las señales como PageRank.
A menudo puedes encontrar estas redirecciones en el código buscando "window.location.href". Las redirecciones también podrían estar en el archivo de configuración. En la configuración de Next.js, hay una función de redireccionamiento que puede usar para configurar redireccionamientos. En otros sistemas, es posible que los encuentres en el enrutador.
Problemas de internacionalización
Por lo general, hay algunas opciones de módulos para diferentes marcos que admiten algunas características necesarias para la internacionalización, como hreflang. Por lo general, se han portado a diferentes sistemas e incluyen i18n, intl o, muchas veces, los mismos módulos utilizados para las etiquetas de encabezado, como Helmet, se pueden usar para agregar las etiquetas necesarias.
Señalamos problemas de hreflang en el aplicaciones móviles informe en Auditoría del sitio. También realizamos un estudio y descubrimos que El 67% de los dominios que utilizan hreflang tienen problemas.
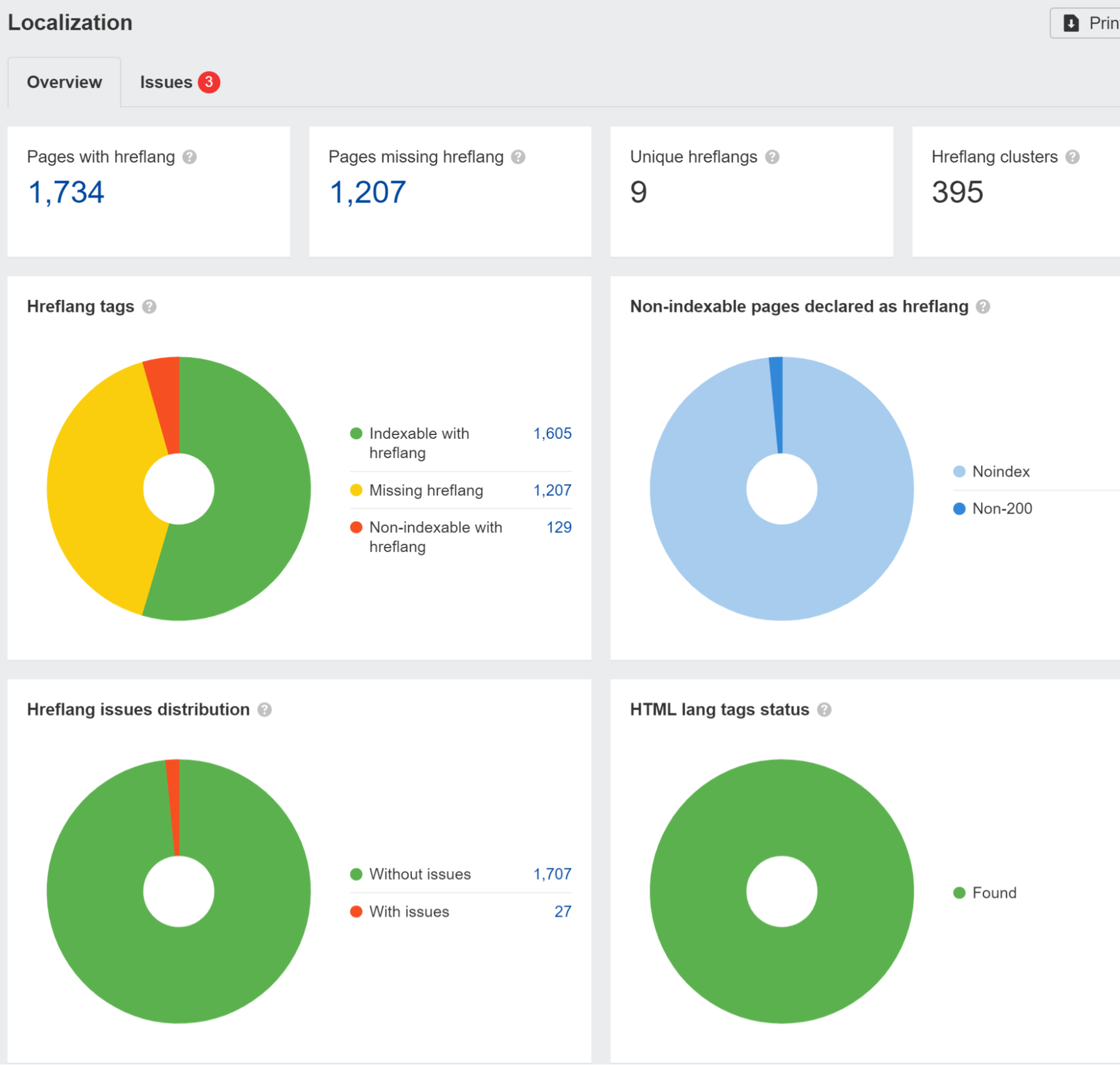
También debe tener cuidado si su sitio bloquea o trata a visitantes de un país específico o utiliza una IP particular de diferentes maneras. Esto puede hacer que su contenido no sea visto por Googlebot. Si tiene una lógica para redirigir a los usuarios, es posible que desee excluir los bots de esta lógica.
Le informaremos si esto sucede cuando configure un proyecto en Site Audit.

Usar datos estructurados
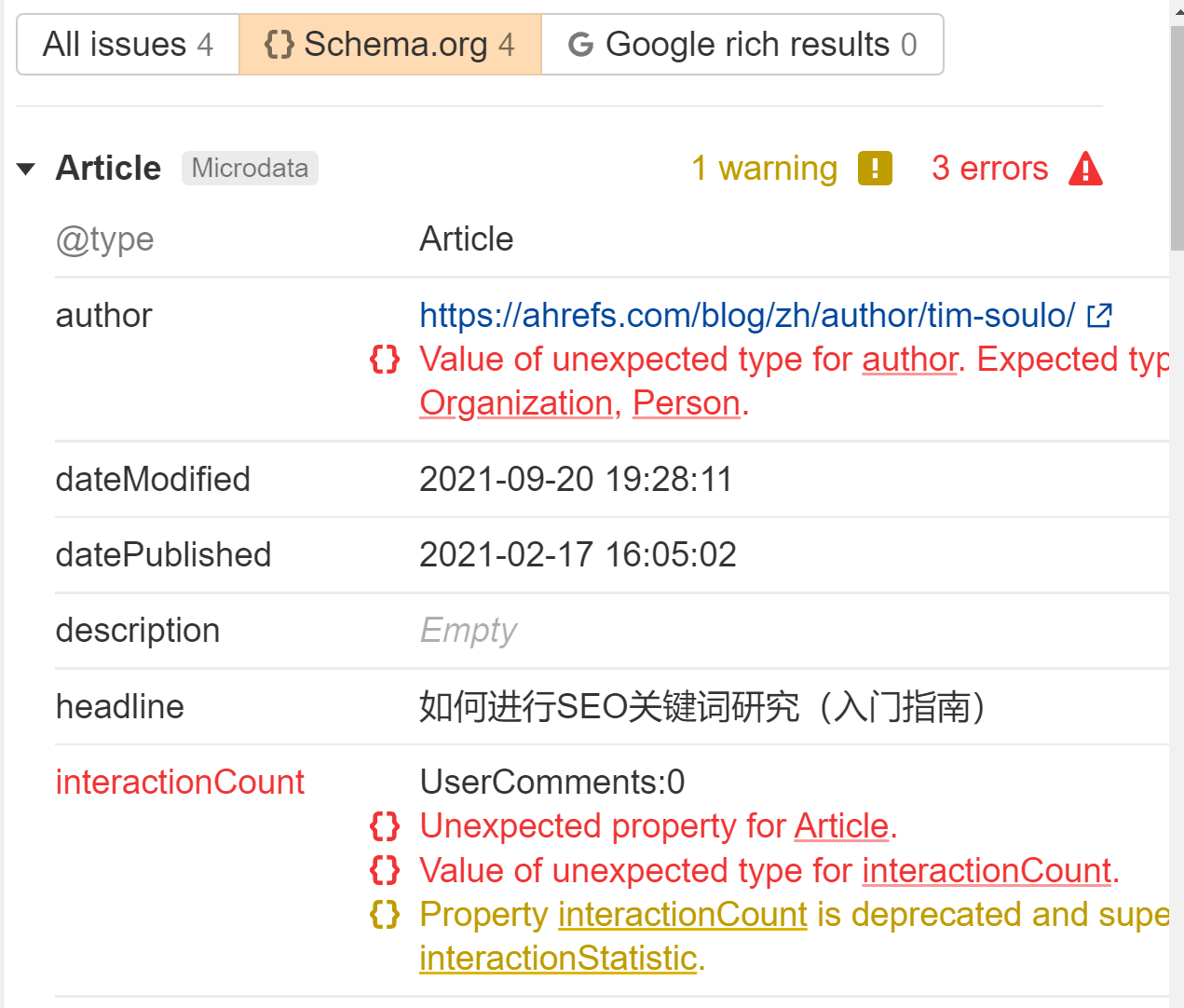
JavaScript se puede utilizar para generar o inyectar datos estructurados en sus páginas. Es bastante común hacer esto con JSON-LD y no es probable que cause ningún problema, pero ejecuta algunas pruebas para asegurarte de que todo salga como esperas.
