Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Deep Learning es un subconjunto de Machine Learning. El aprendizaje profundo se establece en redes neuronales artificiales para imitar el cerebro humano. En el aprendizaje profundo, agregamos varias capas ocultas para recopilar los detalles más minuciosos para aprender los datos para el modelado predictivo.
El Aprendizaje Profundo, curiosamente, la falta de poder de procesamiento no era del agrado de todos. Con el aumento exponencial actual en el poder de procesamiento, implementar Deep Learning es un revuelo.
Las redes de creencias profundas, las redes neuronales profundas y las redes neuronales recurrentes son algunos de los modelos de aprendizaje profundo. En este artículo, compararemos tres modelos que comprenden CNN (red neuronal de convolución), DNN (red neuronal profunda) y LSTM (memoria a corto plazo).
Dado que el conjunto de datos MNIST es la mejor manera de comenzar a trabajar y practicar en conjuntos de datos basados en imágenes, la aplicación de este algoritmo es dar un paso adelante en una imagen médica, clasificando y prediciendo signos. La implementación práctica a continuación muestra la amplia facilidad de uso para trabajar, implementar y practicar en conjuntos de datos de imágenes en toda su extensión.
Afirmación de conjunto de datos
Aquí usaremos el conjunto de datos MNIST de dígitos escritos a mano que van del 0 al 9. Este conjunto de datos se dividirá en dos partes, es decir, el conjunto de entrenamiento y el conjunto de prueba para la predicción. Usando la biblioteca sklearn, el conjunto de datos MNIST se importará al cuaderno Jupyter.

Fuente: https://en.wikipedia.org/wiki/MNIST_database
Implementación
La implementación se realiza en el Jupyter Cuaderno. Toda la implementación está disponible en mi Kaggle. El enlace se menciona a continuación:
Enlace del cuaderno: https://www.kaggle.com/code/shibumohapatra/cnn-dnn-lstm-comparison
Requisitos previos de las bibliotecas
Para empezar, primero, importaremos bibliotecas para el algoritmo. Las bibliotecas y su uso se mencionan a continuación:
- entumecido: trabajar con arreglos
- pandas: procesamiento de datos
- TensorFlow: seguimiento de modelos para predicción
- matplotlib: trazar gráficos
- Keras: API para TensorFlow
- Tensorflow.keras.modelos: para construir un modelo de aprendizaje automático. Importaremos Sequential (una pila de capas con solo un tensor de entrada y un tensor de salida).
- Sklearn.modelo: para dividir los datos en un conjunto de entrenamiento y un conjunto de prueba
- Tensorflow.keras.capas: importar diferentes capas para implementar el aprendizaje profundo. La descripción de las capas se menciona a continuación:
-
- Denso: creando redes neuronales de avance, lo que significa que cada entrada y cada salida dependen recíprocamente.
- Aplanar: serialización de tensor multidimensional.
- Abandonar: para evitar el sobreajuste.
- conv2D: una capa de convolución 2D para mantener la relación entre píxeles de datos de imagen.
- MaxPooling2D: reducir el espacio s
desde tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout, LSTM from tensorflow.keras.utils import normalize from sklearn.model_selection import train_test_split
Exploración de datos
Aquí cargaremos los datos MNIST y los dividiremos en 4 conjuntos train_x, train_y, test_x y test_y. Después de eso, normalizaremos los conjuntos train_x y test_x e imprimiremos sus respectivas formas de datos. Luego, mostraremos el conjunto de datos para garantizar que la exploración sea correcta. Implementé un bucle for para trazar 4 imágenes del conjunto de datos.
