Introducción
Encontrar y rastrear las posiciones de articulaciones corporales importantes o puntos clave en una imagen o secuencia de video es la tarea de detección de postura, comúnmente conocida como estimacion de poses o detección de puntos clave. Busca comprender y representar el posicionamiento y la disposición espacial de las personas u otras cosas en una escena. La detección de poses juega un papel crucial y encuentra aplicaciones en varios sectores, incluidos la robótica y la automatización, los juegos, la seguridad y la vigilancia, así como el monitoreo de deportes y estado físico. Permite una amplia gama de aplicaciones que involucran interacción humano-computadora, análisis, animación, atención médica, seguridad y robótica al ofrecer información detallada sobre el movimiento humano y las relaciones espaciales. En este artículo, vamos a estudiar algunos interesantes detección de poses algoritmos utilizando nuevas técnicas de visión artificial. Comprenda cómo, como principiantes, podemos usarlos en un entorno real. Estos algoritmos son:
- pose abierta
- posenet
- MoveNet
También examinaremos dos nuevos algoritmos aportados recientemente por Google que utilizan la arquitectura MobileNet V2. Estos dos algoritmos son, Relámpago MoveNet y Trueno MoveNet.
OBJETIVOS DE APRENDIZAJE
- Comprender los conceptos básicos: aprenda todo lo que hay que saber sobre la idea de la estimación de la postura y por qué es tan crucial para la visión artificial.
- Comprensión de la detección de puntos clave: Familiarícese con los métodos de detección de puntos clave, que implican localizar componentes del cuerpo o puntos clave particulares en una imagen o video.
- Asociación y seguimiento de puntos clave: aprenda a realizar un seguimiento de los puntos clave a lo largo del tiempo y a asociarlos entre fotogramas para estimar la pose continua de una persona mediante el seguimiento y la asociación de puntos clave. Reconocer las dificultades y los métodos utilizados en este proceso.
- Preprocesamiento de datos: desarrolle sus habilidades de modelado entrenando modelos de estimación de poses utilizando conjuntos de datos anotados. Identifique los pasos involucrados en la recopilación y el etiquetado de datos de entrenamiento, la elección de funciones de pérdida adecuadas y la mejora del rendimiento del modelo.
- Aplicaciones e Integración: Conozca las diferentes formas en que se utiliza la estimación de poses en la visión por computadora en áreas que incluyen la realidad aumentada, el reconocimiento de gestos, la interacción humano-computadora y el reconocimiento de acciones humanas.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Arquitecturas del Modelo
1. Pose Abierta
El modelo de detección de poses de OpenPose tiene una arquitectura compleja con varias etapas y partes. Para encontrar y estimar puntos clave de numerosas personas en una imagen o video, se utiliza una canalización de varias etapas. El modelo primero examina la imagen de entrada y hace un esfuerzo por comprender sus características. El modelo mapea estas características para representar varios aspectos de la imagen, incluidas formas, colores y texturas. En la etapa posterior, el modelo se enfoca en comprender las conexiones entre las diferentes partes del cuerpo.
Produce otro conjunto de mapas que ilustran los vínculos potenciales entre diferentes partes del cuerpo, como la conexión entre la muñeca y el codo o el hombro y la cadera. Para determinar la verdadera pose de cada persona, el modelo emplea un algoritmo para descifrar los mapas de enlace. Analiza los mapas para establecer las relaciones entre los componentes del cuerpo y crea un modelo esquelético integral de cada pose.
Estos pasos permiten que el modelo OpenPose detecte y rastree las poses de varias personas en tiempo real con precisión y eficiencia.

2. Pose Net
La red neuronal convolucional (CNN) sirve como base para el diseño de la posenet modelo de detección de poses. Para extraer información útil, toma una imagen de entrada y la ejecuta a través de varias capas de procesamiento convolucional. Estas capas convolucionales ayudan en la captura de numerosos patrones y estructuras de la imagen. El método de estimación de la pose de una persona que utiliza PoseNet se centra en estimar los puntos clave de la pose de una sola persona. Las coordenadas 2D de los puntos clave del cuerpo pueden retroceder directamente utilizando la arquitectura CNN. Esto significa que el modelo desarrolla la capacidad de pronosticar las coordenadas X e Y de las articulaciones del cuerpo, como las muñecas, los codos, las rodillas y los tobillos durante el entrenamiento.
