Si ha tenido la oportunidad de crear una aplicación de búsqueda para datos no estructurados (es decir, wiki, sitios web informativos, páginas de ayuda de autoservicio, documentación interna, etc.) utilizando motores de búsqueda de código abierto o comercial, entonces probablemente esté familiarizado con los desafíos de precisión inherentes que implica obtener resultados de búsqueda relevantes. El significado previsto tanto de la consulta como del documento se puede perder porque la búsqueda se reduce a la coincidencia de palabras clave y términos del componente. En consecuencia, si bien obtiene resultados que pueden contener las palabras correctas, no siempre son relevantes para el usuario. Necesita que su motor de búsqueda sea más inteligente para que pueda clasificar los documentos basándose en la coincidencia del significado o la semántica del contenido con la intención de la consulta del usuario.
amazona kendra proporciona un servicio de búsqueda inteligente completamente administrado que automatiza la ingestión de documentos y brinda resultados de búsqueda y preguntas frecuentes altamente precisos basados en el contenido de muchas fuentes de datos. Si no ha migrado a Amazon Kendra y le gustaría mejorar la calidad de los resultados de búsqueda, puede usar Amazon Kendra Intelligent Ranking para OpenSearch autogestionado en su solución de búsqueda existente.
Estamos encantados de presentar el nuevo Clasificación inteligente de Amazon Kendra para OpenSearch autogestionado, y su complemento complementario para el Opensearch ¡buscador! Ahora puede agregar fácilmente una clasificación inteligente a sus consultas de documentos de OpenSearch, sin necesidad de migrar, duplicar sus índices de OpenSearch o reescribir sus aplicaciones. La diferencia entre la clasificación inteligente de Amazon Kendra para OpenSearch autogestionado y el servicio de Amazon Kendra totalmente gestionado es que, mientras que el primero ofrece una potente reclasificación semántica de los resultados de búsqueda, el segundo proporciona mejoras adicionales en la precisión de la búsqueda y funciones como aprendizaje incremental, pregunta respuesta, coincidencia de preguntas frecuentes y conectores integrados. Para obtener más información sobre el servicio completamente administrado, visite el Página de servicio de Amazon Kendra.
Con Amazon Kendra Intelligent Ranking para OpenSearch autogestionado, los resultados anteriores son como este:
consulta: ¿Cuál es la dirección de la Casa Blanca?
Golpe1 (mejor): El presidente pronunció hoy un discurso a la nación desde la Casa Blanca.
Golpe2: La Casa Blanca está ubicada en: 1600 Pennsylvania Avenue NW, Washington, DC 20500
conviértete en esto:
consulta: ¿Cuál es la dirección de la Casa Blanca?
Golpe1 (mejor): La Casa Blanca está ubicada en: 1600 Pennsylvania Avenue NW, Washington, DC 20500
Golpe2: El presidente pronunció hoy un discurso a la nación desde la Casa Blanca.
En esta publicación, le mostramos cómo comenzar con Amazon Kendra Intelligent Ranking para OpenSearch autogestionado y le brindamos algunos ejemplos que demuestran el poder y el valor de esta característica.
Componentes de Amazon Kendra Intelligent Ranking para OpenSearch autogestionado
Requisitos previos
Para este tutorial, necesitará una terminal bash en Linux, Maco Subsistema de Windows para Linux, Y un Cuenta de AWS. Sugerencia: considere usar una instancia de Amazon Cloud9 o un Nube informática elástica de Amazon (Amazon EC2) instancia.
Vas a:
- Instale Docker, si aún no está instalado en su sistema.
- Instala el último Interfaz de línea de comandos de AWS (AWS CLI), si aún no está instalado.
- Cree e inicie contenedores OpenSearch, con el complemento de clasificación inteligente de Amazon Kendra habilitado.
- Cree índices de prueba y cargue algunos documentos de muestra.
- Ejecute algunas consultas, con y sin clasificación inteligente, ¡y déjese impresionar por las diferencias!
Instalar Docker
Si Docker (es decir, docker y docker-compose) aún no está instalado en su entorno, luego instálelo. Ver Obtener ventana acoplable para direcciones.
Instale la CLI de AWS
Si aún no tiene instalada la última versión de AWS CLI, instálela y configúrela ahora (consulte AWS Introducción a la CLI). Sus credenciales de usuario de AWS predeterminadas deben tener acceso de administrador, o solicite a su administrador de AWS que agregue la siguiente política a sus permisos de usuario:
Cree e inicie OpenSearch usando el script de inicio rápido
Descargue nuestra search_processing_kendra_quickstart.sh script:
El script de inicio rápido:
- Crea un plan de ejecución de recuperación de clasificación inteligente de Amazon Kendra en su cuenta de AWS.
