“Los datos están en el centro de cada aplicación, proceso y decisión comercial. Cuando los datos se utilizan para mejorar las experiencias de los clientes e impulsar la innovación, pueden generar crecimiento empresarial”.
– Swami Sivasubramanian, vicepresidente de bases de datos, análisis y aprendizaje automático en AWS en Con un enfoque de ETL cero, AWS ayuda a los constructores a realizar análisis casi en tiempo real.
Los clientes de todas las industrias se basan cada vez más en los datos y buscan aumentar los ingresos, reducir los costos y optimizar sus operaciones comerciales mediante la implementación de análisis casi en tiempo real de los datos transaccionales, mejorando así la agilidad. Basándose en las necesidades de los clientes y sus comentarios, AWS está invirtiendo y progresando constantemente para hacer realidad nuestra visión de ETL cero para que los constructores puedan centrarse más en crear valor a partir de los datos, en lugar de prepararlos para el análisis.
Nuestra oficina de ETL cero integración con Desplazamiento al rojo de Amazon facilita el movimiento de datos punto a punto para prepararlos para análisis, inteligencia artificial (IA) y aprendizaje automático (ML) utilizando Amazon Redshift en petabytes de datos. A los pocos segundos de escribir los datos transaccionales apoyadas Las bases de datos de AWS, zero-ETL, hacen que los datos estén disponibles sin problemas en Amazon Redshift, lo que elimina la necesidad de crear y mantener canales de datos complejos que realizan operaciones de extracción, transformación y carga (ETL).
Para ayudarle a centrarse en crear valor a partir de los datos en lugar de invertir tiempo y recursos indiferenciados en crear y gestionar canales de ETL entre bases de datos transaccionales y almacenes de datos, le ofrecemos anunció cuatro integraciones de ETL cero de bases de datos de AWS con Amazon Redshift en AWS re:Invent 2023:
En esta publicación, brindamos orientación paso a paso sobre cómo comenzar con análisis operativos casi en tiempo real utilizando Integración de ETL cero de Amazon Aurora PostgreSQL con Amazon Redshift.
Resumen de la solución
Para crear una integración ETL cero, especifique un Edición compatible con Amazon Aurora PostgreSQL clúster (compatible con PostgreSQL 15.4 y soporte zero-ETL) como origen y un almacén de datos Redshift como destino. La integración replica datos de la base de datos de origen en el almacén de datos de destino.
Debe crear clústeres aprovisionados de base de datos de Aurora PostgreSQL dentro del Entorno de vista previa de la base de datos de Amazon RDS y un corrimiento al rojo clúster de vista previa aprovisionado or grupo de trabajo de vista previa sin servidor, en la región AWS de EE. UU. Este (Ohio). Para Amazon Redshift, asegúrese de elegir la ruta de vista previa_2023 para poder utilizar integraciones de ETL cero.
El siguiente diagrama ilustra la arquitectura implementada en esta publicación.
Los siguientes son los pasos necesarios para configurar la integración ETL cero para esta solución. Para obtener guías completas de introducción, consulte Trabajar con integraciones Aurora zero-ETL con Amazon Redshift y Trabajar con integraciones de ETL cero.
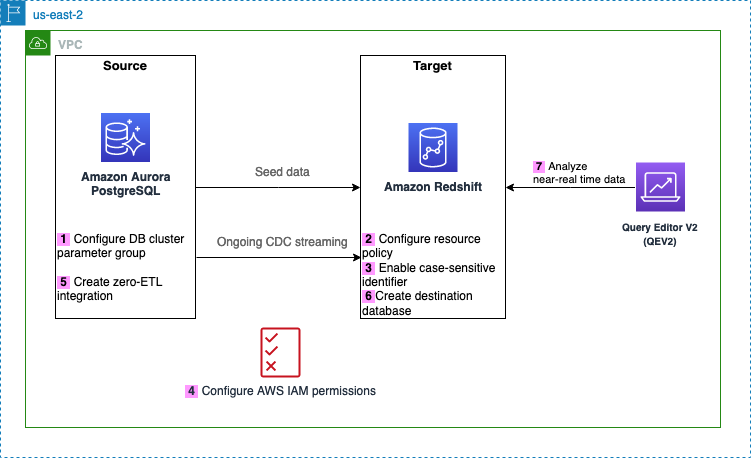
Después del Paso 1, también puede omitir los Pasos 2 a 4 y comenzar directamente a crear su integración ETL cero desde el Paso 5, en cuyo caso Amazon RDS mostrará un mensaje sobre las configuraciones faltantes y podrá elegir Arréglalo por mí para permitir que Amazon RDS configure automáticamente los pasos.
- Configure el origen de Aurora PostgreSQL con un grupo de parámetros de clúster de base de datos personalizado.
- Configura el Amazon Redshift sin servidor destino con la política de recursos requerida para su espacio de nombres.
- Actualice el grupo de trabajo de Redshift Serverless para habilitar los identificadores que distinguen entre mayúsculas y minúsculas.
- Configure los permisos necesarios.
- Cree la integración de ETL cero.
- Cree una base de datos a partir de la integración en Amazon Redshift.
- Comience a analizar los datos transaccionales casi en tiempo real.
Configure el origen de Aurora PostgreSQL con un grupo de parámetros de clúster de base de datos personalizado
Para los clústeres de base de datos de Aurora PostgreSQL, debe crear el grupo de parámetros personalizados dentro del Entorno de vista previa de la base de datos de Amazon RDS, en la región este de EE. UU. (Ohio). Puede acceder directamente al entorno de vista previa de Amazon RDS.
Para crear una base de datos Aurora PostgreSQL, complete los siguientes pasos:
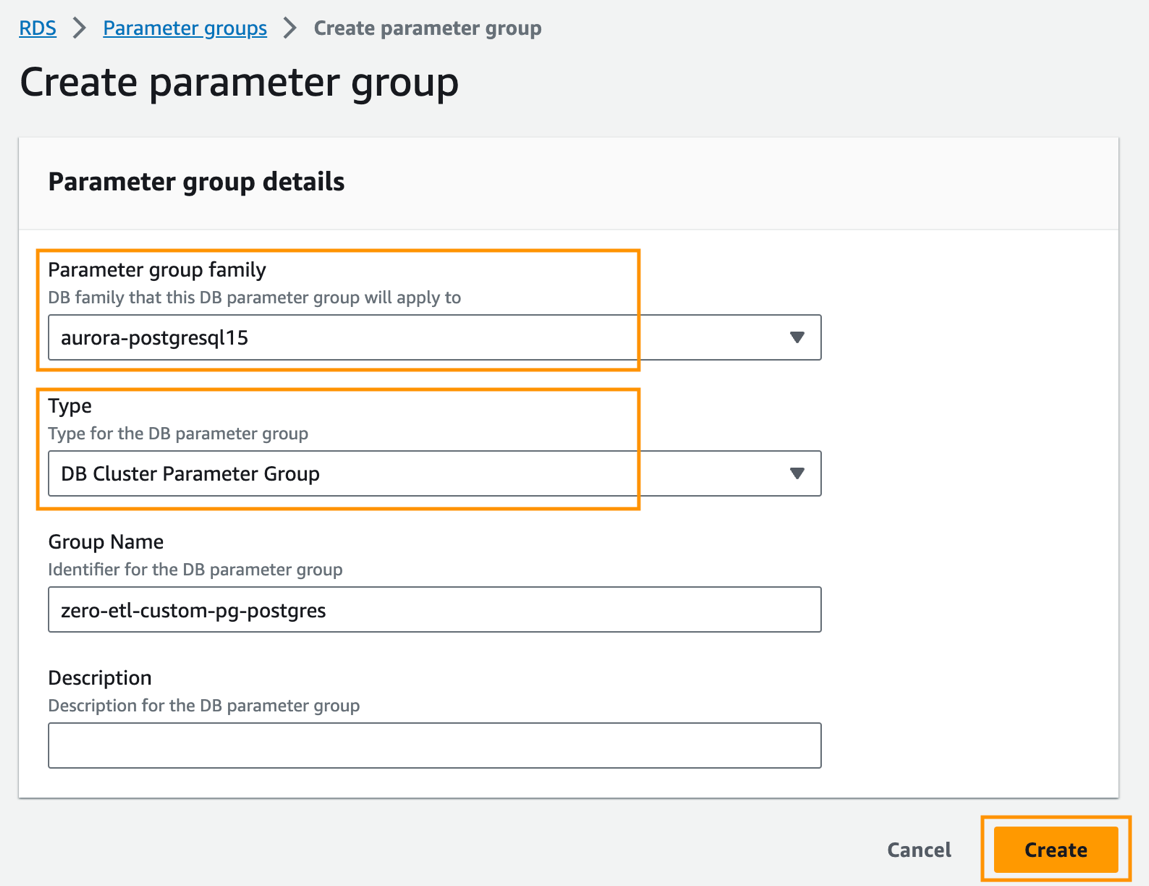
- En la consola de Amazon RDS, elija Grupos de parámetros en el panel de navegación.
- Elige Crear grupo de parámetros.
- Familia de grupos de parámetros, escoger
aurora-postgresql15. - Tipo de Propiedad, escoger
DB Cluster Parameter Group. - Nombre del grupo, ingrese un nombre (por ejemplo,
zero-etl-custom-pg-postgres). - Elige Crear.
Las integraciones ETL cero de Aurora PostgreSQL con Amazon Redshift requieren valores específicos para el Parámetros del clúster de base de datos Aurora, que requiere replicación lógica mejorada (aurora.enhanced_logic_replication).
- En Grupos de parámetros página, seleccione el grupo de parámetros recién creado.
- En Acciones menú, seleccione Editar.
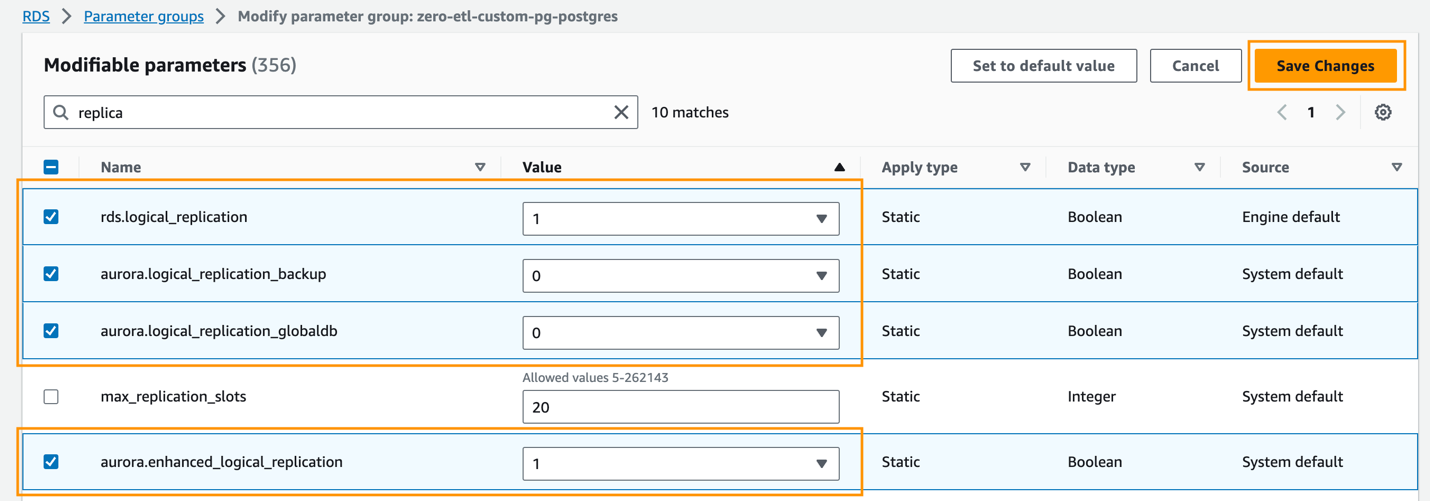
- Configure lo siguiente Aurora PostgreSQL (familia aurora-postgresql15) configuración de parámetros del clúster:
rds.logical_replication=1aurora.enhanced_logical_replication=1aurora.logical_replication_backup=0aurora.logical_replication_globaldb=0
Al habilitar la replicación lógica mejorada (aurora.enhanced_logic_replication) se establece automáticamente el parámetro REPLICA IDENTITY en FULL, lo que significa que todos los valores de las columnas se escriben en el registro de escritura anticipada (WAL).
