Muchas empresas están migrando sus almacenes de datos locales a la nube de AWS. Durante la migración de datos, un requisito clave es validar todos los datos que se han movido del origen al destino. Esta validación de datos es un paso crítico y, si no se realiza correctamente, puede provocar el fracaso de todo el proyecto. Sin embargo, desarrollar soluciones personalizadas para determinar la precisión de la migración comparando los datos entre el origen y el destino a menudo puede llevar mucho tiempo.
En esta publicación, analizamos un proceso paso a paso para validar grandes conjuntos de datos después de la migración utilizando una herramienta basada en configuración que utiliza EMR de Amazon y la biblioteca de código abierto Apache Griffin. Griffin es una solución de calidad de datos de código abierto para big data, que admite tanto el modo por lotes como el de transmisión por secuencias.
En el panorama actual basado en datos, donde las organizaciones manejan petabytes de datos, la necesidad de marcos de validación de datos automatizados se ha vuelto cada vez más crítica. Los procesos de validación manual no sólo consumen mucho tiempo sino que también son propensos a errores, especialmente cuando se trata de grandes volúmenes de datos. Los marcos de validación de datos automatizados ofrecen una solución optimizada al comparar de manera eficiente grandes conjuntos de datos, identificar discrepancias y garantizar la precisión de los datos a escala. Con tales marcos, las organizaciones pueden ahorrar tiempo y recursos valiosos mientras mantienen la confianza en la integridad de sus datos, lo que permite una toma de decisiones informada y mejora la eficiencia operativa general.
Las siguientes son características destacadas de este marco:
- Utiliza un marco basado en la configuración.
- Ofrece funcionalidad plug-and-play para una integración perfecta
- Realiza una comparación de recuentos para identificar cualquier disparidad.
- Implementa procedimientos sólidos de validación de datos.
- Garantiza la calidad de los datos mediante controles sistemáticos.
- Proporciona acceso a un archivo que contiene registros no coincidentes para un análisis en profundidad
- Genera informes completos para obtener información y realizar seguimiento
Resumen de la solución
Esta solución utiliza los siguientes servicios:
- Servicio de almacenamiento simple de Amazon (Amazon S3) o Hadoop Distributed File System (HDFS) como origen y destino.
- EMR de Amazon para ejecutar el script PySpark. Usamos un contenedor de Python sobre Griffin para validar datos entre tablas de Hadoop creadas en HDFS o Amazon S3.
- Pegamento AWS para catalogar la tabla técnica, que almacena los resultados del trabajo de Griffin.
- Atenea amazónica para consultar la tabla de salida para verificar los resultados.
Usamos tablas que almacenan el recuento de cada tabla de origen y de destino y también creamos archivos que muestran la diferencia de registros entre el origen y el destino.
El siguiente diagrama ilustra la arquitectura de la solución.
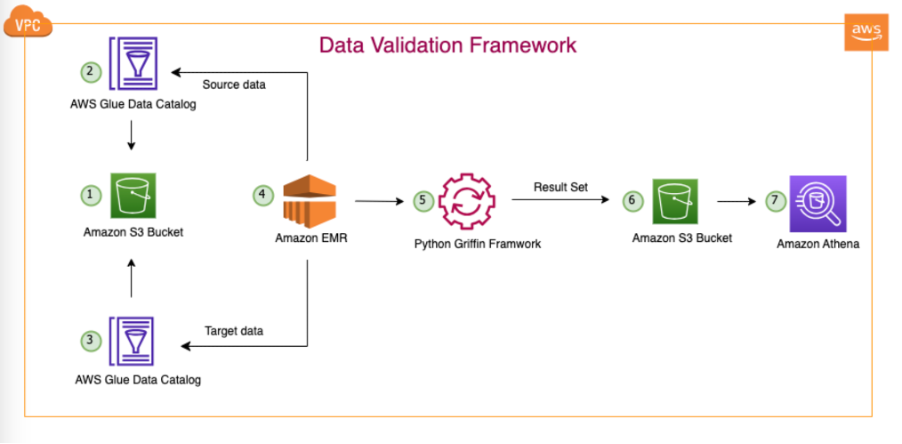
En la arquitectura representada y nuestro caso de uso típico de lago de datos, nuestros datos residen en Amazon S3 o se migran desde las instalaciones a Amazon S3 mediante herramientas de replicación como Sincronización de datos de AWS or Servicio de migración de bases de datos de AWS (AWS DMS). Aunque esta solución está diseñada para interactuar perfectamente con Hive Metastore y AWS Glue Data Catalog, utilizamos el Data Catalog como ejemplo en esta publicación.