- Crea contenedores Docker para OpenSearch y sus paneles.
- Configura OpenSearch para utilizar el servicio de clasificación inteligente de Kendra.
- Inicia los servicios de OpenSearch.
- Proporciona una guía útil para usar el servicio.
Ingrese al --help para ver las opciones de la línea de comandos:
Ahora, ejecute el script para automatizar la configuración de Amazon Kendra y OpenSearch:
¡Eso es! Los contenedores OpenSearch y OpenSearch Dashboard ahora están en funcionamiento.
Lea el mensaje de salida del script de inicio rápido y tome nota del directorio donde puede ejecutar el práctico docker-compose comandos, y el cleanup_resources.sh guión.
Pruebe una consulta de prueba para validar que puede conectarse a su contenedor OpenSearch:
Tenga en cuenta que si obtiene el error curl(35):OpenSSL SSL_connect: SSL_ERROR_SYSCALL in connection to localhost:9200, significa que OpenSearch todavía está disponible. Espere un par de minutos para que OpenSearch esté listo y vuelva a intentarlo.
Cree índices de prueba y cargue documentos de muestra
El siguiente script se utiliza para crear un índice y cargar documentos de muestra. Guárdelo en su computadora como publicación_masiva.sh:
Guarde los archivos de datos a continuación como tinydocs.jsonl:
Y guarde el archivo de datos a continuación como dstinfo.jsonl:
(Estos datos están adaptados de Artículo sobre el horario de verano).
Hacer el script ejecutable:
Ahora usa el publicación_masiva.sh script para crear índices y cargar los datos ejecutando los dos comandos a continuación:
Ejecutar consultas de muestra
Preparar guiones de consulta
Las consultas de OpenSearch se definen en JSON utilizando OpenSearch lenguaje específico de dominio de consulta (DSL). Para esta publicación, usamos el Curl de Linux Comando para enviar consultas a nuestro servidor OpenSearch local usando HTTPS.
Para facilitar esto, hemos definido dos pequeños scripts para construir nuestro DSL de consulta y enviarlo a OpenSearch.
El primer script crea una consulta de coincidencia de texto OpenSearch normal en dos campos de documento: título y cuerpo. Consulte la documentación de OpenSearch para obtener más información sobre sintaxis de consulta de varias coincidencias. Hemos mantenido la consulta muy simple, pero puede experimentar más adelante con la definición de tipos alternativos de consultas.
Guarde el script a continuación como consulta_nokendra.sh:
El segundo script es similar al primero, pero esta vez agregamos una extensión de consulta para indicar a OpenSearch que invoque el complemento de clasificación inteligente de Amazon Kendra como un paso de posprocesamiento para volver a clasificar los resultados originales mediante el servicio de clasificación inteligente de Amazon Kendra.
La size La propiedad determina cuántos documentos de resultados de OpenSearch se envían a Kendra para volver a clasificarlos. Aquí, especificamos un máximo de 20 resultados para volver a clasificar. dos propiedades, title_field (opcional) y body_field (obligatorio), especifique los campos del documento utilizados para la clasificación inteligente.
Guarde el script a continuación como consulta_kendra.sh:
Haga que ambos scripts sean ejecutables:
Ejecutar consultas iniciales
Comience con una simple consulta en el Tinydocs índice, para reproducir el ejemplo utilizado en la introducción de la publicación.
Ingrese al query_nokendra.sh script para buscar la dirección de la Casa Blanca:
Verá los resultados que se muestran a continuación. Observe el orden de los dos resultados, que se clasifican según la puntuación asignada por la consulta de coincidencia de texto de OpenSearch. Aunque el resultado con la puntuación más alta contiene las palabras clave dirección y De la Casa Blanca, está claro que el significado no coincide con la intención de la pregunta. Las palabras clave coinciden, pero la semántica no.
Ahora ejecutemos la consulta con Amazon Kendra Intelligent Ranking, usando el query_kendra.sh script:
Esta vez, verá los resultados en un orden diferente, como se muestra a continuación. El servicio de clasificación inteligente de Amazon Kendra reasignó los valores de puntuación y asignó una puntuación más alta al documento que se acerca más a la intención de la consulta. Desde la perspectiva de las palabras clave, esta es una concordancia más pobre porque no contiene la palabra dirección; sin embargo, desde una perspectiva semántica es la mejor respuesta. ¡Ahora ve el beneficio de usar el complemento de clasificación inteligente de Amazon Kendra!