La estimación de Pose es rápida y fácil debido a la simplicidad de la arquitectura PoseNet, lo que la hace ideal para aplicaciones con recursos de procesamiento limitados, como navegadores web o teléfonos inteligentes. Ofrece un enfoque rápido y simple para determinar la postura de una persona en una imagen o video.
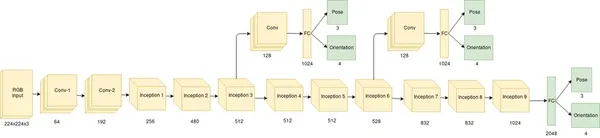
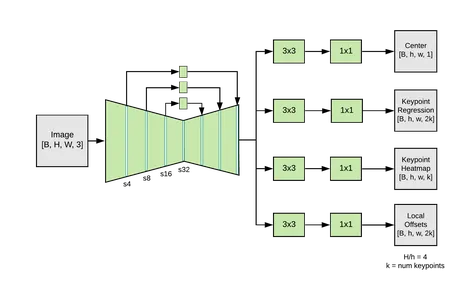
3.MoveNet
La arquitectura del modelo de detección de poses de MoveNet también se construye utilizando una red neuronal convolucional profunda (CNN). Emplea un diseño compatible con dispositivos móviles que está optimizado para operar en sistemas integrados y otros dispositivos con recursos limitados. MoveNet utiliza un enfoque de estimación de pose de una sola persona con el objetivo de estimar los puntos clave de pose de una persona. Comienza con una red troncal simple, luego pasa a las etapas de asociación de puntos clave y detección de puntos clave. La red troncal procesa la imagen de entrada, aislando las características significativas. El paso de asociación de puntos clave refina aún más los puntos clave teniendo en cuenta sus dependencias y relaciones geográficas. La etapa de detección de puntos clave predice los índices de confianza y las posiciones exactas de los puntos clave del cuerpo.
El diseño de MoveNet equilibra la eficiencia y la precisión, lo que lo hace apropiado para la estimación de posturas en tiempo real en dispositivos con potencia computacional limitada. En varias aplicaciones, como el seguimiento del estado físico, la realidad aumentada y la interacción basada en gestos, ofrece un método práctico para identificar y rastrear posiciones humanas.
Detección de relámpagos y truenos en pose
Como versiones especializadas de la familia de modelos MoveNet, Google creó los modelos de detección de poses Lightning y Thunder. En 2021, el equipo de Lightning presentó una versión mejorada de Lightning diseñada específicamente para la estimación de poses a la velocidad del rayo. Es perfecto para aplicaciones con estrictas limitaciones de latencia, ya que utiliza técnicas de compresión de modelos y actualizaciones arquitectónicas para reducir los requisitos informáticos y lograr tiempos de inferencia ultrarrápidos. El lanzamiento de 2022 de Thunder, por otro lado, se centra en la estimación de poses de varias personas. Aumenta la capacidad de MoveNet para identificar y seguir con precisión las posiciones de varias personas a la vez en situaciones reales.
Tanto el modelo Lightning como el Thunder se distinguen de los métodos de la competencia al proporcionar una estimación precisa de la postura que es eficiente y adecuada para ciertos casos de uso: Lightning para una inferencia ultrarrápida y compatibilidad con dispositivos universales, y Thunder para una precisión y un rendimiento mejorados. Estos modelos demuestran la dedicación de Google para desarrollar tecnología de detección de poses para satisfacer una variedad de necesidades de aplicaciones.

Implementando Detección de Pose
Necesitamos apegarnos a algunos procedimientos para usar el modelo MoveNet Lightning para la detección de poses en una imagen. Para comenzar, asegúrese de haber instalado las bibliotecas y dependencias de software necesarias. Dos marcos de aprendizaje profundo ampliamente utilizados, TensorFlow y PyTorch, son ejemplos de este tipo de bibliotecas. A continuación, cargue los pesos del modelo MoveNet Lightning, que normalmente están disponibles en un formato previamente entrenado. Una vez cargado el modelo, preprocesar la imagen de entrada escalándola al tamaño de entrada apropiado y aplicando cualquier normalización necesaria. Alimente al modelo con la imagen preprocesada, luego use la inferencia directa para obtener los resultados. Los puntos clave pronosticados para varias áreas del cuerpo, comúnmente mostrados como coordenadas (x, y), formarán la salida.
