Con Desplazamiento al rojo de Amazon, puede ejecutar una combinación compleja de cargas de trabajo en su almacén de datos, como cargas de datos frecuentes que se ejecutan junto con consultas de paneles de control críticas para el negocio y trabajos de transformación complejos. También vemos cada vez más cargas de trabajo de ciencia de datos y aprendizaje automático (ML). Cada tipo de carga de trabajo tiene diferentes necesidades de recursos y diferentes acuerdos de nivel de servicio (SLA).
Desplazamiento al rojo de Amazon gestión de carga de trabajo (WLM) lo ayuda a maximizar el rendimiento de las consultas y obtener un rendimiento consistente para las cargas de trabajo de análisis más exigentes mediante el uso óptimo de los recursos de su almacén de datos existente.
En Amazon Redshift, usted implementar WLM para definir el número de colas de consultas que están disponibles y cómo se enrutan las consultas a esas colas para su procesamiento. Las colas WLM se configuran en función de grupos de usuarios, roles de usuario o grupos de consultas de Redshift. Cuando los usuarios que pertenecen a un grupo de usuarios o rol ejecutan consultas en la base de datos, sus consultas se enrutan a una cola como se muestra en el siguiente diagrama de flujo.

Control de acceso basado en roles (RBAC) es una nueva mejora que le ayuda a simplificar la administración de privilegios de seguridad en Amazon Redshift. Puede utilizar RBAC para controlar el acceso de los usuarios finales a los datos en un nivel amplio o granular según su función laboral. Hemos introducido soporte para Roles de corrimiento al rojo en colas WLM, ahora encontrará Roles del usuario para cada año fiscal junto con la Grupos de Usuarios y Grupos de consulta como mecanismo de enrutamiento de consultas.
Esta publicación proporciona ejemplos de cargas de trabajo de análisis para una empresa y comparte desafíos comunes y formas de mitigarlos utilizando WLM. Lo guiamos a través de patrones WLM comunes y cómo se pueden asociar con las configuraciones de su almacén de datos. También mostramos cómo asignar roles de usuario a colas WLM y cómo utilizar información de consultas WLM para optimizar la configuración.
Resumen del caso de uso
EjemploCorp es una empresa que utiliza Amazon Redshift para modernizar su plataforma de datos y análisis. Tienen una variedad de cargas de trabajo con usuarios de varios departamentos y personas. Los requisitos de rendimiento del nivel de servicio varían según la naturaleza de la carga de trabajo y los usuarios que acceden a los conjuntos de datos. A exampleCorp le gustaría administrar recursos y prioridades en Amazon Redshift mediante colas WLM. Para esta arquitectura multiinquilino por departamento, EjemploCorp puede lograr aislamiento de lectura/escritura utilizando el Uso compartido de datos de Amazon Redshift característica y cumplir con sus impredecibles requisitos de escalamiento informático utilizando escala de concurrencia.
La siguiente figura ilustra las personas de usuario y el acceso en EjemploCorp.
