El puesto Archive y purgue datos para Amazon RDS para PostgreSQL y Amazon Aurora con compatibilidad con PostgreSQL mediante pg_partman y Amazon S3 propone el archivo de datos como una parte crítica de la gestión de datos y muestra cómo utilizar eficientemente la partición de rango nativo de PostgreSQL para particionar los datos actuales (calientes) con pg_partman y archivar datos históricos (fríos) en Servicio de almacenamiento simple de Amazon (Amazon S3). Los clientes necesitan una solución automatizada nativa de la nube para archivar datos históricos de sus bases de datos. Los clientes quieren que la lógica empresarial se mantenga y se ejecute desde fuera de la base de datos para reducir la carga informática en el servidor de la base de datos. Esta publicación propone una solución automatizada mediante el uso Pegamento AWS para automatizar el proceso de archivo y restauración de datos de PostgreSQL, agilizando así todo el procedimiento.
AWS Glue es un servicio de integración de datos sin servidor que facilita descubrir, preparar, mover e integrar datos de múltiples fuentes para análisis, aprendizaje automático (ML) y desarrollo de aplicaciones. No es necesario preaprovisionar, configurar ni gestionar la infraestructura. También puede escalar automáticamente los recursos para cumplir con los requisitos de su trabajo de procesamiento de datos, proporcionando un alto nivel de abstracción y conveniencia. AWS Glue se integra perfectamente con servicios de AWS como Amazon S3, Servicio de base de datos relacional de Amazon (Amazon RDS), Desplazamiento al rojo de Amazon, Amazon DynamoDB, Secuencias de datos de Amazon Kinesisy Amazon DocumentDB (con compatibilidad con MongoDB) para ofrecer una solución sólida de integración de datos nativa de la nube.
Las características de AWS Glue, que incluyen un programador para automatizar tareas, generación de código para procesos ETL (extracción, transformación y carga), integración de portátiles para desarrollo y depuración interactivos, así como sólidas medidas de seguridad y cumplimiento, lo convierten en una herramienta conveniente y solución rentable para las necesidades de archivo y restauración.
Resumen de la solución
La solución combina la función de partición de rango nativo de PostgreSQL con pg_partman, las funciones de exportación e importación de Amazon S3 en Amazon RDS y AWS Glue como herramienta de automatización.
La solución implica los siguientes pasos:
- Aprovisione los servicios y flujos de trabajo de AWS necesarios utilizando el software proporcionado. Kit de desarrollo en la nube de AWS (AWS CDK) proyecto.
- Configure su base de datos.
- Archive las particiones de tablas más antiguas en Amazon S3 y elimínelas de la base de datos con AWS Glue.
- Restaure los datos archivados de Amazon S3 en la base de datos con AWS Glue cuando sea necesario recargar las particiones de tablas más antiguas.
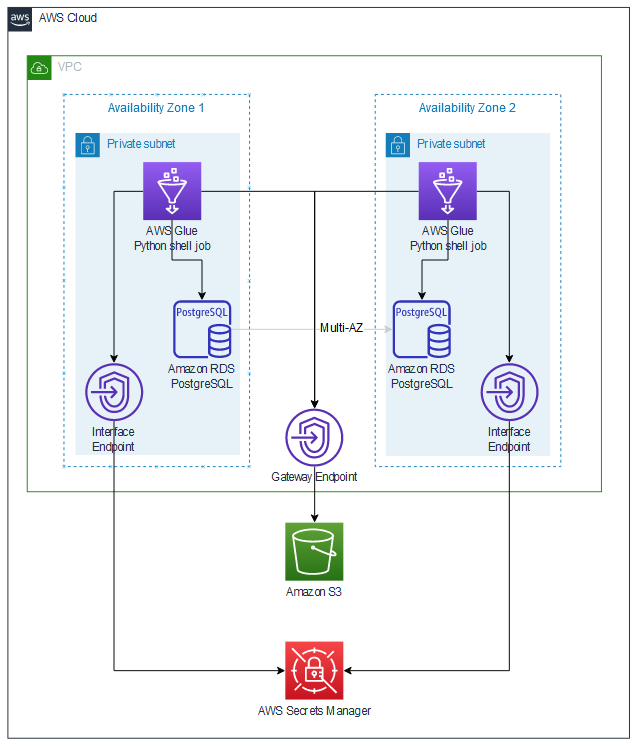
La solución se basa en AWS Glue, que se encarga de archivar y restaurar bases de datos con redundancia de zona de disponibilidad. La solución se compone de los siguientes componentes técnicos:
- An Amazon RDS para PostgreSQL La base de datos Multi-AZ se ejecuta en dos subredes privadas.
