Amazon DynamoDB es una base de datos NoSQL de valor clave, sin servidor y totalmente administrada, diseñada para ejecutar aplicaciones de alto rendimiento a cualquier escala. DynamoDB ofrece seguridad integrada, copias de seguridad continuas, replicación automatizada en varias regiones, almacenamiento en caché en memoria y herramientas de importación y exportación de datos. La escalabilidad y el esquema de datos flexible de DynamoDB lo hacen ideal para una variedad de casos de uso. Estos incluyen aplicaciones web y móviles a escala de Internet, almacenes de metadatos de baja latencia, sitios web minoristas de alto tráfico, Internet de las cosas (IoT) y datos de series temporales, juegos en línea y más.
Los datos almacenados en DynamoDB son la base de valiosos conocimientos de inteligencia empresarial (BI). Para que estos datos sean accesibles para los analistas de datos y otros consumidores, puede utilizar Atenea amazónica. Athena es un servicio interactivo sin servidor que le permite consultar datos de una variedad de fuentes en formatos heterogéneos, sin esfuerzo de aprovisionamiento. Athena accede a los datos almacenados en DynamoDB a través del código abierto Conector de Amazon Athena DynamoDB. Los metadatos de la tabla, como los nombres de las columnas y los tipos de datos, se almacenan utilizando el Catálogo de datos de AWS Glue.
Finalmente, para visualizar conocimientos de BI, puede utilizar Amazon QuickSight, un servicio de análisis empresarial basado en la nube. QuickSight facilita que las organizaciones creen visualizaciones, realicen análisis ad hoc y obtengan rápidamente información empresarial a partir de sus datos, en cualquier momento y en cualquier dispositivo. Es capacidades de BI generativas le permite hacer preguntas sobre sus datos utilizando lenguaje natural, sin tener que escribir consultas SQL o aprender una herramienta de BI.
Esta publicación muestra cómo puede utilizar el conector Athena DynamoDB para consultar fácilmente datos en DynamoDB con SQL y visualizar información en QuickSight.