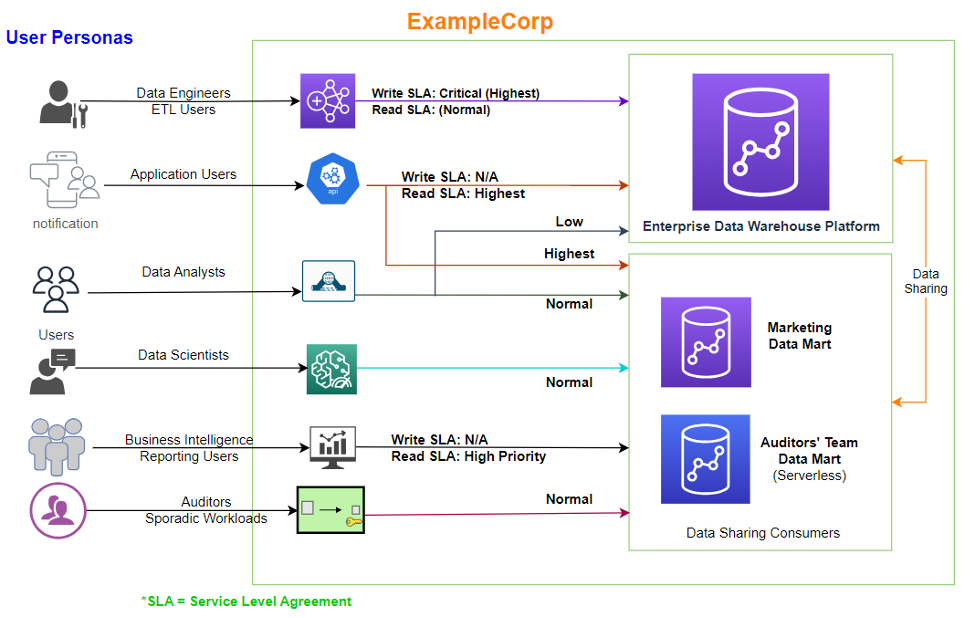
EjemploCorp tiene varios clústeres de Redshift. Para esta publicación, nos centramos en lo siguiente:
- Plataforma de almacén de datos empresariales (EDW) – Esto tiene todas las cargas de trabajo de escritura, junto con algunas de las aplicaciones que ejecutan lecturas a través del API de datos Redshift. Múltiples clústeres de consumidores acceden a los datos estandarizados empresariales del clúster EDW mediante la función de intercambio de datos Redshift para ejecutar informes posteriores, paneles y otras cargas de trabajo de análisis.
- Mercado de datos de marketing – Tiene cargas de trabajo de extracción, transformación y carga (ETL) y de inteligencia empresarial (BI) predecibles en momentos específicos del día. El administrador del clúster comprende los requisitos exactos de recursos por tipo de carga de trabajo.
- Mercado de datos del auditor – Esto sólo se utiliza durante unas pocas horas al día para ejecutar informes programados.
A EjemploCorp le gustaría gestionar mejor sus cargas de trabajo utilizando WLM.
Resumen de la solución
Como comentamos en la sección anterior, EjemploCorp tiene múltiples almacenes de datos de Redshift: un almacén de datos empresarial y dos almacenes de datos de Redshift posteriores. Cada almacén de datos tiene diferentes cargas de trabajo, SLA y requisitos de simultaneidad.
Un administrador de base de datos (DBA) implementará estrategias WLM apropiadas en cada almacén de datos de Redshift según su caso de uso. Para esta publicación, utilizamos los siguientes ejemplos:
- El almacén de datos empresarial demuestra Auto WLM con prioridades de consulta
- El clúster de data mart de marketing demuestra WLM manual
- El equipo de auditores utiliza su data mart con poca frecuencia para cargas de trabajo esporádicas; ellos usan Amazon Redshift sin servidor, que no requiere gestión de carga de trabajo
El siguiente diagrama ilustra la arquitectura de la solución.

Requisitos previos
Antes de comenzar esta solución, necesita lo siguiente:
- Una cuenta de AWS
- Acceso administrativo a Amazon Redshift
Comencemos por comprender algunos conceptos fundamentales antes de resolver el planteamiento del problema de EjemploCorp. Primero, cómo elegir entre WLM automático o manual.
WLM automático versus manual
Amazon Redshift WLM le permite administrar de manera flexible las prioridades dentro de las cargas de trabajo para cumplir con sus SLA. Amazon Redshift admite WLM automático o WLM manual para su almacén de datos de Redshift aprovisionado. El siguiente diagrama ilustra las colas para cada opción.

Auto WLM determina la cantidad de recursos que necesitan las consultas y ajusta la simultaneidad en función de la carga de trabajo. Cuando hay consultas en el sistema que requieren grandes cantidades de recursos (por ejemplo, uniones hash entre tablas grandes), la simultaneidad es menor. Para obtener información adicional, consulte Implementación de WLM automático. Debe utilizar Auto WLM cuando su carga de trabajo sea muy impredecible.