- Elige Guardar Cambios.
- Elige Bases de datos en el panel de navegación, luego elija Crear base de datos.

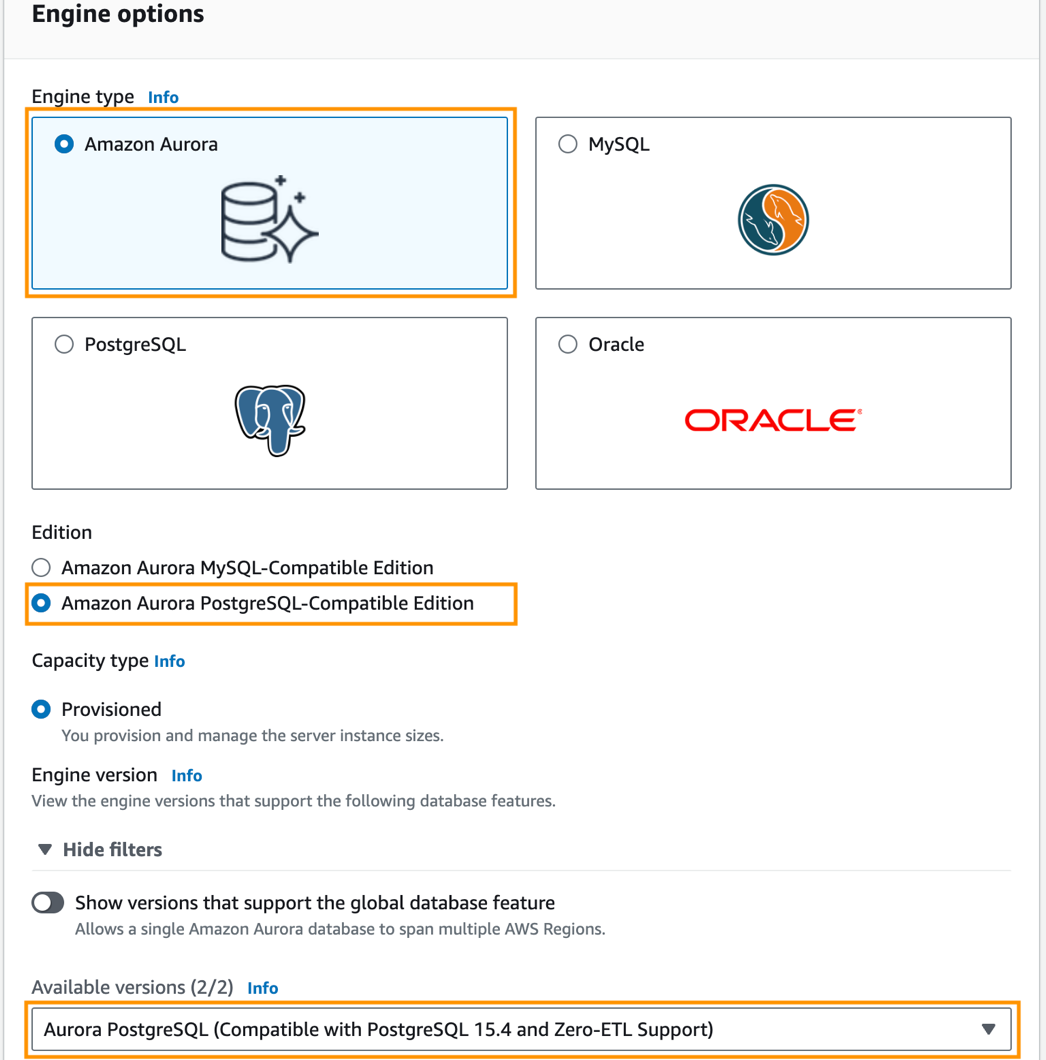
- Tipo de motor, seleccione Aurora amazónica.
- Edición, seleccione Edición compatible con Amazon Aurora PostgreSQL.
- Versiones disponibles, escoger Aurora PostgreSQL (compatible con PostgreSQL 15.4 y soporte Zero-ETL).
- Plantillas, seleccione Producción.
- Identificador de clúster de base de datos, introduzca
zero-etl-source-pg.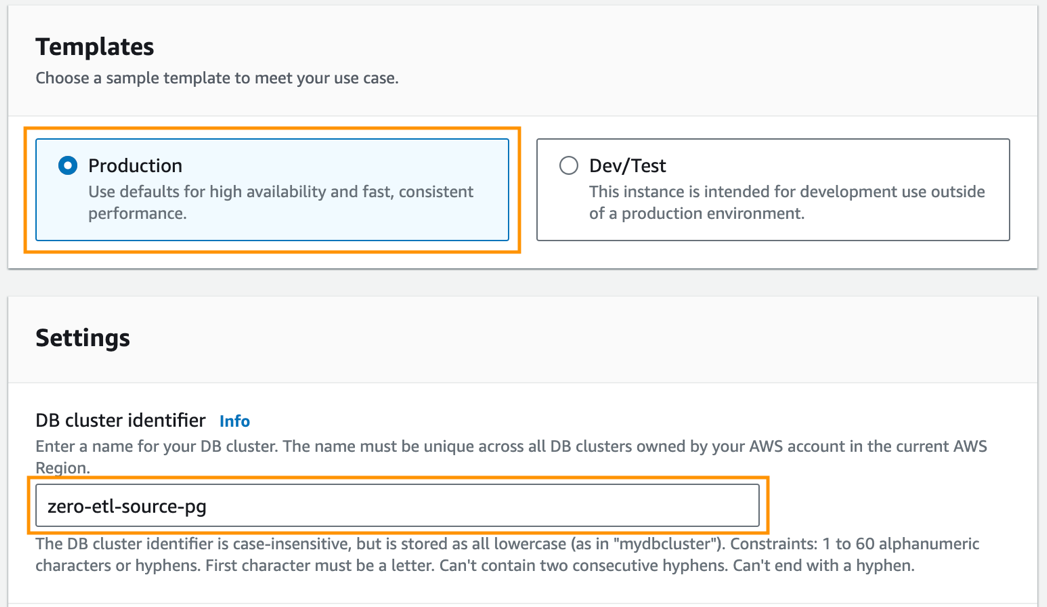
- under Configuración de credenciales, introduzca una contraseña para Contraseña maestra o utilice la opción para generar automáticamente una contraseña para usted.
- En Sección de configuración de instancia, seleccione Clases optimizadas para memoria.
- Elija un tamaño de instancia adecuado (el valor predeterminado es
db.r5.2xlarge).
- under Configuración adicional, Para Grupo de parámetros de clúster de base de datos, elija el grupo de parámetros que creó anteriormente (
zero-etl-custom-pg-postgres).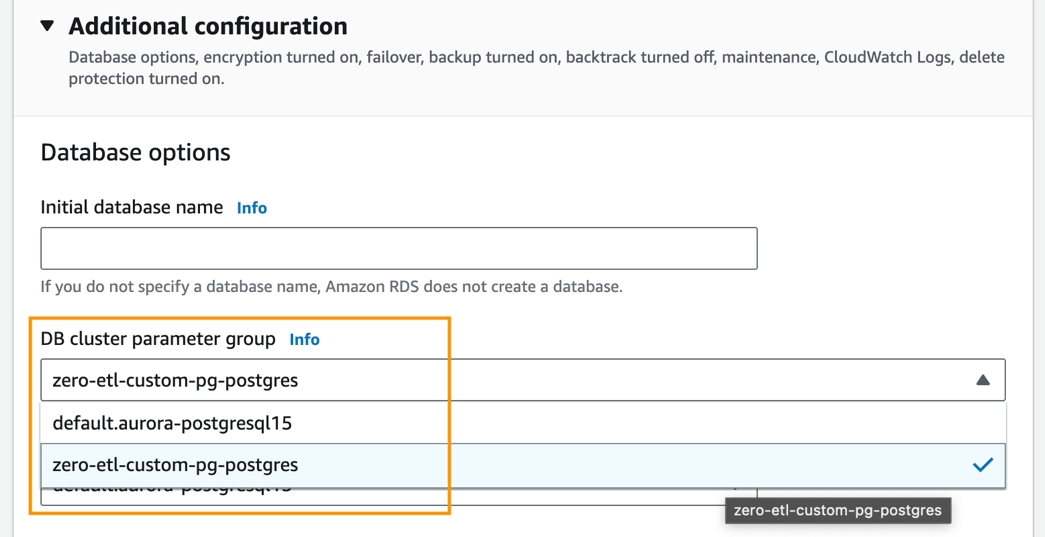
- Deje la configuración predeterminada para las configuraciones restantes.
- Elige Crear base de datos.
En unos minutos, esto debería activar un clúster de Aurora PostgreSQL, con una instancia de escritor y una de lector, con el estado cambiando de Creamos a Disponible. El clúster Aurora PostgreSQL recién creado será la fuente para la integración ETL cero.
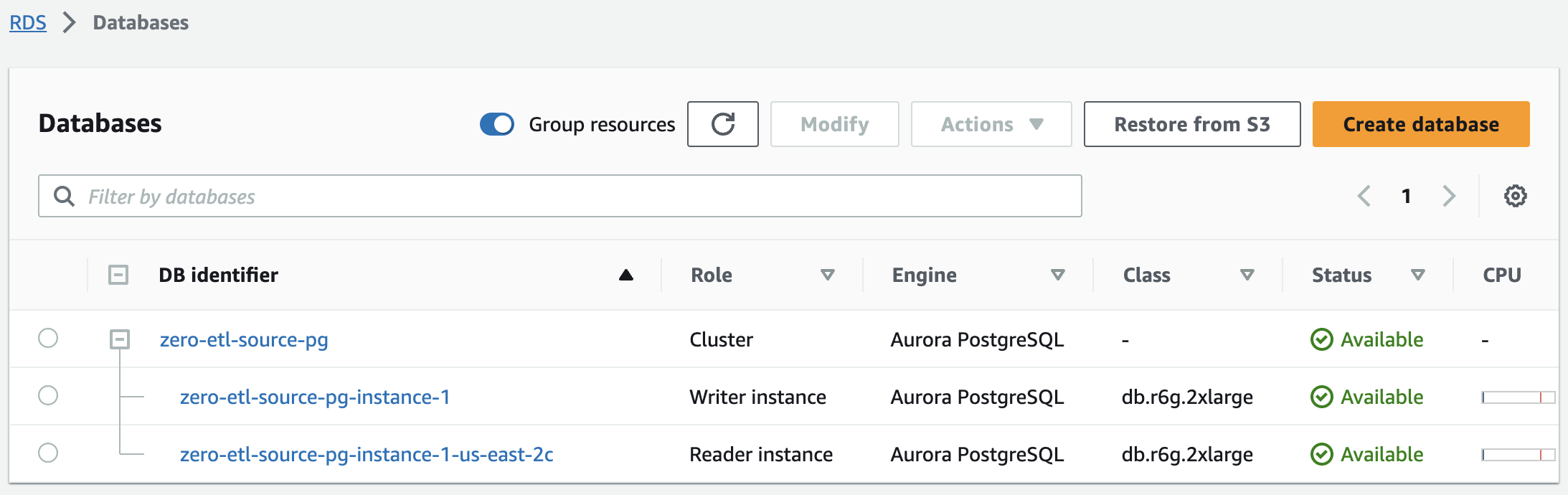
El siguiente paso es crear una base de datos con nombre en Amazon Aurora PostgreSQL para la integración ETL cero.
El modelo de recursos de PostgreSQL le permite crear múltiples bases de datos dentro de un clúster. Por lo tanto, durante el paso de creación de la integración ETL cero, debe especificar qué base de datos desea utilizar como fuente para su integración.
Al configurar PostgreSQL, obtienes tres bases de datos estándar listas para usar: plantilla0, plantilla1 y postgres. Cada vez que crea una nueva base de datos en PostgreSQL, en realidad la está basando en una de estas tres bases de datos en su clúster. La base de datos creada durante la creación del clúster Aurora PostgreSQL se basa en template0. El CREATE DATABASE El comando funciona copiando una base de datos existente y, si no se especifica explícitamente, de forma predeterminada, copia la plantilla de base de datos estándar del sistema1. Para la base de datos nombrada para la integración de ETL cero, es necesario crear la base de datos utilizando la plantilla1 y no la plantilla0. Por lo tanto, si se agrega un nombre de base de datos inicial en Configuración adicional, que se crearía usando template0 y no se puede usar para la integración ETL cero.