Resumen de la solución
El siguiente diagrama ilustra la arquitectura de la solución.
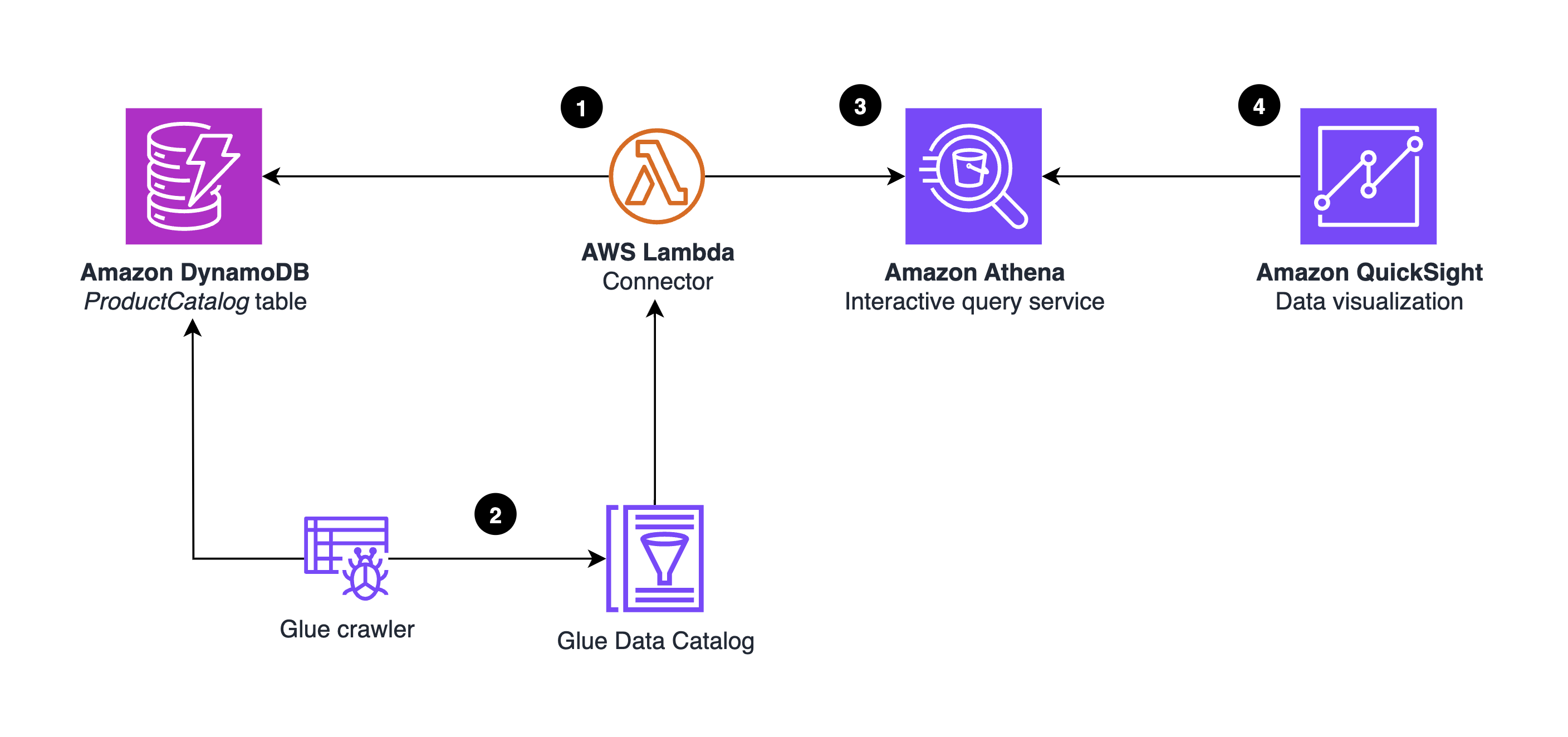
- El conector Athena DynamoDB se ejecuta en un sistema prediseñado sin servidor. AWS Lambda función. No es necesario escribir ningún código.
- Pegamento AWS proporciona metadatos complementarios de la tabla de DynamoDB. En particular, un Rastreador de AWS Glue se ejecuta para inferir y almacenar el formato de la tabla de DynamoDB, el esquema y las propiedades asociadas en el Catálogo de datos de pegamento.
- El editor Athena se utiliza para probar el conector y realizar análisis mediante consultas SQL.
- QuickSight utiliza el conector Athena para visualizar conocimientos de BI de DynamoDB.
Este tutorial utiliza datos de la ProductCatalog mesa, parte de la Archivos de datos de muestra de la guía para desarrolladores de DynamoDB.
Requisitos previos
Antes de comenzar, debe cumplir con los siguientes requisitos previos:
Configurar el conector Athena DynamoDB
El conector Athena DynamoDB comprende una función Lambda sin servidor prediseñada proporcionada por AWS que se comunica con DynamoDB para que pueda consultar sus tablas con SQL usando Athena. El conector está disponible en el Repositorio de aplicaciones sin servidor de AWS, y se utiliza para crear el fuente de datos de Atenas para su posterior uso en análisis y visualización de datos. Para configurar el conector, complete los siguientes pasos:
- En la consola de Athena, elija Fuentes de datos en el panel de navegación.
- Elige Crear fuente de datos.
- En la barra de búsqueda, busque y elija Amazon DynamoDB.
- Elige Siguiente.
- under Detalles de la fuente de datos, ingresa un nombre. Tenga en cuenta que este nombre debe ser único y se hará referencia a él en sus declaraciones SQL cuando consulte su fuente de datos de Athena.
- under Detalles de conexión, escoger Crear función Lambda.
Esto le llevará a la aplicaciones lambda página en la consola Lambda. No cierre la pestaña de creación de fuentes de datos de Athena; volverá a él en un paso posterior.
