
Imagen del autor
Tener un buen título es crucial para el éxito de un artículo. La gente dedica sólo un segundo (si creemos en el libro de Ryan Holiday) “Confía en mí, estoy mintiendo” decidir si hacer clic en el título para abrir el artículo completo. Los medios están obsesionados con optimizar tasa de clics (CTR), el número de clics que recibe un título dividido por el número de veces que se muestra el título. Tener un título de cebo de clics aumenta el CTR. Es probable que los medios elijan un título con un CTR más alto entre los dos porque esto generará más ingresos.
Realmente no estoy interesado en exprimir los ingresos publicitarios. Se trata más de difundir mis conocimientos y experiencia. Y aún así, los espectadores tienen tiempo y atención limitados, mientras que el contenido en Internet es prácticamente ilimitado. Por lo tanto, debo competir con otros creadores de contenido para captar la atención de los espectadores.
¿Cómo elijo un título adecuado para mi próximo artículo? Por supuesto, necesito un conjunto de opciones para elegir. Con suerte, puedo generarlos por mi cuenta o preguntarle a ChatGPT. ¿Pero qué hago a continuación? Como científico de datos, sugiero realizar una prueba A/B/N para comprender qué opción es la mejor basada en datos. Pero hay un problema. Primero, necesito decidir rápidamente porque el contenido caduca rápidamente. En segundo lugar, puede que no haya suficientes observaciones para detectar una diferencia estadísticamente significativa en los CTR, ya que estos valores son relativamente bajos. Entonces, hay otras opciones además de esperar un par de semanas para decidir.
¡Ojalá haya una solución! Puedo utilizar un algoritmo de aprendizaje automático de “bandido de múltiples brazos” que se adapta a los datos que observamos sobre el comportamiento de los espectadores. Cuantas más personas hagan clic en una opción particular del conjunto, más tráfico podremos asignar a esa opción. En este artículo, explicaré brevemente qué es un "bandido bayesiano de múltiples brazos" y mostraré cómo funciona en la práctica usando Python.
Bandidos multiarmados Son algoritmos de aprendizaje automático. El tipo bayesiano utiliza Muestreo de Thompson elegir una opción basada en nuestras creencias previas sobre las distribuciones de probabilidad de los CTR que se actualizan posteriormente en función de los nuevos datos. Todas estas palabras de teoría de la probabilidad y estadística matemática pueden parecer complejas y desalentadoras. Permítanme explicar todo el concepto utilizando la menor cantidad de fórmulas posible.
Supongamos que sólo hay dos títulos para elegir. No tenemos idea de sus CTR. Pero queremos tener el título de mayor rendimiento. Tenemos múltiples opciones. La primera es elegir el título en el que creemos más. Así funcionó durante años en la industria. El segundo asigna el 50% del tráfico entrante al primer título y el 50% al segundo. Esto fue posible con el auge de los medios digitales, donde puedes decidir qué texto mostrar precisamente cuando un espectador solicita una lista de artículos para leer. Con este enfoque, puede estar seguro de que el 50 % del tráfico se asignó a la opción de mejor rendimiento. ¿Es esto un límite? ¡Por supuesto que no!
Algunas personas leerían el artículo un par de minutos después de su publicación. Algunas personas lo harían en un par de horas o días. Esto significa que podemos observar cómo los lectores "tempranos" respondieron a diferentes títulos y cambiar la asignación de tráfico de 50/50 y asignar un poco más a la opción de mejor rendimiento. Después de un tiempo, podemos volver a calcular los CTR y ajustar la división. Como límite, queremos ajustar la asignación de tráfico después de que cada nuevo espectador haga clic o se salte el título. Necesitamos un marco para adaptar la asignación del tráfico de forma científica y automatizada.
Aquí viene el teorema de Bayes, la distribución Beta y el muestreo de Thompson.
