ABBYY es una empresa de tecnología global que brinda soluciones para procesamiento de documentos, captura de datos y tecnologías basadas en lenguaje. Fue fundada en 1989 por un grupo de lingüistas e ingenieros de la Universidad Estatal de Moscú. El nombre de la empresa es un acrónimo de "Advanced Business Computer Systems".
Los primeros productos de ABBYY fueron diccionarios y software lingüístico para diferentes mercados. En la década de 1990, ABBYY amplió su línea de productos para incluir reconocimiento óptico de caracteres (OCR) y aplicaciones de escaneo de documentos. Los productos PDF de ABBYY son algunos de los más populares del mercado. Más de 100 millones de personas utilizan los productos PDF de ABBYY todos los días. La empresa se esfuerza por proporcionar soluciones precisas, confiables y fáciles de usar que todos puedan usar, desde individuos hasta grandes organizaciones.
Esta publicación de blog presentará una descripción general de su línea de productos y algunos pros y contras de trabajar juntos. También compararemos algunos de sus productos con los ofrecidos por otras empresas de primer nivel en esta industria para que pueda decidir si serían los adecuados para sus necesidades.
Vamos a sumergirnos
¿Qué soluciones ofrece ABBYY?
ABBYY ofrece una gama completa de software de edición y conversión de OCR y PDF que es fácil de usar y confiable. Sus productos permiten a los usuarios convertir documentos en archivos PDF con capacidad de búsqueda, editar archivos PDF y extraer datos de formularios y tablas. La empresa también ofrece una aplicación móvil para dispositivos iOS y Android que permite a los usuarios escanear y convertir documentos en papel a formatos digitales. En esta sección, exploraremos los diferentes servicios que brindan.
Ventaja de ABBYY
ABBYY Vantage es una solución de gestión de documentos que le permite automatizar sus procesos comerciales con la ayuda de algoritmos inteligentes e inteligencia artificial. Puede mejorar la eficiencia de su flujo de trabajo utilizando esta herramienta para convertir, anotar, procesar y extraer datos de varios documentos. Esta herramienta también le permite utilizar la tecnología OCR para diversos fines, como la clasificación, indexación y búsqueda de documentos. ABBYY Vantage también ofrece capacidades de análisis de datos para ayudar a las empresas a rastrear tendencias y obtener nuevos conocimientos sobre su negocio.
Cronología de ABBYY
ABBYY Timeline es una aplicación para visualizar eventos históricos a partir de documentos de texto no estructurados, como artículos de noticias o correos electrónicos. La herramienta permite a los usuarios ver cómo evolucionan los conceptos e identificar patrones en las tendencias a lo largo del tiempo. Principalmente, esta aplicación utiliza técnicas de procesamiento de lenguaje natural para identificar eventos de documentos de texto y luego agrupa esos eventos en líneas de tiempo según el tipo de evento.
ABBYY Flexi Capture
ABBYY FlexiCapture es un paquete de software que ayuda a las organizaciones a capturar automáticamente campos clave de formularios en papel en sus bases de datos o sistemas CRM. Esta herramienta puede extraer fácilmente datos de varios formularios, incluidas facturas, órdenes de compra, extractos bancarios, reclamaciones de seguros, etc.
ABBYY FlexiCapture para facturas
ABBYY FlexiCapture for Invoices está diseñado para ayudar a las empresas a optimizar sus procesos de gestión de facturas mediante la automatización de las tareas de procesamiento de facturas. Esta solución le permite ahorrar tiempo al extraer, estandarizar y enriquecer automáticamente los datos de las facturas con información adicional de sus bases de datos internas y crear informes personalizados según sus necesidades.
Servidor FineReader de ABBYY
ABBYY FineReader Server es una solución para la conversión, indexación y recuperación automática de documentos en el lado del servidor. Convierte documentos escaneados en formatos editables en tiempo real utilizando la tecnología OCR (reconocimiento óptico de caracteres), lo que permite a los usuarios editarlos y reutilizarlos según sea necesario. La solución también ofrece funciones avanzadas, como indexación detallada para la capacidad de búsqueda y análisis de documentos mejorado para una mejor comprensión de la estructura del contenido, entre otras.
Las soluciones empresariales de ABBYY están disponibles para integrarse con diferentes sistemas a través de SDK y herramientas para desarrolladores.
