Generador de imágenes Amazon Titan G1 es un modelo de última generación de conversión de texto a imagen, disponible a través de lecho rocoso del amazonas, que es capaz de comprender indicaciones que describen múltiples objetos en diversos contextos y captura estos detalles relevantes en las imágenes que genera. Está disponible en las regiones de AWS EE. UU. Este (Norte de Virginia) y EE. UU. Oeste (Oregón) y puede realizar tareas avanzadas de edición de imágenes, como recorte inteligente, pintura y cambios de fondo. Sin embargo, a los usuarios les gustaría adaptar el modelo a características únicas en conjuntos de datos personalizados en los que el modelo aún no está entrenado. Los conjuntos de datos personalizados pueden incluir datos de propiedad exclusiva que sean coherentes con las directrices de su marca o estilos específicos, como una campaña anterior. Para abordar estos casos de uso y generar imágenes totalmente personalizadas, puede ajustar Amazon Titan Image Generator con sus propios datos usando modelos personalizados para Amazon Bedrock.
Desde generar imágenes hasta editarlas, los modelos de texto a imagen tienen amplias aplicaciones en todas las industrias. Pueden mejorar la creatividad de los empleados y brindarles la capacidad de imaginar nuevas posibilidades simplemente con descripciones textuales. Por ejemplo, puede ayudar a los arquitectos en el diseño y la planificación de plantas y permitir una innovación más rápida al brindar la capacidad de visualizar varios diseños sin el proceso manual de creación. De manera similar, puede ayudar en el diseño en diversas industrias, como la fabricación, el diseño de moda en el comercio minorista y el diseño de juegos, al optimizar la generación de gráficos e ilustraciones. Los modelos de texto a imagen también mejoran la experiencia del cliente al permitir publicidad personalizada, así como chatbots visuales interactivos e inmersivos en casos de uso de medios y entretenimiento.
En esta publicación, lo guiamos a través del proceso de ajuste del modelo Amazon Titan Image Generator para aprender dos nuevas categorías: Ron el perro y Smila la gata, nuestras mascotas favoritas. Analizamos cómo preparar sus datos para la tarea de ajuste del modelo y cómo crear un trabajo de personalización del modelo en Amazon Bedrock. Finalmente, le mostramos cómo probar e implementar su modelo ajustado con Rendimiento aprovisionado.
 |
 |
| ron el perro | smila el gato |
Evaluación de las capacidades del modelo antes de ajustar un trabajo
Los modelos básicos se entrenan con grandes cantidades de datos, por lo que es posible que su modelo funcione lo suficientemente bien desde el primer momento. Por eso es una buena práctica comprobar si realmente necesita ajustar su modelo para su caso de uso o si una ingeniería rápida es suficiente. Intentemos generar algunas imágenes del perro Ron y la gata Smila con el modelo base de Amazon Titan Image Generator, como se muestra en las siguientes capturas de pantalla.
