Amazon Polly es un servicio que convierte texto en voz real. Permite el desarrollo de toda una clase de aplicaciones que pueden convertir texto en voz en varios idiomas.
Este servicio puede ser utilizado por chatbots, audiolibros y otras aplicaciones de texto a voz junto con otros servicios de aprendizaje automático (ML) o IA de AWS. Por ejemplo, Amazon lex y Amazon Polly se pueden combinar para crear un chatbot que participe en una conversación bidireccional con un usuario y realice ciertas tareas según los comandos del usuario. Amazon Transcribe, Traductor de Amazony Amazon Polly se pueden combinar para transcribir voz a texto en el idioma de origen, traducirlo a un idioma diferente y hablarlo.
En esta publicación, presentamos un enfoque interesante para resaltar texto a medida que se habla utilizando Amazon Polly. Esta solución se puede utilizar en muchas aplicaciones de texto a voz para hacer lo siguiente:
- Agregue capacidades visuales al audio en libros, sitios web y blogs
- Aumente la comprensión cuando los clientes intentan entender el texto rápidamente mientras se habla.
Nuestra solución le brinda al cliente (el navegador, en este ejemplo), la capacidad de saber qué texto (palabra u oración) está pronunciando Amazon Polly en cualquier momento. Esto permite que el cliente resalte dinámicamente el texto a medida que se habla. Tal capacidad es útil para proporcionar ayuda visual al habla para los casos de uso mencionados anteriormente.
Nuestra solución se puede ampliar para realizar tareas adicionales además de resaltar texto. Por ejemplo, el navegador puede mostrar imágenes, reproducir música o realizar otras animaciones en la interfaz mientras se habla el texto. Esta capacidad es útil para crear audiolibros dinámicos, contenido educativo y aplicaciones de texto a voz más ricas.
Resumen de la solución
En esencia, la solución utiliza Amazon Polly para convertir una cadena de texto en voz. El texto se puede ingresar desde el navegador o a través de una llamada API al punto final expuesto por nuestra solución. El discurso generado por Amazon Polly se almacena como un archivo de audio (formato MP3) en un Servicio de almacenamiento simple de Amazon (Amazon S3) cubo.
Sin embargo, usando solo el archivo de audio, el navegador no puede encontrar qué partes del texto se pronuncian en ningún momento porque no tenemos información granular sobre cuándo se pronuncia cada palabra.
Amazon Polly proporciona una forma de obtener esto mediante marcas de voz. Las marcas de voz se almacenan en un archivo de texto que muestra el tiempo (medido en milisegundos desde el inicio del audio) cuando se pronuncia cada palabra u oración.
Amazon Polly devuelve objetos de marca de voz en un flujo JSON delimitado por líneas. Un objeto de marca de voz contiene los siguientes campos:
- Horario – La marca de tiempo en milisegundos desde el comienzo de la transmisión de audio correspondiente
- Tipo de Propiedad – El tipo de marca de voz (oración, palabra, visema o SSML)
- Inicio – El desplazamiento en bytes (no caracteres) del inicio del objeto en el texto de entrada (sin incluir las marcas de visema)
- Fin – El desplazamiento en bytes (no caracteres) del final del objeto en el texto de entrada (sin incluir las marcas de visema)
- Valor – Esto varía según el tipo de marca de voz:
- SSML – etiqueta SSML
- visema – El nombre del visema
- palabra o sentencia – Una subcadena del texto de entrada delimitada por los campos de inicio y finalización
Por ejemplo, la oración "María tenía un corderito" puede proporcionarle el siguiente archivo de marcas de voz si usa SpeechMarkTypes = [“palabra”, “oración”] en la llamada a la API para obtener las marcas de voz:
La palabra "tenía" (al final de la línea 3) comienza 373 milisegundos después de que comienza la transmisión de audio, comienza en el byte 5 y termina en el byte 8 del texto de entrada.
Descripción de la arquitectura
La arquitectura de nuestra solución se presenta en el siguiente diagrama.