Marcaremos cualquier dato estructurado que veamos en el Temas informe en Auditoría del sitio. Busque el error "Los datos estructurados tienen validación de Schema.org". Le diremos exactamente qué está mal en cada página.
Utilice enlaces de formato estándar
Los enlaces a otras páginas deben estar en el formato estándar web. Los enlaces internos y externos deben ser una <a> etiqueta con un href atributo. Hay muchas formas de hacer que los enlaces funcionen para usuarios con JavaScript que no son fáciles de buscar.
Bueno:
<a href=”/page”>simple is good</a>
<a href=”/page” onclick=”goTo(‘page’)”>still okay</a>
Malo:
<a onclick=”goTo(‘page’)”>nope, no href</a>
<a href=”javascript:goTo(‘page’)”>nope, missing link</a>
<a href=”javascript:void(0)”>nope, missing link</a>
<span onclick=”goTo(‘page’)”>not the right HTML element</span>
<option value="page">nope, wrong HTML element</option>
<a href=”#”>no link</a>
Botón, ng-click, hay muchas más formas de hacer esto incorrectamente.
En mi experiencia, Google todavía procesa muchos de los enlaces malos y los rastrea, pero no estoy seguro de cómo los trata en cuanto a señales de paso como PageRank. La Web es un lugar desordenado y los analizadores de Google suelen ser bastante indulgentes.
También vale la pena señalar que enlaces internos agregado con JavaScript no se recogerá hasta después de la renderización. Esto debería ser relativamente rápido y no ser motivo de preocupación en la mayoría de los casos.
Utilice el control de versiones de archivos para solucionar la indexación de estados imposibles
Google almacena en caché en gran medida todos los recursos por su parte. Hablaré de esto un poco más adelante, pero debes saber que su sistema puede llevar a que se indexen algunos estados imposibles. Esta es una peculiaridad de sus sistemas. En estos casos, se utilizan versiones de archivos anteriores en el proceso de renderizado y la versión indexada de una página puede contener partes de archivos más antiguos.
Puede utilizar el control de versiones de archivos o la toma de huellas digitales (file.12345.js) para generar nuevos nombres de archivos cuando se realizan cambios significativos para que Google tenga que descargar la versión actualizada del recurso para su procesamiento.
Es posible que no veas lo que se le muestra al robot de Google.
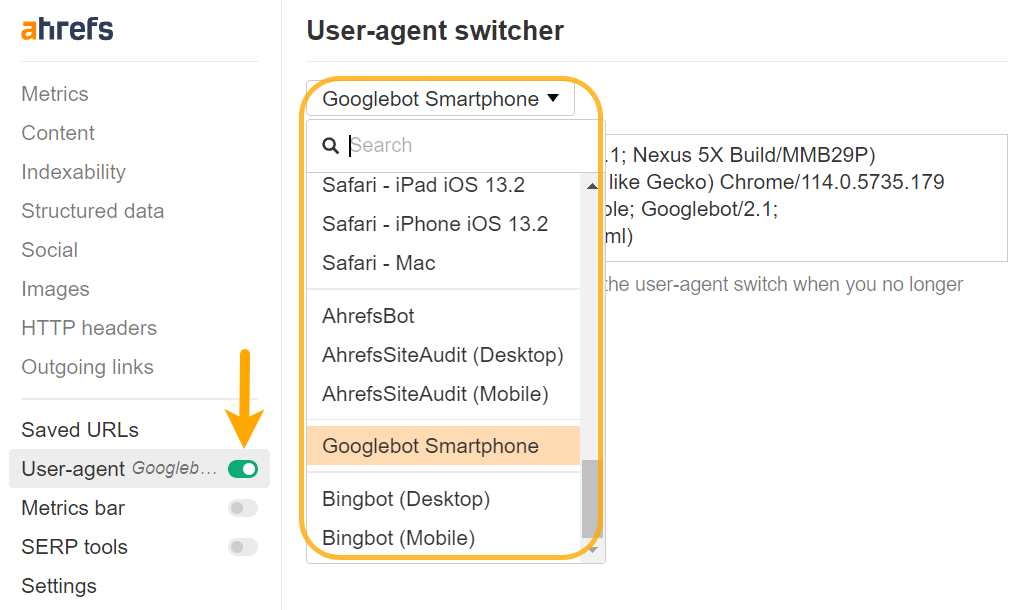
Es posible que deba cambiar su agente de usuario para diagnosticar adecuadamente algunos problemas. El contenido se puede representar de manera diferente para diferentes agentes de usuario o incluso IP. Deberías comprobar lo que Google realmente ve con sus herramientas de prueba, y las cubriré en un momento.
Puede configurar un agente de usuario personalizado con Chrome DevTools para solucionar problemas de sitios que se renderizan previamente en función de agentes de usuario específicos, o puede hacerlo fácilmente con nuestra barra de herramientas también.
Utilice polirellenos para funciones no compatibles
Puede haber funciones utilizadas por los desarrolladores que el robot de Google no admite. Tus desarrolladores pueden usar detección de funciones. Y si falta una característica, pueden optar por omitir esa funcionalidad o usar un método alternativo con un polyfill para ver si pueden hacerlo funcionar.
Esto es principalmente una información para los SEO. Si ve algo que cree que Google debería ver y no lo ve, podría deberse a la implementación.
Usar carga diferida
Desde que escribí esto originalmente, la carga diferida ha pasado de estar impulsada por JavaScript a ser manejada por navegadores.
Es posible que aún te encuentres con algunas configuraciones de carga diferida impulsadas por JavaScript. En su mayor parte, probablemente estén bien si la carga diferida es para imágenes. Lo principal que comprobaría es ver si el contenido se carga de forma diferida. Vuelva a consultar la sección "Compruebe si Google ve su contenido" anterior. Este tipo de configuraciones han causado problemas con la captura correcta del contenido.
Problemas de desplazamiento infinito
Si tiene una configuración de desplazamiento infinito, todavía recomiendo una versión de página paginada para que Google pueda rastrear correctamente.
Otro problema que he visto con esta configuración es que, ocasionalmente, dos páginas se indexan como una. He visto esto varias veces cuando la gente decía que no podían indexar su página. Pero encontré su contenido indexado como parte de otra página que generalmente es la publicación anterior de ellos.
Mi teoría es que cuando Google cambió el tamaño de la ventana gráfica para que fuera más larga (más sobre esto más adelante), activó el desplazamiento infinito y cargó otro artículo cuando se estaba renderizando. En este caso, lo que recomiendo es bloquear el archivo JavaScript que maneja el desplazamiento infinito para que la funcionalidad no pueda activarse.
Problemas de desempeño
Muchos de los marcos de JavaScript se encargan de una gran cantidad de optimización del rendimiento moderna por usted.
Se siguen aplicando todas las mejores prácticas de rendimiento tradicionales, pero obtienes algunas opciones nuevas y sofisticadas. La división de código divide los archivos en archivos más pequeños. La sacudida del árbol separa las piezas necesarias, por lo que no carga todo para cada página como vería en las configuraciones monolíticas tradicionales.
Las configuraciones de JavaScript bien hechas son algo hermoso. Las configuraciones de JavaScript que no se realizan bien pueden sobrecargarse y provocar tiempos de carga prolongados.
Consulte nuestro artículo Guía de elementos básicos de Web Vitals para obtener más información sobre el rendimiento del sitio web.
Los sitios JavaScript utilizan más presupuesto de rastreo
Solicitudes JavaScript XHR comer presupuesto de rastreo, y quiero decir que se lo tragan. A diferencia de la mayoría de los demás recursos que se almacenan en caché, estos se recuperan en vivo durante el proceso de renderizado.
Otro detalle interesante es que el servicio de renderizado intenta no recuperar recursos que no contribuyan al contenido de la página. Si se equivoca, es posible que le falte algún contenido.
Los trabajadores no reciben apoyo, ¿o sí?
Si bien Google históricamente dice que rechaza a los trabajadores de servicios y que los trabajadores de servicios no pueden editar el DOM, el propio Martin Splitt de Google indicó que a veces puedes salirte con la tuya utilizando trabajadores web.
Utilice conexiones HTTP
El robot de Google admite solicitudes HTTP pero no admite otros tipos de conexión como WebSockets or WebRTC. Si los está utilizando, proporcione una alternativa que utilice conexiones HTTP.
Un problema con los sitios JavaScript es que pueden realizar actualizaciones parciales del DOM. Es posible que navegar a otra página como usuario no actualice algunos aspectos como las etiquetas de título o las etiquetas canónicas en el DOM, pero esto puede no ser un problema para los motores de búsqueda.
Google carga cada página sin estado como si fuera una carga nueva. No guarda información anterior ni navega entre páginas.
He visto a SEO tropezar pensando que hay un problema debido a lo que ven después de navegar de una página a otra, como una etiqueta canónica que no se actualiza. Pero es posible que Google nunca vea este estado.