desde keras.datasets import mnist (train_x, train_y), (test_x, test_y) = mnist.load_data()

tren_x = tren_x.astype('float32') prueba_x = prueba_x.astype('float32') tren_x /= 255 prueba_x /= 255 tren_x = tren_x.reshape(tren_x.forma[0], 28, 28, 1) prueba_x = prueba_x .reforma(prueba_x.forma)
# train set print("La forma del conjunto train_x es:",train_x.shape) print("La forma del conjunto train_y es:",train_y.shape)

Entrenar establece la forma del conjunto de datos MNIST
# test set print("La forma del conjunto test_x es:",test_x.shape) print("La forma del conjunto test_y es:",test_y.shape)

La prueba estableció la forma del conjunto de datos MNIST
for i in range(1): plt.subplot(330 + 1 + i) plt.imshow(train_x[i].reshape(28,28), cmap=plt.get_cmap('gray')) plt.axis(' off') plt.mostrar()
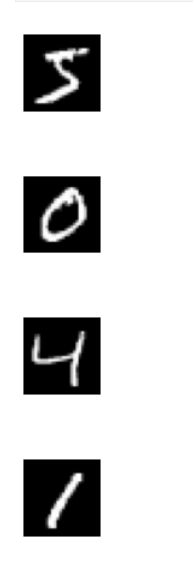
Primeros cuatro dígitos escritos a mano del conjunto de datos MNIST
Cargando datos
Una vez que implementemos más la exploración de datos, debemos cargar el conjunto de datos MNIST y dividirlo en 4 partes x_train, y_train, x_test e y_test. Luego, normalice su conjunto de entrenamiento y prueba para mantener su integridad. Y luego devuelva el tren normalizado y los conjuntos de prueba.
Cargando datos para DNN y RNN (LSTM)
Cargaremos los datos para DNN y RNN (LSTM) mediante la función def load_data_NN(), cargaremos el conjunto de datos y realizaremos la normalización.
def load_data_NN(): # cargar el conjunto de datos mnist mnist = tf.keras.datasets.mnist # 28 x 28 imágenes de 0-9 (x_train, y_train), (x_test, y_test) = mnist.load_data() # normalizar datos x_train = normalizar (tren_x, eje = 1) prueba_x = normalizar(prueba_x, eje = 1) devuelve tren_x, tren_y, prueba_x, prueba_y
carga
Para CNN, definiremos la función def load_data_CNN(), cargaremos y dividiremos el conjunto de datos y remodelaremos el tren y los conjuntos de prueba.
En CNN, la necesidad de remodelar se debe a que incluye una capa de convolución, agrupación máxima, aplanamiento y capas densas. Aquí, los conjuntos de entrenamiento y prueba se reforman en 28 x 28 x 1 (28 filas, 28 columnas, 1 canal de color).
def load_data_CNN(): # cargar el conjunto de datos mnist mnist1 = tf.keras.datasets.mnist # 28 x 28 imágenes de 0-9 (x_train, y_train), (x_test, y_test) = mnist1.load_data() # remodelar datos x_train = x_train .reshape(x_train.shape[0], 28, 28, 1) x_test = x_test.reshape(x_test.shape[0], 28, 28, 1) # convertir de enteros a flotantes x_train = x_train.astype('float32' ) x_test = x_test.astype('float32') # normalizar datos x_train = normalizar(x_train, eje = 1) x_test = normalizar(x_test, eje = 1) return x_train, y_train, x_test, y_test
Definir el modelo 1: DNN (red neuronal profunda)
DNN se basa en redes neuronales artificiales y tiene varias capas ocultas entre las capas de entrada y salida. DNN es competente en el modelado de relaciones no lineales complejas. Aquí, el objetivo principal es dar entrada, implementar el cálculo progresivo en la capa de entrada y mostrar o presentar la salida para resolver problemas. Las redes neuronales profundas (DNN) se consideran redes de avance en las que los datos fluyen desde la capa de entrada a la capa de salida sin retroceder, y los enlaces entre las capas son unidireccionales. Esto significa que este proceso avanza sin volver a tocar el nodo.