Con WLM manual, usted administra la simultaneidad de consultas y la asignación de memoria, a diferencia del WLM automático, donde Amazon Redshift lo administra automáticamente. Usted configura colas WLM separadas para diferentes cargas de trabajo como ETL, BI y ad hoc y personaliza la asignación de recursos. Para obtener información adicional, consulte Tutorial: Configuración de colas de gestión manual de carga de trabajo (WLM).
Utilice el manual cuando su patrón de carga de trabajo sea predecible o si necesita limitar ciertos tipos de consultas según la hora del día, como limitar la ingesta durante el horario comercial. Si necesita garantizar que se puedan ejecutar varias cargas de trabajo al mismo tiempo, puede definir ranuras para cada carga de trabajo.
Ahora que ha elegido WLM automático o manual, exploremos los parámetros y propiedades de WLM.
Propiedades estáticas versus dinámicas
La configuración de WLM para un almacén de datos de Redshift se establece mediante un grupo de parámetros en las propiedades de configuración de la base de datos.

Los ajustes WLM del grupo de parámetros son lugar de trabajo dinámico or estático. Puede aplicar propiedades dinámicas a la base de datos sin reiniciar el clúster, pero las propiedades estáticas requieren un reinicio del clúster para que los cambios surtan efecto. La siguiente tabla resume los requisitos estáticos y dinámicos para diferentes propiedades de WLM.
| Propiedad WLM | WLM automático | WLM manual |
| Grupos de consulta | Dynamic | Estático |
| Comodín de grupo de consulta | Dynamic | Estático |
| Grupos de Usuarios | Dynamic | Estático |
| Comodín de grupo de usuarios | Dynamic | Estático |
| Roles del usuario | Dynamic | Estático |
| Comodín de rol de usuario | Dynamic | Estático |
| Concurrencia en principal | No es aplicable | Dynamic |
| Modo de escalado de simultaneidad | Dynamic | Dynamic |
| Habilitar la aceleración de consultas cortas | No es aplicable | Dynamic |
| Tiempo de ejecución máximo para consultas cortas | Dynamic | Dynamic |
| Porcentaje de memoria a utilizar | No es aplicable | Dynamic |
| Tiempo de espera | No es aplicable | Dynamic |
| Prioridad | Dynamic | No es aplicable |
| Agregar o eliminar colas | Dynamic | Estático |
Tenga en cuenta lo siguiente:
- Los parámetros del grupo de parámetros y el cambio de WLM de manual a automático o viceversa son propiedades estáticas y, por lo tanto, requieren un reinicio del clúster.
- Para las propiedades de WLM Simultaneidad en principal, Porcentaje de memoria a utilizar y Tiempo de espera, que son dinámicas para WLM manual, el cambio solo se aplica a las consultas nuevas enviadas después de que el valor haya cambiado y no a las consultas que se están ejecutando actualmente.
- Las reglas de monitoreo de consultas, que analizaremos más adelante en esta publicación, son dinámicas y no requieren reiniciar el clúster.
En la siguiente sección, analizamos el concepto de clase de servicio, es decir, a qué cola se envía la consulta y por qué.
Clase de servicio
Ya sea que utilice WLM automático o manual, las consultas de usuario enviadas van a la cola de WLM deseada a través de uno de los siguientes mecanismos:
- Grupos de Usuarios – La cola WLM se asigna directamente a Grupos de corrimiento al rojo eso aparecería en la tabla pg_group.
- Grupos_de consulta – La asignación de cola se basa en la grupo_consulta etiqueta. Por ejemplo, un panel enviado por el mismo usuario de informes puede tener prioridades separadas por designación o departamento.
- User_Roles (última incorporación) – La cola se asigna en función de la Roles de corrimiento al rojo.