- Desplácese hacia abajo hasta Configuración de la aplicación e ingrese un valor para los siguientes parámetros (deje los demás parámetros como predeterminados):
SpillBucket– Especifica el Servicio de almacenamiento simple de Amazon (Amazon S3) nombre del depósito para almacenar datos que exceden los límites de tamaño de respuesta de la función Lambda. Para crear un depósito S3, consulte Crear un cubo.AthenaCatalogName– Un nombre en minúscula para la función Lambda que se creará.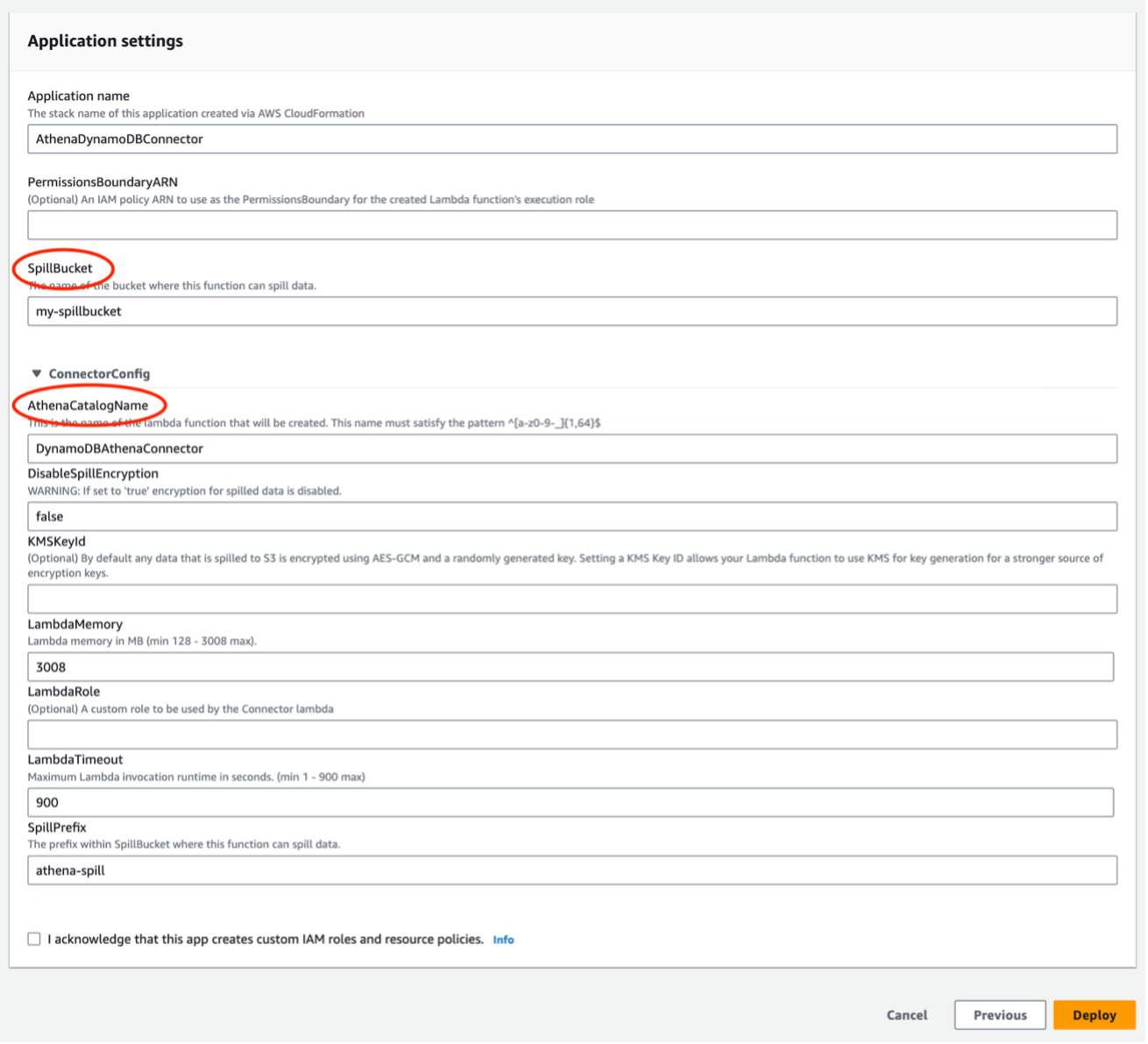
- Seleccione la casilla de verificación de acuse de recibo y elija Despliegue.
Espere a que se complete la implementación antes de pasar al siguiente paso.
- Regrese a la pestaña de creación de fuentes de datos de Athena.
- under Detalles de conexión, elija el icono de actualización y elija la función Lambda que creó.