Ejecute consultas adicionales y compare resultados de búsqueda
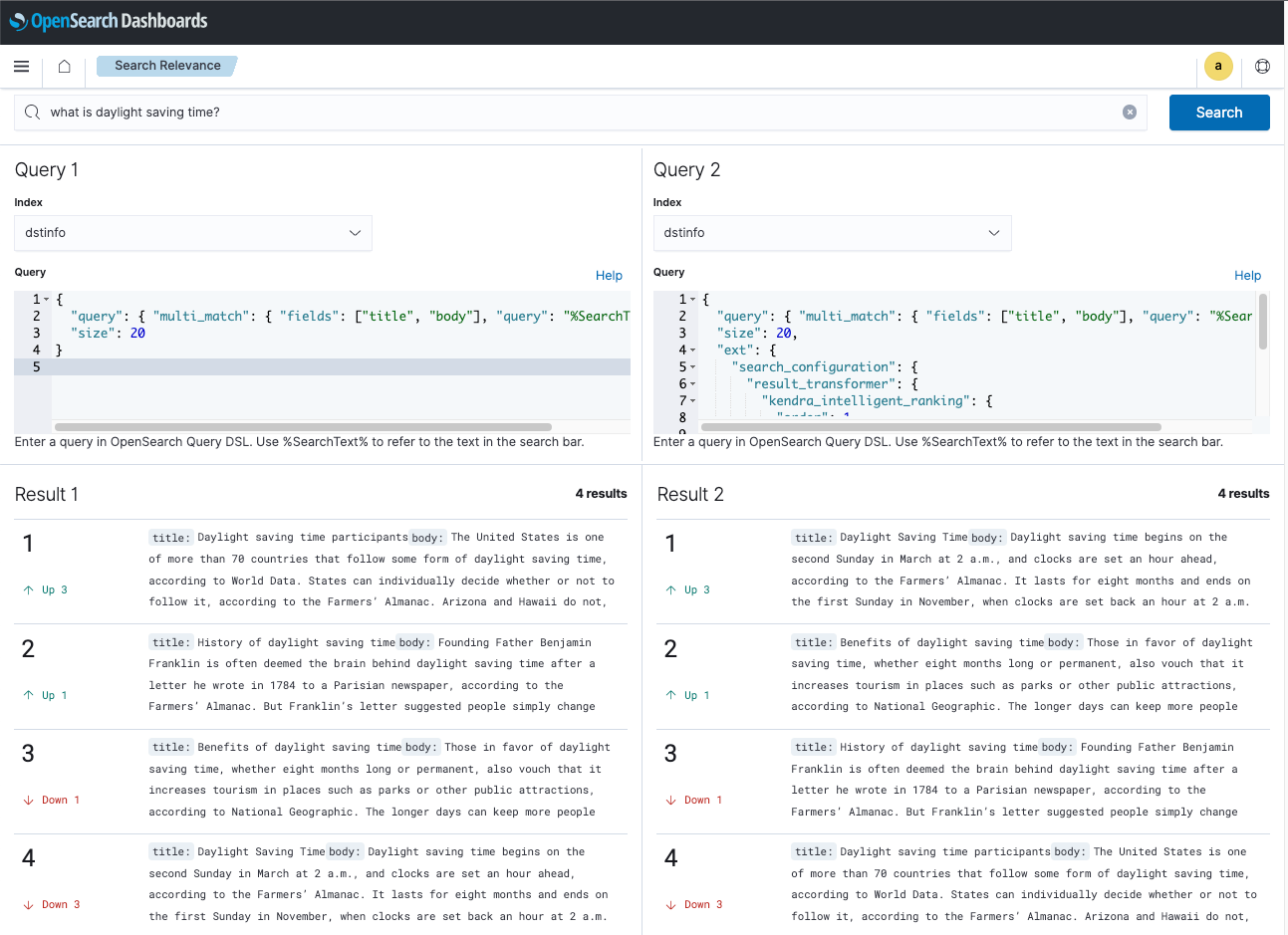
Pruebe el índice dstinfo ahora para ver cómo funciona el mismo concepto con diferentes datos y consultas. Si bien puedes usar los scripts consulta_nokendra.sh y consulta_kendra.sh para hacer consultas desde la línea de comando, usemos en su lugar el OpenSearch Dashboards Complemento de comparación de resultados de búsqueda para ejecutar consultas y comparar resultados de búsqueda.
Pegue la URL de Dashboards local en su navegador: http://localhost:5601/app/searchRelevance – / para acceder a la herramienta de comparación de paneles. Utilice las credenciales predeterminadas: Nombre de usuario: Admin, Contraseña: Admin.
En la barra de búsqueda, ingrese: what is daylight saving time?