Las colas WLM desde una perspectiva de metadatos se definen como clase de servicio configuración. La siguiente tabla enumera los comunes identificadores de clase de servicio para tu referencia.
| ID | Clase de servicio |
| 1-4 | Reservado para uso del sistema. |
| 5 | Utilizado por la cola de superusuario. |
| 6-13 | Utilizado por colas WLM manuales que se definen en la configuración de WLM. |
| 14 | Utilizado por aceleración de consultas cortas. |
| 15 | Reservado para actividades de mantenimiento ejecutadas por Amazon Redshift. |
| 100-107 | Utilizado por la cola WLM automática cuando auto_wlm es verdad. |
Las colas WLM que usted define en función de user_groups, query_groupso user_roles caen en la clase de servicio ID 6–13 para WLM manual y en la clase de servicio ID 100–107 para WLM automático.
Usar Query_group, puede forzar que una consulta vaya a la clase de servicio 5 y se ejecute en la cola de superusuario (siempre que sea un superusuario autorizado) como se muestra en el siguiente código:
Para obtener más detalles sobre cómo asignar una consulta a una clase de servicio particular, consulte Asignar consultas a colas.
La cola de aceleración de consultas cortas (SQA) (clase de servicio 14) prioriza las consultas de ejecución corta por delante de las consultas de ejecución más larga. Si habilita SQA, puede reducir las colas WLM dedicadas a ejecutar consultas breves. Además, las consultas de larga duración no necesitan competir con consultas cortas para espacios en una cola, por lo que puede configurar sus colas WLM para usar menos espacios de consulta (un término utilizado para la simultaneidad disponible). Amazon Redshift utiliza un algoritmo de aprendizaje automático para analizar cada consulta elegible y predecir el tiempo de ejecución de la consulta. Auto WLM asigna dinámicamente un valor para el tiempo de ejecución máximo de SQA según el análisis de la carga de trabajo de su clúster. Como alternativa, puede especificar un valor fijo de 1 a 20 segundos cuando utilice WLM manual.
SQA está habilitado de forma predeterminada en el grupo de parámetros predeterminado y para todos los grupos de parámetros nuevos. SQA puede tener una simultaneidad máxima de seis consultas.
Ahora que comprende cómo se envían las consultas a una clase de servicio, es importante comprender formas de evitar consultas fuera de control e iniciar una acción para un evento no deseado.
Reglas de monitoreo de consultas
Puedes utilizar Amazon Redshift reglas de supervisión de consultas (QMR) para establecer límites de rendimiento basados en métricas para colas WLM y especificar qué acción tomar cuando una consulta va más allá de esos límites.
El clúster de Redshift recopila automáticamente métricas de monitoreo de consultas. Puedes consultar la vista del sistema. SVL_QUERY_METRICS_SUMMARY como ayuda para determinar los valores umbral para definir el QMR. Luego cree el QMR según los siguientes atributos:
- Tiempo de ejecución de la consulta, en segundos
- Recuento de filas de retorno de consulta
- El tiempo de CPU para una declaración SQL
Para obtener una lista completa de QMR, consulte Reglas de supervisión de consultas WLM.

Crear grupos de parámetros de muestra
Para nuestro caso de uso de EjemploCorp, demostramos WLM automático y manual para un almacén de datos Redshift aprovisionado y compartimos una perspectiva sin servidor de WLM.
Las siguientes Formación en la nube de AWS plantilla proporciona una forma automatizada de crear grupos de parámetros de muestra que puede adjuntar a su almacén de datos de Redshift para la gestión de cargas de trabajo.
![]()
Clúster Redshift de almacén de datos empresariales que utiliza WLM automático
Para el clúster EDW, utilizamos Auto WLM. Para configurar la clase de servicio, analizamos las tres opciones: user_roles, user_groupsy query_groups.
A continuación se ofrece un vistazo de cómo se puede configurar esto en colas WLM y luego utilizarlo en sus consultas.
