¿Está buscando extraer datos de los formularios de registro de pacientes? Pruebe el software OCR de Nanonets para extraer campos con más del 98 % de precisión.
La industria de la salud alberga una gran cantidad de datos, la mayoría de los cuales no están estructurados y son complejos. La información de salud personal no se ha utilizado en todo su potencial ya que los datos disponibles están fragmentados y aislados.
Pero si estos datos pudieran extraerse y organizarse correctamente para crear información precisa y confiable que pudiera utilizarse para lograr los objetivos de atención médica de detección temprana, retrasar la progresión y prevención de múltiples enfermedades, reducción de los altos y crecientes costos de atención médica y mejora en la atención de los pacientes. comunicación para brindar una mejor atención al paciente en general.
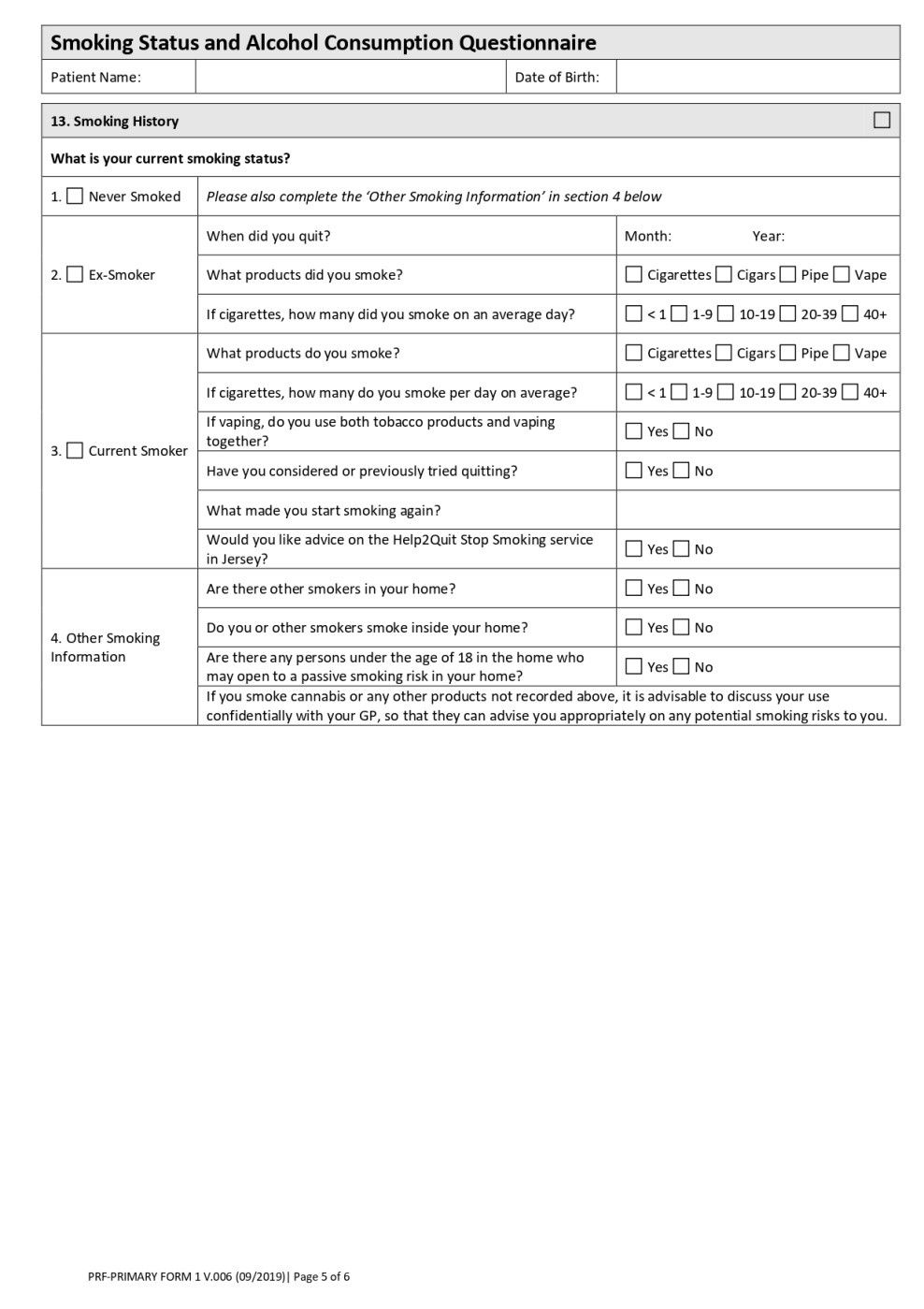
¿Formulario de registro de pacientes y qué contiene?
