La National Football League (NFL) es una de las ligas deportivas más populares de los Estados Unidos y es la liga deportiva mas valiosa del mundo. La NFL, BioCore y AWS están comprometidas con el avance de la comprensión humana en torno al diagnóstico, la prevención y el tratamiento de las lesiones relacionadas con los deportes para hacer que el fútbol sea más seguro. Más información sobre los esfuerzos de salud y seguridad de los jugadores de la NFL está disponible en Sitio web de la NFL.
El Servicios profesionales de AWS El equipo se asoció con la NFL y Biocore para proporcionar soluciones basadas en el aprendizaje automático (ML) para identificar los impactos del casco a partir de las imágenes del juego utilizando técnicas de visión por computadora (CV). Con múltiples vistas de cámara disponibles para cada juego, hemos desarrollado soluciones para identificar los impactos del casco desde cada una de estas vistas y fusionar los resultados del impacto del casco.
La motivación detrás de la utilización de múltiples vistas de cámara proviene de la limitación de información cuando los eventos de impacto se capturan con una sola vista. Con solo una perspectiva, algunos jugadores pueden ocluirse entre sí o ser bloqueados por otros objetos en el campo. Por lo tanto, agregar más perspectivas permite que nuestro sistema ML identifique más impactos que no son visibles en una sola vista. Para mostrar los resultados de nuestro proceso de fusión y cómo el equipo usa las herramientas de visualización para ayudar a evaluar el rendimiento del modelo, hemos desarrollado una base de código para superponer visualmente los resultados de detección de múltiples vistas. Este proceso ayuda a identificar la cantidad real de impactos que experimentan los jugadores individuales al eliminar los impactos duplicados detectados en múltiples vistas.
En esta publicación, utilizamos el conjunto de datos disponible públicamente de la NFL – Competencia Kaggle de detección de impactos y mostrar los resultados de la fusión de dos vistas. El conjunto de datos incluye cuadros delimitadores de cascos en cada cuadro y etiquetas de impacto que se encuentran en cada video. En particular, nos enfocamos en deduplicar y visualizar videos con la ID 57583_000082 en vistas de zona de anotación y lateral. Puedes descargar el videos de zona de anotación y línea de banda, y también la etiquetas de verdad de tierra.
Requisitos previos
La solución requiere lo siguiente:
Comience a utilizar SageMaker Studio Lab e instale los paquetes necesarios
Puede ejecutar el cuaderno desde el GitHub repositorio o desde SageMaker Studio Lab. En esta publicación, ejecutamos el cuaderno desde un entorno de SageMaker Studio Lab. Elegimos SageMaker Studio Lab porque es gratuito, proporciona poderosas sesiones de usuario de CPU y GPU, y 15 GB de almacenamiento persistente que guardará automáticamente su entorno, lo que le permitirá continuar donde lo dejó. Para utilizar SageMaker Studio Lab, solicitar y configurar una nueva cuenta. Una vez aprobada la cuenta, complete los siguientes pasos:
- Visita el sitio web de aws-samples repositorio de GitHub.
- En
READMEsección, elija Laboratorio de estudio abierto.
Esto lo redirige a su entorno de SageMaker Studio Lab.
- Seleccione su tipo de cómputo de CPU, luego elija Iniciar tiempo de ejecución.
- Después de que comience el tiempo de ejecución, elija Copiar al proyecto, que abre una nueva ventana con el entorno de Jupyter Lab.
¡Ya está listo para usar el portátil!
- Abierto
fuse_and_visualize_multiview_impacts.ipynby sigue las instrucciones del cuaderno.
La primera celda del cuaderno instala los paquetes de Python necesarios, como pandas y OpenCV:
%pip install pandas
%pip install opencv-contrib-python-headlessImporte todos los paquetes de Python necesarios y configure las opciones de pandas para una mejor experiencia de visualización:
import os
import cv2
import pandas as pd
import numpy as np
pd.set_option('mode.chained_assignment', None)Usamos pandas para ingerir y analizar el archivo CSV con los cuadros delimitadores del casco anotados, así como los impactos. Usamos NumPy principalmente para manipular arreglos y matrices. Usamos OpenCV para leer, escribir y manipular datos de imágenes en Python.
