Esta publicación es en coautoría con Hernan Figueroa, gerente sénior de ciencia de datos en Marubeni Power International.
Marubeni Power International Inc. (MPII) posee e invierte en plataformas de negocios de energía en las Américas. Una vertical importante para MPII es la gestión de activos para energías renovables y activos de almacenamiento de energía, que son fundamentales para reducir la intensidad de carbono de nuestra infraestructura energética. Trabajar con activos de energía renovable requiere soluciones digitales predictivas y receptivas, porque la generación de energía renovable y las condiciones del mercado eléctrico están cambiando continuamente. MPII está utilizando un motor de optimización de ofertas de aprendizaje automático (ML) para informar los procesos de toma de decisiones aguas arriba en la gestión y el comercio de activos de energía. Esta solución ayuda a los analistas de mercado a diseñar y ejecutar estrategias de licitación basadas en datos optimizadas para la rentabilidad de los activos de energía.
En esta publicación, aprenderá cómo Marubeni está optimizando las decisiones de mercado mediante el uso del amplio conjunto de servicios de análisis y aprendizaje automático de AWS para crear una solución robusta y rentable de optimización de ofertas de energía.
Resumen de la solución
Los mercados de electricidad permiten comercializar potencia y energía para equilibrar la oferta y la demanda de energía en la red eléctrica y para cubrir las diferentes necesidades de confiabilidad de la red eléctrica. Los participantes del mercado, como los operadores de activos de MPII, están ofertando constantemente cantidades de potencia y energía en estos mercados de electricidad para obtener ganancias de sus activos de energía. Un participante del mercado puede presentar ofertas a diferentes mercados simultáneamente para aumentar la rentabilidad de un activo, pero debe considerar los límites de poder de los activos y las velocidades de respuesta, así como otras limitaciones operativas de los activos y la interoperabilidad de esos mercados.
La solución del motor de optimización de ofertas de MPII utiliza modelos ML para generar ofertas óptimas para la participación en diferentes mercados. Las ofertas más comunes son las ofertas de energía diarias, que deben presentarse 1 día antes del día de negociación real, y las ofertas de energía en tiempo real, que deben enviarse 75 minutos antes de la hora de negociación. La solución orquesta la licitación dinámica y la operación de un activo de energía y requiere el uso de capacidades predictivas y de optimización disponibles en sus modelos ML.
La solución Power Bid Optimization incluye varios componentes que desempeñan funciones específicas. Repasemos los componentes involucrados y su función comercial respectiva.
Recopilación e ingesta de datos
La capa de recopilación e ingesta de datos se conecta a todas las fuentes de datos ascendentes y carga los datos en el lago de datos. La licitación del mercado eléctrico requiere al menos cuatro tipos de insumos:
- Previsiones de demanda de electricidad
- Los pronósticos del tiempo
- Historial de precios de mercado
- Previsiones de precios de energía
A estas fuentes de datos se accede exclusivamente a través de API. Por lo tanto, los componentes de ingestión deben poder administrar la autenticación, el abastecimiento de datos en modo de extracción, el preprocesamiento de datos y el almacenamiento de datos. Debido a que los datos se obtienen cada hora, también se requiere un mecanismo para orquestar y programar los trabajos de ingesta.
Preparación de datos
Al igual que con la mayoría de los casos de uso de ML, la preparación de datos juega un papel fundamental. Los datos provienen de fuentes dispares en varios formatos. Antes de que esté listo para ser consumido para el entrenamiento del modelo ML, debe pasar por algunos de los siguientes pasos:
- Consolide conjuntos de datos por hora en función de la hora de llegada. Un conjunto de datos completo debe incluir todas las fuentes.
- Aumente la calidad de los datos utilizando técnicas como la estandarización, la normalización o la interpolación.
Al final de este proceso, los datos seleccionados se organizan y se ponen a disposición para su posterior consumo.