- Director de secretos de AWS almacena las credenciales de la base de datos.
- Un depósito de S3 almacena scripts de Python y archivos de bases de datos.
- Un punto de enlace de S3 Gateway permite a Amazon RDS y AWS Glue comunicarse de forma privada con Amazon S3.
- AWS Glue utiliza un punto final de interfaz de Secrets Manager para recuperar secretos de bases de datos de Secrets Manager.
- Los trabajos ETL de AWS Glue se ejecutan en cualquiera de las subredes privadas. Utilizan el punto final S3 para recuperar scripts de Python. Los trabajos de AWS Glue leen las credenciales de la base de datos de Secrets Manager para establecer conexiones JDBC con la base de datos.
Puedes crear un Nube de AWS9 entorno en una de las subredes privadas disponibles en su cuenta de AWS para configurar datos de prueba en Amazon RDS. El siguiente diagrama ilustra la arquitectura de la solución.
Requisitos previos
Para obtener instrucciones sobre cómo configurar su entorno para implementar la solución propuesta en esta publicación, consulte Implementar la aplicación en el repositorio GitHub.
Aprovisione los recursos de AWS necesarios mediante AWS CDK
Complete los siguientes pasos para aprovisionar los recursos de AWS necesarios:
- Clon el repositorio a una nueva carpeta en su escritorio local.
- Crear un entorno virtual y instalar las dependencias del proyecto.
- Despliegue las pilas a su cuenta de AWS.
El proyecto CDK incluye tres pilas: vpcstack, pila de datos y pila de pegamento, implementado en el vpc_stack.py, db_stack.pyy glue_stack.py módulos, respectivamente.
Estas pilas tienen dependencias preconfiguradas para simplificarle el proceso. app.py declara los módulos de Python como un conjunto de pilas anidadas. Pasa una referencia de vpcstack a dbstack y una referencia de vpcstack y dbstack a pegamentostack.
Gluestack lee los siguientes atributos de las pilas principales:
- El depósito S3, la VPC y las subredes de vpcstack
- El secreto, el grupo de seguridad, el punto final de la base de datos y el nombre de la base de datos de dbstack
La implementación de las tres pilas crea los componentes técnicos enumerados anteriormente en esta publicación.
Configura tu base de datos
Prepare la base de datos utilizando la información proporcionada en Complete y configure los datos de prueba en GitHub.
Archive la partición de la tabla histórica en Amazon S3 y elimínela de la base de datos con AWS Glue
El “Mantener y Archivar” Flujo de trabajo de AWS Glue creado en el primer paso consta de dos trabajos: "Mantenimiento de ejecución de parte" y "Archivar mesas frías".
El trabajo “Mantenimiento de ejecución de Partman” ejecuta el procedimiento Partman.run_maintenance_proc() para crear nuevas particiones y separar particiones antiguas según la configuración de retención en el paso anterior para la tabla configurada. El trabajo "Archivar tablas frías" identifica las particiones antiguas separadas y exporta los datos históricos a un destino de Amazon S3 utilizando aws_s3.query_export_to_s3. Al final, el trabajo elimina las particiones archivadas de la base de datos, liberando espacio de almacenamiento. La siguiente captura de pantalla muestra los resultados de ejecutar este flujo de trabajo bajo demanda desde la consola de AWS Glue.