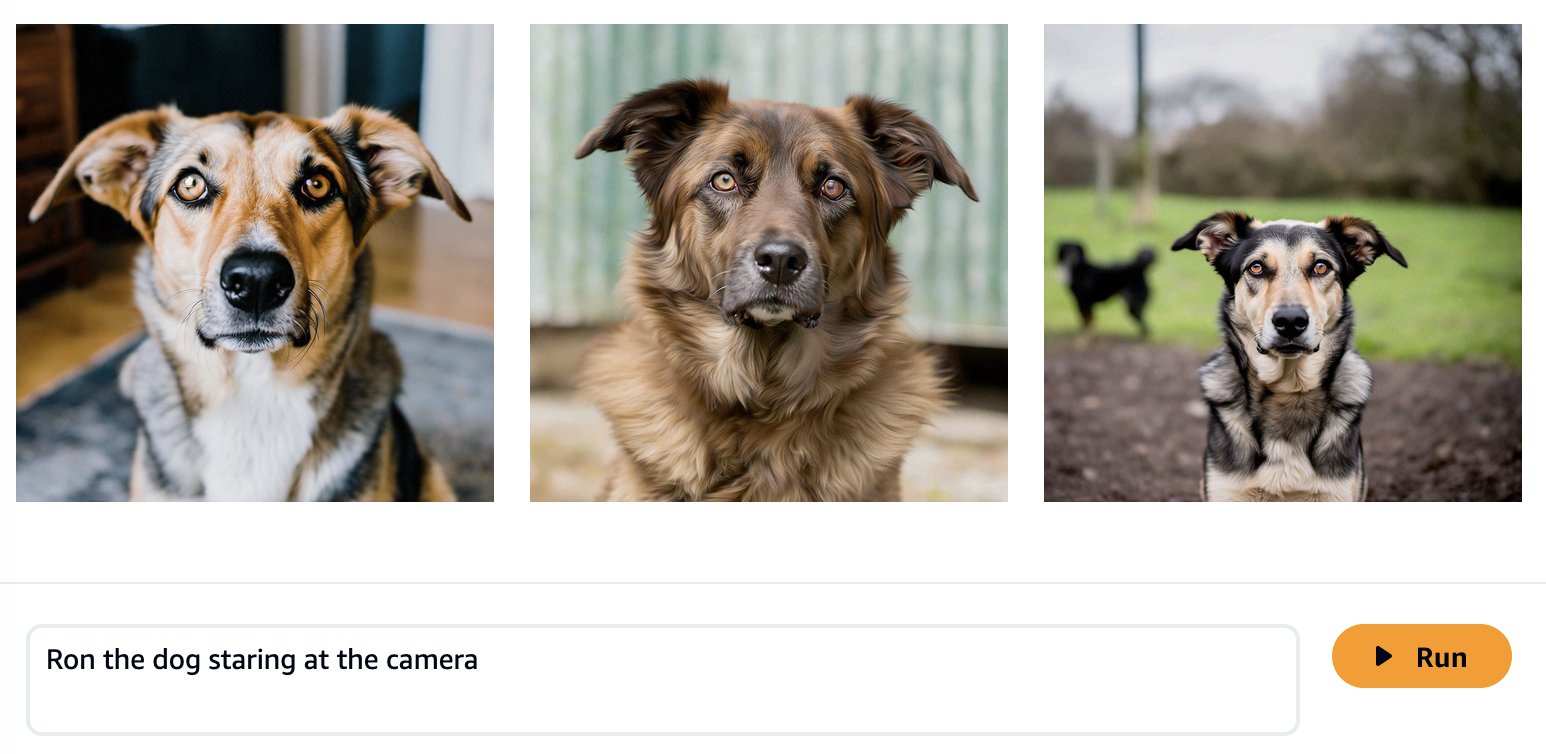

Como era de esperar, el modelo listo para usar aún no conoce a Ron y Smila, y los resultados generados muestran diferentes perros y gatos. Con un poco de ingeniería rápida, podemos proporcionar más detalles para acercarnos al aspecto de nuestras mascotas favoritas.


Aunque las imágenes generadas son más similares a Ron y Smila, vemos que el modelo no es capaz de reproducir la imagen completa de ellos. Ahora comencemos un trabajo de ajuste con las fotos de Ron y Smila para obtener resultados consistentes y personalizados.
Ajuste del generador de imágenes Amazon Titan
Amazon Bedrock le brinda una experiencia sin servidor para ajustar su modelo de Amazon Titan Image Generator. Solo necesita preparar sus datos y seleccionar sus hiperparámetros, y AWS se encargará del trabajo pesado por usted.
Cuando utiliza el modelo de Amazon Titan Image Generator para realizar ajustes, se crea una copia de este modelo en la cuenta de desarrollo del modelo de AWS, propiedad de AWS y administrada por él, y se crea un trabajo de personalización del modelo. Luego, este trabajo accede a los datos de ajuste fino de una VPC y el modelo de Amazon Titan actualiza sus pesos. Luego, el nuevo modelo se guarda en un Servicio de almacenamiento simple de Amazon (Amazon S3) ubicado en la misma cuenta de desarrollo del modelo que el modelo previamente entrenado. Ahora solo su cuenta puede utilizarlo para realizar inferencias y no se comparte con ninguna otra cuenta de AWS. Al ejecutar la inferencia, se accede a este modelo a través de un cálculo de capacidad aprovisionada o directamente, utilizando inferencia por lotes para Amazon Bedrock. Independientemente de la modalidad de inferencia elegida, sus datos permanecen en su cuenta y no se copian a ninguna cuenta propiedad de AWS ni se utilizan para mejorar el modelo de Amazon Titan Image Generator.
