Esta publicación de blog está coescrita con Chaoyang He y Salman Avestimehr de FedML.
El análisis de datos de ciencias de la vida y atención médica del mundo real (HCLS) plantea varios desafíos prácticos, como silos de datos distribuidos, falta de datos suficientes en un solo sitio para eventos raros, pautas regulatorias que prohíben el intercambio de datos, requisitos de infraestructura y costo incurrido en la creación un repositorio de datos centralizado. Debido a que se encuentran en un dominio altamente regulado, los socios y clientes de HCLS buscan mecanismos de preservación de la privacidad para administrar y analizar datos confidenciales, distribuidos y a gran escala.
Para mitigar estos desafíos, proponemos usar un marco de aprendizaje federado (FL) de código abierto llamado FedML, que le permite analizar datos confidenciales de HCLS entrenando un modelo global de aprendizaje automático a partir de datos distribuidos almacenados localmente en diferentes sitios. FL no requiere mover o compartir datos entre sitios o con un servidor centralizado durante el proceso de entrenamiento del modelo.
En esta serie de dos partes, demostramos cómo puede implementar un marco FL basado en la nube en AWS. En la primera publicación, describimos los conceptos de FL y el marco FedML. En el segunda publicación, presentamos los casos de uso y el conjunto de datos para mostrar su eficacia en el análisis de conjuntos de datos de atención médica del mundo real, como el datos de la UCI electrónica, que comprende una base de datos de cuidados intensivos multicéntrica recopilada de más de 200 hospitales.
Antecedentes
Aunque el volumen de datos generados por HCLS nunca ha sido mayor, los desafíos y limitaciones asociados con el acceso a dichos datos limitan su utilidad para futuras investigaciones. El aprendizaje automático (ML) presenta una oportunidad para abordar algunas de estas preocupaciones y se está adoptando para avanzar en el análisis de datos y obtener conocimientos significativos de diversos datos de HCLS para casos de uso como la prestación de atención, el apoyo a decisiones clínicas, la medicina de precisión, la clasificación y el diagnóstico, y enfermedades crónicas. administración de cuidados. Debido a que los algoritmos de ML a menudo no son adecuados para proteger la privacidad de los datos del paciente, existe un interés creciente entre los socios y clientes de HCLS por utilizar mecanismos e infraestructura de preservación de la privacidad para administrar y analizar datos confidenciales, distribuidos y a gran escala. [1]
Hemos desarrollado un marco FL en AWS que permite analizar datos de salud confidenciales y distribuidos de una manera que preserva la privacidad. Implica entrenar un modelo de aprendizaje automático compartido sin mover ni compartir datos entre sitios o con un servidor centralizado durante el proceso de entrenamiento del modelo, y se puede implementar en varias cuentas de AWS. Los participantes pueden optar por mantener sus datos en sus sistemas locales o en una cuenta de AWS que controlen. Por lo tanto, lleva el análisis a los datos, en lugar de mover los datos al análisis.
En esta publicación, mostramos cómo puede implementar el marco FedML de código abierto en AWS. Probamos el marco en datos de eICU, una base de datos de cuidados intensivos multicéntrica recopilada de más de 200 hospitales, para predecir la mortalidad de los pacientes en el hospital. Podemos usar este marco FL para analizar otros conjuntos de datos, incluidos datos genómicos y de ciencias de la vida. También puede ser adoptado por otros dominios que están plagados de datos distribuidos y confidenciales, incluidos los sectores de finanzas y educación.
Aprendizaje federado
Los avances en tecnología han llevado a un crecimiento explosivo de datos en todas las industrias, incluido HCLS. Las organizaciones de HCLS a menudo almacenan datos en silos. Esto plantea un gran desafío en el aprendizaje basado en datos, que requiere grandes conjuntos de datos para generalizar bien y lograr el nivel de rendimiento deseado. Además, recopilar, seleccionar y mantener conjuntos de datos de alta calidad implica un tiempo y un costo significativos.
El aprendizaje federado mitiga estos desafíos mediante la capacitación colaborativa de modelos de ML que usan datos distribuidos, sin necesidad de compartirlos o centralizarlos. Permite representar diversos sitios dentro del modelo final, lo que reduce el riesgo potencial de sesgo basado en el sitio. El marco sigue una arquitectura cliente-servidor, donde el servidor comparte un modelo global con los clientes. Los clientes entrenan el modelo en función de los datos locales y comparten parámetros (como gradientes o pesos del modelo) con el servidor. El servidor agrega estos parámetros para actualizar el modelo global, que luego se comparte con los clientes para la próxima ronda de capacitación, como se muestra en la siguiente figura. Este proceso iterativo de entrenamiento del modelo continúa hasta que el modelo global converge.