- Para crear una nueva base de datos con nombre usando
CREATE DATABASEdentro del nuevo clúster Aurora PostgreSQLzero-etl-source-pg, primero obtenga el punto final de la instancia del escritor del clúster de PostgreSQL.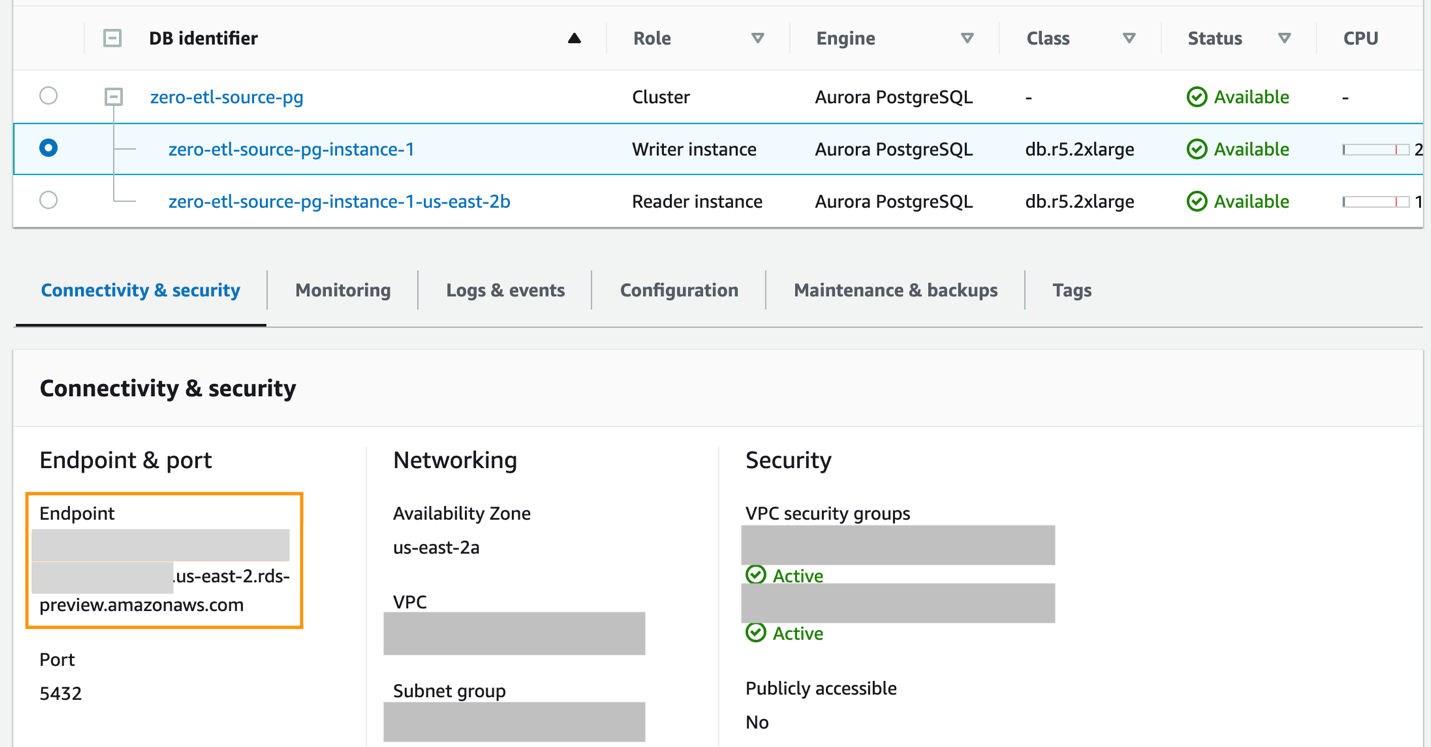
- Desde una terminal o usando AWS CloudShell, SSH en el clúster de PostgreSQL y ejecute los siguientes comandos para instalar psql y crear una nueva base de datos
zeroetl_db:
Adición template template1 es opcional, porque por defecto, si no se menciona, CREATE DATABASE utilizará template1.
También puede conectarse a través de un cliente y crear la base de datos. Referirse a Conéctese a un clúster de base de datos de Aurora PostgreSQL para ver las opciones para conectarse al clúster de PostgreSQL.
Configurar Redshift Serverless como destino
Después de crear su clúster de base de datos de origen Aurora PostgreSQL, configure un almacén de datos de destino de Redshift. El almacén de datos debe cumplir con los siguientes requisitos:
- Creado en vista previa (solo para fuentes Aurora PostgreSQL)
- Utiliza un tipo de nodo RA3 (ra3.16xlarge, ra3.4xlarge o ra3.xlplus) con al menos dos nodos, o Redshift Serverless
- Cifrado (si se utiliza un clúster aprovisionado)
Para esta publicación, creamos y configuramos un grupo de trabajo y un espacio de nombres de Redshift Serverless como almacén de datos de destino, siguiendo estos pasos:
- En la consola de Amazon Redshift, elija Tablero sin servidor en el panel de navegación.
Debido a que la integración de ETL cero para Amazon Aurora PostgreSQL con Amazon Redshift se lanzó en versión preliminar (no para fines de producción), es necesario crear el almacén de datos de destino en un entorno de versión preliminar.
- Elige Crear grupo de trabajo de vista previa.
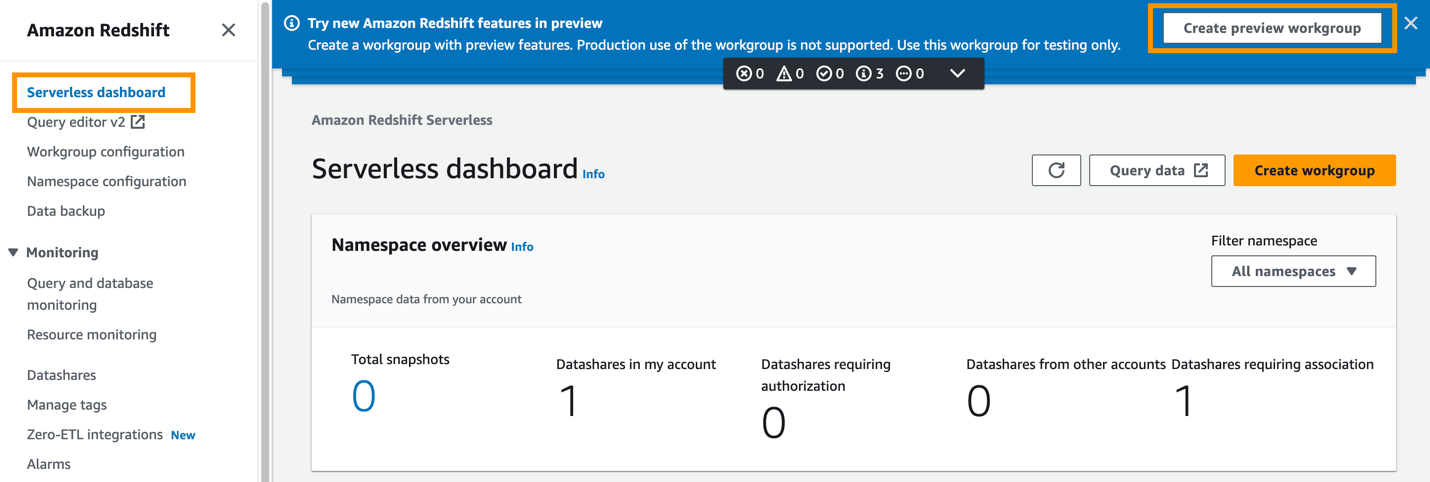
El primer paso es configurar el grupo de trabajo Redshift Serverless.
- Nombre del grupo de trabajo, ingrese un nombre (por ejemplo,
zero-etl-target-rs-wg).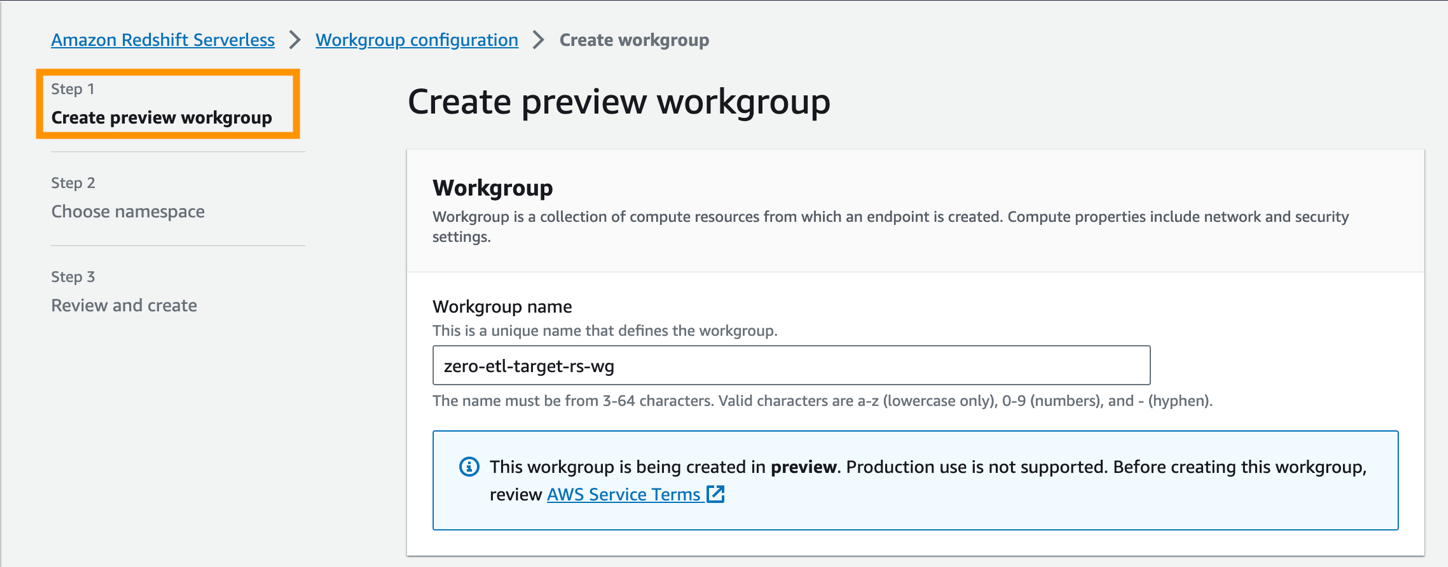
- Además, puede elegir la capacidad para limitar los recursos informáticos del almacén de datos. La capacidad se puede configurar en incrementos de 8, de 8 a 512 RPU. Para esta publicación, configúrelo en
8RPU. - Elige Siguiente.

A continuación, debe configurar el espacio de nombres del almacén de datos.
- Seleccione Crea un nuevo espacio de nombres.
- Espacio de nombres, ingrese un nombre (por ejemplo,
zero-etl-target-rs-ns). - Elige Siguiente.
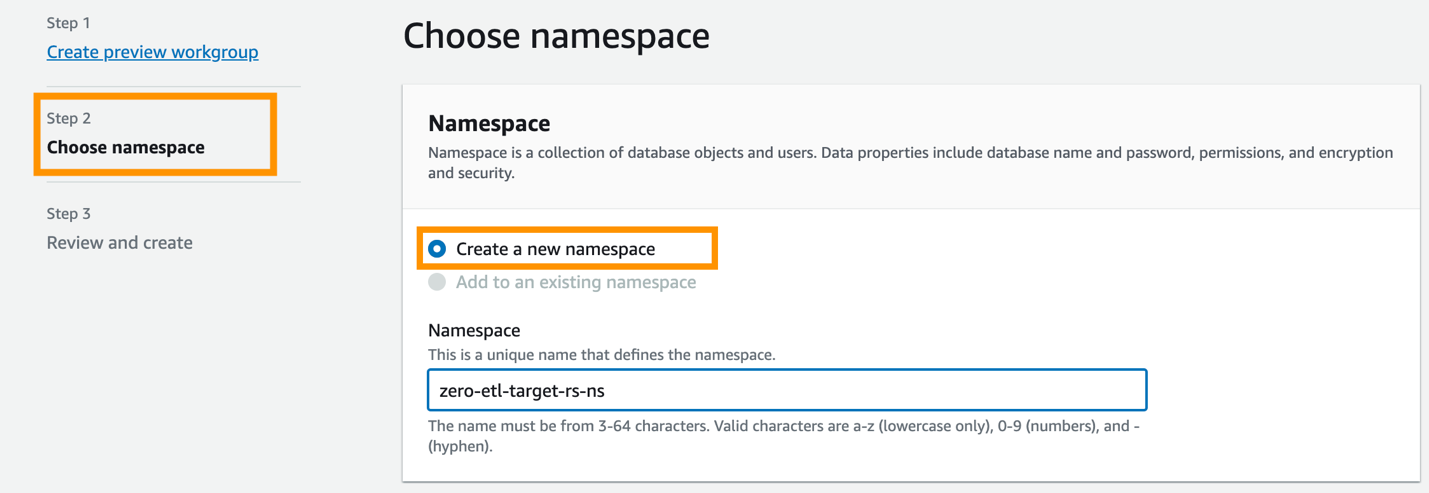
- Elige Crear grupo de trabajo.
