
Imagen de Freepik
La IA conversacional se refiere a agentes virtuales y chatbots que imitan las interacciones humanas y pueden involucrar a los seres humanos en una conversación. El uso de IA conversacional se está convirtiendo rápidamente en una forma de vida: desde preguntarle a Alexa hasta "encontrar el restaurante más cercano” a pedirle a Siri que “crear un recordatorio " Los asistentes virtuales y los chatbots se utilizan a menudo para responder las preguntas de los consumidores, resolver quejas, hacer reservas y mucho más.
Desarrollar estos asistentes virtuales requiere un esfuerzo sustancial. Sin embargo, comprender y abordar los desafíos clave puede agilizar el proceso de desarrollo. He utilizado mi experiencia de primera mano en la creación de un chatbot maduro para una plataforma de contratación como punto de referencia para explicar los desafíos clave y sus correspondientes soluciones.
Para crear un chatbot conversacional de IA, los desarrolladores pueden utilizar marcos como RASA, Lex de Amazon o Dialogflow de Google para crear chatbots. La mayoría prefiere RASA cuando planean cambios personalizados o el bot está en una etapa madura, ya que es un marco de código abierto. Otros marcos también son adecuados como punto de partida.
Los desafíos se pueden clasificar en tres componentes principales de un chatbot.
Comprensión del lenguaje natural (NLU) es la capacidad de un robot para comprender el diálogo humano. Realiza clasificación de intenciones, extracción de entidades y recuperación de respuestas.
Gerente de Diálogo es responsable de un conjunto de acciones que se realizarán en función del conjunto actual y anterior de entradas del usuario. Toma la intención y las entidades como entrada (como parte de la conversación anterior) e identifica la siguiente respuesta.
Generación de lenguaje natural (NLG) es el proceso de generar oraciones escritas o habladas a partir de datos dados. Enmarca la respuesta, que luego se presenta al usuario.
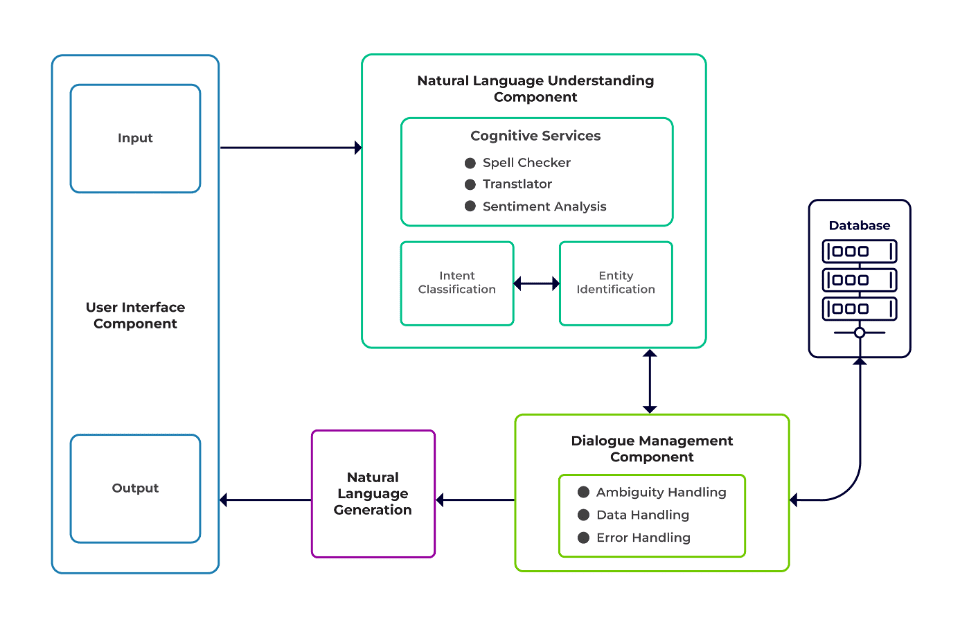
Imagen de Talentica Software
Datos insuficientes
Cuando los desarrolladores reemplazan las preguntas frecuentes u otros sistemas de soporte con un chatbot, obtienen una cantidad decente de datos de capacitación. Pero no ocurre lo mismo cuando crean el bot desde cero. En tales casos, los desarrolladores generan datos de entrenamiento de forma sintética.