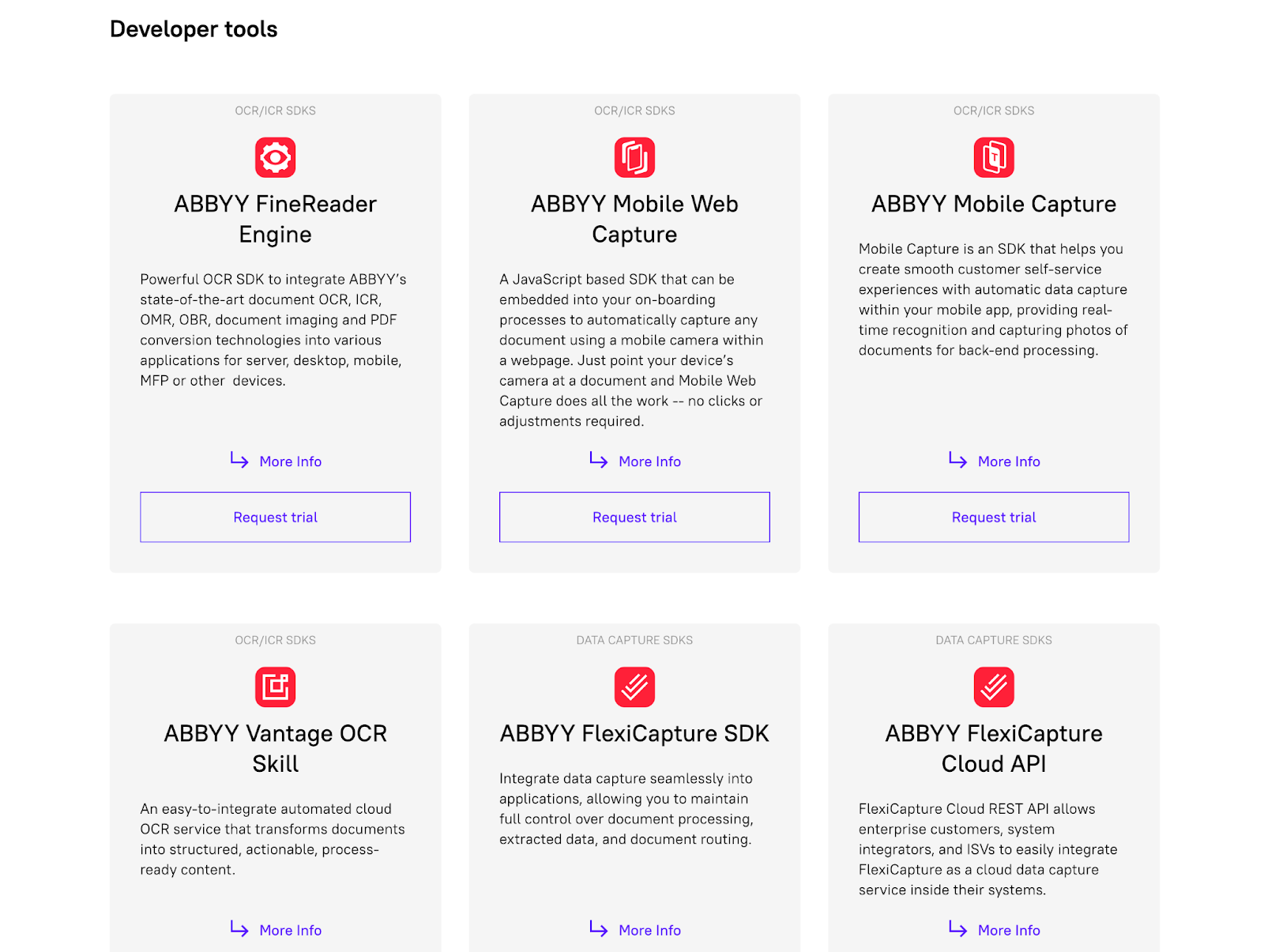
ABBYY FlexiCapture y ABBYY FineReader son los dos servicios más populares que ofrece ABBYY. Miremos más de cerca.
ABBYY FlexiCapture tiene muchas funciones en común con ABBYY FineReader Server (anteriormente conocido como Recognition Server). Sin embargo, cada producto está diseñado con funciones únicas, que las empresas deben tener en cuenta al evaluar soluciones para sus requisitos de OCR y captura de documentos. Para ayudarlo a comparar los productos más fácilmente, hemos compilado una lista de casos de uso que le permitirán evaluar entre ABBYY FlexiCapture y FineReader Server.
¿Busca una solución inteligente de reconocimiento de texto? Dirigirse a Nanonetas y utilice la solución con una precisión superior al 95%.
¿Cuáles son los casos de uso comercial de ABBYY Finereader OCR?
ABBYY FineReader Server es un programa de conversión de documentos que se utiliza para convertir documentos e imágenes en formatos de búsqueda. El programa opera en un servidor, lo que permite la conversión a gran escala de documentos dentro del marco de tiempo de procesamiento de una empresa. También puede proporcionar un medio rentable para que las empresas capturen e indexen manualmente documentos en toda la empresa, ya sea escaneando documentos en papel o procesando archivos e imágenes electrónicos. Sin embargo, un inconveniente es que no proporciona la conversión de valores de escritura a mano o de marca de verificación [1].