- Después de crear el grupo de trabajo y el espacio de nombres, elija Configuraciones de espacio de nombres en el panel de navegación y abra la configuración del espacio de nombres.
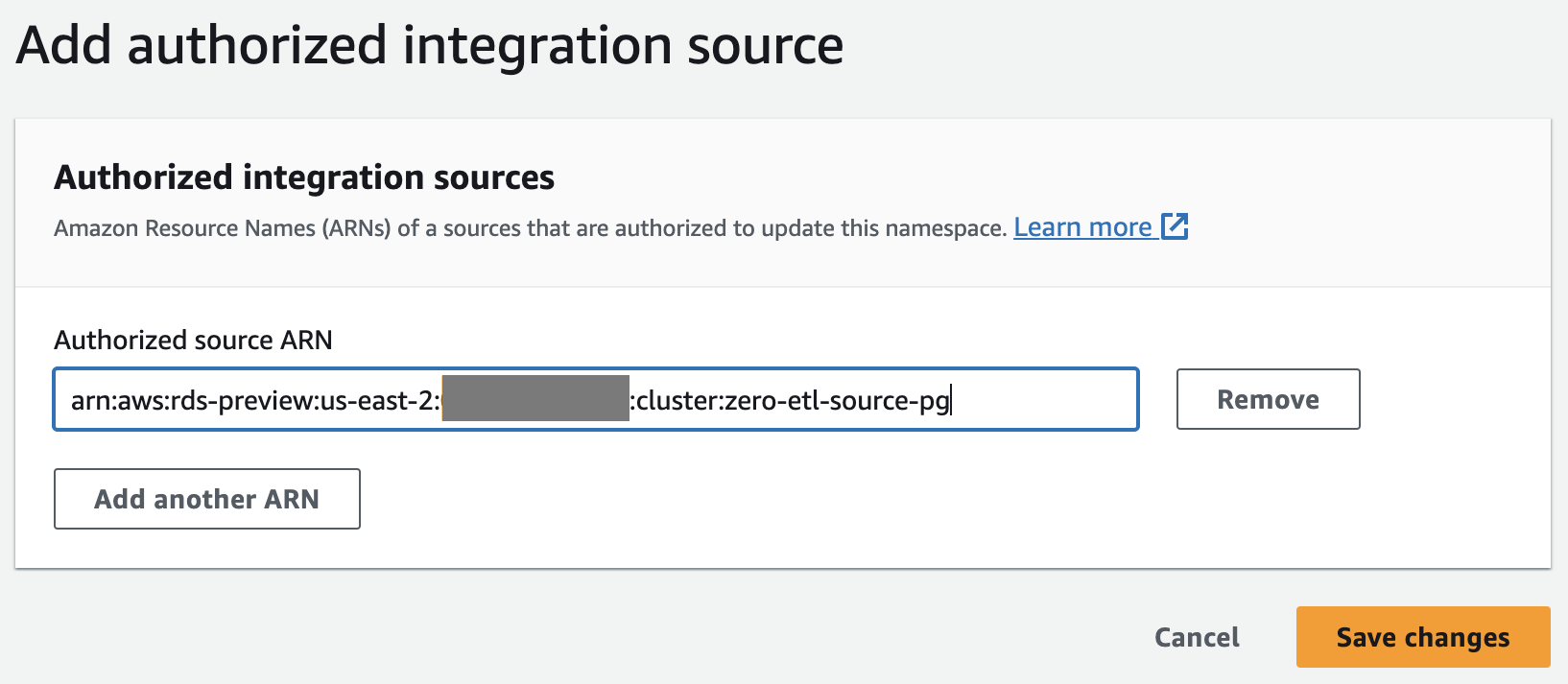
- En Política de recursos pestaña, elegir Agregar principales autorizados.
Un principal autorizado identifica el usuario o rol que puede crear integraciones sin ETL en el almacén de datos.

- ARN principal de IAM o ID de cuenta de AWS, puede ingresar el ARN del usuario o rol de AWS o el ID de la cuenta de AWS a la que desea otorgar acceso para crear integraciones sin ETL. (Un ID de cuenta se almacena como un ARN).
- Elige Guardar los cambios.
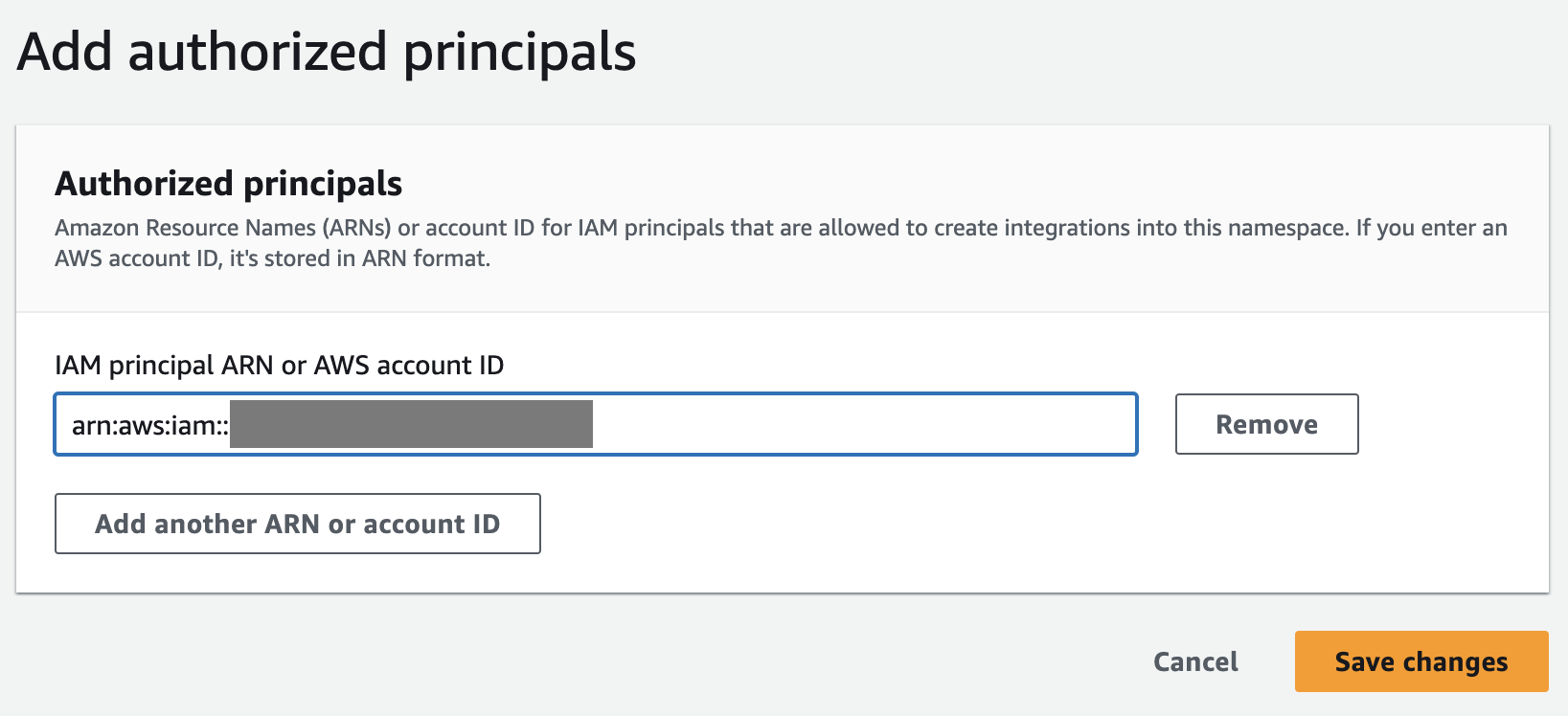
Una vez configurado el principal autorizado, debe permitir que la base de datos de origen actualice su almacén de datos de Redshift. Por lo tanto, debe agregar la base de datos de origen como fuente de integración autorizada al espacio de nombres.
- Elige Agregar fuente de integración autorizada.
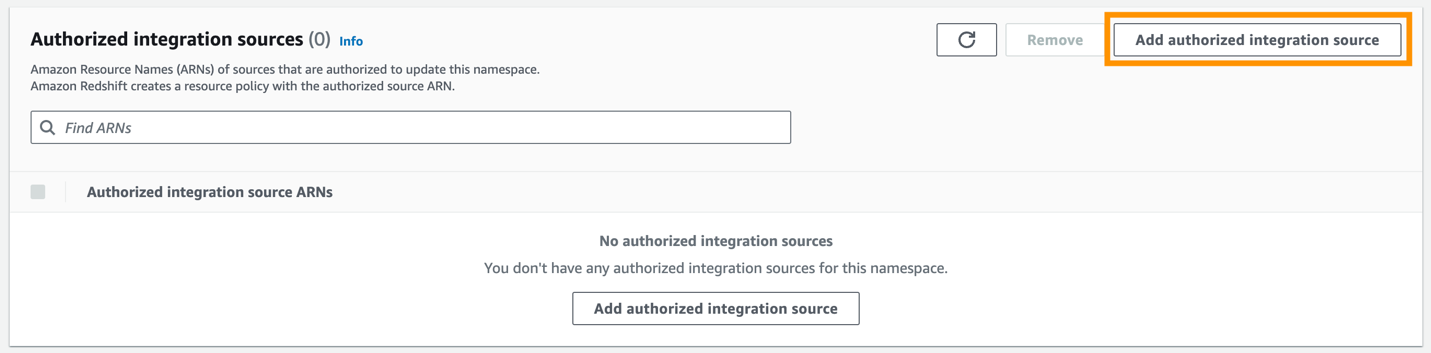
- ARN de origen autorizado, ingrese el ARN del clúster de Aurora PostgreSQL, porque es el origen de la integración de ETL cero.
Puede obtener el ARN del clúster de Aurora PostgreSQL en la consola de Amazon RDS, el Configuración lengüeta debajo Nombre de recurso de Amazon.
- Elige Guardar los cambios.