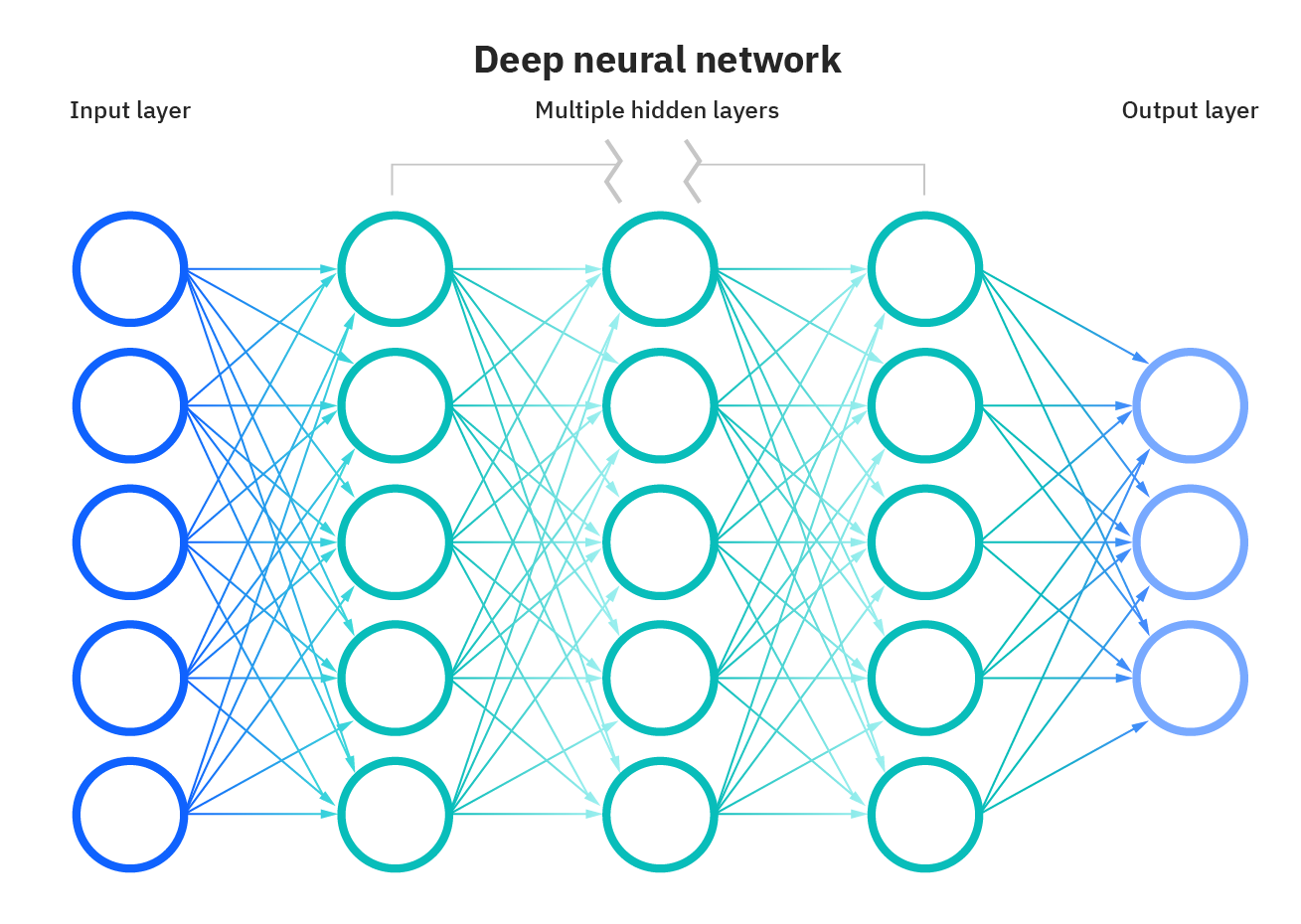
Fuente: https://www.ibm.com/cloud/learn/neural-networks
Para el DNN: se implementan capas secuenciales, aplanadas y 3 densas. Tengo 128 nodos y una función de activación de ReLU para las dos primeras capas densas. Para la tercera capa densa, he definido 10 nodos y una función de activación softmax.
def DNN(): model_dnn = Sequential() model_dnn.add(Flatten()) # capa de entrada model_dnn.add(Dense(128, activación = 'relu')) model_dnn.add(Dense(128, activación = 'relu') ) model_dnn.add(Dense(10, activación = 'softmax')) model_dnn.compile(optimizer= "adam", loss= "sparse_categorical_crossentropy", metrics=["precisión"]) return model_dnn
Al compilar el modelo DNN, he utilizado el optimizador de Adam y las funciones de pérdida de entropía cruzada categórica escasa (modelos de categorización de clases múltiples en los que a la etiqueta de salida se le asigna un valor entero). La precisión del modelo determinará las métricas.
Definir el Modelo 2 – RNN (LSTM)
RNN es una forma abreviada de red neuronal recurrente que se adapta para trabajar con datos de series temporales o datos de secuencia.
