Introducción
Déjame compartir una historia contigo. Años atrás, cuando el equipo de datos del Consorcio Internacional de Periodistas de Investigación (ICIJ) recibió un volcado de datos que hoy conocemos como los Papeles de Panamá, probablemente pensaron que era un esfuerzo inútil. Con esa cantidad masiva de documentos de coama hay una "filtración gigante de más de 11.5 millones de registros financieros y legales que exponen un sistema que permite el crimen, la corrupción y las fechorías, ocultos por compañías secretas en el extranjero". Los escándalos financieros extraterritoriales rojos sobre los que hemos estado leyendo en las noticias desde 2015 fueron los esfuerzos del equipo de ICIJ para aprovechar el poder de los gráficos de conocimiento (KG) que dio contexto y conexión a los datos. Los datos multimedia complejos de varios años en Knowledge Graphs se vincularon para que los investigadores pudieran recorrer las conexiones para desentrañar algunos de los mayores escándalos del pasado.

Ahora que estamos familiarizados, le dejamos con un concepto detallado detrás de los KG, por qué, dónde y cómo podemos usar los KG.
OBJETIVOS DE APRENDIZAJE
El objetivo de aprendizaje de este artículo es hacer que nuestros datos sean más inteligentes mediante una técnica llamada Gráficos de conocimiento. Los KG obtienen puntos de brownie sobre el resto de los gráficos normales debido a la adición de técnicas de organización. El artículo también explora cómo encontrar gráficos de conocimiento en el mundo real y cómo ayudarlo a construir uno.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Índice del contenido
- ¿Qué es un gráfico de conocimiento?
- Principios de organización de los grafos de conocimiento
- Gráfico antiguo simple
- Gráficos más ricos
- Gráficos de conocimiento usando taxonomía
- Gráficos de conocimiento usando ontología
- ¿Cómo implementar gráficos de conocimiento?
- Aplicaciones de los gráficos de conocimiento
- Conclusión
La mayoría de nosotros sabemos que los gráficos en el cálculo son una forma agradable y flexible de modelado de datos que admite varios algoritmos complejos y ciencia de datos y computación. Pero lo que diferencia a los KG de los gráficos es la aplicación de un principio organizador que ayuda a los humanos y al software a interpretarlo rápidamente. Entonces, en lugar de codificar repetidamente el comportamiento inteligente en las aplicaciones, ¡lo codificamos directamente en los datos de una vez por todas! Los KG son el resultado de décadas de investigación en computación semántica, pero con el advenimiento de las computaciones gráficas modernas, pueden extenderse fácilmente a problemas del mundo real.
Así podemos decir que los KG son bases de conocimiento estructuradas que representan entidades del mundo real y las relaciones entre ellas. La mayoría de los KG almacenan este conocimiento en tripletes conocidos como Sujeto-Predicado-Objeto (SPO) formato, que se alinea con los estándares del Marco de descripción de recursos (RDF). La existencia de un triplete SPO particular indica que los respectivos tripletes poseen una relación de un tipo específico. Por ejemplo, considere el siguiente conocimiento.
"Leonard Nimoy fue un actor que interpretó al personaje de Spock en la película de ciencia ficción Star Trek.."
En la siguiente figura se muestra un gráfico de conocimiento de muestra de lo siguiente. Aquí los nodos representan entidades, las etiquetas de borde representan tipos de relaciones y los bordes mismos representan relaciones existentes.
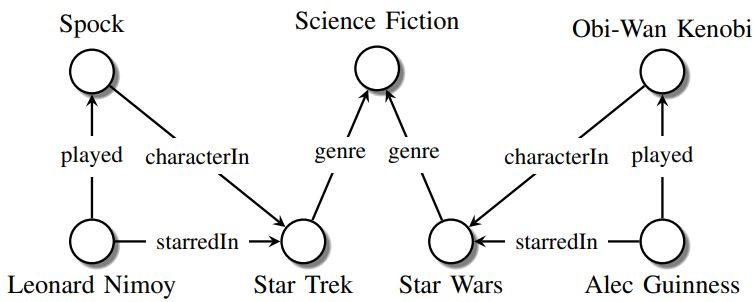
Fuente: arxiv.org
Mientras que los tripletes SPO que se pueden extraer del conocimiento dado se muestran a continuación:
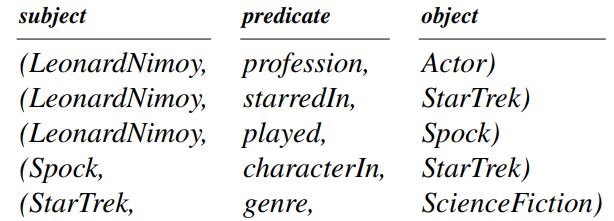
Fuente: arxiv.org
Ahora entendemos la estructura de los KG. A continuación, analizaremos los principios organizativos de los KG, que resaltan su esencia y los diferencian de los gráficos típicos.