Actualizar el grupo de trabajo de Redshift Serverless para habilitar los identificadores que distinguen entre mayúsculas y minúsculas
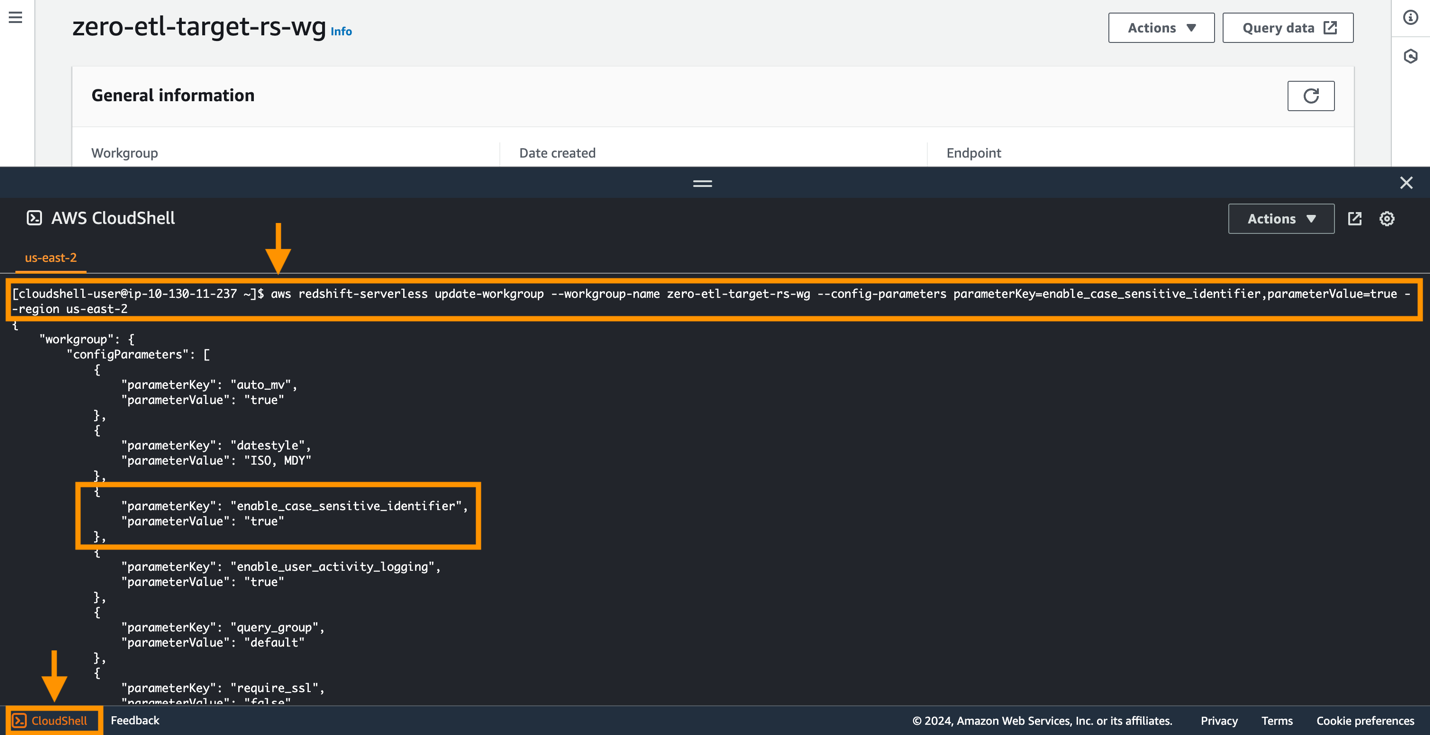
Amazon Aurora PostgreSQL distingue entre mayúsculas y minúsculas de forma predeterminada y está deshabilitada en todos los clústeres aprovisionados y grupos de trabajo Redshift Serverless. Para que la integración sea exitosa, el parámetro de distinción entre mayúsculas y minúsculas enable_case_SENSITIVE_IDENTIFICADOR debe estar habilitado para el almacén de datos.
Para modificar el enable_case_sensitive_identifier parámetro en un grupo de trabajo Redshift Serverless, debe utilizar el Interfaz de línea de comandos de AWS (AWS CLI), porque la consola de Amazon Redshift actualmente no admite la modificación de los valores de los parámetros de Redshift Serverless. Ejecute el siguiente comando para actualizar el parámetro:
Una forma sencilla de conectarse a la CLI de AWS es utilizar CloudShell, que es un shell basado en navegador que proporciona acceso de línea de comandos a los recursos y herramientas de AWS directamente desde un navegador. La siguiente captura de pantalla ilustra cómo ejecutar el comando en CloudShell.
Configurar los permisos necesarios
Para crear una integración de ETL cero, su usuario o función debe tener un adjunto política basada en la identidad con el apropiado Gestión de identidades y accesos de AWS (IAM) permisos. El propietario de una cuenta de AWS puede configurar los permisos requeridos para usuarios o roles que pueden crear integraciones sin ETL. La política de ejemplo permite que el principal asociado realice las siguientes acciones:
- Cree integraciones sin ETL para el clúster de base de datos de Aurora de origen.
- Ver y eliminar todas las integraciones de cero ETL.
- Cree integraciones entrantes en el almacén de datos de destino. Amazon Redshift tiene un formato de ARN diferente para aprovisionado y sin servidor:
- Clúster aprovisionado –
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - Sin servidor –
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
Este permiso no es necesario si la misma cuenta es propietaria del almacén de datos de Redshift y esta cuenta es una entidad principal autorizada para ese almacén de datos.
Complete los siguientes pasos para configurar los permisos:
- En la consola de IAM, elija Políticas internas en el panel de navegación.
- Elige Crear política.
- Cree una nueva política llamada rds-integrations usando el siguiente JSON. Para la vista previa de Amazon Aurora PostgreSQL, todos los ARN y acciones dentro del Entorno de vista previa de la base de datos de Amazon RDS tener -preview agregado al espacio de nombres del servicio. Por lo tanto, en la siguiente política, en lugar de rds, debe utilizar
rds-preview. Por ejemplo,rds-preview:CreateIntegration.
- Adjunte la política que creó a sus permisos de rol o usuario de IAM.
Crear la integración de ETL cero
Para crear la integración de ETL cero, complete los siguientes pasos:
- En la consola de Amazon RDS, elija Integraciones de ETL cero en el panel de navegación.
- Elige Cree una integración sin ETL.
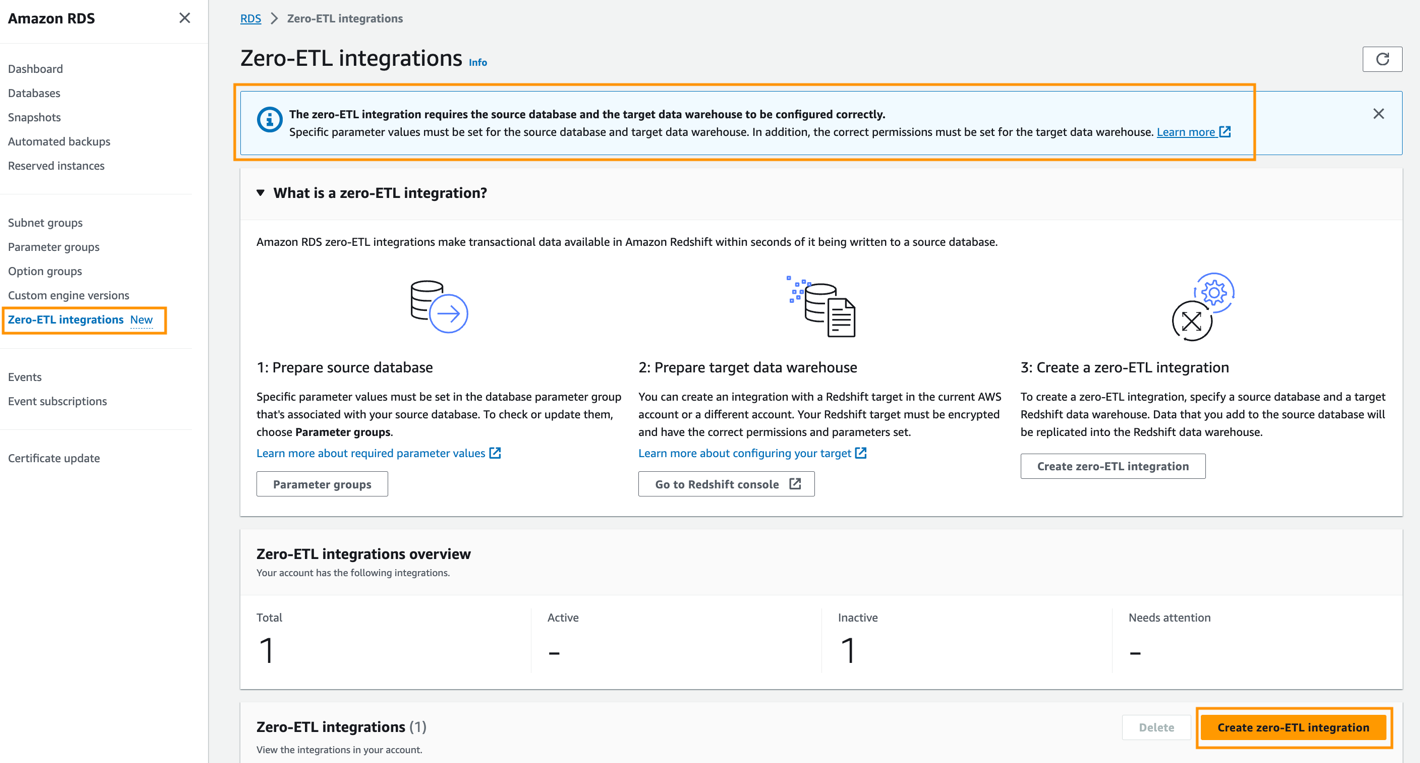
- Identificador de integración, introduzca un nombre, por ejemplo
zero-etl-demo. - Elige Siguiente.

- Base de datos de origen, escoger Explorar bases de datos RDS.
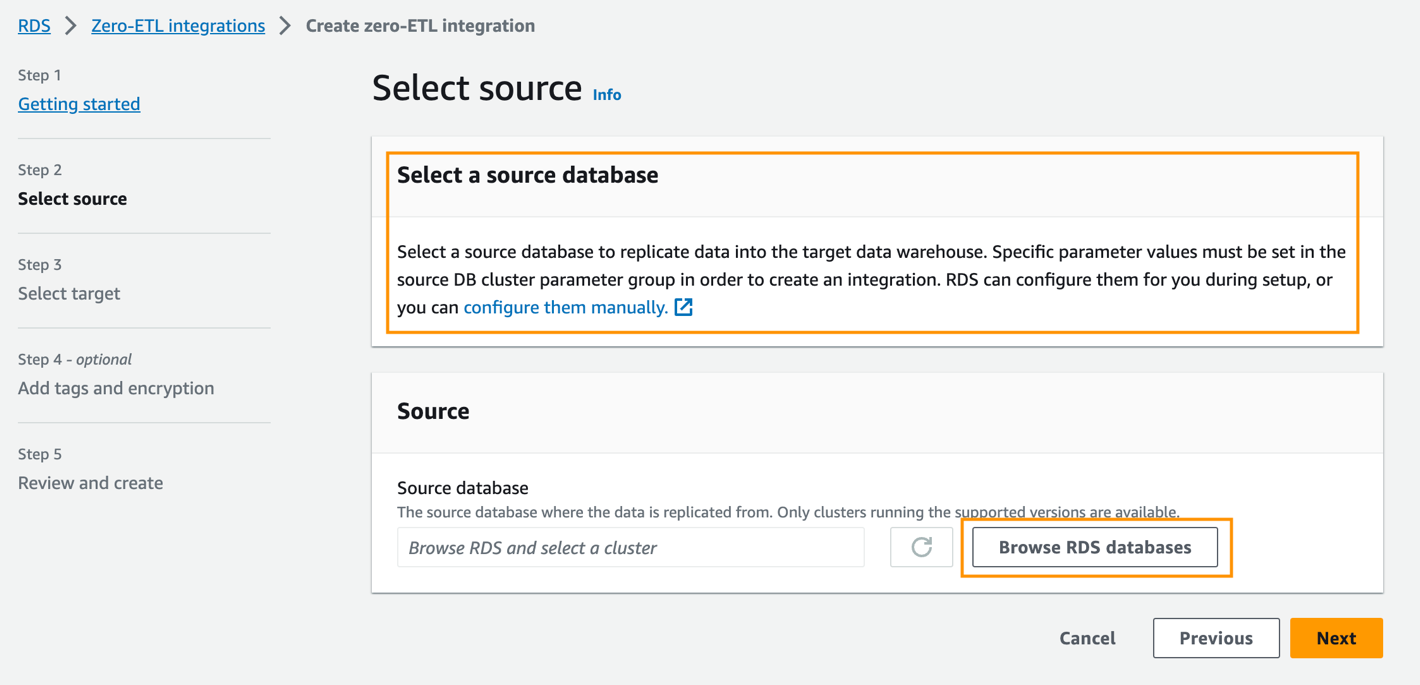
- Seleccione la base de datos de origen
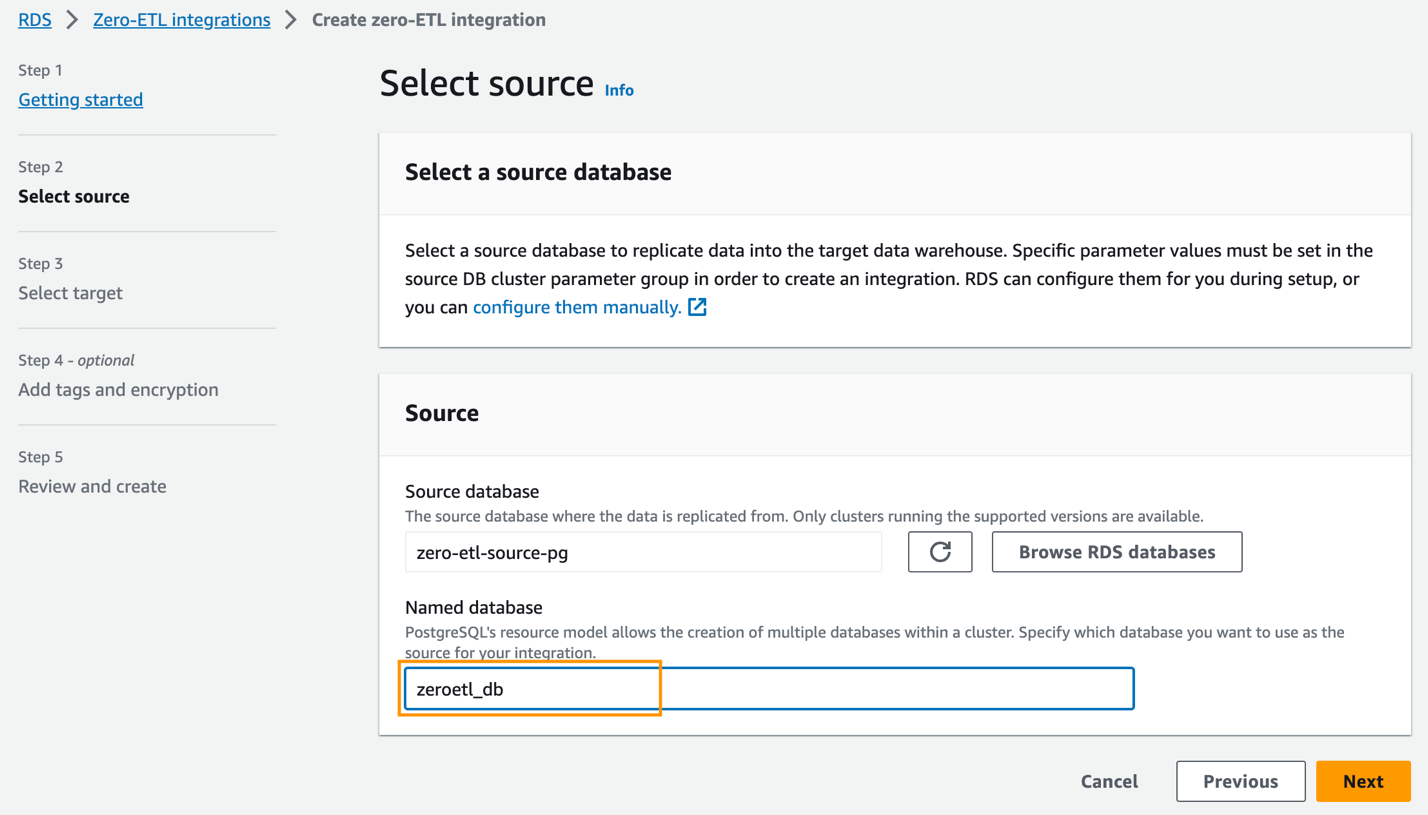
zero-etl-source-pgy elige Elige. - Base de datos nombrada, ingrese el nombre de la nueva base de datos creada en Amazon Aurora PostgreSQL (
zeroetl-db). - Elige Siguiente.