Un Formulario de Registro de Paciente es un documento que llena un paciente que visita un centro de salud por primera vez. Permite a los proveedores de atención médica recopilar información personal y relacionada con la salud antes de registrarlos para recibir la atención prevista.
El contenido de un formulario de registro de pacientes variará entre las instituciones de atención médica, pero el contenido general será el siguiente.
La primera sección indaga sobre los datos del paciente, incluyendo su nombre, sexo, fecha de nacimiento, dirección, estado civil, información de contacto y Número de Identificación en forma de Número de Identidad Nacional o Número de Pasaporte.
La segunda Sección contiene la información sobre el personal a contactar en caso de emergencia, los familiares o el tutor legal de un menor.
La tercera sección contiene información sobre el plan de seguro del paciente, incluido el nombre de la empresa, el número de seguro y la póliza.
La siguiente sección contiene el formulario de consentimiento del paciente, incluida la declaración del paciente, el acuerdo de confidencialidad y otras condiciones legalmente vinculantes, que deben firmarse con la fecha del paciente.
Además, hay secciones que contienen el historial médico, los medicamentos que toma actualmente el paciente, alergias, antecedentes familiares, antecedentes de abuso de sustancias, etc.

A. Entrada manual de datos
En este método, un operador alimentará manualmente la información en el formulario de registro del paciente a una base de datos. Estos métodos tradicionales de entrada de datos dependen de los factores del operador y tendrán más desventajas que ventajas en comparación con los sistemas automatizados.
Para Agencias y Operadores
El gasto de capital será menor en términos de capacitación e infraestructura del operador, ya que la entrada manual de datos no requiere personal altamente calificado ni software y hardware sofisticados para compilar y presentar los datos.
Desventajas
Dado que los registros de salud son bastante detallados, la extracción de datos lleva horas y podría agregar errores a la información de atención médica durante el tipeo y los cálculos, por la falta de cumplimiento de las pautas y definiciones, y puede resultar en una falta de uniformidad en los datos. Esto podría causar efectos en cascada que resultarían en diagnósticos deficientes, prescripciones erróneas y resultados adversos para los pacientes.
Debido a la complejidad de los datos extraídos, los métodos tradicionales solo utilizan un número limitado de variables recopiladas comúnmente para las predicciones. Esto puede crear falsos positivos y falsas alarmas en los pacientes, lo que podría resultar en alertas fatigadas, y se perderán eventos clínicamente significativos, lo que conducirá a un manejo deficiente del paciente.
B. Registros electrónicos de salud (EHR)
EHR captura un gran volumen de datos, que está fragmentado y aislado en muchas instituciones de atención médica, incluidos hospitales, consultorios médicos generales, laboratorios, farmacias, etc.
Para Agencias y Operadores
EHR ha reducido los errores a nivel de operador en la entrada de datos, los cálculos y el incumplimiento de las pautas y definiciones de datos, lo que reduce los errores médicos. La calidad de la atención brindada al paciente ha mejorado, como lo demuestra un estudio realizado entre médicos de los Estados Unidos en 2011 que muestra que la EHR ha alertado al 65% de posibles errores de medicación y 62% de los valores de laboratorio críticos, lo que mejora la atención general del paciente en un 78 %.
Los costos de atención médica se han reducido a través de diagnósticos adecuados, investigaciones apropiadas y gestión siguiendo predicciones precisas realizadas utilizando EHR y técnicas de aprendizaje profundo.
El uso de EHR permitió el proceso de intercambio de información de salud (HIE), donde la información a nivel de paciente se comparte entre diferentes organizaciones. Esto ha creado un fácil acceso para los médicos a los registros médicos cuando los pacientes buscan asistencia médica de proveedores de atención médica en diferentes lugares.
Desventajas
Diferentes instituciones de salud tienen formatos ligeramente diferentes para presentar datos. Mientras tanto, las pautas difieren y los diagnósticos realizados a través de la Clasificación Internacional de Enfermedades (ICD) pueden agregar errores aleatorios a las predicciones de EHR. Por lo tanto, no tener terminología, arquitectura de sistema e indexación uniformes puede reducir los beneficios esperados de EHR.