Este marco opera dentro de Amazon EMR, ejecutando automáticamente tareas programadas diariamente, según la frecuencia definida. Genera y publica informes en Amazon S3, a los que luego se puede acceder a través de Athena. Una característica notable de este marco es su capacidad para detectar discrepancias en los recuentos y discrepancias en los datos, además de generar un archivo en Amazon S3 que contiene registros completos que no coinciden, lo que facilita un análisis más detallado.
En este ejemplo, utilizamos tres tablas en una base de datos local para validar entre el origen y el destino: balance_sheet, covidy survery_financial_report.
Requisitos previos
Antes de comenzar, asegúrese de tener los siguientes requisitos previos:
Implementar la solución
Para que le resulte sencillo comenzar, hemos creado una plantilla de CloudFormation que configura e implementa automáticamente la solución para usted. Complete los siguientes pasos:
- Cree un depósito S3 en su cuenta de AWS llamado
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}(proporcione su ID de cuenta de AWS y región de AWS). - Descomprime lo siguiente presentar a su sistema local.
- Después de descomprimir el archivo en su sistema local, cambie al que creaste en tu cuenta (
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}) en los siguientes archivos:bootstrap-bdb-3070-datavalidation.shValidation_Metrics_Athena_tables.hqldatavalidation/totalcount/totalcount_input.txtdatavalidation/accuracy/accuracy_input.txt
- Cargue todas las carpetas y archivos en su carpeta local a su depósito S3:
- Ejecutar el siguiente Plantilla de CloudFormation Sin embargo, en circunstancias especiales, como el caso de que un banco rechace tu petición, puedes contactar al soporte técnico de Olymp Trade y hacer que transfieran tus fondos a un método de pago alternativo.
La plantilla de CloudFormation crea una base de datos llamada griffin_datavalidation_blog y un rastreador de AWS Glue llamado griffin_data_validation_blog encima de la carpeta de datos en el archivo .zip.
- Elige Siguiente.
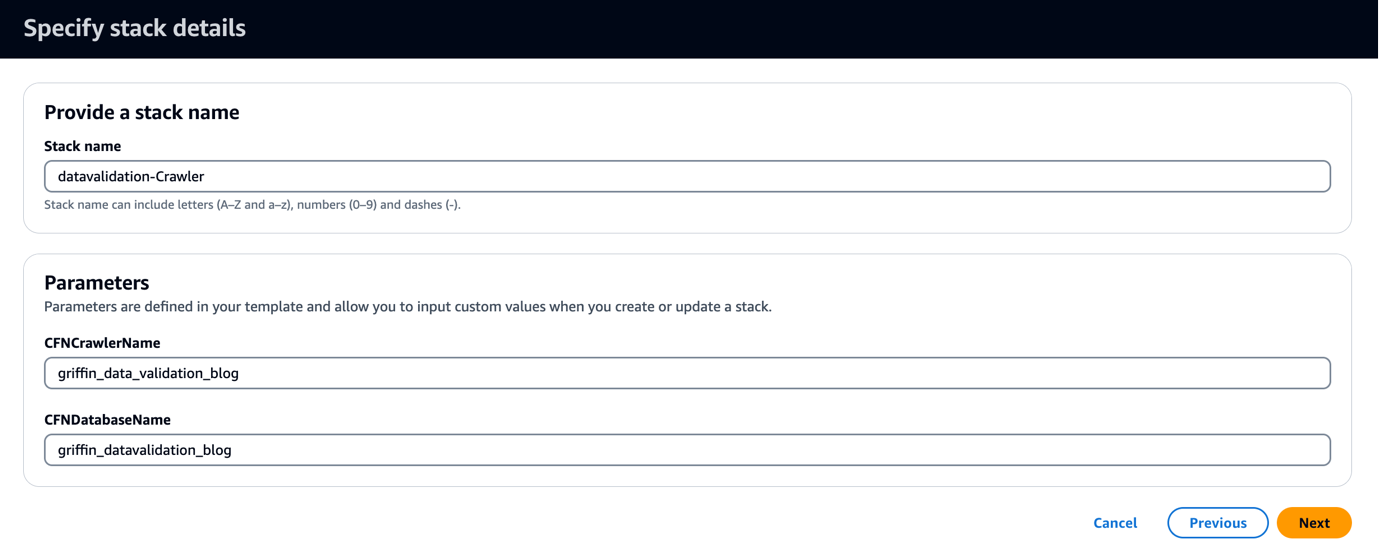
- Elige Siguiente de nuevo.
