Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Índice del contenido
1. Introducción
2. Tipos de algoritmos de aprendizaje automático
3. Regresión lineal simple
4. Regresión multilineal
5. Regresión logística
6. Árbol de decisiones
7. MVS
8. KNN
9. K significa agrupamiento
Introducción
Todos sabemos cómo está liderando la Inteligencia Artificial en la actualidad. El aprendizaje automático es parte de ello. La inteligencia artificial se logra tanto mediante el aprendizaje automático como mediante el aprendizaje profundo. Hay tres pasos en el flujo de trabajo de un proyecto de IA. Son la recopilación de datos, el entrenamiento de modelos y su implementación. Utilizamos el aprendizaje automático para los modelos.
Tipos de algoritmos de aprendizaje automático
Son,
1. Aprendizaje supervisado
2. Aprendizaje no supervisado
3. Aprendizaje por refuerzo
1. Aprendizaje supervisado: Los datos que se utilizan en el aprendizaje supervisado se denominan datos. Etiquetar es algo conocido como categorizar. El uso de este modelo de aprendizaje automático de datos etiquetados se entrena y luego con ese modelo, predeciremos el resultado de
conjuntos de datos no entrenados.
2. Aprendizaje no supervisado: Los datos que se utilizan en el aprendizaje no supervisado son datos no etiquetados. Los datos sin etiquetar se entregan al modelo de aprendizaje automático y se entrenan. Aquí el modelo formará grupos de acuerdo con características y características similares y luego se formarán grupos. Ahora, cuando se envían datos no entrenados, el modelo los reconocerá y los predirá a los grupos correspondientes.
3. Aprendizaje por refuerzo: Aquí, en el modelo de aprendizaje automático por refuerzo, no se proporciona ninguno de los datos, ya sea que esté etiquetado o no. En cambio, aquí Machine intenta con diferentes acciones y cada vez que la máquina ha hecho lo correcto
modelo entonces se da la señal de recompensa. Y de esta manera el modelo se entrena y predice el resultado en el futuro con experiencias pasadas.
El aprendizaje supervisado se clasifica en algoritmos de regresión y clasificación.
Los algoritmos de regresión se utilizan siempre que se necesita predicción para variables objetivo continuas. Como predecir el salario, predecir la edad, predecir el mercado de valores, etc. Por ejemplo, regresión lineal, regresión multilineal, regresión polinomial.
Mientras que los algoritmos de clasificación se utilizan para la predicción de variables discretas, como para predecir Verdadero o Falso, predecir Sí o No, predecir 0 o 1, predecir pasa o falla, etc. por ejemplo, regresión logística, árbol de decisión, SVM, KNN.
El aprendizaje no supervisado se basa completamente en la agrupación. El modelo analizará un patrón similar entre las variables de entrada y el clúster de formas. Por ejemplo, K significa agrupación, agrupación jerárquica.
Algunos algoritmos básicos comunes de aprendizaje automático que se utilizan:
1. Regresión lineal simple
2. Regresión multilineal
3. Regresión logística
4. Árbol de decisiones
5. MVS
6. KNN
7. K significa agrupamiento
Regresión lineal simple
La regresión lineal es un modelo de aprendizaje supervisado que se utiliza para analizar datos continuos. Es una gráfica de datos que grafica la relación lineal entre variables independientes y dependientes.
Las características se denominan variables independientes y el resultado o la etiqueta se conocen como variables dependientes que dependen de las características. La ecuación para la regresión lineal es
y=a+bx+e
dónde,
y = variable dependiente (resultado)
x = variable independiente (característica)
a = intersección
b=pendiente
e=error de modelo
El modelo de entrenamiento significa encontrar la pendiente y la intersección. Con ese modelo de pendiente e intersecciones, predecirá y con un cambio en x.
la regresión lineal se importa de sklearn.
Echemos un vistazo al código.
de sklearn.linear_model importar LinearRegression