Prepare los datos fusionando los resultados de dos vistas
Para fusionar las dos perspectivas juntas, usamos el train_labels.csv de la competencia Kaggle como ejemplo porque contiene impactos de la verdad desde el suelo tanto desde la zona de anotación como desde la línea lateral. La siguiente función toma el conjunto de datos de entrada y genera un marco de datos fusionado que se deduplica para todas las reproducciones en el conjunto de datos de entrada:
def prep_data(df): df['game_play'] = df['gameKey'].astype('str') + '_' + df['playID'].astype('str').str.zfill(6) return df def dedup_view(df, windows): # define view df = df.sort_values(by='frame') view_columns = ['frame', 'left', 'width', 'top', 'height', 'video'] common_columns = ['game_play', 'label', 'view', 'impactType'] label_cleaned = df[view_columns + common_columns] # rename columns sideline_column_rename = {col: 'Sideline_' + col for col in view_columns} endzone_column_rename = {col: 'Endzone_' + col for col in view_columns} sideline_columns = list(sideline_column_rename.values()) # create two dataframes, one for sideline, one for endzone label_endzone = label_cleaned.query('view == "Endzone"') label_endzone.rename(columns=endzone_column_rename, inplace=True) label_sideline = label_cleaned.query('view == "Sideline"') label_sideline.rename(columns=sideline_column_rename, inplace=True) # prepare sideline labels label_sideline['is_dup'] = False for columns in sideline_columns: label_endzone[columns] = np.nan label_endzone['is_dup'] = False # iterrate endzone rows to find matches and dedup for index, row in label_endzone.iterrows(): player = row['label'] frame = row['Endzone_frame'] impact_type = row['impactType'] sideline_row = label_sideline[(label_sideline['label'] == player) & ((label_sideline['Sideline_frame'] >= frame - windows // 2) & (label_sideline['Sideline_frame'] <= frame + windows // 2 + 1)) & (label_sideline['is_dup'] == False) & (label_sideline['impactType'] == impact_type)] if len(sideline_row) > 0: sideline_index = sideline_row.index[0] label_sideline['is_dup'].loc[sideline_index] = True for col in sideline_columns: label_endzone[col].loc[index] = sideline_row.iloc[0][col] label_endzone['is_dup'].loc[index] = True # calculate overlap perc not_dup_sideline = label_sideline[label_sideline['is_dup'] == False] final_output = pd.concat([not_dup_sideline, label_endzone]) return final_output def fuse_df(raw_df, windows): outputs = [] all_game_play = raw_df['game_play'].unique() for game_play in all_game_play: df = raw_df.query('game_play ==@game_play') output = dedup_view(df, windows) outputs.append(output) output_df = pd.concat(outputs) output_df['gameKey'] = output_df['game_play'].apply(lambda x: x.split('_')[0]).map(int) output_df['playID'] = output_df['game_play'].apply(lambda x: x.split('_')[1]).map(int) return output_dfPara ejecutar la función, ejecutamos el siguiente bloque de código para proporcionar la ubicación del train_labels.csv datos y luego realice la preparación de datos para agregar una columna adicional y extraer solo las filas de impacto. Después de ejecutar la función, guardamos la salida en una variable de marco de datos llamada fused_df.
# read the annotated impact data from train_labels.csv
ground_truth = pd.read_csv('train_labels.csv') # prepare game_play column using pipe(prep_data) function in pandas then filter the dataframe for just rows with impacts
ground_truth = ground_truth.pipe(prep_data).query('impact == 1') # loop over all the unique game_plays and deduplicate the impact results from sideline and endzone
fused_df = fuse_df(ground_truth, windows=30)
La siguiente captura de pantalla muestra la verdad básica.

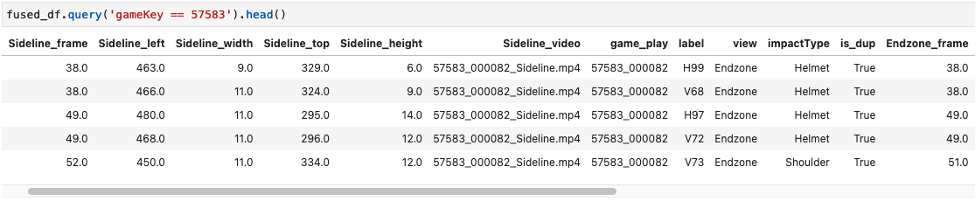
La siguiente captura de pantalla muestra los ejemplos de tramas de datos fusionadas.