- En Revisar página, seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM con nombres personalizados.
- Elige Crear pila.
solicite ver las salidas de la pila en Consola de administración de AWS o utilizando el siguiente comando de AWS CLI:
- Ejecute el rastreador de AWS Glue y verifique que se hayan creado seis tablas en el catálogo de datos.
- Ejecutar el siguiente Plantilla de CloudFormation Sin embargo, en circunstancias especiales, como el caso de que un banco rechace tu petición, puedes contactar al soporte técnico de Olymp Trade y hacer que transfieran tus fondos a un método de pago alternativo.
Esta plantilla crea un clúster EMR con un script de arranque para copiar artefactos y JAR relacionados con Griffin. También ejecuta tres pasos de EMR:
- Cree dos tablas de Athena y dos vistas de Athena para ver la matriz de validación producida por el marco Griffin.
- Ejecute la validación del recuento para las tres tablas para comparar la tabla de origen y la de destino.
- Ejecute validaciones a nivel de registro y a nivel de columna para las tres tablas para comparar entre la tabla de origen y la de destino.
- ID de subred, ingrese su ID de subred.
- Elige Siguiente.
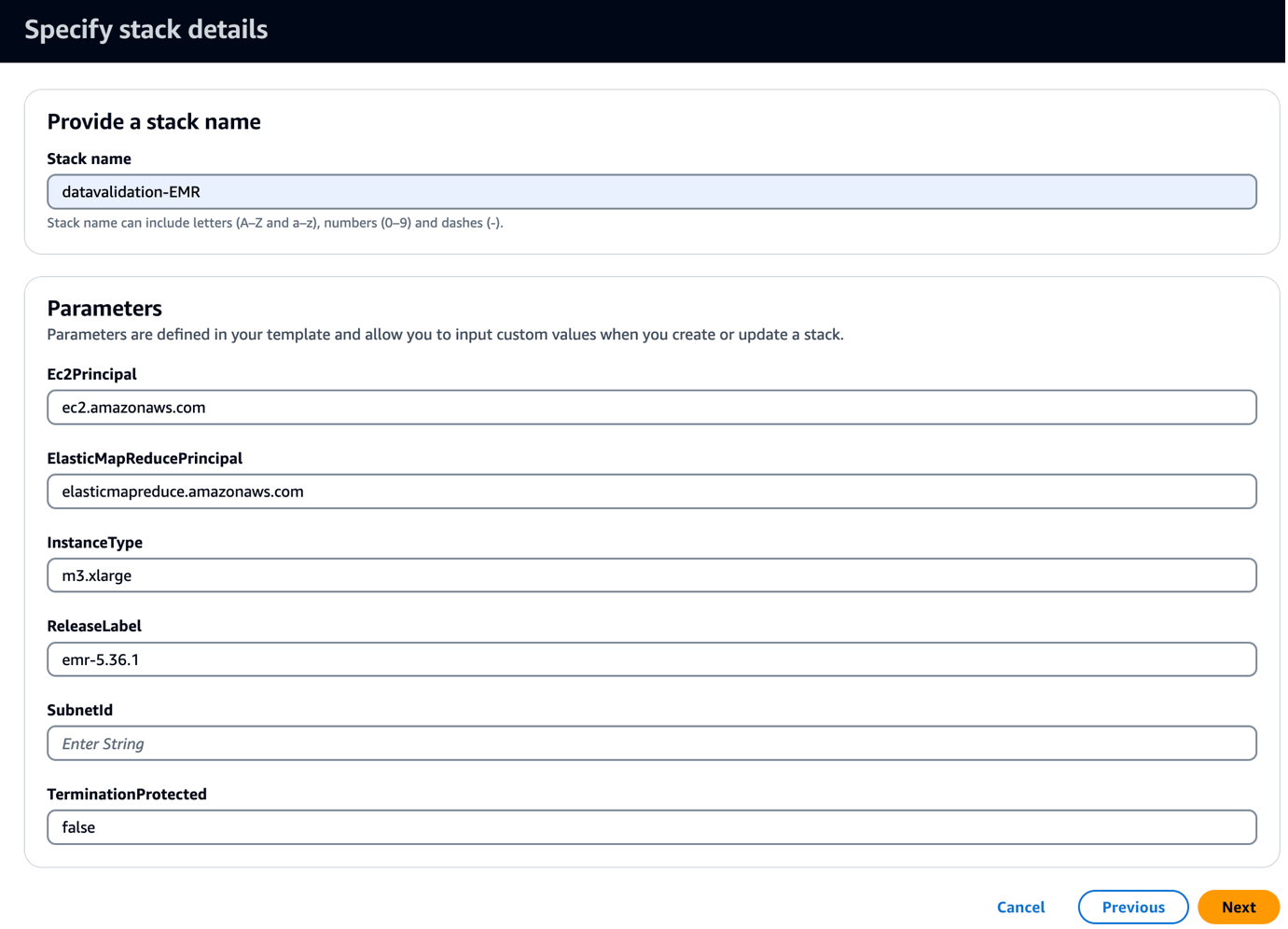
- Elige Siguiente de nuevo.
- En Revisar página, seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM con nombres personalizados.
