El backtesting es un proceso utilizado en finanzas cuantitativas para evaluar estrategias comerciales utilizando datos históricos. Esto ayuda a los operadores a determinar la rentabilidad potencial de una estrategia e identificar los riesgos asociados con ella, lo que les permite optimizarla para un mejor rendimiento.
Arbitraje de reequilibrio de índices aprovecha las discrepancias de precios a corto plazo que resultan de los esfuerzos de los administradores de ETF para minimizar el error de seguimiento del índice. Los principales índices de mercado, como S&P 500, están sujetos a inclusiones y exclusiones periódicas por razones que van más allá del alcance de esta publicación (por ejemplo, consulte CoStar Group, Invitation Homes listos para unirse al S&P 500; Otros se unirán a S&P 100, S&P MidCap 400 y S&P SmallCap 600). El comercio de arbitraje busca obtener ganancias de las acciones añadidas a un índice y de las que se eliminan, con el objetivo de generar ganancias a partir de estas diferencias de precios.
En esta publicación, analizamos el proceso de uso de backtesting para evaluar el rendimiento de una estrategia de rentabilidad de arbitraje de índices. Exploramos específicamente cómo EMR de Amazon y el recién desarrollado Ramificación y etiquetado de Apache Iceberg La característica puede abordar el desafío del sesgo de anticipación en las pruebas retrospectivas. Esto permitirá una evaluación más precisa del desempeño de la estrategia de rentabilidad del arbitraje de índices.
Terminología
Primero analicemos algunos de los términos utilizados en esta publicación:
- Lago de datos de investigación en Amazon S3 - Un datos es un gran repositorio centralizado que le permite administrar todos sus datos estructurados y no estructurados a cualquier escala. Servicio de almacenamiento simple de Amazon (Amazon S3) es un popular servicio de almacenamiento de objetos basado en la nube que se puede utilizar como base para crear un lago de datos.
- iceberg apache – iceberg apache es un formato de tabla de código abierto que está diseñado para proporcionar acceso eficiente, escalable y seguro a grandes conjuntos de datos. Proporciona funciones como transacciones ACID además de lagos de datos basados en Amazon S3, evolución de esquemas, evolución de particiones y control de versiones de datos. Con la indexación de metadatos escalable, Apache Iceberg puede entregar consultas de alto rendimiento a una variedad de motores como Spark y Athena al reducir el tiempo de planificación.
- Mira–sesgo por delante – Este es un desafío común en las pruebas retrospectivas, que ocurre cuando la información futura se incluye inadvertidamente en los datos históricos utilizados para probar una estrategia comercial, lo que lleva a resultados demasiado optimistas.
- Etiquetas de iceberg – El iceberg función de ramificación y etiquetado permite a los usuarios etiquetar instantáneas específicas de sus tablas de datos con etiquetas significativas utilizando la sintaxis SQL o la biblioteca Iceberg, que corresponden a eventos específicos notables para los equipos de inversión internos. Esto, combinado con El viaje en el tiempo de Iceberg garantiza que los datos precisos entren en la tubería de investigación y los protege de problemas difíciles de detectar, como el sesgo de anticipación.
Alcance de prueba
Para nuestros propósitos de prueba, considere lo siguiente ejemplo, en el que se anuncia un cambio en los índices S&P Dow Jones el 2 de septiembre de 2022, entra en vigencia el 19 de septiembre de 2022 y no se vuelve observable en los datos de tenencias de ETF que usaremos en el experimento hasta el 30 de septiembre. 2022. Usamos etiquetas Iceberg para etiquetar instantáneas de datos de mercado para evitar el sesgo de anticipación en el lago de datos de investigación, lo que nos permitirá probar varios escenarios de entrada y salida comercial y evaluar la rentabilidad respectiva de cada uno.
Experimento
Como parte de nuestro experimento, utilizamos un proveedor de datos externo pagado API identificar ETF ESPÍA cambios de tenencias y construir una cartera. Nuestra cartera modelo comprará acciones que se agreguen al índice, lo que se conoce como ir en largo, y venderá una cantidad equivalente de acciones eliminadas del índice, lo que se conoce como quedando corto.