- En Sección de destino, Para Cuenta de AWS, seleccione Usa la cuenta corriente.
- Almacén de datos de Amazon Redshift, escoger Explore los almacenes de datos de Redshift.

Discutimos el Especificar una cuenta diferente opción más adelante en esta sección.
- Seleccione el espacio de nombres de destino de Redshift Serverless (
zero-etl-target-rs-ns), y elige Elige.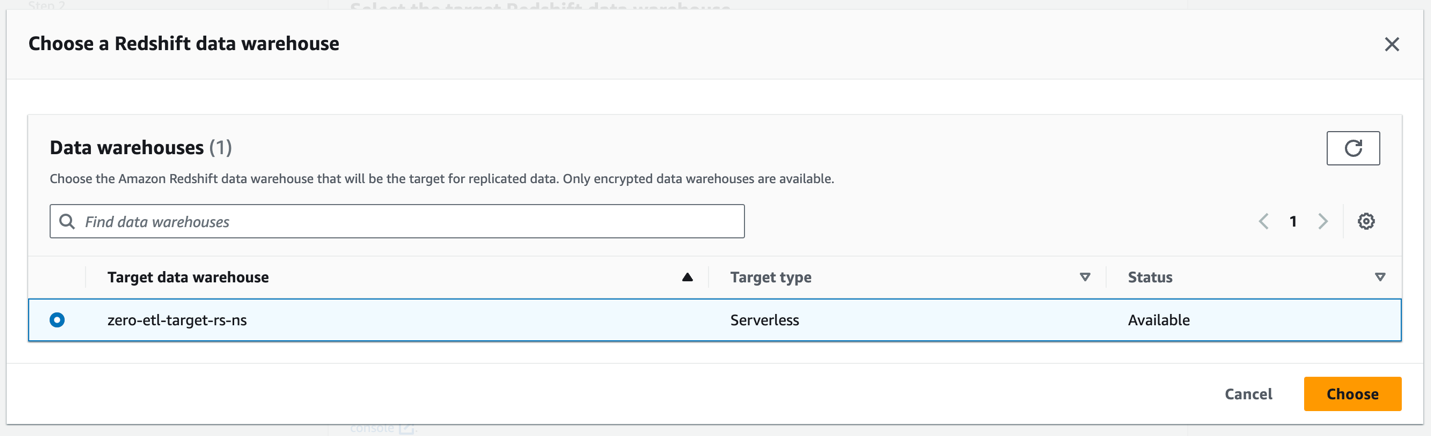
- Agregue etiquetas y cifrado, si corresponde, y elija Siguiente.
- Verifique el nombre de la integración, el origen, el destino y otras configuraciones, y elija Cree una integración sin ETL.
Puede elegir la integración en la consola de Amazon RDS para ver los detalles y monitorear su progreso. Se necesitan unos 30 minutos para cambiar el estado de Creamos a Active, dependiendo del tamaño del conjunto de datos ya disponible en la fuente.
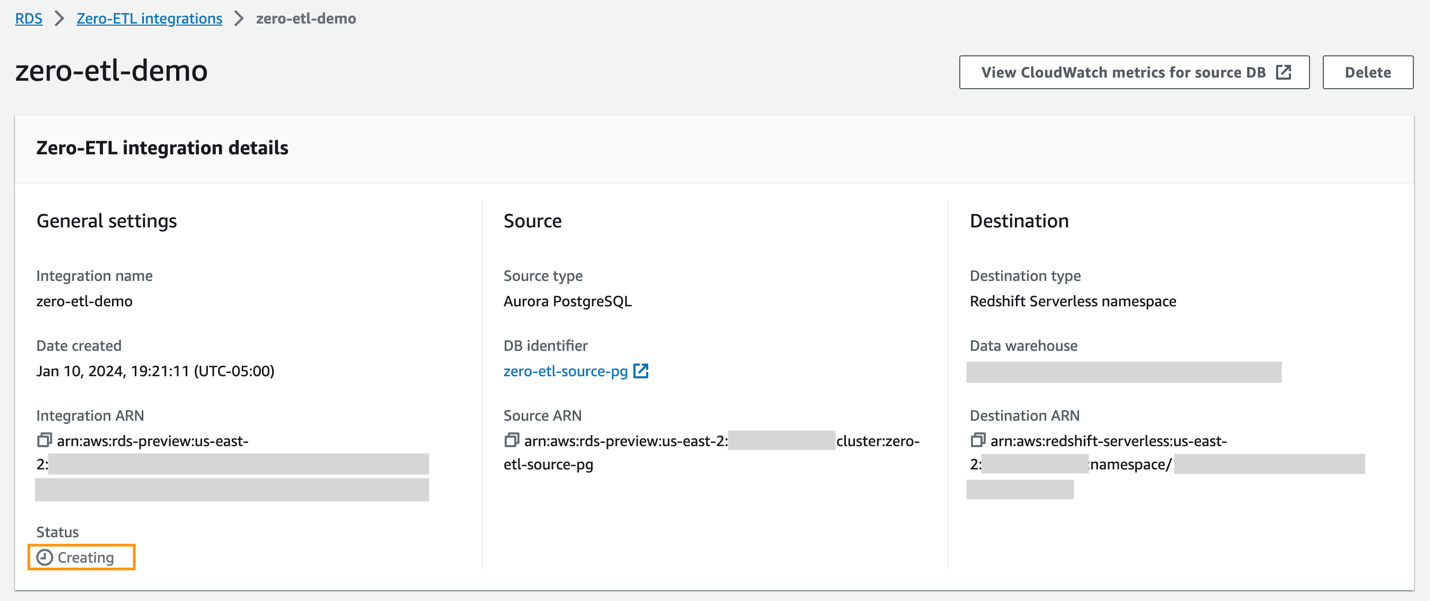
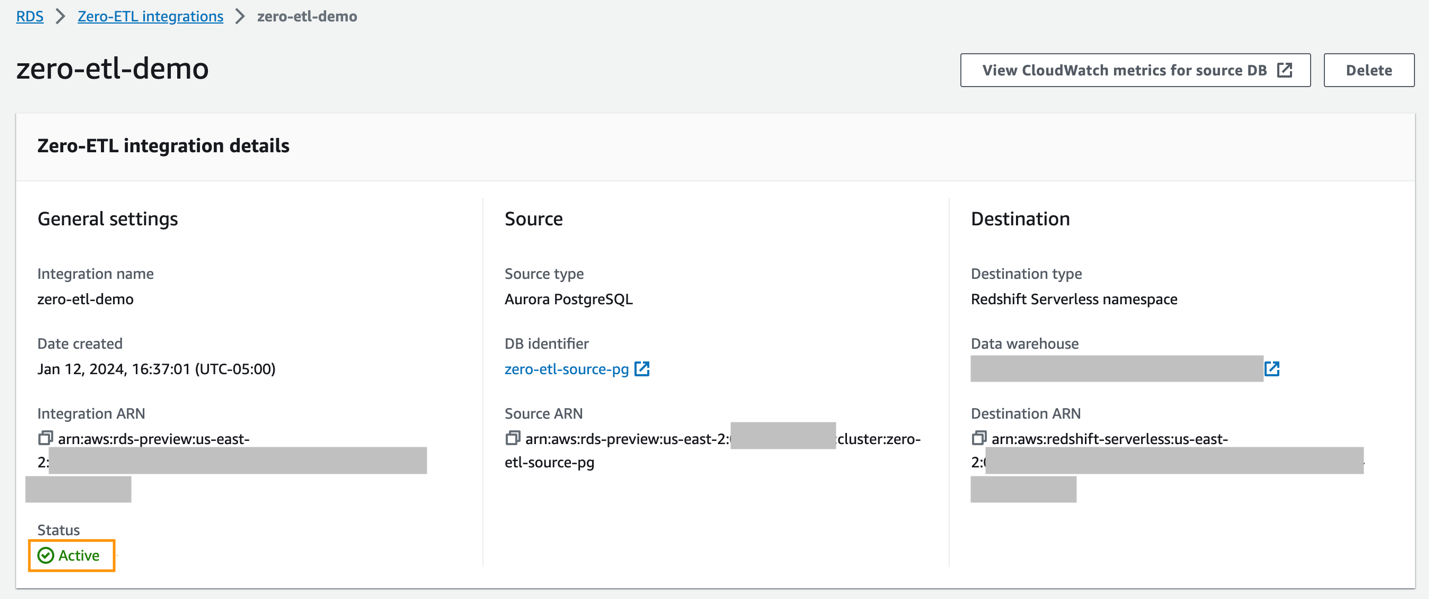
Para especificar un almacén de datos de Redshift de destino que esté en otra cuenta de AWS, debe crear un rol que permita a los usuarios de la cuenta actual acceder a los recursos de la cuenta de destino. Para obtener más información, consulte Proporcionar acceso a un usuario de IAM en otra cuenta de AWS de su propiedad.
Cree un rol en la cuenta de destino con los siguientes permisos:
El rol debe tener la siguiente política de confianza, que especifica el ID de la cuenta de destino. Puede hacerlo creando un rol con una entidad de confianza como ID de cuenta de AWS en otra cuenta.