Por último, realice cualquier procesamiento posterior necesario en los puntos clave, como vincular puntos clave para crear representaciones esqueléticas o aplicar criterios de confianza. Los resultados de la estimación de la pose mejoran con esta fase de posprocesamiento. Al usar el modelo MoveNet Lightning para detectar posturas en una imagen, puede estimar y analizar las posturas de las personas dentro de la imagen siguiendo estos pasos.

Explicación de la detección
Se da una explicación detallada para la detección de una pose en una imagen de entrada. esta página.
Comencemos a construir un modelo de rayos MoveNet para implementar la detección de poses en tiempo real en datos de video.
En primer lugar, importando las bibliotecas necesarias.
import tensorflow as tf
import numpy as np
from matplotlib import pyplot as plt
import cv2Luego, el paso más importante, cargar nuestro modelo de una sola pose MoveNet Lightning. Pose única aquí describe que el modelo va a detectar la pose de un solo individuo, mientras que su otra versión denominada pose múltiple detecta poses de varias personas en un marco.
interpreter = tf.lite.Interpreter(model_path='lite-model_movenet_singlepose_lightning_3.tflite')
interpreter.allocate_tensors()Puntos clave para el modelo
Puede descargar este modelo desde TensorFlow hub. Ahora, definiremos los puntos clave para el modelo. Los puntos clave son áreas únicas o puntos de referencia en el cuerpo humano que se identifican y monitorean en el contexto de modelos de detección de poses como MoveNet. Estos puntos clave representan articulaciones y partes del cuerpo importantes, lo que permite una comprensión completa de la postura del cuerpo. Las muñecas, los codos, los hombros, las caderas, las rodillas y los tobillos se utilizan con frecuencia como puntos clave, además de la cabeza, los ojos, la nariz y las orejas.
EDGES = { (0, 1): 'm', (0, 2): 'c', (1, 3): 'm', (2, 4): 'c', (0, 5): 'm', (0, 6): 'c', (5, 7): 'm', (7, 9): 'm', (6, 8): 'c', (8, 10): 'c', (5, 6): 'y', (5, 11): 'm', (6, 12): 'c', (11, 12): 'y', (11, 13): 'm', (13, 15): 'm', (12, 14): 'c', (14, 16): 'c'
} #Function for drawing keypoints
def draw_keypoints(frame, keypoints, confidence_threshold): y, x, c = frame.shape shaped = np.squeeze(np.multiply(keypoints, [y,x,1])) for kp in shaped: ky, kx, kp_conf = kp if kp_conf > confidence_threshold: cv2.circle(frame, (int(kx), int(ky)), 4, (0,255,0), -1) El diccionario de puntos clave para los puntos clave establecidos anteriormente son,
nose:0, left_eye:1, right_eye:2, left_ear:3, right_ear:4, left_shoulder:5, right_shoulder:6, left_elbow:7, right_elbow:8, left_wrist:9, right_wrist:10, left_hip:11, right_hip:12, left_knee:13, right_knee:14, left_ankle: 15, right_ankle:16Ahora, después de dibujar las Conexiones, veamos cómo capturar video a través de la biblioteca OpenCV.
cap = cv2.VideoCapture(0)
while cap.isOpened(): ret, frame = cap.read() cv2.imshow(frame)cv2.VideoCapture, es una función importante de OpenCV para leer videos de entrada. En este caso, 0 especifica que captura el video desde la cámara principal de la computadora portátil, mientras que 1 se usa para personas que usan cámaras web externas. Para usar un video de entrada personalizado, simplemente encierre la ruta de la imagen entre comillas.
Al estimar la pose a través de la visión por computadora, el procesamiento y el cambio de tamaño del marco y el relleno son muy importantes. Proporciona funcionalidades como:
- Los cuadros de imagen o video de entrada son uniformes para cumplir con el tamaño anticipado del modelo al cambiar el tamaño del cuadro.
