El aprendizaje automático (ML) se vuelve cada vez más complejo a medida que los clientes intentan resolver problemas cada vez más desafiantes. Esta complejidad a menudo conduce a la necesidad de ML distribuido, donde se utilizan varias máquinas para entrenar un único modelo. Aunque esto permite la paralelización de tareas en múltiples nodos, lo que acelera los tiempos de capacitación, una mayor escalabilidad y un mejor rendimiento, existen desafíos importantes en el uso eficaz del hardware distribuido. Los científicos de datos tienen que abordar desafíos como la partición de datos, el equilibrio de carga, la tolerancia a fallas y la escalabilidad. Los ingenieros de ML deben manejar la paralelización, la programación, las fallas y los reintentos manualmente, lo que requiere un código de infraestructura complejo.
En esta publicación, discutimos los beneficios de usar Ray y Amazon SageMaker para ML distribuido y proporciona una guía paso a paso sobre cómo utilizar estos marcos para crear e implementar un flujo de trabajo de ML escalable.
Ray, un marco informático distribuido de código abierto, proporciona un marco flexible para la capacitación distribuida y el servicio de modelos ML. Abstrae los detalles del sistema distribuido de bajo nivel a través de bibliotecas simples y escalables para tareas comunes de aprendizaje automático, como el preprocesamiento de datos, el entrenamiento distribuido, el ajuste de hiperparámetros, el aprendizaje por refuerzo y el servicio de modelos.
SageMaker es un servicio totalmente administrado para crear, entrenar e implementar modelos de ML. Ray se integra perfectamente con las funciones de SageMaker para crear e implementar cargas de trabajo de aprendizaje automático complejas que sean eficientes y confiables. La combinación de Ray y SageMaker proporciona capacidades de un extremo a otro para flujos de trabajo de aprendizaje automático escalables y tiene las siguientes características destacadas:
- Los actores distribuidos y las construcciones de paralelismo en Ray simplifican el desarrollo de aplicaciones distribuidas.
- Ray AI Runtime (AIR) reduce la fricción al pasar del desarrollo a la producción. Con Ray y AIR, el mismo código Python se puede escalar sin problemas desde una computadora portátil hasta un clúster grande.
- La infraestructura administrada de SageMaker y funciones como trabajos de procesamiento, trabajos de capacitación y trabajos de ajuste de hiperparámetros pueden usar las bibliotecas de Ray subyacentes para la computación distribuida.
- Experimentos de Amazon SageMaker permite iterar rápidamente y realizar un seguimiento de las pruebas.
- Tienda de funciones de Amazon SageMaker proporciona un repositorio escalable para almacenar, recuperar y compartir funciones de aprendizaje automático para el entrenamiento de modelos.
- Los modelos entrenados se pueden almacenar, versionar y rastrear en Registro de modelos de Amazon SageMaker para la gobernanza y la gestión.
- Canalizaciones de Amazon SageMaker permite orquestar el ciclo de vida de ML de un extremo a otro, desde la preparación y capacitación de datos hasta la implementación de modelos como flujos de trabajo automatizados.
Resumen de la solución
Esta publicación se centra en los beneficios de usar Ray y SageMaker juntos. Configuramos un flujo de trabajo de aprendizaje automático basado en Ray de un extremo a otro, orquestado mediante SageMaker Pipelines. El flujo de trabajo incluye la ingesta paralela de datos en el almacén de características usando actores Ray, preprocesamiento de datos con Ray Data, modelos de entrenamiento y ajuste de hiperparámetros a escala usando Ray Train y trabajos de ajuste de optimización de hiperparámetros (HPO) y, finalmente, evaluación del modelo y registro del modelo en un registro de modelos.
Para nuestros datos utilizamos un conjunto de datos de vivienda sintética que consta de ocho características (YEAR_BUILT, SQUARE_FEET, NUM_BEDROOM, NUM_BATHROOMS, LOT_ACRES, GARAGE_SPACES, FRONT_PORCHy DECK) y nuestro modelo predecirá la PRICE de la casa.
Cada etapa del flujo de trabajo de ML se divide en pasos discretos, con su propio script que toma parámetros de entrada y salida. En la siguiente sección, destacamos fragmentos de código clave de cada paso. El código completo se puede encontrar en el Repositorio GitHub de aws-samples-for-ray.