En la consola de Amazon Redshift, en Configuraciones en el panel de navegación, elija Gestión de carga de trabajo. Puede crear un nuevo grupo de parámetros o modificar uno existente creado por usted. Seleccione el grupo de parámetros para editar sus colas. Siempre hay una cola predeterminada (la última en caso de que se definan varias colas), que sirve para todas las consultas que no se enrutan a ninguna cola específica.

Roles de usuario en WLM
Con la introducción de roles de usuario en las colas WLM, ahora puede administrar su carga de trabajo agregando diferentes roles a diferentes colas. Esto puede ayudarle a priorizar las consultas según los roles que tiene un usuario. Cuando un usuario ejecuta una consulta, WLM verificará si los roles de este usuario se agregaron en alguna cola de carga de trabajo y asignará la consulta a la primera cola coincidente. Para agregar roles a la cola de WLM, puede ir a la página de WLM, crear o modificar una cola de carga de trabajo existente, agregar los roles de un usuario en la cola y seleccionar Comodines coincidentes para agregar roles que coincidan como comodines.
Para obtener más información sobre cómo convertir de grupos a roles, consulte Funciones de desplazamiento al rojo de Amazon (RBAC), que te guía a través de un procedimiento almacenado para convertir grupos en roles.
En el siguiente ejemplo, hemos creado la cola WLM. EDW_Admins, Que utiliza edw_admin_role creado en Amazon Redshift para enviar las cargas de trabajo en esta cola. El EDW_Admins La cola se crea con un modo de escalado de simultaneidad automático y de alta prioridad.

Grupos de Usuarios
Los grupos son colecciones de usuarios a los que se les conceden permisos asociados con el grupo. Puede utilizar grupos para simplificar la administración de permisos otorgando privilegios solo una vez. Si los miembros de un grupo se agregan o eliminan, no es necesario administrarlos a nivel de usuario. Por ejemplo, puede crear diferentes grupos para ventas, administración y soporte y brindar a los usuarios de cada grupo el acceso adecuado a los datos que necesitan para su trabajo.
Puede otorgar o revocar permisos en el nivel de grupo de usuarios, y esos cambios se aplicarán a todos los miembros del grupo.
ETL, analistas de datos o BI o sistemas de soporte a decisiones pueden utilizar grupos de usuarios para gestionar y aislar mejor sus cargas de trabajo. Para nuestro ejemplo, las consultas de cola ETL WLM se ejecutarán con el grupo de usuarios etl. Las consultas de cola WLM del grupo de analistas de datos (BI) se ejecutarán utilizando el grupo de usuarios bi.
Elige Agregar cola para agregar una nueva cola que usará para user_groups, en este caso ETL. Si desea que coincidan como comodines (cadenas que contienen esas palabras clave), seleccione Comodines coincidentes. Puede personalizar otras opciones, como la prioridad de consulta y el escalado de simultaneidad, como se explicó anteriormente en esta publicación. Elegir Guardar para completar esta configuración de cola.
En el siguiente ejemplo, hemos creado dos colas WLM diferentes para ETL y BI. La cola ETL tiene una prioridad alta y el modo de escalado de simultaneidad está desactivado, mientras que la cola de BI tiene una prioridad baja y el modo de escalado de simultaneidad está desactivado.


Utilice el siguiente código para crear un grupo con varios usuarios:
Grupos de consulta
Query_Groups son etiquetas utilizadas para consultas que se ejecutan dentro de la misma sesión. Piense en ellas como etiquetas que quizás desee utilizar para identificar consultas para un caso de uso identificable de forma única. En nuestro caso de uso de ejemplo, los analistas de datos o BI o los sistemas de soporte de decisiones pueden usar query_groups para gestionar y aislar mejor sus cargas de trabajo. Para nuestro ejemplo, los informes comerciales semanales se pueden ejecutar con el query_group etiqueta wbr. Las consultas del departamento de marketing se pueden ejecutar con un query_group de mercadeo
El beneficio de usar grupos_query es que puedes usarlo para restringir los resultados del STL_QUERY y STV_INFLIGHT mesas y el SVL_QLOG vista. Puede aplicar una etiqueta independiente a cada consulta que ejecute para identificar consultas de forma única sin tener que buscar sus ID.