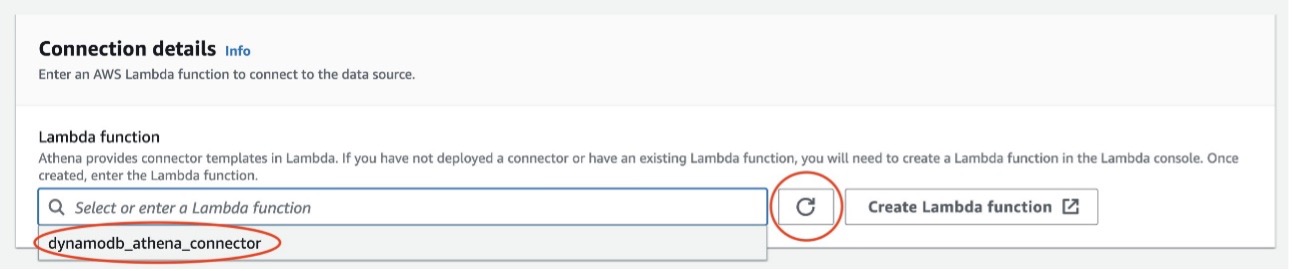
- Elige Siguiente.
- Revisa y elige Crear fuente de datos.
Proporcione metadatos complementarios a través de AWS Glue
El conector Athena ya viene con una capacidad de inferencia incorporada para descubrir el esquema y las propiedades de la tabla de su fuente de datos. Sin embargo, esta capacidad es limitada. Para descubrir con precisión los metadatos de su tabla de DynamoDB y centralizar la administración de esquemas a medida que sus datos evolucionan con el tiempo, el conector se integra con AWS Glue.
Para lograr esto, se ejecuta un rastreador de AWS Glue para determinar automáticamente el formato, el esquema y las propiedades asociadas de los datos sin procesar almacenados en su tabla de DynamoDB, escribiendo los metadatos resultantes en un Base de datos de pegamento. Las bases de datos de pegamento contienen tablas, que contienen metadatos de diferentes almacenes de datos, independientemente de la ubicación real de los datos. Luego, el conector de Athena hace referencia a la tabla Glue y recupera los metadatos de DynamoDB correspondientes para habilitar las consultas.
Cree la base de datos de AWS Glue
Complete los siguientes pasos para crear la base de datos de Glue:
- En la consola de AWS Glue, debajo de Catálogo de datos en el panel de navegación, elija Bases de datos.
- Elige Agregar base de datos (También puedes editar una base de datos existente si ya tienes una).
- Nombre, ingrese un nombre de base de datos.
- Destino, ingrese la cadena literal
dynamo-db-flag. Esta palabra clave indica que la base de datos contiene tablas que el conector puede utilizar para metadatos complementarios. - Elige Crear base de datos.
Siguiendo las mejores prácticas de seguridad, también se recomienda habilitar el cifrado en reposo para su catálogo de datos. Para más detalles, consulte Cifrar su catálogo de datos.
Crear el rastreador de AWS Glue
Complete los siguientes pasos para crear y ejecutar el rastreador de Glue:
- En la consola de AWS Glue, debajo de Catálogo de datos en el panel de navegación, elija Rastreadores.
- Elige Crear rastreador.
- Introduzca un nombre de rastreador y elija Siguiente.
- Fuentes de datos, escoger Agregar una fuente de datos.
- En Fuente de datos menú desplegable, elija DynamoDB. For Nombre de la tabla, ingrese el nombre de su tabla de DynamoDB (literal de cadena).
- Elige Agregar una fuente de datos de DynamoDB.
- Elige Siguiente.
- Rol de IAM, escoger Crear una nueva función de IAM.
- Ingrese un nombre de rol y elija Crear. Esto creará automáticamente un Rol de IAM que confía en AWS Glue y tiene permisos para acceder a los objetivos del rastreador.
- Elige Siguiente.
- Base de datos de destino, elija la base de datos creada previamente.
- Elige Siguiente.
- Revisa y elige Crear rastreador.
- En la página del rastreador recién creada, elija Ejecutar rastreador.
Los tiempos de ejecución del rastreador dependen del tamaño y las propiedades de la tabla de DynamoDB. Puede encontrar detalles de ejecución del rastreador en Carreras de orugas.
Validar los metadatos de salida.
Cuando el estado de ejecución del rastreador se muestra como Completado, siga los pasos a continuación para validar los metadatos de salida:
- En la consola de AWS Glue, elija Mesas en el panel de navegación. Aquí puede confirmar que se ha agregado una nueva tabla a la base de datos como resultado de la ejecución del rastreador.
- Navegue hasta la tabla recién creada y eche un vistazo a la Esquema pestaña. Esta pestaña muestra los nombres de las columnas, los tipos de datos y otros parámetros inferidos de su tabla de DynamoDB.