El siguiente diagrama ilustra este flujo de trabajo.
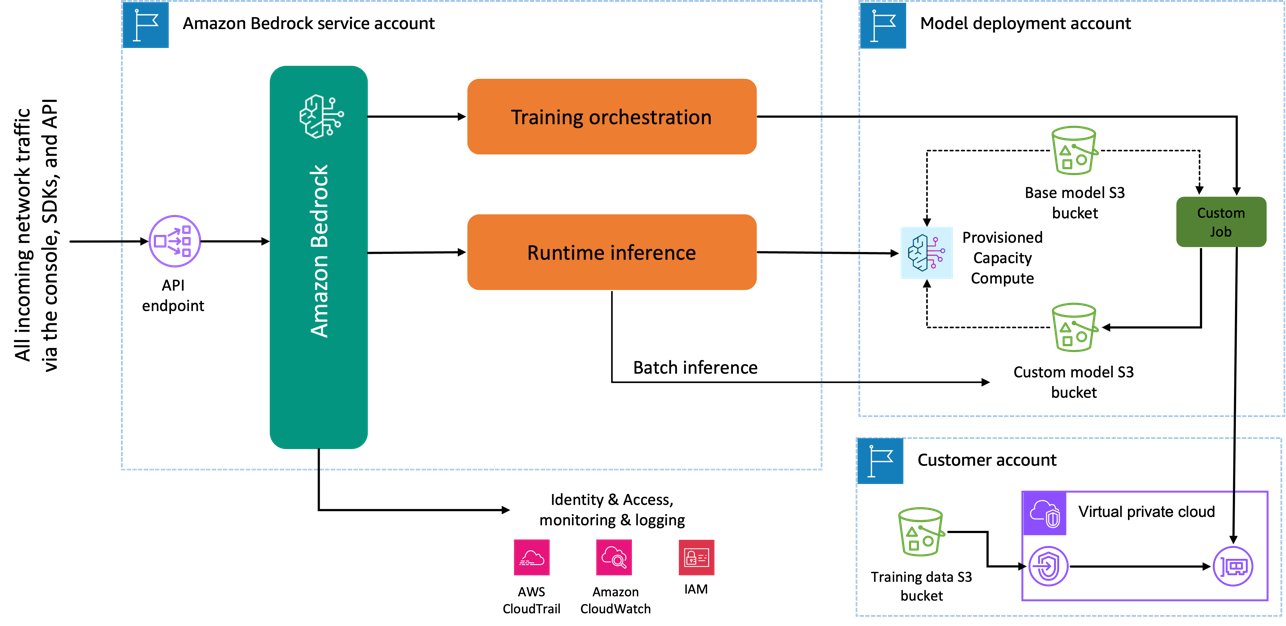
Privacidad de datos y seguridad de la red
Sus datos utilizados para el ajuste, incluidas las indicaciones, así como los modelos personalizados, permanecen privados en su cuenta de AWS. No se comparten ni se utilizan para capacitación de modelos o mejoras de servicios, y no se comparten con proveedores de modelos externos. Todos los datos utilizados para el ajuste se cifran en tránsito y en reposo. Los datos permanecen en la misma región donde se procesa la llamada API. También puedes usar Enlace privado de AWS para crear una conexión privada entre la cuenta de AWS donde residen sus datos y la VPC.