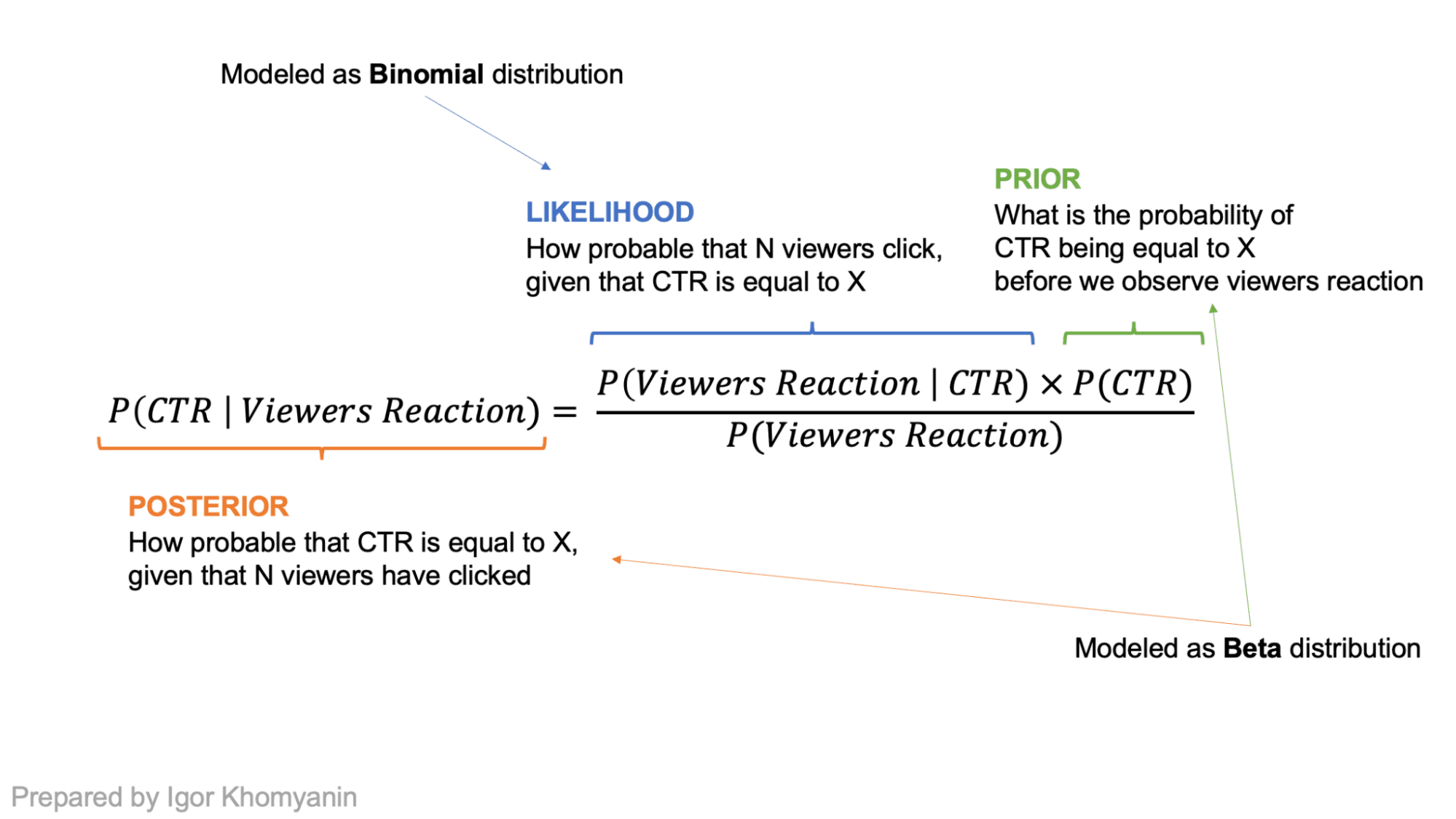
Supongamos que el CTR de un artículo es una variable aleatoria "theta". Por diseño, se encuentra entre 0 y 1. Si no tenemos creencias previas, puede ser cualquier número entre 0 y 1 con la misma probabilidad. Después de observar algunos datos "x", podemos ajustar nuestras creencias y tener una nueva distribución para "theta" que estará más cerca de 0 o 1 usando el teorema de Bayes.