Principios de organización de un gráfico de conocimiento
Hay varias formas de organizar datos en gráficos, cada una con sus ventajas e inconvenientes. En esta sección, analizaremos cada una de las jerarquías organizativas. Comenzaríamos con gráficos sencillos e intentaríamos explicar cómo agregar capas sucesivas de organización ayuda a que los datos sean inteligentes y más interpretables, lo que ayuda a resolver problemas cada vez más sofisticados.
Gráficos antiguos simples
Estos son gráficos a los que no se les ha aplicado ningún principio organizador. Aún así, sabemos que ayudan a resolver nuestros desafíos diarios ya que sustentan algunos sistemas muy importantes. En lugar de asociar los "principios de organización" con los datos, los programas y sistemas que consumen estos datos gráficos están integrados con los "principios de organización".
Un ejemplo típico de lo mismo serían las ventas de una tienda online. La siguiente figura muestra una pequeña parte del gráfico de ventas y catálogo de productos, mostrando los clientes y sus compras en forma de un gráfico simple.
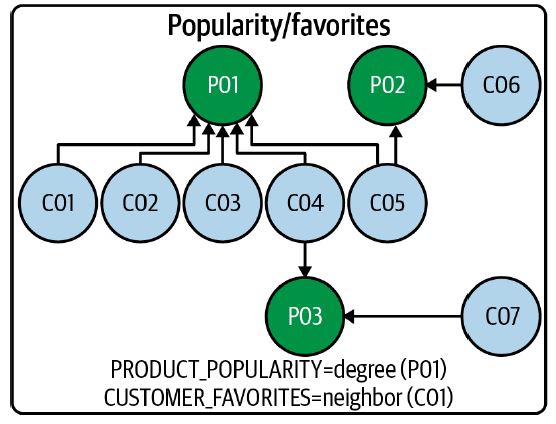
Fuente: neo4j.com
Mirar directamente al gráfico puede no ser intuitivo. Aún así, cuando el conocimiento de que los nodos P representan productos, los nodos C representan clientes y las conexiones entre los nodos representan compras está codificado en el programa, sería fácil responder preguntas como productos que compró un cliente en particular y viceversa o calcular el popularidad del producto. No hay duda del hecho de que este tipo de información gráfica es útil y ayuda a proporcionar datos de forma compacta, pero en los casos en que los científicos de datos sin conocimiento previo del dominio intentan ejecutar el código en seco, alguien tendrá que explicar cómo hacerlo. para leer los datos, o podría tener que aplicar ingeniería inversa a los códigos para entender cómo interpretar los datos. Por lo tanto, una mejor solución es hacer que los datos sean inteligentes aplicando algunos principios de organización a los gráficos, que veremos en las siguientes tres subsecciones.
Modelos de gráficos más ricos
El primer principio organizador que veríamos es el modelo de gráfico de propiedades. Es más rico y mucho más organizado y admite nodos etiquetados, tipos y direcciones de relaciones y propiedades (pares clave-valor) en ambos nodos. Por lo tanto, puede proporcionar a humanos y máquinas algunas pistas esenciales sobre la información que contiene. Por lo tanto, este estilo de organización hace que el gráfico sea autodescriptivo hasta cierto nivel y es un paso claro para hacer que los datos sean más inteligentes. Además, algunos preprocesamientos y visualizaciones se pueden llevar a cabo sin ningún conocimiento del dominio simplemente aprovechando las características de los modelos de gráficos de propiedades.