¿Qué hacer?
Un generador de datos basado en plantillas puede generar una cantidad decente de consultas de usuarios para capacitación. Una vez que el chatbot esté listo, los propietarios del proyecto pueden exponerlo a un número limitado de usuarios para mejorar los datos de capacitación y actualizarlos durante un período.
Selección de modelo inadecuado
La selección adecuada del modelo y los datos de entrenamiento son cruciales para obtener los mejores resultados de extracción de entidades e intenciones. Los desarrolladores suelen entrenar chatbots en un idioma y dominio específicos, y la mayoría de los modelos previamente entrenados disponibles suelen ser de dominio específico y estar entrenados en un solo idioma.
También puede haber casos de lenguas mixtas en las que las personas son políglotas. Es posible que ingresen consultas en un idioma mixto. Por ejemplo, en una región dominada por los franceses, la gente puede utilizar un tipo de inglés que sea una mezcla de francés e inglés.
¿Qué hacer?
El uso de modelos entrenados en varios idiomas podría reducir el problema. Un modelo previamente entrenado como LaBSE (incrustación de oraciones Bert independiente del lenguaje) puede resultar útil en tales casos. LaBSE está capacitado en más de 109 idiomas en una tarea de similitud de oraciones. El modelo ya conoce palabras similares en otro idioma. En nuestro proyecto, funcionó muy bien.
Extracción de entidad incorrecta
Los chatbots requieren que las entidades identifiquen qué tipo de datos está buscando el usuario. Estas entidades incluyen hora, lugar, persona, elemento, fecha, etc. Sin embargo, los robots pueden no identificar una entidad en el lenguaje natural:
Mismo contexto pero diferentes entidades. Por ejemplo, los robots pueden confundir un lugar con una entidad cuando un usuario escribe "Nombre de los estudiantes de IIT Delhi" y luego "Nombre de los estudiantes de Bengaluru".
Escenarios en los que las entidades se predicen erróneamente con baja confianza. Por ejemplo, un bot puede identificar a IIT Delhi como una ciudad con poca confianza.
Extracción parcial de entidades mediante modelo de aprendizaje automático. Si un usuario escribe "estudiantes de IIT Delhi", el modelo solo puede identificar "IIT" como una entidad en lugar de "IIT Delhi".
Las entradas de una sola palabra que no tienen contexto pueden confundir los modelos de aprendizaje automático. Por ejemplo, una palabra como “Rishikesh” puede significar tanto el nombre de una persona como el de una ciudad.
¿Qué hacer?
Agregar más ejemplos de capacitación podría ser una solución. Pero hay un límite después del cual agregar más no ayudaría. Además, es un proceso interminable. Otra solución podría ser definir patrones de expresiones regulares utilizando palabras predefinidas para ayudar a extraer entidades con un conjunto conocido de valores posibles, como ciudad, país, etc.
Los modelos comparten una menor confianza cuando no están seguros de la predicción de la entidad. Los desarrolladores pueden usar esto como disparador para llamar a un componente personalizado que puede rectificar la entidad de baja confianza. Consideremos el ejemplo anterior. Si IIT Delhi se predice como una ciudad con baja confianza, entonces el usuario siempre puede buscarla en la base de datos. Después de no poder encontrar la entidad predicha en el Ciudad tabla, el modelo procedería a otras tablas y, eventualmente, la encontraría en la Innovadora tabla, lo que resulta en la corrección de la entidad.
Clasificación de intención incorrecta
Cada mensaje de usuario tiene alguna intención asociada. Dado que las intenciones derivan del siguiente curso de acciones de un bot, es crucial clasificar correctamente las consultas de los usuarios con intención. Sin embargo, los desarrolladores deben identificar las intenciones con una confusión mínima entre ellas. De lo contrario, puede haber casos llenos de confusión. Por ejemplo, "Muéstrame las posiciones abiertas” versus “Muéstrame candidatos para puestos vacantes”.
¿Qué hacer?
Hay dos formas de diferenciar consultas confusas. En primer lugar, un desarrollador puede introducir una subintención. En segundo lugar, los modelos pueden manejar consultas basadas en entidades identificadas.