- Si es necesario, edite el esquema eligiendo Editar esquema.
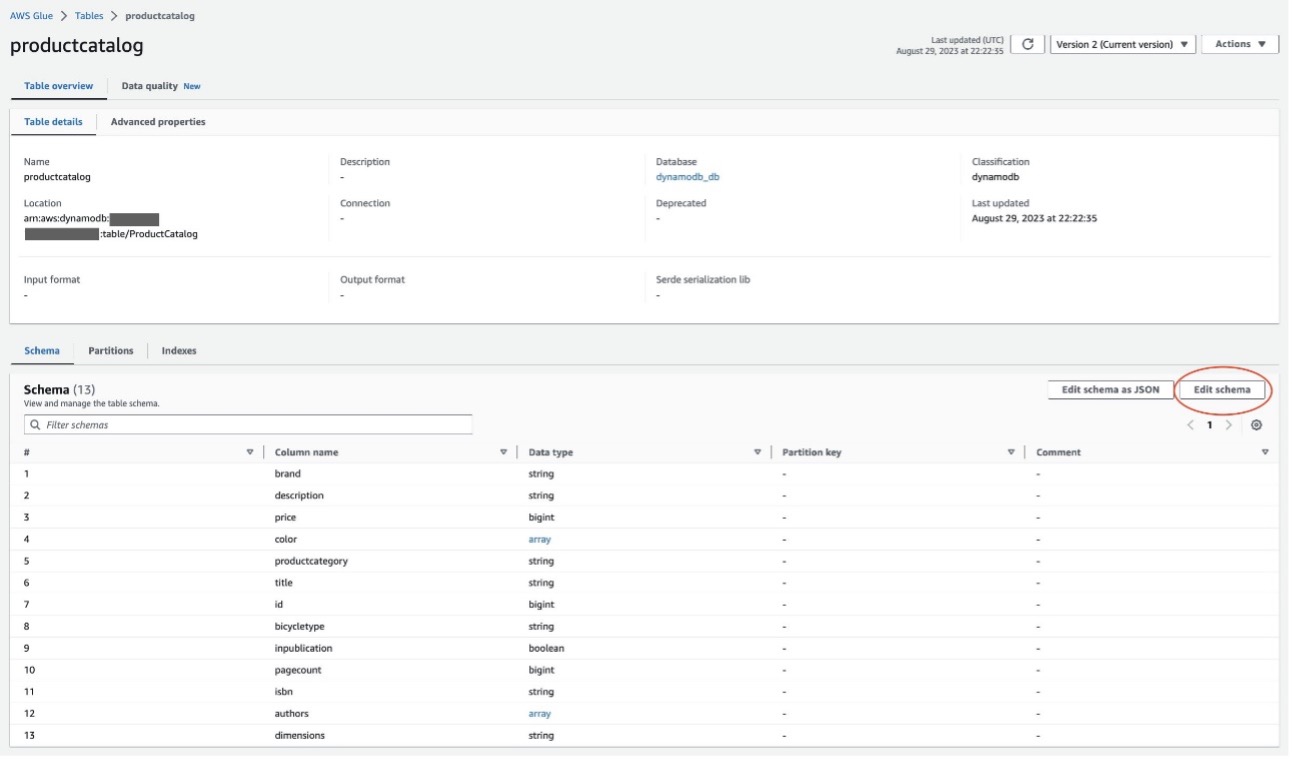
- Elige Propiedades avanzadas.
- under Propiedades de la tabla, verifique el rastreador creado automáticamente y configure el
classificationclave paradynamodb. Esto indica al conector de Athena que la tabla se puede utilizar para metadatos complementarios. - Opcionalmente, agregue las siguientes propiedades para catalogar y hacer referencia correctamente a los datos de DynamoDB en consultas de AWS Glue y Athena. Esto se debe a que las letras mayúsculas no se permiten en los nombres de tablas y columnas de AWS Glue, pero sí en los nombres de tablas y atributos de DynamoDB.
- Si el nombre de su tabla de DynamoDB contiene letras mayúsculas, elija Acciones y Editar tabla y agregue una propiedad de tabla adicional de la siguiente manera:
- Llave:
sourceTable - Valor:
YourDynamoDBTableName
- Llave:
- Si su tabla de DynamoDB tiene atributos que contienen letras mayúsculas, agregue una propiedad de tabla adicional de la siguiente manera:
- Llave:
columnMapping - Valor:
yourcolumn1=YourColumn1,yourcolumn2=YourColumn2, salpicadero de coches y etc.