Probaremos períodos de tenencia a corto plazo, como 1 día y 1, 2, 3 o 4 semanas, porque asumimos que el efecto de reequilibrio es de muy corta duración y la nueva información, como la macroeconomía, impulsará el rendimiento más allá del estudiado. horizontes de tiempo. Por último, simulamos diferentes puntos de entrada para este comercio:
- Mercado abierto el día siguiente al día del anuncio (AD+1)
- Cierre del mercado de la fecha efectiva (ED0)
- Mercado abierto el día después de que las tenencias de ETF registraran el cambio (MD+1)
Lago de datos de investigación
Para ejecutar nuestro experimento, hemos utilizado el siguiente entorno de lago de datos de investigación.

Como se muestra en el diagrama de la arquitectura, el lago de datos de investigación se basa en Amazon S3 y se administra mediante Apache Iceberg, que es un formato de tabla abierta que aporta la confiabilidad y la simplicidad de las tablas del servicio de administración de bases de datos relacionales (RDBMS) a los lagos de datos. Para evitar el sesgo de anticipación en las pruebas retrospectivas, es esencial crear instantáneas de los datos en diferentes momentos. Sin embargo, administrar y organizar estas instantáneas puede ser un desafío, especialmente cuando se trata de un gran volumen de datos.
Aquí es donde la función de etiquetado en Apache Iceberg resulta útil. Con el etiquetado, los investigadores pueden crear instantáneas de datos de mercado con nombres diferentes y realizar un seguimiento de los cambios a lo largo del tiempo. Por ejemplo, pueden crear una instantánea de los datos al final de cada día de negociación y etiquetarla con la fecha y cualquier condición de mercado relevante.
Mediante el uso de etiquetas para organizar las instantáneas, los investigadores pueden consultar y analizar fácilmente los datos en función de condiciones o eventos específicos del mercado, sin tener que preocuparse por las fechas específicas de los datos. Esto puede ser particularmente útil cuando se realizan investigaciones que no son sensibles al tiempo o cuando se buscan tendencias durante largos períodos de tiempo.
Además, la función de etiquetado también puede ayudar con otros aspectos de la gestión de datos, como la retención de datos para el cumplimiento de GDPR y el mantenimiento de linajes de la tabla a través de diferentes ramas. Los investigadores pueden utilizar el etiquetado de Apache Iceberg para garantizar la integridad y precisión de sus datos y, al mismo tiempo, simplificar la gestión de datos.
Requisitos previos
Para seguir este tutorial, debe tener lo siguiente:
- An Cuenta de AWS con un rol de IAM que tenga suficiente acceso para aprovisionar los recursos necesarios.
- Para cumplir con las consideraciones de licencia, no podemos proporcionar una muestra de los datos de los constituyentes de ETF. Por lo tanto, se debe comprar por separado para fines de incorporación del conjunto de datos.
Resumen de la solución
Para configurar y probar este experimento, completamos los siguientes pasos de alto nivel:
- Cree un depósito de S3.
- Cargue el conjunto de datos en Amazon S3. Para esta publicación, los datos de ETF a los que se hace referencia se obtuvieron a través de una llamada API a través de un proveedor externo, pero también puede considerar las siguientes opciones:
- Puedes usar lo siguiente orientación prescriptiva, que describe cómo automatizar la ingesta de datos de varios proveedores de datos en un lago de datos en Amazon S3 mediante Intercambio de datos de AWS.
- También puede utilizar AWS Data Exchange para seleccionar entre una gama de proveedores de conjuntos de datos de terceros. Simplifica el uso de archivos de datos, tablas y API para sus necesidades específicas.
- Por último, también puede consultar la siguiente publicación sobre cómo usar AWS Data Exchange para Amazon S3 para acceder a los datos de un depósito de proveedor: Análisis del impacto de la reforma regulatoria en el mercado de valores utilizando datos de AWS y Refinitiv.
- Cree un clúster de EMR. Puedes usar esto Tutorial de introducción a EMR o usamos CDK para implementar un EMR en un entorno EKS con un extremo administrado personalizado.