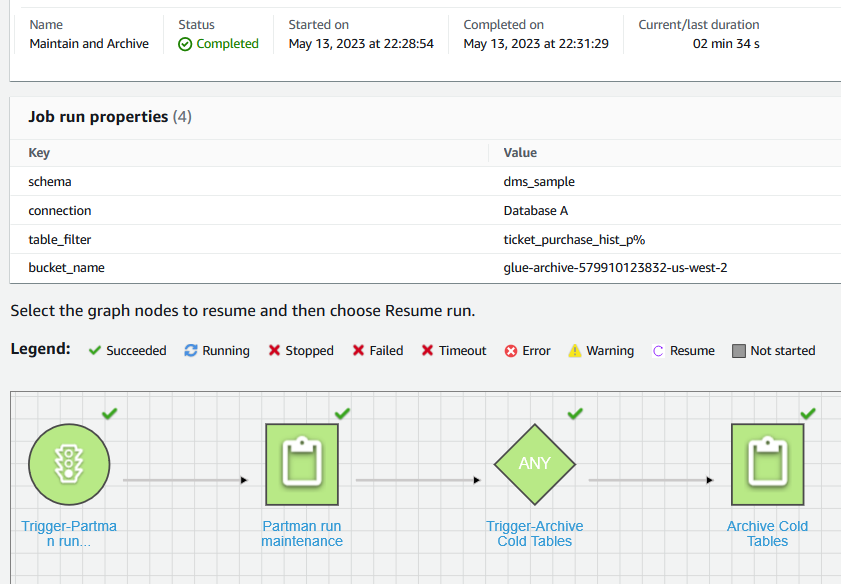
Además, puede configurar este flujo de trabajo de AWS Glue para que se active según una programación, según demanda o con un Puente de eventos de Amazon evento. Debe utilizar los requisitos de su negocio para seleccionar el activador correcto.
Restaurar datos archivados de Amazon S3 a la base de datos
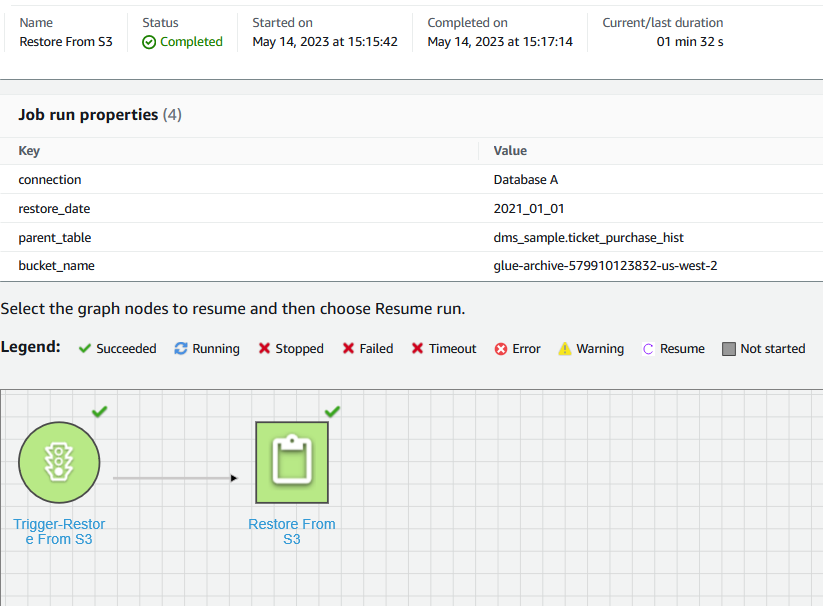
El flujo de trabajo de Glue "Restaurar desde S3" creado en el primer paso consta de un trabajo: "Restaurar desde S3".
Este trabajo inicia la ejecución del procedimiento partman.create_partition_time para crear una nueva partición de tabla basada en el mes especificado. Posteriormente llama aws_s3.table_import_from_s3 para restaurar los datos coincidentes de Amazon S3 en la partición de tabla recién creada.
Para iniciar el flujo de trabajo "Restaurar desde S3", navegue hasta el flujo de trabajo en la consola de AWS Glue y elija Ejecutar.
La siguiente captura de pantalla muestra los detalles de ejecución del flujo de trabajo "Restaurar desde S3".