Entrenamiento e implementación de modelos
El siguiente paso consiste en entrenar y desplegar un modelo capaz de predecir las ofertas óptimas del mercado para comprar y vender energía. Para minimizar el riesgo de bajo rendimiento, Marubeni utilizó la técnica de modelado de conjunto. El modelado de conjuntos consiste en combinar múltiples modelos de ML para mejorar el rendimiento de la predicción. Marubeni agrupa los resultados de los modelos de predicción externos e internos con un promedio ponderado para aprovechar la fortaleza de todos los modelos. Los modelos internos de Marubeni se basan en arquitecturas de memoria a corto plazo (LSTM), que están bien documentadas y son fáciles de implementar y personalizar en TensorFlow. Amazon SageMaker admite implementaciones de TensorFlow y muchos otros entornos de ML. El modelo externo es propietario y su descripción no se puede incluir en esta publicación.
En el caso de uso de Marubeni, los modelos de licitación realizan una optimización numérica para maximizar los ingresos utilizando una versión modificada de las funciones objetivo utilizadas en la publicación. Oportunidades para el almacenamiento de energía en CAISO.
SageMaker permite a Marubeni ejecutar ML y algoritmos de optimización numérica en un solo entorno. Esto es fundamental, porque durante el entrenamiento del modelo interno, la salida de la optimización numérica se usa como parte de la función de pérdida de predicción. Para obtener más información sobre cómo abordar los casos de uso de optimización numérica, consulte Resolver problemas de optimización numérica como programación, enrutamiento y asignación con Amazon SageMaker Processing.
Luego implementamos esos modelos a través de puntos finales de inferencia. Como los datos nuevos se incorporan periódicamente, los modelos deben volver a entrenarse porque se vuelven obsoletos con el tiempo. La sección de arquitectura más adelante en esta publicación proporciona más detalles sobre el ciclo de vida de los modelos.
Generación de datos de oferta de potencia
Cada hora, la solución predice las cantidades y los precios óptimos a los que se debe ofrecer energía en el mercado, también llamado ofertas. Las cantidades se miden en MW y los precios en $/MW. Las ofertas se generan para múltiples combinaciones de condiciones de mercado previstas y percibidas. La siguiente tabla muestra un ejemplo de la última curva de oferta salida para la hora de operación 17 en un nodo comercial ilustrativo cerca de la oficina de Los Ángeles de Marubeni.
| Fecha | Hora | Mercado | Destino | MW | Precio |
| 11/7/2022 | 17 | Energía RT | LCIENEGA_6_N001 | 0 | $0 |
| 11/7/2022 | 17 | Energía RT | LCIENEGA_6_N001 | 1.65 | $80.79 |
| 11/7/2022 | 17 | Energía RT | LCIENEGA_6_N001 | 5.15 | $105.34 |
| 11/7/2022 | 17 | Energía RT | LCIENEGA_6_N001 | 8 | $230.15 |
Este ejemplo representa nuestra disposición a ofertar 1.65 MW de potencia si el precio de la potencia es de al menos $80.79, 5.15 MW si el precio de la potencia es de al menos $105.34 y 8 MW si el precio de la potencia es de al menos $230.15.
Los operadores independientes del sistema (ISO) supervisan los mercados de electricidad en los EE. UU. y son responsables de adjudicar y rechazar las ofertas para mantener la confiabilidad de la red eléctrica de la manera más económica. El Operador Independiente del Sistema de California (CAISO) opera los mercados de electricidad en California y publica los resultados del mercado cada hora antes de la próxima ventana de licitación. Al comparar las condiciones actuales del mercado con su equivalente en la curva, los analistas pueden inferir los ingresos óptimos. La solución Power Bid Optimization actualiza las ofertas futuras utilizando nueva información de mercado entrante y nuevos resultados predictivos del modelo.
Descripción general de la arquitectura de AWS
La arquitectura de la solución ilustrada en la siguiente figura implementa todas las capas presentadas anteriormente. Utiliza los siguientes servicios de AWS como parte de la solución:
- Servicio de almacenamiento simple de Amazon (Amazon S3) para almacenar los siguientes datos:
- Precios, clima y datos de pronóstico de carga de varias fuentes.
- Datos consolidados y aumentados listos para ser utilizados para el entrenamiento de modelos.
- Curvas de oferta de salida actualizadas cada hora.
- Amazon SageMaker para entrenar, probar e implementar modelos para ofrecer ofertas optimizadas a través de puntos finales de inferencia.