- Llave:
- Si el nombre de su tabla de DynamoDB contiene letras mayúsculas, elija Acciones y Editar tabla y agregue una propiedad de tabla adicional de la siguiente manera:
Pruebe el conector con el editor Athena SQL
Una vez que se implementa el conector de Athena DynamoDB y la tabla de AWS Glue se completa con metadatos adicionales, la tabla de DynamoDB está lista para el análisis. El ejemplo de esta publicación utiliza el editor Athena para realizar consultas SQL al ProductCatalog mesa. Para obtener más opciones para interactuar con Athena, consulte Accediendo a Atenas.
Complete los siguientes pasos para probar el conector:
- Abra la editor de consultas de Atenas.
- Si es la primera vez que visita la consola de Athena en su región de AWS actual, complete los siguientes pasos. Este es un requisito previo antes de poder ejecutar consultas de Athena. Ver Cómo Empezar para más información.
- Elige Editor de consultas en el panel de navegación para abrir el editor.
- Navegue hasta Ajustes y elige Gestiona para configurar una ubicación de resultados de consulta en Amazon S3.
- under Datos, seleccione la fuente de datos y la base de datos que creó (es posible que deba elegir el ícono de actualización para que se sincronicen con Athena).
- Las tablas que pertenecen a la base de datos seleccionada aparecen debajo Mesas. Puede elegir un nombre de tabla para que Athena muestre la lista de columnas de la tabla y los tipos de datos.
- Pruebe el conector extrayendo datos de su tabla mediante una instrucción SELECT. Cuando ejecuta consultas de Athena, puede hacer referencia a fuentes de datos, bases de datos y tablas de Athena como
<datasource_name>.<database>.<table_name>. Los registros recuperados se muestran en Resultados.
Para mayor seguridad, consulte Cifrado de los resultados de consultas de Athena almacenados en Amazon S3 para cifrar los resultados de la consulta en reposo.

Para esta publicación, ejecutamos una declaración SELECT para validar el proceso. Puedes consultar el Referencia SQL para Atenea para construir consultas y análisis más complejos.
Visualizar en QuickSight
QuickSight permite crear paneles interactivos modernos, informes paginados, análisis integrados y consultas en lenguaje natural a través de una solución de BI unificada. En este paso, utilizamos QuickSight para generar información visual a partir de la tabla de DynamoDB conectándonos a la fuente de datos de Athena creada previamente.
Permitir que QuickSight acceda a los recursos
Complete los siguientes pasos para otorgar acceso a QuickSight a los recursos:
- En la consola QuickSight, elija el icono de perfil y elija Administrar QuickSight.
- En el panel de navegación, elija Seguridad y permisos.
- under Acceso QuickSight a los servicios de AWS, escoger Gestiona.
- QuickSight puede solicitarle que cambie a la región en la que se administran los usuarios y grupos de su cuenta. Para cambiar la región actual, navegue hasta el ícono de perfil en la consola QuickSight y elija la región a la que desea cambiar.
- Rol de IAM, escoger Utilice la función administrada por QuickSight (defecto).
Las instrucciones posteriores suponen que se está utilizando la función predeterminada administrada por QuickSight. Si este no es el caso, asegúrese de actualizar la función existente para lograr el mismo efecto.
- under Permitir el acceso y la detección automática de estos recursos, seleccione AMI y Amazon S3.
- Amazon S3, escoger Seleccionar cubos S3.
- Elija el depósito de derrames que especificó anteriormente al implementar la función Lambda para el conector y el depósito que especificó como ubicación del resultado de la consulta de Athena en Amazon S3.
- Para ambos depósitos, seleccione Permiso de escritura para Athena Workgroup.
- Elige Atenea amazónica.
- En la ventana emergente, seleccione Siguiente.
- Elige lambda y elija el nombre de recurso de Amazon (ARN) de la función Lambda utilizada anteriormente para el conector de fuente de datos de Athena.
- Elige Acabado.
- Elige Guardar.