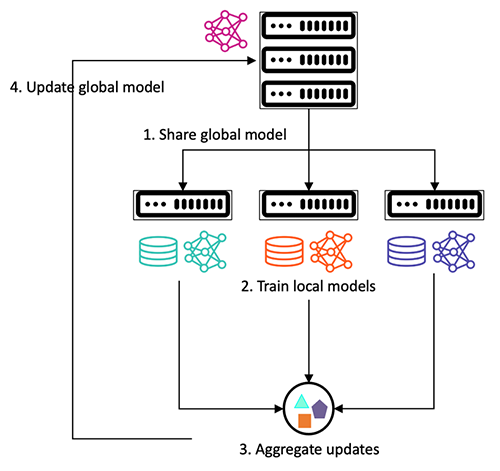
Proceso iterativo de entrenamiento de modelos.
En los últimos años, este nuevo paradigma de aprendizaje se ha adoptado con éxito para abordar la preocupación del gobierno de datos en el entrenamiento de modelos de ML. Uno de esos esfuerzos es MELODDIE, un consorcio liderado por la Iniciativa de Medicamentos Innovadores (IMI), impulsado por AWS. Es un programa de 3 años que involucra a 10 compañías farmacéuticas, 2 instituciones académicas y 3 socios tecnológicos. Su objetivo principal es desarrollar un marco FL multitarea para mejorar el rendimiento predictivo y la aplicabilidad química de los modelos basados en el descubrimiento de fármacos. La plataforma comprende múltiples cuentas de AWS, cada socio farmacéutico conserva el control total de sus respectivas cuentas para mantener sus conjuntos de datos privados y una cuenta central de aprendizaje automático que coordina las tareas de capacitación del modelo.
El consorcio entrenó modelos en miles de millones de puntos de datos, que consisten en más de 20 millones de moléculas pequeñas en más de 40,000 4 ensayos biológicos. Según los resultados experimentales, los modelos colaborativos demostraron una mejora del 10 % en la categorización de las moléculas como farmacológica o toxicológicamente activas o inactivas. También condujo a un aumento del 2 % en su capacidad para generar predicciones confiables cuando se aplica a nuevos tipos de moléculas. Finalmente, los modelos colaborativos fueron típicamente un XNUMX% mejores en la estimación de valores de actividades toxicológicas y farmacológicas.
FedML
FedML es una biblioteca de código abierto para facilitar el desarrollo de algoritmos FL. Admite tres paradigmas informáticos: capacitación en el dispositivo para dispositivos perimetrales, computación distribuida y simulación de una sola máquina. También ofrece diversas investigaciones algorítmicas con un diseño de API genérico y flexible e implementaciones completas de línea base de referencia (optimizador, modelos y conjuntos de datos). Para obtener una descripción detallada de la biblioteca FedML, consulte FedML.
La siguiente figura presenta la arquitectura de biblioteca de código abierto de FedML.