Elige Agregar cola para agregar una nueva cola que usará para query_groups, en este caso wbr or weekly_business_report. Si desea que coincidan como comodines (cadenas que contienen esas palabras clave), seleccione Comodines coincidentes. Puede personalizar otras opciones, como la prioridad de consulta y las opciones de escalado de simultaneidad, como se explicó anteriormente en esta publicación. Elegir Guardar para guardar esta configuración de cola.

Ahora veamos cómo se puede forzar que una consulta utilice el query_groups cola recién creada.
Puede asignar una consulta a una cola en tiempo de ejecución asignando su consulta al grupo de consultas apropiado. Utilice el comando SET para comenzar un grupo de consulta:
Las consultas que siguen al comando SET irían a la cola WLM Query_Group_WBR hasta que restablezca el grupo de consulta o finalice su sesión de inicio de sesión actual. Para obtener información sobre cómo configurar y restablecer el parámetro de configuración del servidor, consulte SET y REAJUSTE, respectivamente.
Las etiquetas del grupo de consulta que especifique deben incluirse en la configuración actual de WLM; de lo contrario, el SET query_group El comando no tiene ningún efecto en las colas de consultas.
Para obtener más query_groups ejemplos, consulte Reglas de asignación de colas WLM.
Clúster de Marketing Redshift mediante WLM manual
Ampliando el caso de uso del clúster de marketing Redshift de EjemploCorp, este clúster sirve dos tipos de cargas de trabajo:
- Ejecutando ETL por un período de 2 horas entre las 7:00 a. m. y las 9:00 a. m.
- Ejecutar informes y paneles de BI durante el tiempo restante del día.
Cuando tenga tanta claridad en las cargas de trabajo y su alcance de uso sea personalizable por diseño, es posible que desee considerar el uso WLM manual, donde puede controlar la memoria y la asignación de recursos de simultaneidad. La WLM automática seguirá siendo aplicable, pero la WLM manual también puede ser una opción.
Vamos configurar WLM manual en este caso, con dos colas WLM: ETL y BI.
Para utilizar mejor los recursos, utilizamos un Interfaz de línea de comandos de AWS (AWS CLI) al inicio de nuestra ETL, lo que hará que nuestras colas WLM sean compatibles con ETL, proporcionando una mayor simultaneidad a la cola ETL. Al final de nuestra ETL, utilizamos un comando de AWS CLI para cambiar la cola WLM para que tenga una configuración de recursos compatible con BI. Para modificar las colas WLM no es necesario reiniciar el clúster; sin embargo, modificar los parámetros o el grupo de parámetros sí lo hace.
Si hubiera utilizado Auto WLM, esto podría haberse logrado cambiando dinámicamente la prioridad de consulta de las colas ETL y BI.
Por defecto, cuando eliges Crear, el WLM creado será Auto WLM. Puede cambiar a WLM manual eligiendo Cambiar el modo WLM. Después de cambiar el modo WLM, elija Editar colas de cargas de trabajo.

Esto abrirá la Modificar colas de carga de trabajo página, donde puede crear sus colas ETL y BI WLM.