Validar los resultados
La solución proporcionada en esta publicación automatizó el proceso de restauración y archivo de datos de PostgreSQL mediante AWS Glue.
Puede utilizar los siguientes pasos para confirmar que los datos históricos de la base de datos se archivarán correctamente después de ejecutar el flujo de trabajo "Mantener y archivar" de AWS Glue:
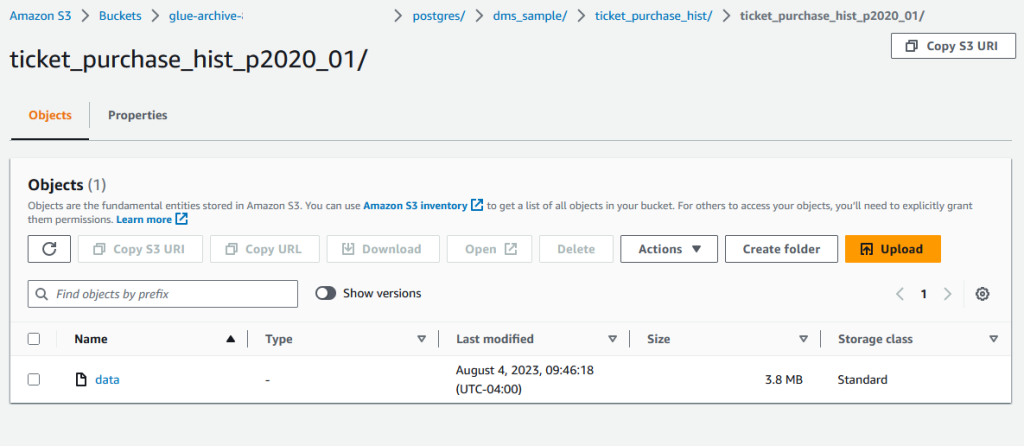
- En la consola de Amazon S3, navegue hasta su depósito S3.
- Confirme que los datos archivados estén almacenados en un objeto S3 como se muestra en la siguiente captura de pantalla.
- Desde un psql herramienta de línea de comando, use el
dtcomando para enumerar las tablas disponibles y confirmar la tabla archivadaticket_purchase_hist_p2020_01no existe en la base de datos.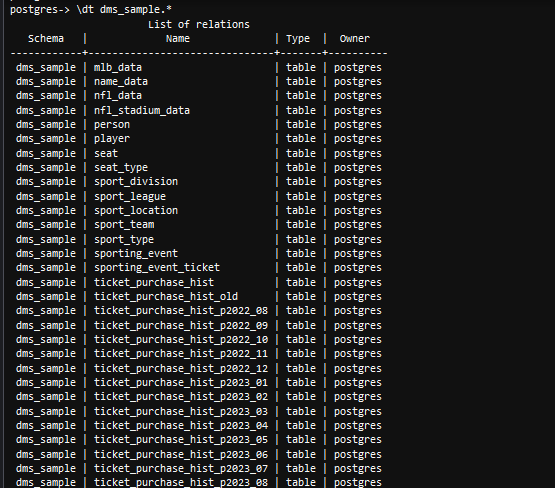
Puede utilizar los siguientes pasos para confirmar que los datos archivados se restauran en la base de datos correctamente después de ejecutar el flujo de trabajo de AWS Glue "Restaurar desde S3".
- Desde una herramienta de línea de comando psql, use el
dtcomando para enumerar las tablas disponibles y confirmar la tabla archivadaticket_history_hist_p2020_01se restaura a la base de datos.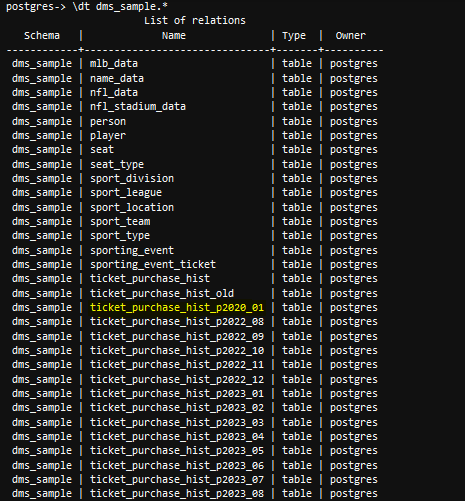
Limpiar
Utilice la información proporcionada en Limpiar para limpiar su entorno de prueba creado para probar la solución propuesta en esta publicación.