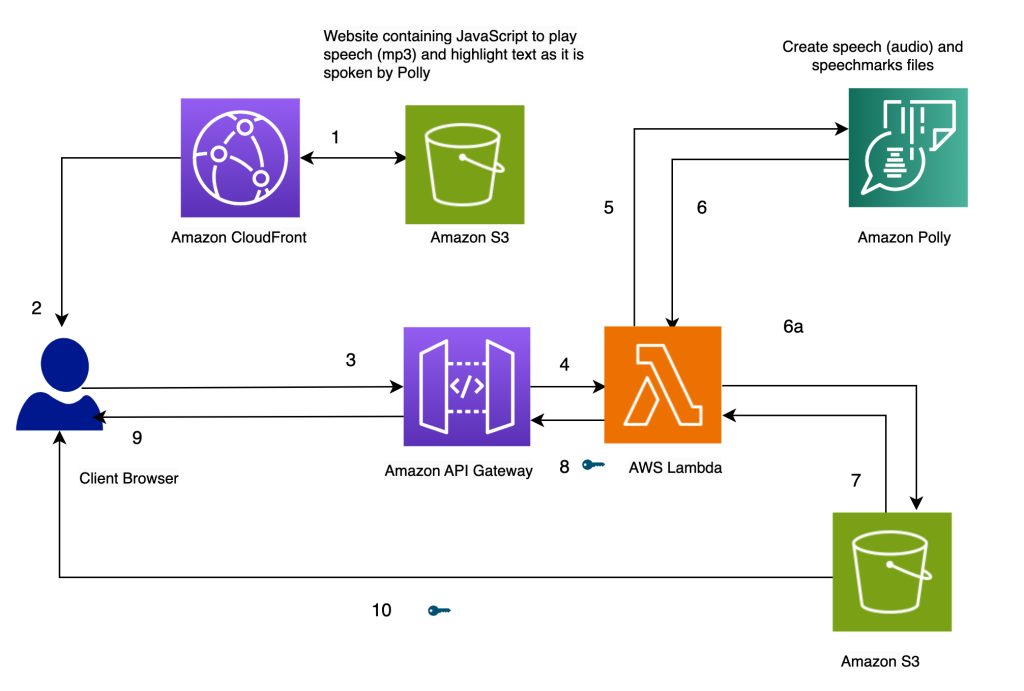
Resalte el texto a medida que se habla, utilizando Amazon Polly
Nuestro sitio web para la solución se almacena en Amazon S3 como archivos estáticos (JavaScript, HTML), que se alojan en Amazon CloudFront (1) y servido al navegador del usuario final (2).
Cuando el usuario ingresa texto en el navegador a través de un formulario HTML simple, JavaScript lo procesa en el navegador. Esto llama a una API (3) a través de Puerta de enlace API de Amazon, para invocar un AWS Lambda función (4). La función Lambda llama a Amazon Polly (5) para generar archivos de voz (audio) y marcas de voz (JSON). Se realizan dos llamadas a Amazon Polly para obtener los archivos de audio y marcas de voz. Las llamadas se realizan mediante funciones asíncronas de JavaScript. El resultado de estas llamadas son los archivos de marcas de voz y audio, que se almacenan en Amazon S3 (6a). Para evitar que varios usuarios sobrescriban los archivos de los demás en el depósito de S3, los archivos se almacenan en una carpeta con una marca de tiempo. Esto minimiza las posibilidades de que dos usuarios sobrescriban los archivos de los demás en Amazon S3. Para una versión de producción, podemos emplear enfoques más sólidos para segregar los archivos de los usuarios en función de la identificación del usuario o la marca de tiempo y otras características únicas.
La función Lambda crea direcciones URL prefirmadas para los archivos de voz y marcas de voz y los devuelve al navegador en forma de matriz (7, 8, 9).
Cuando el navegador envía el archivo de texto al extremo de la API (3), obtiene dos URL prefirmadas para el archivo de audio y el archivo de marcas de voz en una invocación síncrona (9). Esto se indica con el símbolo de llave al lado de la flecha.
Una función de JavaScript en el navegador obtiene el archivo de marcas de voz y el audio de sus identificadores de URL (10). Configura el reproductor de audio para reproducir el audio. (La etiqueta de audio HTML se usa para este propósito).
Cuando el usuario hace clic en el botón de reproducción, analiza las marcas de voz recuperadas en el paso anterior para crear una serie de eventos cronometrados utilizando tiempos de espera. Los eventos invocan una función de devolución de llamada, que es otra función de JavaScript utilizada para resaltar el texto hablado en el navegador. Simultáneamente, la función de JavaScript transmite el archivo de audio desde su identificador de URL.
El resultado es que los eventos se ejecutan en los momentos apropiados para resaltar el texto a medida que se habla mientras se reproduce el audio. El uso de tiempos de espera de JavaScript nos proporciona la sincronización del audio con el texto resaltado.
Requisitos previos
Para ejecutar esta solución, necesita un Cuenta de AWS con una Gestión de identidades y accesos de AWS (IAM) usuario que tiene permiso para utilizar Amazon CloudFront, Amazon API Gateway, Amazon Polly, Amazon S3, AWS Lambda y AWS Step Functions.
Use Lambda para generar voz y marcas de voz
El siguiente código invoca a Amazon Polly synthesize_speech función dos veces para obtener el archivo de marcas de audio y voz. Se ejecutan como funciones asincrónicas y se coordinan para devolver el resultado al mismo tiempo mediante promesas.
