Introducción
A medida que 2023 llega a su fin, la noticia interesante para la comunidad de visión por computadora es que Google ha avanzado recientemente en el mundo de la detección de objetos de disparo cero con el lanzamiento de OWLv2. Este modelo de vanguardia ya está disponible en 🤗 Transformers y representa uno de los sistemas de detección de objetos de disparo cero más robustos hasta la fecha. Se basa en los cimientos establecidos por OWL-ViT v1, que se introdujo el año pasado.
En este artículo, presentaremos el comportamiento y la arquitectura de este modelo y veremos un enfoque práctico sobre cómo ejecutar la inferencia. Empecemos.
OBJETIVOS DE APRENDIZAJE
- Comprender el concepto de detección de objetos de disparo cero en visión por computadora.
- Conozca la tecnología y el enfoque de autoformación detrás del modelo OWLv2 de Google.
- Un enfoque práctico para usar OWLv2.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
La tecnología detrás de OWLv2
Las impresionantes capacidades de OWLv2 se pueden atribuir a su novedoso enfoque de autoformación. El modelo se entrenó en un conjunto de datos a escala web que comprende más de mil millones de ejemplos. Para lograr esto, los autores aprovecharon el poder de OWL-ViT v1, usándolo para generar pseudoetiquetas, que a su vez se usaron para entrenar OWLv1.
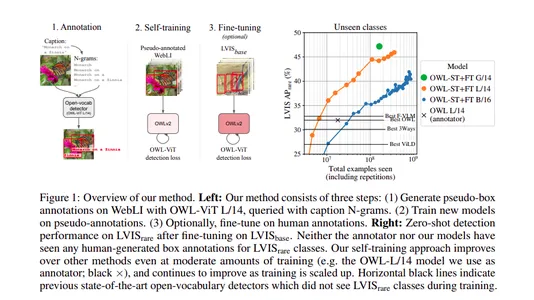
Además, el modelo se sometió a ajustes en los datos de detección, lo que resultó en mejoras de rendimiento con respecto a su predecesor, OWL-ViT v1. La autoformación abre la posibilidad de una formación a escala web para la localización en mundos abiertos, reflejando las tendencias observadas en la clasificación de objetos y el modelado de lenguajes.
Arquitectura OWLv2
Si bien la arquitectura de OWLv2 es similar a la de OWL-ViT, hay una adición notable a su cabezal de detección de objetos. Ahora incluye un clasificador de objetividad que predice la probabilidad de que un cuadro predicho contenga un objeto. La puntuación de objetividad brinda información y se puede utilizar para clasificar o filtrar predicciones independientemente de las consultas de texto.
Detección de objetos de disparo cero
El aprendizaje de disparo cero es una nueva terminología que se ha vuelto popular desde la tendencia de GenAI. Se ve comúnmente en el ajuste fino del modelo de lenguaje grande (LLM). Implica ajustar los modelos base utilizando algunos datos para que un modelo se extienda a nuevas categorías. La detección de objetos de disparo cero cambia las reglas del juego en el campo de la visión por computadora. Se trata de capacitar a los modelos para que detecten objetos en imágenes sin la necesidad de cuadros delimitadores anotados manualmente. Esto no sólo acelera el proceso sino que también elimina las anotaciones manuales, lo que lo hace más emocionante para los humanos y menos aburrido.
¿Cómo utilizar OWLv2?
OWLv2 sigue un enfoque similar a OWL-ViT pero presenta un procesador de imágenes actualizado, Owlv2ImageProcessor. Además, el modelo se basa en CLIPTokenizer para codificar texto. Owlv2Processor es una herramienta útil que combina Owlv2ImageProcessor y CLIPTokenizer, simplificando el proceso de codificación de texto. A continuación se muestra un ejemplo de cómo realizar la detección de objetos utilizando Owlv2Processor y Owlv2ForObjectDetection.
