El panorama de la IA está siendo remodelado por el surgimiento de modelos generativos capaces de sintetizar datos de alta calidad, como texto, imágenes, música y videos. El curso hacia la democratización de la IA ayudó a popularizar aún más la IA generativa luego de los lanzamientos de código abierto para familias de modelos básicos como BERT, T5, GPT, CLIP y, más recientemente, Difusión estable. Cientos de aplicaciones de software como servicio (SaaS) se están desarrollando en torno a estos modelos preentrenados, que se sirven directamente a los clientes finales o se ajustan primero por cliente para generar contenido personal y único (como avatares, ediciones de fotos estilizadas, activos de videojuegos, texto específico del dominio y más). Con el ritmo de la innovación tecnológica y la proliferación de casos de uso novedosos para la IA generativa, los próximos proveedores de SaaS nativos de IA y las nuevas empresas en el segmento B2C deben prepararse para escalar desde el primer día y apuntar a acortar su tiempo de comercialización al reducir la carga operativa. sobrecarga tanto como sea posible.
En esta publicación, revisamos los requisitos técnicos y las consideraciones de diseño de aplicaciones para ajustar y servir modelos de IA hiperpersonalizados a escala en AWS. Proponemos una arquitectura basada en la gestión integral Amazon SageMaker características de capacitación y servicio que permiten a los proveedores de SaaS desarrollar sus aplicaciones más rápido, brindar calidad de servicio y aumentar la rentabilidad.
Alcance y requisitos de la solución
Primero definamos el alcance de las aplicaciones SaaS de IA generativas personalizadas:
A continuación, revisemos los requisitos técnicos y el flujo de trabajo de una aplicación que admita el ajuste fino y el servicio de potencialmente miles de modelos personalizados. El flujo de trabajo generalmente consta de dos partes:
- Genere un modelo personalizado a través de un ajuste ligero y fino del modelo base preentrenado
- Aloje el modelo personalizado para solicitudes de inferencia bajo demanda cuando el usuario regrese
Una de las consideraciones para la primera parte del flujo de trabajo es que debemos estar preparados para un tráfico de usuarios impredecible y con picos. Los picos de uso podrían surgir, por ejemplo, debido a los nuevos lanzamientos de modelos básicos o a los nuevos lanzamientos de funciones de SaaS. Esto impondrá grandes necesidades de capacidad de GPU intermitentes, así como la necesidad de lanzamientos de trabajos de ajuste fino asincrónicos para absorber el pico de tráfico.
Con respecto al alojamiento de modelos, a medida que el mercado se inunda con aplicaciones SaaS basadas en IA, la velocidad del servicio se convierte en un factor distintivo. Una experiencia de usuario rápida y fluida podría verse afectada por los inicios en frío de la infraestructura o la alta latencia de inferencia. Si bien los requisitos de latencia de inferencia dependerán del caso de uso y las expectativas del usuario, en general, esta consideración conduce a una preferencia por el alojamiento de modelos en tiempo real en GPU (a diferencia de las opciones de alojamiento solo de CPU más lentas). Sin embargo, el alojamiento de modelos de GPU en tiempo real puede generar rápidamente altos costos operativos. Por lo tanto, es vital para nosotros definir una estrategia de hospedaje que evite que los costos crezcan linealmente con la cantidad de modelos implementados (usuarios activos).
Arquitectura de soluciones
Antes de describir la arquitectura propuesta, analicemos por qué SageMaker se adapta perfectamente a los requisitos de nuestra aplicación al observar algunas de sus características.
En primer lugar, Entrenamiento SageMaker y Alojamiento Web (Hosting) Las API brindan el beneficio de productividad de los trabajos de capacitación totalmente administrados y las implementaciones de modelos, de modo que los equipos que se mueven rápidamente pueden concentrarse más tiempo en las características y la diferenciación del producto. Además, el paradigma de lanzar y olvidar de los trabajos de capacitación de SageMaker se adapta perfectamente a la naturaleza transitoria de los trabajos de ajuste fino del modelo simultáneos en la fase de incorporación del usuario. Discutimos más consideraciones sobre la concurrencia en la siguiente sección.