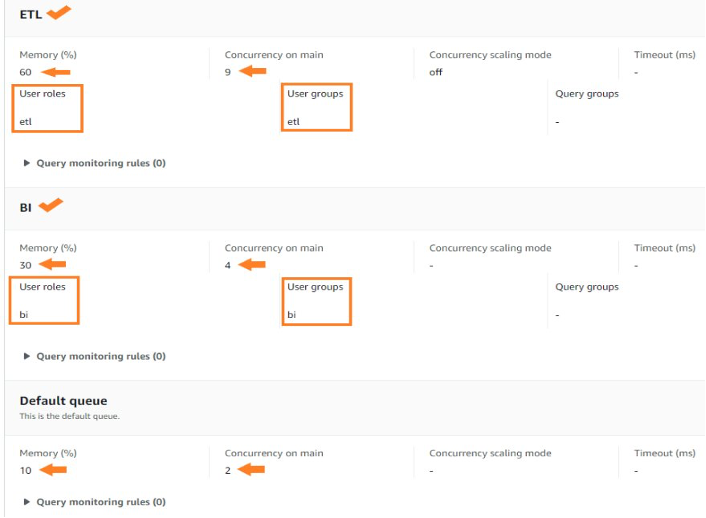
Después de agregar sus colas ETL y BI, elija Guardar. Deberías haber configurado lo siguiente:
- Una cola ETL con una asignación de memoria del 60 % y una simultaneidad de consultas de 9
- Una cola de BI con una asignación de memoria del 30 % y una simultaneidad de consultas de 4
- Una cola predeterminada con una asignación de memoria del 10 % y una simultaneidad de consultas de 2
Sus colas WLM deberían aparecer con la configuración como se muestra en la siguiente captura de pantalla.
Es posible que las empresas prefieran completar estos pasos de forma automatizada. Para el caso de uso del mercado de datos de marketing, el ETL comienza a las 7:00 a. m. Un comienzo ideal para el flujo de ETL sería tener un trabajo que haga que la cola ETL de la configuración de WLM sea compatible. A continuación se explica cómo modificaría la simultaneidad y la memoria (ambas propiedades dinámicas en las colas WLM manuales) a una configuración compatible con ETL:

El comando de AWS CLI anterior establece mediante programación la configuración de sus colas WLM sin necesidad de reiniciar el clúster porque las configuraciones de cola cambiadas eran todas configuraciones dinámicas.
Para el caso de uso del mercado de datos de marketing, a las 9:00 a. m. o cuando finalice el ETL, puede hacer que un trabajo ejecute un comando de AWS CLI para modificar la configuración de recursos de la cola WLM a una configuración compatible con BI, como se muestra en el siguiente código:

Tenga en cuenta que con respecto a una configuración WLM manual, las ranuras máximas que puede asignar a una cola son 50. Sin embargo, esto no significa que en una configuración WLM automática, un clúster de Redshift siempre ejecute 50 consultas simultáneamente. Esto puede cambiar según las necesidades de memoria u otros tipos de asignación de recursos en el clúster. Recomendamos configurar sus colas de consultas WLM manuales con un total de 15 espacios de consulta o menos. Para más información, ver nivel de concurrencia.
En caso de Tiempo de espera de WLM o un Acción de salto QMR dentro de WLM manual, una consulta puede intentar saltar a la siguiente cola coincidente según Reglas de asignación de colas WLM. Esta acción en WLM manual se llama salto de cola de consultas.
Auditor del almacén de datos de Redshift utilizando WLM en Redshift Serverless
La carga de trabajo del almacén de datos del auditor se ejecuta al final del mes y del trimestre. Para esta carga de trabajo periódica, Redshift Serverless es muy adecuado, tanto desde el punto de vista del costo como de la facilidad de administración. Redshift Serverless utiliza ML para aprender de su carga de trabajo para administrar automáticamente la carga de trabajo y escalar automáticamente la computación necesaria para su carga de trabajo.
En Redshift Serverless, puede configurar límites de uso y consultas. Los límites de consulta le permiten configurar el QMR. Tu puedes elegir Administrar límites de consultas para activar automáticamente la acción de cancelación predeterminada cuando las consultas superan los límites de rendimiento. Para obtener más información, consulte Métricas de monitoreo de consultas para Amazon Redshift Serverless.
![]()

Para conocer otros límites detallados en Redshift Serverless, consulte Configure monitoreo, límites y alarmas en Amazon Redshift Serverless para mantener los costos predecibles.