Encuentre el código completo aquí: https://github.com/inuwamobarak/OWLv2
Paso 1: configurar el entorno
En este paso, comenzamos instalando la 🤗 biblioteca Transformers de GitHub.
# Install the 🤗 Transformers library from GitHub.
!pip install -q git+https://github.com/huggingface/transformers.gitPaso 2: cargar modelo y procesador
Aquí, cargamos un punto de control OWLv2 desde el centro. Tenga en cuenta que las opciones de puntos de control están disponibles y, en este ejemplo, cargamos un punto de control de conjunto.
# Cargue un punto de control OWLv2 desde el concentrador.
desde transformadores importe Owlv2Processor, Owlv2ForObjectDetection
# Cargue el procesador y el modelo.
procesador = Owlv2Processor.from_pretrained(“google/owlv2-base-patch16-ensemble”)
modelo = Owlv2ForObjectDetection.from_pretrained(“google/owlv2-base-patch16-ensemble”)
# Load an OWLv2 checkpoint from the hub.
from transformers import Owlv2Processor, Owlv2ForObjectDetection # Load the processor and model.
processor = Owlv2Processor.from_pretrained("google/owlv2-base-patch16-ensemble")
model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")Paso 3: cargar y procesar imágenes
En este paso, cargamos una imagen en la que queremos detectar objetos.
# Load an image that you want to analyze.
from huggingface_hub import hf_hub_download
from PIL import Image # Replace the file paths accordingly.
filepath = hf_hub_download(repo_id="adirik/OWL-ViT", repo_type="space", filename="assets/astronaut.png")
image = Image.open(filepath)
Paso 4: preparar la imagen y las consultas para el modelo
OWLv2 es capaz de detectar objetos dadas consultas de texto. En este paso, preparamos las consultas de imagen y texto para el modelo usando el procesador.
# Define the text queries that you want the model to detect.
texts = [['face', 'bag', 'shoe', 'hair']] # Prepare the image and text for the model using the processor.
inputs = processor(text=texts, images=image, return_tensors="pt") # Print the shapes of input tensors.
for key, val in inputs.items(): print(f"{key}: {val.shape}")Paso 5: pase hacia adelante
En este paso, reenviamos las entradas a través del modelo. Usamos torch.no_grad() para reducir el uso de memoria ya que no necesitamos gradientes en el momento de la inferencia.
# Import the torch library.
import torch # Perform a forward pass through the model.
with torch.no_grad(): outputs = model(**inputs)Paso 6: visualizar los resultados
En este paso final, convertimos las salidas del modelo al formato COCO API y visualizamos los resultados dibujando cuadros delimitadores y etiquetas en la imagen.
# Convert model outputs to COCO API format.
target_sizes = torch.Tensor([image.size[::-1]])
results = processor.post_process_object_detection(outputs=outputs, target_sizes=target_sizes, threshold=0.2) # Retrieve predictions for the first image.
i = 0
text = texts[i]
boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"] # Draw bounding boxes and labels on the image.
from PIL import ImageDraw
draw = ImageDraw.Draw(image) for box, score, label in zip(boxes, scores, labels): box = [round(i, 2) for i in box.tolist()] x1, y1, x2, y2 = tuple(box) draw.rectangle(xy=((x1, y1), (x2, y2)), outline="red") draw.text(xy=(x1, y1), text=text[label]) # Display the image with bounding boxes and labels.
image
Detección de objetos de un solo disparo guiada por imágenes
Realizamos la detección de objetos de un solo disparo guiada por imágenes utilizando OWLv2. Esto significa que detectamos objetos en una nueva imagen según una imagen de consulta de ejemplo.