Podemos ver en la imagen que el primer paso es crear un modelo. Aquí se crea el modelo de regresión lineal y luego se entrena el modelo utilizando el método de ajuste. La predicción se realiza utilizando el método de predicción. podemos encontrar la pendiente y el intercepto usando los métodos coef_ e intercept_ respectivamente.
Regresión multilineal
La regresión multilineal es casi similar a la regresión lineal simple, excepto que aquí el modelo toma múltiples variables de características para predecir la variable de destino. Toda la sintaxis y el código son los mismos que los de la regresión lineal simple. En términos simples, el modelo predecirá una variable dependiente con dos o más de dos variables independientes.
La ecuación para una regresión multilineal es,
y=b0+b1x1+...+bnxn+ Y
Dónde,
y=variable dependiente
b0= intercepto en y
b1x1=Coeficiente de regresión(b1) de la variable independiente x1
bnxn=Coeficiente de regresión(bn) de la variable independiente xn
e=Error de modelo
Regresión logística
El modelo de regresión logística es un modelo de aprendizaje supervisado que es una generalización de un modelo de regresión lineal, que se utiliza principalmente para datos categóricos. Por el nombre de regresión, muchos solían pensar en él como un algoritmo de regresión, pero es un algoritmo de clasificación.
Entendámoslo en detalle. Piense en un ejemplo sobre cómo calificar, ya sea que pueda aprobar o reprobar. Y se le proporcionarán calificaciones para cada tema. Y con esas marcas el modelo encuentra un patrón para decidir si pasa o falla. En nuestros términos, digamos que el porcentaje de aprobación es del 35%. Entonces todos los candidatos que obtengan más del 35% aprobarán y los restantes suspenderán. De manera similar, el modelo predice aprobación o falla.
La regresión logística se importa de sklearn.
de sklearn.linear_model import LogisticRegression
Echemos un vistazo al código.

Podemos ver en la imagen que el primer paso es crear un modelo. Aquí se crea el modelo LogisticRegreesion y luego el modelo se entrena utilizando el método de ajuste. La predicción se realiza utilizando el método de predicción. Finalmente se visualizan los resultados previstos.
Árbol de decisión
Un árbol de decisión es una técnica de aprendizaje automático supervisado. Se utiliza un algoritmo de árbol de decisión para problemas de tipo regresión y clasificación.

Nodo de decisión: Cuando el subnodo se divide en subnodos, se denomina nodo de decisión.
Nodo hoja/terminal: Nodo sin hijos.
Poda: El proceso de reducir el tamaño del árbol de decisión mediante la eliminación de nodos.
Entropía: La entropía es la medida de la aleatoriedad de los elementos. Es la medida de la incertidumbre en el conjunto dado.
Si la entropía = 0, entonces la muestra es completamente homogénea.
Ganancia de información: La ganancia de información mide la cantidad de "Información" que nos brinda una variable de característica sobre la clase. Los algoritmos de árboles de decisión siempre intentan maximizar la ganancia de información.
Un atributo con la ganancia de información más alta se dividirá primero.
Ganancia de información = Entropía (padre) – (peso promedio) * Entropía (hijos)
Para el árbol de decisión de todas las funciones, ¿cuál será el nodo raíz, cuál será el próximo nodo de decisión?
Esto será decidido por la entropía. Los atributos con la mayor ganancia de información se dividirán primero.
Echemos un vistazo al código.

Podemos ver en la imagen que el primer paso es crear un modelo. Aquí se crea el modelo DecisionTreeClassifier y luego se entrena el modelo utilizando el método de ajuste. La predicción se realiza utilizando el método de predicción. Y finalmente se ven los resultados previstos.
Máquina de vectores de soporte (SVM)
Support Vector Machine es un algoritmo de aprendizaje automático supervisado. El algoritmo Support Vector Machine se puede utilizar tanto para problemas de regresión como de clasificación. Pero principalmente SVM se usa para problemas de clasificación. Aquí en SVM, trazamos todos los puntos de datos en un espacio tridimensional. Y luego tenemos que encontrar un hiperplano entre categorías para diferenciar bien todas las categorías.