- Funciones de paso de AWS para orquestar las canalizaciones de datos y ML. Usamos dos máquinas de estado:
- Una máquina de estado para orquestar la recopilación de datos y garantizar que todas las fuentes hayan sido ingeridas.
- Una máquina de estado para orquestar la canalización de ML, así como el flujo de trabajo de generación de ofertas optimizado.
- AWS Lambda para implementar la funcionalidad de ingestión, preprocesamiento y posprocesamiento:
- Tres funciones para ingerir fuentes de datos de entrada, con una función por fuente.
- Una función para consolidar y preparar los datos para el entrenamiento.
- Una función que genera la previsión de precios llamando al extremo del modelo implementado en SageMaker.
- Atenea amazónica para proporcionar a los desarrolladores y analistas de negocios acceso SQL a los datos generados para el análisis y la resolución de problemas.
- Puente de eventos de Amazon para activar la ingestión de datos y la canalización de ML según un cronograma y en respuesta a eventos.
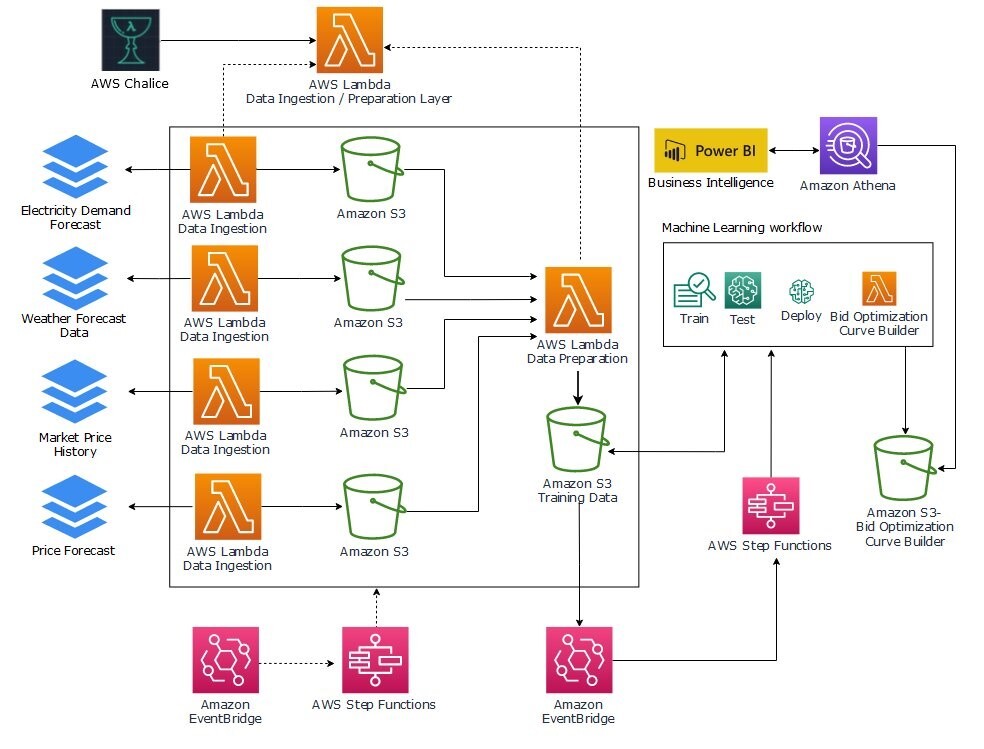
En las siguientes secciones, analizamos el flujo de trabajo con más detalle.
Recopilación y preparación de datos
Cada hora, se invoca la máquina de estado Step Functions de preparación de datos. Llama a cada una de las funciones Lambda de ingesta de datos en paralelo y espera a que se completen las cuatro. Las funciones de recopilación de datos llaman a su API de origen respectiva y recuperan los datos de la última hora. Luego, cada función almacena los datos recibidos en su depósito S3 respectivo.
Estas funciones comparten una línea de base de implementación común que proporciona elementos básicos para la manipulación de datos estándar, como la normalización o la indexación. Para lograr esto, usamos capas Lambda y Cáliz de AWS, como se describe en Uso de capas de AWS Lambda con AWS Chalice. Esto garantiza que todos los desarrolladores utilicen las mismas bibliotecas base para crear nuevas lógicas de preparación de datos y acelerar la implementación.