Crear el conjunto de datos de Athena
Para crear el conjunto de datos de Athena, complete los siguientes pasos:
- En la consola QuickSight, elija el perfil de usuario y cambie a la región en la que implementó la fuente de datos de Athena.
- Regrese a la página de inicio de QuickSight.
- En el panel de navegación, elija Conjuntos de datos.
- Elige Nuevo conjunto de datos.
- Crear un conjunto de datos, seleccione Athena.
- Nombre de fuente de datos, ingrese un nombre y elija Validar conexión.
- Cuando la conexión se muestra como validado, escoger Crear fuente de datos.
- under Catálogo, Base de datosy Mesas, seleccione la fuente de datos de Athena, la base de datos de AWS Glue y la tabla de AWS Glue creadas anteriormente.
- Elige Seleccione.
- En Finalizar la creación del conjunto de datos página, seleccione Importar a SPICE para análisis más rápidos.
- Elige Visualizar.
Para obtener información adicional sobre los modos de consulta QuickSight, consulte Importación de datos en SPICE y Usar SQL para personalizar datos.
Cree visualizaciones QuickSight
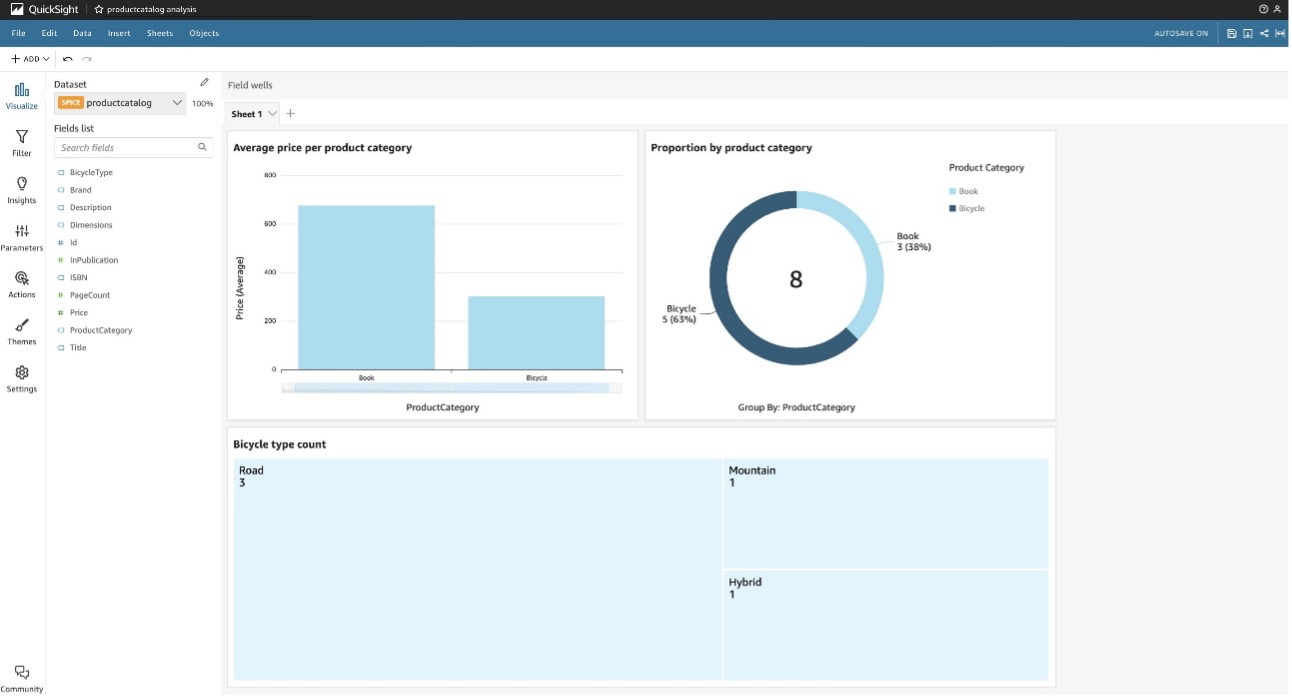
Una vez que los datos de DynamoDB estén disponibles en QuickSight a través del conector Athena DynamoDB, estarán listos para visualizarse. El análisis QuickSight en el siguiente ejemplo muestra un gráfico de barras apiladas verticales con el precio promedio por categoría de producto para el ProductCatalog conjunto de datos de muestra. Además, muestra un gráfico de anillos con la proporción de productos por categoría de producto y un mapa de árbol que contiene el recuento de bicicletas por tipo de bicicleta.