Requisitos previos
Para utilizar el SDK de SageMaker Python y ejecutar el código asociado con esta publicación, necesita los siguientes requisitos previos:
Ingerir datos en SageMaker Feature Store
El primer paso en el flujo de trabajo de ML es leer el archivo de datos de origen desde Servicio de almacenamiento simple de Amazon (Amazon S3) en formato CSV e ingerirlo en SageMaker Feature Store. SageMaker Feature Store es un repositorio diseñado específicamente que facilita a los equipos crear, compartir y administrar funciones de aprendizaje automático. Simplifica el descubrimiento, la reutilización y el uso compartido de funciones, lo que conduce a un desarrollo más rápido, una mayor colaboración dentro de los equipos de los clientes y una reducción de costos.
La ingesta de funciones en el almacén de funciones contiene los siguientes pasos:
- Defina un grupo de características y cree el grupo de características en la tienda de características.
- Prepare los datos de origen para el almacén de funciones agregando una hora del evento y un ID de registro para cada fila de datos.
- Incorpore los datos preparados al grupo de funciones utilizando el SDK de Boto3.
En esta sección, solo destacamos el Paso 3, porque esta es la parte que involucra el procesamiento paralelo de la tarea de ingesta usando Ray. Puede revisar el código completo de este proceso en el Repositorio GitHub.
El proyecto características_ingesta El método se define dentro de una clase llamada Featurestore. Tenga en cuenta que el Featurestore La clase está decorada con @ray.remote. Esto indica que una instancia de esta clase es un actor de Ray, una unidad computacional con estado y concurrente dentro de Ray. Es un modelo de programación que le permite crear objetos distribuidos que mantienen un estado interno y a los que pueden acceder simultáneamente múltiples tareas que se ejecutan en diferentes nodos en un clúster de Ray. Los actores proporcionan una forma de gestionar y encapsular el estado mutable, lo que los hace valiosos para crear aplicaciones complejas con estado en un entorno distribuido. También puede especificar requisitos de recursos en los actores. En este caso, cada instancia de la FeatureStore La clase requerirá 0.5 CPU. Vea el siguiente código:
@ray.remote(num_cpus=0.5)
class Featurestore: def ingest_features(self,feature_group_name, df, region): """ Ingest features to Feature Store Group Args: feature_group_name (str): Feature Group Name data_path (str): Path to the train/validation/test data in CSV format. """ ...Puedes interactuar con el actor llamando al remote operador. En el siguiente código, la cantidad deseada de actores se pasa como argumento de entrada al script. Luego, los datos se dividen en función del número de actores y se pasan a procesos paralelos remotos para que se incorporen al almacén de funciones. Puedes llamar get en la referencia del objeto para bloquear la ejecución de la tarea actual hasta que se complete el cálculo remoto y el resultado esté disponible. Cuando el resultado esté disponible, ray.get devolverá el resultado y la ejecución de la tarea actual continuará.
import modin.pandas as pd
import ray df = pd.read_csv(s3_path)
data = prepare_df_for_feature_store(df)
# Split into partitions
partitions = [ray.put(part) for part in np.array_split(data, num_actors)]
# Start actors and assign partitions in a loop
actors = [Featurestore.remote() for _ in range(args.num_actors)]
results = [] for actor, partition in zip(actors, input_partitions): results.append(actor.ingest_features.remote( args.feature_group_name, partition, args.region ) ) ray.get(results)Preparar datos para entrenamiento, validación y pruebas.
En este paso, utilizamos Ray Dataset para dividir, transformar y escalar de manera eficiente nuestro conjunto de datos en preparación para el aprendizaje automático. Ray Dataset proporciona una forma estándar de cargar datos distribuidos en Ray y admite varios sistemas de almacenamiento y formatos de archivo. Tiene API para operaciones comunes de preprocesamiento de datos de ML, como transformaciones paralelas, barajado, agrupación y agregaciones. Ray Dataset también maneja operaciones que necesitan configuración con estado y aceleración de GPU. Se integra perfectamente con otras bibliotecas de procesamiento de datos como Spark, Pandas, NumPy y más, así como con marcos de aprendizaje automático como TensorFlow y PyTorch. Esto permite crear canalizaciones de datos de un extremo a otro y flujos de trabajo de aprendizaje automático sobre Ray. El objetivo es facilitar el procesamiento de datos distribuidos y el aprendizaje automático a los profesionales e investigadores.