Código gráfico y de video
Después de fusionar los resultados de impacto, usamos los generados fused_df para superponer los resultados en nuestros videos de la zona de anotación y de la línea de banda y fusionar las dos vistas. Usamos la siguiente función para esto, y las entradas necesarias son las rutas al video de la zona de anotación, el video lateral, fused_df marco de datos y la ruta de salida final para el video recién generado. Las funciones utilizadas en esta sección se describen en la sección de rebajas del cuaderno utilizado en SageMaker Studio Lab.
def get_video_and_metadata(vid_path): vid = cv2.VideoCapture(vid_path) total_frame_number = vid.get(cv2.CAP_PROP_FRAME_COUNT) width = int(vid.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(vid.get(cv2.CAP_PROP_FRAME_HEIGHT)) fps = vid.get(cv2.CAP_PROP_FPS) return vid, total_frame_number, width, height, fps def overlay_impacts(frame, fused_df, game_key, play_id, frame_cnt, h1): # look for duplicates duplicates = fused_df.query(f"gameKey == {int(game_key)} and playID == {int(play_id)} and is_dup == True and Sideline_frame == @frame_cnt") frame_has_impact = False if len(duplicates) > 0: for duplicate in duplicates.itertuples(index=False): if frame_cnt == duplicate.Sideline_frame: frame_has_impact = True if frame_has_impact: cv2.rectangle(frame, #frame to be edited (int(duplicate.Sideline_left), int(duplicate.Sideline_top)), #(x,y) of top left corner (int(duplicate.Sideline_left) + int(duplicate.Sideline_width), int(duplicate.Sideline_top) + int(duplicate.Sideline_height)), #(x,y) of bottom right corner (0,0,255), #RED boxes thickness=3) cv2.rectangle(frame, #frame to be edited (int(duplicate.Endzone_left), int(duplicate.Endzone_top)+ h1), #(x,y) of top left corner (int(duplicate.Endzone_left) + int(duplicate.Endzone_width), int(duplicate.Endzone_top) + int(duplicate.Endzone_height) + h1), #(x,y) of bottom right corner (0,0,255), #RED boxes thickness=3) cv2.line(frame, #frame to be edited (int(duplicate.Sideline_left), int(duplicate.Sideline_top)), #(x,y) of point 1 in a line (int(duplicate.Endzone_left), int(duplicate.Endzone_top) + h1), #(x,y) of point 2 in a line (255, 255, 255), # WHITE lines thickness=4) else: # if no duplicates, look for sideline then endzone and add to the view sl_impacts = fused_df.query(f"gameKey == {int(game_key)} and playID == {int(play_id)} and is_dup == False and view == 'Sideline' and Sideline_frame == @frame_cnt") if len(sl_impacts) > 0: for impact in sl_impacts.itertuples(index=False): if frame_cnt == impact.Sideline_frame: frame_has_impact = True if frame_has_impact: cv2.rectangle(frame, #frame to be edited (int(impact.Sideline_left), int(impact.Sideline_top)), #(x,y) of top left corner (int(impact.Sideline_left) + int(impact.Sideline_width), int(impact.Sideline_top) + int(impact.Sideline_height)), #(x,y) of bottom right corner (0, 255, 255), #YELLOW BOXES thickness=3) ez_impacts = fused_df.query(f"gameKey == {int(game_key)} and playID == {int(play_id)} and is_dup == False and view == 'Endzone' and Endzone_frame == @frame_cnt") if len(ez_impacts) > 0: for impact in ez_impacts.itertuples(index=False): if frame_cnt == impact.Endzone_frame: frame_has_impact = True if frame_has_impact: cv2.rectangle(frame, #frame to be edited (int(impact.Endzone_left), int(impact.Endzone_top)+ h1), #(x,y) of top left corner (int(impact.Endzone_left) + int(impact.Endzone_width), int(impact.Endzone_top) + int(impact.Endzone_height) + h1 ), #(x,y) of bottom right corner (0, 255, 255), #YELLOW BOXES thickness=3) return frame, frame_has_impact def generate_impact_video(ez_vid_path:str, sl_vid_path:str, fused_df:pd.DataFrame, output_path:str, freeze_impacts=True): #define video codec to be used for VIDEO_CODEC = "MP4V" # parse game_key and play_id information from the name of the files game_key = os.path.basename(ez_vid_path).split('_')[0] # parse game_key play_id = os.path.basename(ez_vid_path).split('_')[1] # parse play_id # get metadata such as total frame number, width, height and frames per second (FPS) from endzone (ez) and sideline (sl) videos ez_vid, ez_total_frame_number, ez_width, ez_height, ez_fps = get_video_and_metadata(ez_vid_path) sl_vid, sl_total_frame_number, sl_width, sl_height, sl_fps = get_video_and_metadata(sl_vid_path) # define a video writer for the output video output_video = cv2.VideoWriter(output_path, #output file name cv2.VideoWriter_fourcc(*VIDEO_CODEC), #Video codec ez_fps, #frames per second in the output video (ez_width, ez_height+sl_height)) # frame size with stacking video vertically # find shorter video and use the total frame number from the shorter video for the output video total_frame_number = int(min(ez_total_frame_number, sl_total_frame_number)) # iterate through each frame from endzone and sideline for frame_cnt in range(total_frame_number): frame_has_impact = False frame_near_impact = False # reading frames from both endzone and sideline ez_ret, ez_frame = ez_vid.read() sl_ret, sl_frame = sl_vid.read() # creating strings to be added to the output frames img_name = f"Game key: {game_key}, Play ID: {play_id}, Frame: {frame_cnt}" video_frame = f'{game_key}_{play_id}_{frame_cnt}' if ez_ret == True and sl_ret == True: h, w, c = ez_frame.shape h1,w1,c1 = sl_frame.shape if h != h1 or w != w1: # resize images if they're different ez_frame = cv2.resize(ez_frame,(w1,h1)) frame = np.concatenate((sl_frame, ez_frame), axis=0) # stack the frames vertically frame, frame_has_impact = overlay_impacts(frame, fused_df, game_key, play_id, frame_cnt, h1) cv2.putText(frame, #image frame to be modified img_name, #string to be inserted (30, 30), #(x,y) location of the string cv2.FONT_HERSHEY_SIMPLEX, #font 1, #scale (255, 255, 255), #WHITE letters thickness=2) cv2.putText(frame, #image frame to be modified str(frame_cnt), #frame count string to be inserted (w1-75, h1-20), #(x,y) location of the string in the top view cv2.FONT_HERSHEY_SIMPLEX, #font 1, #scale (255, 255, 255), # WHITE letters thickness=2) cv2.putText(frame, #image frame to be modified str(frame_cnt), #frame count string to be inserted (w1-75, h1+h-20), #(x,y) location of the string in the bottom view cv2.FONT_HERSHEY_SIMPLEX, #font 1, #scale (255, 255, 255), # WHITE letters thickness=2) output_video.write(frame) # Freeze for 60 frames on impacts if frame_has_impact and freeze_impacts: for _ in range(60): output_video.write(frame) else: break frame_cnt += 1 output_video.release() returnPara ejecutar estas funciones, podemos proporcionar una entrada como se muestra en el siguiente código, que genera un video llamado output.mp4:
generate_impact_video('57583_000082_Endzone.mp4', '57583_000082_Sideline.mp4', fused_df, 'output.mp4')Esto genera un video como se muestra en el siguiente ejemplo, donde los cuadros delimitadores rojos son impactos que se encuentran tanto en la zona de anotación como en la línea lateral, y los cuadros delimitadores amarillos son impactos que se encuentran en una sola vista en la zona de anotación o la línea lateral.
Conclusión
En esta publicación, demostramos cómo los equipos de NFL, Biocore y AWS ProServe están trabajando juntos para mejorar la detección de impacto al fusionar resultados de múltiples vistas. Esto permite a los equipos depurar y visualizar el rendimiento cualitativo del modelo. Este proceso se puede escalar fácilmente hasta tres o más vistas; en nuestros proyectos hemos utilizado hasta siete vistas diferentes. Detectar impactos de cascos viendo videos desde una sola vista puede ser difícil debido a la obstrucción de la vista, pero detectar impactos desde múltiples vistas y fusionar los resultados nos permite mejorar el rendimiento de nuestro modelo.
Para experimentar con esta solución, visite la aws-samples repositorio de GitHub y consulte el fuse_and_visualize_multiview_impacts.ipynb computadora portátil. También se pueden aplicar técnicas similares a otras industrias, como la fabricación, el comercio minorista y la seguridad, donde tener múltiples vistas beneficiaría al sistema ML para identificar mejor los objetivos con una visión más completa.
Para obtener más información sobre la salud y la seguridad de los jugadores de la NFL, visite el Sitio web de la NFL y Explicación de la NFL: Innovación en la salud y seguridad de los jugadores.