Si utiliza datos importados a SPICE en un análisis QuickSight, el conjunto de datos solo estará disponible después de que se complete la importación. Para más detalles, ver Uso de datos SPICE en un análisis.
Para obtener información completa sobre cómo crear y compartir visualizaciones en QuickSight, consulte Visualización de datos en Amazon QuickSight y Compartir y suscribirse a datos en Amazon QuickSight.
Limpiar
Para evitar incurrir en cargos continuos por uso de AWS, asegúrese de eliminar todos los recursos creados como parte de este tutorial.
- Eliminar la fuente de datos de Athena:
- En la consola de Athena, cambie a la región en la que implementó sus recursos.
- Elige Fuentes de datos en el panel de navegación.
- Seleccione la fuente de datos que creó y en el Acciones menú, seleccione Borrar.
- Elimine la aplicación Lambda:
- En la consola de AWS CloudFormation, cambie a la región en la que implementó sus recursos.
- Elige Stacks en el panel de navegación.
- Seleccione
serverlessrepo-AthenaDynamoDBConnectory elige Borrar.
- Elimine los recursos de AWS Glue:
- En la consola de AWS Glue, cambie a la región en la que implementó sus recursos.
- Elige Bases de datos en el panel de navegación.
- Seleccione la base de datos que creó y elija Borrar.
- Elige Rastreadores en el panel de navegación.
- Seleccione el rastreador que creó y en el la columna Acción menú, seleccione Eliminar rastreador.
- Elimine los recursos de QuickSight:
- En la consola QuickSight, cambie a la región en la que implementó sus recursos.
- Eliminar el análisis creado para este tutorial.
- Eliminar el conjunto de datos de Athena creado para este tutorial.
- Si ya no necesita la fuente de datos de Athena para crear otros conjuntos de datos, eliminar la fuente de datos.
Resumen
Esta publicación demostró cómo puede utilizar el conector Athena DynamoDB para consultar datos en DynamoDB con SQL y crear visualizaciones en QuickSight.
Obtenga más información sobre el conector Athena DynamoDB en el Guía del usuario de Amazon Athena. Descubrir Más conectores de fuentes de datos disponibles para consultar y visualizar una variedad de fuentes de datos sin configurar ni administrar ninguna infraestructura y solo paga por las consultas que ejecuta.
Para conocer las capacidades avanzadas de QuickSight impulsadas por IA, consulte Obtención de conocimientos con aprendizaje automático (ML) en Amazon QuickSight y Respondiendo preguntas empresariales con Amazon QuickSight Q.
Acerca de los autores
 Antonio Samaniego Jurado es arquitecto de soluciones en Amazon Web Services. Con una gran pasión por la tecnología moderna, Antonio ayuda a los clientes a crear aplicaciones de última generación en AWS. Creador de corazón, le encanta el aprendizaje impulsado por la comunidad y el intercambio de mejores prácticas en todo el portafolio de servicios de AWS para aprovechar al máximo el viaje a la nube de los clientes.
Antonio Samaniego Jurado es arquitecto de soluciones en Amazon Web Services. Con una gran pasión por la tecnología moderna, Antonio ayuda a los clientes a crear aplicaciones de última generación en AWS. Creador de corazón, le encanta el aprendizaje impulsado por la comunidad y el intercambio de mejores prácticas en todo el portafolio de servicios de AWS para aprovechar al máximo el viaje a la nube de los clientes.
 Pascal Vogel es arquitecto de soluciones en Amazon Web Services. Pascal ayuda a nuevas empresas y empresas a crear soluciones nativas de la nube. Como entusiasta de la nube, a Pascal le encanta aprender nuevas tecnologías y conectarse con clientes con ideas afines que desean marcar la diferencia en su viaje a la nube.
Pascal Vogel es arquitecto de soluciones en Amazon Web Services. Pascal ayuda a nuevas empresas y empresas a crear soluciones nativas de la nube. Como entusiasta de la nube, a Pascal le encanta aprender nuevas tecnologías y conectarse con clientes con ideas afines que desean marcar la diferencia en su viaje a la nube.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/visualize-amazon-dynamodb-insights-in-amazon-quicksight-using-the-amazon-athena-dynamodb-connector-and-aws-glue/