Preparación de datos
Antes de poder crear un trabajo de personalización de modelo, debe prepare su conjunto de datos de entrenamiento. El formato de su conjunto de datos de entrenamiento depende del tipo de trabajo de personalización que esté creando (ajuste fino o entrenamiento previo continuo) y la modalidad de sus datos (texto a texto, texto a imagen o imagen a imagen). incrustación). Para el modelo Amazon Titan Image Generator, debe proporcionar las imágenes que desea utilizar para el ajuste y un título para cada imagen. Amazon Bedrock espera que sus imágenes se almacenen en Amazon S3 y que los pares de imágenes y títulos se proporcionen en formato JSONL con múltiples líneas JSON.
Cada línea JSON es una muestra que contiene una referencia de imagen, el URI de S3 para una imagen y un título que incluye un mensaje de texto para la imagen. Tus imágenes deben estar en formato JPEG o PNG. El siguiente código muestra un ejemplo del formato:
{"image-ref": "s3://bucket/path/to/image001.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image002.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image003.png", "caption": ""}
Debido a que "Ron" y "Smila" son nombres que también podrían usarse en otros contextos, como el nombre de una persona, agregamos los identificadores "Ron el perro" y "Smila la gata" al crear el mensaje para ajustar nuestro modelo. . Aunque no es un requisito para el flujo de trabajo de ajuste, esta información adicional proporciona más claridad contextual para el modelo cuando se personaliza para las nuevas clases y evitará la confusión de "Ron el perro" con una persona llamada Ron y " El gato Smila” con la ciudad de Smila en Ucrania. Usando esta lógica, las siguientes imágenes muestran una muestra de nuestro conjunto de datos de entrenamiento.
 |
 |
 |
| Ron el perro acostado en una cama para perros blanca | Ron el perro sentado en un suelo de baldosas | Ron el perro acostado en un asiento de coche |
 |
 |
 |
| Smila la gata tumbada en un sofá | La gata Smila mirando a la cámara tumbada en un sofá | La gata Smila recostada en una jaula para mascotas |
Al transformar nuestros datos al formato esperado por el trabajo de personalización, obtenemos la siguiente estructura de muestra:
{"imagen-ref": "/ron_01.jpg", "caption": "Ron el perro acostado en una cama blanca para perros"} {"image-ref": "/ron_02.jpg", "caption": "Ron el perro sentado en un suelo de baldosas"} {"image-ref": "/ron_03.jpg", "caption": "Ron el perro acostado en un asiento de seguridad"} {"image-ref": "/smila_01.jpg", "caption": "Smila la gata tumbada en un sofá"} {"image-ref": "/smila_02.jpg", "caption": "Smila la gata sentada junto a la ventana junto a una estatua de gato"} {"image-ref": "/smila_03.jpg", "caption": "La gata Smila recostada en un transportín"}
Una vez que hayamos creado nuestro archivo JSONL, debemos almacenarlo en un depósito S3 para comenzar nuestro trabajo de personalización. Los trabajos de ajuste fino de Amazon Titan Image Generator G1 funcionarán con entre 5 y 10,000 60 imágenes. Para el ejemplo comentado en esta publicación, utilizamos 30 imágenes: 30 del perro Ron y XNUMX de la gata Smila. En general, proporcionar más variedades del estilo o clase que está intentando aprender mejorará la precisión de su modelo ajustado. Sin embargo, cuantas más imágenes utilice para realizar ajustes, más tiempo se necesitará para completar el trabajo de ajuste. La cantidad de imágenes utilizadas también influye en el precio de su trabajo afinado. Referirse a Precios de Amazon Bedrock para obtener más información.
Ajuste del generador de imágenes Amazon Titan
Ahora que tenemos nuestros datos de entrenamiento listos, podemos comenzar un nuevo trabajo de personalización. Este proceso se puede realizar tanto a través de la consola de Amazon Bedrock como de las API. Para utilizar la consola de Amazon Bedrock, complete los siguientes pasos:
- En la consola de Amazon Bedrock, elija Modelos personalizados en el panel de navegación.
- En Personalizar modelo menú, seleccione Crear trabajo de ajuste.
- Nombre del modelo ajustado, ingresa un nombre para tu nuevo modelo.
- Configuración del trabajo, ingrese un nombre para el trabajo de capacitación.
- Datos de entrada, ingrese la ruta S3 de los datos de entrada.