Los desarrolladores pueden solucionar este problema actualizando el estado usando lo que se llama API de historial. Pero repito, puede que no sea un problema. Muchas veces, son solo los SEO los que causan problemas a los desarrolladores porque les parece extraño. Actualiza la página y mira lo que ves. O mejor aún, ejecútelo en una de las herramientas de prueba de Google para ver qué ve.
Hablando de sus herramientas de prueba, hablemos de ellas.
Herramientas de prueba de Google
Google tiene varias herramientas de prueba que son útiles para JavaScript.
Herramienta de inspección de URL en Google Search Console
Esta debería ser tu fuente de verdad. Cuando inspeccionas una URL, obtendrás mucha información sobre lo que vio Google y el HTML renderizado real de su sistema.
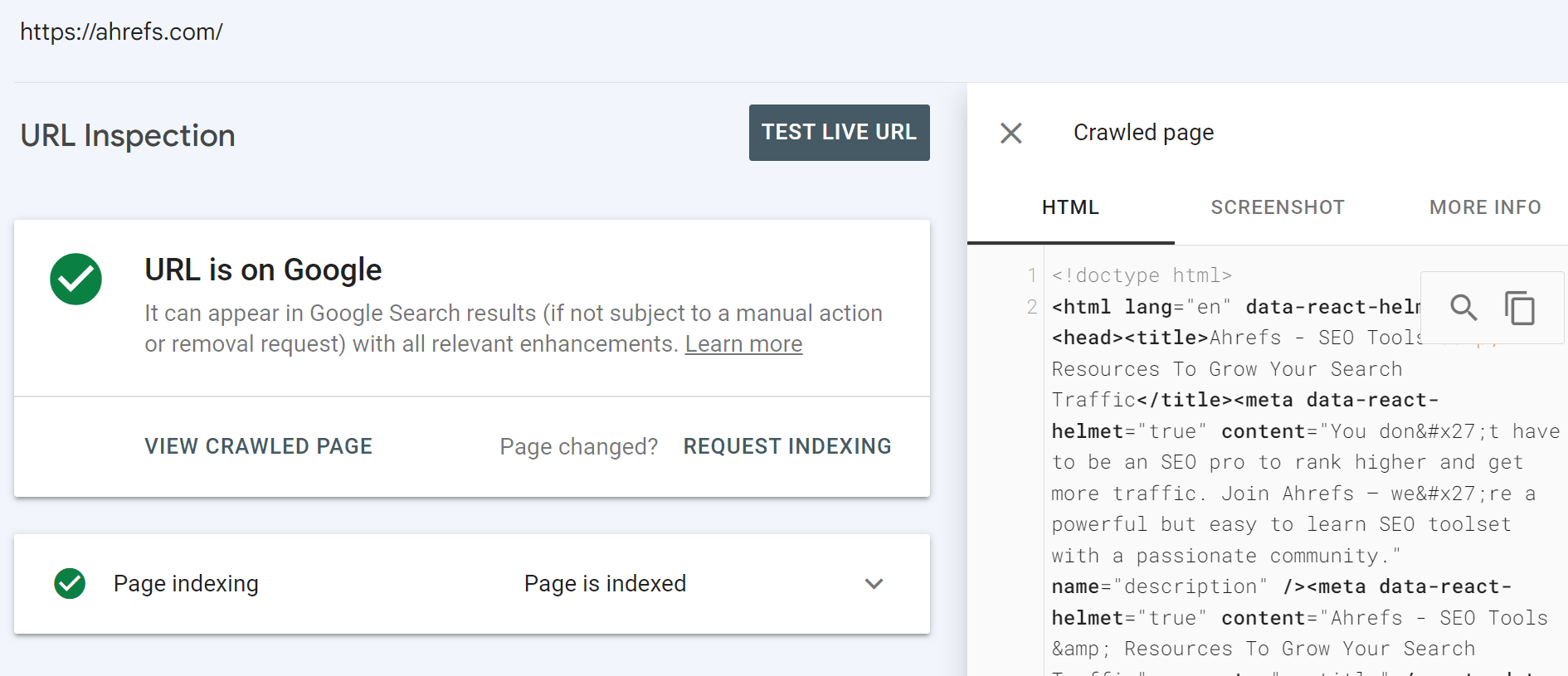
También tiene la opción de realizar una prueba en vivo.

Existen algunas diferencias entre el renderizador principal y la prueba en vivo. El renderizador utiliza recursos almacenados en caché y es bastante paciente. La prueba en vivo y otras herramientas de prueba utilizan recursos en vivo y cortan el procesamiento antes de tiempo porque estás esperando un resultado. Más adelante entraré en más detalles sobre esto en la sección de renderizado.
Las capturas de pantalla de estas herramientas también muestran páginas con los píxeles pintados, lo que Google en realidad no hace al renderizar una página.
Las herramientas son útiles para ver si el contenido está cargado en DOM. El HTML que se muestra en estas herramientas es el DOM renderizado. Puede buscar un fragmento de texto para ver si se cargó de forma predeterminada.
Las herramientas también le mostrarán recursos que pueden estar bloqueados y mensajes de error de la consola, que son útiles para la depuración.
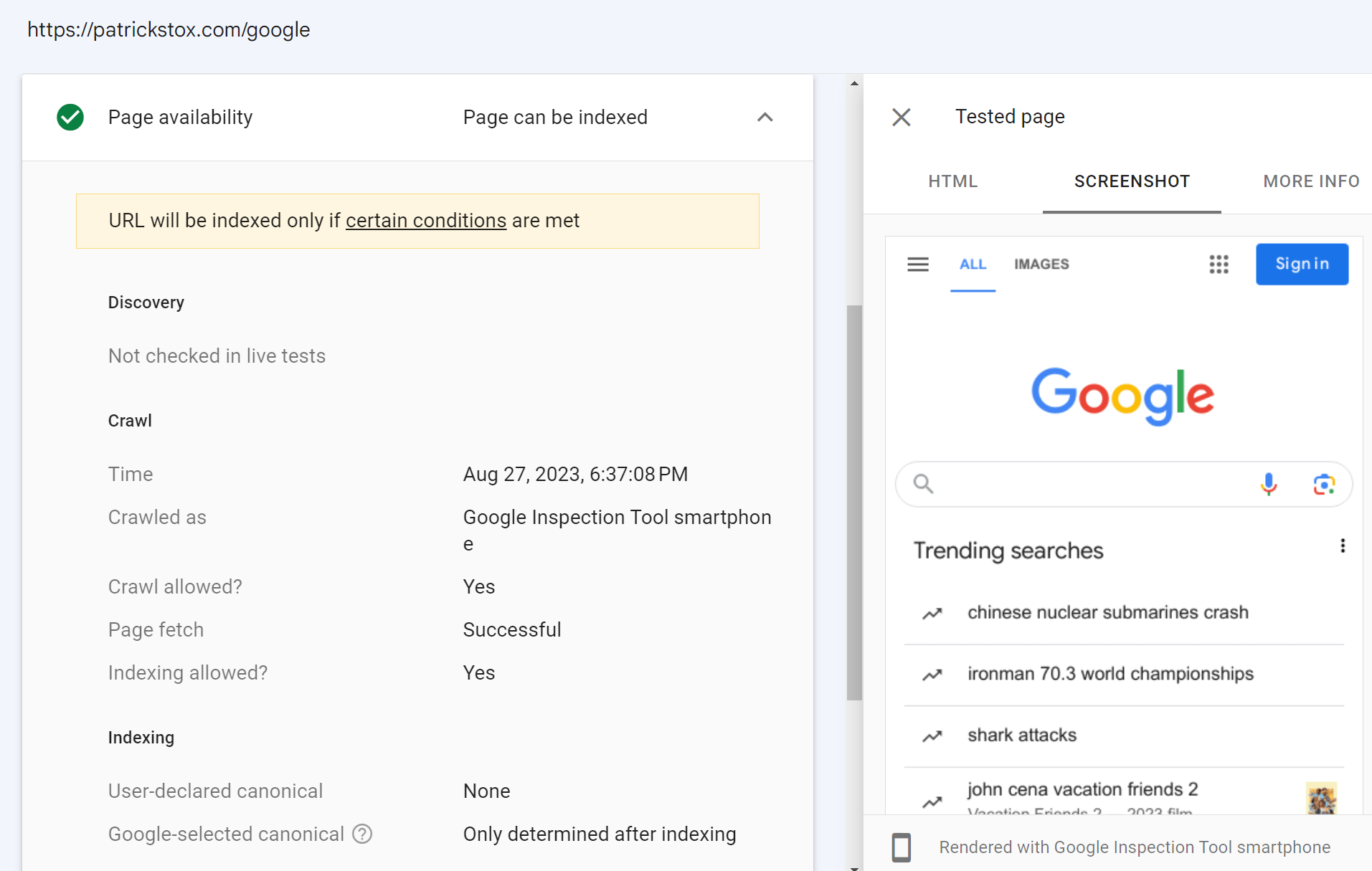
Si no tiene acceso a la propiedad de Google Search Console para un sitio web, aún puede ejecutar una prueba en vivo en él. Si agrega una redirección en su propio sitio web en una propiedad donde tiene acceso a Google Search Console, puede inspeccionar esa URL y la herramienta de inspección seguirá la redirección y le mostrará el resultado de la prueba en vivo para la página en el otro dominio.