Aquí, implementaremos LSTM, que se considera RNN. Las LSTM (memoria a largo plazo a corto plazo) son un tipo especial de RNN, capaz de aprender dependencias a largo plazo, lo que hace que RNN sea brillante al recordar cosas que sucedieron en el pasado para ayudar a que la próxima estimación sea sensata.
El uso de LSTM resuelve el problema de las dependencias a largo plazo de RNN. La RNN no pudo almacenar la palabra en dependencias a largo plazo, pero con base en información reciente, la RNN pudo predecir con mayor precisión. Pero debido al aumento en la longitud de la brecha, RNN no brinda un rendimiento óptimo. La solución a esto la hace LSTM, que retiene la información durante un largo período, por lo que se reduce la pérdida de datos. Las aplicaciones de LSTM se utilizan para clasificar datos y predicciones de series temporales.
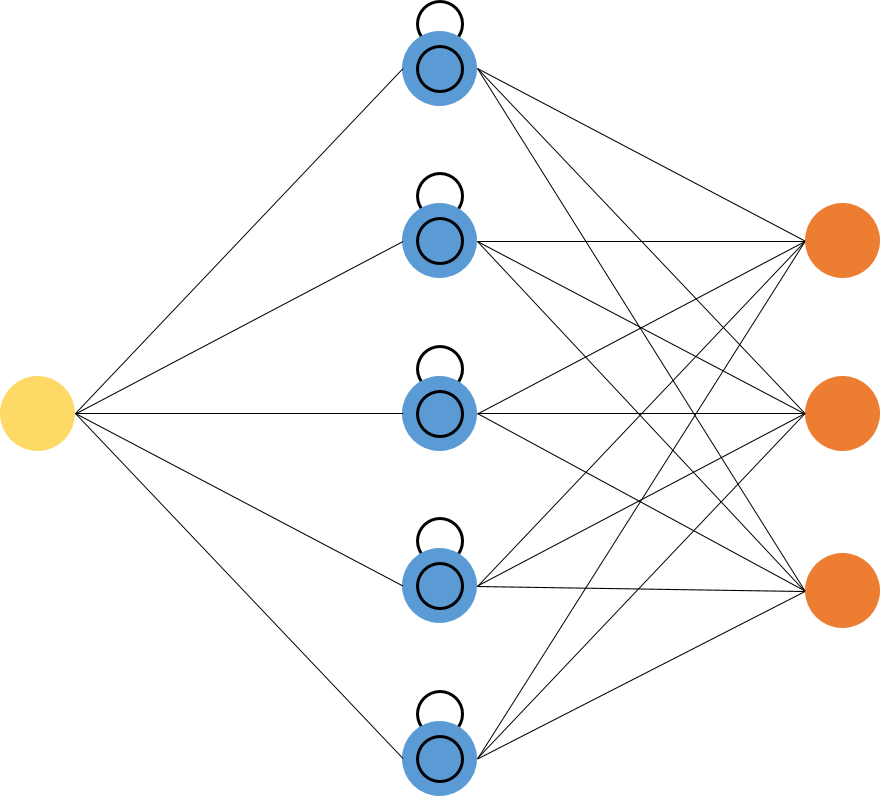
Fuente: https://i.stack.imgur.com/h8HEm.png
En cuanto a DNN (LSTM): capa LSTM, secuencial, capa de abandono (se eliminarán 0.2 es el 20 % de los nodos para evitar el sobreajuste) y capa densa. Las capas anteriores tendrán funciones de activación de ReLU y softmax. Al compilar el modelo LSTM, he utilizado el optimizador de Adam y la función de pérdida (entropía cruzada categórica dispersa). La precisión del modelo determinará las métricas.