EHR está asociado con altos costos de puesta en marcha para el hardware y la capacitación de los operadores, que podrían ser variables debido a las desigualdades de los usuarios en la alfabetización informática y el manejo de la base de datos.
La confidencialidad y la seguridad de la información confidencial de los pacientes están en juego, ya que se recopila una gran cantidad de datos y no se aplican las medidas de seguridad adecuadas.
C. Enfoques híbridos
Dado que la información disponible en EHR está en forma de códigos y estructuras no estándar, la transformación de datos de salud y los enfoques de carga como Dynamic ETL (Extracción, transformación y carga) se han puesto en práctica para reestructurar y transformar los datos de EHR en un formato común. y terminologías estándar para armonizar entre diferentes organizaciones y redes de datos de investigación.
Nanonets es un software OCR basado en IA (queja de GDPR y SOC2) que puede automatizar Procesamiento de documentos con flujos de trabajo sin código.
Nanonets puede automatizar múltiples pasos del procesamiento de documentos de atención médica, incluidos:
carga de documentos, la extracción de datos, proceso de datos (limpieza de datos, formateo, conversión), aprobaciones y archivo de documentos.
Nanonets se adhiere a sus requisitos específicos y, al ser una plataforma completamente sin código, puede ser utilizada por cualquier persona de la organización.
Veamos cómo puede usarlo para extraer datos de los formularios de registro médico.
Primero, para usarlo, crea una cuenta gratis en Nanonets o inicie sesión en su cuenta.
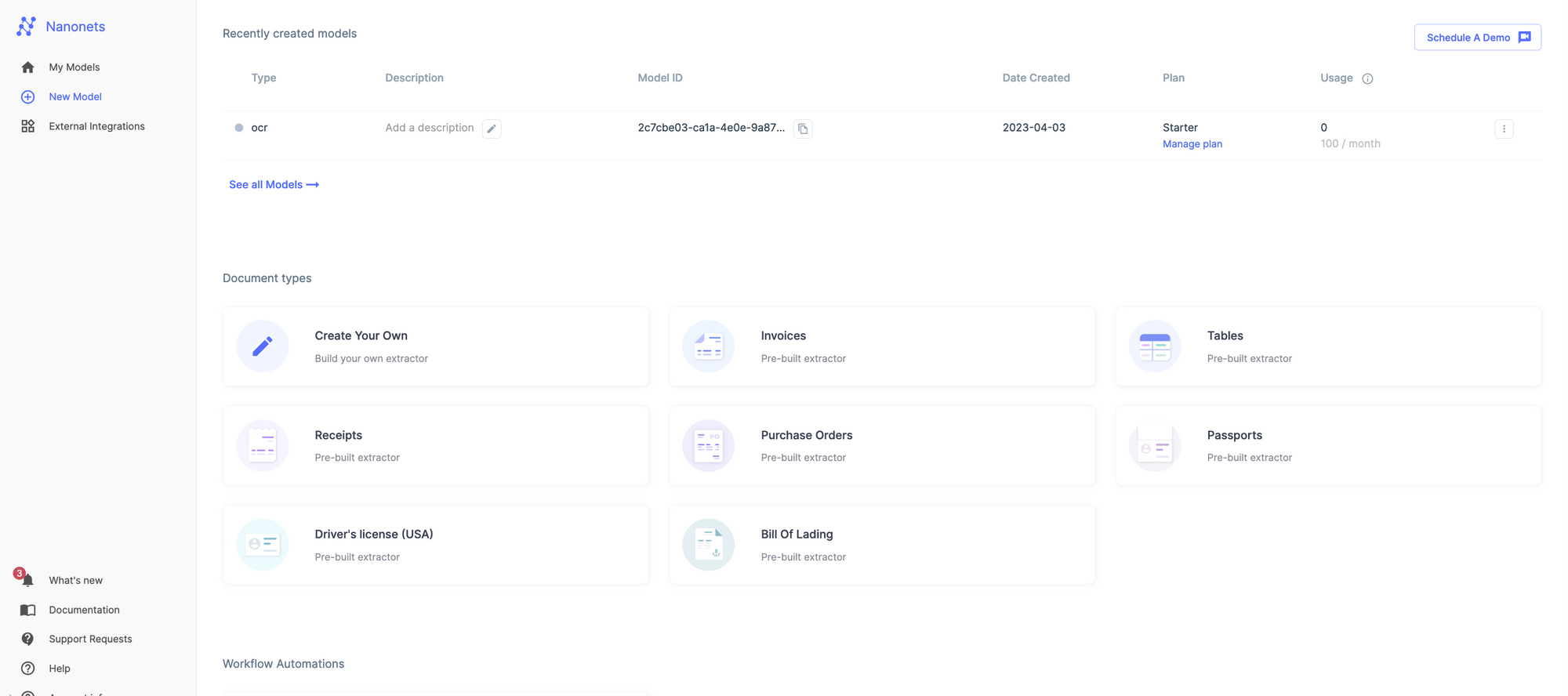
Seleccione un modelo de OCR personalizado. Para entrenar a este modelo, tendrás que proporcionar diez informes médicos.