En la captura de pantalla siguiente, agregué una redirección desde mi sitio a la página de inicio de Google. La prueba en vivo para esto sigue la redirección y me muestra la página de inicio de Google. En realidad, no tengo acceso a la cuenta de Google Search Console de Google, aunque desearía tenerlo.
Herramienta de prueba de resultados enriquecidos
La Herramienta de prueba de resultados enriquecidos le permite verificar su página renderizada como la vería el robot de Google en dispositivos móviles o de escritorio.
Herramienta de prueba optimizada para dispositivos móviles
Todavía puedes usar el Herramienta de prueba compatible con dispositivos móviles por ahora, pero Google ha anunciado que cerrará en diciembre de 2023.
Tiene las mismas peculiaridades que otras herramientas de prueba de Google.
Ahrefs
Ahrefs es la única herramienta SEO importante que representa páginas web al rastrear la web, por lo que tenemos datos de sitios JavaScript que ninguna otra herramienta tiene. Representamos ~200 millones de páginas al día, pero eso es una fracción de lo que rastreamos.
Nos permite comprobar si hay redirecciones de JavaScript. También podemos mostrar enlaces que encontramos insertados con JavaScript, que mostramos con una etiqueta JS en los informes de enlaces:

En el menú desplegable de páginas en Site Explorer, también tenemos una opción de inspección que le permite ver el historial de una página y compararlo con otros rastreos. Tenemos un marcador JS allí para las páginas que se renderizaron con JavaScript habilitado.

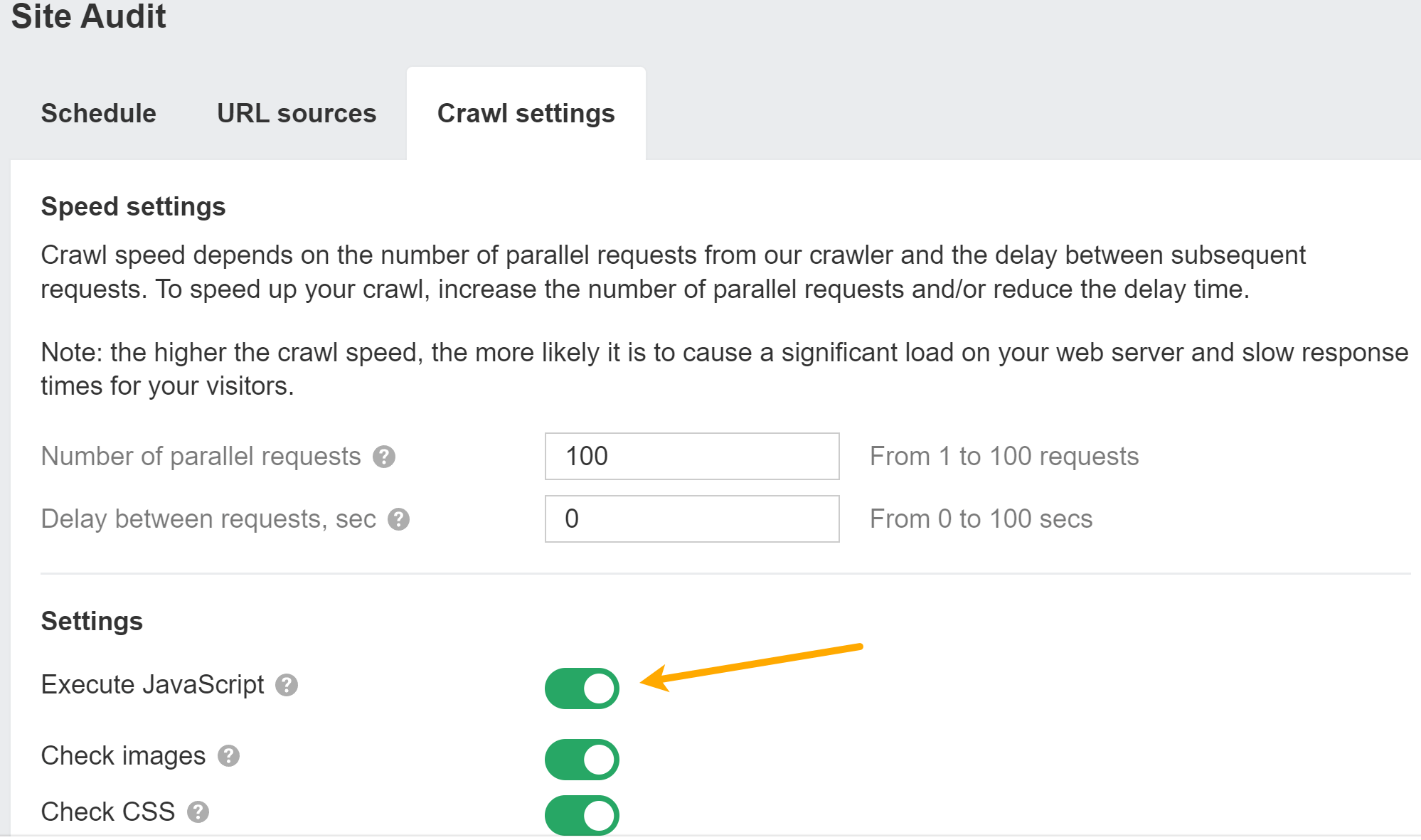
Puedes habilitar JavaScript en Auditoría del sitio rastrea para desbloquear más datos en sus auditorías.
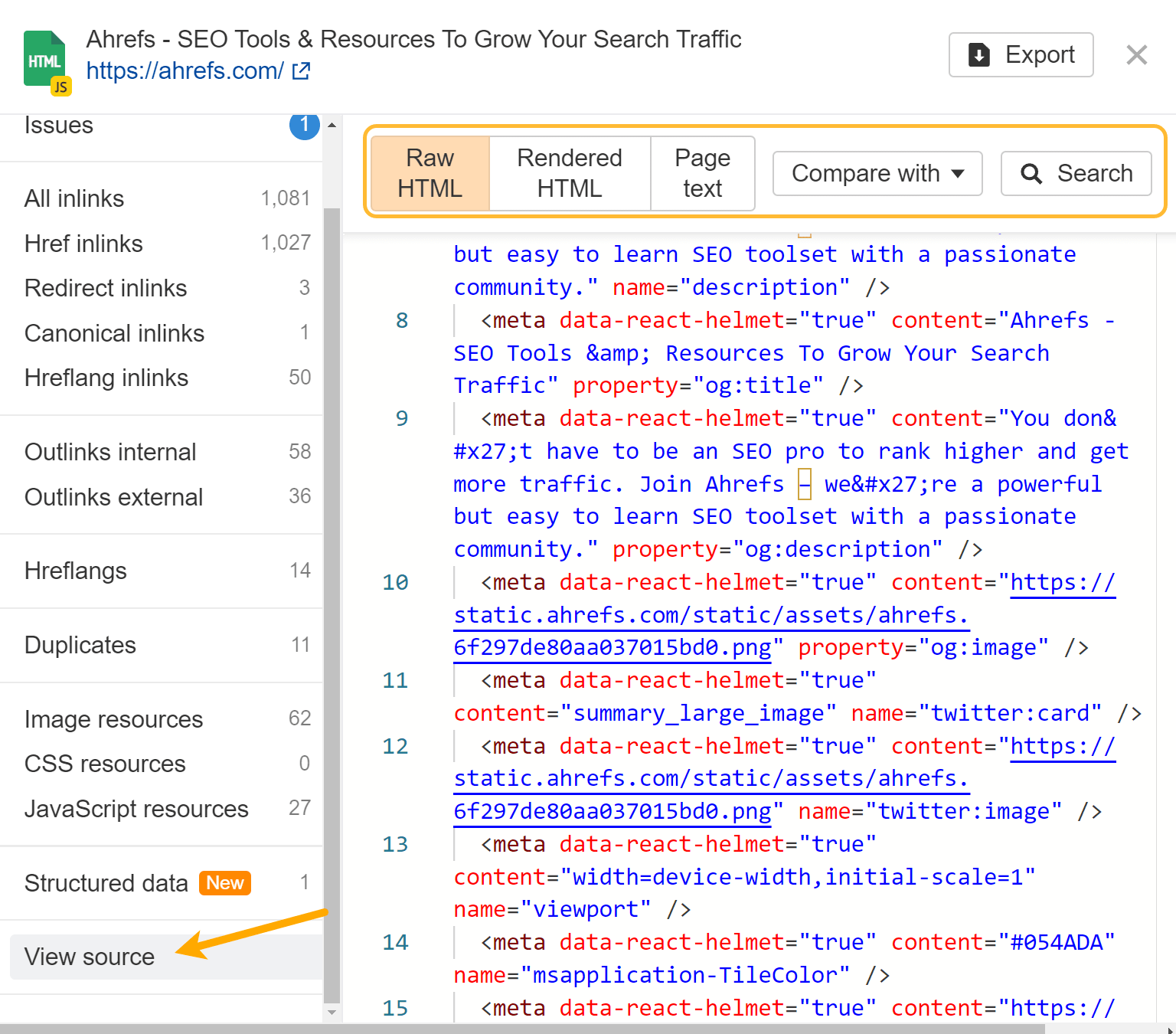
Si tiene habilitada la representación de JavaScript, le proporcionaremos el HTML sin formato y renderizado para cada página. Utilice la opción "lupa" junto a una página en Page Explorer y vaya a "Ver código fuente" en el menú. También puede comparar con rastreos anteriores y buscar en el HTML sin procesar o renderizado en todas las páginas del sitio.