Para la Consulta 1 y la Consulta 2 índice, seleccione dstinfo.
Copie la consulta de DSL a continuación y péguela en el Consulta panel bajo Consulta 1. Esta es una consulta de búsqueda de palabras clave.
Ahora copie la consulta DSL a continuación y péguela en el Consulta en el panel Consulta 2. Esta consulta invoca el complemento Clasificación inteligente de Amazon Kendra para OpenSearch autogestionado para realizar una nueva clasificación semántica de los resultados de búsqueda.
Elija el Buscar botón para ejecutar las consultas y observar los resultados de la búsqueda. En el Resultado 1, el hit clasificado en último lugar es probablemente la respuesta más relevante a esta consulta. En el Resultado 2, el resultado de Amazon Kendra Intelligent Ranking tiene la respuesta más relevante clasificada correctamente en primer lugar.
Ahora que ha probado Amazon Kendra Intelligent Ranking para OpenSearch autogestionado, experimente con algunas consultas propias. Usa los datos que ya hemos cargado o usa el publicación_masiva.sh script para cargar sus propios datos.
Explore la API de puntuación de clasificación de Amazon Kendra
Como ha visto en esta publicación, el complemento de clasificación inteligente de Amazon Kendra para OpenSearch se puede usar convenientemente para la reclasificación semántica de sus resultados de búsqueda. Sin embargo, si utiliza un servicio de búsqueda que no es compatible con el complemento de clasificación inteligente de Amazon Kendra para OpenSearch autogestionado, puede utilizar el volver a puntuar función de Amazon Kendra Intelligent Ranking API directamente.
Pruebe esta API utilizando los resultados de búsqueda de la consulta de ejemplo que utilizamos anteriormente: ¿Cuál es la dirección de la Casa Blanca?
Primero, encuentre su ID de plan de ejecución ejecutando:
El JSON a continuación contiene la consulta de búsqueda y los dos resultados que devolvió la consulta de coincidencia original de OpenSearch, con sus puntajes originales de OpenSearch. Reemplazar {kendra-execution-plan_id} con su ID del plan de ejecución (de arriba) y guárdelo como rescore_input.json:
Ejecute el siguiente comando CLI para volver a puntuar esta lista de documentos mediante el servicio de clasificación inteligente de Amazon Kendra:
El resultado de una ejecución exitosa de esto se verá a continuación.
Como era de esperar, el documento tdoc2 (que contiene el cuerpo de texto "La Casa Blanca está ubicada en: 1600 Pennsylvania Avenue NW, Washington, DC 20500”) ahora tiene la clasificación más alta, ya que es la respuesta semánticamente más relevante para la consulta. Él ResultItems la lista en la salida contiene cada entrada DocumentId con su nuevo Score, clasificados en orden descendente de Score.
Limpiar
Cuando haya terminado de experimentar, apague y elimine sus contenedores Docker y el plan de ejecución Rescore ejecutando el cleanup_resources.sh secuencia de comandos creada por la secuencia de comandos de inicio rápido, por ejemplo:
Conclusión
En esta publicación, le mostramos cómo usar el complemento de clasificación inteligente de Amazon Kendra para OpenSearch autogestionado para agregar fácilmente una clasificación inteligente a sus consultas de documentos de OpenSearch para mejorar drásticamente la clasificación de relevancia de los resultados, mientras usa sus implementaciones existentes de motor de búsqueda de OpenSearch.
También puede utilizar el ranking inteligente de Amazon Kendra API de puntuación directamente a vuelve a puntuar y clasificar los resultados de forma inteligente desde sus propias aplicaciones.
Lea el ranking inteligente de Amazon Kendra para OpenSearch autogestionado documentación para obtener más información sobre esta característica y comenzar a planificar su aplicación en sus aplicaciones de producción.
Acerca de los autores
 Abhinav Yawadekar es un Arquitecto Principal de Soluciones enfocado en Amazon Kendra en el equipo de servicios de idiomas AI/ML en AWS. Abhinav trabaja con clientes y socios de AWS para ayudarlos a crear soluciones de búsqueda inteligente en AWS.
Abhinav Yawadekar es un Arquitecto Principal de Soluciones enfocado en Amazon Kendra en el equipo de servicios de idiomas AI/ML en AWS. Abhinav trabaja con clientes y socios de AWS para ayudarlos a crear soluciones de búsqueda inteligente en AWS.
 Bob Strahan es arquitecto principal de soluciones en el equipo de AWS Language AI Services.
Bob Strahan es arquitecto principal de soluciones en el equipo de AWS Language AI Services.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/get-smarter-search-results-with-the-amazon-kendra-intelligent-ranking-and-opensearch-plugin/