En segundo lugar, SageMaker admite opciones únicas de alojamiento habilitadas para GPU para implementar modelos de aprendizaje profundo a escala. Por ejemplo, NVIDIA Triton Inference Server, un software de inferencia de código abierto de alto rendimiento, se integró de forma nativa en el ecosistema de SageMaker en 2022. A esto le siguió el lanzamiento de la compatibilidad con GPU para puntos finales de varios modelos de SageMaker, que proporciona una solución escalable y de bajo costo. -Latencia y forma rentable de implementar miles de modelos de aprendizaje profundo detrás de un único punto final.
Finalmente, cuando llegamos al nivel de la infraestructura, estas funciones están respaldadas por las mejores opciones informáticas de su clase. Por ejemplo, el tipo de instancia G5, que está equipado con GPU NVIDIA A10g (exclusivas de AWS), ofrece una sólida relación precio-rendimiento, tanto para el entrenamiento como para el alojamiento de modelos. Produce el costo más bajo por FLOP de FP32 (una medida importante de la potencia de cómputo que obtiene por dólar) en toda la paleta de instancias de GPU en AWS, y mejora en gran medida el tipo de instancia de GPU de menor costo anterior (G4dn). Para obtener más información, consulte Logre un rendimiento de inferencia de ML cuatro veces mayor a un costo por inferencia tres veces menor con instancias Amazon EC2 G5 para modelos NLP y CV PyTorch.
Aunque la siguiente arquitectura generalmente se aplica a varios casos de uso de IA generativa, usemos la generación de texto a imagen como ejemplo. En este escenario, una aplicación de generación de imágenes creará uno o varios modelos personalizados y ajustados para cada uno de sus usuarios, y esos modelos estarán disponibles para la generación de imágenes