Si ejecuta un rastreo sin JavaScript y luego otro con él, puede utilizar nuestras funciones de comparación de rastreo para ver las diferencias entre las versiones.
Ahrefs Barra de herramientas SEO también admite JavaScript y le permite comparar HTML con versiones renderizadas de etiquetas.
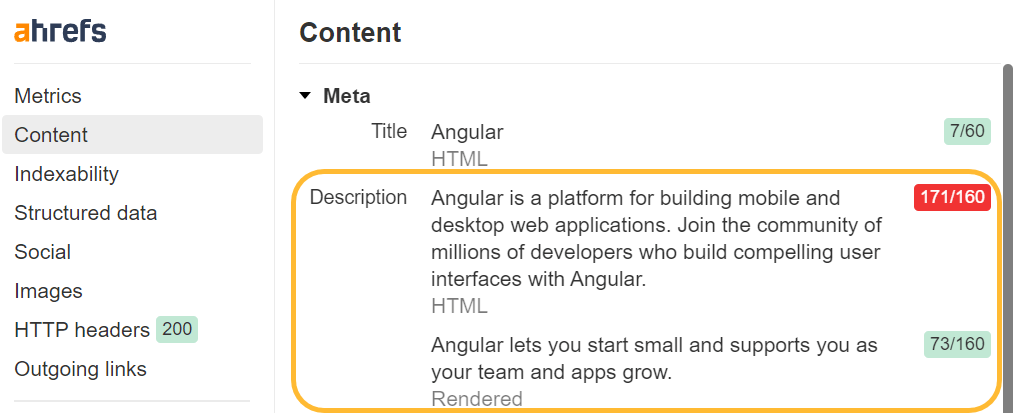
Ver fuente versus inspeccionar
Cuando hace clic derecho en una ventana del navegador, verá un par de opciones para ver el código fuente de la página y para inspeccionarla. Ver código fuente le mostrará lo mismo que lo haría una solicitud GET. Este es el HTML sin formato de la página.

Inspect le muestra el DOM procesado después de que se han realizado cambios y está más cerca del contenido que ve el robot de Google. Es la página después de que JavaScript se haya ejecutado y realizado cambios.
Deberías utilizar principalmente inspeccionar en lugar de ver el código fuente cuando trabajes con JavaScript.
A veces es necesario comprobar ver fuente
Debido a que Google analiza el HTML sin formato y el HTML renderizado para detectar algunos problemas, es posible que en ocasiones aún necesites verificar la fuente de visualización. Por ejemplo, si las herramientas de Google le indican que la página está marcada como noindex, pero no ve una etiqueta noindex en el HTML renderizado, es posible que estuviera allí en el HTML sin formato y se haya sobrescrito.
Para cosas como noindex, nofollow y etiquetas canónicas, es posible que deba verificar el HTML sin formato, ya que los problemas pueden persistir. Recuerde que Google tomará las declaraciones más restrictivas que vio para las metaetiquetas de robots e ignorará las etiquetas canónicas cuando le muestre varias etiquetas canónicas.
No navegues con JavaScript desactivado
He visto esta recomendación demasiadas veces. Google procesa JavaScript, por lo que lo que ves sin JavaScript no se parece en nada a lo que ve Google. Esto es simplemente una tontería.
No utilices la caché de Google
El caché de Google no es una forma confiable de comprobar lo que ve el robot de Google. Lo que normalmente ve en el caché es la instantánea HTML sin formato. Luego, su navegador activa el JavaScript al que se hace referencia en el HTML. No es lo que vio Google cuando mostró la página.
Para complicar aún más esto, los sitios web pueden tener sus propios Intercambio de recursos de origen cruzado (CORS) política configurada de manera que los recursos necesarios no se puedan cargar desde un dominio diferente.
El caché está alojado en webcache.googleusercontent.com. Cuando ese dominio intenta solicitar los recursos del dominio real, la política CORS dice: "No, no puedes acceder a mis archivos". Entonces los archivos no se cargan y la página parece rota en el caché.
El sistema de caché se creó para ver el contenido cuando un sitio web no funciona. No es particularmente útil como herramienta de depuración.
En los primeros días de los motores de búsqueda, una respuesta HTML descargada era suficiente para ver el contenido de la mayoría de las páginas. Gracias al auge de JavaScript, los motores de búsqueda ahora necesitan representar muchas páginas como lo haría un navegador para poder ver el contenido tal como lo ve un usuario.
El sistema que maneja el proceso de renderizado en Google se llama Servicio de renderizado web (WRS). Google ha proporcionado un diagrama simplista para cubrir cómo funciona este proceso.
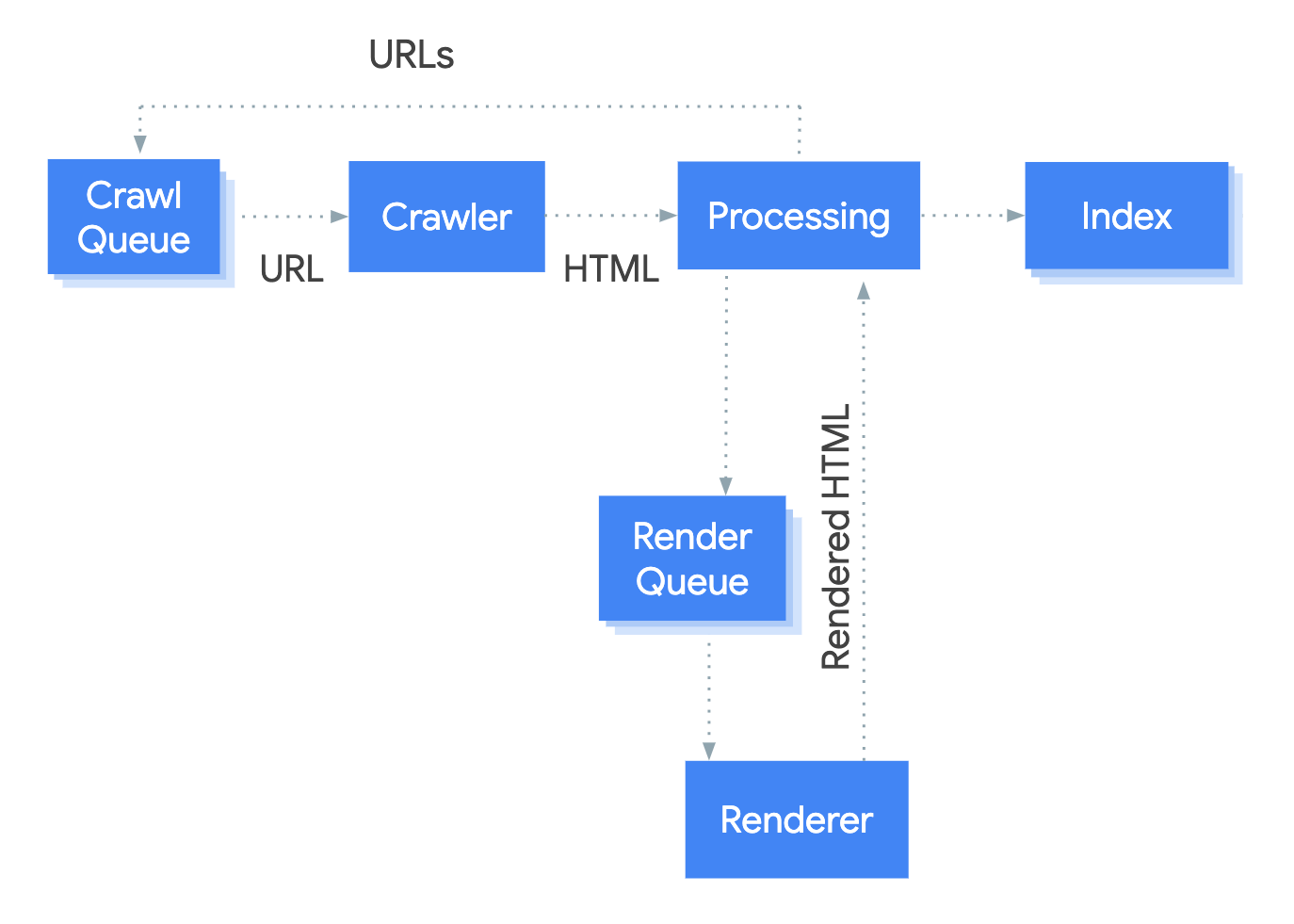
Digamos que comenzamos el proceso en la URL.