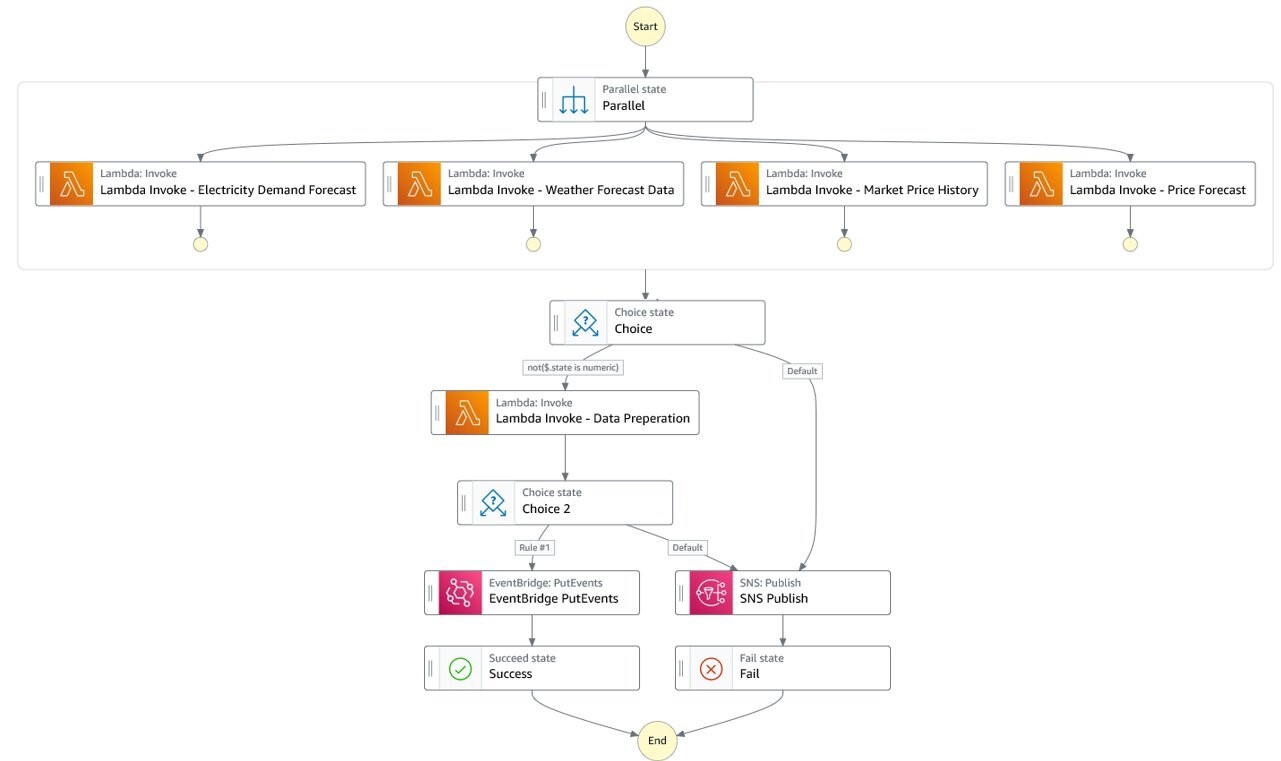
Una vez que se han ingerido y almacenado las cuatro fuentes, la máquina de estado activa la función Lambda de preparación de datos. Los datos sobre el precio de la energía, el clima y el pronóstico de carga se reciben en archivos JSON y delimitados por caracteres. Cada parte de registro de cada archivo lleva una marca de tiempo que se utiliza para consolidar las fuentes de datos en un conjunto de datos que cubre un marco de tiempo de 1 hora.
Esta construcción proporciona un flujo de trabajo totalmente controlado por eventos. La preparación de datos de entrenamiento se inicia tan pronto como se ingieren todos los datos esperados.