Código: https://github.com/inuwamobarak/OWLv2
# Import necessary libraries
# %matplotlib inline # Uncomment this line for compatibility if using Jupyter Notebook.
import cv2
from PIL import Image
import requests
import torch
from matplotlib import rcParams
import matplotlib.pyplot as plt # Set the figure size
rcParams['figure.figsize'] = 11, 8 # Load the input image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
target_sizes = torch.Tensor([image.size[::-1]) # Load the query image
query_url = "http://images.cocodataset.org/val2017/000000058111.jpg"
query_image = Image.open(requests.get(query_url, stream=True).raw) # Display the input image and query image side by side.
fig, ax = plt.subplots(1, 2)
ax[0].imshow(image)
ax[1].imshow(query_image)
Después de cargar las dos imágenes, preprocesamos la entrada e imprimimos la forma.
# Define the device to use for processing.
device = "cuda" if torch.cuda.is_available() else "cpu" # Process input and query images using the preprocessor.
inputs = processor(images=image, query_images=query_image, return_tensors="pt").to(device) # Print the input names and shapes.
for key, val in inputs.items(): print(f"{key}: {val.shape}")A continuación, realizamos la detección de objetos guiada por imágenes. Imprimimos las formas de los resultados del modelo, incluidos los resultados del modelo de visión.
# Perform image-guided object detection using the model.
with torch.no_grad(): outputs = model.image_guided_detection(**inputs) # Print the shapes of the model's outputs.
for k, val in outputs.items(): if k not in {"text_model_output", "vision_model_output"}: print(f"{k}: shape of {val.shape}") print("nVision model outputs")
for k, val in outputs.vision_model_output.items(): print(f"{k}: shape of {val.shape}")Finalmente, visualizamos los resultados dibujando cuadros delimitadores en la imagen. El código maneja la conversión de la imagen al formato RGB y posprocesa los resultados de la detección.
# Visualize the results
import numpy as np # Convert the image to RGB format.
img = cv2.cvtColor(np.array(image), cv2.COLOR_BGR2RGB)
outputs.logits = outputs.logits.cpu()
outputs.target_pred_boxes = outputs.target_pred_boxes.cpu() # Post-process the detection results.
results = processor.post_process_image_guided_detection(outputs=outputs, threshold=0.9, nms_threshold=0.3, target_sizes=target_sizes)
boxes, scores = results[0]["boxes"], results[0]["scores"] # Draw bounding boxes on the image.
for box, score in zip(boxes, scores): box = [int(i) for i in box.tolist()] img = cv2.rectangle(img, box[:2], box[2:], (255, 0, 0), 5) if box[3] + 25 > 768: y = box[3] - 10 else: y = box[3] + 25 # Display the image with predicted bounding boxes.
plt.imshow(img[:, :, ::-1])
Ampliación de la detección de objetos de vocabulario abierto
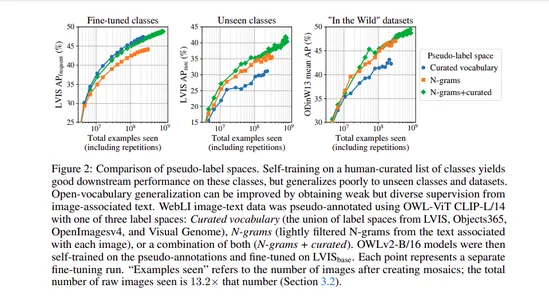
La detección de objetos de vocabulario abierto se ha beneficiado de modelos de visión y lenguaje previamente entrenados. Sin embargo, a menudo se ve obstaculizado por la disponibilidad limitada de datos de entrenamiento de detección. Para abordar esto, los autores recurrieron al autoentrenamiento y a detectores existentes para generar anotaciones de pseudocuadros en pares de imagen y texto. La ampliación del autoentrenamiento presenta su propio conjunto de desafíos, incluida la elección del espacio de etiqueta, el filtrado de pseudoanotaciones y la eficiencia del entrenamiento.
OWLv2 y la receta de autoentrenamiento OWL-ST se han desarrollado para superar estos desafíos. Como resultado, OWLv2 ahora supera el rendimiento de detectores de vocabulario abierto de última generación anteriores, incluso en escalas de entrenamiento similares de alrededor de 10 millones de ejemplos.