- Cree un cuaderno EMR con EMR Studio. Para nuestro entorno de prueba, utilizamos una imagen de Docker de compilación personalizada, que contiene Iceberg v1.3. Para obtener instrucciones sobre cómo adjuntar un clúster a un espacio de trabajo, consulte Asociar un clúster a un espacio de trabajo.
- Configure una sesión de Spark. Puedes seguirlo a través de lo siguiente cuaderno de muestra.
- Cree una tabla Iceberg y cargue los datos de prueba de Amazon S3 en la tabla.
- Etiquete estos datos para conservar una instantánea de ellos.
- Realice actualizaciones de nuestros datos de prueba y etiquete el conjunto de datos actualizado.
- Ejecute backtesting simulado en nuestros datos de prueba para encontrar el punto de entrada más rentable para una operación.
Crear el entorno del experimento.
Podemos ponernos en marcha con Iceberg creando una tabla a través de Spark SQL desde una vista existente, como se muestra en el siguiente código:
Ahora que hemos creado una tabla Iceberg, podemos usarla para la investigación de inversiones. Una de las características clave de Iceberg es su compatibilidad con el control de versiones de datos escalable. Esto significa que podemos rastrear fácilmente los cambios en nuestros datos y retroceder a versiones anteriores sin hacer copias adicionales. Debido a que estos datos se actualizan periódicamente, queremos poder crear instantáneas con nombre de los datos para que los comerciantes cuantitativos tengan fácil acceso a instantáneas consistentes de datos que tienen su propia política de retención. En este caso, etiquetemos el conjunto de datos para indicar que representa los datos de existencias de ETF a partir del primer trimestre de 1:
A medida que avanzamos en el tiempo y los nuevos datos están disponibles para el tercer trimestre, es posible que debamos actualizar los conjuntos de datos existentes para reflejar estos cambios. En el siguiente ejemplo, primero usamos una instrucción UPDATE para marcar las acciones como vencidas en el conjunto de datos de existencias de ETF existente. Luego usamos la declaración MERGE INTO basada en condiciones coincidentes, como el código ISIN. Si no se encuentra una coincidencia entre el conjunto de datos existente y el nuevo conjunto de datos, los nuevos datos se insertarán como nuevos registros en la tabla y el código de estado se establecerá en 'nuevo' para estos registros. De manera similar, si el conjunto de datos existente tiene existencias que no están presentes en el nuevo conjunto de datos, esos registros permanecerán vencidos con un código de estado de 'caducado'. Finalmente, para los registros en los que se encuentra una coincidencia, los datos del conjunto de datos existente se actualizarán con los datos del nuevo conjunto de datos y el registro tendrá un código de estado sin cambios. Con el soporte de Iceberg para el control de versiones de datos eficiente y la consistencia transaccional, podemos estar seguros de que nuestras actualizaciones de datos se aplicarán correctamente y sin corrupción de datos.
Debido a que ahora tenemos una nueva versión de los datos, usamos el etiquetado Iceberg para proporcionar aislamiento para cada nueva versión de los datos. En este caso, lo etiquetamos como Q3_2022 y permitir que los comerciantes cuantitativos y otros usuarios trabajen en esta instantánea de los datos sin verse afectados por las actualizaciones continuas de la canalización:
Esto hace que sea muy fácil ver qué acciones se están agregando y eliminando. Podemos usar la función de viaje en el tiempo de Iceberg para leer los datos en una etiqueta trimestral determinada. Primero, veamos qué acciones se agregan al índice; estas son las filas que están en la instantánea del tercer trimestre pero no en la instantánea del primer trimestre. Luego veremos qué acciones se eliminan; estas son las filas que están en la instantánea del primer trimestre pero no en la instantánea del tercer trimestre:
Ahora usamos el delta obtenido en el código anterior para probar la siguiente estrategia. Como parte del proceso de arbitraje de reequilibrio del índice, vamos a acciones largas que se agregan al índice y acciones cortas que se eliminan del índice, y probaremos esta estrategia tanto para la fecha de vigencia como para la fecha del anuncio. Como prueba de concepto de las dos listas diferentes, elegimos PVH y PENN como acciones eliminadas y CSGP e INVH como acciones añadidas.