Monitorear usando vistas del sistema para métricas operativas
Las vistas del sistema en Amazon Redshift se utilizan para monitorear el rendimiento de la carga de trabajo. Puede ver el estado de consultas, colas y clases de servicio utilizando Sistema específico de WLM mesas. Puede consultar las tablas del sistema para explorar los siguientes detalles:
- Ver qué consultas se están rastreando y qué recursos asigna el administrador de carga de trabajo
- Ver a qué cola se ha asignado una consulta
- Ver el estado de una consulta que actualmente está siendo rastreada por el administrador de carga de trabajo
Puedes descargar la muestra. cuaderno SQL consultas del sistema. Puedes importar esto en Editor de consultas V2.0. Las consultas del cuaderno de muestra pueden ayudarle a explorar las cargas de trabajo que administran las colas WLM.
Conclusión
En esta publicación, cubrimos ejemplos del mundo real para patrones de WLM automático y WLM manual. Introdujimos la asignación de roles de usuario a las colas WLM y compartimos consultas sobre vistas y tablas del sistema para recopilar información operativa sobre su configuración WLM. Le recomendamos que explore el uso de roles de usuario de Redshift con la gestión de cargas de trabajo. Utilizar el script proporcionado en AWS re:Post para convertir grupos en roles y comenzar a usar roles de usuario para sus colas WLM.
Acerca de los autores
 Rohit Vashishta es un arquitecto senior de soluciones especializado en análisis en AWS con sede en Dallas, Texas. Tiene más de 17 años de experiencia diseñando, construyendo, liderando y manteniendo plataformas de big data. Rohit ayuda a los clientes a modernizar sus cargas de trabajo analíticas utilizando la variedad de servicios de AWS y garantiza que los clientes obtengan la mejor relación precio/rendimiento con la máxima seguridad y gobernanza de datos.
Rohit Vashishta es un arquitecto senior de soluciones especializado en análisis en AWS con sede en Dallas, Texas. Tiene más de 17 años de experiencia diseñando, construyendo, liderando y manteniendo plataformas de big data. Rohit ayuda a los clientes a modernizar sus cargas de trabajo analíticas utilizando la variedad de servicios de AWS y garantiza que los clientes obtengan la mejor relación precio/rendimiento con la máxima seguridad y gobernanza de datos.
 Harshida Patel es un especialista principal SA con AWS.
Harshida Patel es un especialista principal SA con AWS.
 Nita Shah es un arquitecto de soluciones especialista en análisis en AWS con sede en Nueva York. Ha estado creando soluciones de almacenamiento de datos durante más de 20 años y se especializa en Amazon Redshift. Se enfoca en ayudar a los clientes a diseñar y construir plataformas de análisis y soporte de decisiones bien diseñadas a escala empresarial.
Nita Shah es un arquitecto de soluciones especialista en análisis en AWS con sede en Nueva York. Ha estado creando soluciones de almacenamiento de datos durante más de 20 años y se especializa en Amazon Redshift. Se enfoca en ayudar a los clientes a diseñar y construir plataformas de análisis y soporte de decisiones bien diseñadas a escala empresarial.
 Yanzhu-ji es gerente de producto en el equipo de Amazon Redshift. Tiene experiencia en visión y estrategia de productos en plataformas y productos de datos líderes en la industria. Tiene una habilidad sobresaliente en la creación de productos de software sustanciales utilizando técnicas de desarrollo web, diseño de sistemas, bases de datos y programación distribuida. En su vida personal, a Yanzhu le gusta pintar, fotografiar y jugar al tenis.
Yanzhu-ji es gerente de producto en el equipo de Amazon Redshift. Tiene experiencia en visión y estrategia de productos en plataformas y productos de datos líderes en la industria. Tiene una habilidad sobresaliente en la creación de productos de software sustanciales utilizando técnicas de desarrollo web, diseño de sistemas, bases de datos y programación distribuida. En su vida personal, a Yanzhu le gusta pintar, fotografiar y jugar al tenis.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/manage-your-workloads-better-using-amazon-redshift-workload-management/