en tiempo real a pedido del usuario final. El flujo de trabajo de la solución se puede dividir en dos fases principales, como se desprende de la arquitectura. La primera fase (A) corresponde al proceso de incorporación de usuarios; aquí es cuando se ajusta un modelo para el nuevo usuario. En la segunda fase (B), el modelo ajustado se utiliza para la inferencia bajo demanda.
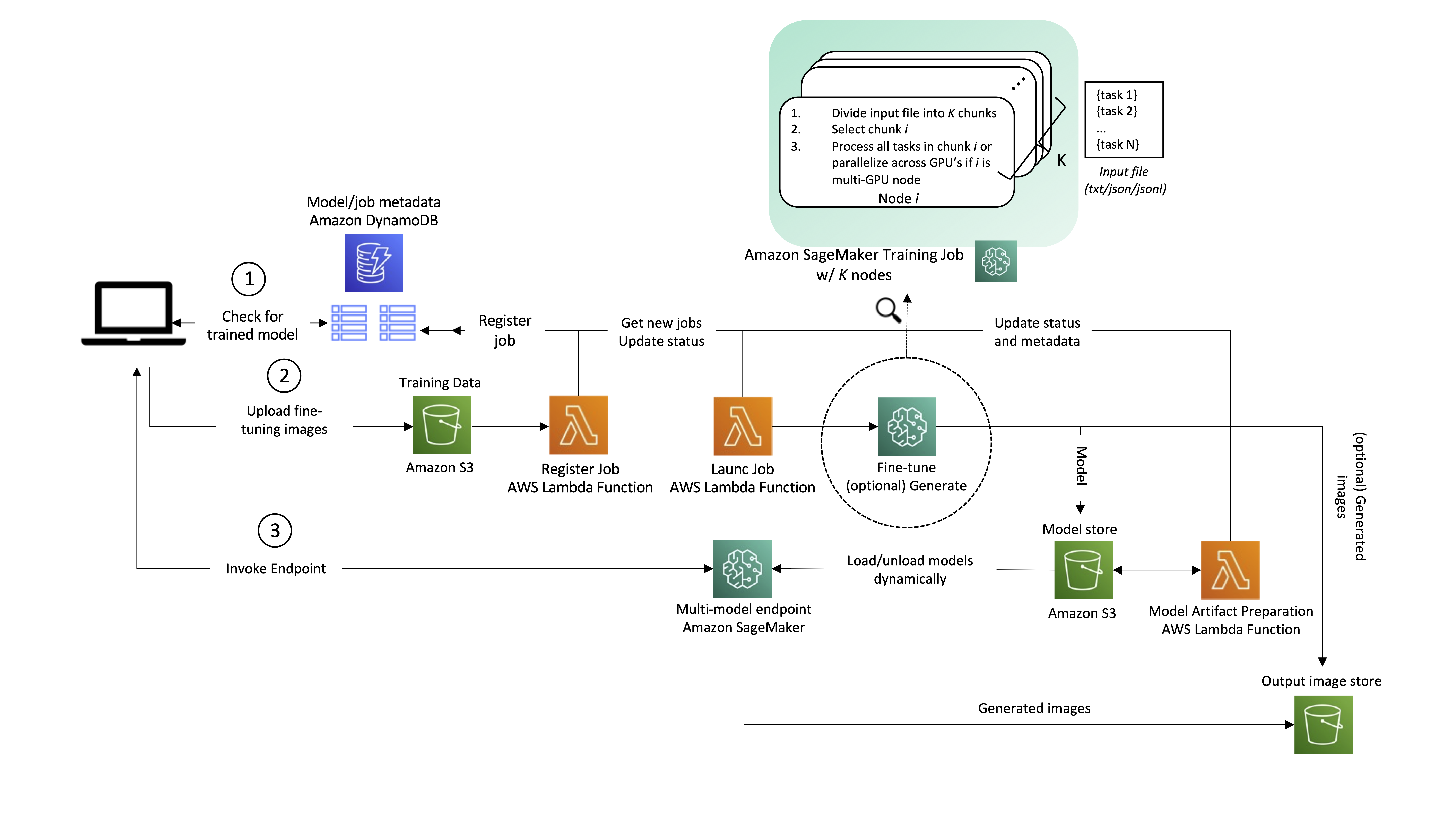
Repasemos los pasos de la arquitectura con más detalle, como se enumeran en el diagrama.
1. Comprobación del estado del modelo
Cuando un usuario interactúa con el servicio, primero verificamos si es un usuario recurrente que ya se ha incorporado al servicio y tiene modelos personalizados listos para servir. Un mismo usuario puede tener más de un modelo personalizado. El mapeo entre el usuario y los modelos correspondientes se guarda en Amazon DynamoDB, que sirve como un almacén de metadatos no relacional, sin servidor y completamente administrado, que es fácil de consultar, económico y escalable. Como mínimo, recomendamos tener dos tablas:
- Uno para almacenar el mapeo entre usuarios y modelos. Esto incluye el ID de usuario y el artefacto del modelo. Servicio de almacenamiento simple de Amazon (Amazon S3) URL.
- Otro para servir como cola, almacenando las solicitudes de creación de modelos y su estado de finalización. Esto incluye el ID de usuario, el ID del trabajo de entrenamiento del modelo y el estado, junto con hiperparámetros y metadatos asociados con el entrenamiento.
2. Incorporación de usuarios y ajuste del modelo.
Si no se ha ajustado ningún modelo para el usuario antes, la aplicación carga imágenes de ajuste fino en Amazon S3, lo que activa un AWS Lambda función para registrar un nuevo trabajo en una tabla de DynamoDB.