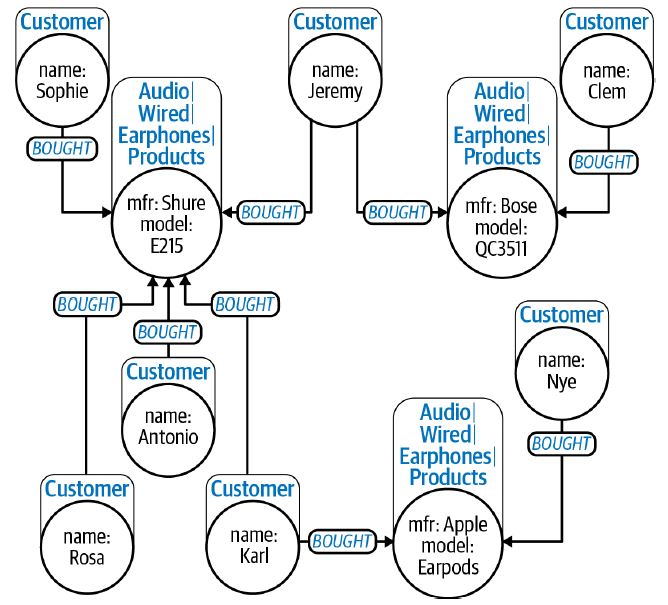
Fuente: neo4j.com
La figura anterior muestra una vista enriquecida de los catálogos de productos y ventas, que incluyen etiquetas, propiedades y relaciones con nombres.
KG que utilizan taxonomías para la jerarquía
En el "principio de organización" anterior, vimos que la creación de categorías de nodos usando etiquetas es evidentemente útil. Aún así, en un pensamiento más profundo, ¡puede darse cuenta de que falta la asociatividad entre las etiquetas!
Continuando con nuestro catálogo de productos de venta, una buena manera de proceder sería enriquecer la clasificación de productos con algún "principio de organización de orden superior", de modo que incluso si el comerciante no tiene existencias de un producto en particular, podría ganar una venta. sugiriendo algún producto similar. Necesitamos una taxonomía para respaldar este tipo de razonamiento "x es un tipo de y".
La taxonomía es un esquema de clasificación que permite una jerarquía más amplia y más estrecha. Los elementos que comparten propiedades similares se agrupan en la misma categoría y la taxonomía ayuda a relacionar una categoría con otra globalmente. Este tipo de jerarquía permite colocar elementos específicos, como productos, en la parte inferior, y elementos más generales, como marcas y productos, se ubican en la parte superior de la jerarquía. La jerarquía en este tipo de "principio organizador" se construye con nodos de categoría conectados por relaciones de subcategoría_de. Y los productos están conectados a la parte apropiada de la taxonomía para clasificarlos como listos para la venta. Lo mismo se muestra en la siguiente figura.
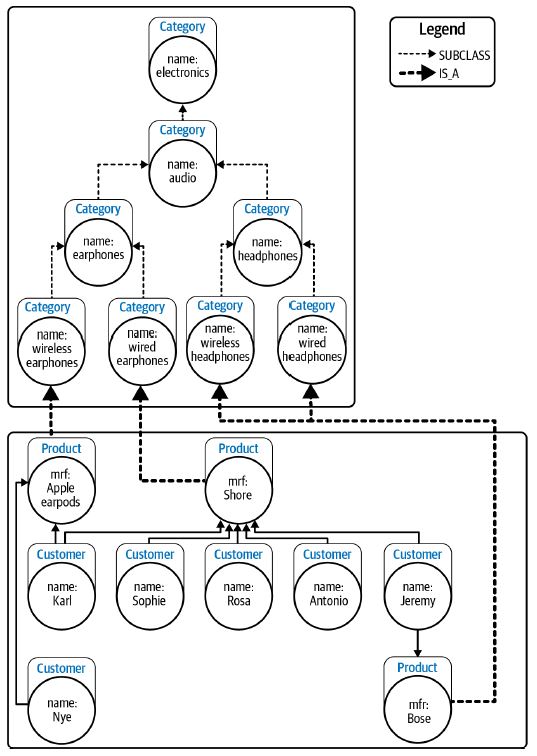
Fuente: neo4j.com
La figura anterior muestra la jerarquía del catálogo de productos en capas sobre los datos de clientes y ventas. Esto permite una visualización más organizada de los datos. Un hecho aún más interesante es que podemos proporcionar múltiples organizaciones jerárquicas simultáneamente para ayudar a proporcionar aún más información sobre los datos.