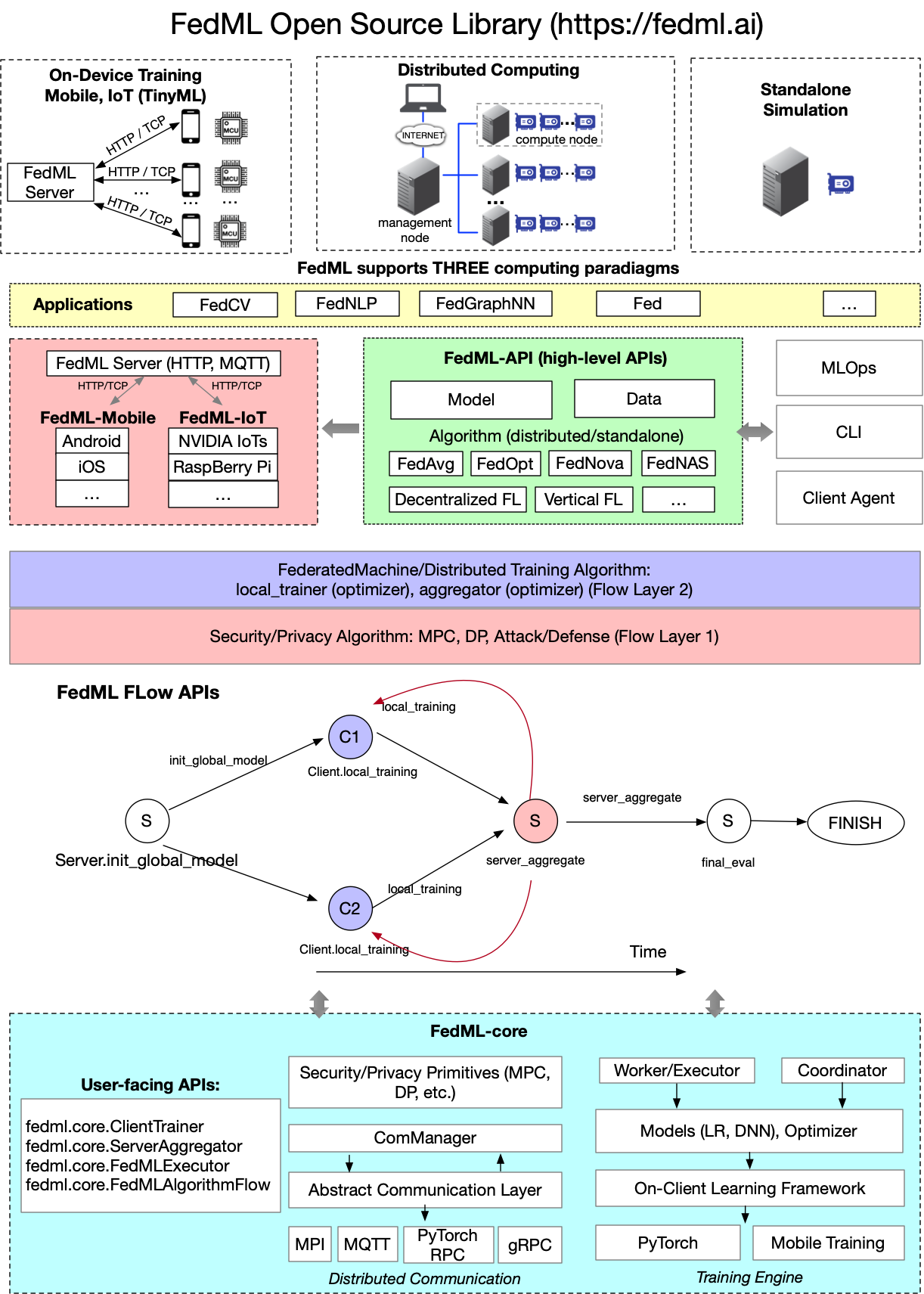
Arquitectura de biblioteca de código abierto de FedML
Como se ve en la figura anterior, desde el punto de vista de la aplicación, FedML protege los detalles del código subyacente y las configuraciones complejas del entrenamiento distribuido. En el nivel de la aplicación, como la visión por computadora, el procesamiento del lenguaje natural y la minería de datos, los científicos e ingenieros de datos solo necesitan escribir el modelo, los datos y el entrenador de la misma manera que un programa independiente y luego pasarlo al objeto FedMLRunner para completar todos los procesos, como se muestra en el siguiente código. Esto reduce en gran medida la sobrecarga para que los desarrolladores de aplicaciones realicen FL.
El algoritmo FedML todavía es un trabajo en progreso y se mejora constantemente. Con este fin, FedML abstrae el entrenador y agregador central y proporciona a los usuarios dos objetos abstractos, FedML.core.ClientTrainer y FedML.core.ServerAggregator, que solo necesita heredar las interfaces de estos dos objetos abstractos y pasarlos a FedMLRunner. Tal personalización brinda a los desarrolladores de ML la máxima flexibilidad. Puede definir estructuras de modelo arbitrarias, optimizadores, funciones de pérdida y más. Estas personalizaciones también se pueden conectar a la perfección con la comunidad de código abierto, la plataforma abierta y la ecología de aplicaciones mencionadas anteriormente con la ayuda de FedMLRunner, que resuelve por completo el problema del retraso prolongado desde los algoritmos innovadores hasta la comercialización.
Finalmente, como se muestra en la figura anterior, FedML admite procesos informáticos distribuidos, como protocolos de seguridad complejos y entrenamiento distribuido como un proceso informático de flujo de gráficos acíclicos dirigidos (DAG), lo que hace que la escritura de protocolos complejos sea similar a los programas independientes. Basado en esta idea, el protocolo de seguridad Flow Layer 1 y el algoritmo ML procesan Flow Layer 2 se pueden separar fácilmente para que los ingenieros de seguridad y los ingenieros de ML puedan operar mientras mantienen una arquitectura modular.
