
Imagen generada con Ideograma.ai
Entonces, es posible que escuche todos estos términos de Vector Database. Algunos pueden entenderlo y otros no. No se preocupe si no las conoce, ya que las bases de datos vectoriales se han convertido en un tema más destacado en los últimos años.
Las bases de datos vectoriales han ganado popularidad gracias a la introducción de la IA generativa al público, especialmente al LLM.
Muchos productos LLM, como GPT-4 y Gemini, ayudan en nuestro trabajo al proporcionar capacidad de generación de texto para nuestra entrada. Bueno, las bases de datos vectoriales en realidad desempeñan un papel en estos productos LLM.
Pero, ¿cómo funcionó Vector Database? ¿Y cuáles son sus relevancias en el LLM?
La pregunta anterior es la que responderíamos en este artículo. Bueno, explorémoslos juntos.
Una base de datos vectorial es un almacenamiento de base de datos especializado diseñado para almacenar, indexar y consultar datos vectoriales. A menudo está optimizado para datos vectoriales de alta dimensión, ya que suele ser el resultado del modelo de aprendizaje automático, especialmente LLM.
En el contexto de una base de datos vectorial, el vector es una representación matemática de los datos. Cada vector consta de una serie de puntos numéricos que representan la posición de los datos. El vector se utiliza a menudo en el LLM para representar los datos de texto, ya que un vector es más fácil de procesar que los datos de texto.
En el espacio LLM, el modelo podría tener una entrada de texto y podría transformar el texto en un vector de alta dimensión que represente las características semánticas y sintácticas del texto. Este proceso es lo que llamamos Incrustación. En términos más simples, la incrustación es un proceso que transforma texto en vectores con datos numéricos.
La incrustación generalmente utiliza un modelo de red neuronal llamado modelo de incrustación para representar el texto en el espacio de incrustación.
Usemos un texto de ejemplo: "Me encanta la ciencia de datos". Representarlos con el modelo OpenAI text-embedding-3-small daría como resultado un vector con 1536 dimensiones.
[0.024739108979701996, -0.04105354845523834, 0.006121257785707712, -0.02210472710430622, 0.029098540544509888,...]
El número dentro del vector es la coordenada dentro del espacio de incrustación del modelo. Juntos, formarían una representación única del significado de la oración proveniente del modelo.
Vector Database sería entonces responsable de almacenar los resultados del modelo de incrustación. Luego, el usuario podría consultar, indexar y recuperar el vector según lo necesite.
Quizás esto sea suficiente introducción y entremos en una práctica más técnica. Intentaríamos establecer y almacenar vectores con una base de datos de vectores de código abierto llamada tejido.
Weaviate es una base de datos de vectores escalable de código abierto que sirve como marco para almacenar nuestro vector. Podemos ejecutar Weaviate en instancias como Docker o utilizar Weaviate Cloud Services (WCS).
Para comenzar a usar Weaviate, necesitamos instalar los paquetes usando el siguiente código:
pip install weaviate-client
Para facilitar las cosas, usaríamos un clúster sandbox de WCS para que actúe como nuestra base de datos vectorial. Weaviate proporciona un clúster gratuito de 14 días que podemos usar para almacenar nuestros vectores sin registrar ningún método de pago. Para hacer eso, debe registrarse en su consola WCS inicialmente.
Una vez dentro de la plataforma WCS, seleccione Crear un clúster e ingrese el nombre de su Sandbox. La interfaz de usuario debería verse como la imagen a continuación.