Otra función de Lambda consulta la tabla en busca de un nuevo trabajo y lo inicia con SageMaker Training. Se puede activar para cada registro usando Secuencias de Amazon DynamoDB, o en un horario usando Puente de eventos de Amazon (un patrón probado por los clientes de AWS, incluso internamente en Amazon). Opcionalmente, se pueden pasar imágenes o indicaciones para la inferencia y procesarlas directamente en el trabajo de capacitación de SageMaker justo después de que se entrena el modelo. Esto puede ayudar a acortar el tiempo de entrega de las primeras imágenes a la aplicación. A medida que se generan las imágenes, puede explotar la mecanismo de sincronización de punto de control en SageMaker para cargar resultados intermedios en Amazon S3. Con respecto a la simultaneidad de inicio de trabajo, SageMaker API CreateTrainingJob admite una tasa de solicitud de una por segundo, con mayores tasas de ráfaga disponibles durante períodos de alto tráfico. Si necesita iniciar de manera sostenible más de una tarea de ajuste por segundo (TPS), tiene los siguientes controles y opciones:
- Uso Piscinas cálidas administradas por SageMaker, que le permiten retener y reutilizar la infraestructura aprovisionada después de completar un trabajo de capacitación para reducir la latencia de arranque en frío para cargas de trabajo repetitivas.
- Implemente reintentos en la función de Lambda del trabajo de lanzamiento (que se muestra en el diagrama de arquitectura).
- En última instancia, si la tasa de solicitud de ajustes finos se mantiene constantemente por encima de 1 TPS, puede iniciar N ajustes finos en paralelo con un solo trabajo de capacitación de SageMaker solicitando un trabajo con
num_instances=K, y repartiendo el trabajo entre las distintas instancias. Un ejemplo de cómo puede lograr esto es pasar una lista de tareas a ejecutar como un archivo de entrada al trabajo de entrenamiento, y cada instancia procesa una tarea diferente o parte de este archivo, diferenciada por el identificador numérico de la instancia (que se encuentra en recursoconfig.json). Tenga en cuenta que las tareas individuales no deben diferir mucho en la duración del entrenamiento, para evitar la situación en la que una sola tarea mantiene todo el clúster en funcionamiento durante más tiempo del necesario.
Finalmente, el modelo ajustado se guarda, lo que activa una función de Lambda que prepara el artefacto para su publicación en un punto final de varios modelos de SageMaker. En este punto, se podría notificar al usuario que la capacitación se completó y que el modelo está listo para usar. Referirse a Administrar solicitudes de back-end y notificaciones de front-end en aplicaciones web sin servidor para conocer las mejores prácticas al respecto.
3. Servicio a pedido de las solicitudes de los usuarios
Si previamente se ha afinado un modelo para el usuario, el camino es mucho más sencillo. La aplicación invoca el punto final multimodelo, pasando la carga útil y el ID del modelo del usuario. El modelo seleccionado se carga dinámicamente desde Amazon S3 en el disco y la memoria de GPU de la instancia de punto final (si no se ha utilizado recientemente; para obtener más información, consulte Cómo funcionan los puntos finales multimodelo), y se utiliza para la inferencia. La salida del modelo (contenido personalizado) finalmente se devuelve a la aplicación.
La entrada y la salida de la solicitud deben guardarse en S3 para futuras referencias del usuario. Para evitar afectar la latencia de la solicitud (el tiempo medido desde el momento en que un usuario realiza una solicitud hasta que se devuelve una respuesta), puede realizar esta carga directamente desde la aplicación del cliente o, alternativamente, dentro del código de inferencia de su terminal.
Esta arquitectura proporciona la asincronía y la concurrencia que formaban parte de los requisitos de la solución.
Conclusión
En esta publicación, analizamos las consideraciones para ajustar y servir modelos de IA hiperpersonalizados a escala, y propusimos una solución flexible y rentable en AWS utilizando SageMaker.
No cubrimos el caso de uso del entrenamiento previo de modelos grandes. Para obtener más información, consulte Capacitación distribuida en Amazon SageMaker y Paralelismo de datos fragmentados, así como historias sobre cómo los clientes de AWS han entrenado modelos masivos en SageMaker, como AI21 y Estabilidad IA.