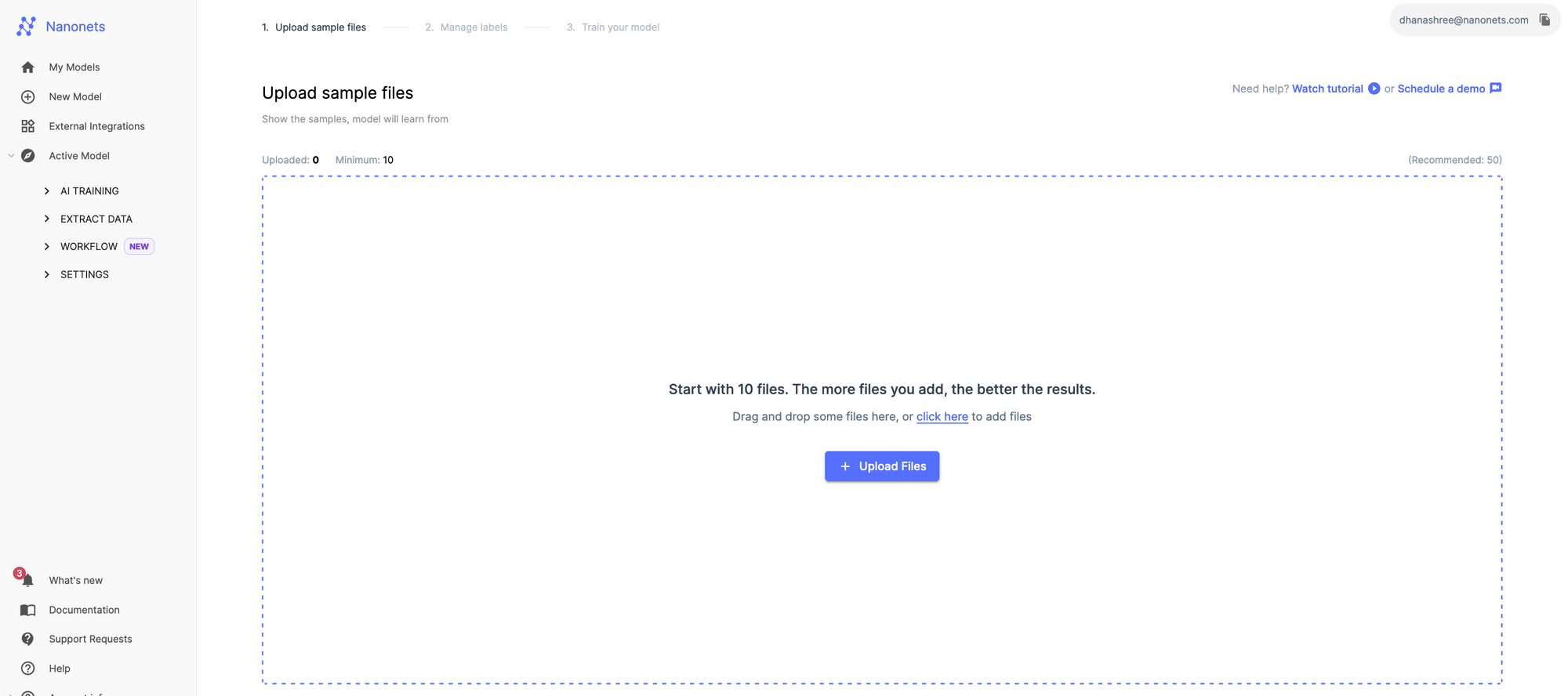
¿Por qué necesito hacer esto? Proporcionar diez documentos médicos lo ayudará a entrenar a la IA para que reconozca su documento de manera eficiente.