Para seguir los ejemplos a continuación, deberá usar el cuaderno provisto en el Repositorio de GitHub de ejemplo de Quant Research.
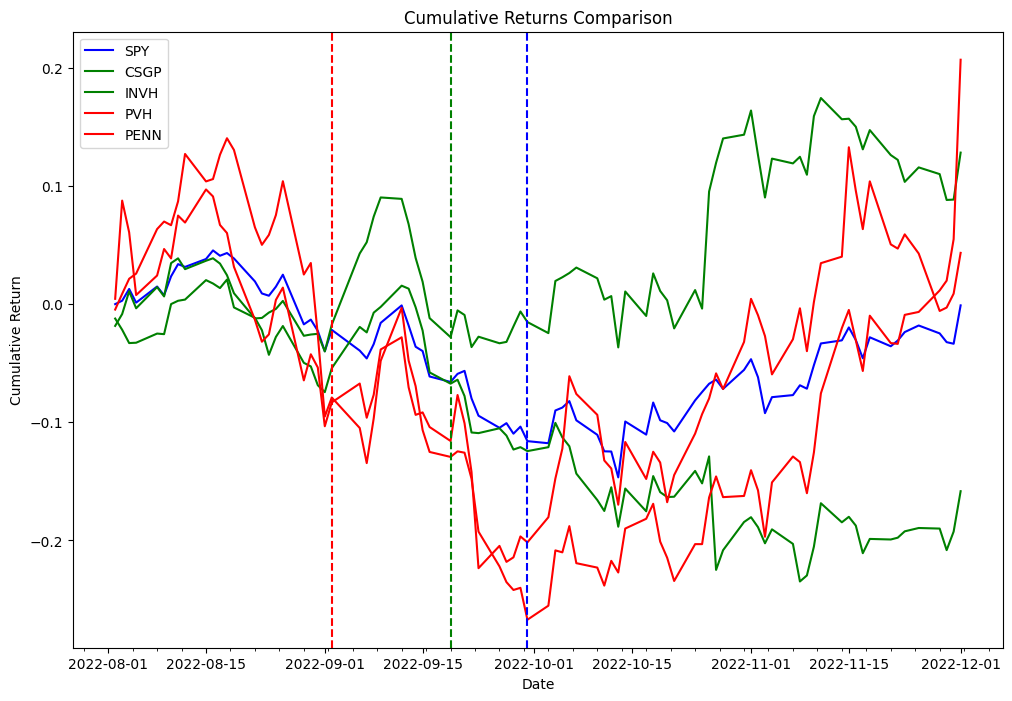
La siguiente tabla representa los registros de órdenes de cartera:
| Solicitar ID | Columna | Timestamp | Tamaño | Precio | Costes | Lado |
|---|---|---|---|---|---|---|
| 0 | (PENE, PENE) | 2022-09-06 | 31948.881789 | 31.66 | 0.0 | Vender |
| 1 | (PVH, PVH) | 2022-09-06 | 18321.729571 | 55.15 | 0.0 | Vender |
| 2 | (INVH, INVH) | 2022-09-06 | 27419.797094 | 38.20 | 0.0 | Comprar |
| 3 | (CSGP, CSGP) | 2022-09-06 | 14106.361969 | 75.00 | 0.0 | Comprar |
| 4 | (CSGP, CSGP) | 2022-11-01 | 14106.361969 | 83.70 | 0.0 | Vender |
| 5 | (INVH, INVH) | 2022-11-01 | 27419.797094 | 31.94 | 0.0 | Vender |
| 6 | (PVH, PVH) | 2022-11-01 | 18321.729571 | 52.95 | 0.0 | Comprar |
| 7 | (PENE, PENE) | 2022-11-01 | 31948.881789 | 34.09 | 0.0 | Comprar |
Hallazgos de experimentación
La siguiente tabla muestra los índices de Sharpe para varios períodos de tenencia y dos puntos de entrada comerciales diferentes: anuncio y fechas de vigencia.