def RNN(forma_entrada): modelo_rnn = Sequential() modelo_rnn.add(LSTM(128, forma_entrada=forma_entrada, activación = 'relu', return_sequences=True)) modelo_rnn.add(Dropout(0.2)) modelo_rnn.add(LSTM(128 , input_shape=input_shape, activación = 'relu')) model_rnn.add(Abandono(0.2)) model_rnn.add(Dense(32, activación = 'relu')) model_rnn.add(Abandono(0.2)) model_rnn.add(Dense (10, activación = 'softmax')) model_rnn.compile(optimizer= "adam", loss= "sparse_categorical_crossentropy", metrics=["precisión"]) return model_rnn
Definir el modelo 3: CNN (red neuronal de convolución)
CNN es una categoría de redes neuronales artificiales. En Deep Learning, CNN se usa ampliamente en el reconocimiento y categorización de objetos. Con el uso de CNN, Deep Learning detecta objetos en una imagen. Las redes neuronales convolucionales (CNN, o ConvNet) son una clase de redes neuronales profundas que se aplican con mayor frecuencia al análisis de imágenes visuales. Las aplicaciones de las CNN son la comprensión de video, el reconocimiento de voz y la comprensión de PNL. los CNN tiene una capa de entrada, una capa de salida, una o varias capas ocultas y toneladas de parámetros, lo que permite a CNN aprender patrones y objetos complejos.
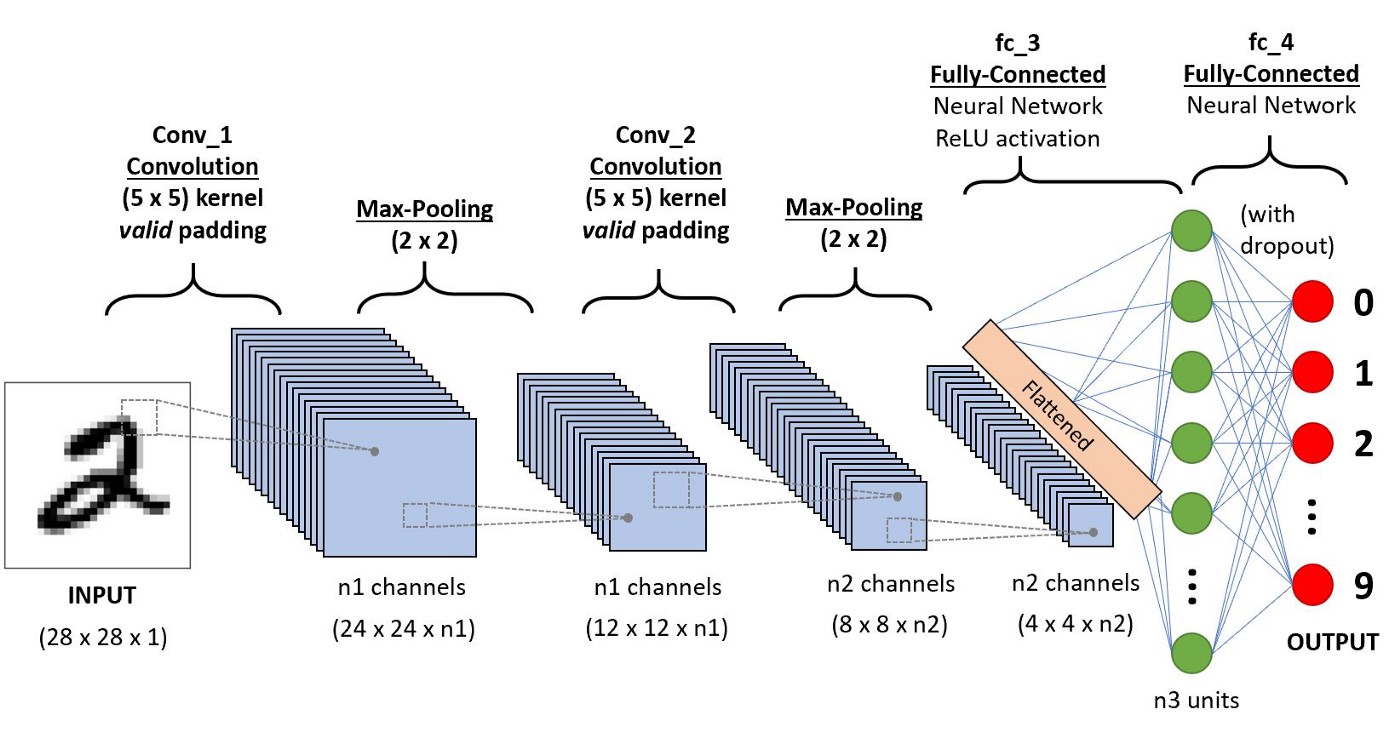
Fuente: https://miro.medium.com/max/1400/1*uAeANQIOQPqWZnnuH-VEyw.jpeg
Para CNN, seguiremos el Sequential, agregando la capa Conv2D, MaxPooling2D Layer y Dense Layer. Las funciones de activación de ReLU y softmax serán similares a los modelos anteriores. Al compilar el modelo LSTM, he utilizado el optimizador de Adam y la función de pérdida (entropía cruzada categórica escasa). La precisión del modelo determinará las métricas.