- Elige Crear pila.
Puede ver los resultados de la pila en la consola o utilizando el siguiente comando de AWS CLI:
La implementación tarda aproximadamente 5 minutos en completarse. Cuando la pila esté completa, deberías ver el EMRCluster recurso lanzado y disponible en su cuenta.
Cuando se inicia el clúster de EMR, ejecuta los siguientes pasos como parte del lanzamiento posterior al clúster:
- Acción de arranque – Instala el archivo Griffin JAR y los directorios para este marco. También descarga archivos de datos de muestra para utilizarlos en el siguiente paso.
- Athena_Table_Creation – Crea tablas en Athena para leer los informes de resultados.
- Conteo_Validación – Ejecuta el trabajo para comparar el recuento de datos entre los datos de origen y de destino de la tabla del catálogo de datos y almacena los resultados en un depósito de S3, que se leerá a través de una tabla de Athena.
- Exactitud – Ejecuta el trabajo para comparar las filas de datos entre los datos de origen y de destino de la tabla del catálogo de datos y almacena los resultados en un depósito de S3, que se leerá a través de la tabla de Athena.
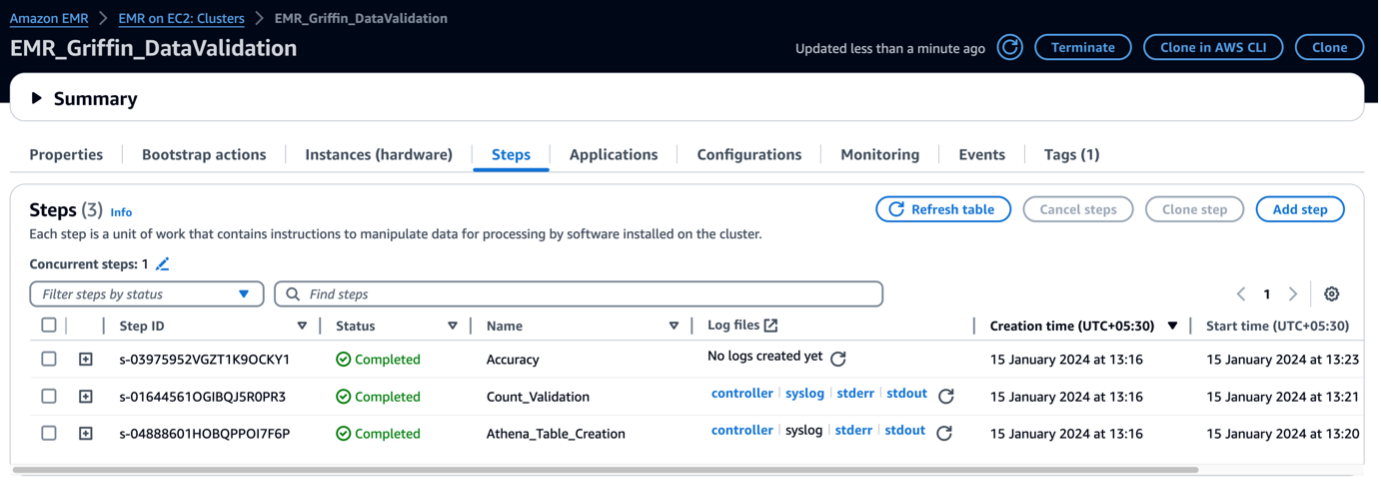
Cuando se completen los pasos de EMR, la comparación de tablas estará lista y lista para ver en Athena automáticamente. No se necesita intervención manual para la validación.