En la imagen a continuación, puede ver la relación entre los componentes de FineReader Server.
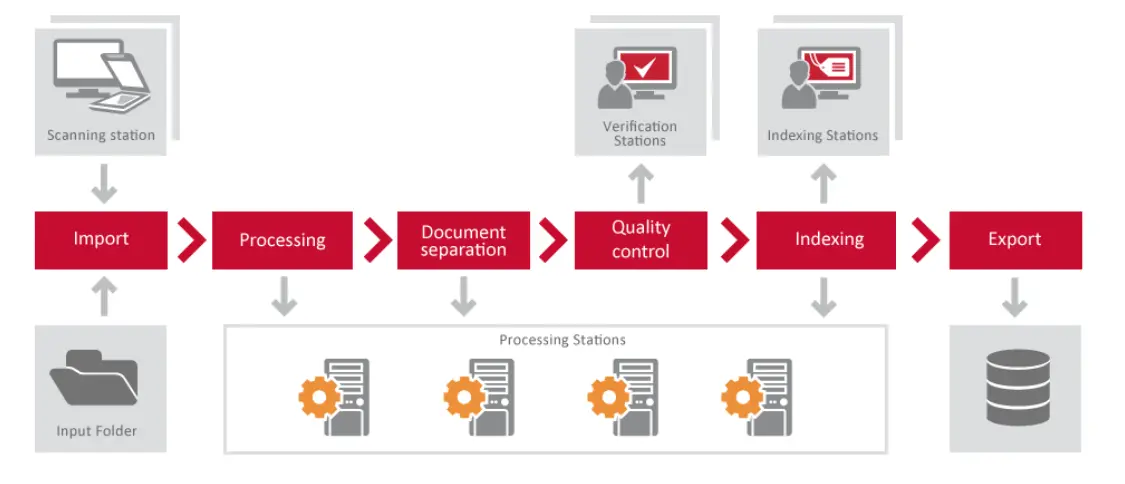
Algunos casos de uso comunes
Procesamiento a granel
Supervise carpetas compartidas en una red y realice conversiones de PDF de imagen a texto a partir de imágenes o documentos. Cuando se agrega un nuevo archivo a una carpeta, se convierte a una versión de búsqueda de texto y luego se mueve a la carpeta de exportación correspondiente mientras se mantiene la designación original de la subcarpeta. El archivo de exportación mantendría la integridad legal del archivo de imagen original y agregaría una capa de texto que permite realizar búsquedas detrás de la imagen en el archivo PDF en las carpetas de exportación.
Escaneo de documentos
Cuando escanea documentos a un formato digital, obtiene el beneficio adicional de poder copiar y pegar texto de esos documentos en otros documentos. Sin embargo, debe volver a escribir manualmente el texto si no hay ningún software de OCR disponible. El tiempo que lleva hacer esto puede ser significativo. FineReader OCR permite a los usuarios convertir rápidamente imágenes escaneadas en archivos de texto editables a los que se puede acceder y manipular fácilmente en otras aplicaciones, como Word o Excel. Lo mismo ocurre con los faxes, que a menudo se reciben en formato TIFF y no admiten la edición ni la manipulación. Con FineReader OCR, estos faxes se pueden convertir en archivos PDF editables o incluso en documentos de Word con unos pocos clics.
Digitalización de Documentos (Imágenes a Texto)
ABBYY ofrece una solución de extracción de datos que se puede utilizar para convertir imágenes de texto impreso o escrito a mano en un formato editable. Esta es una herramienta importante para empresas y organizaciones que necesitan digitalizar grandes volúmenes de documentos, como financieros, legales o médicos. El proceso de extracción de datos puede extraer automáticamente el texto de las imágenes, que luego se puede almacenar en una base de datos o convertir a un PDF con capacidad de búsqueda u otro formato de documento. Esta solución puede ahorrar mucho tiempo y dinero a las empresas y organizaciones al reducir la necesidad de ingresar datos manualmente. Además, el proceso de extracción de datos se puede utilizar para mejorar la precisión de la entrada de datos al proporcionar un método consistente y preciso para convertir documentos en papel a formato digital.
Máquina traductora
ABBYY FineReader OCR se puede utilizar como una herramienta de traducción automática al convertir una imagen en texto en otro idioma (traducción automática). Esto puede ser útil si desea brindar servicios de traducción sin tener que contar con traductores humanos en su ubicación, pero aún desea brindar traducciones de calidad a sus clientes (o simplemente no desea perder el tiempo traduciendo algo usted mismo).