Veamos las secciones de los scripts que realizan este preprocesamiento de datos. Comenzamos cargando los datos del almacén de funciones:
def load_dataset(feature_group_name, region): """ Loads the data as a ray dataset from the offline featurestore S3 location Args: feature_group_name (str): name of the feature group Returns: ds (ray.data.dataset): Ray dataset the contains the requested dat from the feature store """ session = sagemaker.Session(boto3.Session(region_name=region)) fs_group = FeatureGroup( name=feature_group_name, sagemaker_session=session ) fs_data_loc = fs_group.describe().get("OfflineStoreConfig").get("S3StorageConfig").get("ResolvedOutputS3Uri") # Drop columns added by the feature store # Since these are not related to the ML problem at hand cols_to_drop = ["record_id", "event_time","write_time", "api_invocation_time", "is_deleted", "year", "month", "day", "hour"] ds = ray.data.read_parquet(fs_data_loc) ds = ds.drop_columns(cols_to_drop) print(f"{fs_data_loc} count is {ds.count()}") return ds
Luego dividimos y escalamos los datos utilizando las abstracciones de nivel superior disponibles en ray.data biblioteca:
def split_dataset(dataset, train_size, val_size, test_size, random_state=None): """ Split dataset into train, validation and test samples Args: dataset (ray.data.Dataset): input data train_size (float): ratio of data to use as training dataset val_size (float): ratio of data to use as validation dataset test_size (float): ratio of data to use as test dataset random_state (int): Pass an int for reproducible output across multiple function calls. Returns: train_set (ray.data.Dataset): train dataset val_set (ray.data.Dataset): validation dataset test_set (ray.data.Dataset): test dataset """ # Shuffle this dataset with a fixed random seed. shuffled_ds = dataset.random_shuffle(seed=random_state) # Split the data into train, validation and test datasets train_set, val_set, test_set = shuffled_ds.split_proportionately([train_size, val_size]) return train_set, val_set, test_set def scale_dataset(train_set, val_set, test_set, target_col): """ Fit StandardScaler to train_set and apply it to val_set and test_set Args: train_set (ray.data.Dataset): train dataset val_set (ray.data.Dataset): validation dataset test_set (ray.data.Dataset): test dataset target_col (str): target col Returns: train_transformed (ray.data.Dataset): train data scaled val_transformed (ray.data.Dataset): val data scaled test_transformed (ray.data.Dataset): test data scaled """ tranform_cols = dataset.columns() # Remove the target columns from being scaled tranform_cols.remove(target_col) # set up a standard scaler standard_scaler = StandardScaler(tranform_cols) # fit scaler to training dataset print("Fitting scaling to training data and transforming dataset...") train_set_transformed = standard_scaler.fit_transform(train_set) # apply scaler to validation and test datasets print("Transforming validation and test datasets...") val_set_transformed = standard_scaler.transform(val_set) test_set_transformed = standard_scaler.transform(test_set) return train_set_transformed, val_set_transformed, test_set_transformed
Los conjuntos de datos de entrenamiento, validación y prueba procesados se almacenan en Amazon S3 y se pasarán como parámetros de entrada a los pasos posteriores.
Realizar entrenamiento de modelos y optimización de hiperparámetros.
Con nuestros datos preprocesados y listos para modelar, es hora de entrenar algunos modelos de ML y ajustar sus hiperparámetros para maximizar el rendimiento predictivo. Usamos Rayo XGBoost, un backend distribuido para XGBoost construido en Ray que permite entrenar modelos XGBoost en grandes conjuntos de datos mediante el uso de múltiples nodos y GPU. Proporciona reemplazos simples para entrenar y predecir API de XGBoost mientras maneja las complejidades de la administración de datos distribuidos y la capacitación interna.