def CNN(forma_entrada): model_cnn = Sequential() model_cnn.add(Conv2D(32, (3,3), input_shape = input_shape)) model_cnn.add(MaxPooling2D(pool_size=(2,2))) model_cnn.add(Flatten ()) # convierte mapas de características 3D en vectores de características 3D model_cnn.add(Dense(100, activación='relu')) model_cnn.add(Dense(10, activación='softmax')) model_cnn.compile(loss="sparse_categorical_crossentropy ", optimizador="adam", métricas=["precisión"]) devuelve model_cnn
Fase de predicción
La siguiente implementación nos ayuda a predecir y verificar la salida prevista de un índice específico o distinto del conjunto de datos de la imagen.
Ahora, podemos entrenar y probar el conjunto de datos con nuestros modelos construidos.
def sample_prediction(índice): plt.imshow(x_test[índice].reshape(28, 28),cmap='Grises') pred = model.predict(x_test[índice].reshape(1, 28, 28, 1)) imprimir(np.argmax(pred))
Predicción del modelo DNN
Para que DNN prediga primero, cargaremos la función load_data_NN(), cargaremos y ajustaremos el modelo con 5 épocas. Después de la evaluación y prueba del modelo, se adquiere la precisión y, finalmente, definiremos una imagen de muestra para verificar que el modelo está prediciendo la imagen con la máxima precisión.
if __name__ == "__main__": # cargar datos x_train, y_train, x_test, y_test = load_data_NN() # cargar el modelo model = DNN() print("nnModel Trainingn") model.fit(x_train, y_train, epochs = 5) print("nnEvaluación del modelon") model.evaluate(x_test, y_test) score1 = model.evaluate(x_test, y_test, detallado=1) print('n''Precisión de la prueba del modelo DNN:', score1[1]) print(" nnPredicción de muestra") sample_prediction(20)
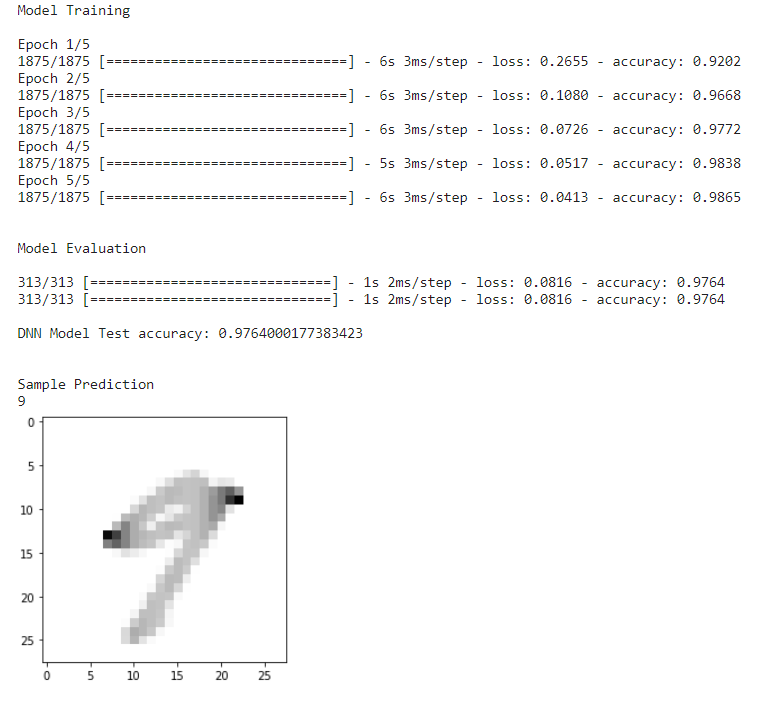
Predicción del modelo DNN
Predicción del modelo RNN (LSTM)
El enfoque para RNN (LSTM) y DNN es el mismo para el modelo.