1. Rastreador
El rastreador envía solicitudes GET al servidor. El servidor responde con encabezados y el contenido del archivo, que luego se guarda. Los encabezados y el contenido suelen aparecer en la misma solicitud.
Es probable que la solicitud provenga de un agente de usuario móvil ya que Google está en indización móvil primero ahora, pero también sigue rastreando con el agente de usuario de escritorio.
Las solicitudes provienen principalmente de Mountain View (CA, EE. UU.), pero también algo de rastreo en busca de páginas que se adapten a la configuración regional fuera de los EE. UU. Como mencioné anteriormente, esto puede causar problemas si los sitios bloquean o tratan a los visitantes de un país específico de diferentes maneras.
También es importante tener en cuenta que, si bien Google indica el resultado del proceso de rastreo como "HTML" en la imagen de arriba, en realidad, está rastreando y almacenando los recursos necesarios para crear la página, como los archivos HTML, JavaScript y CSS. También hay un límite de tamaño máximo de 15 MB para archivos HTML.
2. Tratamiento
Hay muchos sistemas ofuscados por el término "Procesamiento" en la imagen. Voy a cubrir algunos de estos que son relevantes para JavaScript.
Recursos y enlaces
Google no navega de una página a otra como lo haría un usuario. Parte del "Procesamiento" es verificar la página en busca de enlaces a otras páginas y archivos necesarios para crear la página. Estos enlaces se extraen y se agregan a la cola de rastreo, que es lo que utiliza Google para priorizar y programar el rastreo.

Google extraerá enlaces de recursos (CSS, JS, etc.) necesarios para crear una página a partir de cosas como <link> las etiquetas.
Como mencioné antes, enlaces internos agregado con JavaScript no se recogerá hasta después de la renderización. Esto debería ser relativamente rápido y no ser motivo de preocupación en la mayoría de los casos. Cosas como los sitios de noticias pueden ser la excepción donde cada segundo cuenta.
Almacenamiento en caché
Cada archivo que descargue Google, incluidas páginas HTML, archivos JavaScript, archivos CSS, etc., se almacenará en caché de forma agresiva. Google ignorará los tiempos de caché y buscará una nueva copia cuando así lo desee. Hablaré un poco más sobre esto y por qué es importante en la sección "Renderizador".
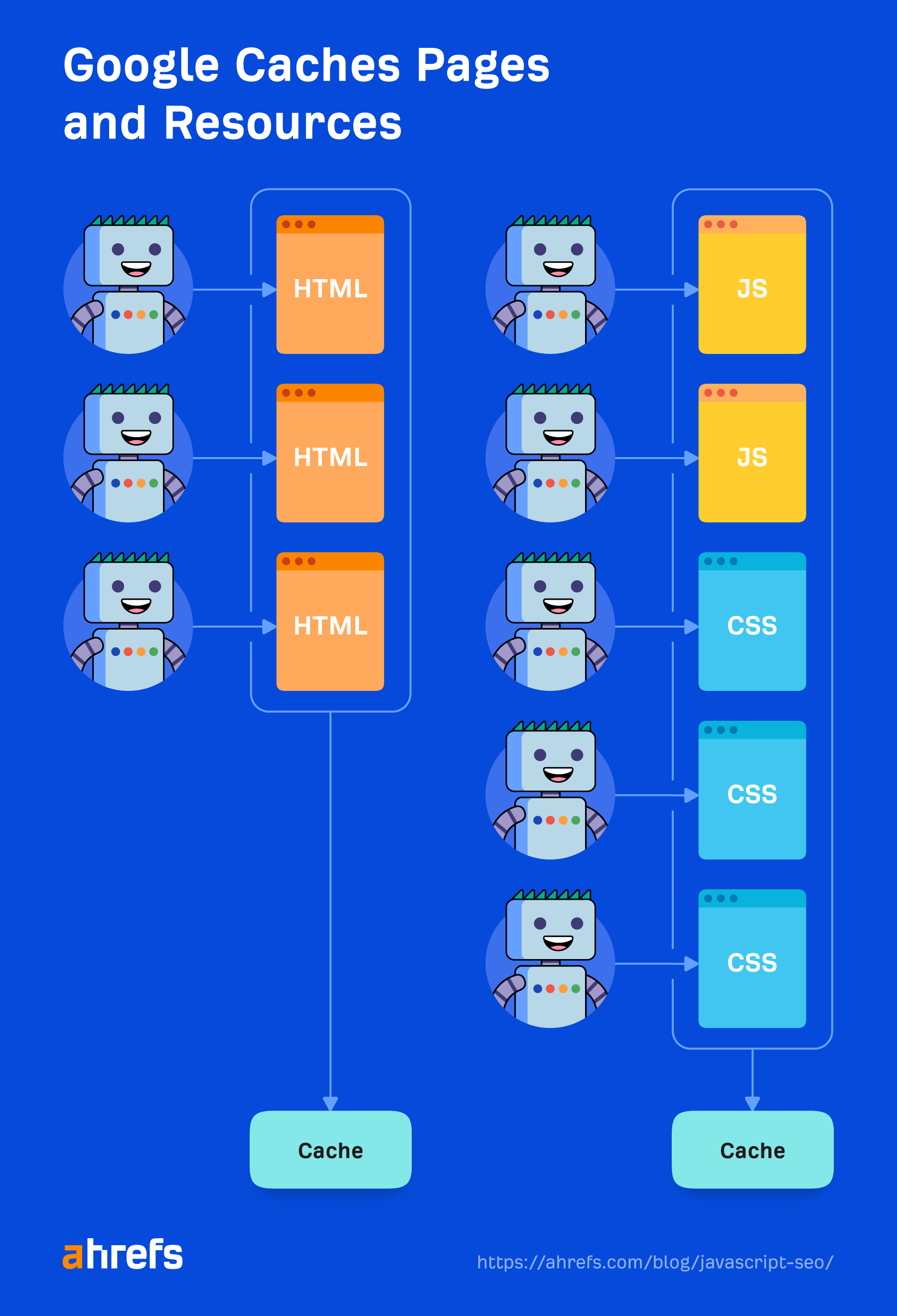
Eliminación de duplicados
El contenido duplicado se puede eliminar o quitar prioridad del HTML descargado antes de enviarlo a renderizado. Ya hablé de esto en la sección "Contenido duplicado" anterior.
Directivas más restrictivas
Como mencioné anteriormente, Google elegirá la más restrictiva. declaraciones entre HTML y la versión renderizada de una página. Si JavaScript cambia una declaración y eso entra en conflicto con la declaración de HTML, Google simplemente obedecerá la que sea más restrictiva. Noindex anulará el índice y noindex en HTML omitirá la representación por completo.
3. Cola de renderizado
Una de las mayores preocupaciones de muchos SEO con JavaScript y la indexación en dos etapas (HTML y luego página renderizada) es que es posible que las páginas no se representen durante días o incluso semanas. Cuando Google investigó esto, encontró las páginas llegaron al renderizador en un tiempo medio de cinco segundos, y el percentil 90 fueron minutos. Por lo tanto, la cantidad de tiempo entre la obtención del HTML y la representación de las páginas no debería ser una preocupación en la mayoría de los casos.
Sin embargo, Google no muestra todas las páginas. Como mencioné anteriormente, una página con una metaetiqueta robots o un encabezado que contenga una etiqueta noindex no se enviará al renderizador. No desperdiciará recursos al generar una página que no puede indexar de todos modos.
También cuenta con controles de calidad en este proceso. Si analiza el HTML o puede determinar razonablemente a partir de otras señales o patrones que una página no tiene la calidad suficiente para indexar, entonces no se molestará en enviarla al renderizador.
También hay una peculiaridad con los sitios de noticias. Google quiere indexar páginas en sitios de noticias rápidamente para poder indexar las páginas basándose primero en el contenido HTML y volver más tarde para representarlas.
4. renderizador
El renderizador es donde Google representa una página para ver lo que ve un usuario. Aquí es donde procesará JavaScript y cualquier cambio realizado por JavaScript en el DOM.