Para permitir la distribución de la capacitación en múltiples nodos, utilizamos una clase auxiliar llamada RayHelper. Como se muestra en el siguiente código, utilizamos la configuración de recursos del trabajo de capacitación y elegimos el primer host como nodo principal:
class RayHelper(): def __init__(self, ray_port:str="9339", redis_pass:str="redis_password"): .... self.resource_config = self.get_resource_config() self.head_host = self.resource_config["hosts"][0] self.n_hosts = len(self.resource_config["hosts"])Podemos usar la información del host para decidir cómo inicializar Ray en cada una de las instancias del trabajo de capacitación:
def start_ray(self): head_ip = self._get_ip_from_host() # If the current host is the host choosen as the head node # run `ray start` with specifying the --head flag making this is the head node if self.resource_config["current_host"] == self.head_host: output = subprocess.run(['ray', 'start', '--head', '-vvv', '--port', self.ray_port, '--redis-password', self.redis_pass, '--include-dashboard', 'false'], stdout=subprocess.PIPE) print(output.stdout.decode("utf-8")) ray.init(address="auto", include_dashboard=False) self._wait_for_workers() print("All workers present and accounted for") print(ray.cluster_resources()) else: # If the current host is not the head node, # run `ray start` with specifying ip address as the head_host as the head node time.sleep(10) output = subprocess.run(['ray', 'start', f"--address={head_ip}:{self.ray_port}", '--redis-password', self.redis_pass, "--block"], stdout=subprocess.PIPE) print(output.stdout.decode("utf-8")) sys.exit(0)
Cuando se inicia un trabajo de entrenamiento, se puede inicializar un clúster de Ray llamando al start_ray() método en una instancia de RayHelper:
if __name__ == '__main__': ray_helper = RayHelper() ray_helper.start_ray() args = read_parameters() sess = sagemaker.Session(boto3.Session(region_name=args.region))
Luego utilizamos el entrenador XGBoost de XGBoost-Ray para entrenar:
def train_xgboost(ds_train, ds_val, params, num_workers, target_col = "price") -> Result: """ Creates a XGBoost trainer, train it, and return the result. Args: ds_train (ray.data.dataset): Training dataset ds_val (ray.data.dataset): Validation dataset params (dict): Hyperparameters num_workers (int): number of workers to distribute the training across target_col (str): target column Returns: result (ray.air.result.Result): Result of the training job """ train_set = RayDMatrix(ds_train, 'PRICE') val_set = RayDMatrix(ds_val, 'PRICE') evals_result = {} trainer = train( params=params, dtrain=train_set, evals_result=evals_result, evals=[(val_set, "validation")], verbose_eval=False, num_boost_round=100, ray_params=RayParams(num_actors=num_workers, cpus_per_actor=1), ) output_path=os.path.join(args.model_dir, 'model.xgb') trainer.save_model(output_path) valMAE = evals_result["validation"]["mae"][-1] valRMSE = evals_result["validation"]["rmse"][-1] print('[3] #011validation-mae:{}'.format(valMAE)) print('[4] #011validation-rmse:{}'.format(valRMSE)) local_testing = False try: load_run(sagemaker_session=sess) except: local_testing = True if not local_testing: # Track experiment if using SageMaker Training with load_run(sagemaker_session=sess) as run: run.log_metric('validation-mae', valMAE) run.log_metric('validation-rmse', valRMSE)
Tenga en cuenta que al crear una instancia del trainer, pasamos RayParams, que toma el número de actores y el número de CPU por actor. XGBoost-Ray utiliza esta información para distribuir el entrenamiento entre todos los nodos conectados al clúster de Ray.
Ahora creamos un objeto estimador XGBoost basado en el SDK de Python de SageMaker y lo usamos para el trabajo de HPO.
Orqueste los pasos anteriores utilizando SageMaker Pipelines
Para crear un flujo de trabajo de aprendizaje automático escalable y reutilizable de un extremo a otro, necesitamos utilizar una herramienta de CI/CD para organizar los pasos anteriores en una canalización. SageMaker Pipelines tiene integración directa con SageMaker, SageMaker Python SDK y SageMaker Studio. Esta integración le permite crear flujos de trabajo de ML con un SDK de Python fácil de usar y luego visualizar y administrar su flujo de trabajo usando SageMaker Studio. También puede realizar un seguimiento del historial de sus datos dentro de la ejecución del canal y designar pasos para el almacenamiento en caché.