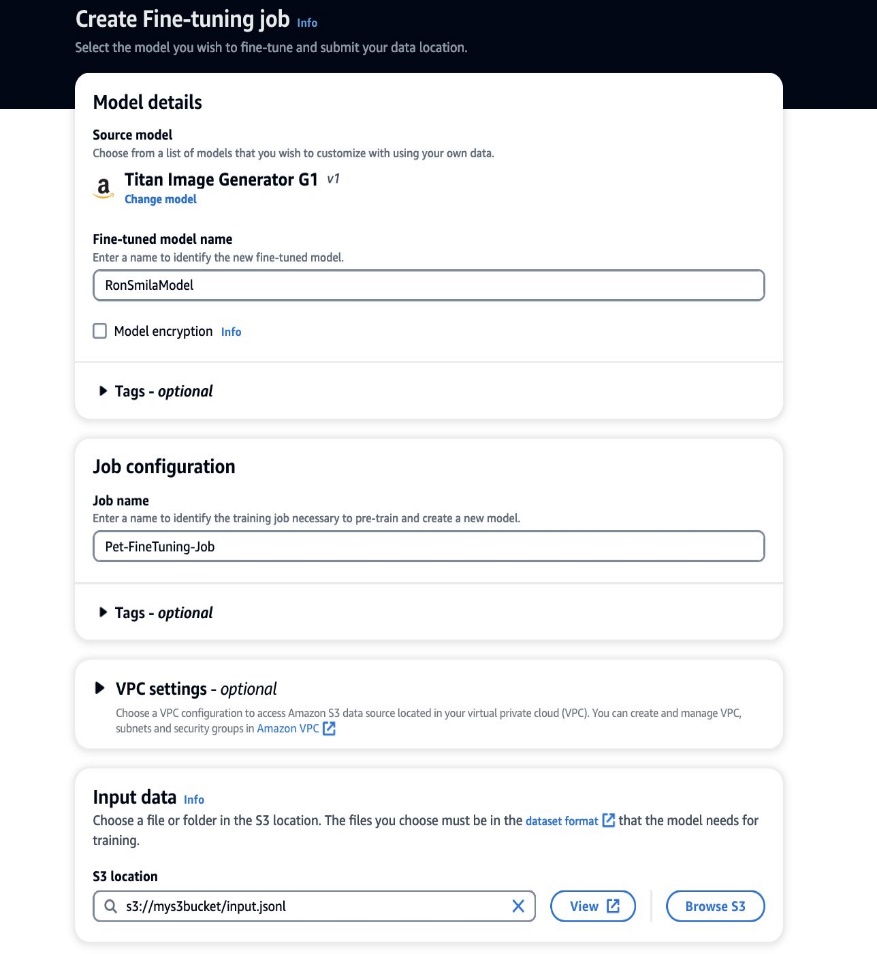
- En Hiperparámetros sección, proporcione valores para lo siguiente:
- Numero de pasos – El número de veces que el modelo se expone a cada lote.
- Tamaño del lote – El número de muestras procesadas antes de actualizar los parámetros del modelo.
- Tasa de aprendizaje – La velocidad a la que se actualizan los parámetros del modelo después de cada lote. La elección de estos parámetros depende de un conjunto de datos determinado. Como pauta general, le recomendamos comenzar fijando el tamaño del lote en 8, la tasa de aprendizaje en 1e-5 y establecer el número de pasos de acuerdo con el número de imágenes utilizadas, como se detalla en la siguiente tabla.
| Número de imágenes proporcionadas | 8 | 32 | 64 | 1,000 | 10,000 |
| Número de pasos recomendados | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
Si los resultados de su trabajo de ajuste no son satisfactorios, considere aumentar el número de pasos si no observa ningún signo del estilo en las imágenes generadas y disminuir el número de pasos si observa el estilo en las imágenes generadas pero con artefactos o borrosidad. Si el modelo ajustado no logra aprender el estilo único en su conjunto de datos incluso después de 40,000 XNUMX pasos, considere aumentar el tamaño del lote o la tasa de aprendizaje.