Comprendamos en detalle el algoritmo de la máquina de vectores de soporte.
La tarea principal del algoritmo SVM es encontrar el hiperplano derecho entre grupos. Para los grupos dados, habrá muchos posibles hiperplanos entre ellos. Pero, ¿cuál tiene razón entre todos? Encontrémoslo.
Suponga que toma 2 grupos como estrellas y círculos.
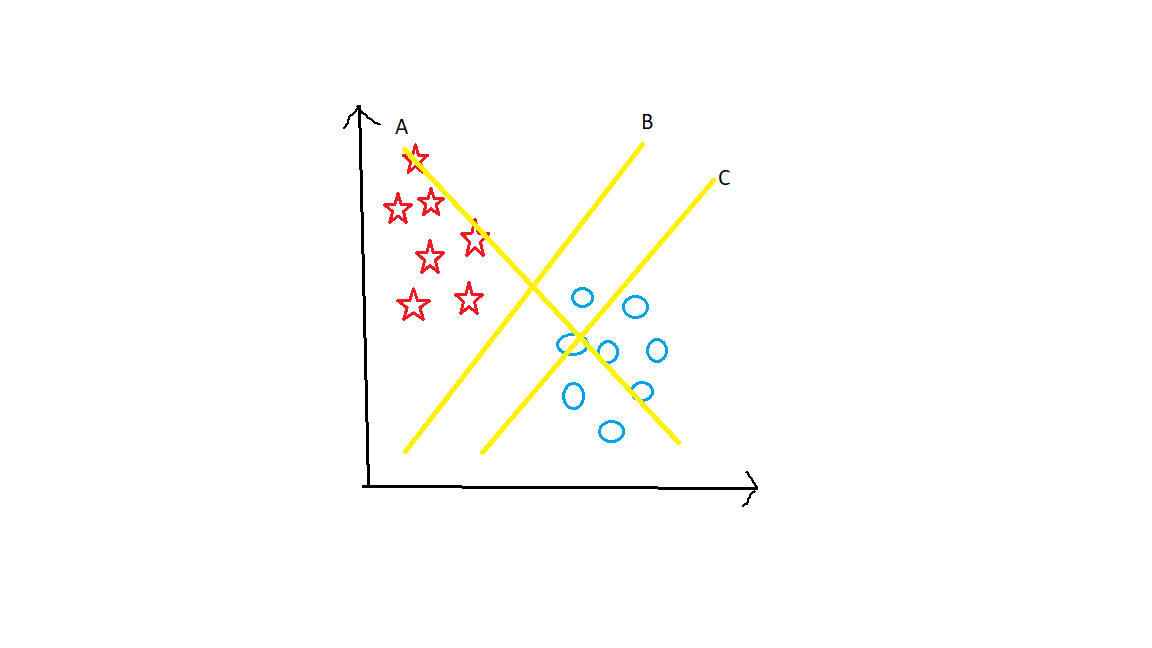
Aquí hay 3 hiperplanos, a saber, A, B y C. ¿Qué piensas? Cuál es el hiperplano derecho. Ahora tienes que mantener un punto principal en tu mente. Hyperplane debería segregar muy bien los grupos. Aquí claramente el hiperplano B los separa de la mejor manera.
Tomemos otro ejemplo.

Ahora echa un vistazo a este gráfico. Cual crees que es el mejor hiperplano?? Aquí los 3 hiperplanos los segregan bien. En este caso, tenemos que ver un margen. El margen es la distancia entre el hiperplano y el punto de datos más cercano. B tiene el margen máximo en comparación con A y C. El hiperplano con el margen más alto es el mejor hiperplano. Porque las posibilidades de obtener una clasificación incorrecta serán menores si el margen es mayor.
Tengamos otro ejemplo.
Ahora, por cual hiperplano te decidirás??? El Hiperplano A tiene el margen más alto y el Hiperplano B los segrega bien. Así que aquí la Clasificación es nuestro lema principal. El hiperplano A tiene un error de clasificación. mientras que B clasifica bien. Entonces el Hiperplano B es correcto.
De esta manera, se decide Hyperplane.
Echemos un vistazo al código.


Podemos ver en la imagen que el primer paso es crear un modelo. Aquí el modelo SVC se crea usando la biblioteca SVM y luego el modelo se entrena usando el método de ajuste. La predicción se realiza utilizando el método de predicción. Podemos encontrar la precisión del modelo utilizando el método precision_score. Aquí obtuvimos un 1% de precisión.
K Vecinos más cercanos (KNN)
K Nearest Neighbors (KNN) es un algoritmo de aprendizaje automático supervisado que se puede usar para problemas de tipo regresión y clasificación. El algoritmo KNN se usa para predecir datos basados en medidas de similitud de datos anteriores. Uno de los casos de uso industrial del algoritmo KNN son las recomendaciones en sitios web como Amazon.
k= número de vecinos más cercanos.
Aquí tenemos que aprender sobre algo llamado Distancia Euclidiana. Es la distancia entre dos puntos de datos que son puntos de consulta y de datos entrenados. Aquí el punto de datos de consulta es una variable dependiente que tenemos que encontrar. La fórmula para la distancia euclidiana es,
re = √[(x2 - X1)2 + (y2 - y1)2]
Aquí,
(x1,y1) = punto de datos de consulta
(x2,y2) = Punto de datos entrenado