La extracción de tablas es un proceso de extracción de datos de archivos PDF o imágenes de documentos de tablas mediante el uso de reconocimiento óptico de caracteres (OCR). Se usa comúnmente para convertir documentos en papel escaneados, como recibos, a un formato digital para que los datos puedan procesarse, analizarse y almacenarse de manera más eficiente. Hay varios programas de OCR disponibles en el mercado, pero ABBYY FineReader es una de las opciones más populares. La tecnología puede reconocer líneas y celdas, y también puede detectar encabezados y pies de página. Es posible procesar documentos de varias páginas a la vez, lo que ahorra tiempo. Además, ABBYY FineReader admite una amplia gama de idiomas, lo que lo hace ideal para extraer datos de documentos en diferentes idiomas.
¿Quiere automatizar la entrada de datos de los documentos? La solución de OCR basada en IA de Nanonets puede ayudar a extraer información clave de documentos estructurados / no estructurados y poner el proceso en piloto automático.
¿Cuáles son los casos de uso comercial de Flexicapture OCR?
ABBYY FlexiCapture es principalmente una aplicación de software de extracción de datos de nivel empresarial que proporciona funciones de reconocimiento óptico de caracteres (OCR). FlexiCapture proporciona un medio para extraer automáticamente información de los documentos en función del establecimiento de reglas, incluidas las palabras clave y la ubicación de los datos en una página. Actualmente, FlexiCapture está disponible en paquetes de soluciones especiales listos para usar, como FlexiCapture for Invoices y FlexiCapture for Mailrooms. Aunque la solución se basa en gran medida en el uso de la misma tecnología OCR que se encuentra en FineReader Server, y puede exportar una versión de texto de un documento que permita realizar búsquedas si es necesario, sus funciones principales son las siguientes:
- Clasificación de documentos (determinando su tipo)
- Hacer coincidir estas clases de documentos con las reglas de extracción de datos correspondientes
- Exportar los datos a algún lugar, como una base de datos, un archivo XML o Microsoft Excel.
Las capacidades de clasificación de documentos de FlexiCapture se pueden utilizar para extraer y luego comparar valores de campo de conjuntos de documentos. Por ejemplo, una solicitud de préstamo puede contener media docena de documentos, algunos de los cuales contienen un SSN. Se puede configurar fácilmente una regla para comparar los SSN de cada documento que contenga un valor para este campo y luego presentar cualquier error al operador durante la fase de verificación del documento.
En la imagen a continuación, puede ver la relación entre los componentes del servidor FlexiCapture.
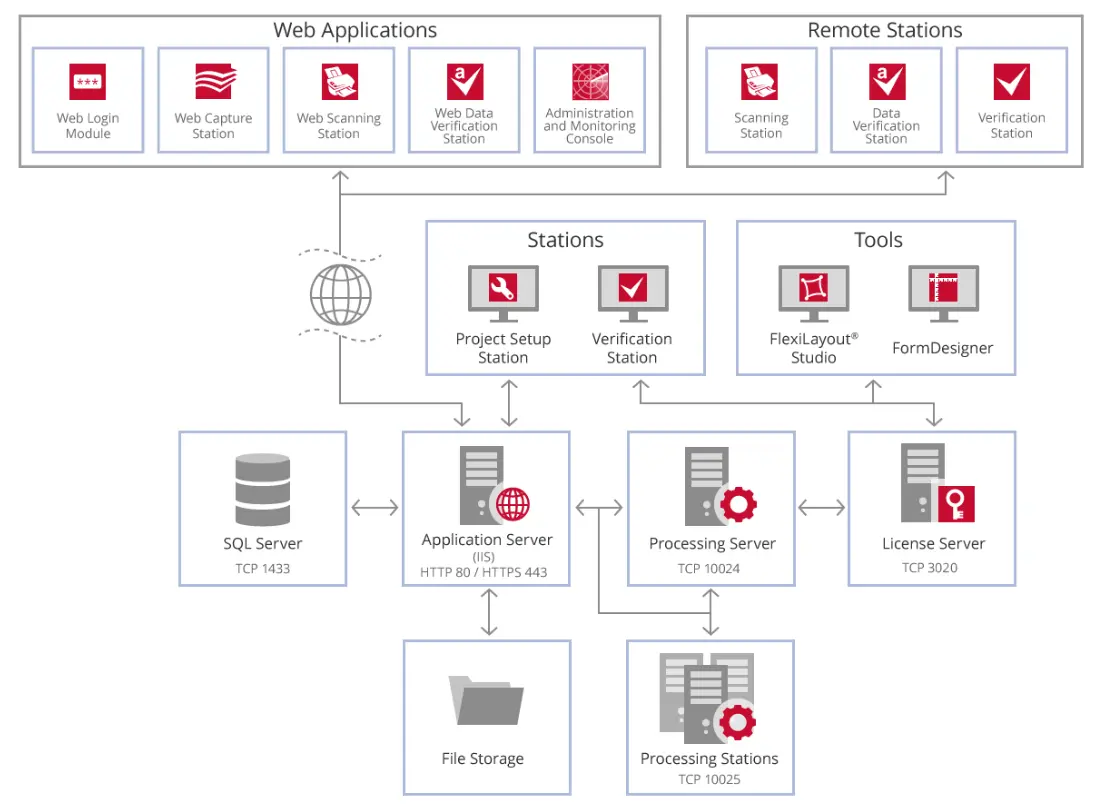
Algunos casos de uso comunes
Coincidencia de 2 vías
ABBYY FineReader tiene características que pueden ayudar a que su departamento de cuentas por pagar funcione mejor. Esto incluye:
- Extracción automática de datos de facturas de documentos en papel y electrónicos
- Cotejo bidireccional de partidas de factura con la compra correspondiente en el sistema ERP
- Búsqueda a través de facturas con capacidad de búsqueda de texto
- Aprobación de pagos por monto en dólares u otras reglas
- Procesamiento automatizado de pedidos de compra entrantes
Clasificación de documentos
- Clasifique los documentos entrantes por tipo y extraiga los datos de los documentos utilizando reglas preconfiguradas.