El número de personas que hacen clic en el título se puede modelar como un Distribución binomial donde "n" es el número de visitantes que ven el título y "p" es el CTR del título. ¡Esta es nuestra probabilidad! Si modelamos lo anterior (nuestra creencia sobre la distribución del CTR) como un Distribución beta y tomando probabilidad binomial, ¡la posterior también sería una distribución Beta con diferentes parámetros! En tales casos, la distribución Beta se llama conjugar antes a la probabilidad.
Demostrar este hecho no es tan difícil, pero requiere algún ejercicio matemático que no es relevante en el contexto de este artículo. Consulte la hermosa prueba. esta página:
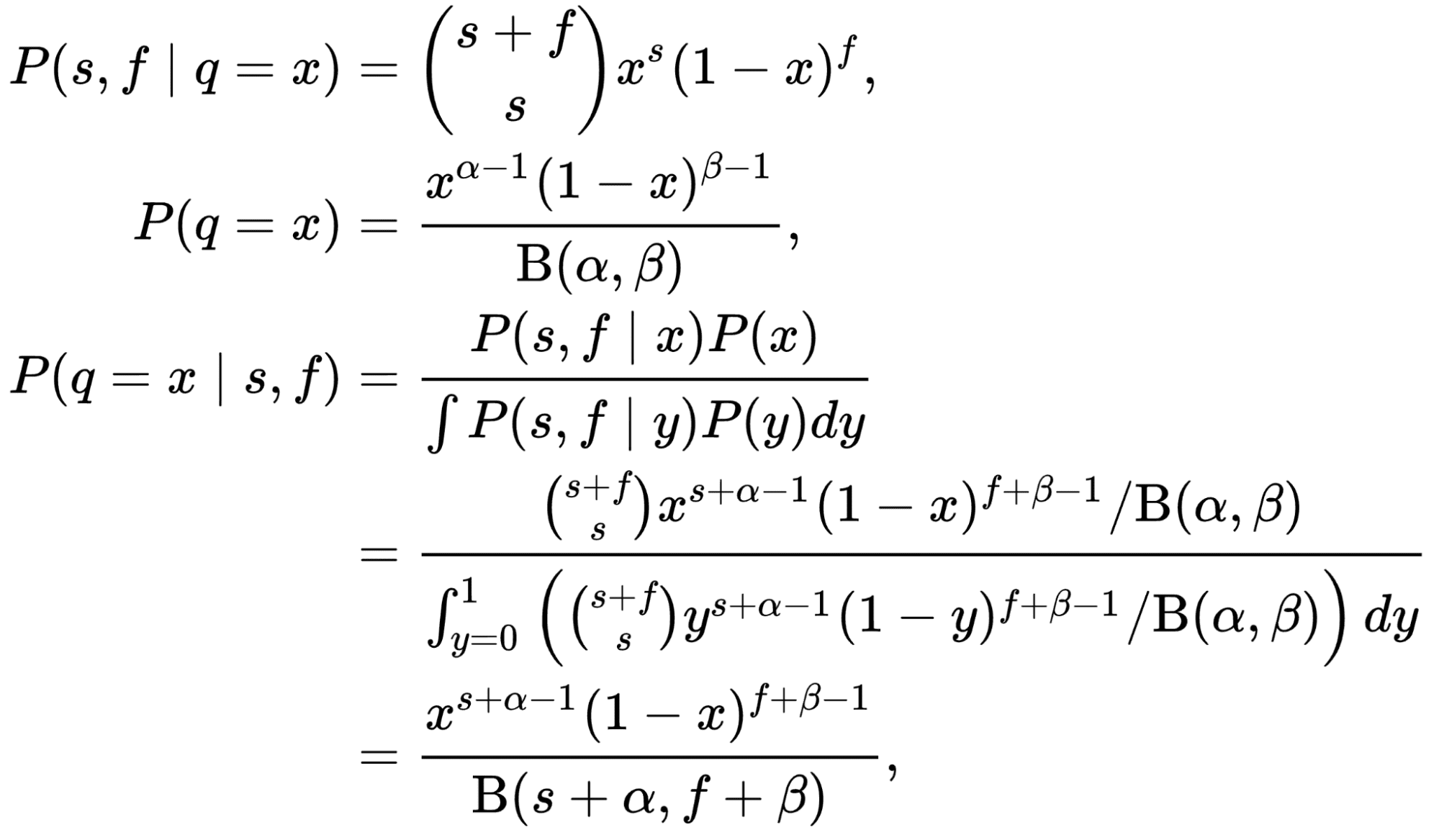
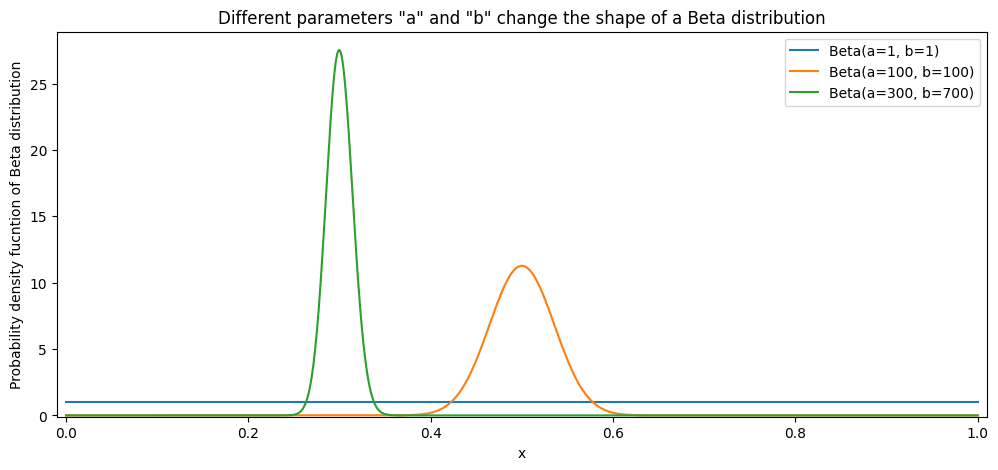
La distribución beta está limitada por 0 y 1, lo que la convierte en un candidato perfecto para modelar una distribución de CTR. Podemos partir de “a = 1” y “b = 1” como parámetros de distribución Beta que modelan el CTR. En este caso, no tendríamos creencias sobre la distribución, lo que haría que cualquier CTR fuera igualmente probable. Luego, podemos comenzar a agregar datos observados. Como puede ver, cada "éxito" o "clic" aumenta "a" en 1. Cada "fracaso" o "salto" aumenta "b" en 1. Esto distorsiona la distribución del CTR pero no cambia la familia de distribución. ¡Aún es una distribución beta!
Suponemos que el CTR se puede modelar como una distribución Beta. Luego, hay dos opciones de título y dos distribuciones. ¿Cómo elegimos qué mostrarle al espectador? Por lo tanto, el algoritmo se denomina "bandido de múltiples brazos". En el momento en que un espectador solicita un título, usted "tira de ambos brazos" y muestra los CTR. Después de eso, compara los valores y muestra un título con el CTR de muestra más alto. Luego, el espectador hace clic o salta. Si se hiciera clic en el título, se ajustaría el parámetro de distribución Beta “a” de esta opción, que representa “éxitos”. De lo contrario, aumenta el parámetro de distribución Beta "b" de esta opción, que significa "fallos". Esto distorsiona la distribución y, para el próximo espectador, habrá una probabilidad diferente de elegir esta opción (o “brazo”) en comparación con otras opciones.