Acerca de los autores
 joão moura es Arquitecto de Soluciones Especialista en AI/ML en AWS, con sede en España. Ayuda a los clientes con la capacitación de modelos de aprendizaje profundo y la optimización de inferencias y, en términos más generales, con la creación de plataformas de aprendizaje automático a gran escala en AWS. También es un defensor activo de hardware especializado en aprendizaje automático y soluciones de aprendizaje automático de bajo código.
joão moura es Arquitecto de Soluciones Especialista en AI/ML en AWS, con sede en España. Ayuda a los clientes con la capacitación de modelos de aprendizaje profundo y la optimización de inferencias y, en términos más generales, con la creación de plataformas de aprendizaje automático a gran escala en AWS. También es un defensor activo de hardware especializado en aprendizaje automático y soluciones de aprendizaje automático de bajo código.
 Dr. Alejandro Arzhanov es un arquitecto de soluciones especializado en AI/ML con sede en Frankfurt, Alemania. Ayuda a los clientes de AWS a diseñar e implementar sus soluciones de ML en la región EMEA. Antes de unirse a AWS, Alexander estaba investigando los orígenes de los elementos pesados en nuestro universo y se apasionó por ML después de usarlo en sus cálculos científicos a gran escala.
Dr. Alejandro Arzhanov es un arquitecto de soluciones especializado en AI/ML con sede en Frankfurt, Alemania. Ayuda a los clientes de AWS a diseñar e implementar sus soluciones de ML en la región EMEA. Antes de unirse a AWS, Alexander estaba investigando los orígenes de los elementos pesados en nuestro universo y se apasionó por ML después de usarlo en sus cálculos científicos a gran escala.
 olivier cruchant es un arquitecto de soluciones especialista en aprendizaje automático en AWS, con sede en Francia. Olivier ayuda a los clientes de AWS, desde pequeñas empresas emergentes hasta grandes empresas, a desarrollar e implementar aplicaciones de aprendizaje automático de nivel de producción. En su tiempo libre, disfruta leer trabajos de investigación y explorar la naturaleza con amigos y familiares.
olivier cruchant es un arquitecto de soluciones especialista en aprendizaje automático en AWS, con sede en Francia. Olivier ayuda a los clientes de AWS, desde pequeñas empresas emergentes hasta grandes empresas, a desarrollar e implementar aplicaciones de aprendizaje automático de nivel de producción. En su tiempo libre, disfruta leer trabajos de investigación y explorar la naturaleza con amigos y familiares.
 Heiko Hotz es arquitecto sénior de soluciones para inteligencia artificial y aprendizaje automático con un enfoque especial en procesamiento de lenguaje natural (NLP), modelos de lenguaje extenso (LLM) e inteligencia artificial generativa. Antes de ocupar este puesto, fue director de ciencia de datos del servicio de atención al cliente de la UE de Amazon. Heiko ayuda a nuestros clientes a tener éxito en su viaje de IA/ML en AWS y ha trabajado con organizaciones en muchas industrias, incluidas las de seguros, servicios financieros, medios y entretenimiento, atención médica, servicios públicos y fabricación. En su tiempo libre, Heiko viaja tanto como puede.
Heiko Hotz es arquitecto sénior de soluciones para inteligencia artificial y aprendizaje automático con un enfoque especial en procesamiento de lenguaje natural (NLP), modelos de lenguaje extenso (LLM) e inteligencia artificial generativa. Antes de ocupar este puesto, fue director de ciencia de datos del servicio de atención al cliente de la UE de Amazon. Heiko ayuda a nuestros clientes a tener éxito en su viaje de IA/ML en AWS y ha trabajado con organizaciones en muchas industrias, incluidas las de seguros, servicios financieros, medios y entretenimiento, atención médica, servicios públicos y fabricación. En su tiempo libre, Heiko viaja tanto como puede.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/architect-personalized-generative-ai-saas-applications-on-amazon-sagemaker/