La siguiente captura de pantalla ilustra la creación de esto en la consola de IAM.
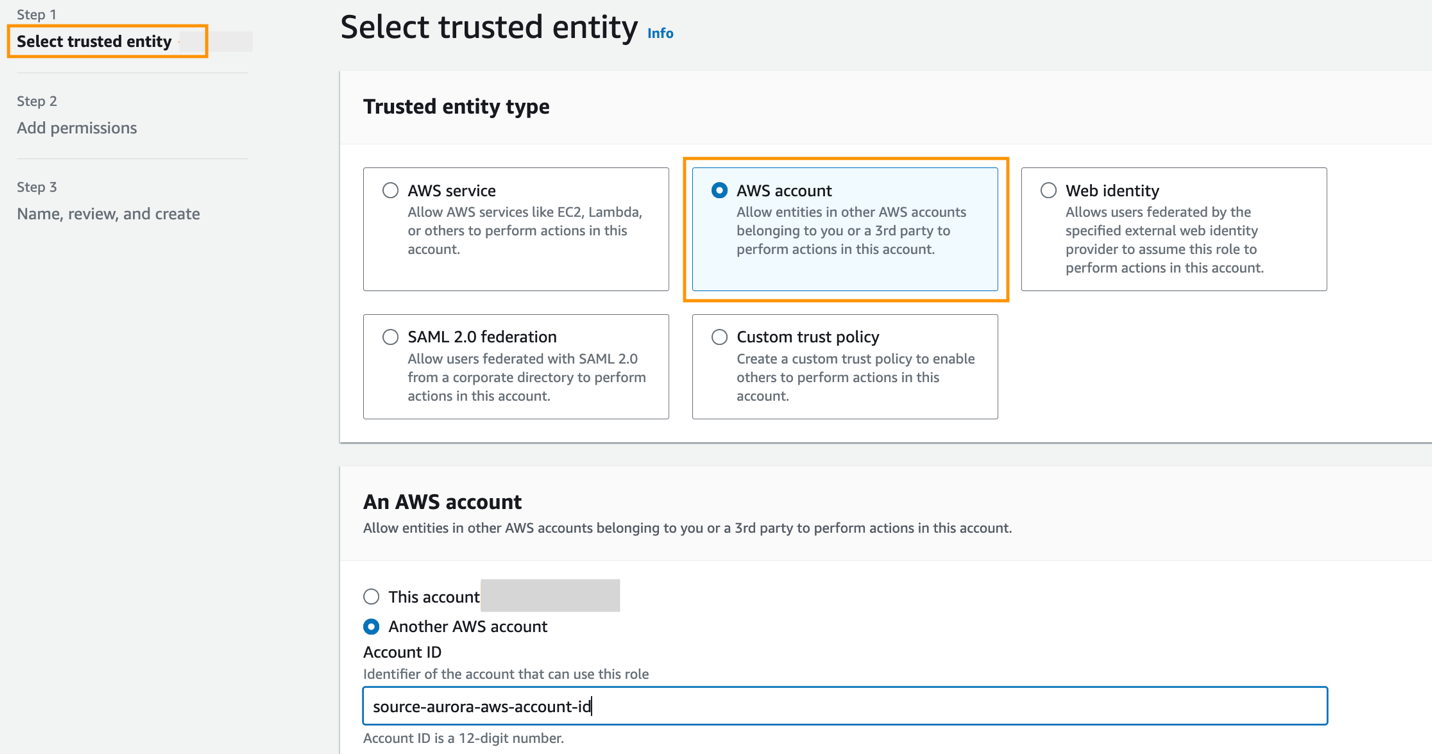
Luego, al crear la integración ETL cero, por ejemplo Especificar una cuenta diferente, elija el ID de la cuenta de destino y el nombre del rol que creó.
Crear una base de datos a partir de la integración en Amazon Redshift
Para crear su base de datos, complete los siguientes pasos:
- En el tablero de Redshift Serverless, navegue hasta el
zero-etl-target-rs-nsespacio de nombres - Elige Consultar datos para abrir el editor de consultas v2.

- Conéctese al almacén de datos de Redshift Serverless eligiendo Crear conexión.
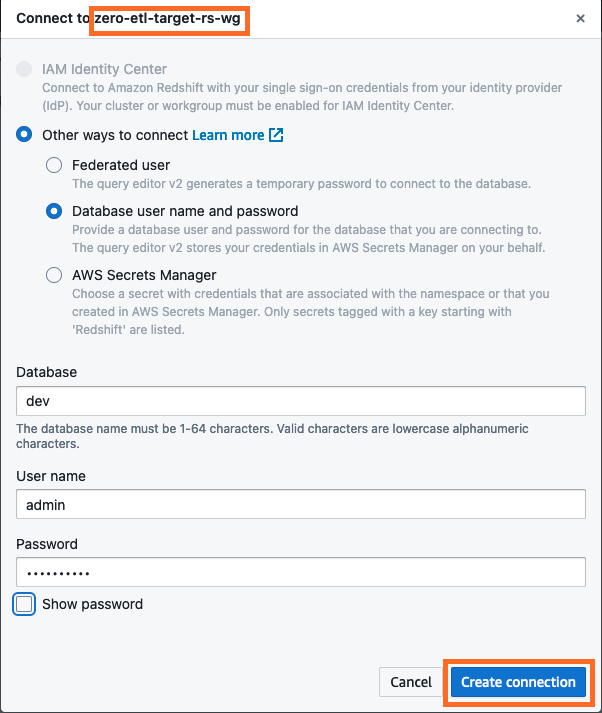
- Obtener el
integration_iddel desplegablesvv_integrationtabla del sistema: - Ingrese al
integration_iddel paso anterior para crear una nueva base de datos a partir de la integración. También debe incluir una referencia a la base de datos nombrada dentro del clúster que especificó cuando creó la integración.CREATE DATABASE aurora_pg_zetl FROM INTEGRATION '<result from above>' DATABASE zeroetl_db;
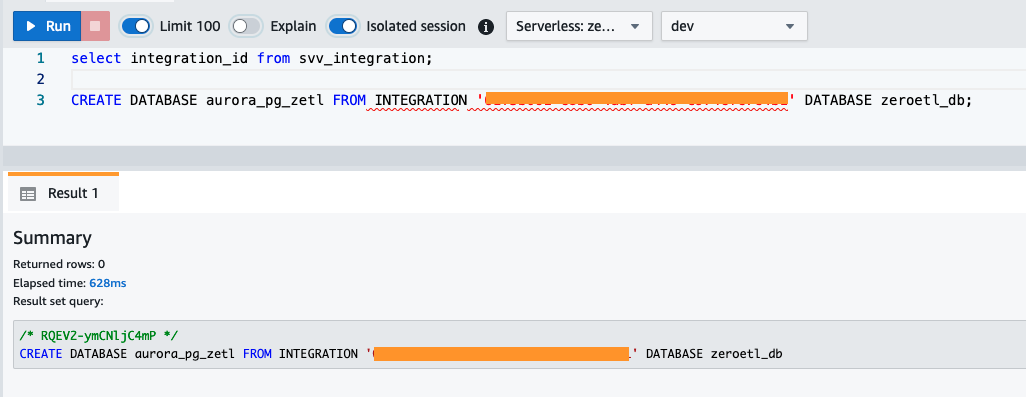
La integración ahora está completa y una instantánea completa del origen se reflejará tal como está en el destino. Los cambios en curso se sincronizarán casi en tiempo real.
Analice los datos transaccionales casi en tiempo real
Ahora puede comenzar a analizar los datos casi en tiempo real desde el origen de Amazon Aurora PostgreSQL hasta el destino de Amazon Redshift:
- Conéctese a su base de datos Aurora PostgreSQL de origen. En esta demostración, usamos psql para conectarse a Amazon Aurora PostgreSQL:

- Cree una tabla de muestra con una clave principal. Asegúrese de que todas las tablas que se replicarán desde el origen al destino tengan una clave principal. Las tablas sin una clave principal no se pueden replicar en el destino.
- Inserte datos ficticios en la tabla de naciones y verifique si los datos están cargados correctamente:

Estos datos de muestra ahora deberían replicarse en Amazon Redshift.
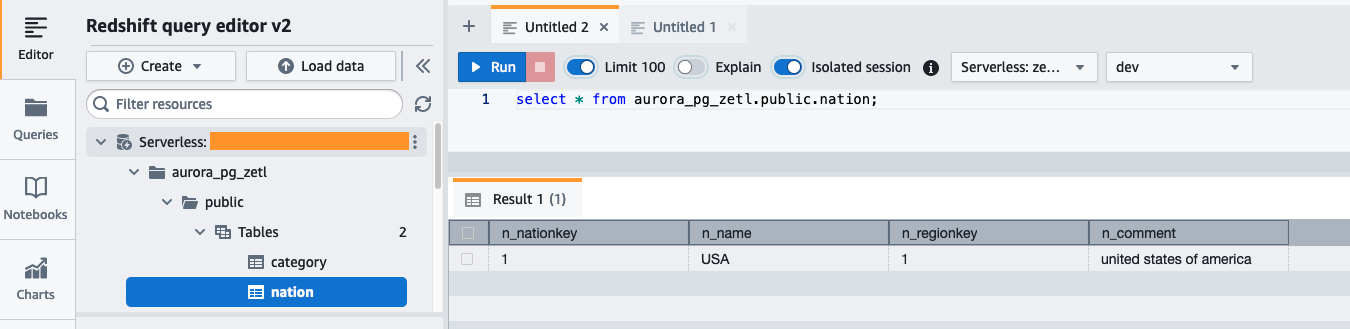
Analizar los datos de origen en el destino.
En el panel de Redshift Serverless, abra el editor de consultas v2 y conéctese a la base de datos. aurora_pg_zetl que creó anteriormente.
Ejecute la siguiente consulta para validar la replicación exitosa de los datos de origen en Amazon Redshift:
También puede utilizar la siguiente consulta para validar la instantánea inicial o la actividad de captura de datos de cambios (CDC) en curso:
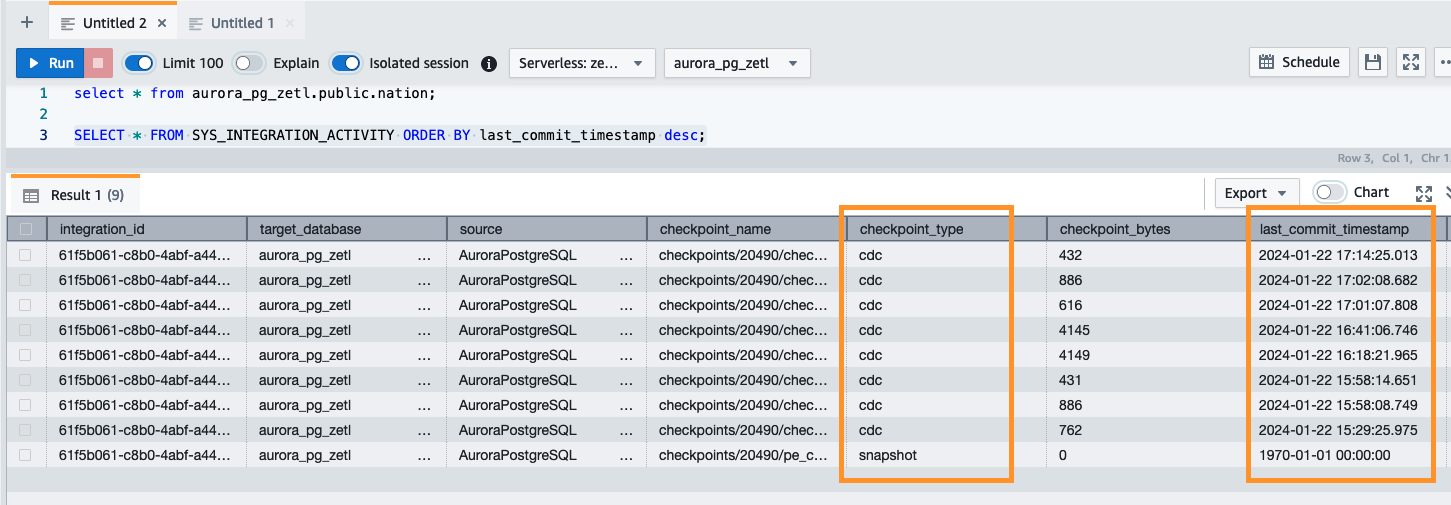
Monitoreo
Hay varias opciones para obtener métricas sobre el rendimiento y el estado de la integración zero-ETL de Aurora PostgreSQL con Amazon Redshift.