Impresionante rendimiento y escalamiento
El rendimiento de OWLv2 es realmente impresionante. Con una arquitectura L/14, OWL-ST mejora la precisión promedio (AP) en clases raras de LVIS. Incluso cuando el modelo no ha visto anotaciones de cuadros humanos para estas clases raras, logra esta mejora, con AP aumentando del 31.2 % al 44.6 %.
La capacidad de OWL-ST para escalar a más de mil millones de ejemplos significa un logro en el entrenamiento a escala web para la localización de mundos abiertos, similar a lo que hemos presenciado en la clasificación de objetos y el modelado de lenguaje.
Conclusión
OWLv2 y la innovadora receta de autoentrenamiento OWL-ST representan un paso adelante en la detección de objetos de disparo cero. Estos avances prometen remodelar el panorama de la visión por computadora al hacer que sea más fácil y eficiente detectar objetos en imágenes sin la necesidad de cuadros delimitadores anotados manualmente. Le animamos a explorar OWLv2 y sus aplicaciones en sus proyectos. Las posibilidades son interesantes y estamos ansiosos por ver cómo la comunidad de visión por computadora aprovecha esta tecnología para soluciones innovadoras.
Puntos clave
- OWLv2 es el último modelo de Google para la detección de objetos sin disparo, disponible en 🤗 Transformers, y se basa en la versión anterior, OWL-ViT v1.
- La detección de objetos de disparo cero elimina la necesidad de cuadros delimitadores anotados manualmente, lo que hace que el proceso sea más eficiente y menos tedioso.
- OWLv2 utiliza la autoformación en un conjunto de datos a escala web de más de mil millones de ejemplos y aprovecha las pseudoetiquetas de OWL-ViT v1 para mejorar el rendimiento.
Preguntas frecuentes
R1: La detección de objetos de disparo cero es una forma para que los modelos detecten objetos en imágenes sin la necesidad de cuadros delimitadores anotados manualmente. Es importante porque agiliza el proceso de detección de objetos y lo hace menos laborioso.
A2: La autoformación implica el uso de un detector existente para generar anotaciones de pseudocuadro en pares de imagen y texto. OWLv2 aprovecha este enfoque de autoformación para mejorar el rendimiento y la escalabilidad.
R3: El clasificador de objetividad en el cabezal de detección de objetos de OWLv2 predice la probabilidad de que un cuadro predicho contenga un objeto. Utilice esta información para clasificar o filtrar predicciones independientemente de las consultas de texto.
R4: Utilice OWLv2 con procesadores como Owlv2ImageProcessor, CLIPTokenizer y Owlv2Processor para realizar la detección de objetos condicionados por texto. Ejemplos prácticos están disponibles en el artículo.
R5: La autoformación aborda desafíos como la elección del espacio de etiquetas, el filtrado de pseudoanotaciones y la detección de objetos de vocabulario abierto a escala de capacitación.
R6: Las capacidades de OWLv2 tienen el potencial de beneficiar las aplicaciones de visión por computadora, incluida la detección de objetos, la comprensión de imágenes y más. Los investigadores y desarrolladores pueden aprovechar esta tecnología para encontrar soluciones innovadoras.
Enlaces de referencia
- https://github.com/inuwamobarak/OWLv2
- https://huggingface.co/docs/transformers/main/en/model_doc/owlv2
- https://arxiv.org/abs/2306.09683
- https://huggingface.co/docs/transformers/main/en/model_doc/owlvit
- https://arxiv.org/abs/2205.06230
- Minderer, M., Gritsenko, A. y Houlsby, N. (2023). Ampliación de la detección de objetos de vocabulario abierto. ArXiv. /abs/2306.09683
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/10/owlv2-googles-breakthrough-in-zero-shot-object-detection/