- En Datos resultantes , ingrese la ruta de salida de S3 donde se almacenan las salidas de validación, incluidas las métricas de precisión y pérdida de validación registradas periódicamente.
- En Acceso al servicio sección, generar una nueva Gestión de identidades y accesos de AWS (IAM) o elija una función de IAM existente con los permisos necesarios para acceder a sus depósitos de S3.
Esta autorización permite a Amazon Bedrock recuperar conjuntos de datos de entrada y validación de su depósito designado y almacenar resultados de validación sin problemas en su depósito S3.
- Elige Modelo de ajuste fino.
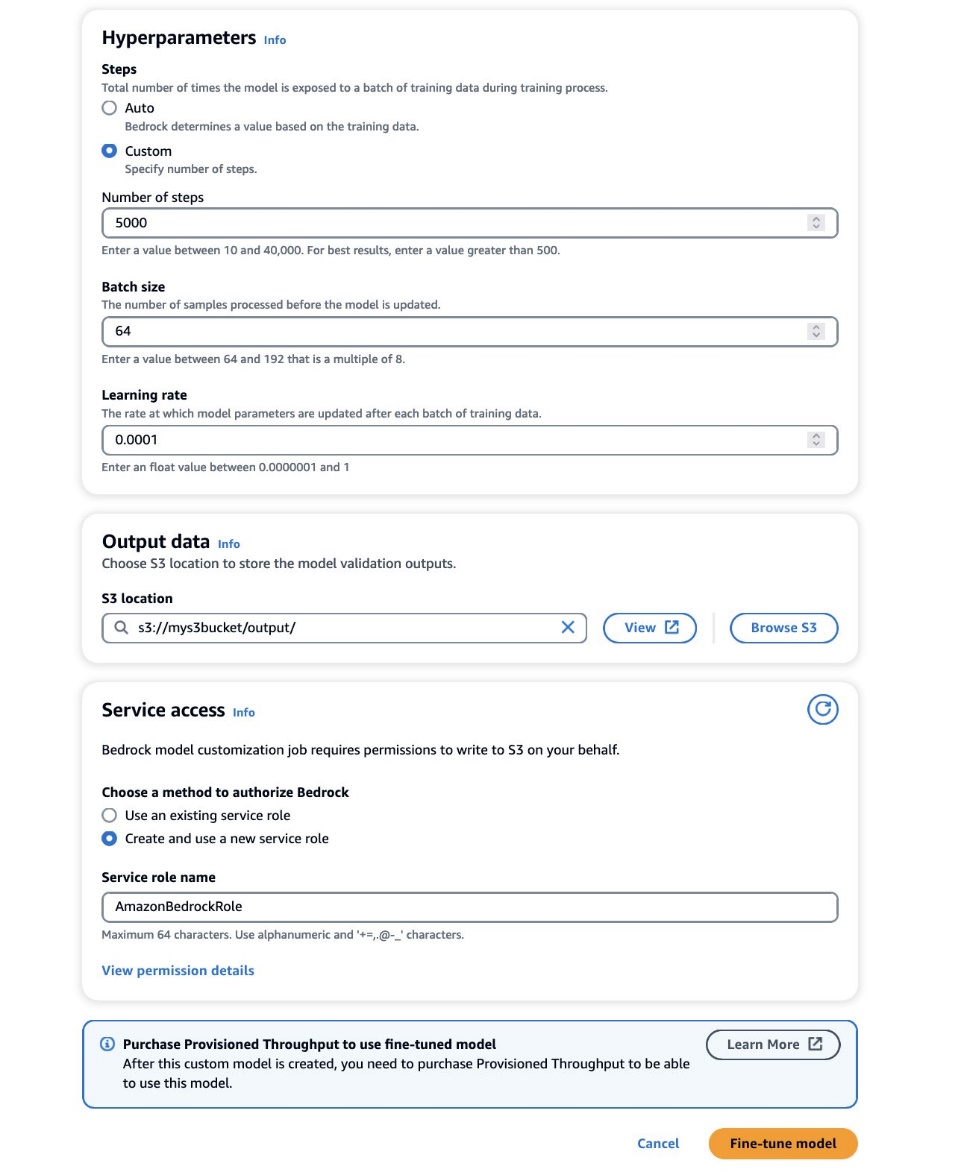
Con las configuraciones correctas establecidas, Amazon Bedrock ahora entrenará su modelo personalizado.