Si navega a la consola de Amazon Redshift, puede elegir Integraciones de ETL cero en el panel de navegación. Puede elegir la integración ETL cero que desee y mostrar Reloj en la nube de Amazon métricas relacionadas con la integración. Estas métricas también están disponibles directamente en CloudWatch.
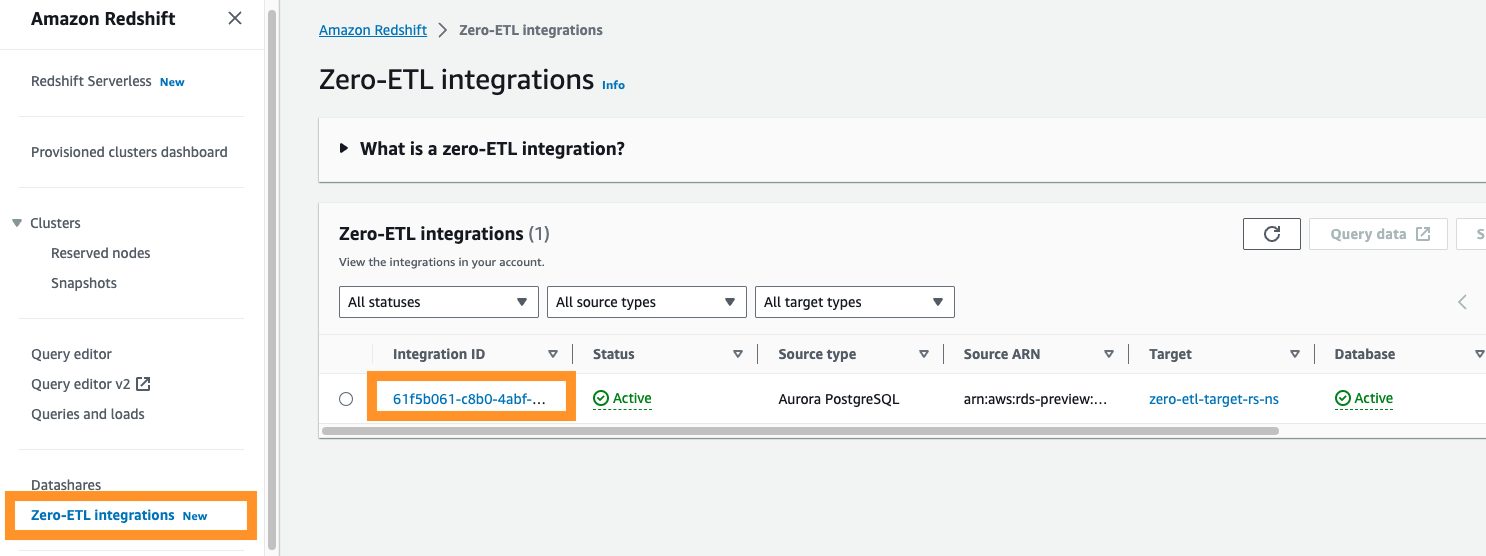
Para cada integración, hay dos pestañas con información disponible:
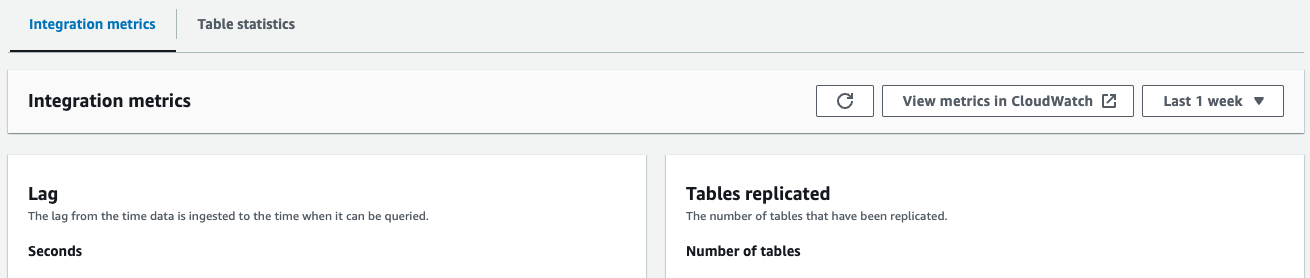
- Métricas de integración – Muestra métricas como el número de tablas replicadas correctamente y detalles de retraso.
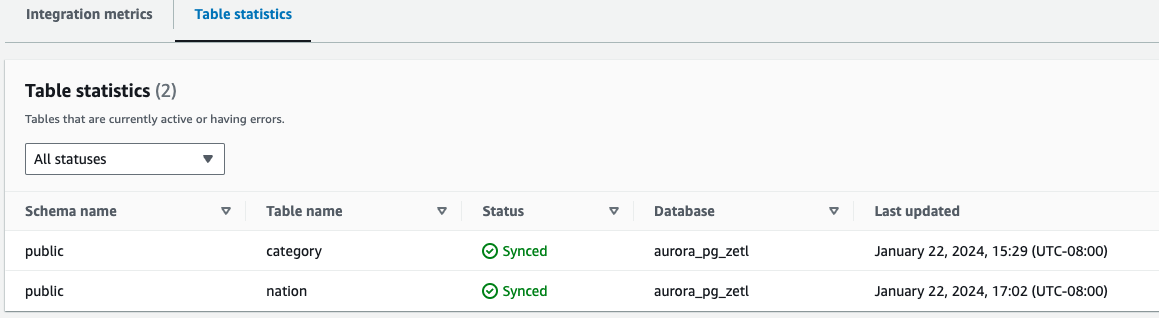
- Estadísticas de la tabla – Muestra detalles sobre cada tabla replicada desde Amazon Aurora PostgreSQL a Amazon Redshift
Además de las métricas de CloudWatch, puede consultar lo siguiente vistas del sistema, que proporcionan información sobre las integraciones:
Limpiar
Cuando elimina una integración de ETL cero, sus datos transaccionales no se eliminan de Aurora o Amazon Redshift, pero Aurora no envía datos nuevos a Amazon Redshift.
Para eliminar una integración de ETL cero, complete los siguientes pasos:
- En la consola de Amazon RDS, elija Integraciones de ETL cero en el panel de navegación.
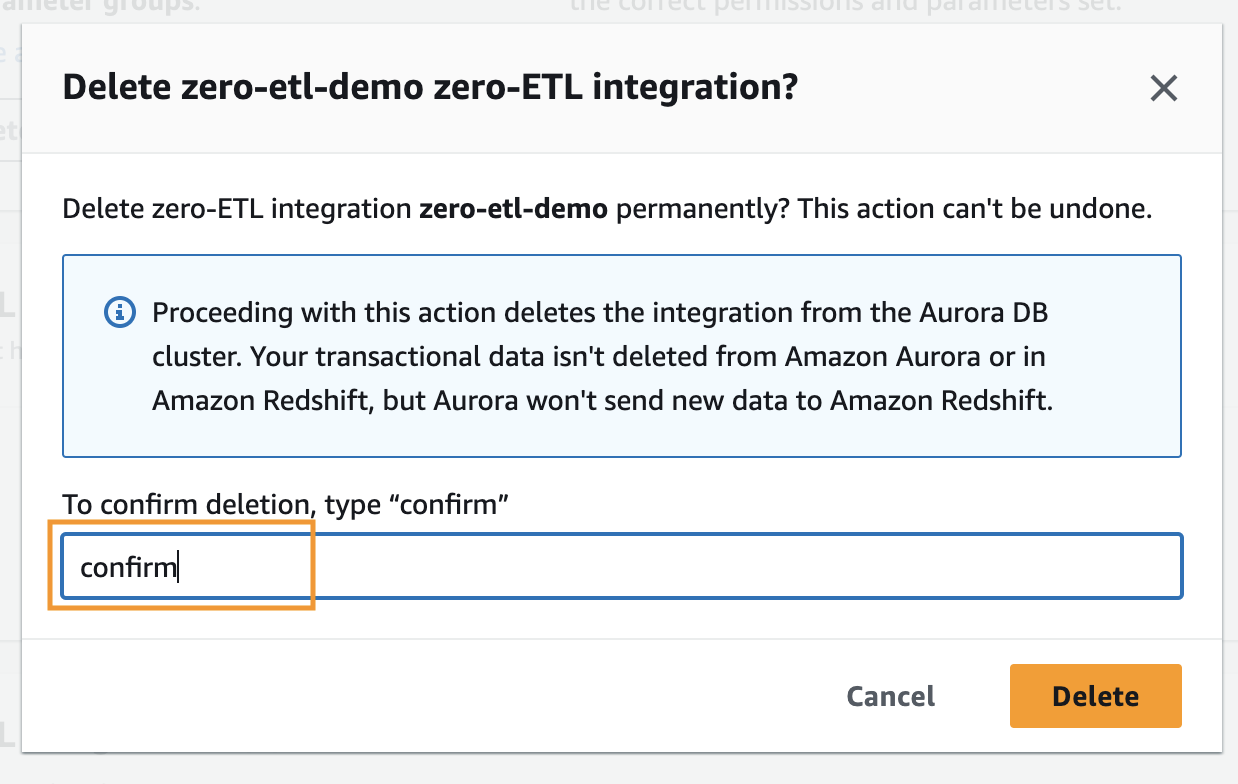
- Seleccione la integración de ETL cero que desea eliminar y elija Borrar.

- Para confirmar la eliminación, ingrese confirmar y elija Borrar.
Conclusión
En esta publicación, explicamos cómo puede configurar la integración ETL cero de Amazon Aurora PostgreSQL a Amazon Redshift, una característica que reduce el esfuerzo de mantener las canalizaciones de datos y permite análisis casi en tiempo real de datos operativos y transaccionales.
Para obtener más información sobre la integración de ETL cero, consulte Trabajar con integraciones Aurora zero-ETL con Amazon Redshift y Limitaciones.
Acerca de los autores
 Raks Khare es un arquitecto de soluciones especialista en análisis en AWS con sede en Pensilvania. Ayuda a los clientes a diseñar soluciones de análisis de datos a escala en la plataforma de AWS.
Raks Khare es un arquitecto de soluciones especialista en análisis en AWS con sede en Pensilvania. Ayuda a los clientes a diseñar soluciones de análisis de datos a escala en la plataforma de AWS.
 Juan Luis Polo Garzón es Arquitecto Asociado Especialista en Soluciones en AWS, especializado en cargas de trabajo de análisis. Tiene experiencia ayudando a los clientes a diseñar, construir y modernizar sus soluciones de análisis basadas en la nube. Fuera del trabajo, le gusta viajar, hacer actividades al aire libre, hacer caminatas y asistir a eventos de música en vivo.
Juan Luis Polo Garzón es Arquitecto Asociado Especialista en Soluciones en AWS, especializado en cargas de trabajo de análisis. Tiene experiencia ayudando a los clientes a diseñar, construir y modernizar sus soluciones de análisis basadas en la nube. Fuera del trabajo, le gusta viajar, hacer actividades al aire libre, hacer caminatas y asistir a eventos de música en vivo.
 Sushmita Barthakur es arquitecto senior de soluciones en Amazon Web Services y ayuda a los clientes empresariales a diseñar sus cargas de trabajo en AWS. Con una sólida experiencia en análisis y gestión de datos, tiene una amplia experiencia ayudando a los clientes a diseñar y crear soluciones de análisis e inteligencia empresarial, tanto en las instalaciones como en la nube. Sushmita reside en Tampa, FL y le gusta viajar, leer y jugar tenis.
Sushmita Barthakur es arquitecto senior de soluciones en Amazon Web Services y ayuda a los clientes empresariales a diseñar sus cargas de trabajo en AWS. Con una sólida experiencia en análisis y gestión de datos, tiene una amplia experiencia ayudando a los clientes a diseñar y crear soluciones de análisis e inteligencia empresarial, tanto en las instalaciones como en la nube. Sushmita reside en Tampa, FL y le gusta viajar, leer y jugar tenis.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/achieve-near-real-time-operational-analytics-using-amazon-aurora-postgresql-zero-etl-integration-with-amazon-redshift/