Canalización de ML
Después de la preparación de datos, los nuevos conjuntos de datos se almacenan en Amazon S3. Una regla de EventBridge activa la canalización de ML a través de una máquina de estado de Step Functions. La máquina de estado impulsa dos procesos:
- Comprobar si el modelo de generación de la curva de oferta está actualizado
- Active automáticamente el reentrenamiento del modelo cuando el rendimiento se degrade o los modelos tengan más de una cierta cantidad de días.
Si la antigüedad del modelo implementado actualmente es más antigua que el último conjunto de datos por un cierto umbral, digamos 7 días, la máquina de estado de Step Functions inicia la canalización de SageMaker que entrena, prueba e implementa un nuevo punto final de inferencia. Si los modelos aún están actualizados, el flujo de trabajo omite la canalización de ML y pasa al paso de generación de ofertas. Independientemente del estado del modelo, se genera una nueva curva de oferta tras la entrega de un nuevo conjunto de datos por hora. El siguiente diagrama ilustra este flujo de trabajo. Por defecto, el StartPipelineExecution la acción es asíncrona. Podemos hacer que la máquina de estado espere el final de la canalización antes de invocar el paso de generación de ofertas usando el 'Esperar devolución de llamada' opción.


Para reducir el costo y el tiempo de comercialización en la creación de una solución piloto, Marubeni utilizó Inferencia sin servidor de Amazon SageMaker. Esto garantiza que la infraestructura subyacente utilizada para la capacitación y la implementación incurra en cargos solo cuando sea necesario. Esto también facilita el proceso de construcción de la canalización porque los desarrolladores ya no necesitan administrar la infraestructura. Esta es una excelente opción para cargas de trabajo que tienen períodos de inactividad entre picos de tráfico. A medida que la solución madure y pase a producción, Marubeni revisará su diseño y adoptará una configuración más adecuada para un uso predecible y constante.
Generación de ofertas y consulta de datos
La función Lambda de generación de ofertas invoca periódicamente el punto final de inferencia para generar predicciones por hora y almacena el resultado en Amazon S3.
Luego, los desarrolladores y analistas de negocios pueden explorar los datos usando Athena y Microsoft Power BI para la visualización. Los datos también pueden estar disponibles a través de API para aplicaciones comerciales posteriores. En la fase piloto, los operadores consultan visualmente la curva de oferta para respaldar sus actividades de transacciones de energía en los mercados. Sin embargo, Marubeni está considerando automatizar este proceso en el futuro y esta solución brinda las bases necesarias para hacerlo.
Conclusión
Esta solución permitió a Marubeni automatizar por completo sus canalizaciones de ingesta y procesamiento de datos, así como reducir el tiempo de implementación de sus modelos predictivos y de optimización de horas a minutos. Las curvas de oferta ahora se generan automáticamente y se mantienen actualizadas a medida que cambian las condiciones del mercado. También lograron una reducción de costos del 80 % al cambiar de un punto final de inferencia aprovisionado a un punto final sin servidor.
La solución de pronóstico de MPII es una de las recientes iniciativas de transformación digital que Marubeni Corporation está lanzando en el sector eléctrico. MPII planea construir soluciones digitales adicionales para soportar nuevas plataformas comerciales de energía. MPII puede confiar en los servicios de AWS para respaldar su estrategia de transformación digital en muchos casos de uso.
"Podemos centrarnos en administrar la cadena de valor para nuevas plataformas comerciales, sabiendo que AWS administra la infraestructura digital subyacente de nuestras soluciones."
– Hernan Figueroa, Gerente Sr. Data Science en Marubeni Power International.
Para obtener más información sobre cómo AWS está ayudando a las organizaciones de energía en sus iniciativas de sostenibilidad y transformación digital, consulte Energía AWS.
![]() Marubeni Power International es una subsidiaria de Marubeni Corporation. Marubeni Corporation es un importante conglomerado japonés de comercio e inversión. La misión de Marubeni Power International es desarrollar nuevas plataformas comerciales, evaluar nuevas tendencias y tecnologías energéticas y administrar la cartera de energía de Marubeni en las Américas. Si desea saber más sobre Marubeni Power, consulte https://www.marubeni-power.com/.