Validar datos con Python Griffin
Cuando su clúster EMR esté listo y todos los trabajos estén completos, significa que la validación del recuento y la validación de datos están completas. Los resultados se almacenaron en Amazon S3 y la tabla de Athena ya está creada encima. Puede consultar las tablas de Athena para ver los resultados, como se muestra en la siguiente captura de pantalla.
La siguiente captura de pantalla muestra los resultados del recuento de todas las tablas.
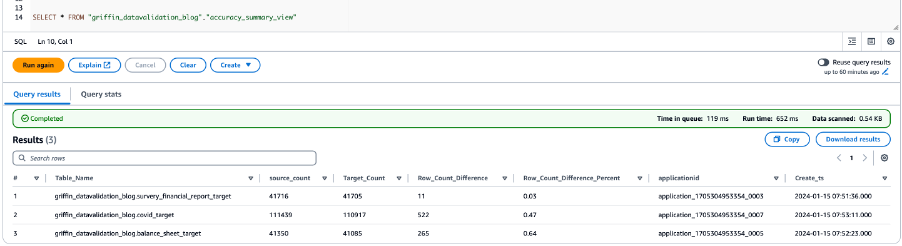
La siguiente captura de pantalla muestra los resultados de precisión de los datos para todas las tablas.
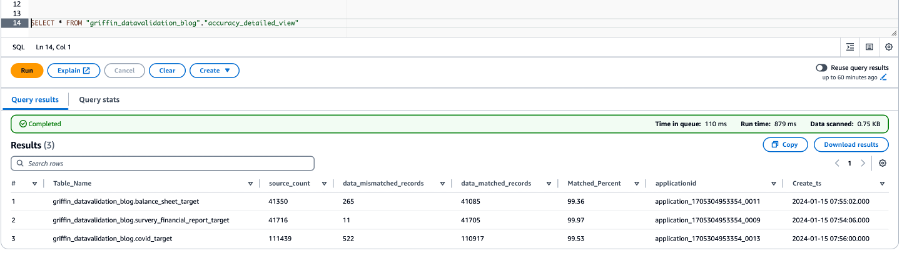
La siguiente captura de pantalla muestra los archivos creados para cada tabla con registros no coincidentes. Se generan carpetas individuales para cada tabla directamente desde el trabajo.
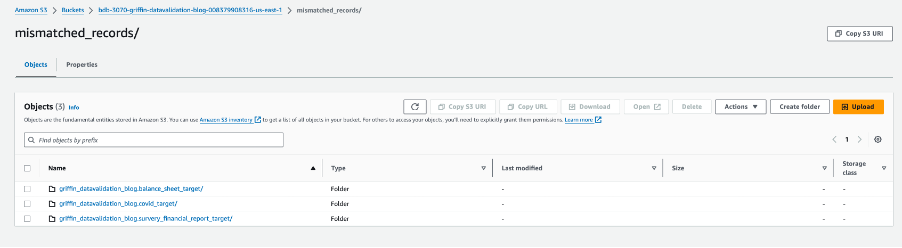
Cada carpeta de tabla contiene un directorio para cada día que se ejecuta el trabajo.