- Exporte una versión en PDF del documento con capacidad de búsqueda de texto a un sistema de administración de contenido y complete los campos con datos extraídos del documento.
- Proporcione a los usuarios un medio para corregir los datos extraídos junto con colas para administrar las excepciones a las reglas preprogramadas dentro del proceso de flujo de trabajo del documento.
Principales alternativas para las soluciones de ABBYY

Amazon Textract es un servicio que extrae automáticamente texto y datos de documentos escaneados. Va más allá del simple reconocimiento óptico de caracteres (OCR) para identificar también el contenido de los campos en los formularios y la información almacenada en las tablas.
Amazon AWS Textract es una herramienta más nueva que está ganando popularidad gracias a su bajo costo y facilidad de uso. Es ideal para escanear una gran cantidad de documentos, aunque sus niveles de precisión no son tan altos como los de ABBYY [2].
La principal diferencia entre ABBYY y Amazon Textract es que, mientras que ABBYY proporciona una solución independiente para extraer texto de imágenes mediante el reconocimiento óptico de caracteres (OCR), Amazon proporciona a sus clientes una API que pueden integrar en sus propias aplicaciones. Incluso proporcionan diferentes SDK, lo que facilita a los desarrolladores la integración de esta función en sus productos; sin embargo, esto requiere conocimientos adicionales sobre lenguajes de programación como Java o Python.
Además, a diferencia de AWS Textract, ABBYY brinda un control absoluto sobre todos los aspectos de su proceso de OCR (por ejemplo, le permite personalizar la segmentación de palabras).
Tanto ABBYY como AWS Textract funcionan muy bien en términos de precisión y velocidad en la mayoría de los casos.
Pros de Textract
- Puede utilizar AWS Textract con cualquier aplicación de procesamiento de texto con un SDK.
- AWS Textract admite más de 25 idiomas en 200 países y territorios. Puede usarlo para traducir sus archivos de imagen en tiempo real y crear canales de procesamiento multilingües.
- Esta herramienta es rentable. Cuesta solo $0.0025 por 100,000 XNUMX caracteres procesados, ¡menos de la mitad del costo de otras soluciones!
- AWS Textract es escalable, lo que significa que puede usarlo a pequeña o gran escala, según sus necesidades.
Contras de Textract
- AWS Textract requiere mucho tiempo y recursos para entrenar con sus datos antes de poder usarlos en producción.
- El software moderno de reconocimiento óptico de caracteres (OCR) puede identificar si un documento cargado es original o una falsificación mediante la validación de fechas, la búsqueda de regiones pixeladas y otros métodos. AWS Textract no tiene esta capacidad; solo puede extraer texto de un documento cargado.
- Textract no permite integraciones con proveedores ascendentes y descendentes fácilmente. Por ejemplo, es posible que tengamos que construir una canalización de RPA con un servicio de terceros. Sería difícil encontrar complementos apropiados que se adapten a Textract.
ABBYY contra Tesseract

Tesseract OCR fue diseñado para reconocer una amplia gama de lenguajes escritos en código C++ puro. También se puede compilar para su uso en dispositivos móviles como las plataformas Android e iOS. El software utiliza funciones avanzadas como la detección de diseño de texto vertical, lo que permite a los usuarios leer el texto desde varios ángulos sin perder precisión.