Sobre los autores
 chris boomhower es ingeniero de aprendizaje automático en AWS Professional Services. Chris tiene más de 6 años de experiencia en el desarrollo de soluciones de aprendizaje automático supervisadas y no supervisadas en diversas industrias. En la actualidad, dedica la mayor parte de su tiempo a ayudar a los clientes de las industrias del deporte, la salud y la agricultura a diseñar y crear soluciones de aprendizaje automático escalables y de extremo a extremo.
chris boomhower es ingeniero de aprendizaje automático en AWS Professional Services. Chris tiene más de 6 años de experiencia en el desarrollo de soluciones de aprendizaje automático supervisadas y no supervisadas en diversas industrias. En la actualidad, dedica la mayor parte de su tiempo a ayudar a los clientes de las industrias del deporte, la salud y la agricultura a diseñar y crear soluciones de aprendizaje automático escalables y de extremo a extremo.
 ben fenker es un científico de datos sénior en los servicios profesionales de AWS y ha ayudado a los clientes a crear e implementar soluciones de aprendizaje automático en industrias que van desde deportes hasta atención médica y fabricación. Tiene un doctorado. en física de la Universidad de Texas A&M y 6 años de experiencia en la industria. Ben disfruta del béisbol, la lectura y la crianza de sus hijos.
ben fenker es un científico de datos sénior en los servicios profesionales de AWS y ha ayudado a los clientes a crear e implementar soluciones de aprendizaje automático en industrias que van desde deportes hasta atención médica y fabricación. Tiene un doctorado. en física de la Universidad de Texas A&M y 6 años de experiencia en la industria. Ben disfruta del béisbol, la lectura y la crianza de sus hijos.
 Samuel Huddleston es un científico de datos principal en Biocore LLC, que se desempeña como líder tecnológico para el programa de atletas digitales de la NFL. Biocore es un equipo de ingenieros de clase mundial con sede en Charlottesville, Virginia, que brinda investigación, pruebas, experiencia en biomecánica, modelado y otros servicios de ingeniería a clientes dedicados a la comprensión y reducción de lesiones.
Samuel Huddleston es un científico de datos principal en Biocore LLC, que se desempeña como líder tecnológico para el programa de atletas digitales de la NFL. Biocore es un equipo de ingenieros de clase mundial con sede en Charlottesville, Virginia, que brinda investigación, pruebas, experiencia en biomecánica, modelado y otros servicios de ingeniería a clientes dedicados a la comprensión y reducción de lesiones.
 jarvis lee es un científico de datos sénior de los servicios profesionales de AWS. Ha estado en AWS durante más de cinco años, trabajando con clientes en problemas de aprendizaje automático y visión artificial. Fuera del trabajo, le gusta andar en bicicleta.
jarvis lee es un científico de datos sénior de los servicios profesionales de AWS. Ha estado en AWS durante más de cinco años, trabajando con clientes en problemas de aprendizaje automático y visión artificial. Fuera del trabajo, le gusta andar en bicicleta.
 Tyler Mullenbach es el líder de práctica global para ML con AWS Professional Services. Es responsable de impulsar la dirección estratégica de ML para servicios profesionales y garantizar que los clientes obtengan logros comerciales transformadores mediante la adopción de tecnologías ML.
Tyler Mullenbach es el líder de práctica global para ML con AWS Professional Services. Es responsable de impulsar la dirección estratégica de ML para servicios profesionales y garantizar que los clientes obtengan logros comerciales transformadores mediante la adopción de tecnologías ML.
 canción de kevin es científico de datos en AWS Professional Services. Tiene un doctorado en biofísica y más de 5 años de experiencia en la industria en la creación de soluciones de aprendizaje automático y visión artificial.
canción de kevin es científico de datos en AWS Professional Services. Tiene un doctorado en biofísica y más de 5 años de experiencia en la industria en la creación de soluciones de aprendizaje automático y visión artificial.
 betty zhang es un científico de datos con 10 años de experiencia en datos y tecnología. Su pasión es crear soluciones innovadoras de aprendizaje automático para impulsar cambios transformadores para las empresas. En su tiempo libre, le gusta viajar, leer y aprender sobre nuevas tecnologías.
betty zhang es un científico de datos con 10 años de experiencia en datos y tecnología. Su pasión es crear soluciones innovadoras de aprendizaje automático para impulsar cambios transformadores para las empresas. En su tiempo libre, le gusta viajar, leer y aprender sobre nuevas tecnologías.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/analyze-and-visualize-multi-camera-events-using-amazon-sagemaker-studio-lab/