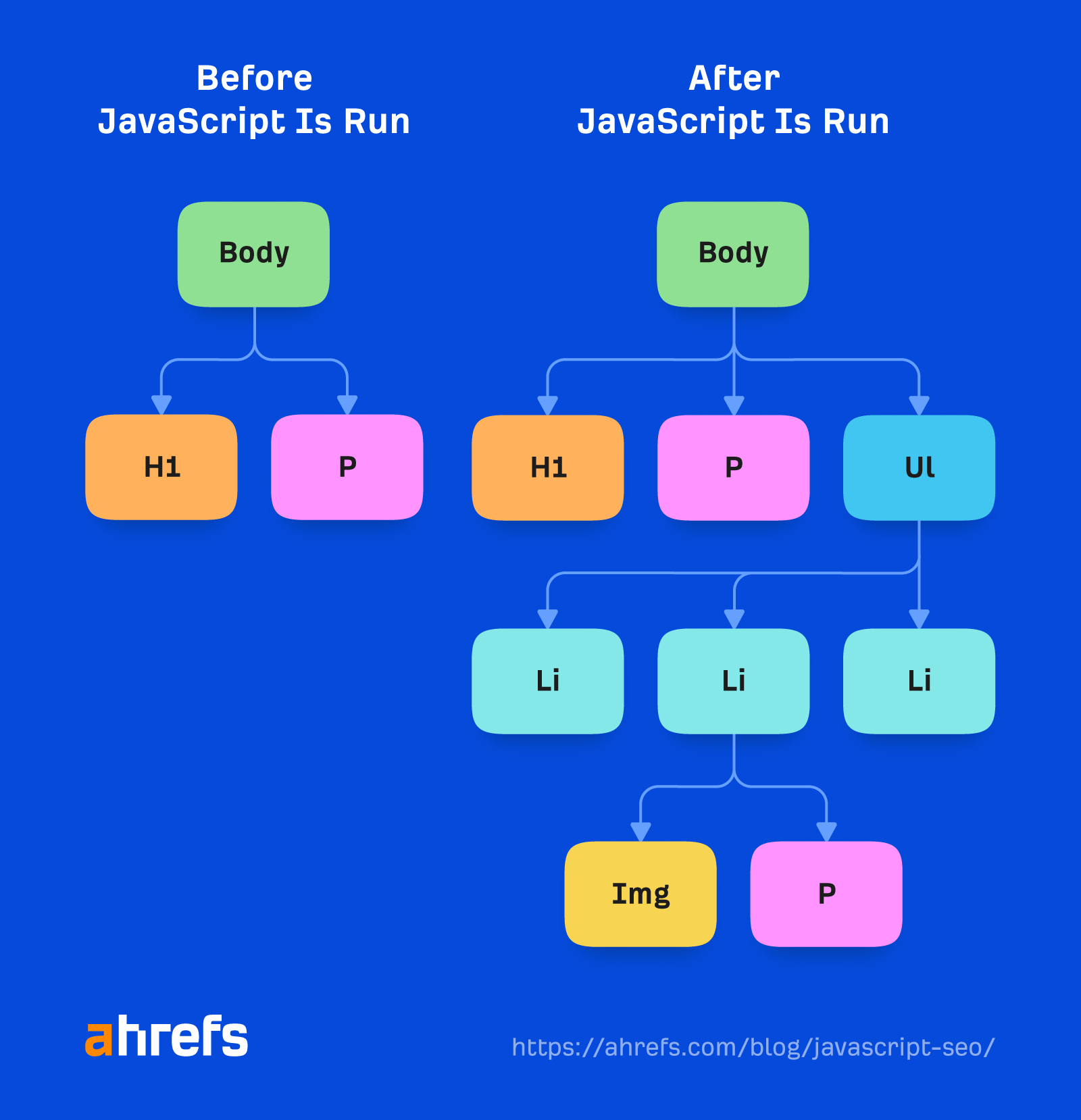
Para ello, Google está utilizando un navegador Chrome sin cabeza que ahora es "imperecedero", lo que significa que debe utilizar la última versión de Chrome y admitir las últimas funciones. Hace años, Google renderizaba con Chrome 41 y muchas funciones no eran compatibles en ese momento.
Google tiene más información sobre el WRS, que incluye cosas como denegar permisos, ser apátrida, aplanar DOM claro y DOM sombra, y más que vale la pena leer.
El renderizado a escala web puede ser la octava maravilla del mundo. Es una tarea seria y requiere una enorme cantidad de recursos. Debido a la escala, Google está tomando muchos atajos en el proceso de renderizado para acelerar las cosas.
Recursos almacenados en caché
Google depende en gran medida de los recursos de almacenamiento en caché. Las páginas se almacenan en caché. Los archivos se almacenan en caché. Casi todo se almacena en caché antes de enviarse al renderizador. No se trata de descargar cada recurso para cada carga de página, porque eso sería costoso para él y para los propietarios de sitios web. En cambio, utiliza estos recursos almacenados en caché para ser más eficiente.
La excepción son las solicitudes XHR, que el renderizador realizará en tiempo real.
No hay tiempo de espera de cinco segundos
Un mito común del SEO es que Google sólo espera cinco segundos para cargar su página. Si bien siempre es una buena idea hacer que su sitio sea más rápido, este mito realmente no tiene sentido con la forma en que Google almacena en caché los archivos mencionados anteriormente. Ya está cargando una página con todo lo almacenado en caché en sus sistemas, sin realizar solicitudes de recursos nuevos.
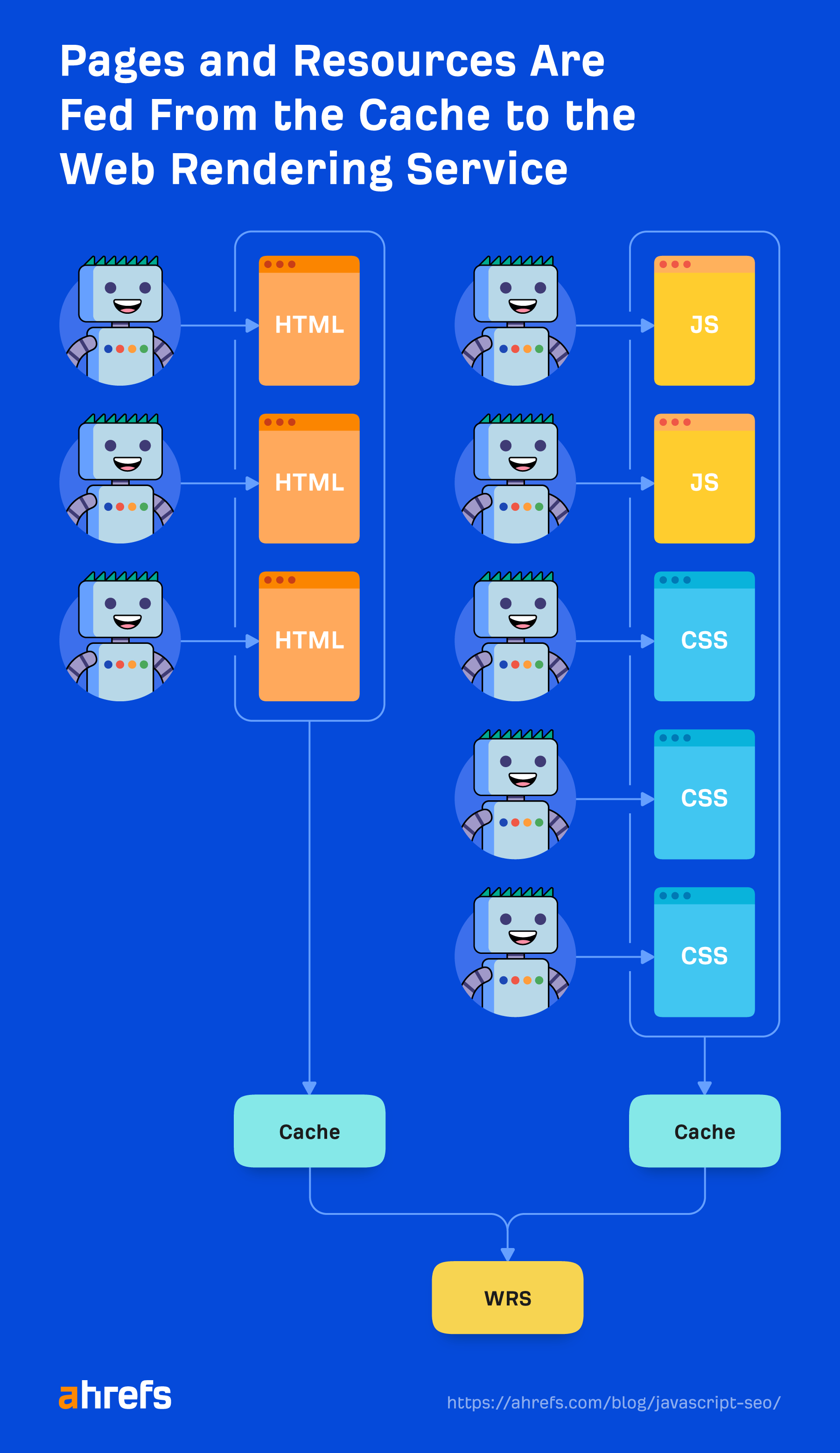
Si solo esperara cinco segundos, se perdería mucho contenido.
El mito probablemente proviene de herramientas de prueba como la herramienta de inspección de URL, donde los recursos se obtienen en vivo en lugar de almacenarse en caché y deben devolver un resultado a los usuarios dentro de un período de tiempo razonable. También podría deberse a que las páginas no tienen prioridad para el rastreo, lo que hace que las personas piensen que están esperando mucho tiempo para procesarlas e indexarlas.
No hay un tiempo de espera fijo para el renderizador. Se ejecuta con un temporizador acelerado para ver si se agrega algo más adelante. También analiza el bucle de eventos en el navegador para ver cuándo se han realizado todas las acciones. Es muy paciente y no debes preocuparte por ningún límite de tiempo específico.