if __name__ == "__main__": # cargar datos x_train, y_train, x_test, y_test = load_data_NN() # cargar modelo model = RNN(x_train.shape[1:]) print("nnModel Trainingn") model.fit(x_train, y_train, epochs = 5) print("nnModel Evaluationn") model.evaluate(x_test, y_test) score2 = model.evaluate(x_test, y_test, detallado=1) print('n''RNN (LSTM) Precisión de la prueba del modelo:' , puntuación2[1])
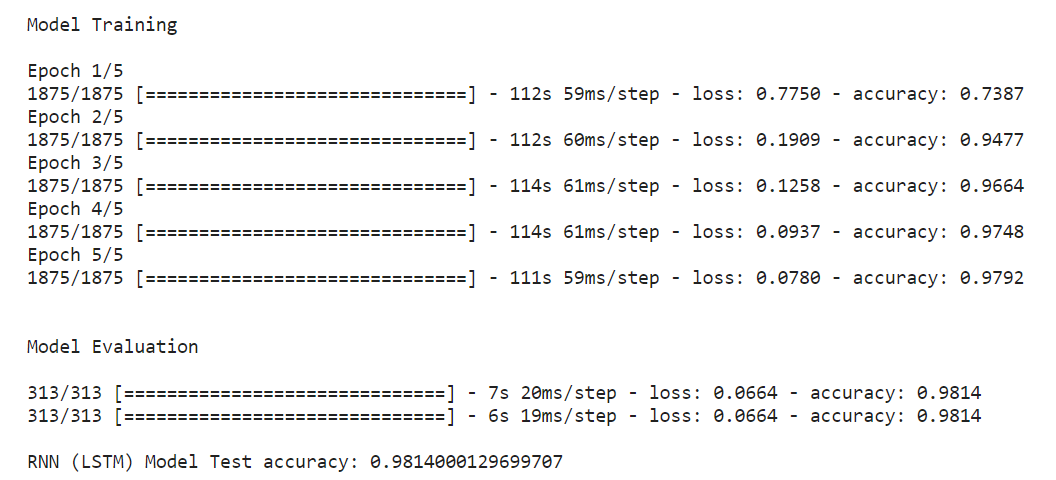
Predicción del modelo RNN (LSTM)
Predicción del modelo CNN
Para CNN, cargaremos la función load_data_CNN(); la función CNN se diferencia de las otras dos porque tiene una capa de convolución, densa, aplanada, etc. Junto con el tren y el conjunto de prueba, también tiene diferentes tamaños. Esta función hecha a la medida es beneficiosa para CNN.
if __name__ == "__main__": # cargar datos x_train, y_train, x_test, y_test = load_data_CNN() # cargar modelo input_shape = (28,28,1) model = CNN(input_shape) print("nnModel Trainingn") model.fit (x_train, y_train, epochs = 5) print("nnModel Evaluationn") model.evaluate(x_test, y_test) score3 = model.evaluate(x_test, y_test, verbose=1) print('n''Precisión de la prueba del modelo CNN:' , score3[1]) print("nnPredicción de muestra") sample_prediction(20)
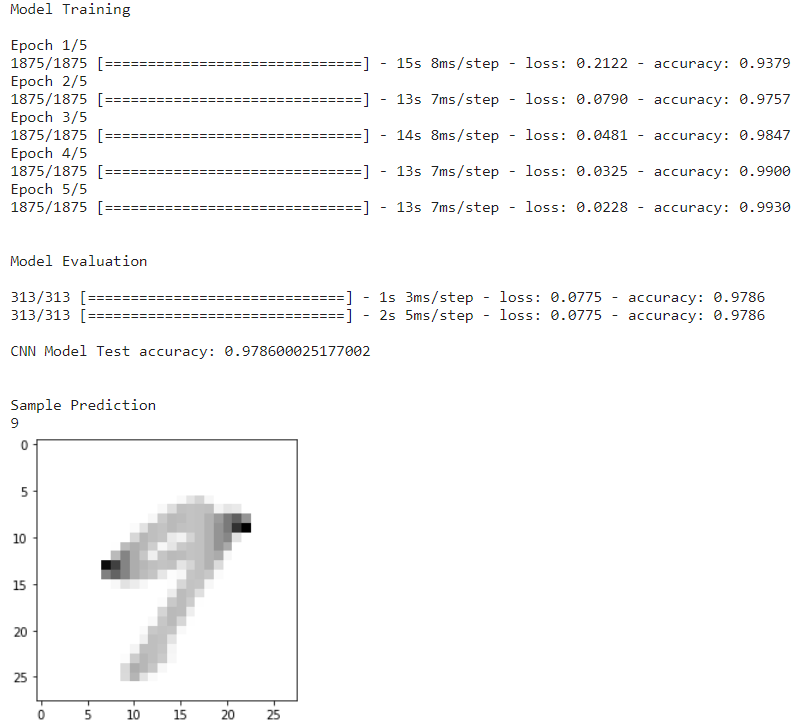
Predicción del modelo CNN
Una vez cargada la función CNN, lo siguiente es ajustar el modelo con 5 épocas. Después de la evaluación y prueba del modelo, se adquiere la precisión y se obtendrá una imagen de entrada de muestra para predecir la imagen.