SageMaker Pipelines crea un gráfico acíclico dirigido (DAG) que incluye los pasos necesarios para crear un flujo de trabajo de aprendizaje automático. Cada canalización es una serie de pasos interconectados orquestados por dependencias de datos entre pasos y se puede parametrizar, lo que le permite proporcionar variables de entrada como parámetros para cada ejecución de la canalización. SageMaker Pipelines tiene cuatro tipos de parámetros de canalización: ParameterString, ParameterInteger, ParameterFloaty ParameterBoolean. En esta sección, parametrizamos algunas de las variables de entrada y configuramos la configuración del almacenamiento en caché de pasos:
processing_instance_count = ParameterInteger( name='ProcessingInstanceCount', default_value=1
)
feature_group_name = ParameterString( name='FeatureGroupName', default_value='fs-ray-synthetic-housing-data'
)
bucket_prefix = ParameterString( name='Bucket_Prefix', default_value='aws-ray-mlops-workshop/feature-store'
)
rmse_threshold = ParameterFloat(name="RMSEThreshold", default_value=15000.0) train_size = ParameterString( name='TrainSize', default_value="0.6"
)
val_size = ParameterString( name='ValidationSize', default_value="0.2"
)
test_size = ParameterString( name='TestSize', default_value="0.2"
) cache_config = CacheConfig(enable_caching=True, expire_after="PT12H")
Definimos dos pasos de procesamiento: uno para la ingesta del almacén de funciones de SageMaker y el otro para la preparación de datos. Esto debería ser muy similar a los pasos anteriores descritos anteriormente. La única nueva línea de código es la ProcessingStep después de la definición de los pasos, lo que nos permite tomar la configuración del trabajo de procesamiento e incluirla como un paso de la canalización. Además, especificamos la dependencia del paso de preparación de datos del paso de ingesta del almacén de funciones de SageMaker. Vea el siguiente código:
feature_store_ingestion_step = ProcessingStep( name='FeatureStoreIngestion', step_args=fs_processor_args, cache_config=cache_config
) preprocess_dataset_step = ProcessingStep( name='PreprocessData', step_args=processor_args, cache_config=cache_config
)
preprocess_dataset_step.add_depends_on([feature_store_ingestion_step])
De manera similar, para construir un paso de entrenamiento y ajuste del modelo, necesitamos agregar una definición de TuningStep después del código del paso de entrenamiento del modelo para permitirnos ejecutar el ajuste de hiperparámetros de SageMaker como un paso en el proceso:
tuning_step = TuningStep( name="HPTuning", tuner=tuner, inputs={ "train": TrainingInput( s3_data=preprocess_dataset_step.properties.ProcessingOutputConfig.Outputs[ "train" ].S3Output.S3Uri, content_type="text/csv" ), "validation": TrainingInput( s3_data=preprocess_dataset_step.properties.ProcessingOutputConfig.Outputs[ "validation" ].S3Output.S3Uri, content_type="text/csv" ) }, cache_config=cache_config,
)
tuning_step.add_depends_on([preprocess_dataset_step])
Después del paso de ajuste, elegimos registrar el mejor modelo en el Registro de modelos de SageMaker. Para controlar la calidad del modelo, implementamos una puerta de calidad mínima que compara la métrica objetiva del mejor modelo (RMSE) con un umbral definido como el parámetro de entrada del pipeline. rmse_threshold. Para hacer esta evaluación, creamos otro paso de procesamiento para ejecutar un guión de evaluación. El resultado de la evaluación del modelo se almacenará como un archivo de propiedades. Los archivos de propiedades son particularmente útiles cuando se analizan los resultados de un paso de procesamiento para decidir cómo se deben ejecutar otros pasos. Vea el siguiente código:
# Specify where we'll store the model evaluation results so that other steps can access those results
evaluation_report = PropertyFile( name='EvaluationReport', output_name='evaluation', path='evaluation.json',
) # A ProcessingStep is used to evaluate the performance of a selected model from the HPO step. # In this case, the top performing model is evaluated. evaluation_step = ProcessingStep( name='EvaluateModel', processor=evaluation_processor, inputs=[ ProcessingInput( source=tuning_step.get_top_model_s3_uri( top_k=0, s3_bucket=bucket, prefix=s3_prefix ), destination='/opt/ml/processing/model', ), ProcessingInput( source=preprocess_dataset_step.properties.ProcessingOutputConfig.Outputs['test'].S3Output.S3Uri, destination='/opt/ml/processing/test', ), ], outputs=[ ProcessingOutput( output_name='evaluation', source='/opt/ml/processing/evaluation' ), ], code='./pipeline_scripts/evaluate/script.py', property_files=[evaluation_report],
)
Definimos una ModelStep para registrar el mejor modelo en el Registro de modelos de SageMaker en nuestra cartera. En caso de que el mejor modelo no pase nuestro control de calidad predeterminado, especificamos adicionalmente un FailStep para generar un mensaje de error:
register_step = ModelStep( name='RegisterTrainedModel', step_args=model_registry_args
) metrics_fail_step = FailStep( name="RMSEFail", error_message=Join(on=" ", values=["Execution failed due to RMSE >", rmse_threshold]),
)
A continuación, usamos un ConditionStep para evaluar si el paso de registro del modelo o el paso de falla deben tomarse a continuación en el proceso. En nuestro caso, se registrará el mejor modelo si su puntuación RMSE es inferior al umbral.