ABBYY y Tesseract brindan soluciones de OCR y cuentan con altas tasas de precisión y admiten una variedad de idiomas. Sin embargo, hay algunas diferencias críticas entre los dos. ABBYY ofrece una interfaz más fácil de usar, lo que la hace ideal para aquellos que son nuevos en OCR. También proporciona más funciones, como exportar múltiples formatos y realizar la edición de imágenes. Por otro lado, Tesseract es de código abierto y, por lo tanto, de uso gratuito. También tiene un motor más preciso, lo que lo convierte en la mejor opción para aquellos que necesitan el nivel de precisión más alto posible.
Pros de Tesseract
- Funciona con varios idiomas en varias fuentes, incluidas la escritura romana, cirílica, ideográfica Han, hebreo, árabe y tailandés.
- El código fuente está disponible bajo una licencia de Apache, por lo que su uso y modificación son gratuitos. También ocupa poco espacio en la memoria en comparación con otros motores de OCR, por lo que no ocupa demasiado espacio en su computadora o teléfono inteligente.
- Tesseract es versátil y se puede utilizar para diversas tareas, desde el simple reconocimiento óptico de caracteres (OCR) hasta tareas más complejas como el aprendizaje automático (ML).
Contras de Tesseract
- Tesseract no siempre produce resultados perfectos, especialmente con texto complejo o escrito a mano.
- El procesamiento de imágenes de Tesseract es rudimentario; por lo tanto, es necesario utilizar un preprocesador o una imagen que ya haya sido procesada para obtener los mejores resultados [8].
ABBYY frente a Ephesoft

Ephesoft es otra herramienta de reconocimiento de documentos que utiliza tecnología de reconocimiento óptico de caracteres (OCR) para convertir imágenes en archivos de texto. Este software está diseñado específicamente para empresas que necesitan una solución para administrar grandes volúmenes de documentos en papel, como facturas o recibos. Al igual que los productos de ABBYY, Ephesoft se puede utilizar en múltiples industrias, incluidas la atención médica, el gobierno, las finanzas y la fabricación.
Ambos conjuntos de software ofrecen una amplia gama de características y beneficios, pero existen algunas diferencias críticas entre ellos. Por ejemplo, ABBYY generalmente se considera más preciso que Ephesoft [6]t, especialmente al reconocer texto en documentos con diseños complejos. Sin embargo, Ephesoft suele ser más rápido que ABBYY, lo que lo convierte en una buena opción para las organizaciones que deben procesar un gran volumen de documentos a diario. En términos de precio, ABBYY suele ser más cara que Ephesoft, aunque ambas empresas ofrecen descuentos por licencias por volumen. En última instancia, el mejor software de OCR para su negocio dependerá de sus necesidades y presupuesto específicos.
Ventajas de Ephesoft
- El sistema tiene una funcionalidad de seguimiento que ayuda a rastrear los cambios en los documentos del usuario. Esto puede ser útil para prevenir el fraude y controlar quién realizó cambios cuando varios usuarios trabajan en un documento.
- Ephesoft utiliza técnicas de mejora de la calidad de la imagen para extraer datos de las imágenes, como OCR (reconocimiento óptico de caracteres), reconocimiento de códigos de barras y reconocimiento de caracteres. Esto aumenta significativamente la precisión de la extracción de datos en comparación con los métodos manuales, donde los datos pueden no ser totalmente precisos o completos debido a la mala calidad de la imagen u otros factores.
- Admite documentos en varios idiomas, como inglés, español, francés, etc., lo que lo hace adecuado para industrias con diversas bases de clientes que utilizan diferentes idiomas como modo principal de comunicación/documentación.
Contras de Ephesoft
- Necesita un entrenamiento adecuado antes de usarlo. Si no tiene experiencia previa trabajando con este tipo de software, es posible que le resulte difícil usarlo de manera efectiva. Sin embargo, una vez que se acostumbre, le resultará muy fácil usar este producto de manera efectiva en su entorno comercial.
- El software Ephesoft cuesta más que otros productos similares en el mercado. La inversión inicial requerida para comprar Ephesoft puede ser alta, pero el costo puede reducirse al optar por una versión en la nube [7].
ABBYY contra la hiperciencia

Los modelos de aprendizaje automático patentados de Hyperscience y la potente tecnología de reconocimiento óptico de caracteres (OCR) brindan una capacidad de extracción de datos sin igual para formularios escritos a mano, junto con otros documentos estructurados y semiestructurados. La plataforma cuenta con informes de rendimiento superiores, garantía de calidad integrada y extracción de alto nivel para una captura y análisis de documentos precisos y rápidos.
Tanto ABBYY como Hyperscience ofrecen soluciones de OCR de escritorio y basadas en la nube. Si necesita OCR un gran volumen de documentos, ABBYY puede ser una mejor opción, ya que podrá procesarlos en lotes utilizando la aplicación de escritorio.