Comparación de las precisiones del modelo
Después de implementar tres modelos y adquirir sus puntajes, compararlos es imprescindible para llegar a una declaración final. El código mencionado a continuación presentará un formato de tabla que indica los modelos de mayor a menor precisión.
El código indica, llamando a los modelos y sus precisiones en un formato de matriz, clasificándolos en orden descendente y mostrando la salida en formato de tabla.
resultados=pd.DataFrame({'Modelo':['DNN','RNN (LSTM)','CNN'], 'Puntuación de precisión':[puntuación1[1],puntuación2[1],puntuación3[1]]} ) result_df=results.sort_values(by='Puntaje de precisión', ascendente=Falso) result_df=result_df.set_index('Modelo') result_df
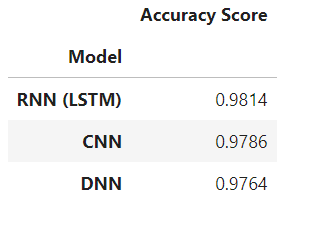
Tabla de precisiones del modelo
La tabla generada arriba establece que la RNN (LSTM) lidera la predicción con un puntaje de máxima precisión, mientras que la CNN está en 2nd lugar y DNN tiene la menor puntuación de precisión.
Conclusión
Para resumir toda la ejecución:
- Importamos bibliotecas. Explorado y cargado el conjunto de datos trazando algunas de las imágenes.
- Luego definimos dos funciones hechas a medida para DNN, RNN (LSTM) y CNN.
- Implementamos algoritmos para cada uno de los modelos de Deep Learning.
- Después de eso, comenzamos con la fase de predicción para todos los modelos de Deep Learning.
- Por último, hicimos una tabla de comparación para saber qué modelos de aprendizaje profundo son adecuados para la predicción de conjuntos de datos MNIST.
Así, el modelo RNN (LSTM) es el ganador en toda la implementación, con una puntuación del 98.54 %. El modelo CNN obtuvo 2nd lugar con 98.08%, y el modelo DNN está en 3rd lugar con 97.21 %. Con la tabla de comparación final, los puntos clave son:
- Con un tiempo de implementación rápido, el modelo CNN requiere menos parámetros para el entrenamiento y se mantiene el rendimiento del modelo.
- Con una ejecución más rápida, el modelo DNN requiere la mayoría de los parámetros para el entrenamiento, pero el rendimiento del modelo se ve comprometido con menos precisión.
- Con el tiempo de ejecución más lento, el LSTM funcionó mejor que los otros dos. Esto beneficia al LSTM para mostrar un mejor rendimiento.
- Por lo tanto, con la implementación anterior, podemos concluir que el modelo LSTM es apropiado para que Deep Learning funcione con MNIST y otros conjuntos de datos de imágenes.
Con suerte, este artículo lo ayudará a comprender cómo seleccionar los modelos de aprendizaje profundo apropiados. Gracias.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2022/11/analyzing-and-comparing-deep-learning-models/