La biblioteca de código abierto de FedML admite casos de uso de ML federado tanto para el perímetro como para la nube. En el borde, el marco facilita el entrenamiento y la implementación de modelos de borde en teléfonos móviles y dispositivos de Internet de las cosas (IoT). En la nube, permite ML colaborativo global, incluidos servidores de agregación de nube pública de múltiples regiones y múltiples inquilinos, así como la implementación de nube privada en modo Docker. El marco aborda preocupaciones clave con respecto a la preservación de la privacidad FL, como la seguridad, la privacidad, la eficiencia, la supervisión débil y la equidad.
Conclusión
En esta publicación, mostramos cómo puede implementar el marco FedML de código abierto en AWS. Esto le permite entrenar un modelo de ML en datos distribuidos, sin necesidad de compartirlos o moverlos. Configuramos una arquitectura de múltiples cuentas, donde en un escenario del mundo real, las organizaciones pueden unirse al ecosistema para beneficiarse del aprendizaje colaborativo mientras mantienen la gobernanza de datos. En el próximo post, utilizamos el conjunto de datos de eICU de varios hospitales para demostrar su eficacia en un escenario del mundo real.
Revise la presentación en re:MARS 2022 centrada en "Aprendizaje federado administrado en AWS: un estudio de caso para el cuidado de la salud” para ver un tutorial detallado de esta solución.
Referencia
[1] Kaissis, GA, Makowski, MR, Rückert, D. et al. Aprendizaje automático seguro, que preserva la privacidad y federado en imágenes médicas. Nat Mach Intell 2, 305–311 (2020). https://doi.org/10.1038/s42256-020-0186-1
[2] FedML https://fedml.ai
Acerca de los autores
 Olivia Choudhury, PhD, es arquitecto senior de soluciones de socios en AWS. Ella ayuda a los socios, en el dominio de la salud y las ciencias de la vida, a diseñar, desarrollar y escalar soluciones de vanguardia que aprovechan AWS. Tiene experiencia en genómica, análisis de atención médica, aprendizaje federado y aprendizaje automático para preservar la privacidad. Fuera del trabajo, juega juegos de mesa, pinta paisajes y colecciona manga.
Olivia Choudhury, PhD, es arquitecto senior de soluciones de socios en AWS. Ella ayuda a los socios, en el dominio de la salud y las ciencias de la vida, a diseñar, desarrollar y escalar soluciones de vanguardia que aprovechan AWS. Tiene experiencia en genómica, análisis de atención médica, aprendizaje federado y aprendizaje automático para preservar la privacidad. Fuera del trabajo, juega juegos de mesa, pinta paisajes y colecciona manga.
 Vidya Sagar Ravipati es Gerente en la Laboratorio de soluciones de Amazon ML, donde aprovecha su vasta experiencia en sistemas distribuidos a gran escala y su pasión por el aprendizaje automático para ayudar a los clientes de AWS en diferentes verticales de la industria a acelerar su adopción de la inteligencia artificial y la nube. Anteriormente, fue ingeniero de aprendizaje automático en servicios de conectividad en Amazon que ayudó a crear plataformas de personalización y mantenimiento predictivo.
Vidya Sagar Ravipati es Gerente en la Laboratorio de soluciones de Amazon ML, donde aprovecha su vasta experiencia en sistemas distribuidos a gran escala y su pasión por el aprendizaje automático para ayudar a los clientes de AWS en diferentes verticales de la industria a acelerar su adopción de la inteligencia artificial y la nube. Anteriormente, fue ingeniero de aprendizaje automático en servicios de conectividad en Amazon que ayudó a crear plataformas de personalización y mantenimiento predictivo.
 Wajahat Aziz es un arquitecto principal de soluciones de aprendizaje automático y HPC en AWS, donde se enfoca en ayudar a los clientes de atención médica y ciencias de la vida a aprovechar las tecnologías de AWS para desarrollar soluciones de ML y HPC de última generación para una amplia variedad de casos de uso, como desarrollo de medicamentos, Ensayos clínicos y aprendizaje automático para preservar la privacidad. Fuera del trabajo, a Wajahat le gusta explorar la naturaleza, hacer caminatas y leer.