Después de varias iteraciones, el algoritmo tendrá una estimación de las distribuciones de CTR. El muestreo de esta distribución activará principalmente el brazo de CTR más alto, pero aún permitirá a los nuevos usuarios explorar otras opciones y reajustar la asignación.
Bueno, todo esto funciona en teoría. ¿Es realmente mejor que la división 50/50 que hemos comentado antes?
Todo el código para crear una simulación y construir gráficos se puede encontrar en mi Repositorio de GitHub.
Como mencionamos anteriormente, sólo tenemos dos títulos para elegir. No tenemos creencias previas sobre los CTR de este título. Entonces, comenzamos desde a=1 y b=1 para ambas distribuciones Beta. Simularé un tráfico entrante simple asumiendo una cola de espectadores. Sabemos con precisión si el espectador anterior “hizo clic” o “saltó” antes de mostrar un título al nuevo espectador. Para simular acciones de "hacer clic" y "saltar", necesito definir algunos CTR reales. Que sean el 5% y el 7%. Es fundamental mencionar que el algoritmo no sabe nada sobre estos valores. Los necesito para simular un clic; tendrías clics reales en el mundo real. Lanzaré una moneda súper sesgada por cada título que arroje cara con una probabilidad del 5% o 7%. Si sale cara, se oye un clic.
Entonces, el algoritmo es sencillo:
- Con base en los datos observados, obtenga una distribución Beta para cada título.
- CTR de muestra de ambas distribuciones
- Comprenda qué CTR es mayor y lance una moneda relevante
- Entender si hubo un clic o no
- Aumentar el parámetro “a” en 1 si hubo un clic; aumentar el parámetro “b” en 1 si hubo un salto
- Repita hasta que haya usuarios en la cola.
Para comprender la calidad del algoritmo, también guardaremos un valor que representa una proporción de espectadores expuestos a la segunda opción, ya que tiene un CTR "real" más alto. Utilicemos una estrategia dividida 50/50 como contraparte para tener una calidad de referencia.
Código por autor
Después de 1000 usuarios en la cola, nuestro “bandido de múltiples brazos” ya comprende bien cuáles son los CTR.
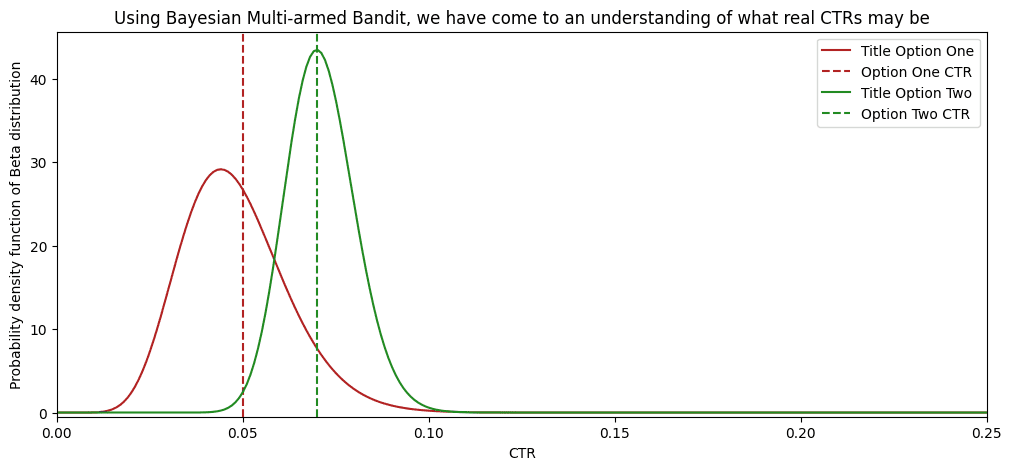
Y aquí hay un gráfico que muestra que dicha estrategia produce mejores resultados. Después de 100 espectadores, el “bandido de múltiples brazos” superó el 50% de los espectadores que ofrecieron la segunda opción. Debido a que cada vez había más evidencia que respaldaba el segundo título, el algoritmo asignó cada vez más tráfico al segundo título. ¡Casi el 80 % de todos los espectadores han visto la opción con mejor rendimiento! Mientras que en la división 50/50, sólo el 50% de las personas ha visto la opción con mejor desempeño.