Una vez capacitado, ahora puede configurar reglas para formatear sus datos. Puede cambiar la cantidad de ceros o buscar el valor en la base de datos y más con estas reglas sin código.

El siguiente paso es exportar y seleccionar la forma en que desea exportar los datos de sus informes médicos. Explore las opciones o seleccione una integración y conéctela directamente a su sistema EHR de atención médica.
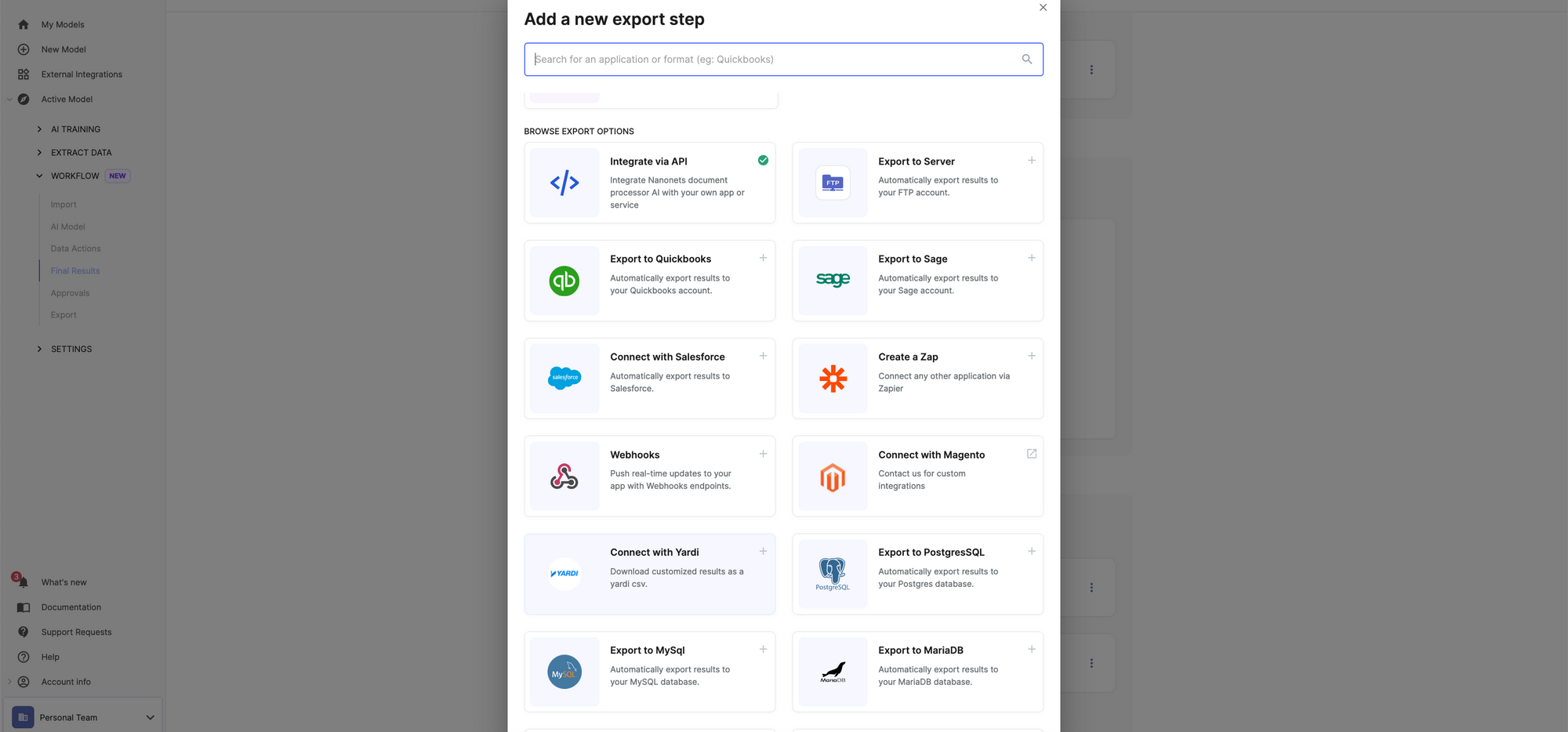
¿Necesitas hacer más? Programe una llamada con nuestros expertos en inteligencia artificial donde puede explicarnos su caso de uso y configuraremos flujos de trabajo para usted.