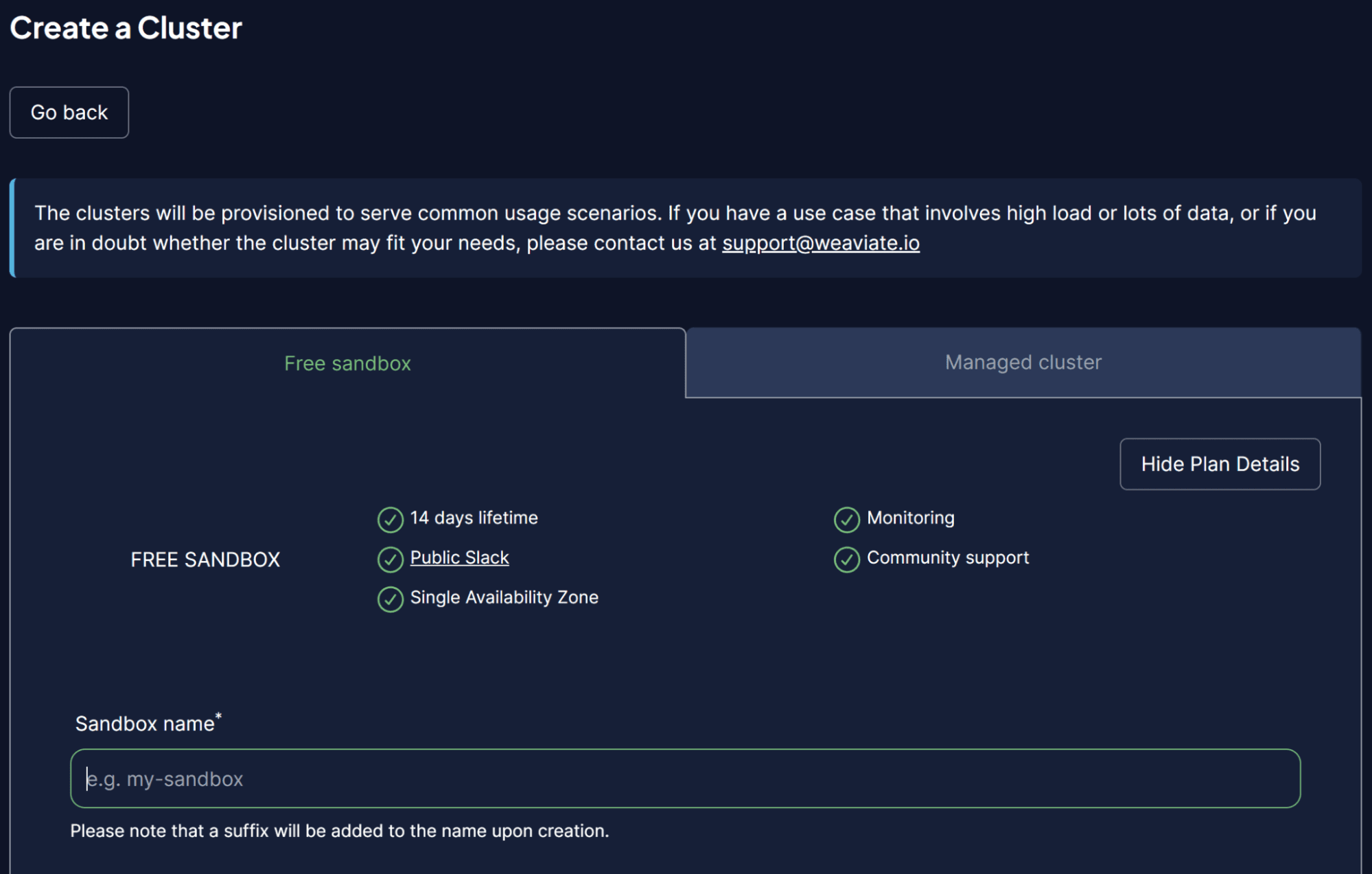
Imagen del autor
No olvide habilitar la autenticación, ya que también queremos acceder a este clúster a través de la clave API de WCS. Una vez que el clúster esté listo, busque la clave API y la URL del clúster, que usaremos para acceder a la base de datos de vectores.
Una vez que todo esté listo, simularemos almacenar nuestro primer vector en la base de datos de vectores.