Gráficos de conocimiento utilizando ontologías para relaciones multinivel
Las taxonomías ayudan a organizar al incorporar la subcategoría_de relaciones; La ontología permite definir relaciones más complejas entre categorías como parte_de, compatible_con y depende_de. Así, siguiendo las instrucciones ontológicas, no solo podemos explorar las categorías verticalmente (jerárquicamente), sino que también permite la comparación horizontal. Además de esto, se pueden construir de forma modular para hacerlos más compactos con un uso sofisticado de capas. Por lo tanto, la ontología ayuda a que el conocimiento sea procesable. La siguiente figura es una representación ontológica que muestra las rutas de actualización de los productos en una categoría.
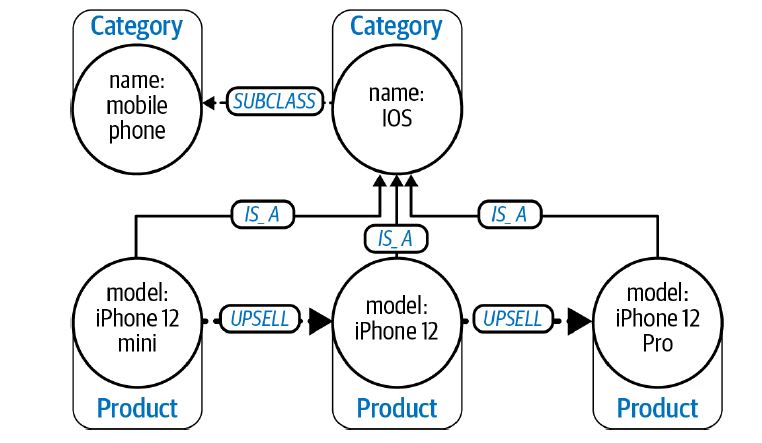
Fuente: neo4j.com
Por lo tanto, hasta ahora, hemos visto diferentes tipos de principios organizadores de KG. Sin embargo, el principio organizador que elegimos usar siempre debe estar impulsado por su uso previsto. Es aconsejable no incorporar características ricas y demasiado complicadas en los principios de organización si ningún proceso o agente asociado las usaría. Es un error común optar por un principio de organización demasiado ambicioso, ya que sería costoso en términos de recursos y tiempo.
¿Cómo implementar gráficos de conocimiento?
Ahora que hemos entendido los KG y los diferentes principios organizativos, la siguiente pregunta es cómo implementarlos. La implementación de KG generalmente implica los siguientes pasos:
- El primer paso es recopilar datos de bases de datos estructuradas/no estructuradas o datos de texto o multimedia de imágenes y videos.
- El siguiente paso sería preprocesarlo para eliminar información irrelevante y redundante para garantizar que los datos estén en un formato que pueda utilizarse fácilmente para construir los KG.
- El tercer paso es extraer las entidades y relaciones de los datos. Reconocimiento de entidad nombrada, la extracción de relaciones y la detección de objetos pueden lograr esto.
- Una vez extraídas las entidades y relaciones, el siguiente paso es construir los grafos de conocimiento. Graficar bases de datos como neo4j o Titán puede lograr esto.
- Luego, sígalo completando el KG con entidades y relaciones extraídas.
- Una vez que se ha construido KG, se puede consultar para obtener información útil.
- Finalmente, el KG debe mantenerse regularmente, actualizarse con nuevos datos y monitorearse en busca de errores.
Vale la pena mencionar que estos pasos no son discretos y pueden variar según el caso de uso específico y la tecnología. Además, bibliotecas y marcos como OpenAI, GPT 3y de Google tensor puede ayudar con los pasos.
¿Dónde encontrarías gráficos de conocimiento en el mundo real?
Ahora que sabemos cómo construir KG, sería interesante que fueras un
- Detección de fraude – La representación de escenarios de fraude de forma visual gráfica, que es el núcleo de un gráfico de conocimiento, permite a los consultores financieros identificar para ampliar su trabajo de algoritmo de aprendizaje automático para considerar conjuntos de datos aún más heterogéneos que podrían no estar directamente relacionados con el tema en cuestión, o reconsidere las características y variables que las capacidades tradicionales de aprendizaje automático pueden ignorar. Si sus algoritmos de aprendizaje automático los han determinado como no fraudulentos, lo más probable es que no lo sean. Por ejemplo, el modelo anterior no tenía en cuenta las direcciones de correo electrónico como una característica valiosa para determinar el fraude. Pero si dos clientes tienen la misma dirección de correo electrónico, eso podría generar una señal de alarma: podrían ser la misma persona. En este caso, una dirección de correo electrónico está relacionada con una entidad (cliente) conectada a otro cliente a través de la misma dirección de correo electrónico.