¿Por qué Nanonets?
Nanonets es una plataforma OCR inteligente. No necesita una plantilla para identificar el texto de los formularios de registro de pacientes. Puede identificar fácilmente el texto de un documento no reconocido.
Es fácil de usar, se puede configurar en 1 día y garantiza una precisión superior al 99 % durante la extracción de datos.
Pero además de las funciones regulares de OCR, esto es lo que diferencia a Nanonets:
Procesamiento de imágenes sin igual
Los formularios de registro de pacientes pueden tener diferentes formatos para diferentes instituciones de salud. Las nanoredes pueden manejar la extracción de datos de cualquier documento o imagen, lo que no es perfecto para empezar. Con procesamiento previo y posterior avanzado, la plataforma puede enderezar, reorientar, rotar, recortar y realizar coincidencias aproximadas, para que obtenga los datos exactos de sus formularios de registro en todo momento.

El mejor OCR de su clase
Nanonets puede extraer datos de su documento médico con más del 98% de precisión. Puede detectar más de 40 idiomas y es compatible con OCR personalizado.
Potentes integraciones
Puede automatizar fácilmente la entrada de datos en sus sistemas con Nanonets. Escanee sus documentos y actualice los perfiles de los pacientes en más de 500 software empresarial en tiempo real con las integraciones de Nanonets.
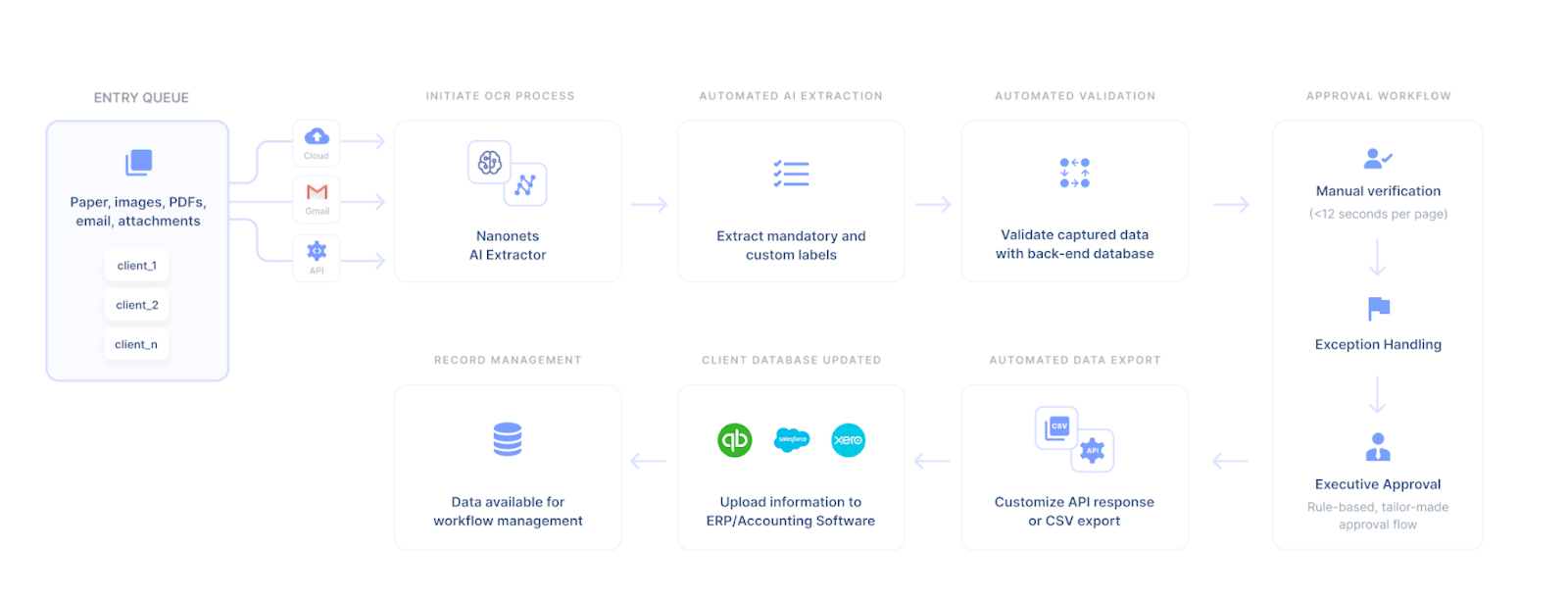
Flujos de trabajo personalizables automatizados
Automatice la selección de documentos, la incorporación de pacientes, el formato de datos, el enriquecimiento de datos, la recopilación de informes médicos, la sincronización de datos, la coincidencia de documentos y más con flujos de trabajo sin código. Simplemente ingrese sus reglas y configúrelo en modo de piloto automático.