Implemente el generador de imágenes Amazon Titan optimizado con rendimiento aprovisionado
Después de crear un modelo personalizado, el rendimiento aprovisionado le permite asignar una tasa fija y predeterminada de capacidad de procesamiento al modelo personalizado. Esta asignación proporciona un nivel constante de rendimiento y capacidad para manejar cargas de trabajo, lo que resulta en un mejor rendimiento en las cargas de trabajo de producción. La segunda ventaja del rendimiento aprovisionado es el control de costos, porque la fijación de precios estándar basada en tokens con modo de inferencia bajo demanda puede ser difícil de predecir a gran escala.
Cuando se complete el ajuste fino de su modelo, este modelo aparecerá en la Modelos personalizados página en la consola de Amazon Bedrock.
Para comprar rendimiento aprovisionado, seleccione el modelo personalizado que acaba de ajustar y elija Rendimiento aprovisionado de compras.
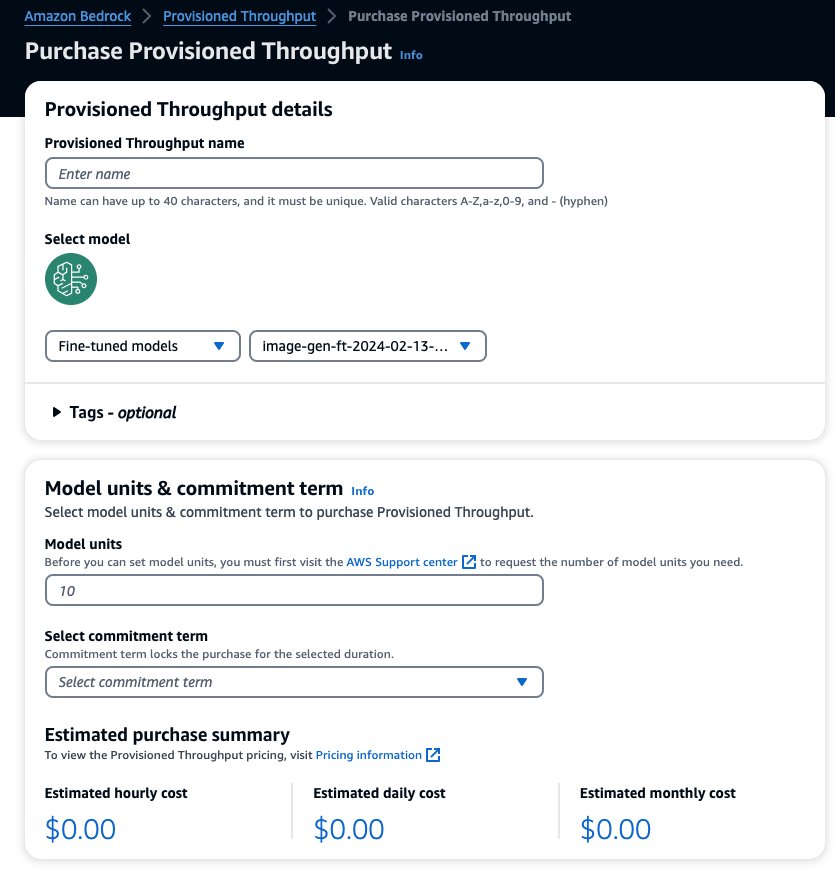
Esto rellena previamente el modelo seleccionado para el que desea comprar rendimiento aprovisionado. Para probar su modelo ajustado antes de la implementación, establezca las unidades del modelo en un valor de 1 y establezca el plazo de compromiso en Sin compromiso. Esto le permite comenzar rápidamente a probar sus modelos con sus indicaciones personalizadas y verificar si la capacitación es adecuada. Además, cuando haya nuevos modelos optimizados y nuevas versiones disponibles, podrá actualizar el rendimiento aprovisionado siempre que lo actualice con otras versiones del mismo modelo.