Marubeni Power International es una subsidiaria de Marubeni Corporation. Marubeni Corporation es un importante conglomerado japonés de comercio e inversión. La misión de Marubeni Power International es desarrollar nuevas plataformas comerciales, evaluar nuevas tendencias y tecnologías energéticas y administrar la cartera de energía de Marubeni en las Américas. Si desea saber más sobre Marubeni Power, consulte https://www.marubeni-power.com/.
Acerca de los autores
 Hernán Figueroa lidera las iniciativas de transformación digital en Marubeni Power International. Su equipo aplica ciencia de datos y tecnologías digitales para respaldar las estrategias de crecimiento de Marubeni Power. Antes de unirse a Marubeni, Hernán era científico de datos en la Universidad de Columbia. Tiene un doctorado. en Ingeniería Eléctrica y una Licenciatura en Ingeniería Informática.
Hernán Figueroa lidera las iniciativas de transformación digital en Marubeni Power International. Su equipo aplica ciencia de datos y tecnologías digitales para respaldar las estrategias de crecimiento de Marubeni Power. Antes de unirse a Marubeni, Hernán era científico de datos en la Universidad de Columbia. Tiene un doctorado. en Ingeniería Eléctrica y una Licenciatura en Ingeniería Informática.
 lino brescia es un ejecutivo de cuenta principal con sede en la ciudad de Nueva York. Tiene más de 25 años de experiencia en tecnología y se unió a AWS en 2018. Administra clientes empresariales globales a medida que transforman su negocio con los servicios en la nube de AWS y realizan migraciones a gran escala.
lino brescia es un ejecutivo de cuenta principal con sede en la ciudad de Nueva York. Tiene más de 25 años de experiencia en tecnología y se unió a AWS en 2018. Administra clientes empresariales globales a medida que transforman su negocio con los servicios en la nube de AWS y realizan migraciones a gran escala.
 Narciso Zekpa es Arquitecto de Soluciones Sr. con sede en Boston. Ayuda a los clientes del noreste de EE. UU. a acelerar la transformación de su negocio a través de soluciones innovadoras y escalables en la nube de AWS. Cuando Narcisse no está construyendo, disfruta pasar tiempo con su familia, viajar, cocinar, jugar baloncesto y correr.
Narciso Zekpa es Arquitecto de Soluciones Sr. con sede en Boston. Ayuda a los clientes del noreste de EE. UU. a acelerar la transformación de su negocio a través de soluciones innovadoras y escalables en la nube de AWS. Cuando Narcisse no está construyendo, disfruta pasar tiempo con su familia, viajar, cocinar, jugar baloncesto y correr.
 Pedram Jahangiri es arquitecto de soluciones empresariales de AWS, con un doctorado en ingeniería eléctrica. Tiene más de 10 años de experiencia en la industria energética y de TI. Pedram tiene muchos años de experiencia práctica en todos los aspectos de Advanced Analytics para crear soluciones cuantitativas y a gran escala para empresas mediante el aprovechamiento de las tecnologías de la nube.
Pedram Jahangiri es arquitecto de soluciones empresariales de AWS, con un doctorado en ingeniería eléctrica. Tiene más de 10 años de experiencia en la industria energética y de TI. Pedram tiene muchos años de experiencia práctica en todos los aspectos de Advanced Analytics para crear soluciones cuantitativas y a gran escala para empresas mediante el aprovechamiento de las tecnologías de la nube.
 Sara Childers es un administrador de cuentas con sede en Washington DC. Ella es una ex educadora de ciencias convertida en entusiasta de la nube enfocada en ayudar a los clientes a través de su viaje a la nube. Sarah disfruta trabajar junto a un equipo motivado que fomenta ideas diversificadas para equipar mejor a los clientes con las soluciones más innovadoras y completas.
Sara Childers es un administrador de cuentas con sede en Washington DC. Ella es una ex educadora de ciencias convertida en entusiasta de la nube enfocada en ayudar a los clientes a través de su viaje a la nube. Sarah disfruta trabajar junto a un equipo motivado que fomenta ideas diversificadas para equipar mejor a los clientes con las soluciones más innovadoras y completas.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/how-marubeni-is-optimizing-market-decisions-using-aws-machine-learning-and-analytics/