En el lado de JavaScript, el resaltado de texto se realiza mediante resaltador (inicio, finalización, palabra) y los eventos cronometrados se establecen mediante setTimers():
Aproximaciones alternativas
En lugar del enfoque anterior, puede considerar algunas alternativas:
- Cree tanto las marcas de voz como los archivos de audio dentro de una máquina de estado de Step Functions. La máquina de estado puede invocar la condición de bifurcación paralela para invocar dos funciones Lambda diferentes: una para generar voz y otra para generar marcas de voz. El código para esto se puede encontrar en el uso de funciones de paso subcarpeta en el repositorio de Github.
- Invoque Amazon Polly de forma asíncrona para generar las marcas de audio y voz. Este enfoque se puede usar si el contenido del texto es grande o si el usuario no necesita una respuesta en tiempo real. Para obtener más detalles sobre la creación de archivos de audio largos, consulte Creación de archivos de audio largos.
- Haga que Amazon Polly cree la URL prefirmada directamente usando el
generate_presigned_urlllame al cliente de Amazon Polly en Boto3. Si opta por este enfoque, Amazon Polly genera las marcas de audio y voz cada vez. En nuestro enfoque actual, almacenamos estos archivos en Amazon S3. Aunque no se puede acceder a estos archivos almacenados desde el navegador en nuestra versión del código, puede modificar el código para reproducir archivos de audio generados previamente al obtenerlos de Amazon S3 (en lugar de regenerar el audio para el texto nuevamente usando Amazon Polly). tenemos mas ejemplos de código para acceder a Amazon Polly con Python en la biblioteca de códigos de AWS.
Crea la solución
La solución completa está disponible en nuestro Repo de Github. Para crear esta solución en su cuenta, siga las instrucciones del archivo README.md. La solución incluye un Formación en la nube de AWS plantilla para aprovisionar sus recursos.
Limpiar
Para limpiar los recursos creados en esta demostración, realice los siguientes pasos:
- Elimine los cubos de S3 creados para almacenar la plantilla de CloudFormation (Cubo A), el código fuente (Cubo B) y el sitio web (
pth-cf-text-highlighter-website-[Suffix]). - Eliminar la pila de CloudFormation
pth-cf. - Elimine el depósito S3 que contiene los archivos de voz (
pth-speech-[Suffix]). Este depósito fue creado por la plantilla de CloudFormation para almacenar los archivos de marcas de audio y voz generados por Amazon Polly.
Resumen
En esta publicación, mostramos un ejemplo de una solución que puede resaltar texto a medida que se habla utilizando Amazon Polly. Fue desarrollado utilizando la función de marcas de voz de Amazon Polly, que nos proporciona marcadores para el lugar donde comienza cada palabra u oración en un archivo de audio.
La solución está disponible como plantilla de CloudFormation. Se puede implementar tal cual en cualquier aplicación web que realice la conversión de texto a voz. Esto sería útil para agregar capacidades visuales al audio en libros, avatares con capacidades de sincronización de labios (usando marcas de voz de visema), sitios web y blogs, y para ayudar a las personas con discapacidad auditiva.
Se puede ampliar para realizar tareas adicionales además de resaltar texto. Por ejemplo, el navegador puede mostrar imágenes, reproducir música y realizar otras animaciones en la interfaz mientras se habla el texto. Esta capacidad puede ser útil para crear audiolibros dinámicos, contenido educativo y aplicaciones de texto a voz más completas.
Lo invitamos a probar esta solución y obtener más información sobre los servicios de AWS relevantes en los siguientes enlaces. Puede ampliar la funcionalidad para sus necesidades específicas.
Sobre la autora
 Varad G Varadarajan es un asesor de confianza y CTO de campo para clientes de Digital Native Businesses (DNB) en AWS. Los ayuda a diseñar y crear soluciones innovadoras a escala con los productos y servicios de AWS. Las áreas de interés de Varad son la consultoría estratégica de TI, la arquitectura y la gestión de productos. Fuera del trabajo, Varad disfruta de la escritura creativa, ver películas con familiares y amigos y viajar.
Varad G Varadarajan es un asesor de confianza y CTO de campo para clientes de Digital Native Businesses (DNB) en AWS. Los ayuda a diseñar y crear soluciones innovadoras a escala con los productos y servicios de AWS. Las áreas de interés de Varad son la consultoría estratégica de TI, la arquitectura y la gestión de productos. Fuera del trabajo, Varad disfruta de la escritura creativa, ver películas con familiares y amigos y viajar.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/highlight-text-as-its-being-spoken-using-amazon-polly/