# Condition step for evaluating model quality and branching execution
cond_lte = ConditionLessThanOrEqualTo( left=JsonGet( step_name=evaluation_step.name, property_file=evaluation_report, json_path='regression_metrics.rmse.value', ), right=rmse_threshold,
)
condition_step = ConditionStep( name='CheckEvaluation', conditions=[cond_lte], if_steps=[register_step], else_steps=[metrics_fail_step],
)Finalmente, organizamos todos los pasos definidos en una canalización:
pipeline_name = 'synthetic-housing-training-sm-pipeline-ray'
step_list = [ feature_store_ingestion_step, preprocess_dataset_step, tuning_step, evaluation_step, condition_step ] training_pipeline = Pipeline( name=pipeline_name, parameters=[ processing_instance_count, feature_group_name, train_size, val_size, test_size, bucket_prefix, rmse_threshold ], steps=step_list
) # Note: If an existing pipeline has the same name it will be overwritten.
training_pipeline.upsert(role_arn=role_arn)
La canalización anterior se puede visualizar y ejecutar directamente en SageMaker Studio, o ejecutarse llamando execution = training_pipeline.start(). La siguiente figura ilustra el flujo de la tubería.
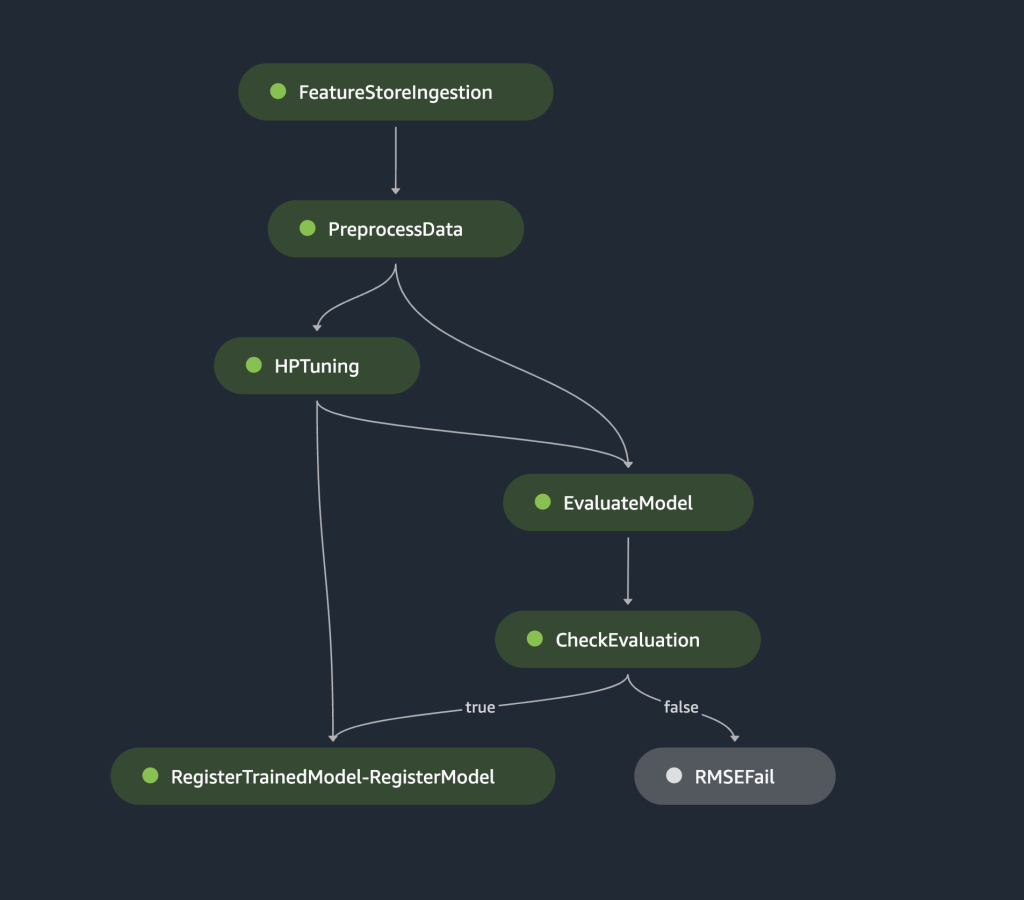
Además, podemos revisar el linaje de artefactos generados por la ejecución de la canalización.