Para el ejemplo de almacenamiento de la base de datos vectorial, usaría el Colección de libros conjunto de datos de ejemplo de Kaggle. Solo usaría las 100 filas y 3 columnas principales (título, descripción, introducción).
import pandas as pd
data = pd.read_csv('commonlit_texts.csv', nrows = 100, usecols=['title', 'description', 'intro'])
Dejemos a un lado nuestros datos y conectémonos a nuestra base de datos de vectores. Primero, necesitamos configurar una conexión remota usando la clave API y la URL de su clúster.
import weaviate
import os
import requests
import json
cluster_url = "Your Cluster URL"
wcs_api_key = "Your WCS API Key"
Openai_api_key ="Your OpenAI API Key"
client = weaviate.connect_to_wcs(
cluster_url=cluster_url,
auth_credentials=weaviate.auth.AuthApiKey(wcs_api_key),
headers={
"X-OpenAI-Api-Key": openai_api_key
}
)
Una vez que configure su variable de cliente, nos conectaremos al servicio de nube Weaviate y crearemos una clase para almacenar el vector. La clase en Weaviate es la recopilación de datos o análogos del nombre de la tabla en una base de datos relacional.
import weaviate.classes as wvc
client.connect()
book_collection = client.collections.create(
name="BookCollection",
vectorizer_config=wvc.config.Configure.Vectorizer.text2vec_openai(),
generative_config=wvc.config.Configure.Generative.openai()
)
En el código anterior, nos conectamos al Weaviate Cluster y creamos una clase BookCollection. El objeto de clase también utiliza el modelo de incrustación OpenAI text2vec para vectorizar los datos de texto y el módulo generativo OpenAI.
Intentemos almacenar los datos de texto en una base de datos vectorial. Para hacer eso, puede usar el siguiente código.
sent_to_vdb = data.to_dict(orient='records')
book_collection.data.insert_many(sent_to_vdb)
Imagen del autor
¡Acabamos de almacenar con éxito nuestro conjunto de datos en la base de datos de vectores! ¿Qué tan fácil es eso?
Ahora, es posible que tenga curiosidad acerca de los casos de uso de bases de datos vectoriales con LLM. Eso es lo que vamos a discutir a continuación.
Algunos casos de uso en los que se puede aplicar LLM con Vector Database. Explorémoslos juntos.
Búsqueda semántica
La búsqueda semántica es un proceso de búsqueda de datos utilizando el significado de la consulta para recuperar resultados relevantes en lugar de depender únicamente de la búsqueda tradicional basada en palabras clave.
El proceso implica la utilización del modelo LLM de incrustación de la consulta y la realización de una búsqueda de similitud de incrustación en nuestra base de datos vectorial incrustada almacenada.
Intentemos utilizar Weaviate para realizar una búsqueda semántica basada en una consulta específica.
book_collection = client.collections.get("BookCollection")
client.connect()
response = book_collection.query.near_text(
query="childhood story,
limit=2
)
En el código anterior, intentamos realizar una búsqueda semántica con Weaviate para encontrar los dos libros principales estrechamente relacionados con la historia de la infancia de la consulta. La búsqueda semántica utiliza el modelo de incrustación OpenAI que configuramos anteriormente. El resultado es el que podéis ver a continuación.
{'title': 'Act Your Age', 'description': 'A young girl is told over and over again to act her age.', 'intro': 'Colleen Archer has written for nHighlightsn. In this short story, a young girl is told over and over again to act her age.nAs you read, take notes on what Frances is doing when she is told to act her age. '}
{'title': 'The Anklet', 'description': 'A young woman must deal with unkind and spiteful treatment from her two older sisters.', 'intro': "Neil Philip is a writer and poet who has retold the best-known stories from nThe Arabian Nightsn for a modern day audience. nThe Arabian Nightsn is the English-language nickname frequently given to nOne Thousand and One Arabian Nightsn, a collection of folk tales written and collected in the Middle East during the Islamic Golden Age of the 8th to 13th centuries. In this tale, a poor young woman must deal with mistreatment by members of her own family.nAs you read, take notes on the youngest sister's actions and feelings."}
Como puede ver, en el resultado anterior no hay palabras directas sobre historias de la infancia. Sin embargo, el resultado no deja de estar muy relacionado con una historia que apunta a los niños.
Búsqueda generativa
La Búsqueda Generativa podría definirse como una aplicación de extensión de la Búsqueda Semántica. La búsqueda generativa, o generación aumentada de recuperación (RAG), utiliza indicaciones LLM con la búsqueda semántica que recupera datos de la base de datos vectorial.