El motor OCR de ABBYY se basa en inteligencia artificial (IA), mientras que el motor OCR de Hyperscience se basa en aprendizaje automático (ML). Esto significa que ABBYY puede aprender y mejorar con el tiempo, mientras que Hyperscience siempre producirá resultados consistentes con sus datos de entrenamiento. Por lo tanto, si necesita una herramienta de OCR que pueda adaptarse a condiciones cambiantes (p. ej., fuentes diferentes, imágenes de baja calidad, etc.), ABBYY puede ser una mejor opción. Sin embargo, si necesita una herramienta de OCR que siempre produzca el mismo alto nivel de precisión, independientemente del documento de entrada, Hyperscience puede ser una mejor opción.
ABBYY vs. Readiris

Readiris es un motor de OCR potente y preciso que se puede utilizar para convertir documentos e imágenes escaneados en texto editable y apto para búsquedas. Ofrece una amplia gama de funciones y opciones, lo que lo convierte en una solución de OCR versátil y potente para diversas necesidades.
Readiris es una de las alternativas populares a ABBYY FineReader. También es un programa de OCR con una amplia gama de funciones y muchos usuarios.
Ventajas de Readiris
- Procesamiento de documentos un 20 % más rápido
- Edita textos incrustados en tus imágenes con OCR
- Convierta documentos de Microsoft Office a PDF
- Anota y comenta
- Proteger y firmar archivos PDF
- Integración con impresoras (escáneres Twain) [3]
Desventajas de Readiris
- Los precios pueden ser costosos cuando se trabaja con grandes cantidades de datos.
- La precisión puede ser baja cuando se trabaja con datos no estructurados en comparación con otras herramientas [4]
ABBYY frente a Google Cloud Vision

Google Cloud Vision OCR es una solución de análisis de imágenes y reconocimiento de texto basada en la nube. El servicio utiliza algoritmos de aprendizaje profundo para procesar imágenes y videos, reconocer objetos, escenas y rostros, así como detectar texto en más de 100 idiomas.
Ventajas de Google Cloud Vision
- Los resultados son precisos y confiables: Google utiliza modelos de aprendizaje profundo para su servicio OCR, lo que significa que aprende más sobre cómo se formatea su documento específico a medida que pasa el tiempo, mejorando su precisión con el tiempo.
- Es compatible con la mayoría de los tipos de archivos: Google Cloud Vision OCR funciona con archivos JPEG, PNG, BMP, TIFF, PDF y GIF animados. Incluso puede convertir páginas HTML en texto sin formato con Google Cloud Vision OCR (aunque no se conservará todo el formato).
- Es fácil de usar: todo lo que necesita hacer es cargar una imagen que contenga el texto que desea convertir y hacer clic en "Crear texto" en la consola de Google Cloud Vision. No necesita instalar ningún software ni descargar ninguna biblioteca de software.
- Proporciona una interfaz API para integrarse con software personalizado.
Contras de Google Cloud Vision
- Requiere una conexión a Internet (lo que significa que no puede usarlo sin conexión).
- Es lento para procesar grandes volúmenes de datos. Puede usarlo para cantidades de texto de pequeñas a medianas, pero si desea procesar grandes cantidades de texto en modo por lotes, es posible que esta solución no sea lo suficientemente rápida para sus necesidades.
- En algunos casos, como la extracción de tablas, la precisión de Google Cloud Vision OCR no es tan alta como la de otras herramientas [5].
¿Quiere automatizar la entrada de datos de los documentos? La solución de OCR basada en IA de Nanonets puede ayudar a extraer información clave de documentos estructurados / no estructurados y poner el proceso en piloto automático.
ABBYY frente a nanoredes

Nanonets es un software OCR basado en IA que automatiza captura de datos para procesamiento inteligente de documentos de facturas, recibos, tarjetas de identificación y más. Las nanoredes usan OCR avanzado, procesamiento de imágenes de aprendizaje automáticoy Deep Learning para extraer información relevante de datos no estructurados. Es rápido, preciso, fácil de usar, permite a los usuarios crear modelos OCR personalizados desde cero y tiene algunas integraciones geniales con Zapier. Digitalice documentos, extraiga campos de datos e integre con sus aplicaciones diarias a través de API en una interfaz simple e intuitiva.
Ventajas de las nanoredes
- interfaz de usuario moderna
- Maneja grandes volúmenes de documentos
- A un precio razonable
- Facilidad de uso
- Captura cognitiva de datos – lo que resulta en una intervención mínima
- No requiere un equipo interno de desarrolladores
- Los algoritmos / modelos se pueden entrenar / reentrenar
- Excelente documentación y soporte
- Muchas opciones de personalización
- Amplia variedad de opciones de integración
- Funciona con varios idiomas distintos del inglés
- Casi no se requiere procesamiento posterior
- Integración bidireccional perfecta con varios software de contabilidad
- Excelente API de OCR para desarrolladores
Contras de las nanoredes
- No puede manejar picos de volumen muy alto
- La interfaz de usuario de captura de tabla puede ser mejor.