Resumen
Esta publicación mostró cómo utilizar los flujos de trabajo de AWS Glue para automatizar el proceso de archivado y restauración en RDS para particiones de tablas de bases de datos PostgreSQL utilizando Amazon S3 como almacenamiento de archivos. La automatización se ejecuta según demanda, pero se puede configurar para que se active según un cronograma recurrente. Le permite definir la secuencia y las dependencias de los trabajos, realizar un seguimiento del progreso de cada trabajo de flujo de trabajo, ver los registros de ejecución y monitorear el estado general y el rendimiento de sus tareas. Aunque utilizamos Amazon RDS para PostgreSQL como ejemplo, la misma solución funciona para Edición compatible con Amazon Aurora-PostgreSQL también. Modernice los trabajos cron de su base de datos con AWS Glue mediante esta publicación y el Repositorio GitHub. Obtenga una comprensión de alto nivel de AWS Glue y sus componentes mediante la siguiente práctica taller.
Acerca de los autores
 Anand Komandooru es arquitecto sénior de la nube en AWS. Se unió a la organización de servicios profesionales de AWS en 2021 y ayuda a los clientes a crear aplicaciones nativas de la nube en la nube de AWS. Tiene más de 20 años de experiencia en la creación de software y su principio de liderazgo favorito de Amazon es "Los líderes tienen mucha razón."
Anand Komandooru es arquitecto sénior de la nube en AWS. Se unió a la organización de servicios profesionales de AWS en 2021 y ayuda a los clientes a crear aplicaciones nativas de la nube en la nube de AWS. Tiene más de 20 años de experiencia en la creación de software y su principio de liderazgo favorito de Amazon es "Los líderes tienen mucha razón."
 Li Liu es un arquitecto senior especializado en bases de datos del equipo de servicios profesionales de Amazon Web Services. Ayuda a los clientes a migrar bases de datos locales tradicionales a la nube de AWS. Se especializa en diseño, arquitectura y ajuste del rendimiento de bases de datos.
Li Liu es un arquitecto senior especializado en bases de datos del equipo de servicios profesionales de Amazon Web Services. Ayuda a los clientes a migrar bases de datos locales tradicionales a la nube de AWS. Se especializa en diseño, arquitectura y ajuste del rendimiento de bases de datos.
 neil potter es arquitecto senior de aplicaciones en la nube en AWS. Trabaja con clientes de AWS para ayudarlos a migrar sus cargas de trabajo a la nube de AWS. Se especializa en modernización de aplicaciones y diseño nativo de la nube y reside en Nueva Jersey.
neil potter es arquitecto senior de aplicaciones en la nube en AWS. Trabaja con clientes de AWS para ayudarlos a migrar sus cargas de trabajo a la nube de AWS. Se especializa en modernización de aplicaciones y diseño nativo de la nube y reside en Nueva Jersey.
 vivek shrivastava es Arquitecto Principal de Datos, Data Lake en Servicios Profesionales de AWS. Es un entusiasta de los big data y posee 14 certificaciones de AWS. Le apasiona ayudar a los clientes a crear soluciones de análisis de datos escalables y de alto rendimiento en la nube. En su tiempo libre le encanta leer y busca espacios para la domótica.
vivek shrivastava es Arquitecto Principal de Datos, Data Lake en Servicios Profesionales de AWS. Es un entusiasta de los big data y posee 14 certificaciones de AWS. Le apasiona ayudar a los clientes a crear soluciones de análisis de datos escalables y de alto rendimiento en la nube. En su tiempo libre le encanta leer y busca espacios para la domótica.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- ChartPrime. Eleve su juego comercial con ChartPrime. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/automate-the-archive-and-purge-data-process-for-amazon-rds-for-postgresql-using-pg_partman-amazon-s3-and-aws-glue/