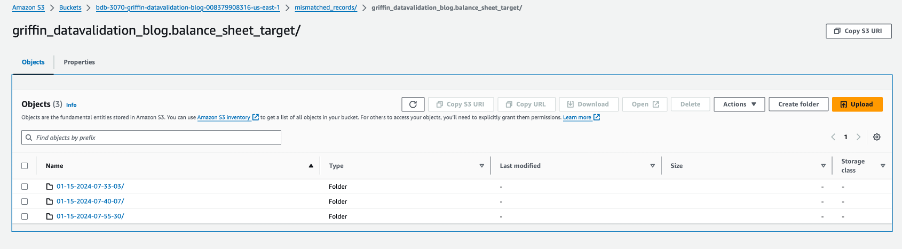
Dentro de esa fecha específica, un archivo llamado __missRecords contiene registros que no coinciden.

La siguiente captura de pantalla muestra el contenido del __missRecords archivo.

Limpiar
Para evitar incurrir en cargos adicionales, complete los siguientes pasos para limpiar sus recursos cuando haya terminado con la solución:
- Eliminar la base de datos de AWS Glue
griffin_datavalidation_blogy soltar la base de datosgriffin_datavalidation_blogcascada. - Elimina los prefijos y objetos que creaste en el depósito.
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}. - Elimine la pila de CloudFormation, que elimina sus recursos adicionales.
Conclusión
Esta publicación mostró cómo puede usar Python Griffin para acelerar el proceso de validación de datos posterior a la migración. Python Griffin le ayuda a calcular el recuento y la validación a nivel de filas y columnas, identificando registros que no coinciden sin escribir ningún código.
Para obtener más información sobre los casos de uso de calidad de datos, consulte Primeros pasos con AWS Glue Data Quality del catálogo de datos de AWS Glue y Calidad de datos de AWS Glue.
Acerca de los autores
 dipal majan Se desempeña como consultor principal en Amazon Web Services y brinda orientación experta a clientes globales en el desarrollo de aplicaciones en la nube altamente seguras, escalables, confiables y rentables. Con una gran experiencia en desarrollo, arquitectura y análisis de software en diversos sectores como finanzas, telecomunicaciones, comercio minorista y atención médica, aporta conocimientos invaluables a su función. Más allá del ámbito profesional, Dipal disfruta explorando nuevos destinos, habiendo visitado ya 14 de los 30 países de su lista de deseos.
dipal majan Se desempeña como consultor principal en Amazon Web Services y brinda orientación experta a clientes globales en el desarrollo de aplicaciones en la nube altamente seguras, escalables, confiables y rentables. Con una gran experiencia en desarrollo, arquitectura y análisis de software en diversos sectores como finanzas, telecomunicaciones, comercio minorista y atención médica, aporta conocimientos invaluables a su función. Más allá del ámbito profesional, Dipal disfruta explorando nuevos destinos, habiendo visitado ya 14 de los 30 países de su lista de deseos.
 Akhil es consultor principal en AWS Professional Services. Ayuda a los clientes a diseñar y crear soluciones de análisis de datos escalables y a migrar canales de datos y almacenes de datos a AWS. En su tiempo libre le encanta viajar, jugar y ver películas.
Akhil es consultor principal en AWS Professional Services. Ayuda a los clientes a diseñar y crear soluciones de análisis de datos escalables y a migrar canales de datos y almacenes de datos a AWS. En su tiempo libre le encanta viajar, jugar y ver películas.
 ramesh raghupatía es Arquitecto de datos sénior con WWCO ProServe en AWS. Trabaja con clientes de AWS para diseñar, implementar y migrar a almacenes de datos y lagos de datos en la nube de AWS. Mientras no está en el trabajo, a Ramesh le gusta viajar, pasar tiempo con la familia y hacer yoga.
ramesh raghupatía es Arquitecto de datos sénior con WWCO ProServe en AWS. Trabaja con clientes de AWS para diseñar, implementar y migrar a almacenes de datos y lagos de datos en la nube de AWS. Mientras no está en el trabajo, a Ramesh le gusta viajar, pasar tiempo con la familia y hacer yoga.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/automate-large-scale-data-validation-using-amazon-emr-and-apache-griffin/