Wajahat Aziz es un arquitecto principal de soluciones de aprendizaje automático y HPC en AWS, donde se enfoca en ayudar a los clientes de atención médica y ciencias de la vida a aprovechar las tecnologías de AWS para desarrollar soluciones de ML y HPC de última generación para una amplia variedad de casos de uso, como desarrollo de medicamentos, Ensayos clínicos y aprendizaje automático para preservar la privacidad. Fuera del trabajo, a Wajahat le gusta explorar la naturaleza, hacer caminatas y leer.
 divya bhargavi es científica de datos y líder vertical de medios y entretenimiento en Amazon ML Solutions Lab, donde resuelve problemas comerciales de alto valor para los clientes de AWS mediante el aprendizaje automático. Trabaja en comprensión de imágenes/videos, sistemas de recomendación de gráficos de conocimiento, casos de uso de publicidad predictiva.
divya bhargavi es científica de datos y líder vertical de medios y entretenimiento en Amazon ML Solutions Lab, donde resuelve problemas comerciales de alto valor para los clientes de AWS mediante el aprendizaje automático. Trabaja en comprensión de imágenes/videos, sistemas de recomendación de gráficos de conocimiento, casos de uso de publicidad predictiva.
 Ujjwal ratán es el líder de AI/ML y ciencia de datos en la unidad de negocios de ciencias de la vida y atención médica de AWS y también es un arquitecto principal de soluciones de AI/ML. A lo largo de los años, Ujjwal ha sido un líder de pensamiento en la industria de la salud y las ciencias de la vida, ayudando a múltiples organizaciones de Global Fortune 500 a alcanzar sus objetivos de innovación mediante la adopción del aprendizaje automático. Su trabajo relacionado con el análisis de imágenes médicas, texto clínico no estructurado y genómica ha ayudado a AWS a crear productos y servicios que brindan diagnósticos y terapias altamente personalizadas y dirigidas con precisión. En su tiempo libre, le gusta escuchar (y tocar) música y hacer viajes por carretera no planificados con su familia.
Ujjwal ratán es el líder de AI/ML y ciencia de datos en la unidad de negocios de ciencias de la vida y atención médica de AWS y también es un arquitecto principal de soluciones de AI/ML. A lo largo de los años, Ujjwal ha sido un líder de pensamiento en la industria de la salud y las ciencias de la vida, ayudando a múltiples organizaciones de Global Fortune 500 a alcanzar sus objetivos de innovación mediante la adopción del aprendizaje automático. Su trabajo relacionado con el análisis de imágenes médicas, texto clínico no estructurado y genómica ha ayudado a AWS a crear productos y servicios que brindan diagnósticos y terapias altamente personalizadas y dirigidas con precisión. En su tiempo libre, le gusta escuchar (y tocar) música y hacer viajes por carretera no planificados con su familia.
 Chaoyang él es cofundador y director de tecnología de FedML, Inc., una startup que se ejecuta para una comunidad que construye IA abierta y colaborativa desde cualquier lugar a cualquier escala. Su investigación se centra en algoritmos, sistemas y aplicaciones de aprendizaje automático distribuido/federado. Recibió su Ph.D. en Informática de la Universidad del Sur de California, Los Ángeles, Estados Unidos.
Chaoyang él es cofundador y director de tecnología de FedML, Inc., una startup que se ejecuta para una comunidad que construye IA abierta y colaborativa desde cualquier lugar a cualquier escala. Su investigación se centra en algoritmos, sistemas y aplicaciones de aprendizaje automático distribuido/federado. Recibió su Ph.D. en Informática de la Universidad del Sur de California, Los Ángeles, Estados Unidos.
 Salman Avestimehr es profesor, director inaugural del USC-Amazon Center for Secure and Trusted Machine Learning (Trusted AI) y director del laboratorio de investigación de Teoría de la información y aprendizaje automático (vITAL) en el Departamento de Ingeniería Eléctrica e Informática y el Departamento de Ciencias Informáticas de Universidad del Sur de California. También es cofundador y director ejecutivo de FedML. Recibió mi Ph.D. en Ingeniería Eléctrica y Ciencias de la Computación de UC Berkeley en 2008. Su investigación se centra en las áreas de teoría de la información, aprendizaje automático descentralizado y federado, aprendizaje y computación seguros y que preservan la privacidad.
Salman Avestimehr es profesor, director inaugural del USC-Amazon Center for Secure and Trusted Machine Learning (Trusted AI) y director del laboratorio de investigación de Teoría de la información y aprendizaje automático (vITAL) en el Departamento de Ingeniería Eléctrica e Informática y el Departamento de Ciencias Informáticas de Universidad del Sur de California. También es cofundador y director ejecutivo de FedML. Recibió mi Ph.D. en Ingeniería Eléctrica y Ciencias de la Computación de UC Berkeley en 2008. Su investigación se centra en las áreas de teoría de la información, aprendizaje automático descentralizado y federado, aprendizaje y computación seguros y que preservan la privacidad.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/part-1-federated-learning-on-aws-with-fedml-health-analytics-without-sharing-sensitive-data/