- Gobierno de datos – A medida que varias divisiones dentro de una compañía financiera generan nuevos datos a lo largo del tiempo, las diferencias de datos que ocurren conducen a una calidad inconsistente y falta de utilidad para la organización en general. Los gráficos actúan como una capa semántica, modelan metadatos y agregan un rico significado descriptivo a los elementos de datos.
Los metadatos y las relaciones combinados forman una capa semántica que describe completamente el significado de los datos y permite la visualización de todos los datos en su granularidad. Al visualizar los datos, los gráficos de conocimiento le permiten al usuario identificar datos duplicados o inconsistentes, ya que estos datos tendrán una relación interconectada con otras entidades. Finalmente, los patrones vistos a partir de las relaciones pueden ayudar a la organización a desarrollar análisis para comprender la usabilidad de los datos. - Manejo de información – Los KG también tienen su aplicabilidad en el campo de las finanzas. Thomson Reuters lanzó su primer gráfico de conocimiento en 2017 para brindar una visión integral del ecosistema financiero y ayudar a las organizaciones a optimizar sus "inversiones, objetivos y perspectivas".
Su gráfico de conocimiento reúne información sobre organizaciones, personas, instrumentos y cotizaciones, presentaciones e informes de proveedores y clientes, metadatos y taxonomías, acuerdos de fusiones y adquisiciones, etc. Permite que las organizaciones financieras lo utilicen como base para proyectos de investigación, evaluaciones de riesgos, etc. - Información privilegiada – implica el intercambio de información entre dos o más personas o entidades. Los investigadores que trabajan en esquemas de uso de información privilegiada tienen que revisar diferentes tipos de datos en busca de relaciones y filtraciones de información para llegar a la persona deseada. Tradicionalmente, la SEC y otras agencias gubernamentales examinan fuentes como llamadas telefónicas, mensajes, intercambios de correo electrónico e información de fuente abierta y las combinan para encontrar nuevos patrones. Como puedes imaginar, el uso de métodos tradicionales puede complicar este proceso. Knowledge Graph nos permite representar todas estas diferentes fuentes de datos, permite el reconocimiento de patrones incluso en las relaciones más pequeñas y se alimenta constantemente con nueva información a medida que llega.
Conclusión
Si bien espero haber satisfecho con éxito su ansia de conocimiento por hoy, quiero dejarles una información de despedida. Quiero presentarles algo llamado "Gráficos de escena". Un gráfico de escena (SG) difiere de KG porque SG extrae SPO de imágenes y videos. Los gráficos de conocimiento se utilizan para representar entidades del mundo real y sus relaciones y se utilizan para representar información en un formato estructurado en un sentido general. Pueden representar estructuras como personas, cosas y conceptos. Los gráficos de escena, por otro lado, se utilizan para incorporar objetos, atributos y relaciones espaciales entre objetos (contención, proximidad, acciones, etc.) en imágenes y videos (entornos 3D).
Por lo tanto, hoy, hemos analizado profundamente cómo hacer que nuestros datos sean más inteligentes e inteligentes. La técnica que utilizamos para el mismo es Knowledge Graphs. Para resumir brevemente la lectura de hoy, los puntos clave para usted en este artículo serían:
- Cómo los gráficos de conocimiento difieren de los gráficos normales debido a la adición de "técnicas de organización".
- Luego profundizamos en cada una de las técnicas de organización, explicando cada caso con nuestra analogía de las ventas en línea de una tienda.
- Lo seguimos construyendo gráficos de conocimiento y dónde podemos encontrarlos en el mundo real.
- Fined con información adicional sobre los gráficos de escena que se aprovechan cuando nos encontramos con datos de imagen y video.
Espero que hayas tenido una buena lectura hasta aquí. Si te ha gustado, ¡mantente atento a mis próximos blogs! ¡Te deseo un feliz aprendizaje!
Referencias:
- Gráficos de conocimiento Datos en contexto para negocios receptivos – por Jesús Barrasa, Amy E. Hodler y Jim Webber
- Guía para principiantes de gráficos de conocimiento y gráficos de escena – por Asad Haider Rizvi
- Knowledge Graph Representacional y Aplicaciones en IA – por Parishad Behnam Ghader
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/01/knowledge-graphs-deep-dive-into-its-theories-and-applications/