- Utilice el relleno para resolver la situación en la que las dimensiones del marco original son más pequeñas que el tamaño de entrada necesario del modelo. Agregar relleno amplía el marco para acomodar el tamaño de entrada requerido, lo que garantiza un procesamiento uniforme independientemente del tamaño de entrada.
Consulte el código detallado esta página.
Conclusión
Entonces, ¿qué hemos aprendido de este artículo? Estudiemos algunos puntos importantes de este artículo.
- Perspectiva de la investigación: La estimación de poses es un tema de alta investigación, con nuevos desarrollos y dificultades que surgen todos los días. Puede avanzar en el área investigando nuevos algoritmos de visión por computadora, mejorando las técnicas actuales o abordando problemas particulares relacionados con la estimación de poses.
- Importancia: La estimación de pose contribuye significativamente a interacciones más naturales e intuitivas entre personas y computadoras en la interacción humano-computadora. Con la ayuda de este artículo, puede utilizar su experiencia para construir y crear sistemas interactivos que reaccionen a gestos físicos, posturas o movimientos corporales.
- Proyectos académicos: La estimación de poses es un excelente tema para proyectos académicos, ya sea que se realicen de forma independiente o en colaboración. Los desafíos relacionados con la estimación de poses, los conjuntos de datos o las aplicaciones pueden explorarse, y puede crear un proyecto que muestre su comprensión y sus habilidades de aplicación práctica.
- Amplia gama de aplicaciones: La estimación de pose tiene numerosos usos en diversos campos, incluidos los deportes, la medicina, la vigilancia y las industrias de la animación y el entretenimiento.
Un método potente para predecir con precisión las poses humanas en aplicaciones en tiempo real es el modelo de detección de poses MoveNet, en particular su forma mejorada MoveNet Lightning. Estos modelos pueden detectar y rastrear puntos clave que representan con precisión diferentes partes del cuerpo mediante el uso de redes neuronales convolucionales profundas. Son ideales para implementar en dispositivos con recursos limitados, como teléfonos móviles y sistemas embebidos, debido a su simplicidad y eficiencia. Los modelos MoveNet brindan una solución flexible para una variedad de aplicaciones, incluido el seguimiento del estado físico, la realidad aumentada, la interacción basada en gestos y el análisis de multitudes. Pueden manejar la estimación de poses tanto de una sola persona como de varias personas. Han hecho contribuciones significativas al campo de la identificación de posturas que demuestran el desarrollo de la tecnología de visión por computadora y su promesa de mejorar la interacción humano-computadora y la comprensión del movimiento.
Preguntas frecuentes
R. La detección de poses es el método para determinar y rastrear la pose del cuerpo de una persona en fotografías fijas o imágenes en movimiento mediante la aplicación de algoritmos de visión por computadora. Implica ubicar articulaciones importantes o puntos clave en el cuerpo y descubrir sus ubicaciones y orientaciones.
R. Las redes neuronales convolucionales (CNN), un tipo de modelo de aprendizaje profundo, utilizan algoritmos de detección de poses para ubicar partes importantes del cuerpo humano. Siguiendo su conexión, estos puntos clave crean representaciones esqueléticas que revelan detalles sobre la postura, la posición y el movimiento del cuerpo.
R. La detección de poses tiene una amplia gama de usos, que incluyen realidad aumentada, robótica, animación, vigilancia, análisis de movimiento, análisis deportivo y atención médica. Permite reconocer gestos, rastrear actividades, animar personajes, usar ejercicios de rehabilitación, monitorear la seguridad y más.
R. La detección de poses tiene dificultades para identificar los puntos críticos de varias personas en entornos concurridos debido a las oclusiones (partes del cuerpo que están cubiertas o superpuestas), las condiciones de iluminación fluctuantes y las posiciones complejas. El rendimiento en tiempo real, la precisión y la robustez son otros factores cruciales.
R. OpenPose, MoveNet, PoseNet y AlphaPose son algunos de los modelos de detección de poses más conocidos. Estos modelos, que utilizan métodos de aprendizaje profundo, también están disponibles en el campo de la visión artificial para aplicaciones de identificación de poses.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- EVM Finanzas. Interfaz unificada para finanzas descentralizadas. Accede Aquí.
- Grupo de medios cuánticos. IR/PR amplificado. Accede Aquí.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/06/learning-pose-estimation-using-new-computer-vision-techniques/