Un chatbot de dominio específico debe ser un sistema cerrado donde debe identificar claramente de qué es capaz y de qué no. Los desarrolladores deben realizar el desarrollo en fases mientras planifican los chatbots de dominios específicos. En cada fase, pueden identificar las funciones no compatibles del chatbot (mediante una intención no compatible).
También pueden identificar lo que el chatbot no puede manejar en la intención "fuera de alcance". Pero podría haber casos en los que el bot se confunda con una intención no compatible y fuera de alcance. Para tales escenarios, debe existir un mecanismo de respaldo donde, si la confianza de la intención está por debajo de un umbral, el modelo pueda funcionar correctamente con un intento de respaldo para manejar casos de confusión.
Una vez que el bot identifica la intención del mensaje de un usuario, debe enviar una respuesta. Bot decide la respuesta basándose en un determinado conjunto de reglas e historias definidas. Por ejemplo, una regla puede ser tan simple como "Buenos días" cuando el usuario saluda "Hola". Sin embargo, la mayoría de las veces, las conversaciones con chatbots comprenden una interacción de seguimiento y sus respuestas dependen del contexto general de la conversación.
¿Qué hacer?
Para manejar esto, los chatbots se alimentan con ejemplos de conversaciones reales llamados Historias. Sin embargo, los usuarios no siempre interactúan como se esperaba. Un chatbot maduro debería manejar todas estas desviaciones con elegancia. Los diseñadores y desarrolladores pueden garantizar esto si no sólo se centran en un camino feliz mientras escriben historias, sino que también trabajan en caminos infelices.
La interacción del usuario con los chatbots depende en gran medida de las respuestas del chatbot. Los usuarios pueden perder el interés si las respuestas son demasiado robóticas o demasiado familiares. Por ejemplo, es posible que a un usuario no le guste una respuesta como "Ha escrito una consulta incorrecta" por una entrada incorrecta, aunque la respuesta sea correcta. La respuesta aquí no coincide con la personalidad de un asistente.
¿Qué hacer?
El chatbot actúa como asistente y debe poseer una personalidad y un tono de voz específicos. Deben ser acogedores y humildes, y los desarrolladores deben diseñar conversaciones y declaraciones en consecuencia. Las respuestas no deben parecer robóticas o mecánicas. Por ejemplo, el robot podría decir: "Lo siento, parece que no tengo ningún detalle. ¿Podría volver a escribir su consulta? para abordar una entrada incorrecta.
Los chatbots basados en LLM (Large Language Model) como ChatGPT y Bard son innovaciones revolucionarias y han mejorado las capacidades de las IA conversacionales. No sólo son buenos para entablar conversaciones abiertas, similares a las de los humanos, sino que también pueden realizar diferentes tareas como resúmenes de texto, redacción de párrafos, etc., que antes sólo podían lograrse mediante modelos específicos.
Uno de los desafíos de los sistemas de chatbot tradicionales es categorizar cada oración en intenciones y decidir la respuesta en consecuencia. Este enfoque no es práctico. Respuestas como “Lo siento, no pude comunicarme contigo” suelen ser irritantes. Los sistemas de chatbot sin intención son el camino a seguir y los LLM pueden hacerlo realidad.
Los LLM pueden lograr fácilmente resultados de última generación en el reconocimiento general de entidades con nombre, salvo cierto reconocimiento de entidades de dominio específico. Un enfoque mixto para el uso de LLM con cualquier marco de chatbot puede inspirar un sistema de chatbot más maduro y sólido.
Con los últimos avances y la investigación continua en IA conversacional, los chatbots mejoran cada día. Áreas como la gestión de tareas complejas con múltiples propósitos, como “reservar un vuelo a Mumbai y conseguir un taxi a Dadar”, están recibiendo mucha atención.
Pronto se llevarán a cabo conversaciones personalizadas basadas en las características del usuario para mantenerlo interesado. Por ejemplo, si un bot descubre que el usuario no está contento, redirige la conversación a un agente real. Además, con datos de chatbot cada vez mayores, las técnicas de aprendizaje profundo como ChatGPT pueden generar automáticamente respuestas a consultas utilizando una base de conocimientos.
Suman Saurav es científico de datos en Talentica Software, una empresa de desarrollo de productos de software. Es alumno de NIT Agartala con más de 8 años de experiencia diseñando e implementando soluciones revolucionarias de IA utilizando PNL, IA conversacional e IA generativa.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them