Resultados de ajuste fino
Para nuestra tarea de personalizar el modelo del perro Ron y la gata Smila, los experimentos demostraron que los mejores hiperparámetros eran 5,000 pasos con un tamaño de lote de 8 y una tasa de aprendizaje de 1e-5.
Los siguientes son algunos ejemplos de las imágenes generadas por el modelo personalizado.
 |
 |
 |
| Ron el perro con capa de superhéroe | Ron el perro en la luna | Ron el perro en una piscina con gafas de sol |
 |
 |
 |
| Smila el gato en la nieve. | Smila la gata en blanco y negro mirando a la cámara | Smila la gata con gorro navideño |
Conclusión
En esta publicación, analizamos cuándo utilizar el ajuste fino en lugar de diseñar sus indicaciones para generar imágenes de mejor calidad. Mostramos cómo ajustar el modelo de Amazon Titan Image Generator e implementar el modelo personalizado en Amazon Bedrock. También proporcionamos pautas generales sobre cómo preparar sus datos para realizar ajustes y establecer hiperparámetros óptimos para una personalización del modelo más precisa.
Como siguiente paso, puede adaptar lo siguiente ejemplo a su caso de uso para generar imágenes hiperpersonalizadas utilizando Amazon Titan Image Generator.
Acerca de los autores
 Maira Ladeira Tanke es científico senior de datos de IA generativa en AWS. Con experiencia en aprendizaje automático, tiene más de 10 años de experiencia diseñando y creando aplicaciones de IA con clientes de todos los sectores. Como líder técnica, ayuda a los clientes a acelerar la consecución de valor empresarial a través de soluciones de IA generativa en Amazon Bedrock. En su tiempo libre, Maira disfruta viajar, jugar con su gata Smila y pasar tiempo con su familia en un lugar cálido.
Maira Ladeira Tanke es científico senior de datos de IA generativa en AWS. Con experiencia en aprendizaje automático, tiene más de 10 años de experiencia diseñando y creando aplicaciones de IA con clientes de todos los sectores. Como líder técnica, ayuda a los clientes a acelerar la consecución de valor empresarial a través de soluciones de IA generativa en Amazon Bedrock. En su tiempo libre, Maira disfruta viajar, jugar con su gata Smila y pasar tiempo con su familia en un lugar cálido.
 dani mitchell es un arquitecto de soluciones especializado en IA/ML en Amazon Web Services. Se centra en casos de uso de visión por computadora y en ayudar a los clientes de EMEA a acelerar su recorrido por el aprendizaje automático.
dani mitchell es un arquitecto de soluciones especializado en IA/ML en Amazon Web Services. Se centra en casos de uso de visión por computadora y en ayudar a los clientes de EMEA a acelerar su recorrido por el aprendizaje automático.
 Bharati Srinivasan es científica de datos en AWS Professional Services, donde le encanta crear cosas interesantes en Amazon Bedrock. Le apasiona impulsar el valor empresarial a partir de aplicaciones de aprendizaje automático, centrándose en la IA responsable. Además de crear nuevas experiencias de IA para los clientes, a Bharathi le encanta escribir ciencia ficción y desafiarse a sí misma con deportes de resistencia.
Bharati Srinivasan es científica de datos en AWS Professional Services, donde le encanta crear cosas interesantes en Amazon Bedrock. Le apasiona impulsar el valor empresarial a partir de aplicaciones de aprendizaje automático, centrándose en la IA responsable. Además de crear nuevas experiencias de IA para los clientes, a Bharathi le encanta escribir ciencia ficción y desafiarse a sí misma con deportes de resistencia.
 Achin jainista es un científico aplicado del equipo de Inteligencia general artificial (AGI) de Amazon. Tiene experiencia en modelos de texto a imagen y se centra en la creación de Amazon Titan Image Generator.
Achin jainista es un científico aplicado del equipo de Inteligencia general artificial (AGI) de Amazon. Tiene experiencia en modelos de texto a imagen y se centra en la creación de Amazon Titan Image Generator.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