Y más. Nanonets se puede personalizar según sus necesidades y ofrece software OCR de marca blanca y opciones de alojamiento en las instalaciones o en la nube.
¿Necesitas extraer datos de formularios de registro de pacientes?
Si es así, dirígete a las nanoredes or programe una llamada con nuestro equipo.
Tecnología
Los sistemas de gestión de información de salud que utilizan EHR requieren conexiones de red costosas con acceso a Internet confiable y de alta velocidad, hardware y software. Debido a los altos costos de puesta en marcha y la falta de disponibilidad de tecnología asequible y efectiva, la implementación de métodos basados en inteligencia artificial para la extracción automatizada de datos solo será un programa consistente en algunas organizaciones.
Propiedad de los datos
Con las relaciones competitivas existentes entre los proveedores de atención médica, surgen problemas con respecto al tipo y la cantidad de información que se intercambia. Los proveedores de tecnología limitan la información patentada que se comparte sobre una base de 'solo lectura'. Por lo tanto, la información actualizada no estará disponible.
Preocupaciones de privacidad de los pacientes
Dado que se trata información de salud personal, el intercambio de información entre organizaciones solo se realiza para el cuidado del paciente respetando las leyes de privacidad. Se asocian responsabilidades legales para evitar la divulgación ilícita de información; por lo tanto, el riesgo de daño en el intercambio de datos siempre debe ser mayor que las posibles recompensas.
A. Precisión de datos mejorada
En lugar de métodos de entrada de datos tradicionales lentos y propensos a errores que desperdician el valioso talento de los empleados, la extracción de datos automatizada garantiza una mayor precisión con el uso repetido.
A medida que la extracción de datos de EHR y los textos libres se incorporan a las técnicas de aprendizaje profundo, se realizan predicciones válidas y precisas sobre dominios de atención médica divergentes con respecto a la calidad y los resultados de la atención y la utilización de los recursos. La información confiable y precisa ayudará en los diagnósticos correctos y el manejo adecuado, mejorando los resultados del paciente.
B. Mayor eficiencia
Los sistemas automatizados reunirán la información de salud personal fragmentada y aislada, que aún no se ha utilizado en todo su potencial, en una forma estructurada que mejore la eficacia y la eficiencia de la atención brindada.
Un estudio realizado en 2016 reveló que los analistas de datos dedican solo el 20% de sus horas de trabajo al análisis de datos, mientras que el resto del tiempo se dedica a recopilar y extraer los datos. La extracción de datos automatizada reduce la mano de obra y el tiempo perdido en la extracción manual de datos propensos a errores y los orienta para mejorar la atención al paciente.
C. Mejora de la atención al paciente
Las personas accederán a los centros de salud desde diferentes lugares. Por lo tanto, un sistema interconectado y automatizado brindará a los proveedores de atención médica una imagen clara de la condición del paciente y se podrá ofrecer un manejo consistente y efectivo. Entre el 30 y el 50 % de los médicos de los Estados Unidos informaron que los sistemas electrónicos son beneficiosos para brindar la atención recomendada y las investigaciones adecuadas y permiten una buena comunicación con el paciente a través de una mejor atención general al paciente en el 78 % de una población de estudio.
D. Costos reducidos
Dado que los registros de los pacientes brindan una multitud de datos en diferentes dominios, la entrada manual de datos requerirá mucho tiempo y será costosa, con un resultado erróneo poco valorado. Aunque la extracción automatizada de datos tiene un alto costo inicial, a largo plazo, la reducción de costos podría lograrse cuando las actividades repetitivas regulares que consumen trabajo humano pudieran automatizarse para obtener datos y predicciones estructurados y precisos.