Con RAG, el resultado de la búsqueda de consultas se procesa en LLM, por lo que los obtenemos en la forma que queremos en lugar de los datos sin procesar. Probemos una implementación simple de RAG con Vector Database.
response = book_collection.generate.near_text(
query="childhood story",
limit=2,
grouped_task="Write a short LinkedIn post about these books."
)
print(response.generated)
El resultado se puede ver en el texto siguiente.
Excited to share two captivating short stories that explore themes of age and mistreatment. "Act Your Age" by Colleen Archer follows a young girl who is constantly told to act her age, while "The Anklet" by Neil Philip delves into the unkind treatment faced by a young woman from her older sisters. These thought-provoking tales will leave you reflecting on societal expectations and family dynamics. #ShortStories #Literature #BookRecommendations 📚
Como puede ver, el contenido de los datos es el mismo que antes, pero ahora se ha procesado con OpenAI LLM para proporcionar una breve publicación en LinkedIn. De esta manera, RAG es útil cuando queremos una salida de forma específica a partir de los datos.
Responder preguntas con RAG
En nuestro ejemplo anterior, utilizamos una consulta para obtener los datos que queríamos y RAG procesó esos datos en el resultado deseado.
Sin embargo, podemos convertir la capacidad RAG en una herramienta para responder preguntas. Podemos lograr esto combinándolos con el marco LangChain.
Primero, instalemos los paquetes necesarios.
pip install langchain
pip install langchain_community
pip install langchain_openai
Luego, intentemos importar los paquetes e iniciar las variables que necesitamos para que el control de calidad con RAG funcione.
from langchain.chains import RetrievalQA
from langchain_community.vectorstores import Weaviate
import weaviate
from langchain_openai import OpenAIEmbeddings
from langchain_openai.llms.base import OpenAI
llm = OpenAI(openai_api_key = openai_api_key, model_name = 'gpt-3.5-turbo-instruct', temperature = 1)
embeddings = OpenAIEmbeddings(openai_api_key = openai_api_key )
client = weaviate.Client(
url=cluster_url, auth_client_secret=weaviate.AuthApiKey(wcs_api_key)
)
En el código anterior, configuramos el LLM para la generación de texto, el modelo de incrustación y la conexión del cliente Weaviate.
A continuación, configuramos la conexión de Weaviate a la base de datos de vectores.
weaviate_vectorstore = Weaviate(client=client, index_name='BookCollection', text_key='intro',by_text = False, embedding=embeddings)
retriever = weaviate_vectorstore.as_retriever()
En el código anterior, haga que Weaviate Database BookCollection sea la herramienta RAG que buscará la función 'introducción' cuando se le solicite.
Luego, crearíamos una cadena de respuestas a preguntas a partir de LangChain con el siguiente código.
qa_chain = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever = retriever
)
Ya todo está listo. Probemos el control de calidad con RAG usando el siguiente ejemplo de código.
response = qa_chain.invoke(
"Who is the writer who write about love between two goldfish?")
print(response)
El resultado se muestra en el texto siguiente.
{'query': 'Who is the writer who write about love between two goldfish?', 'result': ' The writer is Grace Chua.'}
Con Vector Database como lugar para almacenar todos los datos de texto, podemos implementar RAG para realizar control de calidad con LangChain. ¿Qué tan genial es eso?
Una base de datos vectorial es una solución de almacenamiento especializada diseñada para almacenar, indexar y consultar datos vectoriales. A menudo se utiliza para almacenar datos de texto y se implementa junto con modelos de lenguaje grandes (LLM). Este artículo probará una configuración práctica de Vector Database Weaviate, incluidos casos de uso de ejemplo como búsqueda semántica, generación aumentada de recuperación (RAG) y respuesta a preguntas con RAG.
Cornelio Yudha Wijaya es subgerente de ciencia de datos y redactor de datos. Mientras trabaja a tiempo completo en Allianz Indonesia, le encanta compartir consejos sobre datos y Python a través de las redes sociales y los medios escritos. Cornellius escribe sobre una variedad de temas de inteligencia artificial y aprendizaje automático.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/vector-databases-in-ai-and-llm-use-cases?utm_source=rss&utm_medium=rss&utm_campaign=vector-databases-in-ai-and-llm-use-cases