Los datos sugieren que la fecha de vigencia es el punto de entrada más rentable en la mayoría de los períodos de tenencia, mientras que la fecha de anuncio es un punto de entrada efectivo para los períodos de tenencia a corto plazo (5 días calendario, 2 días hábiles). Debido a que los resultados se obtienen al probar un solo evento, esto no es estadísticamente significativo para aceptar o rechazar una hipótesis de que los eventos de reequilibrio de índices se pueden usar para generar un alfa consistente. La infraestructura que usamos para nuestras pruebas se puede usar para ejecutar el mismo experimento requerido para hacer pruebas de hipótesis a escala, pero los datos de los constituyentes del índice no están fácilmente disponibles.
Conclusión
En esta publicación, demostramos cómo el uso de backtesting y la función de etiquetado Apache Iceberg pueden proporcionar información valiosa sobre el rendimiento de las estrategias de rentabilidad del arbitraje de índices. Mediante el uso de un escalable Amazon EMR en Amazon EKS stack, los investigadores pueden manejar fácilmente todo el ciclo de vida de la investigación de inversiones, desde la recopilación de datos hasta el backtesting. Además, la función de etiquetado Iceberg puede ayudar a abordar el desafío del sesgo de anticipación, al tiempo que brinda beneficios como el control de retención de datos para el cumplimiento de GDPR y el mantenimiento del linaje de la tabla a través de diferentes sucursales. Los hallazgos del experimento demuestran la efectividad de este enfoque para evaluar el desempeño de las estrategias de arbitraje de índices y pueden servir como una guía útil para los investigadores en la industria financiera.
Acerca de los autores
 Boris Litvin es Principal Solution Architect, responsable de la innovación en la industria de servicios financieros. Es un ex fundador de Quant y FinTech, y le apasiona la inversión sistemática.
Boris Litvin es Principal Solution Architect, responsable de la innovación en la industria de servicios financieros. Es un ex fundador de Quant y FinTech, y le apasiona la inversión sistemática.
 chico bachar es arquitecto de soluciones en AWS, con sede en Nueva York. Acompaña a los clientes nuevos y los ayuda a comenzar su viaje a la nube con AWS. Es un apasionado de la identidad, la seguridad y las comunicaciones unificadas.
chico bachar es arquitecto de soluciones en AWS, con sede en Nueva York. Acompaña a los clientes nuevos y los ayuda a comenzar su viaje a la nube con AWS. Es un apasionado de la identidad, la seguridad y las comunicaciones unificadas.
 Noam Ouaknine es administrador técnico de cuentas en AWS y tiene su sede en Florida. Ayuda a los clientes empresariales a desarrollar y lograr su estrategia a largo plazo a través de orientación técnica y planificación proactiva.
Noam Ouaknine es administrador técnico de cuentas en AWS y tiene su sede en Florida. Ayuda a los clientes empresariales a desarrollar y lograr su estrategia a largo plazo a través de orientación técnica y planificación proactiva.
 Sercan Karaoglu es Senior Solutions Architect, especializado en mercado de capitales. Es un ex ingeniero de datos y un apasionado de la investigación cuantitativa de inversiones.
Sercan Karaoglu es Senior Solutions Architect, especializado en mercado de capitales. Es un ex ingeniero de datos y un apasionado de la investigación cuantitativa de inversiones.
 Jack Ye es ingeniero de software en el equipo de Athena Data Lake and Storage. Es miembro de Apache Iceberg Committer y PMC.
Jack Ye es ingeniero de software en el equipo de Athena Data Lake and Storage. Es miembro de Apache Iceberg Committer y PMC.
 Amogh Jahagirdar es ingeniero de software en el equipo de Athena Data Lake. Es un Committer Apache Iceberg.
Amogh Jahagirdar es ingeniero de software en el equipo de Athena Data Lake. Es un Committer Apache Iceberg.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/backtesting-index-rebalancing-arbitrage-with-amazon-emr-and-apache-iceberg/