Es paciente, pero también cuenta con salvaguardias en caso de que algo se atasque o alguien intente extraer Bitcoin en sus páginas. Sí, es una cosa. También tuvimos que agregar salvaguardias para la minería de Bitcoin e incluso publicó un estudio al respecto.
Lo que ve el robot de Google
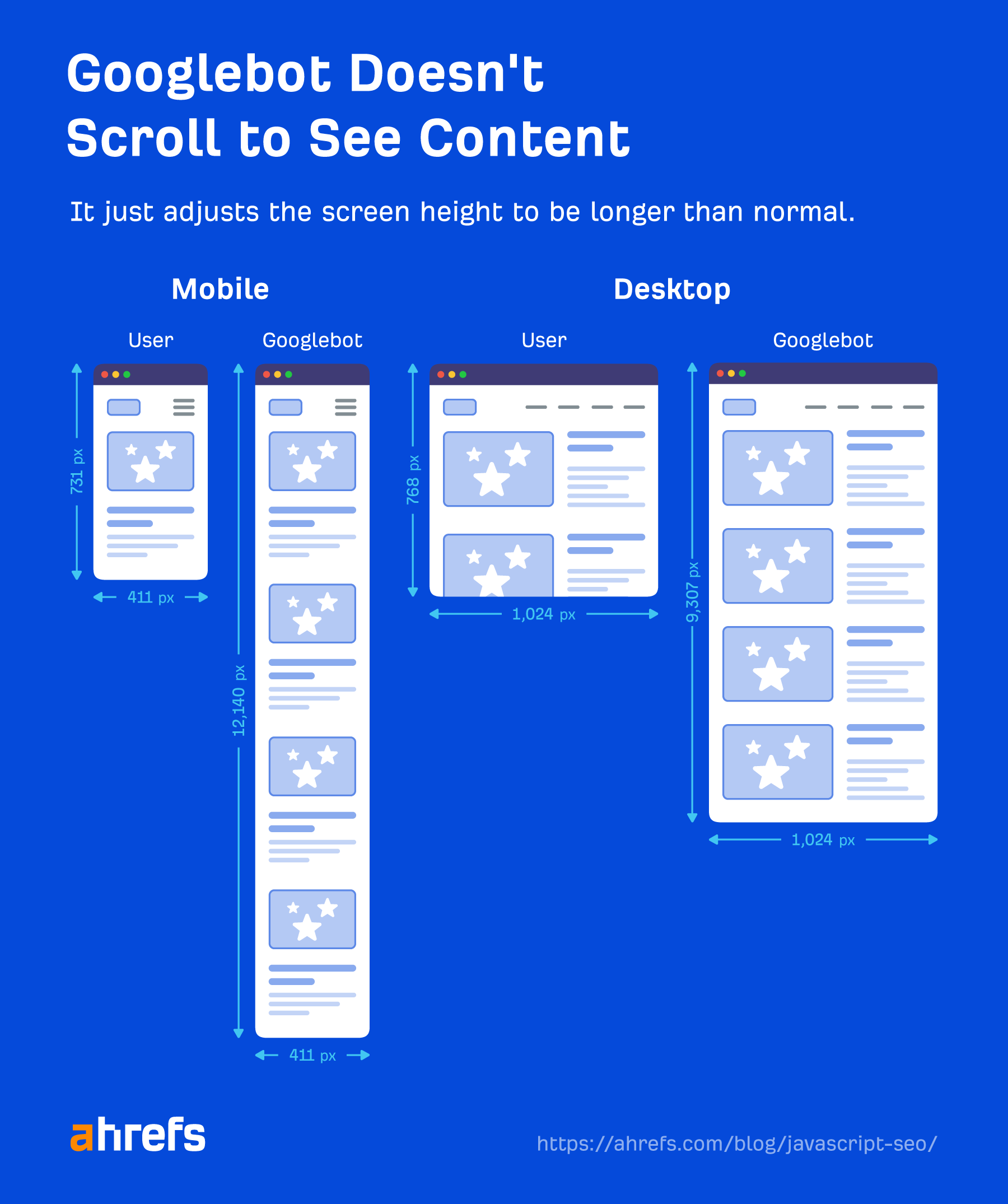
El robot de Google no realiza ninguna acción en las páginas web. No hará clic en elementos ni se desplazará, pero eso no significa que no tenga soluciones alternativas. Mientras el contenido se cargue en el DOM sin una acción necesaria, Google lo verá. Si no se carga en el DOM hasta después de hacer clic, no se encontrará el contenido.
Google tampoco necesita desplazarse para ver su contenido porque tiene una solución alternativa inteligente para verlo. Para dispositivos móviles, carga la página con un tamaño de pantalla de 411×731 píxeles y cambia el tamaño de la longitud a 12,140 píxeles.
Básicamente, se convierte en un teléfono realmente largo con un tamaño de pantalla de 411×12140 píxeles. Para escritorio hace lo mismo y pasa de 1024×768 píxeles a 1024×9307 píxeles. No he visto ninguna prueba reciente para estos números y puede cambiar dependiendo de la longitud de las páginas.
Otro atajo interesante es que Google no pinta los píxeles durante el proceso de renderizado. Se necesita tiempo y recursos adicionales para finalizar la carga de una página y realmente no es necesario ver el estado final con los píxeles pintados. Además, las tarjetas gráficas son caras entre los juegos, la minería de criptomonedas y la inteligencia artificial.
Google sólo necesita conocer la estructura y el diseño, y lo consigue sin tener que pintar los píxeles. Como Martin lo pone:
En la búsqueda de Google realmente no nos importan los píxeles porque realmente no queremos mostrárselos a nadie. Queremos procesar la información y la información semántica, por lo que necesitamos algo en el estado intermedio. En realidad, no tenemos que pintar los píxeles.
Una imagen puede ayudar a explicar un poco mejor lo que se recorta. En Chrome Dev Tools, si ejecuta una prueba en la pestaña "Rendimiento", obtendrá un gráfico de carga. La parte verde sólida aquí representa la etapa de pintura. Para Googlebot, eso nunca sucede, por lo que ahorra recursos.

Gris = Descargas
Azul =HTML
Amarillo = JavaScript
Morado = Diseño
Verde = Pintura
5. Cola de rastreo
Google tiene un recurso que habla un poco sobre el presupuesto de rastreo. Pero debe saber que cada sitio tiene su propio presupuesto de rastreo y que se debe priorizar cada solicitud. Google también tiene que equilibrar el rastreo de sus páginas con el de cualquier otra página de Internet.
Los sitios más nuevos en general o los sitios con muchas páginas dinámicas probablemente se rastrearán más lentamente. Algunas páginas se actualizarán con menos frecuencia que otras y es posible que algunos recursos también se soliciten con menos frecuencia.
Hay muchas opciones cuando se trata de renderizar JavaScript. Google tiene un gráfico sólido que voy a mostrar. Cualquier tipo de configuración de SSR, renderizado estático y prerenderizado estará bien para los motores de búsqueda. Gatsby, Next, Nuxt, etc., son geniales.

El más problemático será el renderizado completo del lado del cliente, donde todo el renderizado se realiza en el navegador. Si bien Google probablemente aceptará la renderización del lado del cliente, es mejor elegir una opción de renderización diferente para admitir otras motores de búsqueda.
Bing también tiene soporte para renderizado de JavaScript, pero se desconoce la escala. Yandex y Baidu tienen soporte limitado por lo que he visto, y muchos otros motores de búsqueda tienen poco o ningún soporte para JavaScript. Nuestro propio motor de búsqueda, Sí, tiene soporte y renderizamos ~200 millones de páginas por día. Pero no representamos todas las páginas que rastreamos.
También está la opción de representación dinámica, que se renderiza para ciertos agentes de usuario. Esta es una solución alternativa y, para ser honesto, nunca la recomendé y me alegro de que Google también la desaconseje ahora.
Situacionalmente, es posible que quieras usarlo para renderizar ciertos bots, como motores de búsqueda o incluso bots de redes sociales. Los robots de redes sociales no ejecutan JavaScript, por lo que cosas como Etiquetas OG no se verá a menos que renderice el contenido antes de entregárselo.
En la práctica, hace que las configuraciones sean más complejas y más difíciles de solucionar para los SEO. Definitivamente es cloaking, aunque Google dice que no lo es y que está de acuerdo.
Note
Si estuvieras usando el viejo Esquema de rastreo AJAX con hashbangs (#!), sepa que esto ha quedado obsoleto y ya no es compatible.
Reflexiones finales
JavaScript no es algo que los SEO deban temer. Con suerte, este artículo le ha ayudado a comprender cómo trabajar mejor con él.
No tenga miedo de comunicarse con sus desarrolladores, trabajar con ellos y hacerles preguntas. Serán sus mayores aliados para ayudarlo a mejorar su sitio JavaScript para los motores de búsqueda.
¿Tiene preguntas? Hágamelo saber en Twitter.
Seguí leyendo
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://ahrefs.com/blog/javascript-seo/