A diferencia de la recopilación de datos aislada, la extracción y compilación de datos automatizada proporcionará bases de datos de información de salud personal controladas centralmente que podrían usarse entre muchos proveedores de atención médica, lo que reducirá los costos de duplicación de datos.
E. Flujo de trabajo y toma de decisiones simplificados
El EHR basado en Fast Healthcare Interoperability Resources (FHIR) y los métodos de aprendizaje profundo pueden proporcionar predicciones precisas sobre eventos médicos en múltiples centros. Se realizan predicciones sobre tasas de mortalidad, reingresos, tiempo de estancia hospitalaria, etc. que ayudarán a gestionar los recursos disponibles para atender la demanda. Los datos no estructurados o semiestructurados extraídos de un formulario de registro de pacientes podrían utilizarse para identificar los efectos y las deficiencias de los tratamientos y las comorbilidades y para determinar el resultado esperado en el paciente con una afección particular.
Referencias:
- Choi, E., Schuetz, A., Stewart, WF y Sun, J. (2016). Uso de modelos de redes neuronales recurrentes para la detección temprana de la aparición de insuficiencia cardíaca. Revista de la Asociación Estadounidense de Informática Médica, 24(2), 361-370. Enlace: https://doi.org/10.1093/jamia/ocw112
- Jones, SS, Rudin, RS, Perry, T. y Shekelle, PG (2012). Tecnología de la información de salud: una revisión sistemática actualizada con un enfoque en el uso significativo. Anales de Medicina Interna, 156(1), 48-54. Enlace: https://doi.org/10.7326/0003-4819-156-1-201201030-00007
- Kharrazi, H., Anzaldi, LJ, Hernández, L., Davison, A., Boyd, CM y Leff, B. (2018). Un estado de la ciencia de la aplicación de tecnologías de salud digital para el manejo de condiciones crónicas. JMIR mHealth y uHealth, 6(4), e107. Enlace: https://doi.org/10.2196/mhealth.8474
- King, J., Patel, V., Jamoom, EW y Furukawa, MF (2014). Beneficios clínicos del uso de registros de salud electrónicos: hallazgos nacionales. Investigación de Servicios de Salud, 49(1 Pt 2), 392-404. Enlace: https://doi.org/10.1111/1475-6773.12135
- Rajkomar, A., Oren, E., Chen, K., Dai, AM, Hajaj, N., Hardt, M., … & Sundberg, P. (2018). Aprendizaje profundo escalable y preciso con registros de salud electrónicos. Medicina digital NPJ, 1(1), 1-10. Enlace: https://doi.org/10.1038/s41746-018-0029-1
- Savova, GK, Masanz, JJ, Ogren, PV, Zheng, J., Sohn, S., Kipper-Schuler, KC y Chute, CG (2010). Mayo Clinical Text Analysis and Knowledge Extraction System (cTAKES): arquitectura, evaluación de componentes y aplicaciones. Revista de la Asociación Estadounidense de Informática Médica, 17(5), 507-513. Enlace: https://doi.org/10.1136/jamia.2009.001560
- Terry, NP (2012). Proteger la privacidad del paciente en la era de Big Data. UMKC Law Review, 81, 385. Enlace: https://ssrn.com/abstract=2108079
- Chaleco, JR y Gamm, LD (2011). Intercambio de información en salud: desafíos persistentes y nuevas estrategias. Revista de la Asociación Estadounidense de Informática Médica, 17(3), 288-294. Enlace: https://doi.org/10.1136/jamia.2010.003673
- Ong, TC, Kahn, MG, Kwan, BM, Yamashita, T., Brandt, E., Hosokawa, P., Uhrich, C. y Schilling, LM (2017). Dynamic-ETL: un enfoque híbrido para la extracción, transformación y carga de datos de salud. BMC Informática Médica y Toma de Decisiones, 17(1). https://doi.org/10.1186/s12911-017-0532-3
- Joseph, N., Lindblad, I., Zaker, S., Elfversson, S., Albinzon, M., Ødegård, Ø., Hantler, L. y Hellström, PM (2022). Extracción automatizada de datos de registros médicos electrónicos: validez de la extracción de datos para construir bases de datos de investigación para la elegibilidad en ensayos clínicos gastroenterológicos. Upsala Revista de Ciencias Médicas, 127. https://doi.org/10.48101/ujms.v127.8260
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://nanonets.com/blog/automate-data-extraction-from-patient-registration-forms/