Compare y revise los precios de ABBYY
|
|
Equipo de Facilitación Lingüística |
De demostración |
Precios |
|
|
Adobe Acrobat Pro DC |
100+ idiomas |
7-día |
A partir de 14.99 $/mes |
Soluciones |
|
LeerIRIS |
130+ idiomas |
30-día |
A partir de 129 $/mes |
Windows y Mac |
|
ABBY FineReader |
198+ idiomas |
7-día |
$ 117 / año |
Windows, iOS, Android y Mac. |
|
Visión de la nube de Google |
130+ idiomas |
Gratis |
Versión gratuita $ 1.5 por 1000 unidades |
Nube, API |
|
Nanonetas |
100+ idiomas |
SIN COSTO |
Versión gratuita Pro: $499 / mes |
Nube, Windows y Mac |
|
Tesseract |
120+ idiomas |
SIN COSTO |
SIN COSTO |
Windows |
¿Por qué elegir Nanonets en lugar de ABBYY?
Nanonets es un software OCR que utiliza inteligencia artificial para automatizar la extracción de tablas de documentos PDF, imágenes y archivos escaneados. A diferencia de otras soluciones, no requiere reglas ni plantillas separadas para cada nuevo tipo de documento. En cambio, se basa en la inteligencia cognitiva para manejar documentos semiestructurados e invisibles mientras mejora con el tiempo. También puede personalizar la salida para extraer solo tablas o entradas de datos de su interés.
Es rápido, preciso, fácil de usar, permite a los usuarios crear modelos OCR personalizados desde cero y tiene algunas integraciones geniales con Zapier. Digitalice documentos, extraiga tablas o campos de datos e integre con sus aplicaciones diarias a través de API en una interfaz simple e intuitiva.
¿Por qué Nanonets es el mejor OCR?
- Las nanoredes pueden extraer datos en la página, mientras que los analizadores de PDF de línea de comando solo extraen objetos, encabezados y metadatos como (título, páginas, estado de cifrado, etc.)
- La tecnología de análisis de PDF de Nanonets no se basa en plantillas. Además de ofrecer modelos previamente entrenados para casos de uso populares, el algoritmo de análisis de PDF de Nanonets también puede manejar tipos de documentos invisibles.
- ¡Además de manejar documentos PDF nativos, las capacidades integradas de OCR de Nanonet le permiten manejar documentos e imágenes escaneados también!
- Funciones de automatización robustas con capacidades de IA y ML.
- Las nanoredes manejan datos no estructurados, restricciones de datos comunes, documentos PDF de varias páginas, tablas y elementos de varias líneas con facilidad.
- Nanonets es una herramienta sin código que puede aprender y volver a capacitarse continuamente en datos personalizados para proporcionar resultados que no requieren procesamiento posterior.
Análisis de facturas automatizado con Nanonets: creación de flujos de trabajo de procesamiento de facturas completamente sin contacto.
Integre sus herramientas existentes con Nanonets y automatice la recopilación de datos, el almacenamiento de exportación y la contabilidad.
Nanonets también puede ayudar a automatizar los flujos de trabajo de análisis de facturas al:
- Importación y consolidación de datos de facturas de múltiples fuentes: correo electrónico, documentos escaneados, archivos/imágenes digitales, almacenamiento en la nube, ERP, API, etc.
- Capturar y extraer datos de facturas de forma inteligente a partir de facturas, recibos, facturas y otros documentos financieros.
- Categorización y codificación de transacciones basadas en reglas de negocio.
- Configuración de flujos de trabajo de aprobación automatizados para obtener aprobaciones internas y administrar excepciones.
- Conciliación de todas las transacciones.
- Se integra perfectamente con ERP o software de contabilidad como Quickbooks, Sage, Xero, Netsuite y más.
Referencias
[ 1 ] ¿Puedo reconocer texto escrito a mano en ABBYY FineReader? - Centro de ayuda
[ 2 ] ABBYY FineReader VS Amazon Textract: ¿comparar diferencias y reseñas?
[ 3 ] Los 7 mejores software OCR de 2022 (gratuitos y de pago)
[ 4 ] Los 10 mejores software de OCR en 2022 | Las mejores soluciones de OCR
[ 6 ] Ephesoft frente a FineReader PDF para Windows y Mac 2022 | G2
[ 7 ] 21 mejores software de OCR en 2022
[ 8 ] Tesseract OCR en Python con Pytesseract y OpenCV
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://nanonets.com/blog/abbyy-reviews-compare-competitors-alternatives/