from sagemaker.lineage.visualizer import LineageTableVisualizer viz = LineageTableVisualizer(sagemaker.session.Session())
for execution_step in reversed(execution.list_steps()): print(execution_step) display(viz.show(pipeline_execution_step=execution_step)) time.sleep(5)
Implementar el modelo
Después de registrar el mejor modelo en el Registro de modelos de SageMaker mediante una ejecución de canalización, implementamos el modelo en un punto final en tiempo real utilizando las capacidades de implementación de modelos totalmente administradas de SageMaker. SageMaker tiene otras opciones de implementación de modelos para satisfacer las necesidades de diferentes casos de uso. Para más detalles, consulte Implementar modelos para inferencia al elegir la opción correcta para su caso de uso. Primero, registremos el modelo en el Registro de modelos de SageMaker:
xgb_regressor_model = ModelPackage( role_arn, model_package_arn=model_package_arn, name=model_name
)El estado actual del modelo es PendingApproval. Necesitamos establecer su estado en Approved antes del despliegue:
sagemaker_client.update_model_package( ModelPackageArn=xgb_regressor_model.model_package_arn, ModelApprovalStatus='Approved'
) xgb_regressor_model.deploy( initial_instance_count=1, instance_type='ml.m5.xlarge', endpoint_name=endpoint_name
)
Limpiar
Una vez que haya terminado de experimentar, recuerde limpiar los recursos para evitar cargos innecesarios. Para limpiar, elimine el punto final en tiempo real, el grupo de modelos, la canalización y el grupo de funciones llamando a las API. Eliminar punto final, Eliminar grupo de paquetes de modelos, Eliminar canalizacióny Eliminar grupo de funciones, respectivamente, y cierre todas las instancias del cuaderno de SageMaker Studio.
Conclusión
Esta publicación demostró un tutorial paso a paso sobre cómo usar SageMaker Pipelines para orquestar flujos de trabajo de aprendizaje automático basados en Ray. También demostramos la capacidad de SageMaker Pipelines para integrarse con herramientas de aprendizaje automático de terceros. Existen varios servicios de AWS que admiten cargas de trabajo de Ray de forma escalable y segura para garantizar la excelencia en el rendimiento y la eficiencia operativa. Ahora es su turno de explorar estas poderosas capacidades y comenzar a optimizar sus flujos de trabajo de aprendizaje automático con Amazon SageMaker Pipelines y Ray. ¡Tome acción hoy y libere todo el potencial de sus proyectos de ML!
Sobre la autora
 Raju Rangan es arquitecto senior de soluciones en Amazon Web Services (AWS). Trabaja con entidades patrocinadas por el gobierno, ayudándolas a crear soluciones de IA/ML utilizando AWS. Cuando no esté jugando con soluciones en la nube, lo verá pasando el rato con su familia o haciendo birdies en un animado juego de bádminton con amigos.
Raju Rangan es arquitecto senior de soluciones en Amazon Web Services (AWS). Trabaja con entidades patrocinadas por el gobierno, ayudándolas a crear soluciones de IA/ML utilizando AWS. Cuando no esté jugando con soluciones en la nube, lo verá pasando el rato con su familia o haciendo birdies en un animado juego de bádminton con amigos.
 Jerez Ding es arquitecto senior de soluciones especializado en IA/ML en Amazon Web Services (AWS). Tiene una amplia experiencia en aprendizaje automático con un doctorado en informática. Trabaja principalmente con clientes del sector público en diversos desafíos comerciales relacionados con la IA/ML, ayudándolos a acelerar su viaje de aprendizaje automático en la nube de AWS. Cuando no ayuda a los clientes, disfruta de las actividades al aire libre.
Jerez Ding es arquitecto senior de soluciones especializado en IA/ML en Amazon Web Services (AWS). Tiene una amplia experiencia en aprendizaje automático con un doctorado en informática. Trabaja principalmente con clientes del sector público en diversos desafíos comerciales relacionados con la IA/ML, ayudándolos a acelerar su viaje de aprendizaje automático en la nube de AWS. Cuando no ayuda a los clientes, disfruta de las actividades al aire libre.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/orchestrate-ray-based-machine-learning-workflows-using-amazon-sagemaker/