Tomemos un ejemplo y entendámoslo en profundidad. Aquí están los datos que muestran las notas de Matemáticas y Química de los estudiantes y también se da una etiqueta para estos datos que es aprobado o reprobado. Ahora tenemos que averiguar si un estudiante con 5 en Matemáticas y 6 en Química reprobará o aprobará.
| Matemáticas | Química | etiqueta (aprobado/reprobado) |
| 5 | 5 | fallar |
| 7 | 8 | pass |
| 4 | 5 | fallar |
| 3 | 5 | fallar |
| 9 | 7 | pass |
Bueno, aquí el punto de consulta.(x1,y1) es (5,6). Calcular las distancias euclidianas a todos los puntos.
d1 =√(5-5)2+ (5-6)2 = 1
d2 =√(7-5)2+ (8-6)2 = 2.828
d3 =√(4-5)2+ (5-6)2 = 1.414
d4 =√(3-5)2+ (5-6)2 = 2.236
d5 =√(9-5)2+ (7-6)2 =4.123
| Matemáticas | Química | etiqueta (aprobado/reprobado) | distancia euclidiana | Clasificación |
| 5 | 5 | fallar | 1 | 1 |
| 6 | 8 | pass | 2.828 | 4 |
| 4 | 5 | fallar | 1.414 | 2 |
| 3 9 |
5 7 |
fallar pass |
2.236 4.123 |
3 5 |
Para n=5, k es 3, por lo que tenemos que encontrar los 3 vecinos más cercanos que estén en el rango 1,2, 3 y 3. Los resultados de estos 3 vecinos son 3 fallas. Hay 0 suspensos y 5 aprobados. Entonces, si la mayoría falla, el estudiante con calificaciones de 6 en matemáticas y XNUMX de química fallará.
Así es como funciona el algoritmo KNN.
Echemos un vistazo al código.

Podemos ver en la imagen que el primer paso es crear un modelo. Aquí se crea el modelo KNeighborsClassifier y luego se entrena el modelo usando el método de ajuste. La predicción se realiza utilizando el método de predicción. Podemos encontrar la precisión del modelo utilizando el método precision_score. Aquí obtuvimos un 1% de precisión.
K significa agrupamiento
El agrupamiento de K Means es un algoritmo de aprendizaje automático no supervisado. Aquí no habrá datos etiquetados. Los datos se clasificarán en grupos. Este algoritmo es un algoritmo basado en el centroide. Cada grupo tiene un centroide. El lema de este algoritmo es minimizar la distancia entre el centroide y los puntos de datos.
En el algoritmo K Means, encontramos los mejores centroides asignando alternativamente centroides aleatorios a un conjunto de datos. Y de los grupos resultantes se seleccionan puntos de datos medios para formar nuevos centroides. Este proceso continúa iterativamente hasta que se optimiza el modelo.
Para los conjuntos de datos de aprendizaje no supervisados, no hay etiquetas, solo están presentes las características. con la ausencia de etiquetas, tenemos que identificar qué puntos de datos en el conjunto de datos son similares. Un clúster está formado por un grupo de puntos de datos similares.
Aquí, para todos los puntos de datos aleatorios, se forman dos grupos y se asignaron centroides aleatorios. Para la primera iteración, los clústeres eran así con centroides.

Después de la segunda iteración, los centroides se reasignaron y los grupos serán así.

Después de la tercera iteración, nuevamente se reasignaron los centroides y, finalmente, el modelo se optimizó. Incluso si iteramos nuevamente, los puntos del centroide no cambiaron. Y los grupos finales serán así.

De esta forma, funciona el algoritmo de agrupamiento de K Means.
Echemos un vistazo a

Podemos ver en la imagen que el primer paso es crear un modelo. Aquí se crea el modelo KMeans y luego se entrena el modelo utilizando el método de ajuste. La predicción se realiza utilizando el método de predicción. Y luego, al llegar a la visualización, podemos ver que todos los puntos de datos se dividen en 1 grupos con centroides.
Conclusión
Como dije, este artículo es para principiantes y también para aquellos que necesitan una revisión. En este artículo se explican en detalle algunos algoritmos básicos de aprendizaje automático. algunos conocimientos a través de mi artículo sobre algoritmos de aprendizaje automático.
Leer más blogs sobre algoritmos de aprendizaje automático en nuestro sitio web.
Conéctese conmigo en Linkedin: https://www.linkedin.com/in/amrutha-k-6335231a6vl/
Relacionado:
Fuente: https://www.analyticsvidhya.com/blog/2022/01/machine-learning-algorithms/