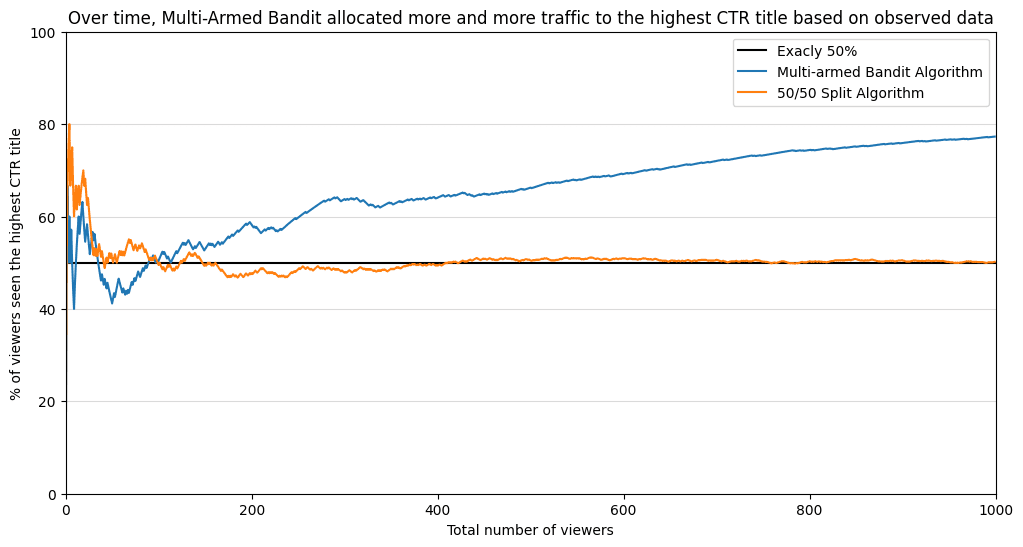
¡Bandido bayesiano con múltiples brazos expuso a un 25% adicional de espectadores a una opción de mejor rendimiento! Con más datos entrantes, la diferencia solo aumentará entre estas dos estrategias.
Por supuesto, los “bandidos armados” no son perfectos. El muestreo y la presentación de opciones en tiempo real son costosos. Lo mejor sería tener una buena infraestructura para implementar todo con la latencia deseada. Además, es posible que no quieras asustar a tus espectadores cambiando los títulos. Si tienes suficiente tráfico para ejecutar un A/B rápido, ¡hazlo! Luego, cambie manualmente el título una vez. Sin embargo, este algoritmo se puede utilizar en muchas otras aplicaciones más allá de los medios.
Espero que ahora entiendas qué es un “bandido de múltiples brazos” y cómo se puede utilizar para elegir entre dos opciones adaptadas a los nuevos datos. Específicamente no me centré en matemáticas y fórmulas ya que los libros de texto las explicarían mejor. ¡Tengo la intención de presentar una nueva tecnología y despertar el interés en ella!
Si tiene alguna pregunta, no dude en comunicarse con Etiqueta LinkedIn.
El cuaderno con todo el código lo puedes encontrar en mi Repositorio GitHub.
Igor Khomyanin es científico de datos en Salmon, con funciones de datos anteriores en Yandex y McKinsey. Me especializo en extraer valor de los datos mediante Estadística y Visualización de Datos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/beyond-guesswork-leveraging-bayesian-statistics-for-effective-article-title-selection?utm_source=rss&utm_medium=rss&utm_campaign=beyond-guesswork-leveraging-bayesian-statistics-for-effective-article-title-selection

